 网硕互联帮助中心
网硕互联帮助中心一、浏览器访问 Web 服务器的 HTTP 通信全流程
包含 DNS 解析、TCP 连接、HTTP 收发、连接管理 4 个核心环节,我分步骤拆解(清晰到每一步):
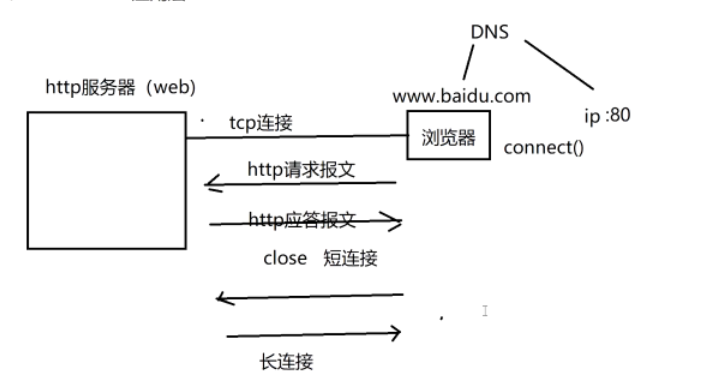
步骤 1:DNS 解析(浏览器先找到服务器的 IP)
- 浏览器输入www.baidu.com(域名),但网络通信需要IP 地址;
- 浏览器向DNS 服务器发起请求,查询www.baidu.com对应的 IP(比如180.101.50.242);
- DNS 返回该域名的 IP,浏览器拿到目标服务器的 IP 后,准备建立连接。
步骤 2:建立 TCP 连接(三次握手)
- 浏览器调用connect(),向服务器的80 端口(HTTP 默认端口)发起 TCP 三次握手:
- 浏览器发SYN → 2. 服务器回SYN+ACK → 3. 浏览器回ACK;
- 握手完成后,浏览器与服务器建立可靠的 TCP 连接(图中 “tcp 连接”)。
步骤 3:发送 HTTP 请求报文
- 浏览器通过已建立的 TCP 连接,向服务器发送HTTP 请求报文(比如GET /index.html HTTP/1.1),包含请求方法、资源路径、协议版本等信息。
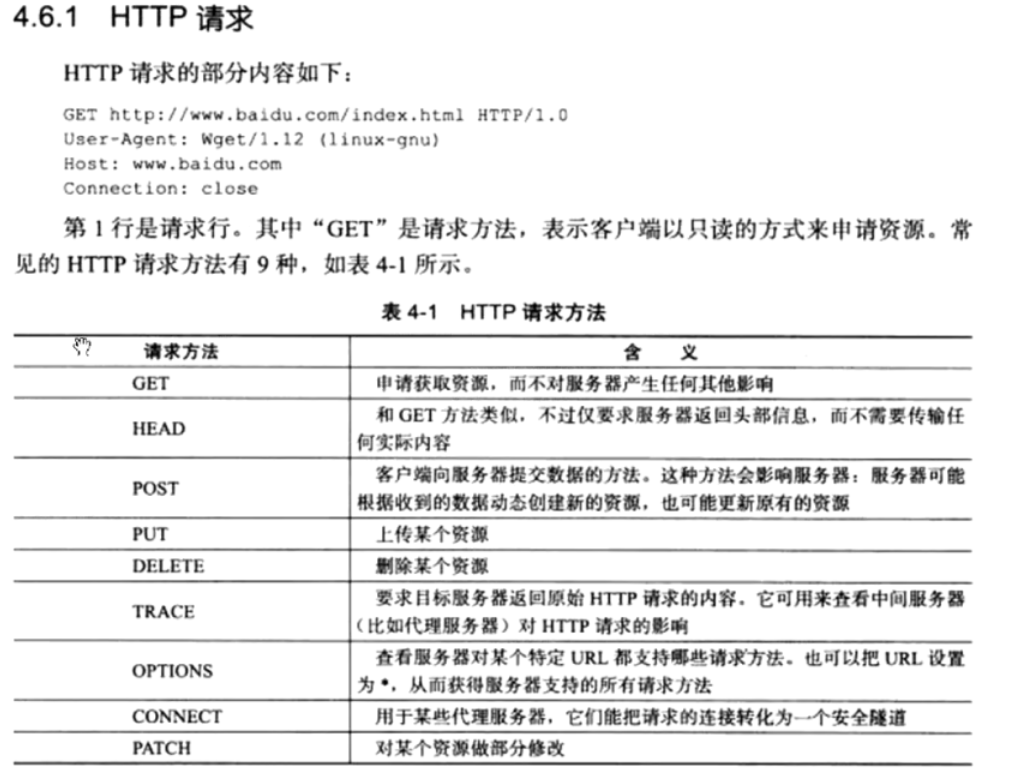
GET http://www.baidu.com/index.html HTTP/1.0 → 请求行
User-Agent: Wget/1.12 (linux-gnu) → 请求头1
Host: www.baidu.com → 请求头2
Connection: close → 请求头3
①请求行(第 1 行,HTTP 请求的核心指令)
请求行由 「请求方法」+「请求 URL」+「协议版本」 三部分组成,每部分都有明确作用:
- 是客户端对服务器的 “操作指令”,图中GET表示 “读取服务器资源”(只读、不修改服务器数据);
- 不同方法对应不同操作(比如 POST 是 “提交数据”,PUT 是 “上传资源”)。
- 明确要访问的服务器资源路径,这里是百度首页的index.html文件。
- 表示使用的 HTTP 协议版本,不同版本支持的特性不同(比如 HTTP/1.0 默认短连接,HTTP/1.1 默认长连接)。
②请求头(第 2-4 行,传递附加信息)
请求头是 “键值对” 格式(键: 值),用来告诉服务器请求的附加信息,图中这几个头是高频必知的:
- 告诉服务器 “客户端的身份”:这里是 Linux 系统下的Wget工具(一种命令行下载工具);
- 服务器可以通过这个头识别客户端类型(比如是浏览器、手机 APP 还是爬虫)。
- 告诉服务器 “目标域名”:因为一台服务器可能绑定多个域名,这个头用来指定要访问的具体域名;
- 是 HTTP/1.1 的必选头(HTTP/1.0 可选,但实际也会传)。
- 告诉服务器 “本次请求用短连接”:HTTP/1.0 默认是短连接,请求完成后服务器会关闭 TCP 连接;
- 如果是Connection: keep-alive,就是长连接(HTTP/1.1 默认),连接会保留供后续请求复用。
③补充:GET 请求的特点(结合示例)
图中是GET请求,它的核心特点是:
- 无请求体:因为是 “读取资源”,不需要向服务器提交数据,所以请求只有 “请求行 + 请求头”;
- 数据在 URL 中:如果要传参数,会拼接在 URL 后面(比如index.html?name=test);
- 幂等性:多次调用GET请求,不会修改服务器的状态(比如多次请求index.html,服务器数据不会变)。
步骤 4:服务器返回 HTTP 应答报文
- 服务器接收请求后,处理请求(比如读取index.html文件),通过 TCP 连接向浏览器返回HTTP 应答报文(包含状态码、响应头、响应体),报文实力如下。
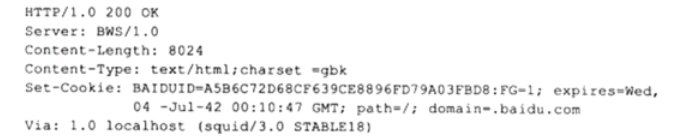
一、状态行(第 1 行)
HTTP/1.0 200 OK
- HTTP/1.0:使用的 HTTP 协议版本;
- 200:状态码,表示 “请求成功”(是最常见的成功状态码);
- OK:状态码的描述文本,与200对应。
二、响应头(第 2-6 行,服务器返回的附加信息)
- 服务器标识:表示这是百度的 BWS 服务器(Baidu Web Server)。
- 响应体的字节数:告诉客户端,后续返回的资源(比如网页)大小是 8024 字节。
- 响应体的类型和编码:
- text/html:资源是 HTML 网页;
- charset=gbk:网页内容的编码格式是 GBK。
- 服务器向客户端设置 Cookie:用于身份识别、会话保持(比如登录状态),后续客户端请求会自动携带这个 Cookie。
- 代理信息:表示请求经过了本地的 Squid 代理服务器(版本 3.0)转发。
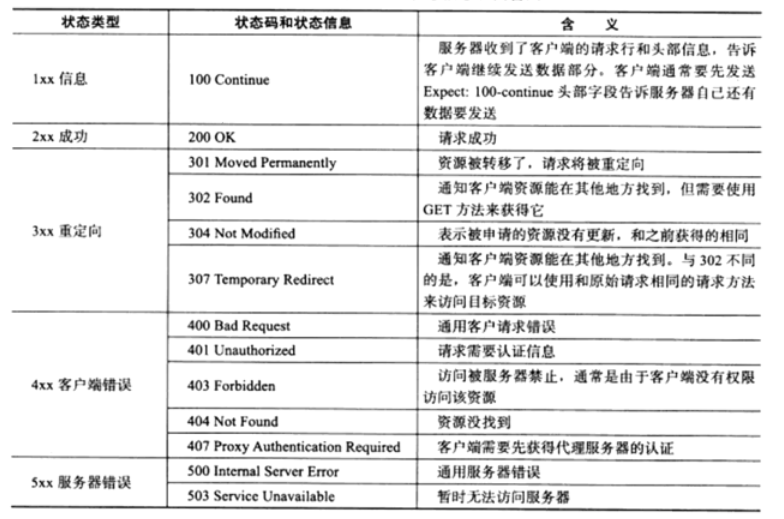
HTTP 应答报文中的「状态码分类与含义」
步骤 5:连接管理(短连接 / 长连接)
- 短连接(图中 “close 短连接”):HTTP 1.0 默认是短连接,服务器返回应答后,主动关闭 TCP 连接;
- 长连接(图中 “长连接”):HTTP 1.1 默认是长连接,服务器返回应答后,TCP 连接不关闭,后续浏览器可复用该连接发送新的 HTTP 请求(减少重复握手的开销)。
总结整个流程
浏览器通过DNS 解析域名→TCP 三次握手建连→发 HTTP 请求→收 HTTP 响应→根据短 / 长连接策略管理 TCP 连接,完成一次 Web 资源的访问。
二、写myhttp.c http服务器让其和浏览器通信
我们现在写:一个tcp的服务器端,他的业务时和浏览器(客户端)进行通信,所以不用写客户端 只用吧服务器端写好。
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#include <sys/socket.h>
#include <netinet/in.h>
#include <arpa/inet.h>
#include <pthread.h>
// 1. 服务器初始化函数:创建套接字+绑定+监听
int socket_init()
{
// 创建TCP套接字
int sockfd = socket(AF_INET, SOCK_STREAM, 0);
if (sockfd == -1)
{
return -1;
}
// 配置服务器地址(IP:127.0.0.1,端口:80)
struct sockaddr_in saddr;
memset(&saddr, 0, sizeof(saddr));
saddr.sin_family = AF_INET;
saddr.sin_port = htons(80);
saddr.sin_addr.s_addr = inet_addr("127.0.0.1");
// 绑定地址
int res = bind(sockfd, (struct sockaddr*)&saddr, sizeof(saddr));
if (res == -1)
{
printf("bind err\\n");
return -1;
}
// 监听(队列长度5)
if(listen(sockfd,5) == -1 )
{
return -1;
}
return sockfd;
}
// 2. 线程处理函数:与客户端通信
void* thread_fun(void* arg)
{
// 接收客户端套接字描述符
int *p = (int*)arg;
int c = *p;
free(p); // 释放动态分配的内存
char buff[1024] = {0};
// 接收客户端数据
int n = recv(c, buff, 1023, 0);
if (n <= 0)
{
close(c);
pthread_exit(NULL); // 线程退出
}
printf("buff=%s\\n", buff);
send(c, "OK", 2, 0); // 回复客户端
close(c);
return NULL;
}
// 3. 主函数:接收连接+创建线程
int main()
{
int sockfd = socket_init();
if (sockfd == -1)
{
exit(1);
}
while(1)
{
// 接收客户端连接,得到客户端套接字c
int c = accept(sockfd, NULL, NULL);
if (c < 0)
{
continue;
}
// 动态分配内存存c(避免线程间共享栈变量)
int *p = (int*)malloc(sizeof(int));
*p = c;
// 创建线程,执行thread_fun处理该客户端
pthread_t tid;
pthread_create(&tid, NULL, thread_fun, (void*)p);
}
exit(1);
}
核心逻辑讲解
socket_init():服务器初始化
- 完成socket(创建 TCP 套接字)→ bind(绑定 127.0.0.1:80)→ listen(开启监听),返回监听套接字 sockfd。
main():主线程接收连接 + 创建工作线程
- 循环调用accept接收客户端连接,得到客户端套接字c;
- 动态分配内存存储c(避免线程共享栈变量),通过pthread_create创建新线程,将c传给thread_fun。
thread_fun():工作线程处理客户端通信
- 接收c,释放内存;
- 通过recv接收客户端数据,send回复 “OK”;
- 通信完成后关闭c,线程退出。
多线程并发的特点
- 相比多进程,线程更轻量(资源开销小);
- 需注意内存管理(用malloc传递c,避免栈变量被多线程共享);
- 实现 “一个客户端对应一个线程” 的并发服务,适合高并发场景。
测试
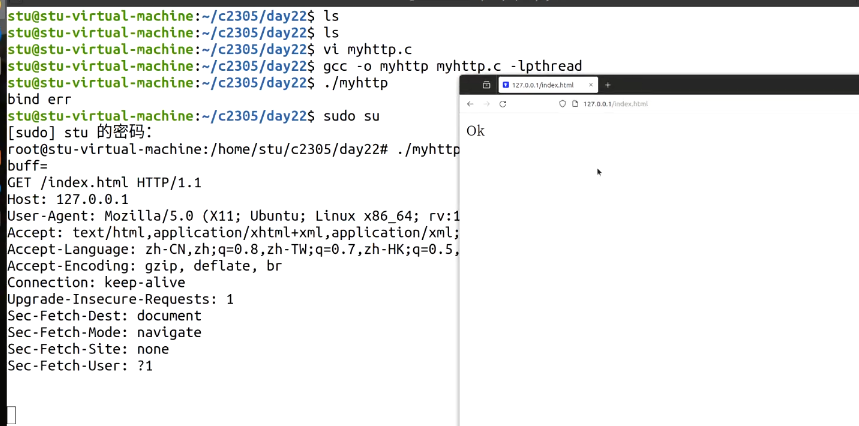
①测试准备(终端操作)
②通信测试(浏览器 + 服务器交互)
- 通过recv接收浏览器的 HTTP 请求,终端打印请求内容(buff=GET /index.html…);
- 调用send回复 “OK”。
③核心验证点
- 验证了 “多线程服务器 + 80 端口权限 + HTTP 请求处理” 的流程;
- 解决了 “普通用户无法绑定低端口” 的问题(通过 root 提权);
- 实现了浏览器与服务器的 HTTP 请求 – 响应交互。
解析模块:
解析拿出请求方法
三、在原多线程 TCP 服务器基础上,扩展为简易 HTTP 文件服务器
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#include <sys/socket.h>
#include <netinet/in.h>
#include <arpa/inet.h>
#include <pthread.h>
#include <fcntl.h>
#include <sys/stat.h>
// 你的代码里定义的文件根目录,和截图一致
#define PATH "/home/stu/c2305/day22"
// 解析HTTP请求行,提取请求的文件名 如 GET /index.html HTTP/1.1 -> /index.html
char* get_filename(char buff[])
{
char* ptr = NULL;
char* s = strtok_r(buff, " ", &ptr); // 分割出GET/POST
if(s == NULL)
{
return NULL;
}
s = strtok_r(NULL, " ", &ptr); // 分割出请求的文件路径
return s;
}
// 服务器初始化:创建socket、绑定、监听
int socket_init()
{
int sockfd = socket(AF_INET,SOCK_STREAM,0);
if(sockfd == -1)
{
perror("socket err");
return -1;
}
struct sockaddr_in saddr;
memset(&saddr,0,sizeof(saddr));
saddr.sin_family = AF_INET;
saddr.sin_port = htons(80); // HTTP默认80端口
saddr.sin_addr.s_addr = inet_addr("127.0.0.1");
int res = bind(sockfd,(struct sockaddr*)&saddr,sizeof(saddr));
if(res == -1)
{
perror("bind err");
return -1;
}
if(listen(sockfd,5) == -1)
{
perror("listen err");
return -1;
}
return sockfd;
}
// 线程处理函数:处理客户端HTTP请求+返回文件
void* thread_fun(void* arg)
{
int c = *(int*)arg;
free(arg); // 释放malloc的堆内存
char buff[1024] = {0};
int n = recv(c,buff,1023,0);
if(n <= 0)
{
close(c);
pthread_exit(NULL);
}
printf("收到客户端请求:\\n%s\\n",buff);
// 1. 解析请求的文件名
char* filename = get_filename(buff);
if(filename == NULL)
{
close(c);
pthread_exit(NULL);
}
// 2. 拼接完整文件路径
char file_path[256] = {0};
strcpy(file_path,PATH);
// 如果访问根目录 / ,默认打开index.html
if(strcmp(filename,"/") == 0)
{
strcat(file_path,"/index.html");
}
else
{
strcat(file_path,filename);
}
printf("要打开的文件路径: %s\\n",file_path);
// 3. 以只读方式打开文件
int fd = open(file_path,O_RDONLY);
if(fd == -1)
{
// 文件打开失败,返回HTTP 404响应
char err_msg[512] = "HTTP/1.1 404 Not Found\\r\\nContent-Type:text/html;charset=utf-8\\r\\n\\r\\n<html><head><meta charset='utf-8'></head><body><h1>404 页面不存在</h1></body></html>";
send(c,err_msg,strlen(err_msg),0);
close(c);
pthread_exit(NULL);
}
// 4. 获取文件大小
struct stat st;
fstat(fd,&st);
int file_size = st.st_size;
// 5. 拼接HTTP 200成功响应头
char head_msg[512] = {0};
sprintf(head_msg,"HTTP/1.1 200 OK\\r\\nContent-Length:%d\\r\\nContent-Type:text/html;charset=utf-8\\r\\n\\r\\n",file_size);
send(c,head_msg,strlen(head_msg),0);
// 6. 循环读取文件内容并发送给浏览器
char file_buff[1024] = {0};
int read_len = 0;
while((read_len = read(fd,file_buff,1024)) > 0)
{
send(c,file_buff,read_len,0);
memset(file_buff,0,sizeof(file_buff));
}
// 收尾:关闭文件、关闭客户端套接字
close(fd);
close(c);
pthread_exit(NULL);
}
int main()
{
int sockfd = socket_init();
if(sockfd == -1)
{
exit(1);
}
printf("HTTP服务器启动成功,监听 127.0.0.1:80 …\\n");
pthread_attr_t attr;
pthread_attr_init(&attr);
// 设置线程分离属性:线程退出后自动释放资源,解决内存泄漏!
pthread_attr_setdetachstate(&attr,PTHREAD_CREATE_DETACHED);
while(1)
{
int c = accept(sockfd,NULL,NULL);
if(c < 0)
{
continue;
}
printf("有客户端连接成功!\\n");
int* p = (int*)malloc(sizeof(int));
*p = c;
pthread_t tid;
// 创建分离属性的线程
pthread_create(&tid,&attr,thread_fun,(void*)p);
}
pthread_attr_destroy(&attr);
close(sockfd);
exit(0);
}
一、核心功能升级:从 “回复固定 OK” 到 “返回文件”
原代码只是接收请求后回复 “OK”,这段代码新增了HTTP 请求解析 + 文件路径拼接的逻辑,目标是:浏览器访问127.0.0.1/index.html → 服务器解析出请求的文件是/index.html → 拼接本地路径/home/stu/c2305/day22/index.html → 读取该文件并返回给浏览器。
二、逐段解析新增逻辑
1. get_filename(char buff[]):解析 HTTP 请求中的文件路径
作用:从浏览器发送的 HTTP 请求(存在buff中)里,提取要访问的文件路径(比如从GET /index.html HTTP/1.1中提取/index.html)
char* get_filename(char buff[])
{
char* ptr = NULL;
// 第一步:用空格分割请求行,拿到第一个字段(请求方法,比如GET)
char* s = strtok_r(buff, " ", &ptr);
if (s == NULL) { return NULL; }
printf("请求方法: %s\\n", s);
// 第二步:分割得到第二个字段(文件路径,比如/index.html)
s = strtok_r(NULL, " ", &ptr);
return s; // 返回解析出的文件路径
}
- 示例:若buff是GET /index.html HTTP/1.1,strtok_r第一次分割出GET,第二次分割出/index.html,最终返回/index.html。
2. 线程函数thread_fun:新增文件路径拼接逻辑
在原 “接收请求” 后,新增了解析路径、拼接本地目录的步骤:
// 1. 解析HTTP请求中的文件路径
char* filename = get_filename(buff);
if (filename == NULL ) { break; }
// 2. 拼接本地文件的完整路径
char path[256] = {PATH}; // PATH是宏定义的本地目录:/home/stu/c2305/day22
// 处理根路径请求(比如浏览器访问127.0.0.1,filename是"/")
if ( strcmp(filename,"/") == 0 )
{
filename = "/index.html"; // 默认返回index.html
}
strcat(path,filename); // 拼接成完整路径:比如/home/stu/c2305/day22/index.html
printf("path:%s\\n",path);
- 示例:若解析出filename=/index.html,拼接后path为/home/stu/c2305/day22/index.html,后续会打开这个文件并返回给浏览器。
四、我们现在请求服务器查看一张图片
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#include <sys/socket.h> // 网络套接字核心头文件 socket/bind/listen/accept/recv/send
#include <netinet/in.h> // 网络地址结构体 sockaddr_in 网络字节序转换函数
#include <arpa/inet.h> // 地址转换相关函数
#include <pthread.h> // 线程库头文件 pthread_create/pthread_exit
#include <fcntl.h> // 文件打开 open 函数头文件
#include <sys/types.h> // 系统类型定义
// 服务器存放网页文件的根目录,和你的截图一致,不要修改
#define PATH "/home/stu/c2305/day22"
/**************************************************************************
函数名:get_filename
函数功能:解析浏览器发送的HTTP请求报文,提取请求的文件路径
参数:buff 接收客户端请求数据的缓冲区
返回值:成功返回请求的文件路径 如:/index.html 失败返回NULL
**************************************************************************/
char* get_filename(char buff[])
{
char* ptr = NULL;
// 第一次分割,获取请求方法 GET/POST
char* s = strtok_r(buff, " ", &ptr);
if(s == NULL) // 分割失败,返回NULL
{
return NULL;
}
// 第二次分割,获取请求的文件路径 核心提取逻辑
s = strtok_r(NULL, " ", &ptr);
return s;
}
/**************************************************************************
函数名:socket_init
函数功能:TCP服务器初始化核心函数,完成 创建套接字-绑定端口-开启监听 三步操作
返回值:成功返回监听套接字描述符 失败返回-1
**************************************************************************/
int socket_init()
{
// 创建TCP流式套接字 AF_INET:IPv4协议 SOCK_STREAM:TCP协议 0:默认
int sockfd = socket(AF_INET,SOCK_STREAM,0);
if(sockfd == -1)
{
printf("socket err\\n");
return -1;
}
// 初始化服务器地址结构体
struct sockaddr_in saddr;
memset(&saddr,0,sizeof(saddr)); // 清空结构体垃圾值
saddr.sin_family = AF_INET; // 地址族:IPv4
saddr.sin_port = htons(80); // 绑定HTTP默认端口80,主机序转网络序
saddr.sin_addr.s_addr = inet_addr("127.0.0.1"); // 绑定本地回环地址,仅本机可访问
// 绑定:将套接字与指定的IP+端口进行绑定
int res = bind(sockfd,(struct sockaddr*)&saddr,sizeof(saddr));
if(res == -1)
{
printf("bind err\\n");
return -1;
}
// 监听:开启套接字监听,等待客户端连接,5是半连接队列长度
if(listen(sockfd,5) == -1)
{
return -1;
}
return sockfd; // 初始化成功,返回监听套接字
}
/**************************************************************************
函数名:thread_fun
函数功能:线程处理业务函数,每个客户端连接对应一个独立线程
完成:接收HTTP请求 -> 解析文件路径 -> 打开文件 -> 返回文件给浏览器
参数:arg 主线程传递的客户端套接字描述符地址
返回值:线程退出返回NULL
**************************************************************************/
void* thread_fun(void* arg)
{
// 接收主线程传递的客户端套接字描述符
int c = *(int*)arg;
free(arg); // 释放malloc申请的堆内存,防止内存泄漏
// 定义缓冲区接收客户端的HTTP请求数据
char buff[1024] = {0};
// 阻塞接收客户端发送的请求数据,成功返回接收字节数,失败/断开返回<=0
int n = recv(c,buff,1023,0);
if(n <= 0) // 接收失败或客户端断开连接
{
close(c); // 关闭客户端套接字
pthread_exit(NULL); // 线程正常退出
}
printf("recv buf=%s\\n",buff); // 打印收到的HTTP请求报文
// 1. 解析HTTP请求中要访问的文件路径
char* filename = get_filename(buff);
if(filename == NULL) // 解析失败,直接释放资源退出
{
close(c);
pthread_exit(NULL);
}
// 2. 拼接要打开的文件完整路径
char path[256] = {0};
strcpy(path, PATH); // 拼接根目录
if(strcmp(filename, "/") == 0) // 如果访问根目录 / ,默认打开首页index.html
{
filename = "/index.html";
}
strcat(path, filename); // 拼接完整文件路径
printf("path=%s\\n",path); // 打印拼接后的文件路径
// ====================== 以下是你截图的核心代码 完整保留 ======================
// 以只读方式打开拼接好的文件
int fd = open(path,O_RDONLY);
if(fd == -1) // 文件打开失败,直接跳出逻辑
{
close(c);
pthread_exit(NULL);
}
// 通过文件偏移量计算文件大小:将光标移到文件末尾,返回的偏移量就是文件总字节数
int filesize = lseek(fd,0,SEEK_END);
lseek(fd,0,SEEK_SET); // 将光标重新移回文件开头,准备读取文件内容
// 拼接HTTP响应头,严格遵守HTTP协议格式
char head[256] = {"HTTP/1.1 200 OK\\r\\n"}; // 状态行:请求成功
strcat(head,"Server: myhttp\\r\\n"); // 响应头:服务器标识
sprintf(head,"%sContent-Length:%d\\r\\n",head,filesize); // 响应头:告诉浏览器文件大小
strcat(head,"\\r\\n"); // 响应头结束标志:空行(\\r\\n)
send(c,head,strlen(head),0); // 将响应头发送给浏览器
// 循环读取文件内容,分批次发送给浏览器
char data[1024] = {0}; // 定义文件读取缓冲区
int num = 0;
// 每次读取1024字节,读到内容>0则发送,读完返回0则结束循环
while((num = read(fd,data,1024))>0)
{
send(c,data,num,0); // 将读取的文件内容发送给客户端
}
close(fd); // 文件读取完毕,关闭文件描述符释放资源
// ====================== 你截图的核心代码 结束 ======================
close(c); // 关闭客户端套接字,释放连接资源
return NULL;
}
/**************************************************************************
主函数:程序入口
功能:初始化服务器 -> 循环接收客户端连接 -> 为每个客户端创建独立线程处理业务
**************************************************************************/
int main()
{
// 调用初始化函数,获取监听套接字
int sockfd = socket_init();
if(sockfd == -1) // 初始化失败,直接退出程序
{
exit(1);
}
// 设置线程分离属性,解决线程退出后的资源泄漏问题
pthread_attr_t attr;
pthread_attr_init(&attr); // 初始化线程属性
// 设置分离属性:线程运行结束后,系统自动回收线程资源,无需主线程join
pthread_attr_setdetachstate(&attr, PTHREAD_CREATE_DETACHED);
// 死循环,永久监听客户端连接请求
while(1)
{
// 阻塞等待客户端连接,成功返回客户端套接字,失败返回-1
int c = accept(sockfd,NULL,NULL);
if(c < 0) // 连接失败,继续等待下一个客户端
{
continue;
}
// 动态申请堆内存存放客户端套接字,防止线程共享栈变量导致数据错乱
int *p = (int*)malloc(sizeof(int));
*p = c;
pthread_t tid; // 定义线程ID
// 创建线程处理当前客户端的业务请求
pthread_create(&tid,&attr,thread_fun,(void*)p);
}
close(sockfd); // 关闭监听套接字(实际死循环不会执行到这里)
exit(0);
}
一、先看【代码整体架构】(3 大核心部分,总分总结构,特别清晰)
整个代码一共分为 3 个核心函数 + 头文件 / 宏定义,执行逻辑是:宏定义/头文件 → socket_init() 服务器初始化 → main() 主线程:接连接+创线程 → thread_fun() 子线程:处理业务+返回文件 → get_filename() 工具函数:解析请求所有功能各司其职,主线程只做「接待」,子线程只做「干活」,分工明确。
二、第一部分:头文件 + 宏定义(程序的基础依赖)
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#include <sys/socket.h> // 网络核心函数:socket/bind/listen/accept/recv/send
#include <netinet/in.h> // 网络地址结构体 sockaddr_in + 字节序转换 htons
#include <arpa/inet.h> // 地址转换 inet_addr
#include <pthread.h> // 线程库:pthread_create 创建线程、pthread_exit 退出线程
#include <fcntl.h> // 文件操作:open 打开文件
#include <sys/types.h> // 系统基础类型定义
#define PATH "/home/stu/c2305/day22" // 固定宏:你的服务器存放html文件的根目录
✅ 核心说明:
三、第二部分:3 个核心函数 逐函数讲解(重中之重,全部吃透)
✅ 函数 1:char* get_filename(char buff[]) 【工具函数:解析 HTTP 请求】
作用
从浏览器发送的HTTP 请求报文里,提取出你要访问的文件路径。
核心逻辑
浏览器访问 http://127.0.0.1/index.html 时,会给服务器发一段请求数据,格式是:GET /index.html HTTP/1.1 …
- 这个函数用 strtok_r 按空格分割这段字符串;
- 第一次分割:拿到 GET(请求方法,我们不用管);
- 第二次分割:拿到 /index.html(核心!这就是要打开的文件路径);
关键点
- 返回值:成功返回文件路径,失败返回 NULL;
- 特殊情况:如果浏览器只访问 http://127.0.0.1,分割出来的是 /,后续会自动替换成 /index.html(访问首页)。
✅ 函数 2:int socket_init() 【核心初始化函数:TCP 服务器三件套】
作用
一站式完成 TCP 服务器的初始化工作,执行 TCP 服务器的经典三步操作,成功返回「监听套接字」,失败返回 – 1,是所有网络通信的基础。
内部执行的 3 个核心步骤(TCP 服务器必背)
易错点(面试常问)
- 运行时报 bind err:因为 80 端口是 Linux 的特权端口(1024 以下),普通用户没权限绑定,必须用 sudo ./myhttp 运行;
- 返回 – 1 都是初始化失败,程序直接退出。
✅ 函数 3:void* thread_fun(void* arg) 【核心业务函数:子线程干活的核心】
作用
这是整个程序的业务核心!每一个浏览器连接,都会创建一个独立的这个线程,所有和浏览器的「通信、解析请求、读文件、返回文件」的工作,都在这个函数里完成。
给谁干活?
参数arg是主线程传过来的「客户端套接字 c」,这个c是浏览器和服务器的专属通信通道,每个浏览器的c都不一样,互不干扰。
内部完整执行流程(按顺序,和代码一一对应,必记)
plaintext
1. 接收主线程传的客户端套接字c → free释放堆内存(防止内存泄漏)
2. recv(c, buff, …) 阻塞接收浏览器发来的HTTP请求数据
3. 如果接收失败/浏览器断开 → 关闭c,线程退出
4. 调用get_filename解析出要访问的文件路径
5. 拼接完整文件路径:根目录PATH + 文件路径 → 比如 /home/stu/c2305/day22/index.html
6. open(path, O_RDONLY) 以只读方式打开这个文件
7. 用lseek计算文件大小:光标移到文件末尾得到总字节数 → 光标移回开头准备读取
8. 拼接HTTP响应头:按HTTP协议规范,告诉浏览器「请求成功,接下来给你发文件」
9. send发送响应头 → 循环read读文件内容 + send发送给浏览器
10. 读完文件后,close关闭文件、close关闭客户端套接字 → 线程完成工作,自动退出
补充的「打开文件、lseek 算大小、拼响应头、读文件发送」的代码,完整放在这个函数里,这部分是HTTP 服务器的核心能力:从「只返回 OK」升级为「返回真实网页文件」。
四、第三部分:main() 主函数 【程序入口 + 总指挥,最核心的调度逻辑】
这是程序的入口,所有代码从这里开始执行,主线程只做一件事:无限循环接收连接,为每个连接创建独立线程,什么业务都不处理,保证永不卡顿,是多线程并发的精髓!
main 函数完整执行流程(逐行逻辑,必背)
- 为什么不用 &c 直接传?因为c是主线程的栈变量,主线程会立刻回到循环,栈变量的值会被下一个浏览器的连接覆盖,子线程会拿到错误的值;
- 用malloc申请的是堆内存,独立不受影响,子线程拿到后free释放即可;
核心精髓
主线程 只做「接客」,子线程 只做「干活」,主线程永远不会阻塞在业务逻辑上,可以同时接收无数个浏览器的连接,这就是「多线程并发」!
五、整段代码的【完整运行流程】(从头到尾串一遍,打通任督二脉)
把所有逻辑串起来,一步一步执行,这就是你运行程序后,完整的执行过程,背下来,面试直接说,满分答案!
plaintext
1. 编译代码:gcc -o myhttp myhttp.c -lpthread (加-lpthread链接线程库)
2. 运行程序:sudo ./myhttp (sudo提权,绑定80端口成功,服务器启动)
3. 主线程进入死循环,阻塞在accept(),等待浏览器连接
4. 打开浏览器,输入 http://127.0.0.1 访问本机
5. accept()收到连接,返回客户端套接字c → malloc存c → 创建子线程
6. 子线程执行thread_fun:
– recv接收浏览器的HTTP请求 → get_filename解析出 / → 替换成/index.html
– 拼接路径 /home/stu/c2305/day22/index.html → open打开这个文件
– lseek算文件大小 → 拼接HTTP响应头 → send发送响应头
– 循环read读文件内容,send发送给浏览器
7. 浏览器收到文件内容,渲染出网页页面
8. 子线程close文件、close客户端套接字 → 线程退出,系统自动回收资源
9. 主线程一直卡在accept(),等待下一个浏览器访问,循环往复,永久运行
六、核心知识点总结 + 面试必背考点(全部是你代码里的重点)
✅ 1. 多线程的核心优势
一个线程处理一个客户端,支持并发访问:多个浏览器可以同时访问你的服务器,互不影响,效率远高于单线程。
✅ 2. 两个内存泄漏的解决方案(代码里都做了,必记)
- 堆内存泄漏:用malloc传参,子线程里free释放;
- 线程资源泄漏:设置线程分离属性,线程退出自动回收资源。
✅ 3. TCP 和 HTTP 的关系(你这个代码完美体现)
- TCP 是传输层协议:负责建立可靠的连接、收发数据,是底层通信保障;
- HTTP 是应用层协议:是 TCP 之上的规则,规定了请求和响应的格式;
- 你的代码本质是:基于 TCP 协议实现了 HTTP 协议的核心规则。
✅ 4. 关键函数分类记忆
- TCP 服务器四件套:socket → bind → listen → accept
- 数据收发:recv 收数据、send 发数据
- 文件操作:open 打开、read 读取、close 关闭、lseek 计算大小
- 线程操作:pthread_create 创建、pthread_exit 退出
最后补充:运行前的准备工作(保证一次成功)
在你的目录 /home/stu/c2305/day22 下,创建一个测试的index.html文件,随便写内容就行:
cd /home/stu/c2305/day22
touch index.html
echo "<h1>我的HTTP服务器运行成功!</h1><p>这是我的第一个网页</p>" > index.html
写完后浏览器访问 http://127.0.0.1,就能看到页面了!
测试:
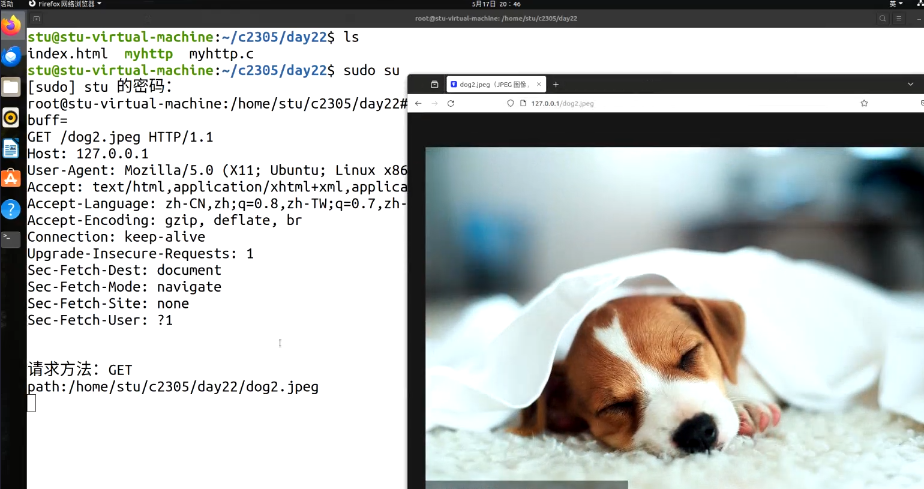
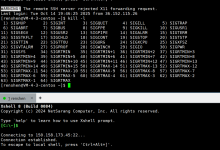
一、测试过程(步骤清晰)
- 接收浏览器的 HTTP 请求(GET /dog2.jpeg HTTP/1.1);
- 解析出文件路径 /dog2.jpeg,拼接为完整路径 /home/stu/c2305/day22/dog2.jpeg;
- 打开图片文件,计算大小、构造 HTTP 响应头、发送文件内容;
二、终端日志解析(每一行的含义)
plaintext
buff=GET /dog2.jpeg HTTP/1.1… # 服务器收到浏览器的HTTP请求,请求方法是GET,目标资源是/dog2.jpeg
请求方法: GET # 解析出请求方法为GET
path:/home/stu/c2305/day22/dog2.jpeg # 拼接后的完整图片路径
这些日志对应代码中的 printf 输出,证明服务器成功解析了请求并定位到了图片文件。
三、核心验证点(服务器的能力升级)
- 原代码只能返回 HTML 文件,这次测试验证了:服务器支持返回任意静态资源(图片、CSS、JS 等),只要资源在根目录下,浏览器就能正确请求并渲染;
- 本质原因:HTTP 响应头中的 Content-Length 只负责告诉浏览器「资源大小」,不限制资源类型,浏览器会根据文件后缀自动识别并渲染(如.jpeg会识别为图片)。
四、为什么能成功显示图片?
服务器的处理逻辑对所有静态资源通用:




评论前必须登录!
注册