 网硕互联帮助中心
网硕互联帮助中心一、语法
代码执行是严格从上到下的顺序,缩进规则极其严格,开头的空格数量不能随意增减,因为空格在Python中代表代码逻辑层级,多一个或少一个空格都会导致程序无法运行。
1.1输出函数print()
print()输出函数和input()输入函数是两个最基础的函数。这两个函数分别负责信息的输出和接收,是编程中最常用的基础功能。
(1)当参数是字符串时,比如用单引号或双引号包裹的内容,print会原样输出。这里要特别注意,代码中的符号必须是英文格式,比如引号、括号等,中文符号会报错。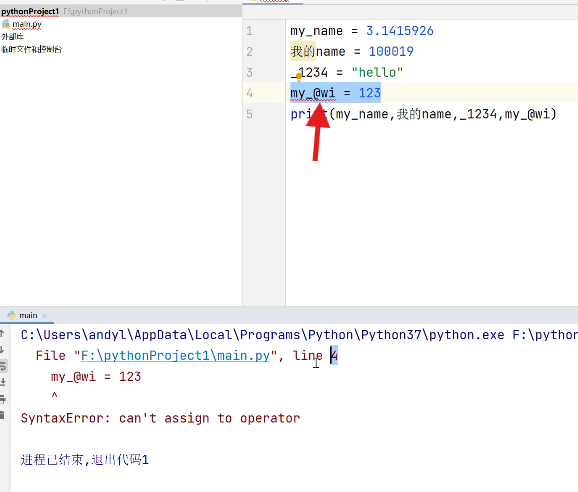
(2)参数为变量名的情况,比如a=3、b=15、c=a+b,此时print(c)会输出变量c的值18。print函数会先计算变量内容再输出。
(3)参数为表达式时,比如a+b-7,print会先计算表达式结果(这里是11)再输出。核心规律是:print总会先计算括号内的内容(无论是变量、表达式还是其他),再输出最终结果。
(4)参数为多个参数时,参数间会自动添加空格分隔。比如print(a, b)会把变量a和b的值用空格隔开输出。
(5)输出末尾设置end参数,它默认值是\\n(换行符),所以每次print输出后会自动换行。如果想改变输出后的行为,比如让内容不换行或在末尾加其他字符,可以修改end参数的值。连接输出通过设置end='##',可以让两个print语句的输出用"##"连接起来;若设为end=''(空字符串),则直接拼接输出内容。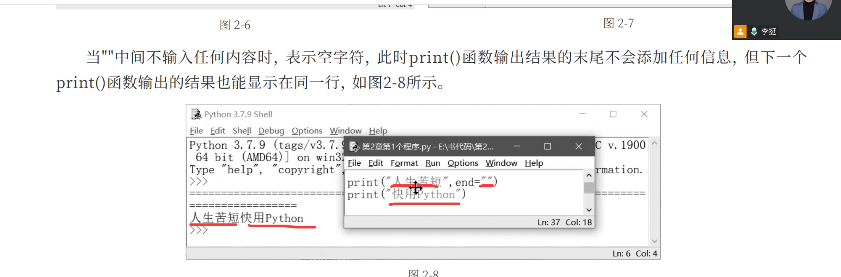
(6)参数为函数:先计算函数的结果,再将函数结果输出。其中dir(__builtins__)能列出当前Python环境中所有可用的内置函数。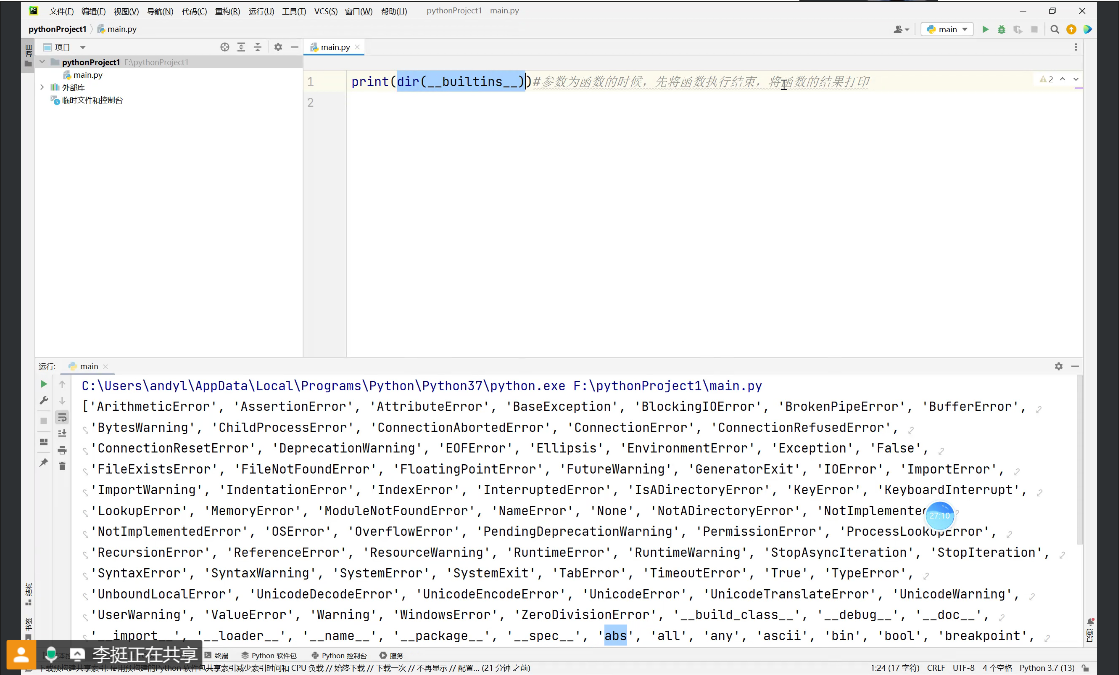
1.2输入函数input()
与print函数相反,是用来接收用户输入信息的。比如需要获取用户性别、年龄等信息时就要用到它。input函数的基本用法很简单:直接写input(),括号里可以加上提示信息,比如input("请输入账号:")。这时程序会暂停,等待用户输入内容。提示信息会显示在终端上引导用户正确输入。通过input()函数获取的用户输入,无论输入数字还是文字,返回的都是字符串类型。
1.3元素的命名
(1)只能用字母(a-z/A-Z)、数字(0-9)、下划线或汉字来组合命名。特别注意,像@、$、%这些符号都是绝对不允许出现的,系统会直接报错提示语法错误。
(2)变量名不能以数字开头,比如"3myname"会直接报错。
(3)变量名不能和保留字相同,保留字是python内已被使用的具有特定功能的名称,如false、if等。比如写"False=11"就会报错。
(4)变量名最好别用Python内置函数名(比如list/dict等),虽然语法允许,但容易引发混淆。例如把内置函数名(如print)用作变量名是允许的,但这样做会覆盖原有函数功能。比如先写print=10,再写print(1+1)就会报错——因为此时print已经变成普通变量,不再是函数了。虽然Python允许这种操作,但会导致内置函数失效,所以编程时要避免使用内置函数名作为变量名。这种错误不会立即显现,而是在后续调用被覆盖的函数时才暴露,属于典型的"埋雷"行为。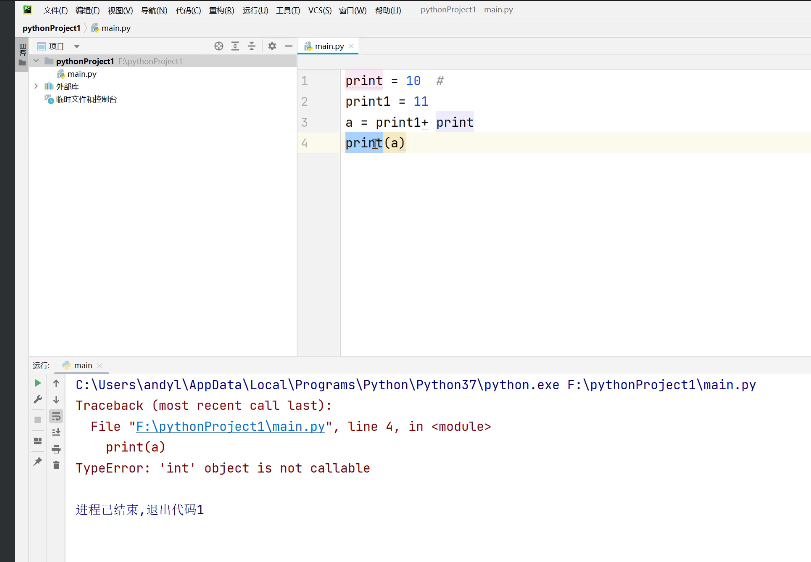
1.4赋值语句
(1)Python严格区分大小写,所以大写的ELSE和小写的else是不同的标识符,不会冲突。变量名不能与关键字完全相同,但通过大小写变化可以绕过这一限制。
(2)关于变量值的覆盖:当给变量先后赋不同的值时,后赋的值会完全覆盖之前的值,就像内存中的存储空间被新内容替换一样。
(3)多重赋值的用法:可以用a,b,c,d = 10,12,13,15这样的形式,同时给多个变量赋值,数值会按顺序对应分配给各个变量。
二、基本数据类型
每种数据类型都有专属的操作方法,比如数值型擅长加减乘除,字符串型专精连接和切片操作,而矩阵则侧重求逆等运算。
基本数据类型就两种:数值类型和字符串类型。
2.1数值型
1)整型(如123);
2)浮点型(带小数点的数);
3)复数(AI领域很少用,主要在机械/电学等领域)。重点掌握前两种就行。
整型的运算很直观,支持加减乘除、整除、取余、幂运算等基础操作。就像小学数学里的整数计算,只是现在要用代码表达出来。
增强赋值运算符是基础运算符和赋值语句的结合体。比如a += 3完全等价于a = a + 3,这种写法不仅更简洁,还能提高代码效率。常见的增强赋值运算符包括+=、-=、*=、/=、//=、%=和**=。
2.2字符串
字符串索引:从左往右从0开始计数,从右往左是从-1开始计数。用索引可以获取字符串中的字符,如a='python',a[2]='t'。获取多个字符切片,要使用两个参数。如a[2:5]='tho',切片只包含左边的索引的字符,不包含右边索引。
其实使用两个参数包含了第三个参数,只不过默认步长(第三个参数)为1。当尝试用[-1:-6]反向切片时,由于默认步长是1(从左往右),导致无法获取有效结果。解决方法是显式设置步长为-1,即写成[-1:-6:-1],这样就能实现从右往左的切片。
[起始:结束:步长],其中步长决定了切片方向,正数从左往右,负数从右往左。
 字符串操作:连接用简单的(+)就可以连接两个字符串,如a='python'+'人工智能'。字符串复制可以用(*)来解决,如a='python'*倍数
字符串操作:连接用简单的(+)就可以连接两个字符串,如a='python'+'人工智能'。字符串复制可以用(*)来解决,如a='python'*倍数
字符串函数:len(参数)用来获取字符串长度,如len(a)。
字符串方法:
(1)count()方法:用来统计字符串中某个子串出现的次数。比如代码a.count("3500")会在字符串a中查找"3500"出现的次数,示例中返回结果是3,说明"3500"出现了三次。
(2)replace()方法:用于替换字符串中的内容,参数一是要被替换的子串,参数二是新内容。比如a.replace("3500","4000")会把所有"3500"替换成"4000"。
(3)strip()方法:专门处理字符串开头和结尾的字符,比如去掉开头和结尾的"#"号。strip只处理首尾字符,如果字符串中间有相同字符不会被删除。另外,字符串末尾的空格也会被strip默认清除。带参数时会删除字符串开头指定的内容,不带参数则默认删除首尾的空格、换行符和制表符等空白字符。
(4)split():能按指定分隔符把字符串拆分成列表。比如用"#"分隔字符串"a#b#c",就会得到['a','b','c']这个列表。
(5)join()方法:会在每个字符之间插入指定字符串。比如用"-"连接列表元素,就能把['a','b']变成"a-b"。这些方法组合使用可以灵活处理各种字符串操作需求。
(6)format方法:"字符{}字符{}…".format(参数1,参数2)
带花括号的引号内容仍是字符串,不是字典。这些花括号是"槽位",会被format()方法的参数依次填充。比如第一个参数会替换第一个花括号,第二个参数替换第二个,以此类推。
转义字符:就是那些会改变原本含义的特殊字符,比如键盘上的制表符(Tab键)、换行符、引号等。这些字符在字符串中无法直接显示,需要用反斜杠(\\)加特定字母来表示。比如"\\n"代表换行,"\\t"代表制表符(相当于多个空格)。在文件路径中使用反斜杠时要小心,因为像"\\U"这样的组合会被当作转义字符处理,可能导致路径错误,因此要在路径前加上r表示路径。
2.3数据类型检测
处理数据前要先明确类型,用type()函数可以快速判断。比如字符串会返回class 'str',整数返回class 'int',浮点数则是class 'float'。
强制类型转换:常用的转换函数包括:
- int():把数据转为整数(如字符串"31415"→整数31415)
- float():转为浮点数
- str():转为字符串
字符串类型转换有个需要注意的点:如果一个字符串看起来像浮点数(比如"3.14"),你不能直接把它转成整数(int)。必须分两步走:先转成浮点数(float),再转成整数。
多行字符串处理:当文本包含多个段落时,直接写成字符串可能会遇到格式问题。就像你看到的,颜色显示都不对,这说明系统没正确识别这种多行结构。需要特殊处理才能保持原有段落格式。单引号或双引号只能包裹单行字符串,遇到多行内容时就会失效。这时候应该改用三引号(三个单引号或双引号)来包裹多行字符串,这样就能正确识别换行位置。注释是完全不会被执行的说明文字,而三引号字符串是真实存在的字符串对象,只是没被使用而已。当遇到特别长的代码行时,可以用反斜杠(\\)来换行拆分,这样既保持代码功能不变,又能提升可读性。

三、程序控制语句
3.1条件判断语句
(1)if语句:缩进非常重要,通常用四个空格来表示代码块,缩进的代码都属于if语句的执行部分。缩进决定了代码的逻辑结构,多行代码的缩进表示它们都属于同一个条件判断块。
条件判断有七种常见形式,比如用双等号(==)判断是否相等,返回True或False。还有大于(>)、大于等于(>=)等比较运算符。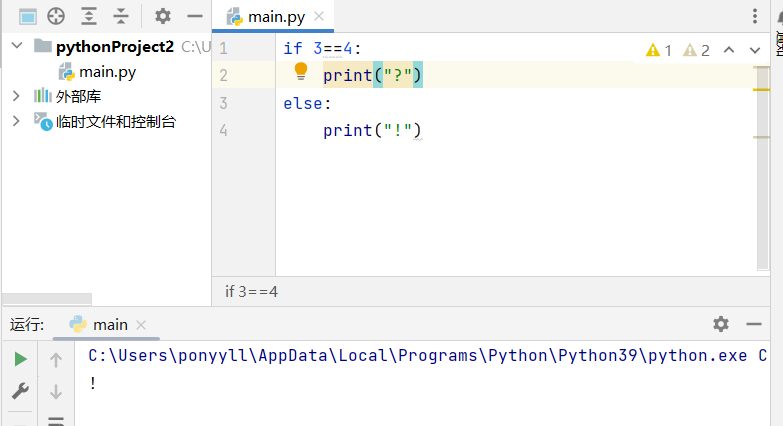
当条件表达式是a*2这样的计算时,只要结果不是0或None,就视为True,触发条件执行,只有结果为0或None才会跳过后续代码。
(2)if-else条件语句:条件判断后跟一个代码块,如果条件为true就执行这个代码块,否则执行else后面的代码块。
(3)if-elif-else的形式:处理多个条件时可用。它会按顺序检查每个条件,第一个满足的就执行对应的代码块,不满足就进行下一次判断elif,都不满足就执行else部分。
(4)"与(and)"运算、"或(or)"运算:and表示前后条件要同时满足才为True,or表示前后条件满足一个就为True。在多个条件判断时,要用括号标明哪些条件先进行运算。
(5)if-else的简洁写法:表达式1 if 条件 else 表达式2。这种单行写法相当于把常规的if-else结构压缩成一行,先判断条件,为真则返回表达式1,否则返回表达式2。就像例子中比较a和b的大小,可以直接写成a if a>b else b来获取较大值。
3.2循环语句
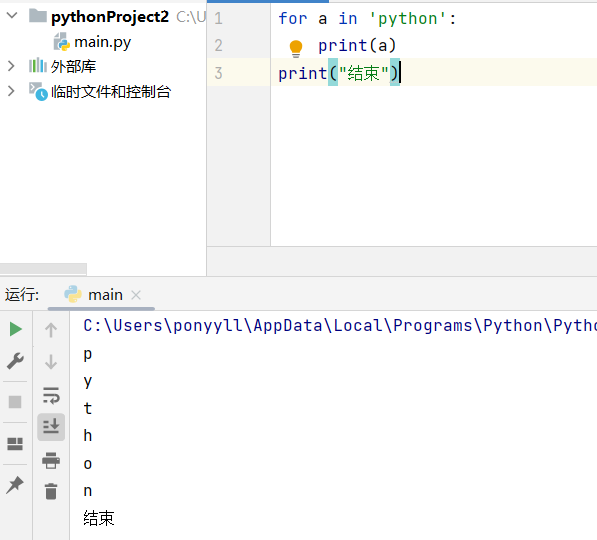
(1)for循环:"for 变量 in 循环内容:",后面跟带缩进的代码块。
循环次数完全由循环内容的数量决定,比如有几个元素就会循环几次,每次循环都会自动将当前元素赋值给循环变量。
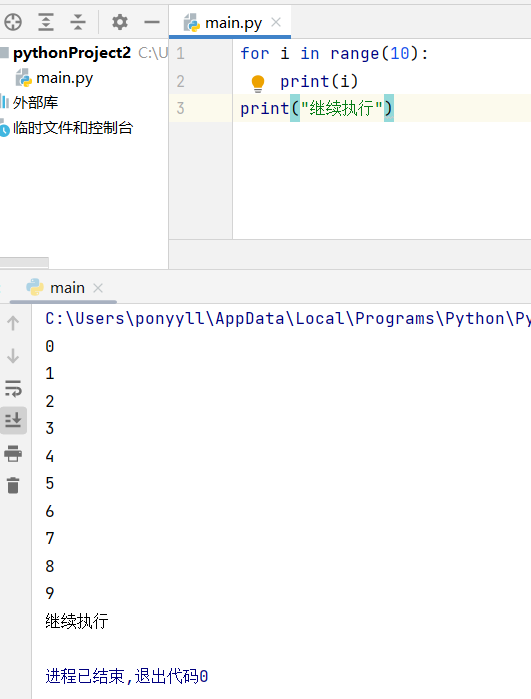
range函数解决了数字循环的问题。因为数字不像字符串那样可以拆分成单个字符,所以需要range函数来生成一个可迭代的数字序列。比如想循环n次,用range(n)就能生成0到n-1的序列供循环使用。
range函数不仅能生成简单的数字序列,还能通过参数控制范围和步长:
- 单参数(如range(1000)):生成从0到999的序列
- 双参数(如range(4,8)):生成从4到7(不包含8)的序列
- 三参数(如range(4,8,2)):从4开始,步长为2,生成4和6(跳过5和7)
for循环复合写法:B = [a*2 for a in range(5)]这行代码其实等效于:先创建一个空列表B,然后用for循环遍历range(5),每次循环把a*2的结果用append()方法添加到列表B中。执行后得到的B列表会包含[0,2,4,6,8]这些元素。
(2)while循环:只要条件满足(如4>=3为True),就会反复执行代码块,执行完又返回检查条件。关键点在于这个循环会持续到条件不满足为止,如果条件永远为真(比如4>=3),就会陷入死循环。
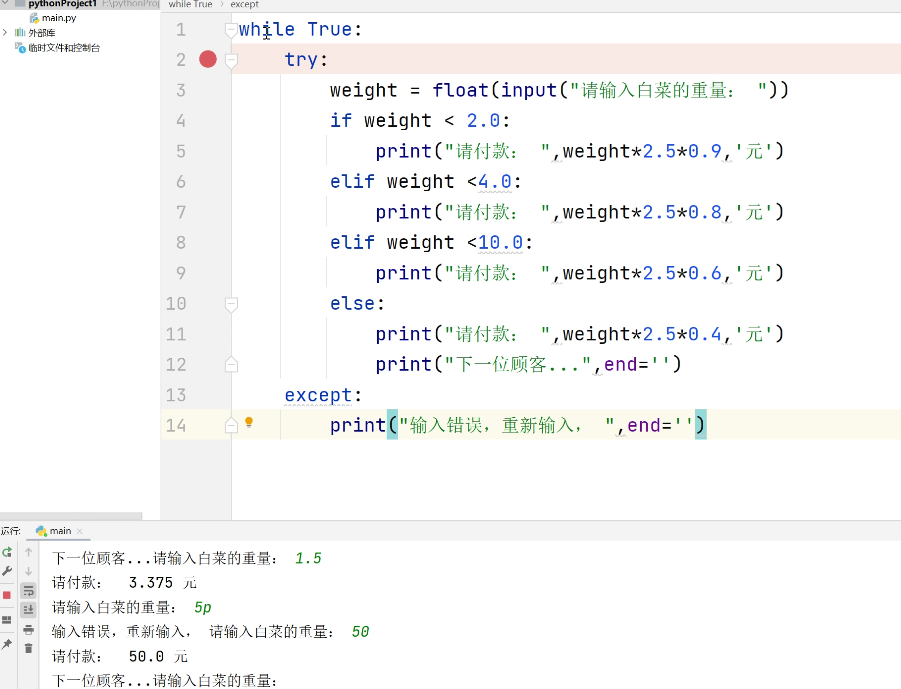
(3)嵌套循环:缩进决定了代码块的归属。外层循环的每次迭代,必须完整执行内层循环的所有内容后,外层循环的变量才会更新。
(4)break、continue关键字的作用:break一旦满足条件是直接终止整个循环,而continue只是跳过当前这次循环,相当于"这轮我先不玩了",但循环还会继续下一轮。
3.3异常处理语句
当我们用input()接收用户输入并强制转为整数时,如果用户不小心输入了字母程序就会报错ValueError(值错误)。
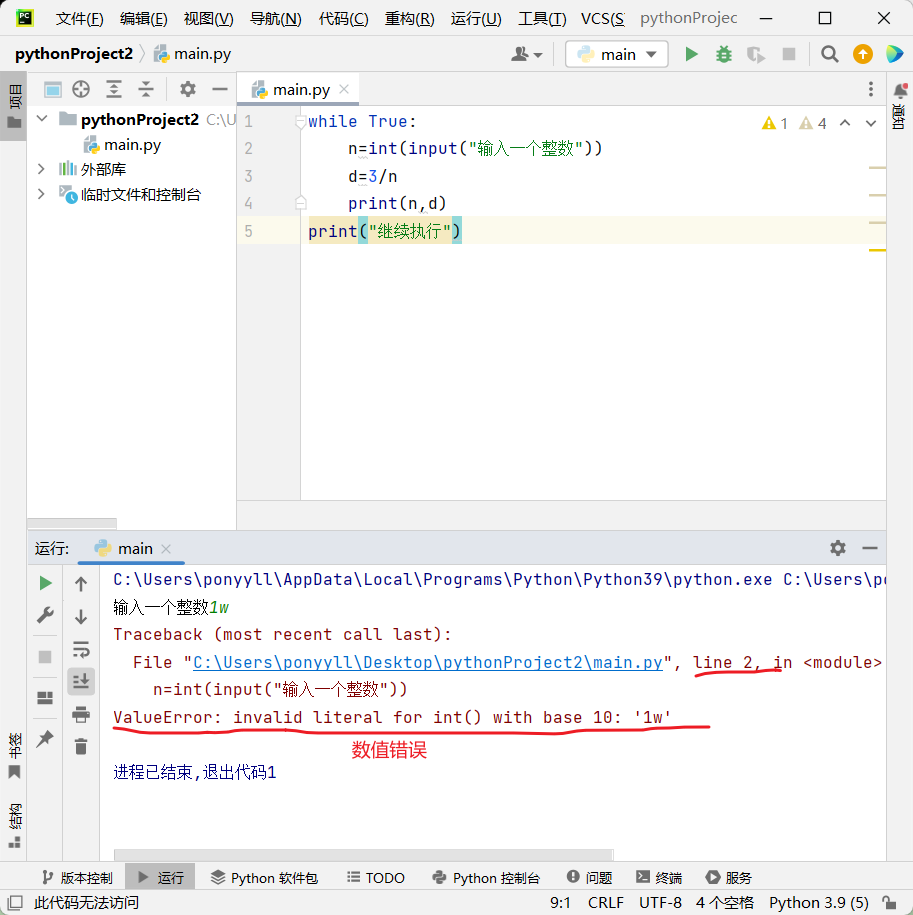
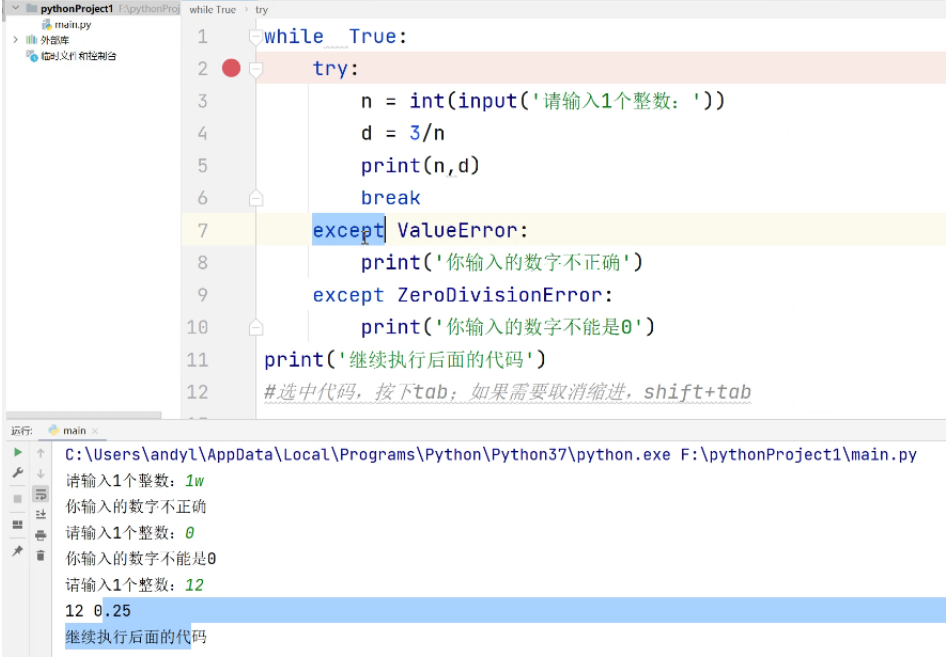
try-except异常处理结构:当try代码块出现异常时,系统会自动跳转到except代码块执行。比如可以用它来拦截用户输入的异常值。
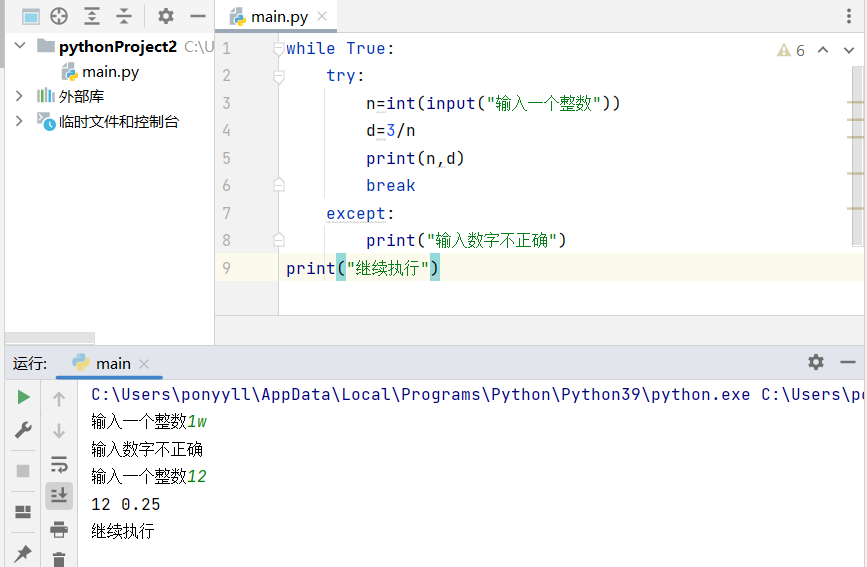
但这里有个易忽略的细节:输入0也会被判定为"不正确"。这说明代码的验证逻辑可能存在漏洞,需要进一步检查条件判断语句是否合理。这种情况在编程中很常见,提醒我们要特别注意边界条件的测试。
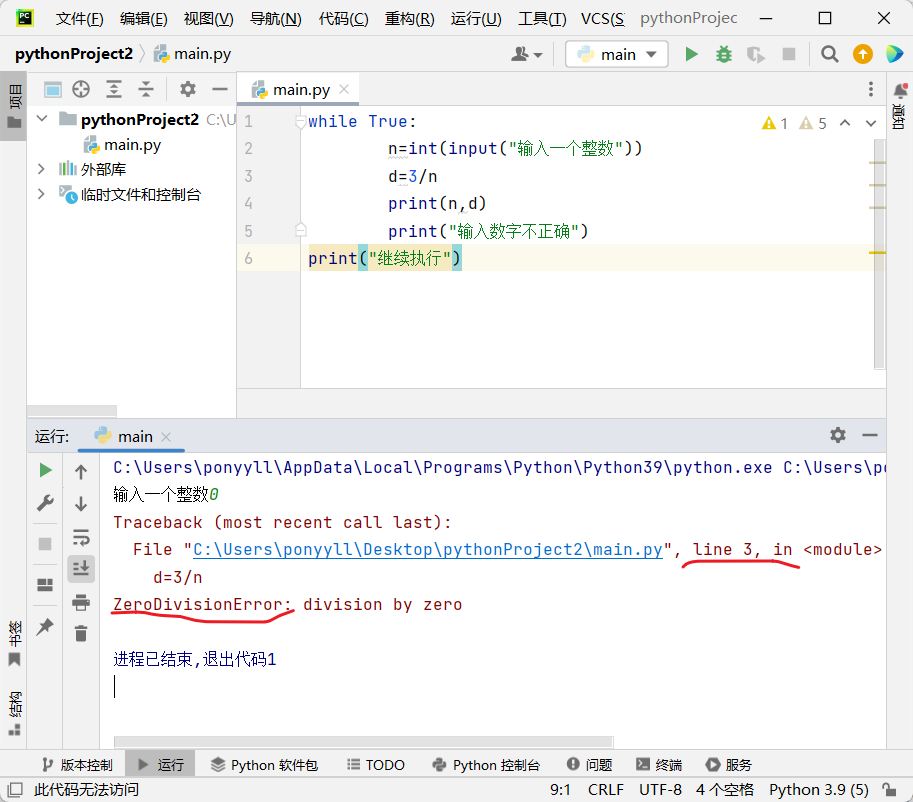
当程序遇到输入错误时,不能简单地机械报错,而应该根据具体错误类型给出人性化提示。比如输入0会触发ZeroDivisionError(零除错误),输入非数字会触发ValueError(值错误)。通过捕获特定异常类型,可以针对性地提示"数字不能为0"或"请输入有效数字",这样比笼统的"输入不正确"更清晰易懂。
四、组合数据类型
在基础阶段,我们会重点学习三种组合数据类型:列表、元组和字典。
4.1列表
用中括号[]表示,里面能装各种类型的数据。数值(比如1、2)、字符串(比如"python")、甚至其他列表、元组、字典都能往里塞。
列表元素用逗号隔开,每个元素可以是完全不同的数据类型。这种特性让列表成为处理复杂数据的利器,比如电商系统中用户的名字(字符串)、年龄(数值)、购物车(列表)就能统一管理。
索引从0开始,a[0]取第一个元素。判断元素个数要看逗号分隔,遇到子列表时,无论它内部多复杂,都视为一个独立元素。负数索引表示从后往前数,-1是最后一个元素。
切片操作和字符串类似,语法是[start:end],这些规则和字符串切片完全一致。
在嵌套列表操作中,需要分步操作:先通过主列表索引定位到子列表,再通过子列表索引定位具体元素。调试模式下可以逐层展开列表结构,直观看到每个子列表的内容。比如要获取s1[2][4]的值,必须先拿到s1[2]这个子列表,才能继续索引[4]。
列表类型函数:list()可以将类型强制转换为列表。
列表方法:
(1)append():在列表最后增加一个元素
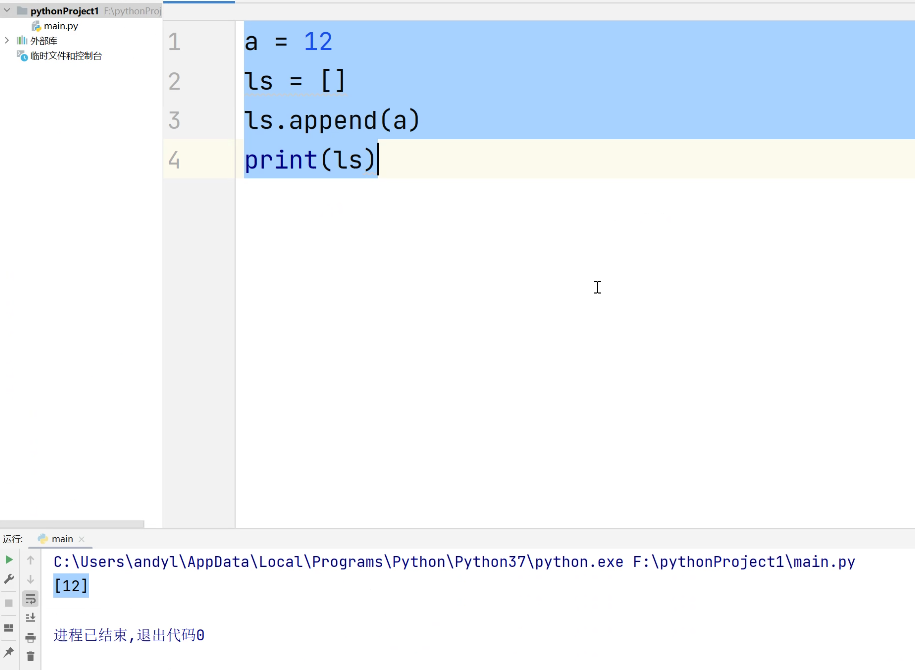
(2)clear():清除列表中所有元素,括号内无需添加参数。
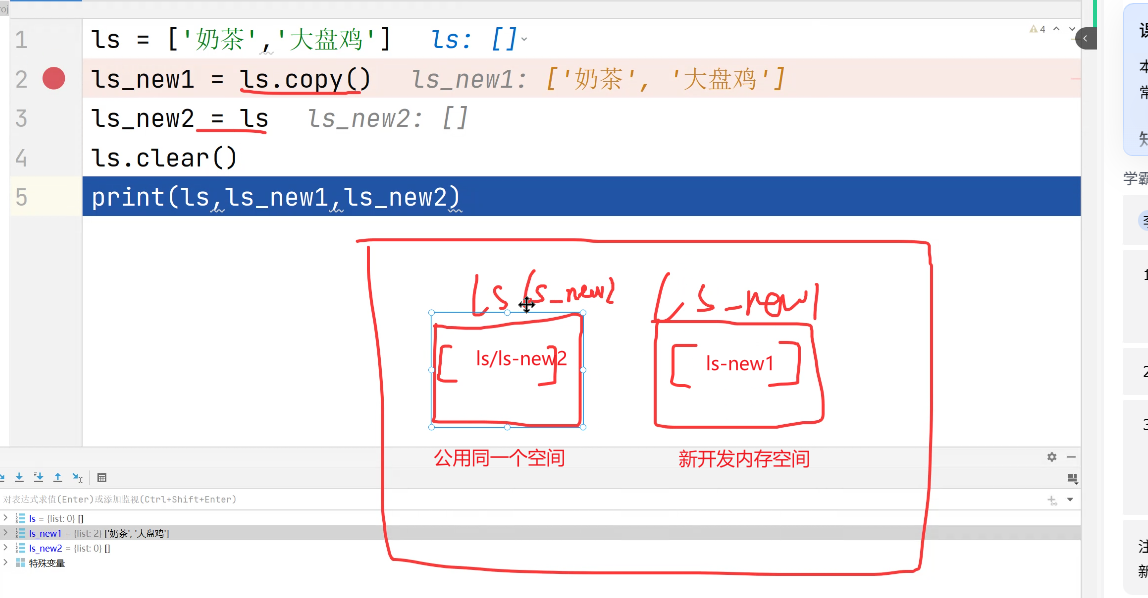
(3)copy():会真正创建新内存空间,把原列表内容完整复制过去,此时修改原列表不会影响新列表。直接赋值(lst2 = lst)只是给同一块内存空间起了新名字(如lst2),本质上lst和lst2是同一个对象。所以用clear()清空其中一个,另一个也会同步清空。
(4)count():统计元素出现次数,比如统计"奶茶"在列表里出现了3次,就返回数字3
(5)index():查找元素位置,比如找"冰激凌"的下标是2(从0开始数)
(6)insert():它在指定位置插入元素,其他元素会自动后移。如a.insert(2,"abc")就是在索引2的位置加入元素"abc"。
(7)pop():是按索引删除元素,比如pop(2)就是删除下标2的元素。
(8)remove():是删除第一个匹配值,remove("大盘鸡")只删除第一个"大盘鸡",后面重复的不会删。
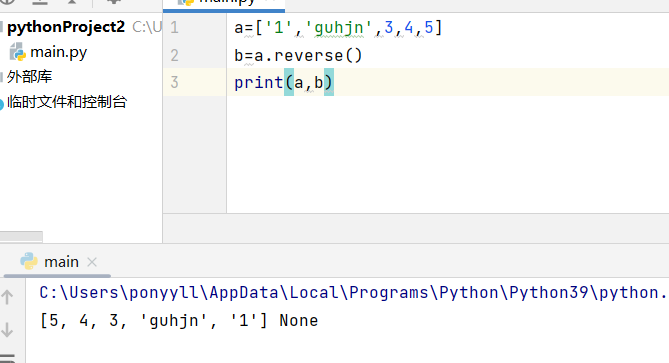
(9)reverse():直接翻转整个列表顺序。如下图翻转后的信息不会返回给b。
(10)sort():中文列表排序默认按拼音字母顺序。数字列表默认从小到大排序,但可以通过设置reverse=True参数改为从大到小排列。
4.2元组
元组使用圆括号()包裹元素。列表和元组的关键区别在于可变性。列表(list)用方括号表示,可以随意增删改元素;而元组(tuple)用圆括号表示,一旦创建就不可修改,包括不能删除、添加或反转元素。可用tuple()函数强制转换为元组。
4.3字典
没有序号,只能通过键来找值

字典特别适合存储键值对形式的数据,比如用户信息这种结构化数据;而列表更适合存储同类型元素的集合。两者的核心区别在于:字典通过键快速访问值,列表则通过索引位置访问元素。字典特别适合管理这类关联性数据,每个键值对就是一个独立的数据单元。
字典和列表的最大区别在于字典是无序的,不能像列表那样通过索引号来获取元素,必须通过键来访问对应的值。
dict()函数和list()、tuple()类似,都是强制类型转换函数,也可以用来创建空字典。比如a = dict()就会生成一个空字典。如果想往字典里添加内容,可以用a[键] = 值的方式。而列表添加元素是用append()方法,字典则是直接通过键赋值的方式,必须明确指定键和对应的值。
字典是通过键(key)来访问值(value)的,而不是像列表那样通过下标(index)。
操作方法:
(1)clear():直接清空整个字典内容。
(2)get():它接收两个参数,第一个参数是要查找的键,如果字典中存在这个键,就返回对应的值;如果键不存在,则返回第二个参数的值。比如dict.get('key1','default'),就是在字典里找'key1',找到返回其值,找不到就返回'default'。这个方法可以接受1-2个参数。单参数查不到返None,双参数查不到返默认值。
(3)keys():会返回一个dict_keys对象。比如执行a = D.keys()后,变量a会包含字典D的所有键集合。这里要注意的是,dict_keys并不是普通的列表,而是字典键的动态视图,会随字典更新而变化。



评论前必须登录!
注册