 网硕互联帮助中心
网硕互联帮助中心目录
一、核心思想
二、架构组成
1.基础架构:Transformer编码器
2.输入表示
3.输出表示
三、预训练任务(Pre-Training)
1.掩码语言模型(MLM,Masked Language Model)
2.下一句预测(NSP,Next Sentence Prediction)
3.总结
四、网络细节
1.自注意力机制
2.层归一化与残差连接
3.前馈网络
五、微调(Fine-tuning)
1. 微调的基本思想
2. 常见任务的微调
2.1 句子对分类任务(如MNLI,QQP等)
2.2 单句子分类任务(如SST-2,情感分类)
2.3 问答任务(如SQuAD)
2.4 序列标注任务(如NER)
3. 微调步骤
4. 微调技巧
六、主要应用场景
七、总结
论文链接:https://arxiv.org/pdf/1810.04805
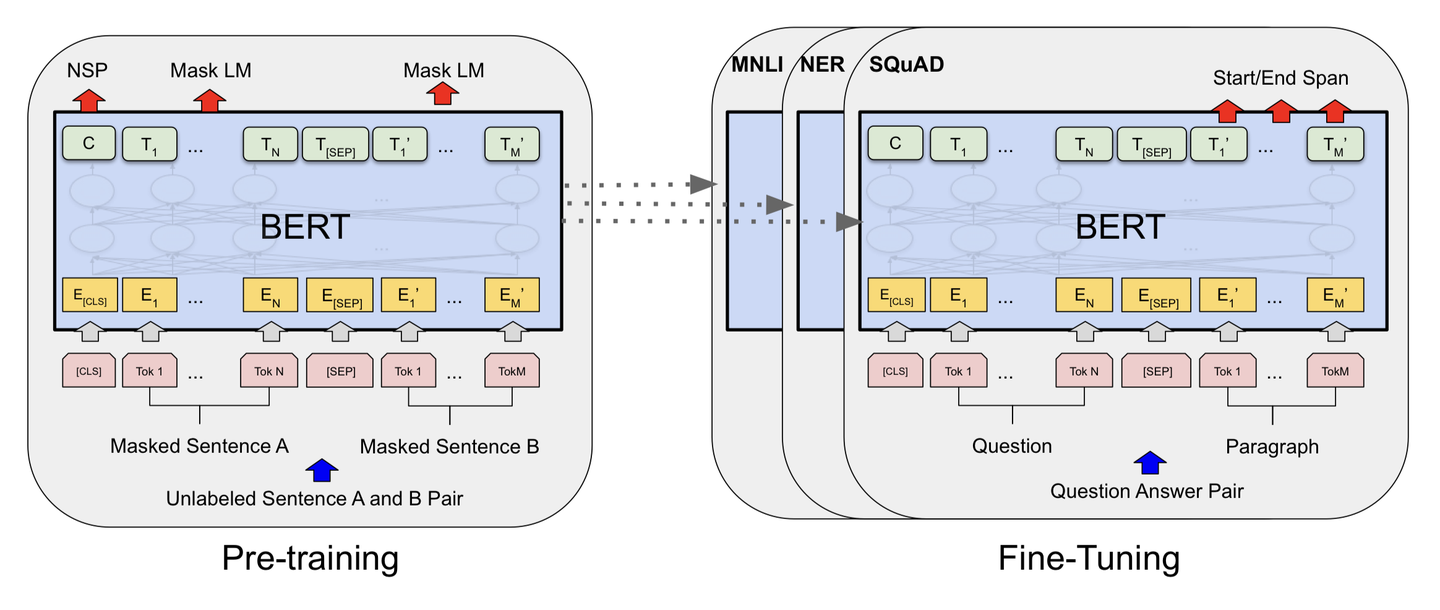
BERT是Google在2018年提出的革命性自然语言处理模型,它彻底改变了NLP领域的预训练范式。
一、核心思想
双向上下文理解:与传统语言模型(如GPT)的单向预测不同,BERT通过掩码语言模型(MLM)实现双向上下文编码,能够同时考虑单词左右两侧的上下文信息。
二、架构组成
1.基础架构:Transformer编码器
- BERT完全基于Transformer的编码器(Encoder)部分
- 采用多头自注意力机制和前馈神经网络
- 主要版本:
- BERT-Base:12层,768隐藏单元,12个注意力头(110M参数)
- BERT-Large:24层,1024隐藏单元,16个注意力头(340M参数)
2.输入表示
特殊标记:
- [CLS]:分类任务的聚合表示
- [SEP]:句子分隔符
- [MASK]:掩码标记
BERT的输入为每一个token对应的表征(图中的粉红色块就是token,黄色块就是token对应的embedding表征),并且单词字典是采用WordPiece算法来进行构建的。为了完成具体的分类任务,除了单词的token之外,还在输入的每一个序列开头都插入特定的分类token([CLS]),该分类token对应的最后一个Transformer层输出被用来起到聚集整个序列表征信息的作用。
由于BERT是一个预训练模型,其必须要适应各种各样的自然语言任务,因此模型所输入的序列必须有能力包含一句话(文本情感分类,序列标注任务)或者两句话以上(文本摘要,自然语言推断,问答任务)。那么如何令模型有能力去分辨哪个范围是属于句子A,哪个范围是属于句子B呢?BERT采用了两种方法去解决:
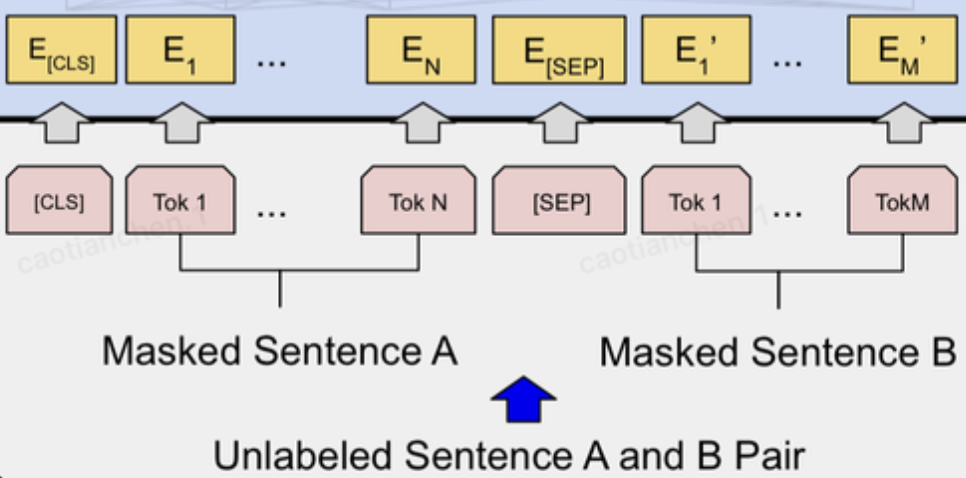
因此最后模型的输入序列tokens为下图(如果输入序列只包含一个句子的话,则没有[SEP]及之后的token):

输入序列 = 三部分嵌入的加和:
- 词嵌入(Token Embeddings):WordPiece分词
- 段嵌入(Segment Embeddings):区分句子A和句子B([SEP]分隔)
- 位置嵌入(Position Embeddings):学习到的位置编码

3.输出表示
介绍完BERT的输入,实际上BERT的输出也就呼之欲出了,因为Transformer的特点就是有多少个输入就有多少个对应维度的输出,如下图:

图中C为分类token([CLS])对应最后一个Transformer的输出,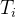 则代表其他token对应最后一个Transformer的输出。
则代表其他token对应最后一个Transformer的输出。
-
token级别任务:需要每个token的表示,因此使用每个token对应的输出向量
。 -
句子级别任务:需要整个句子的表示,因此使用[CLS]的输出C。
为什么[CLS]可以代表整个句子的信息? 在预训练阶段,[CLS]被用于下一句预测(NSP)任务,这使得[CLS]的向量能够捕捉两个句子之间的关系信息,从而学习到整个输入序列的语义表示。因此,在微调时,对于句子级别的任务,我们可以直接利用[CLS]的向量作为整个序列的表示,然后加上一个简单的分类层(如全连接层)进行分类。
BERT的输出在具体任务应用的示例:
(1)序列标注(如命名实体识别):
-
每个token都需要预测一个标签(如B-PER, I-PER, O等)。
-
将每个token对应的输出向量
输入到一个分类层(通常是一个全连接层,然后接Softmax)来预测每个token的标签。
(2)问答任务(如SQuAD):
-
需要预测答案在原文中的起始和结束位置。
-
将每个token的输出向量
分别输入到两个分类层(一个用于预测起始位置,一个用于预测结束位置),每个分类层输出一个概率分布,表示每个token作为起始/结束位置的概率。
(3)句子分类(如情感分析):
-
将[CLS]的输出向量C输入到一个分类层,然后通过Softmax得到不同类别的概率。
三、预训练任务(Pre-Training)
BERT的预训练采用无监督学习,在大规模文本语料上训练,使模型学习到深层的语言表示。训练包含两个核心任务,设计理念是让模型理解单词级和句子级的语言信息。
首先,输入序列token化:
原始文本: "The quick brown fox jumps over the lazy dog."
分词后: ["the", "quick", "brown", "fox", "jumps", "over", "the", "lazy", "dog", "."]
1.掩码语言模型(MLM,Masked Language Model)
- 随机掩盖15%的输入token
- 掩盖策略:
- 80%替换为[MASK]
输入: ["the", "quick", "brown", "[MASK]", "jumps", "over", "the", "lazy", "dog", "."]
标签: ["the", "quick", "brown", "fox", "jumps", "over", "the", "lazy", "dog", "."]
- 10%替换为随机词
输入: ["the", "quick", "brown", "car", "jumps", "over", "the", "lazy", "dog", "."]
标签: ["the", "quick", "brown", "fox", "jumps", "over", "the", "lazy", "dog", "."]
- 10%保持原词不变
输入: ["the", "quick", "brown", "fox", "jumps", "over", "the", "lazy", "dog", "."]
标签: ["the", "quick", "brown", "fox", "jumps", "over", "the", "lazy", "dog", "."]
设计原因:为了缓解预训练(有[MASK])和微调(没有[MASK])之间的不匹配。如果总是用[MASK]替换,模型在微调时从未见过真实单词,可能导致性能下降。
模型预测:将遮盖后的序列输入BERT模型,模型会对序列中的每一个位置都输出一个向量表示。
计算损失:只计算被遮盖位置(即那15%的token)的预测损失。具体来说,将被遮盖位置对应的输出向量送入一个Softmax分类器(词汇表大小的全连接层),预测该位置的原始token是什么。
损失函数:本质上是一个交叉熵损失。
假设我们遮盖了 k 个 token,词汇表大小为 V。
-
公式:
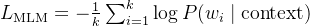
-
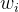 是第 i 个被遮盖位置的真实token。
是第 i 个被遮盖位置的真实token。 -
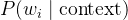 是模型预测该位置为真实token w_i 的概率。
是模型预测该位置为真实token w_i 的概率。 -
对所有被遮盖的位置的负对数似然求平均。
-
-
直观理解:就是让模型预测被遮盖词的概率尽可能大。例如,对于 "The quick [MASK] fox jumps",模型应该给 "brown" 这个词分配很高的概率。
2.下一句预测(NSP,Next Sentence Prediction)
- 输入:句子A + 句子B
- 预测:B是否是A的下一句
- 正例:连续句子
句子A: "The capital of France is Paris."
句子B: "It is the largest city in France."
标签:IsNext (1)
- 负例:随机选择的句子
句子A: "The capital of France is Paris."
句子B: "The sky is blue today." // 无关句子
标签:NotNext (0)
模型输入:句子对和[CLS]、[SEP]一起构成完整输入:[CLS] 句子A [SEP] 句子B [SEP]。
[CLS] The capital of France is Paris. [SEP] It is the largest city in France. [SEP]
|———- 句子A ———| |————– 句子B ————–|
模型预测:BERT模型输出[CLS] token的向量表示。这个向量被认为聚合了整个输入序列的语义信息。
计算损失:将[CLS]向量送入一个二分类器(全连接层+Softmax),预测 IsNext 或 NotNext。
NSP损失函数:也是一个标准的二分类交叉熵损失。
-
公式:
![L_{\\text{NSP}} = - \\left[ y \\log(p) + (1 - y) \\log(1 - p) \\right]](https://www.wsisp.com/helps/wp-content/uploads/2026/01/20260119101804-696e04dc2816e.png)
-
y 是真实标签(1表示 IsNext,0表示 NotNext)。
-
p 是模型预测为 IsNext 的概率。
-
3.总结
在BERT的预训练中,两个任务是联合训练的。模型同时进行MLM和NSP,其总损失是这两个损失的简单加和:
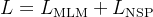
| 目标 | 学习词级双向上下文表示 | 学习句间关系表示 |
| 输入 | 可能被遮盖的单个句子/句子对 | 必须是句子对 (A, B) |
| 输出 | 预测被遮盖的词 (词汇表大小) | 二分类 (是/否下一句) |
| 损失函数 | 交叉熵损失 (对被遮盖位置) | 二分类交叉熵损失 |
| 关键作用 | 实现深度双向编码,是BERT的核心 | 增强对句子对任务的理解能力 |
BERT的预训练通过巧妙的MLM和NSP任务设计:
- MLM实现了真正的双向语言建模
- NSP学习了句子间关系
- 联合训练让模型同时掌握词汇和篇章知识
这种预训练方式使得BERT能够学习到深层次、可迁移的语言表示,为其在各种下游任务上的优异表现奠定了基础。预训练的质量直接决定了微调效果,是BERT成功的关键所在。
四、网络细节
1.自注意力机制
- 公式:
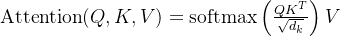
- 多头注意力:并行多个注意力头,捕获不同子空间的语义信息
2.层归一化与残差连接
- 每个子层后都有残差连接和层归一化
- 解决深度网络训练中的梯度问题
3.前馈网络
- 两层全连接层 + ReLU激活函数
- 公式:
五、微调(Fine-tuning)
1. 微调的基本思想
BERT的微调是指在预训练好的模型参数基础上,使用下游任务的有标注数据对整个模型或部分模型进行进一步的训练,使模型适应特定任务。由于预训练模型已经学习了丰富的语言表示,微调通常只需要相对较少的有标注数据就能取得很好的效果。
2. 常见任务的微调
2.1 句子对分类任务(如MNLI,QQP等)
任务描述:判断两个句子之间的关系,如是否相似、是否蕴含等。
数据格式:
- 输入:两个句子,中间用[SEP]分隔。
- 例如:[CLS] 句子1 [SEP] 句子2 [SEP]
- 标签:类别标签(如0,1,2等)
模型调整:
- 在BERT的输出中,取[CLS]对应的向量(即整个序列的表示)作为句子对的表示。
- 然后接一个全连接层(分类器),将768维(BERT-base)的向量映射到类别数量的维度,然后通过softmax得到分类概率。
损失函数:交叉熵损失函数。
2.2 单句子分类任务(如SST-2,情感分类)
任务描述:对单个句子进行分类。
数据格式:
- 输入:单个句子,格式为[CLS] 句子 [SEP]
- 标签:类别标签
模型调整:同样使用[CLS]对应的向量作为句子表示,然后接分类器。
2.3 问答任务(如SQuAD)
任务描述:给定一个问题和一段上下文,从上下文中找出答案的起始和结束位置。
数据格式:
- 输入:问题与上下文组合,格式为[CLS] 问题 [SEP] 上下文 [SEP]
- 标签:答案在上下文中的起始位置和结束位置(索引)。
模型调整:
- 在BERT的输出中,对上下文部分的每个token分别预测两个概率:作为答案起始位置的概率和作为答案结束位置的概率。
- 具体来说,我们引入两个可训练的向量S和E(维度与隐藏层相同),分别与上下文部分每个token的输出向量点积,然后通过softmax得到每个位置作为起始和结束的概率。
- 训练时,最大化正确答案起始位置和结束位置的概率。
损失函数:起始位置和结束位置的交叉熵损失之和。
2.4 序列标注任务(如NER)
任务描述:对句子中的每个token进行分类,如命名实体识别。
数据格式:
- 输入:单个句子,格式为[CLS] 单词1 单词2 … [SEP]
- 标签:每个token对应的标签(使用BIO等标注体系),注意标签与token一一对应。
模型调整:
- 取每个token对应的输出向量(即BERT最后一层的对应位置的向量),然后接一个全连接层,将768维映射到标签数量的维度,然后通过softmax得到每个token的标签概率。
- 注意:由于BERT使用WordPiece分词,可能会出现一个单词被分成多个子词的情况。通常的处理方法是取第一个子词的输出作为该单词的表示,或者取所有子词输出的平均。
损失函数:每个token的交叉熵损失之和(或平均)。
3. 微调步骤
4. 微调技巧
- 学习率:微调时学习率通常较小,避免破坏预训练模型已经学到的知识。
- 批次大小:由于BERT模型较大,批次大小可能受显存限制,可以使用梯度累积来模拟更大的批次。
- 训练轮数:通常3-5个epoch即可,过多可能导致过拟合。
- 分层学习率:有时会对BERT层和顶层分类器使用不同的学习率,BERT层的学习率更小。
- 使用验证集:早停(early stopping)策略可以防止过拟合。
六、主要应用场景
1.单句分类任务:情感分析、文本分类,使用[CLS]位置的输出作为句子表示
2.句子对任务:自然语言推理、语义相似度,输入格式:[CLS]句子A[SEP]句子B[SEP]
3.问答任务:SQuAD数据集,预测答案在原文中的开始和结束位置
4.序列标注:命名实体识别、词性标注,使用每个token对应的输出
七、总结
BERT的成功源于:
BERT奠定了现代预训练语言模型的基础,其思想和架构深刻影响了后续的NLP模型发展,如GPT系列、T5等。虽然已有更先进的模型出现,但BERT的设计理念至今仍有重要价值。



评论前必须登录!
注册