 网硕互联帮助中心
网硕互联帮助中心一、CatBoost时间序列预测原理:
特征工程转换
-
将时间序列问题转化为监督学习问题
-
使用滑动窗口创建滞后特征
-
添加统计特征(均值、标准差、最大值、最小值)
处理时序依赖
-
通过滞后特征捕捉时间依赖关系
-
模型能够学习历史模式对未来值的影响
有序提升机制
-
CatBoost使用有序提升(Ordered Boosting)处理时序数据
-
避免目标泄漏,确保时间上的因果关系
类别特征处理
-
内置类别特征处理能力,适合包含分类变量的时序数据
-
使用目标统计和排序提升减少过拟合
梯度提升框架
-
基于决策树的梯度提升算法
-
逐步优化损失函数,减少预测误差
二、与其他算法的优势:
vs 传统统计方法(ARIMA, SARIMA)
-
无需手动识别参数(p,d,q)
-
能自动捕捉非线性关系
-
处理缺失值和异常值更鲁棒
vs LSTM/RNN
-
训练速度更快,计算资源需求更低
-
超参数调整更简单
-
对小数据集表现更好,不易过拟合
vs XGBoost/LightGBM
-
内置类别特征处理,无需独热编码
-
有序提升减少过拟合,提升泛化能力
-
自动处理缺失值,预处理更简单
-
如需要数据及源码,关注微信公众号【爱敲代码的破晓】,后台私信【Catboost0123】
vs Prophet
-
更灵活的特征工程能力
-
能结合外部特征一起建模
-
对突变点(breakpoints)的适应性更强
综合优势
-
训练速度快,支持GPU加速
-
内置正则化,防止过拟合
-
提供特征重要性分析
-
对异常值不敏感,稳定性好
-
如需要数据及源码,关注微信公众号【爱敲代码的破晓】,后台私信【Catboost0123】
三、应用示例
1.数据准备
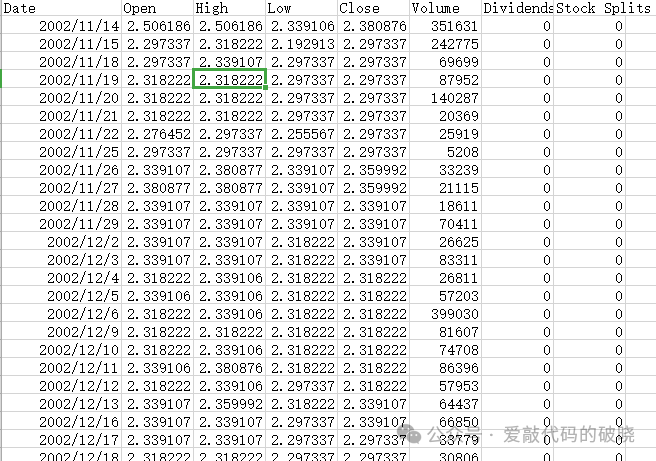
2.导入第三方库
import pandas as pd
import numpy as np
import joblib
import matplotlib.pyplot as plt
from sklearn.metrics import mean_absolute_error, mean_squared_error, r2_score
import warnings
warnings.filterwarnings('ignore')
如需要数据及源码,关注微信公众号【爱敲代码的破晓】,后台私信【Catboost0123】
3.模型配置
# 数据配置
DATA_PATH = 'data.csv'
TARGET_COLUMN = 'Open'
TEST_SIZE = 0.2
RANDOM_STATE = 42
# 特征工程配置
LOOKBACK_WINDOW = 30 # 使用过去30天的数据预测下一天
FORECAST_HORIZON = 1 # 预测未来1天
# CatBoost模型配置
CATBOOST_PARAMS = {
'iterations': 1000,
'learning_rate': 0.03,
'depth': 6,
'loss_function': 'RMSE',
'verbose': 100,
'random_seed': RANDOM_STATE,
'task_type': 'CPU', # 可改为'GPU'如果有GPU
'early_stopping_rounds': 50
}
# 绘图配置
PLOT_CONFIG = {
'figsize': (12, 8),
'train_color': 'blue',
'test_color': 'red',
'pred_color': 'green',
'dpi': 100
}
4.加载数据
def load_and_prepare_data():
"""加载并准备数据"""
print("加载数据…")
df = pd.read_csv(DATA_PATH, parse_dates=['Date'])
df = df.sort_values('Date')
df.set_index('Date', inplace=True)
# 确保没有缺失值
df = df.fillna(method='ffill')
5.特征工程
def create_features(data, target_col, window_size):
"""创建时间序列特征"""
features = []
targets = []
for i in range(window_size, len(data)):
# 使用过去window_size天的数据
feature_window = data[target_col].iloc[i-window_size:i].values
# 添加统计特征
feature_mean = np.mean(feature_window)
feature_std = np.std(feature_window)
feature_max = np.max(feature_window)
feature_min = np.min(feature_window)
# 添加滞后特征
lag_features = list(feature_window)
# 组合所有特征
all_features = lag_features + [feature_mean, feature_std, feature_max, feature_min]
features.append(all_features)
targets.append(data[target_col].iloc[i])
return np.array(features), np.array(targets)
如需要数据及源码,关注微信公众号【爱敲代码的破晓】,后台私信【Catboost0123】
6.训练模型
def train_model():
"""训练模型"""
print("开始训练CatBoost模型…")
# 加载数据
df = load_and_prepare_data()
# 创建特征
X, y = create_features(df, TARGET_COLUMN, LOOKBACK_WINDOW)
# 划分训练集和测试集
train_size = int(len(X) * (1 – TEST_SIZE))
X_train, X_test = X[:train_size], X[train_size:]
y_train, y_test = y[:train_size], y[train_size:]
print(f"训练集大小: {X_train.shape[0]}")
print(f"测试集大小: {X_test.shape[0]}")
# 创建并训练模型
model = CatBoostRegressor(**CATBOOST_PARAMS)
model.fit(
X_train, y_train,
eval_set=(X_test, y_test),
use_best_model=True,
plot=False
)
# 保存模型
joblib.dump(model, 'catboost_timeseries_model.pkl')
print("模型已保存为 'catboost_timeseries_model.pkl'")
# 预测
y_pred_train = model.predict(X_train)
y_pred_test = model.predict(X_test)
return {
'model': model,
'X_train': X_train,
'X_test': X_test,
'y_train': y_train,
'y_test': y_test,
'y_pred_train': y_pred_train,
'y_pred_test': y_pred_test,
'dates': df.index[LOOKBACK_WINDOW:]
}
7.模型预测
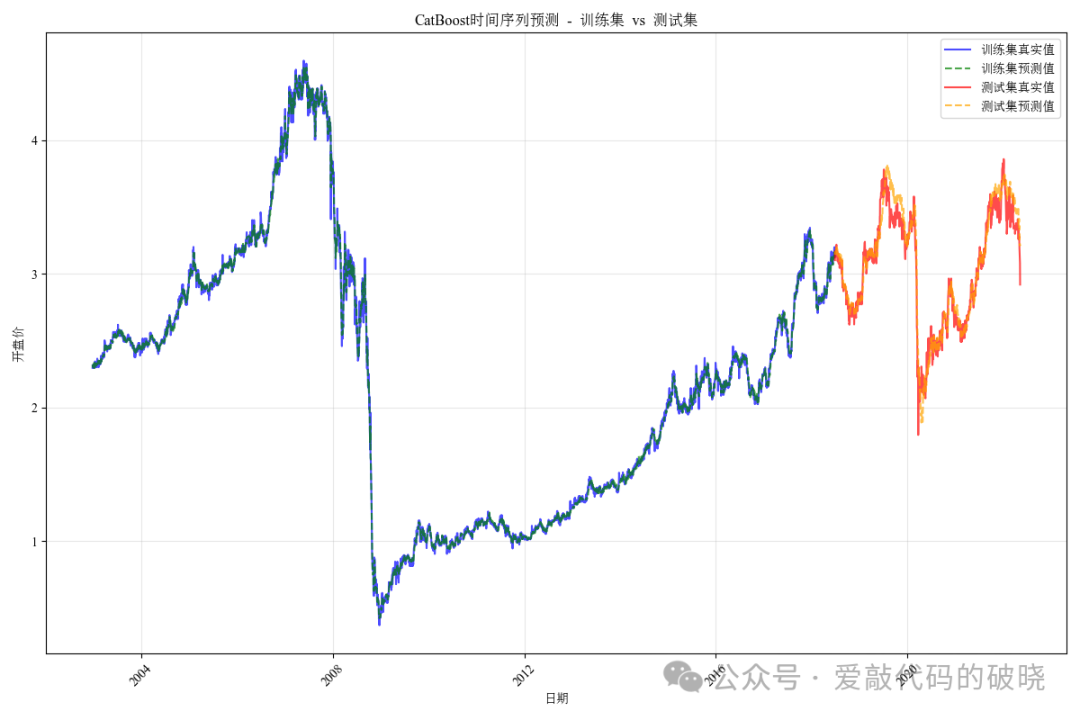
def plot_predictions(results):
"""绘制预测曲线"""
dates = results['dates']
train_size = len(results['y_train'])
plt.figure(figsize=PLOT_CONFIG['figsize'])
# 训练集部分
train_dates = dates[:train_size]
plt.plot(train_dates, results['y_train'],
label='训练集真实值', color=PLOT_CONFIG['train_color'], alpha=0.7)
plt.plot(train_dates, results['y_pred_train'],
label='训练集预测值', color=PLOT_CONFIG['pred_color'], alpha=0.7, linestyle='–')
# 测试集部分
test_dates = dates[train_size:]
plt.plot(test_dates, results['y_test'],
label='测试集真实值', color=PLOT_CONFIG['test_color'], alpha=0.7)
plt.plot(test_dates, results['y_pred_test'],
label='测试集预测值', color='orange', alpha=0.7, linestyle='–')
plt.title('CatBoost时间序列预测 – 训练集 vs 测试集')
plt.xlabel('日期')
plt.ylabel('开盘价')
plt.legend()
plt.grid(True, alpha=0.3)
plt.xticks(rotation=45)
plt.tight_layout()
plt.savefig('prediction_plot.png', dpi=PLOT_CONFIG['dpi'])
plt.show()
8.模型评价并绘图
def evaluate_predictions(y_true, y_pred, set_name="数据集"):
"""评估预测结果"""
mae = mean_absolute_error(y_true, y_pred)
mse = mean_squared_error(y_true, y_pred)
rmse = np.sqrt(mse)
r2 = r2_score(y_true, y_pred)
# 计算MAPE(避免除零)
mape = np.mean(np.abs((y_true – y_pred) / np.maximum(np.abs(y_true), 1e-10))) * 100
print(f"\\n{set_name}评估结果:")
print(f"MAE: {mae:.4f}")
print(f"MSE: {mse:.4f}")
print(f"RMSE: {rmse:.4f}")
print(f"R²: {r2:.4f}")
print(f"MAPE: {mape:.2f}%")
return {
'MAE': mae,
'MSE': mse,
'RMSE': rmse,
'R2': r2,
'MAPE': mape
}
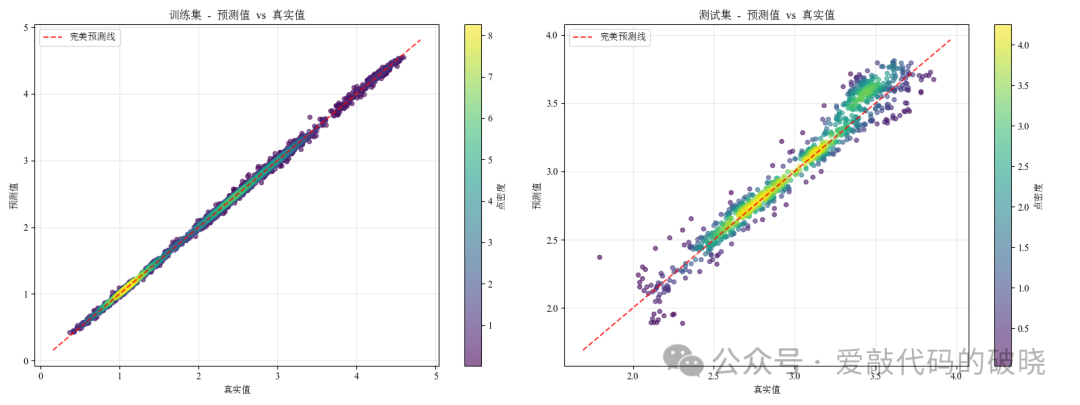
def plot_density_scatter(ax, y_true, y_pred, title):
"""绘制渐变密度散点图"""
from scipy.stats import gaussian_kde
# 计算点密度
xy = np.vstack([y_true, y_pred])
z = gaussian_kde(xy)(xy)
# 按密度排序,使得密度高的点显示在上层
idx = z.argsort()
x, y, z = y_true[idx], y_pred[idx], z[idx]
scatter = ax.scatter(x, y, c=z, s=20, alpha=0.6, cmap='viridis')
plt.colorbar(scatter, ax = ax, label = "点密度")
# 添加对角线(完美预测线)
lims = [np.min([ax.get_xlim(), ax.get_ylim()]),
np.max([ax.get_xlim(), ax.get_ylim()])]
ax.plot(lims, lims, 'r–', alpha=0.8, label='完美预测线')
ax.set_xlabel('真实值')
ax.set_ylabel('预测值')
ax.set_title(title)
ax.legend()
ax.grid(True, alpha=0.3)
return scatter
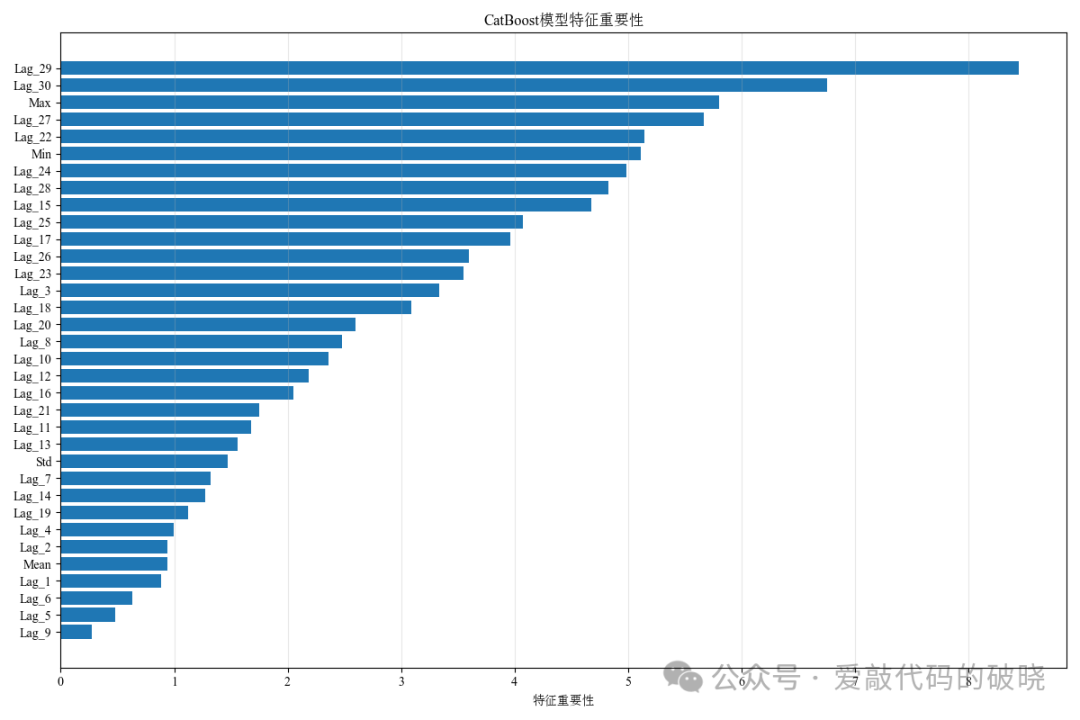
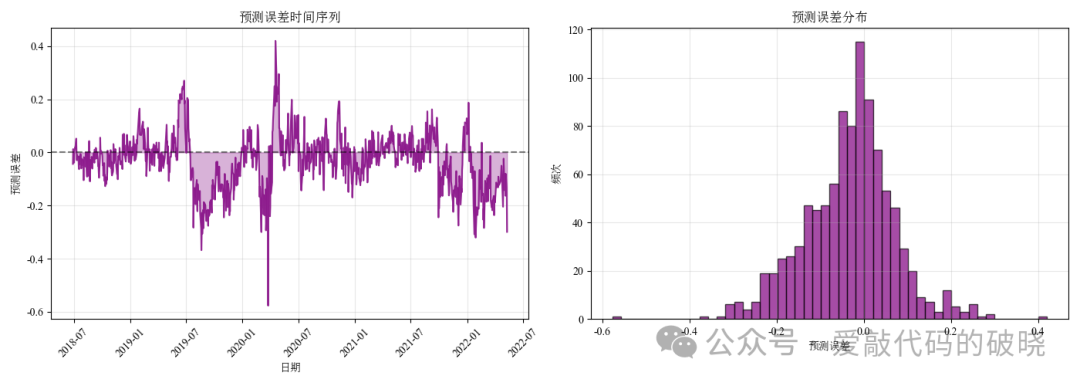
以下是输出的图件:









评论前必须登录!
注册