 网硕互联帮助中心
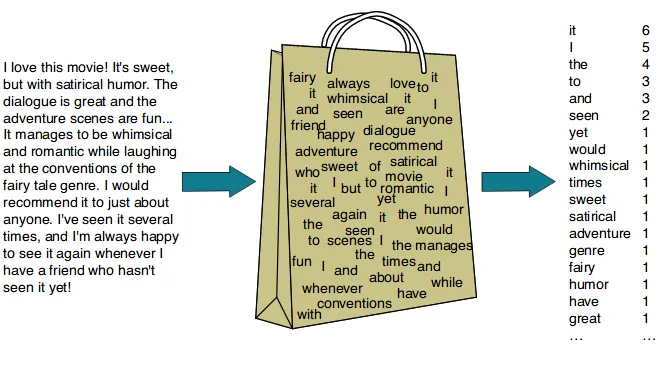
网硕互联帮助中心 语言人工智能历史始于一种名为词袋(bag-of-words)的技术,这是一种表示非结构化文本的方法 。它早在20世纪50年代就被提出,但直到2000年前后才开始流行。
-
核心思想:将文本看作一个“词的集合”,忽略词序,只统计每个词出现的次数。
换言之,在 BoW 模型中,句子或文档被表示为一个固定长度的向量,向量的每个维度对应词汇表(vocabulary)中的一个词,值表示该词在文本中出现的频率或次数。
一、介绍
词袋模型是一种文本表示,用于描述文档中单词的出现情况。我们只跟踪单词数量,忽略语法细节和词序。之所以称之为“词袋”,是因为任何关于文档中单词顺序或结构的信息都会被丢弃。该模型只关注已知单词是否出现在文档中,而不是出现在文档的哪个位置。
1.1 结构化处理文本
文本的最大问题之一是它混乱且非结构化,而机器学习算法更喜欢结构化、定义明确的固定长度输入,通过使用词袋技术,我们可以将可变长度的文本转换为固定长度的向量**。**
此外,在更精细的层面上,机器学习模型处理的是数值数据,而不是文本数据。更具体地说,通过使用词袋(BoW)技术,我们将文本转换为其等效的数字向量。
1.2 模型特点
| 简单易实现,计算高效 | 完全丢失词序与上下文信息 |
| 可作为许多模型(如朴素贝叶斯、SVM)的输入特征 | 词汇表维度高,稀疏性强 |
| 适用于小规模文本分析、特征工程初期 | 无法处理同义词、多义词问题 |
总的来说,词袋模型为文本向量化提供了最基础的形式化框架。但由于它仅仅将语言视为一个几乎字面意义上的“词袋”,而忽略了文本的语义特性和上下文含义,因此难以有效表达词与词之间的语义联系。这也成为后续 Word2Vec、Transformer 等模型提出的直接动因。
二、构建步骤
词袋模型的工作原理如下:
2.1 文本表示的起点:分词(Tokenization)
分词是构建词袋模型的第一步,也是影响模型性能的重要因素。
在自然语言处理中,计算机无法直接理解原始文本。分词(Tokenization) 是将文本切分成最小可处理单元(词或子词,token)的过程,是所有文本表示方法的基础步骤。
- 举例:
假设我们有两个句子需要创建数值表示。词袋模型的第一步是分词(tokenization),即将句子拆分成单个词或子词(词元,token)。最常见的分词方法是通过空格分割来把句子分割成词。然而,这种方法也有其缺点,因为某些语言(如汉语)的词之间没有空格。
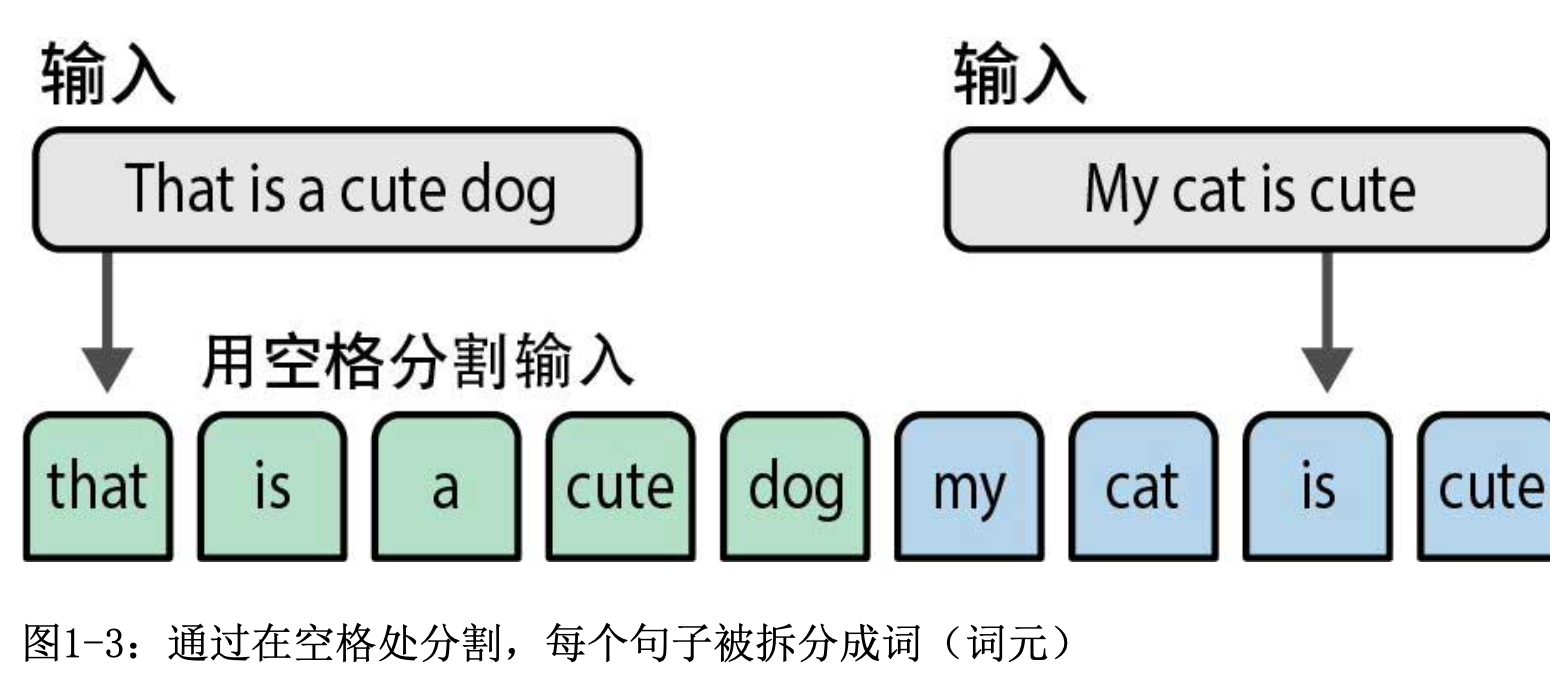
(1) 为什么需要分词?
- 模型的输入必须是离散的 token 序列,不能直接处理字符串。
- 对于英语等以空格分词的语言,可直接按空格或标点切分;
- 对于中文、日语等无显式词界的语言,需要使用分词算法(如结巴分词、BERT WordPiece、SentencePiece 等)。
(2) 常见分词方式
| Word-level Tokenization | 按词切分,例如“我 喜欢 NLP” → [“我”, “喜欢”, “NLP”] | 英语、经过分词的中文文本 |
| Character-level Tokenization | 按字切分,例如“我喜欢NLP” → [“我”, “喜”, “欢”, “N”, “L”, “P”] | 低资源语言、字符模型 |
| Subword Tokenization(BPE/WordPiece) | 将词拆成更小的单元(如“unhappiness” → [“un”, “happy”, “ness”]) | 现代大模型(如 BERT、LLaMA)常用 |
- 在 BoW 模型中,分词结果决定了词汇表的构成。 不同的分词策略,会显著影响 BoW 特征空间的维度与稀疏性:
- 分得太细 → 词汇表过大,稀疏性高;
- 分得太粗 → 无法捕捉词义变化。
2.1 建立词汇表(Vocabulary)
在分词之后,我们将每个句子中所有不同的词组合起来,创建一个可用于表示句子的词表(vocabulary)。即从语料库中提取所有不同的词,形成一个固定的词汇集合。
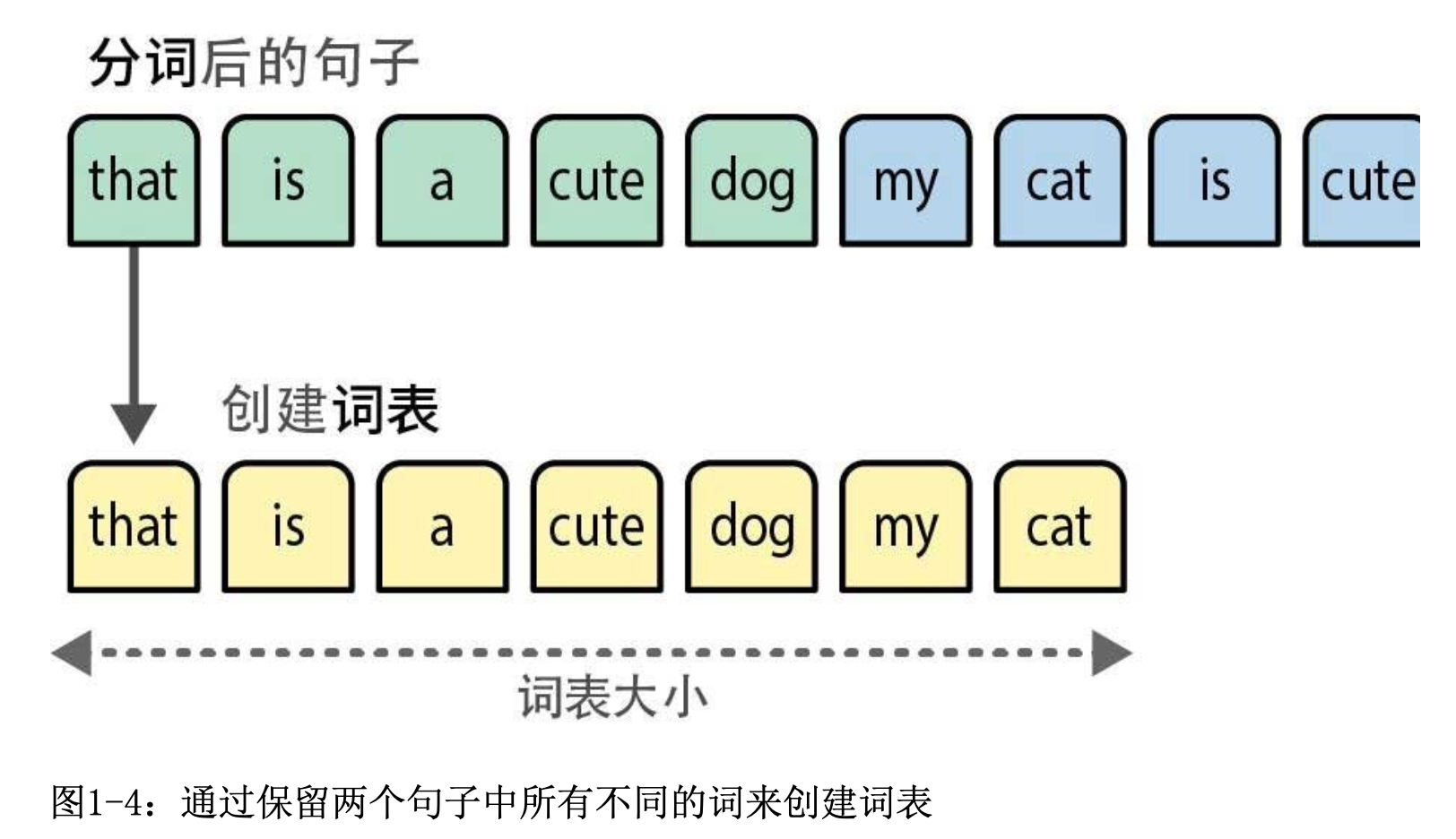
使用词表,我们只需计算每个句子中词出现的次数,就创建了一个词袋。
2.2 向量化表示(Vectorization)
词袋模型旨在以数字形式创建文本的表示(representation),也称为向量或向量表示。通过过计算单个词出现的次数创建词袋,这些值被称为向量表示。 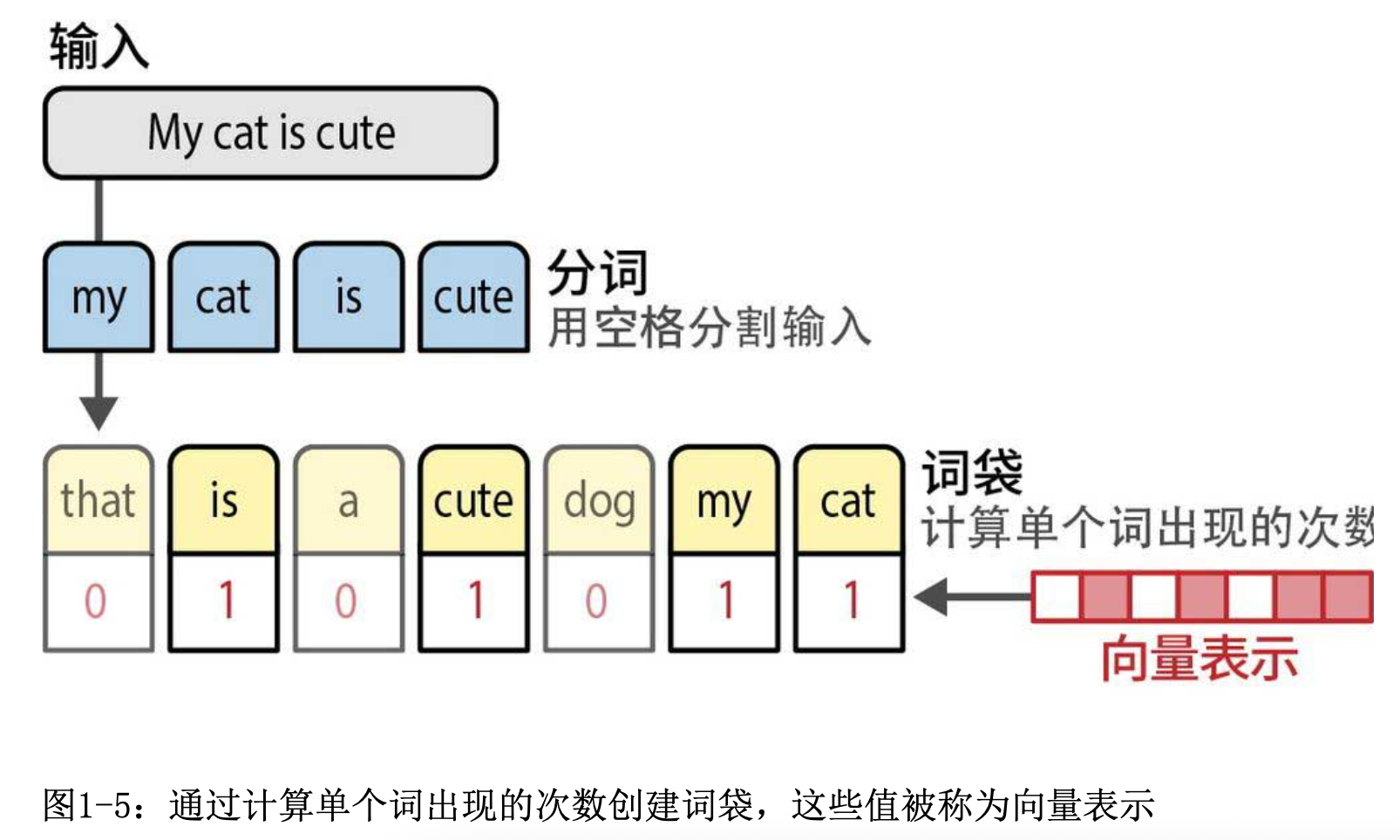
2.3 语料库和词表
| corpus | 原始语料库(原始文本集合) | [“this is a book”, “that is a pen”] |
| feature_names | 特征词汇表(经过分词、清洗后) | [‘book’, ‘pen’, ‘this’, ‘that’] |
三、BoW构建
下面通过一个简单示例来说明 词袋模型(Bag of Words) 的构建过程。
-
Sentence 1: ”Welcome to Great Learning, Now start learning”
-
Sentence 2: “Learning is a good practice”
3.1 分词
Tokenization
将每个句子拆分为单词:
- Sentence 1 → [Welcome, To, Great, Learning, Now, start, learning]
- Sentence 2 → [learning, is, a, good, practice]
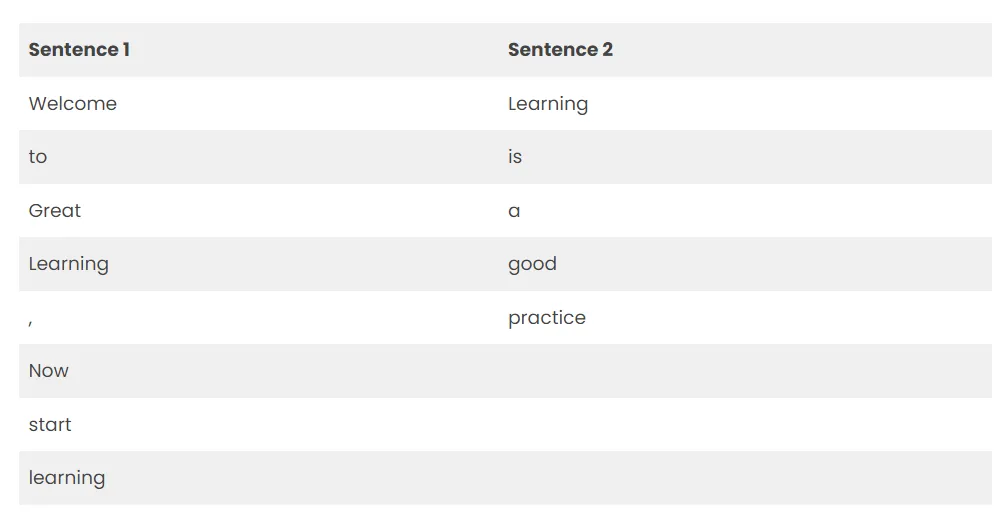
3.2 构建词表
Vocabulary
浏览上述文本中的所有单词,并列出模型词汇表中的所有单词。
Welcome
To
Great
Learning
,
Now
start
learning
is
a
good
practice
这里需要注意,“Learning” 和 “learning” 因大小写不同被视为两个不同的词,因此在词汇表中会重复出现。同时,标点符号(如逗号 “,”) 也被分词器识别为独立的 token,并被计入词袋中。
因为我们知道词汇表有 12 个单词,所以我们可以使用固定长度为 12 的文档表示,并在向量中的一个位置对每个单词进行评分。
3.3 计算词频并用向量表示
我们这里采用的评分方法是统计每个单词的出现次数,不存在则记为0。这种评分方法比较常用。
-
Sentence1
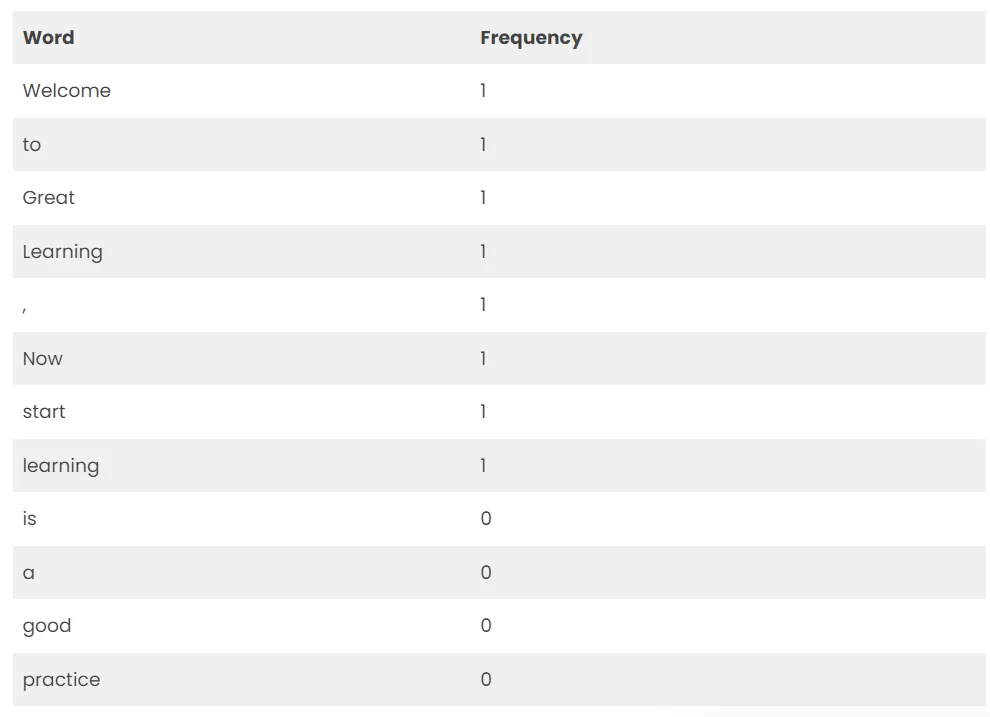
将上述频率写入向量中:
[1,1,1,1,1,1,1,1,0,0,0]
-
Sentence2
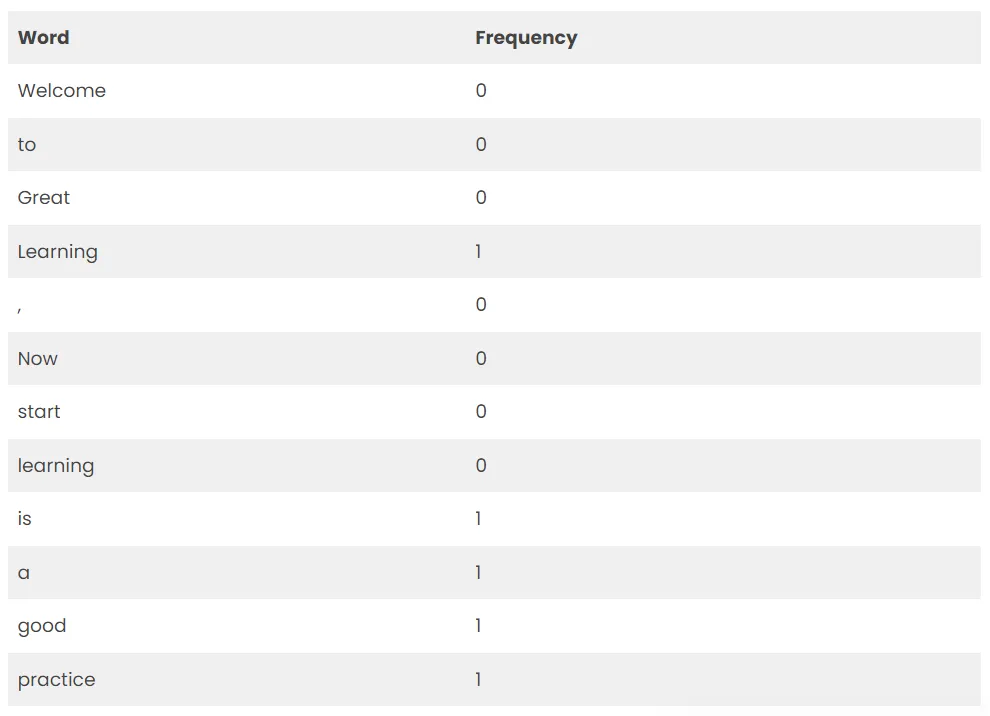
将上述频率写入向量中:
[0,0,0,0,0,0,0,1,1,1,1,1]
-
综上所述:

3.4 局限性
词袋模型仅能反映文本中词出现的频率,而忽略了语言的结构与语义信息,主要局限如下:
- 忽略词序:例如,“Learning start now” 与 “Now start learning” 在 BoW 表示中完全相同,无法体现语序差异。
- 忽略语义差异:例如,“good practice” 与 “bad practice” 的结构一致,但语义相反。
- 大小写敏感:如 “Learning” 与 “learning” 含义相同,却被视为两个不同的词。
- 包含无意义符号:标点符号(如逗号 “,”)会被当作独立 token 加入词汇表,增加噪声却无实际信息。
因此,词袋模型仅将语言视为一个几乎字面意义上的“词袋”,无法捕捉上下文与语义关系。 这一局限正是 TF-IDF 与后续词向量模型(如 Word2Vec、GloVe)出现的动机。
四、BoWs实现
sklearn的CountVectorizer类可以实现Bag Of Words的功能。
from sklearn.feature_extraction.text import CountVectorizer
vectorizer = CountVectorizer(max_features=max_features, stop_words=stop_words)
X_train = vectorizer.fit_transform(train_texts)
X_test = vectorizer.transform(test_texts)
1. 参数说明
| max_features | int 或 None | None | 限制词表大小。对所有词的 词频(term frequency) 排序,取前 max_features 个作为关键词集合。例如 max_features=10000 表示只保留前 10,000 个高频词。 |
| stop_words | string/list/None | None | 去除停用词。例如 stop_words='english' 自动去掉英文常用停用词。 |
| ngram_range | tuple (min_n, max_n) | (1, 1) | 控制 n-gram 范围。默认 (1,1) 只保留 unigram(单词), (1,2) 表示保留 unigram + bigram(两词组合)。 |
| lowercase | bool | True | 是否将文本转换为小写。通常保持 True 以减少词表冗余。 |
| min_df | int / float | 1 | 最小文档频率。词语至少出现在 min_df 个文档中才会被保留。 |
| max_df | int / float | 1.0 | 最大文档频率。词语若出现在超过 max_df 个文档中(或比例),则被忽略。常用来去掉高频词。 |
| token_pattern | string | r"(?u)\\b\\w\\w+\\b" | 正则表达式,用于识别词语边界。默认匹配至少两个字符的单词。 |
| analyzer | string/callable | ‘word’ | 指定分析对象:'word' 按单词分词,'char' 按字符,'char_wb' 按字符且只考虑单词边界。 |
2. fit:统计训练文本中所有词出现的频率
根据 max_features 和 stop_words 生成一个 词汇表(vocabulary)。词汇表里每个词对应一个索引,比如:
{'apple': 0, 'banana': 1, 'orange': 2}
3. transform:把测试文本也转换成同样维度的词频向量
- 使用已有词汇表,把新文本映射成向量
- 例如:
test_texts = ["apple orange"]
X_test =
[[1 0 1]]
注意,如果测试文本里有训练集中没有出现的词,它们会被 忽略(不会增加新维度)。
五、BoW 与现代 LLM 的关系
BoW其实是语言表示演进的第一步
5.1 从 BoW 到 LLM:语言表示的技术演化路径
从历史视角看,BoW 并不是“被淘汰的旧技术”,而是现代大模型语言表示体系的起点。
- 语言表示方法大致经历了以下阶段:
| BoW / TF-IDF | 稀疏词频向量 | 统计词出现 |
| Word2Vec / GloVe | 稠密词向量 | 学习词语语义空间 |
| RNN / LSTM | 序列模型 | 建模词序 |
| Transformer | 注意力机制 | 建模长距离依赖 |
| LLM | 大规模预训练 | 学习语言的隐式概率结构 |
可以看到,BoW 是第一个将“文本 → 数值向量”的工程可行方案,没有它,就没有后续的词向量和 Transformer 输入形式。
5.2 为什么说 BoW 不是“差模型”,而是“时代最优解”
很多现代 NLP 教程会把 BoW 描述为“原始、简单、效果差”,这种说法在工程史上是不准确的。
(1) 计算资源限制决定了模型形式
-
在 BoW 流行的年代(1990–2010),那时:
- GPU 尚未普及
- 深度神经网络训练成本极高
- 大规模语料不可获得
- 分布式训练基础设施不存在
-
在这种环境下:
- 稠密向量训练几乎不可行
- Transformer 完全无法训练
- BoW 是唯一可工业化落地的文本表示方式
(2) 在很多任务上,BoW 至今仍然是强基线
-
即使在今天,文本分类、信息检索、搜索排序、推荐系统特征工程,BoW / TF-IDF + 线性模型仍然是强基线,且成本极低。
-
在工业界常见经验是:一个调优良好的 TF-IDF + Logistic Regression,往往能击败一个没有调参的小型神经网络模型。
5.3 BoW 与现代 LLM 的本质差异
从数学本质上看,BoW 和 LLM 的区别是统计阶数与结构建模能力:
| BoW | 一阶统计(词频) | 稀疏向量 |
| Word2Vec | 二阶共现统计 | 稠密嵌入 |
| Transformer | 高阶条件概率 | 序列隐空间 |
| LLM | 全局语言分布 | 隐式世界模型 |
-
BoW 是
P
(
w
)
P(w)
P(w)
-
LLM 是:
P
(
w
t
∣
w
<
t
,
context
)
P(w_t|w_{<t}, \\text{context})
P(wt∣w<t,context) 本质上,LLM 是 BoW 的高阶条件概率扩展。
5.4 从工程角度看:LLM 仍然继承了 BoW 的思想
尽管 Transformer 表面上非常复杂,但在底层LLM 仍然需要:
-
Tokenization(分词)
-
Vocabulary(词表)
-
Token ID 向量化
-
稀疏→稠密嵌入映射
这样看来,BoW 的思想仍然存在于 embedding lookup 表中,只是被神经网络“软化”了。
5.5 为什么说 BoW 是 NLP 的“牛顿力学”
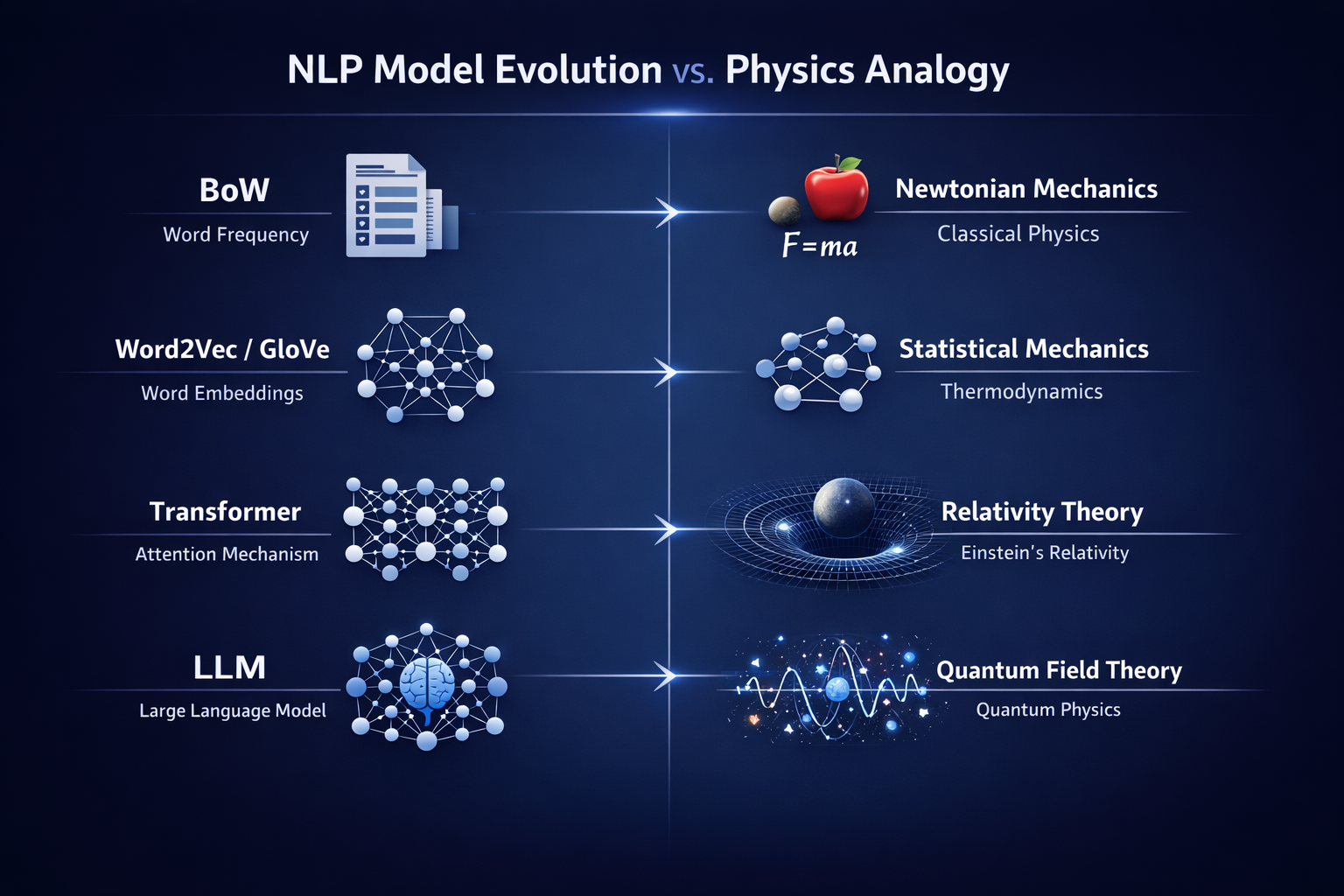
可以用一个物理学类比:
| BoW | 牛顿力学 |
| Word2Vec | 经典统计物理 |
| Transformer | 相对论 |
| LLM | 量子场论级复杂系统 |
牛顿力学并没有“过时”,只是适用范围有限。同理,BoW 不是错误模型,而是在低复杂度语言建模中的最优工程选择。
5.6 BoW 的思想在现代系统中的隐秘复活
有趣的是,很多现代 LLM 系统又回归了“词频思想”:
-
BM25 仍然是搜索引擎核心
-
Hybrid Search = BM25 + Embedding
-
RAG 系统中仍使用 TF-IDF / BM25 召回
-
Prompt caching / prefix caching 本质是统计语言片段复用
深度模型并没有取代统计模型,而是与之叠加。
六、总结
词袋模型并不是一个“落后的技术”,它是现代语言模型体系的工程原点:
- 第一次实现文本 → 数值空间映射
- 建立了词表、分词、向量化的统一范式
- 为 Word2Vec、Transformer、LLM 提供了概念与工程基础
没有 BoW,就没有今天的大模型语言智能。它不是被淘汰的旧模型,而是语言智能工程史上的第一块基石。它的局限来自时代,而它的思想仍活在每一个 LLM 的 embedding 层中。


评论前必须登录!
注册