 网硕互联帮助中心
网硕互联帮助中心一、大模型蒸馏是什么?
简单来说,大模型蒸馏就是“让小模型学习大模型的能力”的过程。我们可以把这个过程类比成“老师教学生”:这里的“老师”是性能优异但体量庞大的大模型(也叫教师模型),“学生”是参数少、体积小、效率高的小模型(也叫学生模型)。蒸馏的核心目标,不是让学生模型简单模仿老师的最终输出,而是让学生学习老师在决策过程中蕴含的“隐性知识”,最终实现“小模型达到近似大模型的性能,同时效率大幅提升”。
从技术定义来看,大模型蒸馏是一种模型压缩与知识迁移技术,通过设计特定的学习目标和训练策略,将教师模型的知识(包括最终的预测分布、中间层的特征表示、注意力分布等)迁移到学生模型中,从而优化学生模型的泛化能力和性能。
二、为什么需要大模型蒸馏?——核心应用价值
搞懂了“是什么”,接下来要明确“为什么需要”。大模型蒸馏的价值,本质上是为了平衡“模型性能”和“部署成本”,具体体现在三个核心场景:
资源受限场景的适配
手机、智能手表、边缘计算设备(如工业传感器、智能摄像头)的内存、算力和功耗都有限制,无法直接运行几十亿、上百亿参数的大模型。通过蒸馏得到的小模型,参数规模可压缩至原来的1/10甚至1/100,推理速度提升数倍,能完美适配这些场景。比如手机端的语音识别、实时翻译,边缘设备的图像检测等,背后都可能用到蒸馏技术。
降低部署与运维成本
大模型的部署需要高性能的GPU集群,运维过程中产生的算力消耗、电力成本都非常高。小模型不仅可以部署在普通硬件上,还能减少存储占用和网络传输开销(比如云端推理时,小模型的响应速度更快,带宽消耗更少),大幅降低企业的部署和运维成本。
提升推理效率
在一些对响应速度要求极高的场景(如自动驾驶的实时决策、金融交易的实时风控、客服机器人的即时回复),大模型的推理延迟可能会导致严重问题。蒸馏后的小模型推理速度更快,能满足低延迟的业务需求,同时保证决策的准确性。
三、大模型蒸馏的核心原理
蒸馏技术的核心逻辑是“知识迁移”,而实现这一逻辑的关键在于两个核心假设和一套损失函数设计:
1. 核心假设
- 假设一:大模型的决策过程中蕴含着超越硬标签的“有效知识”。比如,当识别一张模糊的动物图片时,大模型可能输出“60%是老虎,35%是狮子,5%是其他”的软标签,这个软标签不仅告诉我们“最可能是老虎”,还隐含了“老虎和狮子的特征相似”这一知识,而硬标签“老虎”无法体现这一点。
- 假设二:小模型通过学习这些隐性知识,可以在自身参数规模有限的情况下,逼近大模型的泛化能力。小模型的“学习能力”有限,直接用原始数据训练很难达到好的性能,但以大模型的知识为“指导”,可以少走很多弯路。
2. 损失函数:蒸馏的“指挥棒”
要让学生模型学好教师模型的知识,关键是设计合理的损失函数——告诉学生模型“哪里学得好,哪里学得不好”。蒸馏的损失函数通常是“蒸馏损失”和“原始任务损失”的加权和,即:
总损失 = α×蒸馏损失 + β×原始任务损失
- 蒸馏损失:衡量学生模型和教师模型输出的软标签之间的差距,核心是让学生模仿教师的概率分布。常用的计算方式是KL散度(相对熵),KL散度越小,说明两个概率分布越接近。
- 原始任务损失:衡量学生模型输出与真实硬标签之间的差距(比如交叉熵损失),确保学生模型不会因为过度模仿教师而偏离真实任务目标。
- α和β是权重参数,用于平衡两个损失的重要性,通常需要根据具体任务调优。
这里有一个关键技巧:温度系数(Temperature, T)。在计算软标签时,会将教师模型的logits(未经过softmax的输出)除以温度T,再进行softmax运算。T越大,软标签的概率分布越平滑,蕴含的隐性知识越丰富;T越小,软标签越接近硬标签。通常在蒸馏阶段,T取5~10,在推理阶段,T=1(即输出正常的硬标签)。
四、大模型蒸馏的关键技术方法
根据“迁移的知识类型”和“训练方式”的不同,蒸馏技术可以分为多种类型,接下来我们介绍最常用的4种核心方法,从基础到进阶逐步展开:
1. 响应蒸馏(Response Distillation):最基础的蒸馏方法
响应蒸馏也叫“输出层蒸馏”,是最直观、最基础的蒸馏方式——只让学生模型学习教师模型输出层的软标签。
核心思路:用教师模型对训练数据进行预测,得到带温度系数的软标签;然后让学生模型同时学习这些软标签(蒸馏损失)和真实硬标签(原始任务损失);通过联合优化总损失,让学生模型的输出尽可能接近教师模型。
适用场景:适用于简单任务(如文本分类、图像识别),实现简单、易落地,但缺点是只利用了教师模型最表层的知识,没有用到中间层的有效信息,蒸馏效果有限。
2. 特征蒸馏(Feature Distillation):学习中间层的“特征表示”
特征蒸馏是比响应蒸馏更进阶的方法——它不仅让学生学习教师的输出,还让学生学习教师模型中间层的特征表示。
核心思路:大模型的中间层(比如Transformer的编码器层、CNN的卷积层)会对输入数据进行逐步的特征提取,这些中间特征蕴含着丰富的语义信息(比如文本中的语法结构、图像中的边缘/纹理特征)。通过设计“特征对齐损失”,让学生模型中间层的特征分布尽可能接近教师模型对应的中间层,从而让学生学到更底层、更核心的特征提取能力。
常用方法:
- 直接特征映射:让学生模型的某一层输出与教师模型的某一层输出通过L2损失对齐;
- 注意力对齐:在Transformer模型中,让学生的注意力矩阵与教师的注意力矩阵对齐(比如计算注意力矩阵的KL散度),学习教师模型的“关注重点”;
- 特征蒸馏网络:在学生和教师的中间层之间添加一个小网络(如全连接层),将教师的特征转换为学生可学习的维度,再计算损失。
适用场景:适用于复杂任务(如文本生成、目标检测),蒸馏效果通常比响应蒸馏更好,是目前大模型蒸馏中最常用的方法之一。
3. 自蒸馏(Self-Distillation):自己教自己
自蒸馏是一种特殊的蒸馏方式——不需要单独的教师模型,让模型“自己教自己”。
核心思路:利用模型在训练过程中的“阶段性输出”或“多版本输出”作为“教师信号”。比如:
- 训练过程中,用模型在epoch 10的输出作为软标签,指导epoch 5的模型学习;
- 对于具有多分支结构的模型,用主分支的输出指导分支的学习,再反过来用分支的输出优化主分支;
- 用模型的集成输出(比如多次推理的平均结果)作为软标签,指导单个模型学习。
适用场景:当没有合适的大模型作为教师,或者需要进一步优化现有模型的性能时,自蒸馏是很好的选择。它的优点是不需要额外的教师模型算力,实现灵活。
4. 提示蒸馏(Prompt Distillation):适配大语言模型的专用方法
提示蒸馏是针对大语言模型(LLM)设计的蒸馏方法,核心是解决“大语言模型的能力迁移”问题——LLM的能力往往依赖于提示(Prompt)工程,蒸馏时需要让学生模型学习教师模型在提示引导下的生成行为。
核心思路:
- 首先用大量的提示样本喂给教师LLM,得到高质量的生成结果(作为软标签);
- 然后让学生模型学习“提示→教师生成结果”的映射关系,同时结合原始任务损失优化;
- 进阶方法会加入“提示模板迁移”,让学生模型学习教师模型对不同提示模板的适配能力,提升泛化性。
适用场景:大语言模型的蒸馏(如将GPT-3蒸馏成小体量的对话模型),能让小模型在对话、文本生成、逻辑推理等任务上逼近大模型的表现。
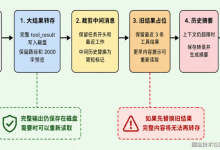
五、大模型蒸馏的实现步骤(循序渐进版)
了解了核心方法,接下来我们梳理蒸馏的完整实现步骤,从准备工作到最终部署,每一步都明确关键要点:
1. 准备阶段:明确目标与数据
- 明确任务与指标:先确定要解决的任务(如分类、生成、检测),以及核心评估指标(如准确率、F1值、BLEU值、推理速度、参数量),避免盲目蒸馏。
- 选择教师与学生模型:
- 教师模型:选择性能优异、在目标任务上表现好的大模型(如BERT-Large、ResNet50、GPT-3);
- 学生模型:根据部署场景选择合适的小模型结构(如BERT-Base、ResNet18、DistilBERT),也可以自定义小模型结构(注意:学生模型的输入/输出维度要与教师模型匹配,或通过适配层调整)。
- 准备数据集:
- 训练集:需要足够大的标注数据,最好包含一定的难例样本(帮助学生模型学习边界知识);
- 验证集:用于调优超参数(如α、β、温度T、学习率);
- 测试集:用于评估蒸馏后模型的最终性能。
2. 教师模型预处理
- 训练/微调教师模型:如果教师模型在目标任务上表现不佳,需要先在目标数据集上微调教师模型,确保其具备足够的“教学能力”;
- 生成软标签:用微调后的教师模型对训练集进行推理,生成带温度系数T的软标签(注意:保存教师模型的logits,后续计算蒸馏损失时直接使用,避免重复推理)。
3. 设计蒸馏策略与损失函数
- 选择蒸馏方法:根据任务复杂度选择合适的蒸馏方法(简单任务用响应蒸馏,复杂任务用特征蒸馏,LLM用提示蒸馏);
- 设计损失函数:
- 确定蒸馏损失和原始任务损失的类型(如KL散度、交叉熵、L2损失);
- 初始化权重α和β(比如先设α=0.7,β=0.3,后续通过验证集调优);
- 如果用特征蒸馏,确定需要对齐的中间层位置(比如Transformer的第3、6、9层)。
4. 训练学生模型
- 初始化学生模型:用随机初始化或预训练的小模型作为初始状态;
- 联合训练:将原始数据、教师模型的软标签同时喂给学生模型,计算总损失,通过反向传播优化学生模型的参数;
- 关键技巧:
- 学习率:学生模型的学习率通常比单独训练时小(避免过度拟合软标签);
- 温度T:根据任务调整,文本类任务T=58,图像类任务T=25;
- 早停策略:用验证集的性能作为早停依据,避免学生模型过拟合。
5. 评估与调优
- 性能评估:在测试集上评估学生模型的核心指标(准确率、推理速度、参数量),与教师模型和单独训练的学生模型对比;
- 超参数调优:如果性能不达标,调整α、β、T、学习率等参数,重新训练;
- 结构优化:如果效率仍不满足需求,可进一步缩小学生模型的参数规模,或采用量化、剪枝等其他压缩技术(与蒸馏结合使用)。
6. 部署
- 将调优后的学生模型导出为部署格式(如ONNX、TensorRT);
- 在目标设备上进行部署测试,验证推理速度、功耗、稳定性是否符合要求。
六、大模型蒸馏的常见挑战与解决方案
在实际应用中,蒸馏过程可能会遇到各种问题,这里总结3个最常见的挑战及对应的解决方案:
1. 挑战一:学生模型与教师模型的“能力差距过大”
如果教师模型是千亿参数的大模型,而学生模型是百万参数的小模型,两者的能力差距过大,学生可能无法学好教师的知识,导致蒸馏效果差。
解决方案:
- 采用“渐进式蒸馏”:先让小模型学习中等规模模型(中间教师)的知识,再让中等规模模型学习大模型的知识,逐步提升;
- 增加蒸馏的“监督信号”:除了软标签和中间特征,还可以加入教师模型的注意力分布、梯度信息等;
- 优化学生模型结构:采用与教师模型同构但简化的结构(如Transformer模型减少层数和注意力头数),提升学生的学习能力。
2. 挑战二:蒸馏效果不稳定,受数据影响大
如果训练数据分布不均、难例样本少,可能导致学生模型只学到教师的“表面知识”,在新数据上的泛化能力差。
解决方案:
- 数据增强:对训练数据进行扩充(如文本的同义词替换、图像的旋转/裁剪),增加数据的多样性;
- 难例挖掘:从训练集中筛选出教师模型预测不准的难例样本,增加其在训练中的权重;
- 正则化:在损失函数中加入L2正则化、dropout等,提升学生模型的泛化能力。
3. 挑战三:复杂任务(如生成任务)的蒸馏效果差
生成任务(如文本生成、图像生成)的输出是序列或像素级的,难以用简单的损失函数衡量学生与教师的差距,蒸馏难度远大于分类任务。
解决方案:
- 采用“逐token蒸馏”:在文本生成任务中,让学生模型逐token模仿教师模型的输出分布(如用交叉熵损失衡量每个位置的token概率差距);
- 引入生成质量评估指标:将BLEU、ROUGE等生成质量指标融入损失函数;
- 用教师模型指导学生的解码过程:在训练时,让教师模型生成中间状态(如编码器的特征),指导学生模型的生成。
七、总结与展望
大模型蒸馏作为一种高效的模型压缩与知识迁移技术,其核心价值在于“平衡性能与效率”,让大模型的强大能力能够下沉到更多资源受限的场景。从基础的响应蒸馏到进阶的特征蒸馏、提示蒸馏,技术的发展始终围绕“更高效地迁移教师知识”这一核心目标。
未来,蒸馏技术的发展方向可能集中在三个方面:
对于技术学习者和实践者来说,掌握蒸馏技术的核心逻辑和实现方法,不仅能帮助我们更好地应用大模型,还能让我们在“模型性能优化”和“部署成本控制”之间找到最佳平衡点。希望通过本文的梳理,大家能彻底搞懂大模型蒸馏,并用它解决实际场景中的问题。



评论前必须登录!
注册