 网硕互联帮助中心
网硕互联帮助中心看这一篇就够了。本文内含YOLO26核心创新介绍+YOLO26网络结构图 + yaml配置文件详细解读与说明 + YOLO虚拟环境安装+训练教程 + 训练参数设置+验证教程+推理教程+参数解析说明等一些有关YOLO26的内容!
本文目录
一、YOLO26简介
YOLO26 的架构遵循四个核心原则:
YOLO26 的主要技术创新:
1. 移除DFL模块,简化预测流程
2. 端到端无NMS推理,降低 latency
3. ProgLoss+STAL,提升检测精度
4. MuSGD优化器,强化训练稳定性
5. CPU推理速度提升高达43%
6. 实例分割增强:多尺度信息融合,掩码更精准
7. 姿态估计增强:集成RLE, keypoint预测更可靠
8.OBB旋转目标检测:角度损失优化,旋转预测更稳定
YOLO26 相比较上一代YOLOv11区别:
与 YOLO11 相比,YOLO26 的主要改进是什么?
YOLO26 支持的多种任务和多尺寸模型:
1. 支持多尺寸模型,适配多场景任务需求
2. YOLO26支持多种视觉任务
二、YOLO26的网络结构分析
YOLO26整体网络结构主要由以下三个大部分组成:
三、yolo26.yaml配置文件进行详细讲解
3.1 参数部分【Parameters】
3.2 主干部分【backbone】
3.3 头部【head】
四、YOLO26虚拟环境配置
创健YOLO26的虚拟环境:
五、YOLO26模型训练参数详细解析
5.1 YOLO26模型训练代码
5.2 YOLO26模型验证代码
5.3 YOLO26模型推理代码
5.4模型大小选择
5.5 训练参数设置
5.6 训练参数说明
六、本文总结
一、YOLO26简介

YOLO26 的架构遵循四个核心原则:
- 简洁性: YOLO26是一个原生的端到端模型,直接生成预测结果,无需非极大值抑制(NMS)。通过消除这一后处理步骤,推理变得更快、更轻量,并且更容易部署到实际系统中。这种突破性方法最初由清华大学的王傲在YOLOv10中开创,并在YOLO26中得到了进一步发展。
- 部署效率: 端到端设计消除了管道的整个阶段,从而大大简化了集成,减少了延迟,并使部署在各种环境中更加稳健。
- 训练创新:YOLO26 引入了MuSGD 优化器,它是 SGD和 Muon的混合体——灵感来源于 Moonshot AI 在 LLM 训练中 Kimi K2的突破。该优化器带来了增强的稳定性和更快的收敛,将语言模型中的优化进展转移到计算机视觉领域。
- 任务特定优化:YOLO26 针对专业任务引入了有针对性的改进,包括用于 Segmentation 的语义分割损失和多尺度原型模块,用于高精度 姿势估计 的残差对数似然估计 (RLE),以及通过角度损失优化解码以解决 旋转框检测 中的边界问题。
这些创新共同提供了一个模型系列,该模型系列在小对象上实现了更高的精度,提供了无缝部署,并且在 CPU 上的运行速度提高了 43% — 使 YOLO26 成为迄今为止资源受限环境中最实用和可部署的 YOLO 模型之一。
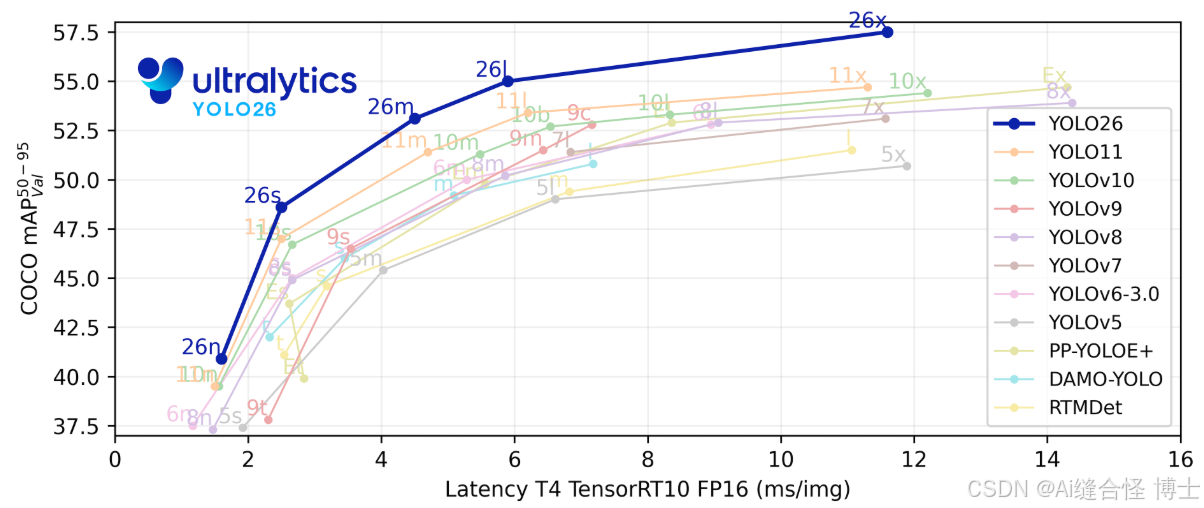
YOLO26 的主要技术创新:
1. 移除DFL模块,简化预测流程
早期YOLO模型依赖分布焦点损失(DFL)提升边界框精度,但这一模块增加了部署复杂度,且存在固定回归限制。YOLO26彻底移除DFL,不仅简化了边界框预测逻辑,提升了硬件兼容性,还解决了超大目标检测的可靠性问题,让模型在边缘设备上的导出与运行更顺畅。
2. 端到端无NMS推理,降低 latency
传统目标检测需通过非极大值抑制(NMS)进行后处理,过滤重叠预测框——这一步骤会增加延迟、提升部署难度。YOLO26采用原生端到端架构,直接输出最终预测结果,内部自动处理重复预测,彻底省去NMS环节,大幅降低推理延迟与集成风险,完美适配实时边缘场景。
3. ProgLoss+STAL,提升检测精度
-
渐进式损失平衡(ProgLoss):让模型训练过程更稳定,收敛更平滑,减少训练波动
-
小目标感知标签分配(STAL):针对小目标、低可见度目标优化学习机制,解决边缘场景中“难检测”问题 两项技术结合,让YOLO26在复杂场景中仍能保持高可靠检测,尤其适用于物联网、机器人、航拍等小目标密集场景。
4. MuSGD优化器,强化训练稳定性
YOLO26采用全新混合优化器MuSGD,融合传统随机梯度下降(SGD)的强泛化能力与大语言模型(LLM)训练中的先进优化思路。该优化器灵感源自Moonshot AI的Kimi K2,能让模型更快达到高性能水平,同时降低训练不稳定性,尤其在大型复杂数据集训练中表现突出。
5. CPU推理速度提升高达43%
YOLO26专为边缘计算优化,提供显著更快的CPU推理,确保在没有GPU的设备上实现实时性能。这一优化让无GPU设备(如摄像头、机器人、嵌入式系统)也能实现实时视觉处理。
6. 实例分割增强:多尺度信息融合,掩码更精准
引入语义分割损失以改善模型收敛,以及升级的原型模块,该模块利用多尺度信息以获得卓越的掩膜质量。
7. 姿态估计增强:集成RLE, keypoint预测更可靠
集成残差对数似然估计(RLE)建模关键点预测不确定性,优化解码流程,在保证实时性的同时,显著提升 keypoint 检测精度,适用于人体动作分析、机器人交互等场景。
8.OBB旋转目标检测:角度损失优化,旋转预测更稳定
引入角度损失函数,解决方形目标 orientation 模糊问题;优化OBB解码逻辑,避免旋转边界附近的角度突变,让倾斜目标的方向估计更稳定,适配航拍测绘、工业检测等场景。
YOLO26 相比较上一代YOLOv11区别:
与 YOLO11 相比,YOLO26 的主要改进是什么?
- DFL 移除:简化导出并扩展边缘兼容性
- 端到端无NMS推理: 消除NMS,实现更快、更简单的部署
- ProgLoss + STAL:提高准确性,尤其是在小物体上
- MuSGD Optimizer:结合 SGD 和 Muon(灵感来自 Moonshot 的 Kimi K2),实现更稳定、高效的训练
- CPU 推理速度提高高达 43%:CPU 设备的主要性能提升
YOLO26 支持的多种任务和多尺寸模型:
1. 支持多尺寸模型,适配多场景任务需求
YOLO26提供五种尺寸规格,从Nano(n)到Extra Large(x),开发者可根据部署设备的硬件限制,灵活平衡运行速度、检测精度与模型体积:
-
Nano(n):极致轻量化,专为低功耗边缘设备设计
-
Small(s)/Medium(m):兼顾速度与精度,适用于多数终端场景
-
Large(l)/Extra Large(x):高精度优先,满足复杂场景检测需求
每个尺寸变体(n、s、m、l、x)都支持所有任务。
2. YOLO26支持多种视觉任务
YOLO26以统一模型架构支撑多种计算机视觉任务,训练、验证、推理与导出流程高度统一,降低技术落地门槛:
-
图像分类:分析整图场景,精准匹配类别标签
-
目标检测:定位并识别图像/视频中的多个目标
-
实例分割:以像素级精度勾勒目标轮廓
-
姿态估计:识别人体及物体关键点,还原姿态信息
-
旋转边界框(OBB)检测:精准识别倾斜目标,适配航拍、卫星影像等场景
二、YOLO26的网络结构分析
YOLO26整体网络结构图
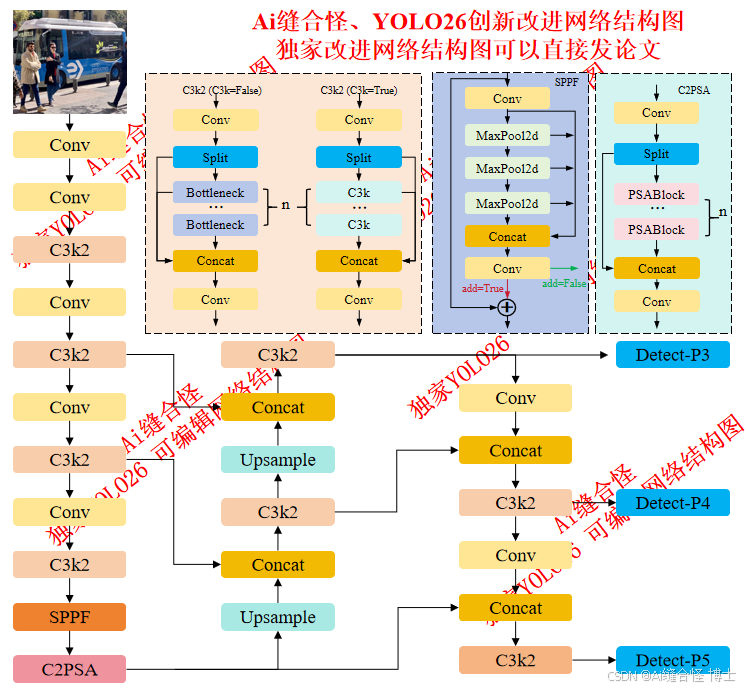
YOLO26整体网络结构主要由以下三个大部分组成:
Backbone:
Backbone部分负责特征提取,采用了一系列卷积和反卷积层,同时使用了残差连接和瓶颈结构来减小网络的大小并提高性能。YOLO26使用C3k2块来处理主干不同阶段的特征提取。较小的3×3内核允许更有效的计算,同时保留模型捕获图像中基本特征的能力。YOLO26主干的核心是C3k2块,它是早期版本中引入的CSP(跨阶段部分)瓶颈的演变。C3k2模块通过分割特征图并应用一系列较小的内核卷积(3×3)来优化网络中的信息流,这比较大的内核卷积更快,计算成本更低。通过处理较小的独立特征图并在几次卷积后合并它们,C3k2模块与YOLOv8的C2f模块相比,使用更少的参数来改进特征表示。
C2PSA块使用两个PSA(部分空间注意力)模块,它们在特征图的不同分支上操作,然后连接起来,类似于C2F块结构。这种设置确保模型专注于空间信息,同时保持计算成本和检测精度之间的平衡。C2PSA模块通过在提取的特征上应用空间注意力来细化模型选择性地关注感兴趣区域的能力。这使得YOLO26在精确检测需要精细对象细节的场景中优于YOLOv8等以前的版本。
此外,Backbone部分还包括一些常见的改进技术,如缝合一些卷积模块,注意力模块,替换主干网络等改进,以进一步增强特征提取的能力。后续会更新大量相关部分改进点。
Neck:
Neck颈部网络位于主干网络和头部网络之间,它的作用是进行特征融合和增强。后续会更新大量相关部分改进点。
Head :
Head头部网络是目标检测模型的决策部分,负责产生最终的检测结果。后续会更新大量相关部分改进点。
三、yolo26.yaml配置文件进行详细讲解
配置文件主要分为三个部分: 参数部分【Parameters】,主干部分【backone】,头部部分【head】。下面分别对这几个部分进行详细说明。
关于YOLO26网络的配置文件yolo26.yaml的详细内容如下:
# Ultralytics 🚀 AGPL-3.0 License – https://ultralytics.com/license
# Ultralytics YOLO26 object detection model with P3/8 – P5/32 outputs
# Model docs: https://docs.ultralytics.com/models/yolo26
# Task docs: https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 80 # number of classes
end2end: True # whether to use end-to-end mode
reg_max: 1 # DFL bins
scales: # model compound scaling constants, i.e. 'model=YOLO26n.yaml' will call YOLO26.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.50, 0.25, 1024] # summary: 260 layers, 2,572,280 parameters, 2,572,280 gradients, 6.1 GFLOPs
s: [0.50, 0.50, 1024] # summary: 260 layers, 10,009,784 parameters, 10,009,784 gradients, 22.8 GFLOPs
m: [0.50, 1.00, 512] # summary: 280 layers, 21,896,248 parameters, 21,896,248 gradients, 75.4 GFLOPs
l: [1.00, 1.00, 512] # summary: 392 layers, 26,299,704 parameters, 26,299,704 gradients, 93.8 GFLOPs
x: [1.00, 1.50, 512] # summary: 392 layers, 58,993,368 parameters, 58,993,368 gradients, 209.5 GFLOPs
# YOLO26n backbone
backbone:
# [from, repeats, module, args]
– [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
– [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
– [-1, 2, C3k2, [256, False, 0.25]]
– [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
– [-1, 2, C3k2, [512, False, 0.25]]
– [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
– [-1, 2, C3k2, [512, True]]
– [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
– [-1, 2, C3k2, [1024, True]]
– [-1, 1, SPPF, [1024, 5, 3, True]] # 9
– [-1, 2, C2PSA, [1024]] # 10
# YOLO26n head
head:
– [-1, 1, nn.Upsample, [None, 2, "nearest"]]
– [[-1, 6], 1, Concat, [1]] # cat backbone P4
– [-1, 2, C3k2, [512, True]] # 13
– [-1, 1, nn.Upsample, [None, 2, "nearest"]]
– [[-1, 4], 1, Concat, [1]] # cat backbone P3
– [-1, 2, C3k2, [256, True]] # 16 (P3/8-small)
– [-1, 1, Conv, [256, 3, 2]]
– [[-1, 13], 1, Concat, [1]] # cat head P4
– [-1, 2, C3k2, [512, True]] # 19 (P4/16-medium)
– [-1, 1, Conv, [512, 3, 2]]
– [[-1, 10], 1, Concat, [1]] # cat head P5
– [-1, 1, C3k2, [1024, True, 0.5, True]] # 22 (P5/32-large)
– [[16, 19, 22], 1, Detect, [nc]] # Detect(P3, P4, P5)
3.1 参数部分【Parameters】
# Parameters
nc: 80 # number of classes
end2end: True # whether to use end-to-end mode
reg_max: 1 # DFL bins
scales: # model compound scaling constants, i.e. 'model=YOLO26n.yaml' will call YOLO26.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.50, 0.25, 1024] # summary: 260 layers, 2,572,280 parameters, 2,572,280 gradients, 6.1 GFLOPs
s: [0.50, 0.50, 1024] # summary: 260 layers, 10,009,784 parameters, 10,009,784 gradients, 22.8 GFLOPs
m: [0.50, 1.00, 512] # summary: 280 layers, 21,896,248 parameters, 21,896,248 gradients, 75.4 GFLOPs
l: [1.00, 1.00, 512] # summary: 392 layers, 26,299,704 parameters, 26,299,704 gradients, 93.8 GFLOPs
x: [1.00, 1.50, 512] # summary: 392 layers, 58,993,368 parameters, 58,993,368 gradients, 209.5 GFLOPs
-
nc:80 是 COCO 数据集的默认类别数(包含人、车、动物、日常物品等 80 类),若用于自定义数据集,需修改为对应类别数(如仅检测行人则设为 1)。
-
end2end: True 。end2end 控制模型是否启用 “端到端” 推理模式。True:模型输出直接是最终的检测结果(坐标 + 置信度 + 类别),无需额外的非极大值抑制(NMS)后处理;False:模型输出原始预测张量,需在推理阶段手动执行 NMS 过滤重复框。
-
reg_max: 1。DFL 是 YOLO 系列用于提升框回归精度的方法,通过将坐标回归转化为 “分箱分类” 问题;YOLO26 此处设为 1,表示禁用 DFL(仅用普通回归)。
-
scales: 代表模型尺寸,分了n,s,m,l,x这5个不同大小的尺寸,参数量依次从小到大。
-
[depth, width, max_channels]: 分别表示网络模型的深度因子、网络模型的宽度因子、最大通道数。
-
depth深度因子的作用:表示模型中重复模块的数量或层数的缩放比例。这里主要用来调整C3k2模块中的子模块Bottleneck重复次数。比如主干中第一个C3k2模块的repeats系数是2,我们使用0.5×2并且向上取整就等于1了,这就代表第一个C3k2模块中Bottleneck只重复一次。
-
width宽度因子的作用:表示模型中通道数(即特征图的深度)的缩放比例,如果某个层原本有64个通道,而width设置为0.5,则该层的通道数变为32。举例:比如使用yolo26n.yaml文件,参数为[0.50, 0.25, 1024]。第一个Conv模块的输出通道数写的是64,但是实际上这个通道数并不是64,而是使用宽度因子 0.25×64得到的最终结果16;同理,C3k2模块的输出通道虽然在yaml文件上写的是256,但是在实际使用时依然要乘上宽度因子0.25,那么第一个C3k2模块最终的到实际通道数就是0.25×256 = 64。如下图所示,其他的依次类推。
-
max-channels: 表示每层最大通道数。每层的通道数会与这个参数进行一个对比,如果特征图通道数大于这个数,那就取 max_channels的值。
3.2 主干部分【backbone】
# YOLO26n backbone
backbone:
# [from, repeats, module, args]
– [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
– [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
– [-1, 2, C3k2, [256, False, 0.25]]
– [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
– [-1, 2, C3k2, [512, False, 0.25]]
– [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
– [-1, 2, C3k2, [512, True]]
– [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
– [-1, 2, C3k2, [1024, True]]
– [-1, 1, SPPF, [1024, 5, 3, True]] # 9
– [-1, 2, C2PSA, [1024]] # 10
主干部分有四个参数[from, number, module, args] ,解释如下:
-
from:这个参数代表从哪一层获得输入,-1就表示从上一层获得输入,[-1, 6]就表示从上一层和第6层这两层获得输入。第一层比较特殊,这里第一层上一层 没有输入,from默认-1就好了。
-
repeats:这个参数表示模块重复的次数,如果为2则表示该模块重复2次,这里并不一定是这个模块的重复次数,也有可能是这个模块中的子模块重复的次数。对于C3k2模块来说,这个repeats就代表C3k2中Bottelneck或是C3k模块重复的次数。
-
module:这个就代表你这层使用的模块的名称,比如你第一层使用了Conv模块,第三层使用了C3k2模块。
-
args:表示这个模块需要传入的参数,第一个参数均表示该层的输出通道数。对于第一层conv参数【64,3,2】:64代表输出通道数,3代表卷积核大小k,2代表stride步长。每层输入通道数,默认是上一层的输出通道数。
其他说明:各层注释中的P1/2表示该层特征图缩放为输入图像尺寸的1/2,是第1特征层;P2/4表示该层特征图缩放为输入图像尺寸的1/4,是第2特征层;其他的依次类推。
3.3 头部【head】
# YOLO26n head
head:
– [-1, 1, nn.Upsample, [None, 2, "nearest"]]
– [[-1, 6], 1, Concat, [1]] # cat backbone P4
– [-1, 2, C3k2, [512, True]] # 13
– [-1, 1, nn.Upsample, [None, 2, "nearest"]]
– [[-1, 4], 1, Concat, [1]] # cat backbone P3
– [-1, 2, C3k2, [256, True]] # 16 (P3/8-small)
– [-1, 1, Conv, [256, 3, 2]]
– [[-1, 13], 1, Concat, [1]] # cat head P4
– [-1, 2, C3k2, [512, True]] # 19 (P4/16-medium)
– [-1, 1, Conv, [512, 3, 2]]
– [[-1, 10], 1, Concat, [1]] # cat head P5
– [-1, 1, C3k2, [1024, True, 0.5, True]] # 22 (P5/32-large)
– [[16, 19, 22], 1, Detect, [nc]] # Detect(P3, P4, P5)
头部分有四个参数[from, number, module, args] ,解释如下:
-
from:这个参数代表从哪一层获得输入,-1就表示从上一层获得输入,[-1, 6]就表示从上一层和第6层这两层获得输入。第一层比较特殊,这里第一层上一层 没有输入,from默认-1就好了。
-
repeats:这个参数表示模块重复的次数,如果为2则表示该模块重复2次,这里并不一定是这个模块的重复次数,也有可能是这个模块中的子模块重复的次数。对于C3k2模块来说,这个repeats就代表C3k2中Bottelneck或是C3k模块重复的次数。
-
module:这个就代表你这层使用的模块的名称,比如你第一层使用了Conv模块,第三层使用了C3k2模块。
-
args:表示这个模块需要传入的参数,第一个参数均表示该层的输出通道数。对于第一层Conv参数[64,3,2]:64代表输出通道数,3代表卷积核大小k,2代表stride步长。每层输入通道数,默认是上一层的输出通道数。
-
nn.Upsample: 表示上采样,将特征图大小进行翻倍操作。比如将大小为20X20的特征图,变为40X40的特征图大小。
-
Concat:代表拼接操作,将相同大小的特征图,通道进行拼接,要求是特征图大小一致,通道数可以不相同。例如[-1, 6]:-1代表上一层,6代表第六层(从第0层开始数),将上一层与第6层进行concat拼接操作。
-
Detect的from有三个数: [16,19,22],这三个就是最终网络的输出特征图,分别对应P3,P4,P5。
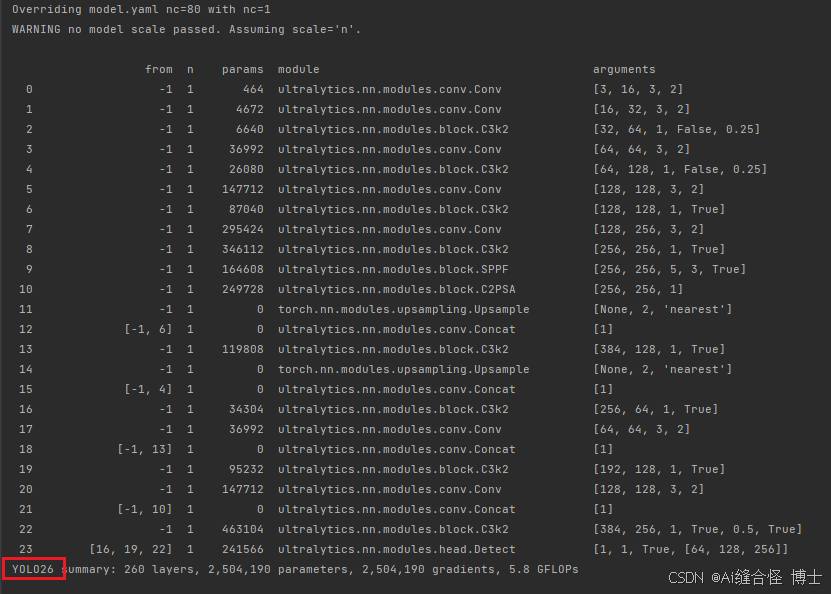
模型训练时打印出的结构参数如下,下图为yolo26.yaml打印信息:
四、YOLO26虚拟环境配置
创健YOLO26的虚拟环境:
首先下载YOLO26项目源码,点击链接即可跳转
YOLO26官方源码链接,点击即可跳转!
# 在终端使用如下命令安装YOLO26的虚拟环境
# 第一步创建一个自己的虚拟环境:
conda create -n yolo26 python=3.10
# 第二步进入到自己的虚拟环境:
conda activate yolo26
# 第三步安装项目需要的torch库:我安装的是这个版本,不建议安装高版本或是最新版本
pip install torch==2.5.1 torchvision==0.20.1 torchaudio==2.5.1 –index-url https://download.pytorch.org/whl/cu121
# 第四步安装项目需要的包:
pip install ultralytics
YOLO26官方源码链接,点击即可跳转!
提示!如果之前订阅过我项目的小伙伴,之前的环境是可以直接运行yolo26。如果订阅专栏的小伙伴,不会创建虚拟环境,可以咨询博主,提供Windows系统下的环境包。如果不会配置环境,也可以远程控制帮忙配置环境几分钟就可以配好去跑实验。
五、YOLO26模型训练参数详细解析
关于yolo26的训练参数该如何设置。接下来对yolo26的相关训练参数和使用方法进行了详细说明。希望对大家有所帮助!
5.1 YOLO26模型训练代码
YOLO26目标检测模型训练时使用的代码如下:
from ultralytics import YOLO
# 加载官方预训练模型
model = YOLO("yolo26n.pt",task="detect")
# 模型训练
results = model.train(data="data.yaml", epochs=100, batch=4)
YOLO26图像分割模型训练时使用的代码如下:
from ultralytics import YOLO
# 加载官方预训练模型
model = YOLO("yolo26n.pt",task="segment")
# 模型训练
results = model.train(data="data.yaml", epochs=100, batch=4)
YOLO26模型训练脚本train.py代码如下:
import warnings
warnings.filterwarnings('ignore')
from ultralytics import YOLO
# 模型配置文件
model_yaml_path = r"./ultralytics/cfg/models/26/yolo26.yaml" # 创建一个 YOLO 模型实例,加载 yolo26.yaml 配置文件(Nano 版本)
#数据集配置文件
data_yaml_path = r'./datasets/data.yaml' # 指定数据集的配置文件,这里使用的是 data.yaml 配置文件
if __name__ == '__main__':
model = YOLO(model_yaml_path,task="detect")
model = model
#训练模型
results = model.train(data=data_yaml_path, # 指定数据集的配置文件
imgsz=640, # 输入图像的尺寸,所有输入图像将被缩放到 640×640 像素
epochs=500, # 训练的轮数,模型将训练 500 个周期
batch=8, # 每次训练的批次大小,每次训练会用到 8 张图像
# amp=False, # 如果出现训练损失为Nan可以关闭amp
device="0", # device="0,1,2,3"训练时使用的 GPU 设备编号,这里使用编号为 0、1、2 和 3 的四个 GPU 进行训练。通常设置为0
project='runs/26train', # 保存训练结果文件夹
name='exp',
)
5.2 YOLO26模型验证代码
自己创建一个val.py脚本文件,把代码粘贴进去就好了:
from ultralytics import YOLO
import warnings
warnings.filterwarnings('ignore')
# 模型配置文件
model_yaml_path = r"./runs/26train/exp/weights/best.pt"
#数据集配置文件
data_yaml_path = r'./datasets/data.yaml'
if __name__ == '__main__':
model = YOLO(model_yaml_path)
model.val(data=data_yaml_path,
split='val',
imgsz=640,
batch=8,
project='runs/val',
name='exp',
save_json = True
)
5.3 YOLO26模型推理代码
自己创建一个predict.py脚本文件,把代码粘贴进去就好了:
import warnings
warnings.filterwarnings('ignore')
from ultralytics import YOLO
if __name__ == '__main__':
model = YOLO(r'./yolo26n.pt') # 使用自己训练好的权重文件
model.predict(
source=r'./ultralytics/assets/bus.jpg', # 预测的数据源,可以是图片、文件夹、视频路径等
imgsz=640, # 图片的输入尺寸
project='runs/detect', # 预测结果保存的项目目录
name='exp', # 子目录名(最终保存路径为 runs/detect/exp)
save=True, # 是否保存预测后的图片
# visualize=True, # 是否可视化中间特征图(默认注释掉,即不启用)
# show_conf=False, # 是否显示置信度(关闭显示)
# show_labels=False, # 是否显示标签(关闭显示)
)
5.4模型大小选择
model = YOLO("yolo26n.pt") 表示使用的是yolov26n模型来训练, 因为我们自己需要改进创新发论文,通常都不会使用这种训练好的模型继续训练,可以选择性的加载官方模型的预训练权重,如果改动比较大建议大家自己重新训练。如果想使用其他大小的模型,只需要把n改为其他大小的对应字母即可。例如:
model = YOLO("yolo26n.pt")
model = YOLO("yolo26s.pt")
model = YOLO("yolo26m.pt")
model = YOLO("yolo26l.pt")
model = YOLO("yolo26x.pt")
加载官方预训练权重去训练方法:
import warnings
warnings.filterwarnings('ignore')
from ultralytics import YOLO
# 模型配置文件
model_yaml_path = r"./ultralytics/cfg/models/26/yolo26.yaml" # 创建一个 YOLO 模型实例,加载 yolo26.yaml 配置文件(Nano 版本)
#数据集配置文件
data_yaml_path = r'./datasets/data.yaml' # 指定数据集的配置文件,这里使用的是 data.yaml 配置文件
if __name__ == '__main__':
model = YOLO(model_yaml_path)
model.load("yolo26n.pt") # 加载预训练权重
#训练模型
results = model.train(data=data_yaml_path, # 指定数据集的配置文件
imgsz=640, # 输入图像的尺寸,所有输入图像将被缩放到 640×640 像素
epochs=500, # 训练的轮数,模型将训练 500 个周期
batch=8, # 每次训练的批次大小,每次训练会用到 8 张图像
# amp=False, # 如果出现训练损失为Nan可以关闭amp
device="0", # device="0,1,2,3"训练时使用的 GPU 设备编号,这里使用编号为 0、1、2 和 3 的四个 GPU 进行训练。通常设置为0
project='runs/26train', # 保存训练结果文件夹
name='exp',
)
YOLO26不同模型参数大小如下:
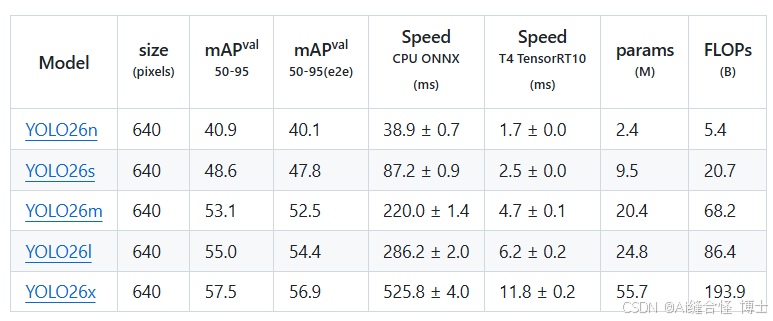
n是参数量最小的模型。一般情况下,模型越大,最终模型的性能效果也会越好。可根据自己实际需求选择相应的模型大小进行训练。
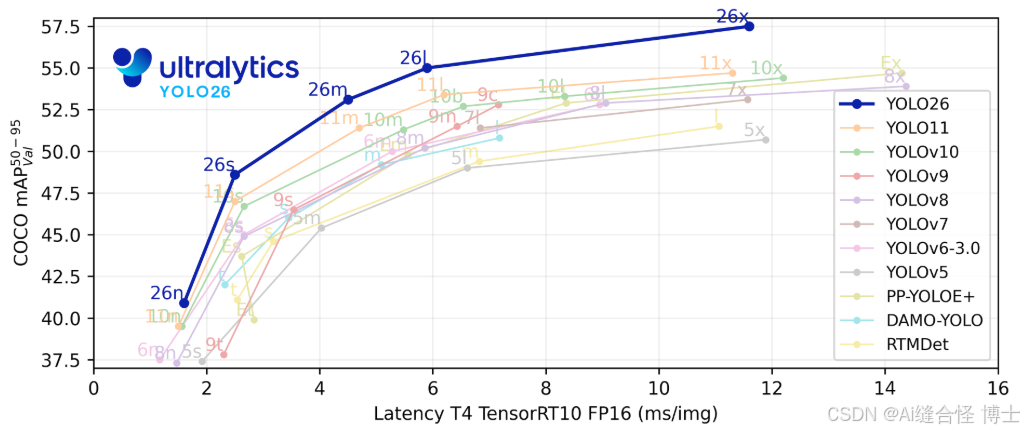
5.5 训练参数设置
通过运行model.train(data="data.yaml", epochs=100, batch=4)训练YOLO26模型,其中(data="data.yaml", epochs=100, batch=4)是训练设置的参数,没有添加的训练参数都是使用的默认值。官方其实给出了很多其他相关参数,详细说明见下文。
如果我们需要自己修改其他训练参数,只需要在train后面的括号中加入相应的参数和具体值即可。
例如加上模型训练优化器参数optimizer,其默认值是auto。
可设置的值为:SGD, Adam, AdamW, NAdam, RAdam, RMSProp。常用SGD或者AdamW。
我们可以直接将其设置为SGD,写法如下:
# 模型训练,添加模型优化器设置
results = model.train(data="data.yaml", epochs=100, batch=4, optimizer='SGD')
5.6 训练参数说明
YOLO26 模型的训练设置包括训练过程中使用的各种超参数和配置。这些设置会影响模型的性能、速度和准确性。关键的训练设置包括批量大小、学习率、动量和权重衰减。此外,优化器、损失函数和训练数据集组成的选择也会影响训练过程。对这些设置进行仔细的调整和实验对于优化性能至关重要。以下是官方给出了训练可设置参数和说明:
| model | None | 指定用于训练的模型文件。接受指向 .pt 预训练模型或 .yaml 配置文件。对于定义模型结构或初始化权重至关重要。 |
| data | None | 数据集配置文件的路径(例如 coco8.yaml).该文件包含特定于数据集的参数,包括训练数据和验证数据的路径、类名和类数。 |
| epochs | 100 | 训练总轮数。每个epoch代表对整个数据集进行一次完整的训练。调整该值会影响训练时间和模型性能。 |
| time | None | 最长训练时间(小时)。如果设置了该值,则会覆盖 epochs 参数,允许训练在指定的持续时间后自动停止。对于时间有限的训练场景非常有用。 |
| patience | 100 | 在验证指标没有改善的情况下,提前停止训练所需的epoch数。当性能趋于平稳时停止训练,有助于防止过度拟合。 |
| batch | 16 | 批量大小,有三种模式:设置为整数(例如,' Batch =16 '), 60% GPU内存利用率的自动模式(' Batch =-1 '),或指定利用率分数的自动模式(' Batch =0.70 ')。 |
| imgsz | 640 | 用于训练的目标图像尺寸。所有图像在输入模型前都会被调整到这一尺寸。影响模型精度和计算复杂度。 |
| save | True | 可保存训练检查点和最终模型权重。这对恢复训练或模型部署非常有用。 |
| save_period | -1 | 保存模型检查点的频率,以 epochs 为单位。值为-1 时将禁用此功能。该功能适用于在长时间训练过程中保存临时模型。 |
| cache | False | 在内存中缓存数据集图像 (True/ram)、磁盘 (disk),或禁用它 (False).通过减少磁盘 I/O 提高训练速度,但代价是增加内存使用量。 |
| device | None | 指定用于训练的计算设备:单个 GPU (device=0)、多个 GPU (device=0,1)、CPU (device=cpu),或苹果芯片的 MPS (device=mps). |
| workers | 8 | 加载数据的工作线程数(每 RANK 多 GPU 训练)。影响数据预处理和输入模型的速度,尤其适用于多 GPU 设置。 |
| project | None | 保存训练结果的项目目录名称。允许有组织地存储不同的实验。 |
| name | None | 训练运行的名称。用于在项目文件夹内创建一个子目录,用于存储训练日志和输出结果。 |
| exist_ok | False | 如果为 True,则允许覆盖现有的项目/名称目录。这对迭代实验非常有用,无需手动清除之前的输出。 |
| pretrained | True | 决定是否从预处理模型开始训练。可以是布尔值,也可以是加载权重的特定模型的字符串路径。提高训练效率和模型性能。 |
| optimizer | 'auto' | 为训练模型选择优化器。选项包括 SGD, Adam, AdamW, NAdam, RAdam, RMSProp 等,或 auto 用于根据模型配置进行自动选择。影响收敛速度和稳定性 |
| verbose | False | 在训练过程中启用冗长输出,提供详细日志和进度更新。有助于调试和密切监控培训过程。 |
| seed | 0 | 为训练设置随机种子,确保在相同配置下运行的结果具有可重复性。 |
| deterministic | True | 强制使用确定性算法,确保可重复性,但由于对非确定性算法的限制,可能会影响性能和速度。 |
| single_cls | False | 在训练过程中将多类数据集中的所有类别视为单一类别。适用于二元分类任务,或侧重于对象的存在而非分类。 |
| rect | False | 可进行矩形训练,优化批次组成以减少填充。这可以提高效率和速度,但可能会影响模型的准确性。 |
| cos_lr | False | 利用余弦学习率调度器,根据历时的余弦曲线调整学习率。这有助于管理学习率,实现更好的收敛。 |
| close_mosaic | 10 | 在训练完成前禁用最后 N 个epoch的马赛克数据增强以稳定训练。设置为 0 则禁用此功能。 |
| resume | False | 从上次保存的检查点恢复训练。自动加载模型权重、优化器状态和历时计数,无缝继续训练。 |
| amp | True | 启用自动混合精度 (AMP) 训练,可减少内存使用量并加快训练速度,同时将对精度的影响降至最低。 |
| fraction | 1.0 | 指定用于训练的数据集的部分。允许在完整数据集的子集上进行训练,这对实验或资源有限的情况非常有用。 |
| profile | False | 在训练过程中,可对ONNX 和TensorRT 速度进行剖析,有助于优化模型部署。 |
| freeze | None | 冻结模型的前 N 层或按索引指定的层,从而减少可训练参数的数量。这对微调或迁移学习非常有用。 |
| lr0 | 0.01 | 初始学习率(即 SGD=1E-2, Adam=1E-3) .调整这个值对优化过程至关重要,会影响模型权重的更新速度。 |
| lrf | 0.01 | 最终学习率占初始学习率的百分比 = (lr0 * lrf),与调度程序结合使用,随着时间的推移调整学习率。 |
| momentum | 0.937 | 用于 SGD 的动量因子,或用于 Adam 优化器的 beta1,用于将过去的梯度纳入当前更新。 |
| weight_decay | 0.0005 | L2 正则化项,对大权重进行惩罚,以防止过度拟合。 |
| warmup_epochs | 3.0 | 学习率预热的历元数,学习率从低值逐渐增加到初始学习率,以在早期稳定训练。 |
| warmup_momentum | 0.8 | 热身阶段的初始动力,在热身期间逐渐调整到设定动力。 |
| warmup_bias_lr | 0.1 | 热身阶段的偏置参数学习率,有助于稳定初始历元的模型训练。 |
| box | 7.5 | 损失函数中边框损失部分的权重,影响对准确预测边框坐标的重视程度。 |
| cls | 0.5 | 分类损失在总损失函数中的权重,影响正确分类预测相对于其他部分的重要性。 |
| dfl | 1.5 | 分布焦点损失权重,在某些YOLO 版本中用于精细分类。 |
| pose | 12.0 | 姿态损失在姿态估计模型中的权重,影响着准确预测姿态关键点的重点。 |
| kobj | 2.0 | 姿态估计模型中关键点对象性损失的权重,平衡检测可信度与姿态精度。 |
| label_smoothing | 0.0 | 应用标签平滑,将硬标签软化为目标标签和标签均匀分布的混合标签,可以提高泛化效果。 |
| nbs | 64 | 用于损耗正常化的标称批量大小。 |
| overlap_mask | True | 决定在训练过程中分割掩码是否应该重叠,适用于实例分割任务。 |
| mask_ratio | 4 | 分割掩码的下采样率,影响训练时使用的掩码分辨率。 |
| dropout | 0.0 | 分类任务中正则化的丢弃率,通过在训练过程中随机省略单元来防止过拟合。 |
| val | True | 可在训练过程中进行验证,以便在单独的数据集上对模型性能进行定期评估。 |
| plots | False | 生成并保存训练和验证指标图以及预测示例图,以便直观地了解模型性能和学习进度。 |
常用的几个训练参数是: 数据集配置文件data、训练轮数epochs、训练批次大小batch、训练使用的设备device,模型优化器optimizer、初始学习率lr0。
以上便是关于YOLO26模型详细说明,看到这里的小伙伴,相信你一定对yolo26模型有了一定的认识啦。
在Visdrone2019数据集上推理预测示例:

生成YOLO26可视化热力图示例:

六、本文总结
到此本文的正式分享内容就结束了,在这里给大家推荐我的YOLO26改进有效涨点专栏,本专栏后期我会根据2026、2025、2024近几年各种最新的前沿顶会顶刊论文复现,也会对一些老的改进机制进行补充,本专栏会持续至少更新1000+创新改进点,限时享优惠,大家尽早关注有效涨点专栏,带着大家快速高效发论文!如果大家觉得本文能帮助到你了,订阅本专栏,关注后续更多的更新~




评论前必须登录!
注册