 网硕互联帮助中心
网硕互联帮助中心一、Redis 基础认识
1.1 定义与核心特性
Redis(Remote Dictionary Server,远程字典服务)是一款完全开源的高性能 Key-Value 数据库,官网地址:https://redis.io/。核心特性如下:
- 数据结构丰富:支持字符串(String)、哈希(Hash)、列表(List)、集合(Set)、有序集合(ZSet)、位图(Bitmap)、HyperLogLog、地理空间(Geo)、向量(Vector)等多种复杂数据类型,可满足缓存、数据库、向量搜索等多场景需求。
- 内存存储 + 持久化:数据全量存储于内存,保证极高的读写性能;同时支持 RDB、AOF 两种持久化方式,将数据落盘到硬盘,保障数据安全性,因此 Redis 可同时作为缓存、数据库使用。
- 高性能:基于内存操作 + 单线程核心模型 + IO 多路复用,单机 QPS 可达 10W+。
1.2 版本演进
| 4.X 及以前 | 纯单线程(核心读写 + 后台操作均单线程) | 基础的事务、Pipeline 支持 |
| 5.X | 核心代码重构 | 为后续多线程铺路,优化底层架构 |
| 6.X | 核心读写仍单线程,后台耗时操作多线程 | 引入多线程 IO、ACL 权限控制 |
| 7.X | 核心读写单线程,更多后台操作异步化 | 增强 Lua 脚本、Redis Function、只读脚本支持 |
二、Redis 线程模型
2.1 整体线程模型(核心)
Redis 线程模型可总结为:客户端多线程,服务端核心单线程(版本差异化扩展)。
2.1.1 基础架构(Mermaid 流程图)
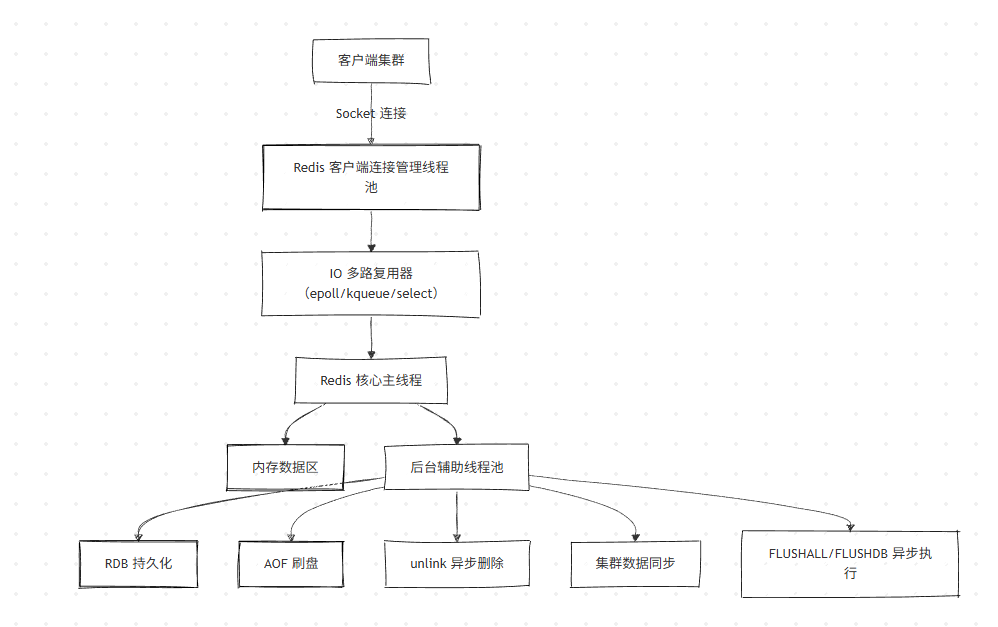
2.1.2 关键细节
- 负责处理所有网络 IO、键值对读写、指令解析执行等核心操作;
- 基于 epoll 实现 IO 多路复用,可单线程同时响应多个客户端的 Socket 读写请求;
- 所有核心指令串行执行,天然避免了并发读写的脏读、幻读、不可重复读等问题。
IO多路复用:简单来说就是一种让单个线程(Redis 主线程)同时监听多个网络套接字(Socket)的 IO 状态,并且仅在套接字有实际 IO 事件(如可读、可写)发生时,才对其进行相应处理的技术。
3. 后台辅助线程(Redis 5.X+):
- 耗时操作使用多线程:RDB 生成、AOF 重写 / 刷盘、unlink 异步删除、集群数据同步、FLUSHALL/FLUSHDB 异步执行等,由独立线程处理,避免阻塞核心主线程;
- 核心读写仍单线程:保证指令执行的原子性,避免多线程上下文切换开销(Redis 性能瓶颈不在 CPU,而在内存 / 网络)。
2.2 总结
Redis 是 “核心单线程 + 辅助多线程” 模型,核心读写单线程(保障原子性),后台耗时操作多线程(提升整体性能)。
三、Redis 指令原子性保障
Redis 核心读写单线程串行执行,天然具备指令级原子性,但复杂业务场景需额外手段保障 “一组指令” 的原子性,核心方案如下:
3.1 复合指令(原子性指令)
Redis 内置的复合指令本身是原子的,一条指令完成多个操作,无需额外控制:
| MSET/HMSET | 批量设置键值 / 哈希字段 | 一次性完成所有设置,中间不会被打断 |
| GETSET | 设置新值并返回旧值 | 原子性完成 “读 + 写” |
| SETNX | 仅当键不存在时设置 | 分布式锁核心指令,原子性判断 + 设置 |
| SETEX | 设置值并指定过期时间 | 原子性完成 “设置 + 过期”,避免先 SET 再 EXPIRE 的竞态 |
| INCR/DECR | 原子自增 / 自减 | 替代 “GET→计算→SET” 的非原子操作 |
复合指令的典型场景:
// Java 中使用 SETNX 实现简单分布式锁
Jedis jedis = new Jedis("localhost", 6379);
String lockKey = "dist:lock:order";
// 原子性获取锁:不存在则设置,过期时间30s避免死锁
Boolean lockSuccess = jedis.setnx(lockKey, "locked");
if (lockSuccess) {
jedis.expire(lockKey, 30); // 补充过期时间(Redis 2.6.12+ 可合并为 set lockKey locked NX EX 30)
try {
// 执行业务逻辑
} finally {
jedis.del(lockKey); // 释放锁
}
}
3.2 Redis 事务
3.2.1 核心命令
| MULTI | 开启事务 | 后续指令进入队列,返回 QUEUED |
| EXEC | 执行事务 | 一次性执行队列中所有指令 |
| DISCARD | 放弃事务 | 清空队列,终止事务 |
| WATCH key [key…] | 监听键变化 | 事务执行前,若监听的键被修改,事务执行失败 |
| UNWATCH | 取消监听 | 仅对当前客户端有效,不影响其他客户端 |
3.2.2 事务特性
- 错误认识:Redis 事务像数据库事务一样,支持回滚;
- 正确结论:Redis 事务的核心是 “批量执行 + 串行化”,而非 “原子回滚”:
- 执行前失败(指令语法错误 / 参数错误):EXEC 时整个事务不执行;
- 执行中失败(如对 String 键执行 LPOP):错误指令返回异常,其他指令正常执行,不会回滚;
- WATCH 机制:监听键被修改时,EXEC 返回 nil,事务不执行(乐观锁思想)。
3.2.3 事务执行流程
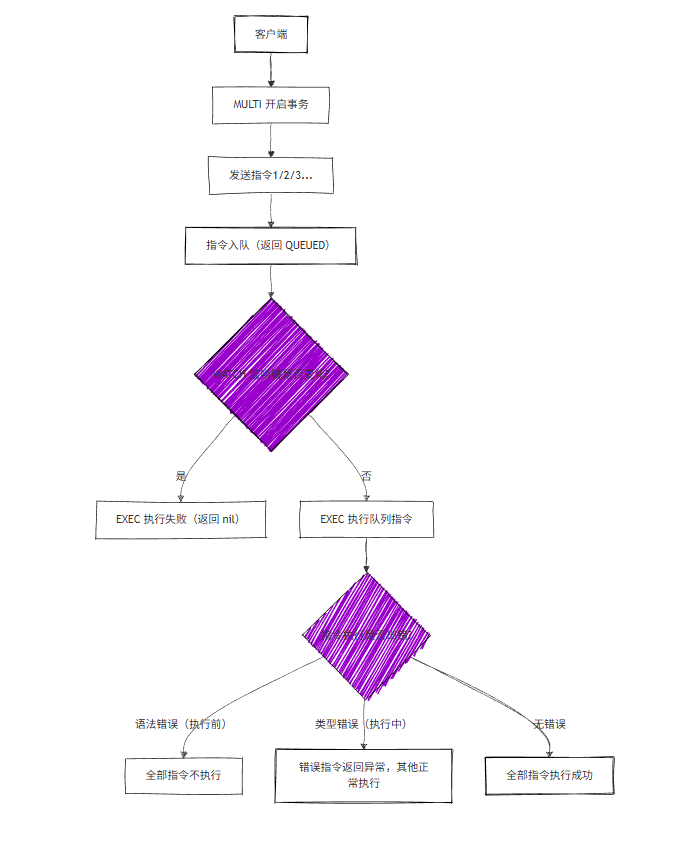
3.2.4 事务失败处理
总结:redis中事务的作用不是像数据库一样保证整个操作的原子性(一起成功或一起失败),而只是保证这一系列的操作一起执行(错误时也不支持回滚),执行过程中不会被其他指令加塞。
3.3 Pipeline(管道)
3.3.1 核心原理
Pipeline 是优化网络 RTT(Round-Trip Time,往返时间)的机制:将多个指令打包,一次性发送到服务端,服务端批量执行后一次性返回结果,减少网络往返次数。
3.3.2 RTT 优化对比(Mermaid 对比图)
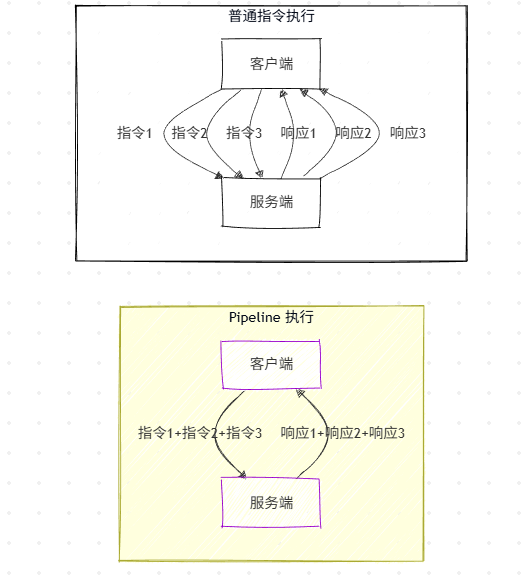
3.3.3 使用示例
// Java 使用 Jedis 实现 Pipeline
Jedis jedis = new Jedis("localhost", 6379);
Pipeline pipeline = jedis.pipelined();
// 批量添加指令
pipeline.set("count", "1");
pipeline.incr("count");
pipeline.incr("count");
pipeline.incr("count");
// 执行并获取结果
List<Object> results = pipeline.syncAndReturnAll();
// 结果:[OK, 2, 3, 4]
System.out.println(results);
3.3.4 关键注意点
- 错误认识:Pipeline 具备原子性;
- 正确结论:Pipeline 仅优化网络传输,不保证原子性 —— 服务端执行时,仍可能被其他客户端的指令 “插队”;
- 性能上限:单次 Pipeline 指令不宜过多(建议 1000 条以内),避免客户端阻塞 / 服务端内存占用过高;
- 与事务的区别:Pipeline 仅批量发送,无 “队列化 + 监听”;事务是 “队列化 + 原子执行”,但无网络优化。
3.4 Lua 脚本(重点)
3.4.1 核心优势
Lua 是轻量级单线程脚本语言,Redis 中执行 Lua 脚本具备以下特性:
- 原子性:脚本内所有指令作为一个整体执行,中间不会被其他指令打断;
- 灵活性:支持自定义逻辑(条件判断、循环、变量等),弥补复合指令 / 事务的局限性;
- 高性能:脚本在服务端执行,减少网络往返。
3.4.2 核心指令:EVAL/EVAL_RO
EVAL script numkeys [key [key …]] [arg [arg …]]
- script:Lua 脚本内容;
- numkeys:键参数个数;
- KEYS[]:脚本中访问的 Redis 键(必须通过 KEYS 数组,便于集群分片);
- ARGV[]:脚本中使用的附加参数。
3.4.3 示例:原子调整库存
// Java 调用 Lua 脚本
Jedis jedis = new Jedis("localhost", 6379);
String luaScript = "local initcount = redis.call('get', KEYS[1]) " +
"local a = tonumber(initcount) " +
"local b = tonumber(ARGV[1]) " +
"if a >= b then " +
" redis.call('set', KEYS[1], a) " +
" return 1 " +
"end " +
"redis.call('set', KEYS[1], b) " +
"return 0";
// 执行脚本:KEYS[1] = stock_1,ARGV[1] = 10
Object result = jedis.eval(luaScript, 1, "stock_1", "10");
System.out.println(result); // 输出 0(库存1<10,设置为10)
3.4.4 关键注意点
3.5 Redis Function(Redis 7+)
3.5.1 核心优势
- 基于 Lua 扩展,支持将脚本封装为 “函数”,提前加载到服务端,客户端直接调用;
- 支持函数嵌套调用,代码复用性更高(Lua 脚本无法复用);
- 支持权限控制、只读调用,更适合生产环境管理。
3.5.2 使用示例
#!lua name=mylib — 命名空间,必须第一行
local function my_hset(keys, args)
local hash = keys[1]
local time = redis.call('TIME')[1] — 获取当前时间戳
— HSET:设置哈希字段,_last_modified_ 记录最后修改时间
return redis.call('HSET', hash, '_last_modified_', time, unpack(args))
end
— 注册函数
redis.register_function('my_hset', my_hset)
2. 加载函数到 Redis:
cat mylib.lua | redis-cli -a 密码 -x FUNCTION LOAD REPLACE
3.调用函数:
127.0.0.1:6379> FCALL my_hset 1 myhash myfield "some value" another_field "another value"
(integer) 3 — 成功设置3个字段
127.0.0.1:6379> HGETALL myhash
1) "_last_modified_"
2) "1717748001"
3) "myfield"
4) "some value"
5) "another_field"
6) "another value"
3.5.3 注意点
- 集群环境:需在每个节点手动加载函数(Redis 不会自动同步);
- 资源控制:函数缓存于服务端,应注意避免过多 / 过大函数占用内存;
- 管理指令:FUNCTION LIST(查看函数)、FUNCTION DELETE(删除函数)等。
3.6 原子性方案对比
| 复合指令 | 原子 | 低(固定逻辑) | 最高 | 简单批量操作(如 MSET、SETNX) |
| 事务 | 弱原子(执行中不回滚) | 中(仅指令队列) | 中 | 简单批量指令,需监听键变化(WATCH) |
| Pipeline | 无 | 中(仅批量发送) | 高(优化 RTT) | 非热点数据批量读写,无需原子性 |
| Lua 脚本 | 强原子 | 高(自定义逻辑) | 高 | 复杂业务逻辑(如库存扣减、分布式锁) |
| Redis Function | 强原子 | 极高(函数复用) | 高 | Redis 7+ 环境,复杂可复用逻辑 |
四、BigKey 问题
4.1 定义
BigKey 指占用内存过大或元素过多的键,例如:
- String 类型:值大于 100KB;
- List/Set/ZSet 类型:元素数大于 1W;
- Hash 类型:字段数大于 1W。
4.2 危害
- 阻塞核心线程:读取 / 删除 BigKey 耗时过长,阻塞其他指令执行;
- 网络阻塞:BigKey 传输占用大量带宽,导致网络延迟;
- 持久化 / 同步慢:RDB/AOF 生成、主从同步时,BigKey 处理耗时久。
4.3 检测方法
# 检测元素数量多的 BigKey
redis-cli –bigkeys
# 检测占用内存大的 BigKey
redis-cli –memkeys
# 带密码检测
redis-cli -a 密码 –bigkeys
4.4 解决方案
- Hash 拆分:将大 Hash 按字段前缀拆分为多个小 Hash(如 user:info:1000 → user:info:1000:1、user:info:1000:2);
- List/Set 拆分:按时间 / 业务维度拆分为多个小列表 / 集合;



评论前必须登录!
注册