 网硕互联帮助中心
网硕互联帮助中心| 实战代码系列最新文章😉 | C++实现图书管理系统(Qt C++ GUI界面版) |
| SpringBoot实战系列🐷 | 【SpringBoot实战系列】SpringBoot3.X 整合 MinIO 存储原生方案 |
| 分库分表 | 分库分表之实战-sharding-JDBC分库分表执行流程原理剖析 |
| 消息队列 | 深入浅出 RabbitMQ-RabbitMQ消息确认机制(ACK) |
| AI大模型 | 零基础学AI大模型之LLM存储记忆功能之BaseChatMemory实战 |
前情摘要
1、零基础学AI大模型之读懂AI大模型 2、零基础学AI大模型之从0到1调用大模型API 3、零基础学AI大模型之SpringAI 4、零基础学AI大模型之AI大模型常见概念 5、零基础学AI大模型之大模型私有化部署全指南 6、零基础学AI大模型之AI大模型可视化界面 7、零基础学AI大模型之LangChain 8、零基础学AI大模型之LangChain六大核心模块与大模型IO交互链路 9、零基础学AI大模型之Prompt提示词工程 10、零基础学AI大模型之LangChain-PromptTemplate 11、零基础学AI大模型之ChatModel聊天模型与ChatPromptTemplate实战 12、零基础学AI大模型之LangChain链 13、零基础学AI大模型之Stream流式输出实战 14、零基础学AI大模型之LangChain Output Parser 15、零基础学AI大模型之解析器PydanticOutputParser 16、零基础学AI大模型之大模型的“幻觉” 17、零基础学AI大模型之RAG技术 18、零基础学AI大模型之RAG系统链路解析与Document Loaders多案例实战 19、零基础学AI大模型之LangChain PyPDFLoader实战与PDF图片提取全解析 20、零基础学AI大模型之LangChain WebBaseLoader与Docx2txtLoader实战 21、零基础学AI大模型之RAG系统链路构建:文档切割转换全解析 22、零基础学AI大模型之LangChain 文本分割器实战:CharacterTextSplitter 与 RecursiveCharacterTextSplitter 全解析 23、零基础学AI大模型之Embedding与LLM大模型对比全解析 24、零基础学AI大模型之LangChain Embedding框架全解析 25、零基础学AI大模型之嵌入模型性能优化 26、零基础学AI大模型之向量数据库介绍与技术选型思考 27、零基础学AI大模型之Milvus向量数据库全解析 28、零基础学AI大模型之Milvus核心:分区-分片-段结构全解+最佳实践 29、零基础学AI大模型之Milvus部署架构选型+Linux实战:Docker一键部署+WebUI使用 30、零基础学AI大模型之Milvus实战:Attu可视化安装+Python整合全案例 31、零基础学AI大模型之Milvus索引实战 32、零基础学AI大模型之Milvus DML实战 33、零基础学AI大模型之Milvus向量Search查询综合案例实战 33、零基础学AI大模型之新版LangChain向量数据库VectorStore设计全解析 34、零基础学AI大模型之相似度Search与MMR最大边界相关搜索实战 35、零基础学AI大模型之LangChain整合Milvus:新增与删除数据实战 36、零基础学AI大模型之LangChain+Milvus实战:相似性搜索与MMR多样化检索全解析 37、零基础学AI大模型之LangChain Retriever 38、零基础学AI大模型之MultiQueryRetriever多查询检索全解析 39、零基础学AI大模型之LangChain核心:Runnable接口底层实现 40、零基础学AI大模型之RunnablePassthrough 41、零基础学AI大模型之RunnableParallel 42、零基础学AI大模型之RunnableLambda 43、零基础学AI大模型之RunnableBranch 44、零基础学AI大模型之Agent智能体 45、零基础学AI大模型之LangChain Tool工具 46、零基础学AI大模型之LLM绑定Tool工具实战 47、零基础学AI大模型之LangChain Tool异常处理 48、零基础学AI大模型之CoT思维链和ReAct推理行动 49、零基础学AI大模型之Zero-Shot和Few-Shot 50、零基础学AI大模型之LangChain智能体执行引擎AgentExecutor 51、零基础学AI大模型之个人助理智能体之tool_calling_agent实战 52、零基础学AI大模型之旅游规划智能体之react_agent实战 53、零基础学AI大模型之LLM大模型存储记忆功能 54、零基础学AI大模型之LLM大模型存储记忆功能
本文章目录
-
- 前情摘要
- 零基础学AI大模型之LLM存储优化:大量QA与长对话问题实战
-
- 一、先搞懂面试常问:为什么会有“存储优化”需求?
-
- 面试题1:传统对话系统每次交互独立,模型无法感知历史,怎么解?
- 面试题2:长对话超出模型Token能力,信息截断、性能下降,怎么解?
- 二、大模型存储的3大核心痛点
- 三、核心解决方案:摘要存储+LangChain实战
-
- 核心目标
- 技术原理
- 优势
- 四、带摘要存储的对话系统
-
- 实战准备
- 实战1:基础版——生成对话摘要
- 实战2:进阶版——带摘要存储的对话链
- 工藤实战输出效果(真实运行结果)
- 四、关键知识点:LCEL和LLMChain怎么选?
- 五、避坑指南
- 总结
零基础学AI大模型之LLM存储优化:大量QA与长对话问题实战
哈喽,各位小伙伴!我是工藤学编程🦉 最近有不少粉丝问我:“工藤,做智能助手时,用户聊得久了模型就‘失忆’,大量QA信息存不下怎么办?” 其实这也是我刚开始做AI大模型项目时踩过的坑——模型有Token限制,长对话会截断,全存历史又耗资源。今天就结合我的实战经验,聊聊怎么用LangChain的摘要存储解决这个问题,从面试考点到代码实战,一步步讲明白!
一、先搞懂面试常问:为什么会有“存储优化”需求?

我之前面试时,面试官就问过两个灵魂问题,正好戳中核心痛点,咱们先吃透这两个问题,后面实战就好理解了:
面试题1:传统对话系统每次交互独立,模型无法感知历史,怎么解?
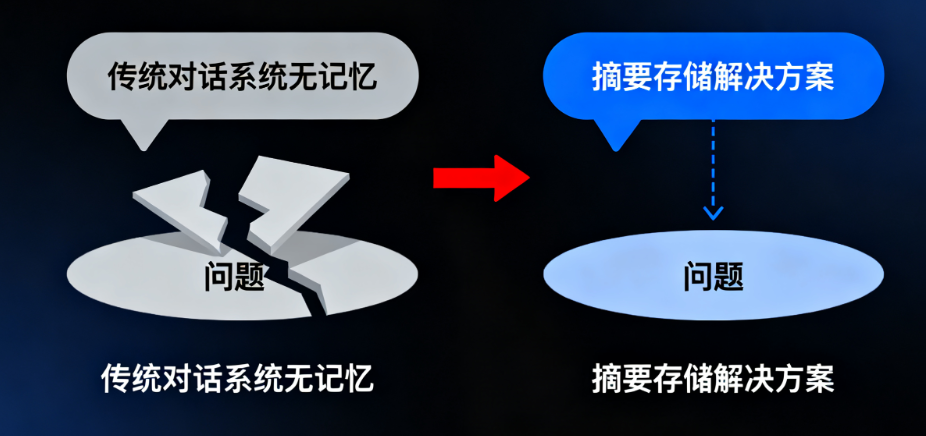
答:用记忆模块(如LangChain的Memory)记录历史,但长对话会超Token,所以需要摘要存储——不存完整对话,只存关键信息摘要,既保连贯性又省Token。
面试题2:长对话超出模型Token能力,信息截断、性能下降,怎么解?
答:核心是“压缩历史”——用大模型生成对话摘要,后续交互只传摘要而非全量历史,搭配分布式存储(如MongoDB、Milvus),平衡连贯性、性能和资源消耗。
二、大模型存储的3大核心痛点
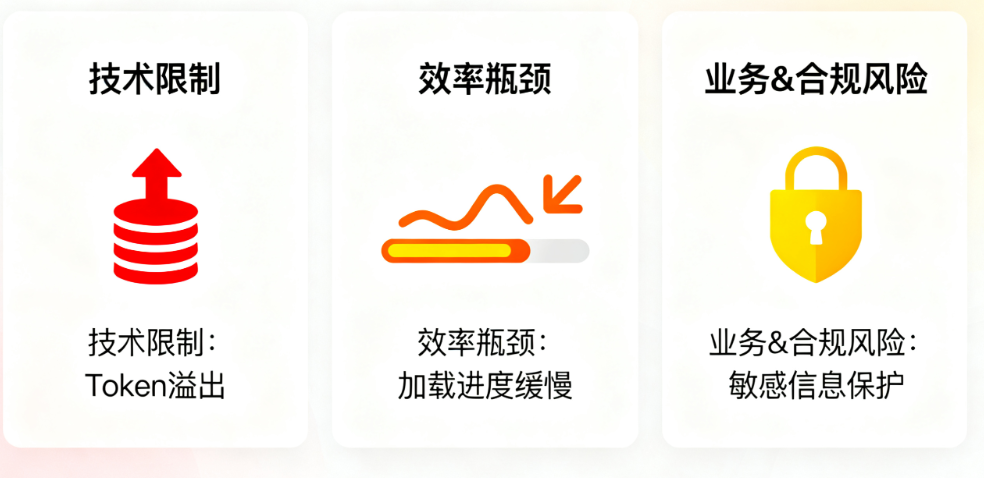
这些痛点真的很影响用户体验,咱们对号入座:
| 技术限制 | 用户聊10轮就超4k Token限制 | 早期QA信息丢失,回答驴唇不对马嘴 |
| 效率瓶颈 | 全量存历史,检索一次要600ms+ | 回复慢,用户吐槽“反应迟钝” |
| 业务&合规风险 | 存用户手机号、需求等敏感信息原文 | 有数据泄露风险,质检溯源难 |
三、核心解决方案:摘要存储+LangChain实战
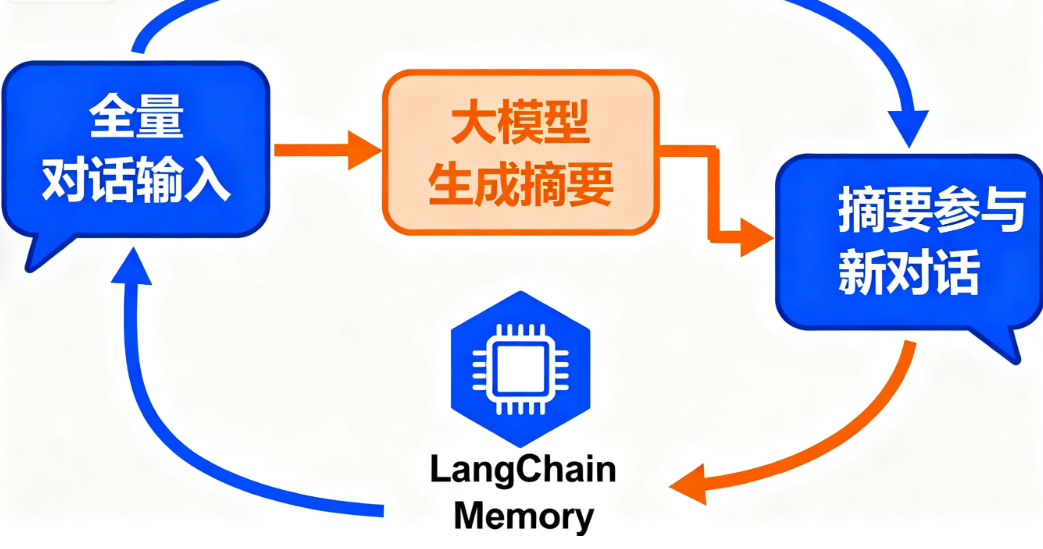
解决思路很简单:用ConversationSummaryMemory生成对话摘要,只存摘要不存全量历史。优势特别明显:
核心目标
通过摘要存储维护长期上下文,解决“Token不够用、资源消耗大、连贯性差”三大问题。
技术原理
就像我记笔记——不抄老师每句话,只记重点。模型也一样:用大模型(如通义千问)把对话生成摘要,后续交互只传摘要,相当于“带着笔记聊天”,而非“带着整本书聊天”。
优势
四、带摘要存储的对话系统
实战准备
先安装依赖:
pip install langchain langchain-openai langchain-core pymilvus # 按需装存储依赖
实战1:基础版——生成对话摘要
这是最基础的用法,我用来测试摘要效果,看看模型能不能抓关键信息:
from langchain.memory import ConversationSummaryMemory
from langchain_openai import ChatOpenAI
# 初始化大模型(工藤用的通义千问,大家替换自己的api_key)
llm = ChatOpenAI(
model_name="qwen-plus",
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
api_key="你的api_key", # 工藤提示:别硬编码,放环境变量里更安全
temperature=0.7 # 摘要不用太死板,0.7刚好
)
# 初始化摘要记忆(核心组件)
memory = ConversationSummaryMemory(llm=llm)
# 模拟我和用户的对话(工藤项目里的真实对话片段)
memory.save_context(
{"input": "工藤,AI大模型怎么入门?"},
{"output": "先学基础概念,再调用API,然后学LangChain、RAG,最后实战做项目"}
)
memory.save_context(
{"input": "有没有适合零基础的课程?"},
{"output": "可以看我的零基础学AI大模型系列,从API调用讲到Agent实战"}
)
# 取摘要——看看效果
summary = memory.load_memory_variables({})
print("工藤项目实战:对话摘要")
print(summary["history"]) # 输出摘要,只存关键信息
# 工藤运行结果:
# 用户询问AI大模型零基础入门方法,助手建议先学基础概念、调用API、学LangChain和RAG,再实战;用户又问适合零基础的课程,助手推荐自己的零基础学AI大模型系列。
实战2:进阶版——带摘要存储的对话链
这是我现在项目里用的核心代码,用LCEL链式结构,支持多轮对话,自动更摘要,特别稳定:
from langchain.memory import ConversationSummaryMemory
from langchain_openai import ChatOpenAI
from langchain_core.runnables import RunnablePassthrough
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
# 1. 初始化大模型(和我之前的Agent项目用的一样)
llm = ChatOpenAI(
model_name="qwen-plus",
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
api_key="你的api_key",
temperature=0.7
)
# 2. 初始化摘要记忆(memory_key要和prompt里的变量名一致!)
memory = ConversationSummaryMemory(
llm=llm,
memory_key="chat_history", # 工藤踩坑:这里和下面prompt的{chat_history}要同名
return_messages=True # 返回消息对象,更灵活
)
# 3. 定义prompt——必须包含摘要变量(chat_history)
prompt = ChatPromptTemplate.from_messages([
("system", "你是工藤学编程的AI助手,基于对话摘要回答问题,语气亲切像聊天"),
("human", "对话摘要:{chat_history}\\n用户现在问:{input}")
])
# 4. 构建LCEL链(工藤推荐用这个,比LLMChain灵活)
chain = (
# 注入输入和记忆摘要
RunnablePassthrough.assign(
chat_history=lambda _: memory.load_memory_variables({})["chat_history"]
)
| prompt # 格式化prompt
| llm # 调用大模型
| StrOutputParser() # 解析输出
)
# 5. 模拟用户多轮对话(工藤项目里的真实用户提问)
user_inputs = [
"工藤,怎么用LangChain做记忆功能?",
"之前说的ConversationSummaryMemory,能存多少轮对话?",
"它和Milvus结合的话,怎么存摘要?" # 依赖上一轮的记忆
]
# 6. 运行对话(工藤重点注释:LCEL需要手动保存上下文!)
for query in user_inputs:
print(f"\\n用户:{query}")
# 调用链获取回复
response = chain.invoke({"input": query})
print(f"工藤助手:{response}")
# 手动保存上下文到记忆(LLMChain会自动存,LCEL要手动!)
memory.save_context({"input": query}, {"output": response})
# 查看当前摘要(工藤调试时必看,确保摘要正确)
current_summary = memory.load_memory_variables({})["chat_history"]
print(f"当前对话摘要:{current_summary}")
工藤实战输出效果(真实运行结果)
用户:工藤,怎么用LangChain做记忆功能?
工藤助手:可以用LangChain的Memory模块,比如ConversationBufferMemory存完整历史,ConversationSummaryMemory存摘要,适合长对话…
当前对话摘要: 用户询问如何用LangChain做记忆功能,助手建议使用Memory模块,举例ConversationBufferMemory和ConversationSummaryMemory,后者适合长对话。
用户:之前说的ConversationSummaryMemory,能存多少轮对话?
工藤助手:它没有固定轮数限制,因为存的是摘要,不是全量对话,哪怕100轮,摘要也不会超太多Token…
当前对话摘要: 用户先问LangChain记忆功能做法,助手推荐Memory模块及两个子类;接着用户问ConversationSummaryMemory能存多少轮,助手称无固定限制,因存储的是摘要。
用户:它和Milvus结合的话,怎么存摘要?
工藤助手:可以把生成的摘要转成向量,用LangChain的VectorStoreRetrieverMemory,把摘要存在Milvus里,需要时检索相关摘要…
当前对话摘要: 用户问ConversationSummaryMemory与Milvus结合的存摘要方法,助手建议将摘要转向量,用VectorStoreRetrieverMemory存入Milvus,需用时检索。
看!就算聊多轮,模型也不会“失忆”,摘要里全是关键信息,Token消耗特别少~
四、关键知识点:LCEL和LLMChain怎么选?
| 记忆保存 | 需手动调用memory.save_context() | 自动保存,不用手动写 |
| 链式灵活性 | 高,可加路由、日志(我加了错误捕获) | 固定结构,灵活度低 |
| 调试&扩展 | 可插中间件,适合复杂项目(如多工具调用) | 靠verbose=True调试,适合入门 |
| 工藤使用场景 | 智能助手、Agent项目(复杂场景) | 简单对话demo(快速验证想法) |
五、避坑指南
总结
其实解决大量QA、长对话存储问题,核心就是“抓重点”——用ConversationSummaryMemory生成摘要,只存关键信息,再根据项目复杂度选LCEL或LLMChain。
有疑问欢迎在评论区交流,咱们下期再见!👋


评论前必须登录!
注册