 网硕互联帮助中心
网硕互联帮助中心Linux 下的线程底层原理是一个非常经典且由于历史原因略显独特的领域。要理解它,我们不能仅仅停留在 pthread_create 的 API 层面,而必须深入到内核(Kernel)的数据结构、系统调用以及内存管理机制中。
以下是关于 Linux 线程底层原理的详细讲解,分为几个核心层面:
Linux 只有 LWP:线程本质是共享了内存空间的进程。
clone() 是基石:通过 CLONE_VM 等标志实现资源共享。
1:1 模型:NPTL 库将用户线程映射为内核 LWP。
Futex:实现了高效的混合态同步锁。
栈是私有的,堆是共享的。
一、 核心概念:Linux 中没有真正的“线程”
这是理解 Linux 线程最关键的一点。
在 Windows 或 Solaris 等操作系统中,进程(Process)和线程(Thread)是内核中两种截然不同的数据结构。进程是资源容器,线程是执行单元。
但在 Linux 内核看来,线程和进程没有本质区别。 它们都被视为执行实体(Execution Entity),在内核中都用同一个数据结构 task_struct 来表示。
-
进程(Process): 独占虚拟内存空间、文件描述符表的 task_struct。
-
线程(Thread): 与其他 task_struct 共享虚拟内存空间、文件描述符表的 task_struct。
因此,Linux 中的线程通常被称为 轻量级进程(LWP, Light Weight Process)。
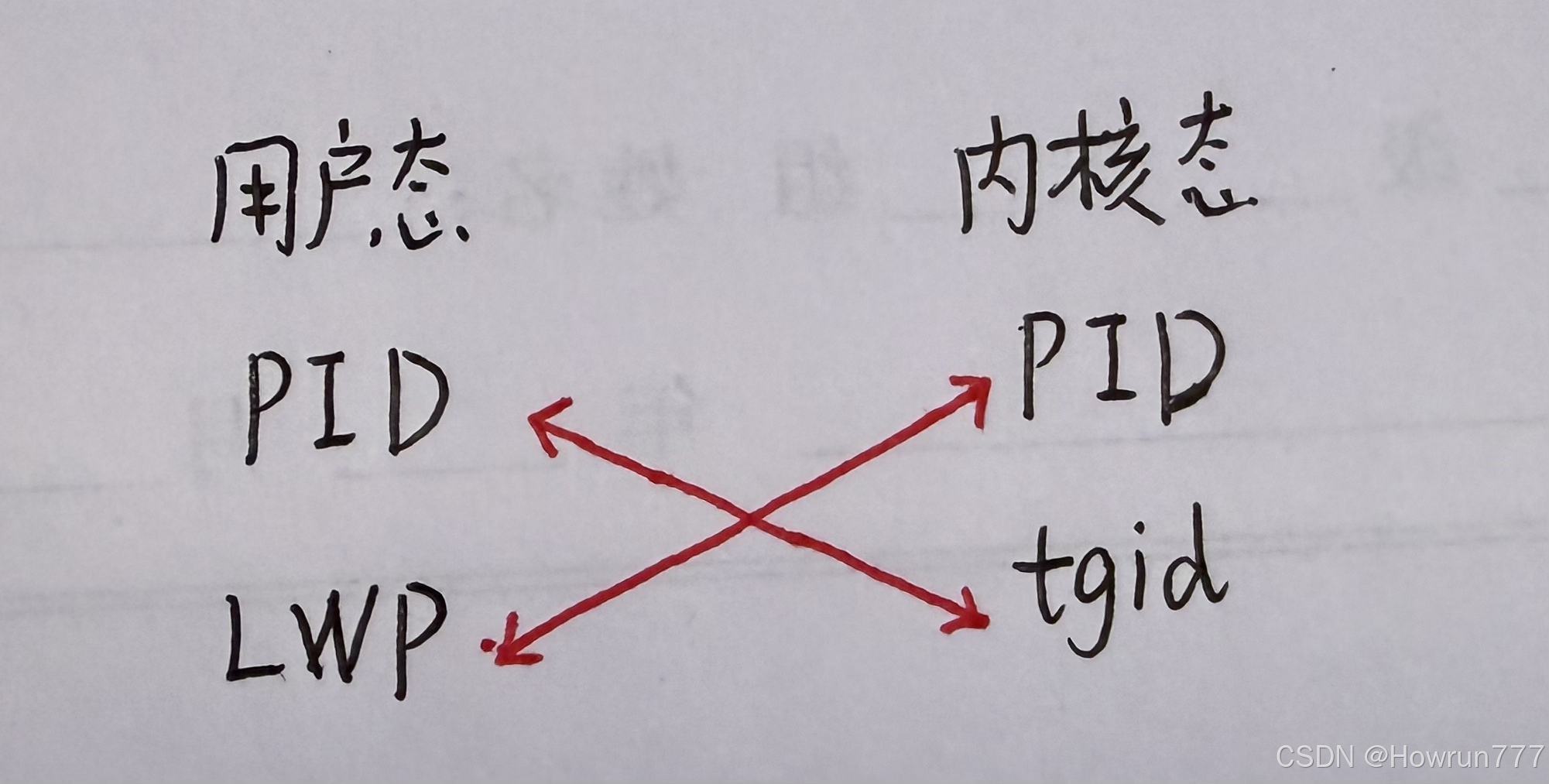
- 用户态:你调用 pthread 库创建的线程(pthread_t)是「用户态线程」;
- 内核态:每个用户态线程对应一个内核态的 LWP(轻量级进程),内核调度的最小单位是LWP(而非进程);
| 内核描述符 | 独立的task_struct | 独立的task_struct |
| 地址空间(mm_struct) | 独立(复制父进程地址空间) | 共享(与线程组其他成员共用同一个) |
| 文件描述符表 | 独立(复制父进程) | 共享 |
| 信号处理(signal) | 独立 | 共享 |
| 用户 / 组 ID(uid/gid) | 独立 | 共享 |
| 栈空间 | 独立(私有栈) | 独立(每个线程有私有栈,默认 8MB) |
| 寄存器 / 程序计数器 | 独立 | 独立(调度时保存 / 恢复) |
| PID(内核态) | 唯一(tgid=pid,线程组 ID = 自身 PID) | 线程组 ID(tgid)= 主线程 PID,自身 PID=LWP(ps -Lf 看到的 LWP) |
二、 内核数据结构与标识
1. task_struct
这是 Linux 内核中最重要的结构体(PCB – Process Control Block)。无论你启动的是一个进程还是一个线程,内核都会分配一个 task_struct。
2. PID 与 TGID(极其重要的区分)
在用户空间(User Space)和内核空间(Kernel Space),对“ID”的定义是不同的,这常让人困惑。
内核视角:
-
PID (Process ID): 每个 task_struct 都有唯一的 PID。如果是多线程程序,每个线程在内核里的 PID 都是不一样的。(对应ps -Lf的LWP字段)
-
TGID (Thread Group ID): 这是线程组 ID。(对应ps -Lf的PID字段)
主线程(进程):tgid = pid(自身 PID 就是线程组 ID);
子线程:tgid = 主线程pid(所有线程同属一个线程组)。
用户视角(POSIX 标准):
-
用户调用 getpid() 时,期望看到所有线程返回同一个 ID。
-
因此,Linux 的 getpid() 系统调用返回的是当前 task_struct 的 TGID,而不是内核里的 PID。
-
用户看到的“线程 ID”(通过 pthread_self() 获得)其实是线程库(NPTL)在用户态维护的一个内存地址,而非内核 ID。
UID PID PPID LWP C NLWP STIME TTY STAT TIME CMD
root 1234 1100 1234 0 3 10:00 pts/0 Sl 0:05 ./my_app
root 1234 1100 1235 2 3 10:01 pts/0 Sl 0:12 ./my_app
root 1234 1100 1236 1 3 10:01 pts/0 Sl 0:08 ./my_app
三、 线程的创建:clone() 系统调用
在 Linux 中,创建进程通常用 fork(),而底层实现线程(包括 fork 自身)最终都指向了 clone() 系统调用。
clone() 的神奇之处在于它可以精细控制父子执行实体之间共享哪些资源。
函数原型大致如下:
int clone(int (*fn)(void *), void *stack, int flags, void *arg, …);
关键的 flags 参数:
通过设置不同的标志位,决定了创建出来的是“进程”还是“线程”:
创建进程 (fork 的行为):
flags 基本为空(或包含 SIGCHLD)。
子进程会复制父进程的页表(Copy-on-Write)、文件描述符表等。资源是隔离的。
创建线程 (pthread_create 的行为):
flags 会包含以下关键位:
CLONE_THREAD: 将子进程放入父进程的线程组中(设置 TGID)。
CLONE_SIGHAND: 共享信号处理函数。
CLONE_FS: 共享文件系统信息(根目录、当前工作目录)。
CLONE_FILES: 共享文件描述符表(打开的文件)。
CLONE_VM: 共享虚拟内存空间(堆、代码段、全局变量)。这是线程通信快的基础。
总结: Linux 线程本质上就是通过 clone() 系统调用,带上 CLONE_VM 等标志创建出来的、与父进程共享地址空间的“进程”。
四、 线程库:NPTL (Native POSIX Thread Library)
内核提供了基础的 clone 机制,但离好用的 POSIX 线程标准(pthread)还有距离。这就是 glibc 中 NPTL 的工作。
1. 1:1 线程模型
Linux 目前使用的是 1:1 模型。
-
含义: 用户空间的每一个线程(pthread),都严格对应内核空间的一个 LWP(task_struct)。
-
优点: 能够真正利用多核 CPU(内核可以把不同的 LWP-轻量级进程 调度到不同的 CPU 核上并行执行)。
-
缺点: 线程创建和上下文切换(Context Switch)还是有内核开销的(虽然比纯进程切换小得多)。
对比其他模型:
- N:1 模型(用户态线程映射到 1 个内核 LWP):内核无感知,无法利用多核;
- M:N 模型(M 个用户线程映射到 N 个内核 LWP):复杂且 Linux 未采用;
- 1:1 模型:优点是能充分利用多核,缺点是线程创建 / 切换有内核开销(pthread 库已做优化)。
2. NPTL 的职责
当你调用 pthread_create 时,NPTL 做了很多幕后工作:
分配栈: 线程的栈是私有的。主线程的栈在传统的栈区,而其他线程的栈通常是在 mmap 区域(堆区附近) 分配出来的固定大小内存。
**调用 clone:**以此栈为参数调用系统调用。
管理元数据: 在用户态维护一个 pthread 结构体,用于存放线程 ID、栈地址、退出状态等。
五、 内存布局:共享与私有
理解线程安全,必须理解内存布局。
1. 共享资源(所有线程都能看、能改)
由于 CLONE_VM,整个进程的虚拟地址空间是共享的:
-
.text (代码段): 所有线程执行同一份代码。
-
.data / .bss (全局/静态变量): 需注意同步竞争。
-
Heap (堆): malloc 出来的内存,指针传递给谁,谁就能访问。
2. 私有资源(线程独享)
-
Stack (栈): 极其重要!虽然理论上通过指针可以访问别的线程的栈,但逻辑上是私有的。局部变量、函数调用链都在这里。
-
Registers (寄存器): 线程调度的本质就是保存和恢复寄存器上下文(PC 指针、SP 栈指针等)。
-
TLS (Thread Local Storage): 通过 __thread 关键字定义的变量。
-
底层实现: 在 x86_64 架构下,通常利用 FS 或 GS 段寄存器指向当前线程的 TCB(Thread Control Block),从而快速访问线程局部变量。
-
六、 同步机制的底层:Futex
线程共享内存带来了竞争,所以需要锁(Mutex)。早期的 Linux 线程锁非常慢,因为每次加锁解锁都要陷入内核(System Call)。
现代 Linux 线程同步的核心机制是 Futex (Fast Userspace muTEX)。
原理:
用户态快路径: 锁本质上是一个整数。线程尝试用原子操作(CAS – Compare And Swap)修改它。如果成功(无竞争),直接拿到锁,完全不经过内核,速度极快。
内核态慢路径: 只有当原子操作发现锁已经被别人拿走了(有竞争),线程才会调用 futex() 系统调用,陷入内核,将自己挂起(Sleeping),等待被唤醒。
这使得 Linux 线程在无竞争情况下的性能非常接近无锁操作。
1. 互斥锁(pthread_mutex_t)的底层
- 无竞争场景:完全在用户态通过原子操作(CAS)加锁 / 解锁,无需内核介入,性能极高;
- 有竞争场景:竞争失败的线程通过 Futex 系统调用陷入内核,进入休眠状态(避免忙等消耗 CPU);
- 解锁时:唤醒内核中休眠的线程,使其重新竞争锁。
2. 条件变量(pthread_cond_t)的底层
- 基于 Futex 实现,pthread_cond_wait:释放互斥锁 + 陷入内核休眠,等待信号;
- pthread_cond_signal:通过 Futex 唤醒休眠的线程,使其重新获取互斥锁并继续执行。
对比:自旋锁 vs 互斥锁(底层)
- 自旋锁:全程在用户态忙等(CAS),适用于临界区极短的场景(避免内核切换开销);
- 互斥锁:竞争时陷入内核休眠,适用于临界区较长的场景(减少 CPU 消耗)。
七、 线程调度
既然线程在内核里就是 task_struct,那么调度器(Scheduler)其实不区分你是进程的主线程,还是子线程。
-
调度算法: 主要是 CFS (Completely Fair Scheduler)。
-
策略: 内核根据 task_struct 的优先级、消耗的时间片等进行调度。
-
优势: 因为内核直接调度 LWP,所以假如一个进程里的线程 A 阻塞了(比如读磁盘),内核会立刻调度该进程里的线程 B 运行,不会导致整个进程卡死(这是 1:1 模型相对于用户级线程 M:N 模型的巨大优势)。
八、 总结图解
用户空间 (User Space)
—————————————
进程 (Process)
|
+— 主线程 (Main Thread) —-+
| [栈] [TLS] [pthread结构] |
| | <— 共享堆、全局变量、文件描述符
+— 子线程 (Thread 1) ——-+
| [栈] [TLS] [pthread结构] |
| |
—————————————
| 调用 clone() |
v v
—————————————
内核空间 (Kernel Space)
|
+— task_struct (PID=100, TGID=100) <– 对应主线程
| | map same mm_struct |
|
+— task_struct (PID=101, TGID=100) <– 对应子线程
| map same mm_struct |




评论前必须登录!
注册