 网硕互联帮助中心
网硕互联帮助中心缓存穿透 缓存雪崩 缓存击穿这三者是缓存架构中最常见的三类故障场景,核心差异在于触发原因、影响范围和应对策略,从底层原理到解决方案可以这样拆解:
一、 缓存穿透
1. 定义
指请求的数据在缓存和数据库中都不存在,每次请求都会穿透缓存直接打到数据库,导致数据库压力骤增,甚至被打垮。
- 典型场景:恶意攻击(如构造大量不存在的 key 发起请求)、业务逻辑疏漏(如查询参数错误)。
- 底层影响:缓存命中率极低,数据库频繁执行无意义的查询,连接池被占满,正常请求无法响应。
2. 核心应对策略
策略原理优缺点 空值缓存 数据库查询为空时,将 key 对应的空值(如 null)写入缓存,并设置短过期时间(如 5 分钟) 优点:实现简单;缺点:会占用少量缓存空间,可能被恶意 key 撑爆 布隆过滤器 启动时将数据库中所有有效 key 预加载到布隆过滤器中,请求先经过过滤器校验,不存在的 key 直接拦截 优点:空间效率极高,拦截效率接近 100%;缺点:存在误判率(无法区分 “一定不存在” 和 “可能存在”),不支持删除操作 请求限流 / 校验 对接口做参数合法性校验,对异常请求频率的 IP 进行限流 优点:从源头拦截恶意请求;缺点:无法应对正常业务的无效查询
3. 代码示例(空值缓存)
public Object getValue(String key) {
// 1. 先查缓存
Object cacheValue = redisTemplate.opsForValue().get(key);
if (cacheValue != null) {
return cacheValue;
}
// 2. 缓存未命中,查数据库
Object dbValue = dbMapper.selectByKey(key);
if (dbValue == null) {
// 3. 数据库无数据,缓存空值并设置短过期时间
redisTemplate.opsForValue().set(key, null, 5, TimeUnit.MINUTES);
return null;
}
// 4. 数据库有数据,缓存并返回
redisTemplate.opsForValue().set(key, dbValue, 30, TimeUnit.MINUTES);
return dbValue;
}
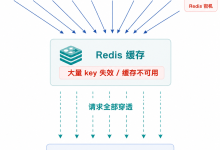
二、 缓存雪崩
1. 定义
指大量缓存数据在同一时间点过期,导致所有请求瞬间穿透到数据库,数据库因压力过载而宕机,进而引发整个系统雪崩。
- 典型场景:缓存集群重启、批量设置相同的过期时间(如促销活动结束时间统一)。
- 底层影响:短时间内数据库请求量飙升,CPU/IO 打满,服务雪崩效应(一层故障蔓延到多层)。
2. 核心应对策略
| 过期时间随机化 | 给每个 key 的过期时间增加随机偏移量(如基础过期时间 30 分钟 ± 5 分钟),避免集中过期 | 优点:实现简单,无额外成本;缺点:无法解决缓存集群宕机的场景 |
| 多级缓存架构 | 引入本地缓存(如 Caffeine) + 分布式缓存(如 Redis),分布式缓存失效时,本地缓存可兜底 | 优点:降低分布式缓存依赖;缺点:本地缓存存在一致性问题,占用 JVM 堆内存 |
| 缓存预热 + 降级限流 | 系统启动前提前加载热点数据到缓存;缓存失效时,对数据库请求进行限流降级,返回兜底数据 | 优点:应对突发流量;缺点:实现复杂,需要配套监控和熔断机制 |
| 集群高可用 | 使用 Redis 哨兵 / 集群模式,避免单节点宕机导致的缓存全量失效 | 优点:解决硬件故障;缺点:无法解决业务层的集中过期问题 |
3. 代码示例(过期时间随机化)
public void setValue(String key, Object value) {
// 基础过期时间 30 分钟,随机偏移 0-5 分钟
int baseExpire = 30 * 60;
int randomExpire = new Random().nextInt(5 * 60);
int totalExpire = baseExpire + randomExpire;
redisTemplate.opsForValue().set(key, value, totalExpire, TimeUnit.SECONDS);
}
三、 缓存击穿
1. 定义
指某个热点 key 突然过期,此时恰好有大量并发请求访问该 key,所有请求都会穿透到数据库,导致数据库瞬间压力暴增。
- 核心区别于雪崩:击穿是单个热点 key 的问题,雪崩是大量 key 的问题。
- 典型场景:秒杀商品的缓存过期、热门资讯的缓存失效。
2. 核心应对策略
| 互斥锁 | 缓存未命中时,通过分布式锁(如 Redis Redlock)保证只有一个请求去数据库查询并更新缓存,其他请求等待 | 优点:逻辑严谨,一致性强;缺点:存在锁竞争,高并发下有性能损耗 |
| 热点数据永不过期 | 对热点 key 不设置过期时间,由后台异步任务定期更新缓存 | 优点:无过期穿透风险;缺点:需要维护热点 key 列表,缓存空间占用较高 |
| 缓存预热 + 延长过期时间 | 提前将热点数据加载到缓存,并设置较长的过期时间,结合监控实时刷新 | 优点:简单高效;缺点:依赖热点数据的预判能力 |
3. 代码示例(互斥锁方案)
public Object getHotValue(String key) {
// 1. 查缓存
Object cacheValue = redisTemplate.opsForValue().get(key);
if (cacheValue != null) {
return cacheValue;
}
// 2. 缓存未命中,加分布式锁
String lockKey = "lock:" + key;
Boolean lock = redisTemplate.opsForValue().setIfAbsent(lockKey, "1", 3, TimeUnit.SECONDS);
if (lock != null && lock) {
try {
// 3. 拿到锁,查数据库并更新缓存
Object dbValue = dbMapper.selectByKey(key);
redisTemplate.opsForValue().set(key, dbValue, 30, TimeUnit.MINUTES);
return dbValue;
} finally {
// 4. 释放锁
redisTemplate.delete(lockKey);
}
} else {
// 5. 未拿到锁,自旋等待(或返回兜底数据)
Thread.sleep(50);
return getHotValue(key);
}
}
四、 三者核心区别总结
| 数据存在性 | 缓存 + 数据库都不存在 | 缓存存在,批量过期 | 缓存过期,数据库存在 |
| 影响范围 | 所有无效 key 的请求 | 所有请求 | 单个热点 key 的请求 |
| 触发原因 | 恶意攻击 / 业务疏漏 | 集中过期 / 集群宕机 | 热点 key 过期 + 高并发 |
| 核心关键词 | 空值、布隆过滤器 | 随机过期、多级缓存 | 分布式锁、热点永不过期 |




评论前必须登录!
注册