 网硕互联帮助中心
网硕互联帮助中心大家好,这里是程序员阿亮,最近发现有一个Redis比较少见的面试题—Redis脑裂问题,这里来给大家做分享,给大家避避坑。
前言
脑裂,如其名,那就是意味着脑子分成多份,那Redis的脑裂又是什么意思呢?
一、Redis脑裂是什么?
Redis 脑裂(Split-Brain)是指在 Redis 高可用架构(如哨兵模式或集群模式)中,由于网络分区或节点故障,导致系统中同时存在两个或多个节点都认为自己是主节点(Master),并各自接受写请求,从而造成数据不一致、冲突甚至丢失的现象。
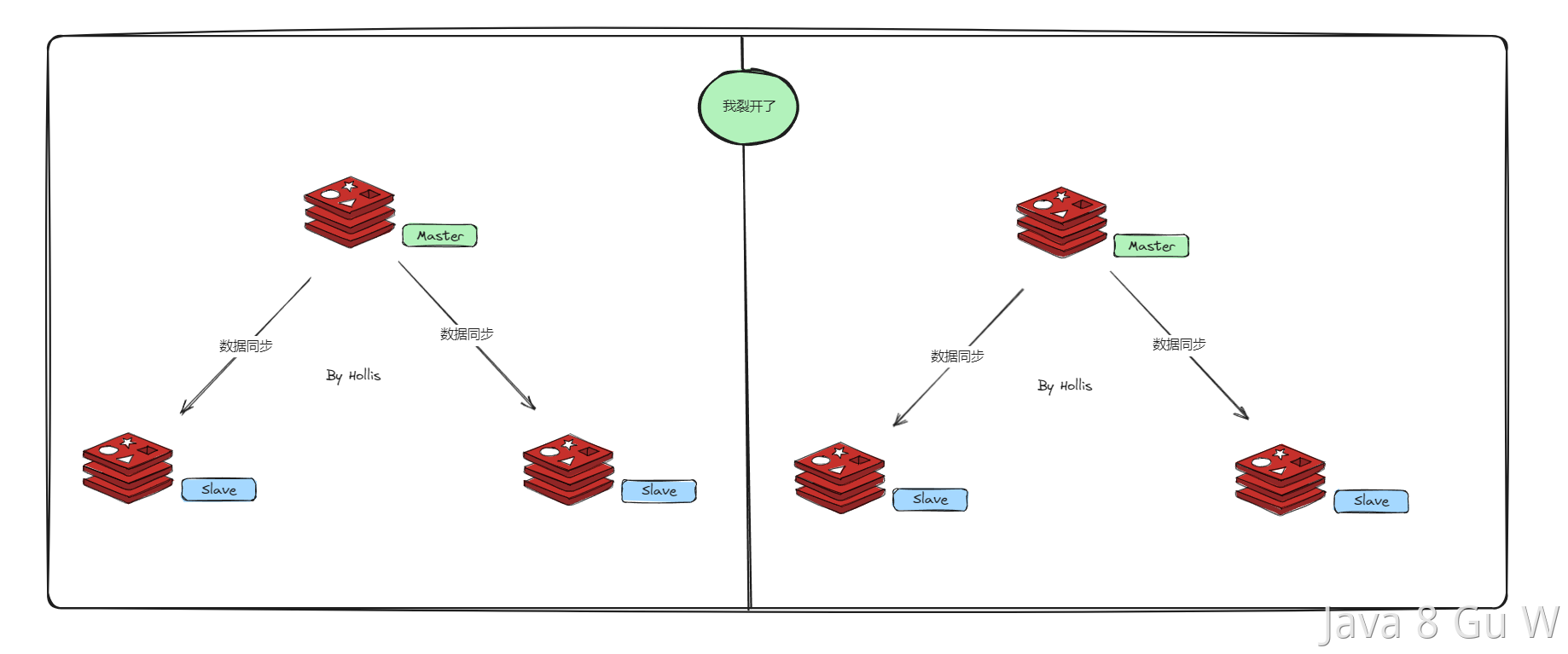
二、发生条件
1.网络分区
- 主节点与部分从节点/哨兵失联,但自身仍能被部分客户端访问。
- 哨兵在另一侧选举出新主节点 → 出现两个 Master。
2.主节点短暂宕机后快速恢复
- 原主节点未及时降级为从节点,就重新开始接受写入。
- 此时新主节点也在运行 → 双主写入。
3.后果
- 写入到旧 Master 的数据,在其被重新同步为从节点时会被覆盖或清空(执行 SLAVEOF 或 REPLICAOF 时会全量同步新主数据)。
- 用户可能看到“写成功了,但数据不见了”。
三、Redis的解决方案
参数介绍
1.min-replicas-to-write(旧版本中为 min-slaves-to-write)
含义:主节点(Master)要接受写操作,必须至少有 N 个从节点(Replica/Slave)处于正常连接状态。 作用:防止主节点在与大多数从节点失联时仍继续写入——这种情况下它很可能已被哨兵集群“罢免”,若继续写入会导致脑裂。
2.min-replicas-max-lag(旧版本中为 min-slaves-max-lag)
含义:从节点的复制延迟不能超过指定秒数(例如 10 秒),才被视为“有效在线”。 作用:避免主节点误判“假活”从节点(如网络卡顿、进程阻塞但未断连)为健康节点,从而错误地认为自己仍具备写入资格。
解决方案
当主节点无法满足上述两个条件时,会自动拒绝写请求(返回错误),从而:
- 阻止旧主在脑裂场景下继续写入脏数据;
- 强制客户端转向新主节点;
- 大幅降低数据冲突和丢失的风险。
注意:这两个参数不能 100% 消除脑裂(因分布式系统本质限制),但能显著缩小脑裂发生的时间窗口,是生产环境推荐配置。
只能尽量避免
这种解决方案是生产环境推荐的配置,但是不是完全避免的。
如果我们的Redis的Master的时间宕机比较短,并且我们的min-replicas-to-write比较小,小于我们的min-replicas-max-lag,但是我们的哨兵在Master宕机的时候选了新主节点,又因为旧Master没有被废除,所以就还是会有脑裂风险。
总结
脑裂问题主要是因为网络分区或者主节点故障导致的Redis多主节点的分区问题,会导致数据不一致、数据丢失等问题。
可以通过配置合理的min-replicas-max-lag、min-replicas-to-write去尽量避免,但是无法彻底解决。
因为在CAP中,我们集群一定要要满足P,但是我们也要保证Redis的高可用性。





评论前必须登录!
注册