 网硕互联帮助中心
网硕互联帮助中心引言
在学习数据结构时,链表通常是我们学习的第一个链式存储的结构。在学习书本上的内容时,我们常见的是节点包裹着数据的方式,这样写逻辑上很直观。但是当真正查阅 Linux 内核源码,看到那个只有指针,不包含任何数据的list_head时,才发现我们从书本上学的链表和真正投入使用的链表实际上还是有一定差距的。
那么内核为什么没有使用我们常见的那种链表结构,而采用了这种 “侵入式” 的设计呢?又是如何在不分配额外内存的情况下,用一套代码管理成千上万种不同的数据?想要回答这个问题,我们首先要学好书本上的链表结构,这是一切的基础,还要将数据结构与 Linux 内核源码融合起来学习,这样才能理解书本上的数据结构在实际中是怎么应用的。
这篇文章是我的学习笔记,我不打算堆放一大堆枯燥的概念,但会写的尽量易懂一点,一些基础内容还是会简单提一下。我会从最基础的链表的 C 语言实现,一步步过渡到内核的链表设计,同时会写一些我自己的理解,尤其是在指针操作那部分。
1. 链表简单介绍
在系统学习链表之前,我们先回顾一下链表的相关知识,这里我不是用教科书上的枯燥定义,而是使用通俗易懂的语言描述一下。
1.1 链表存在的意义
在 C 语言中,数组是最常使用的数据结构,但他有个致命的弱点:太死板了。
数组中的元素在内存中占据一块连续的空间,好处是我们只需要知道相应元素的索引就能轻而易举的找到这个元素。
但缺点就很多了,第一,数组在定义时就必须要确定它的大小,但是我们需要使用的空间往往是动态变化的,因此,要确定数组的大小其实是一件并不容易的事情,太大了浪费空间,太小了存满又是一件麻烦事。第二,如果前面已经在数组中存放了一些元素,现在需要在已经存放好的元素中间的某个位置插入一个新的元素,我们先要把要插入新元素的位置后面的元素挨个往后移动一位,然后才能把这个元素放进去。要删除数组中的一个元素,同样,删除这个元素后,后面的所有元素都要往前移动一位。
这在实际操作过程中是相当麻烦的,并且运行的效率也很低,时间复杂度很高。
而链表正是为了解决这个问题而诞生的,它的每个节点在内存中是分散开存储的,每个节点中都存放着前后两个节点的位置信息。
如果要增加一个新节点,只需要改变前后两个节点中存放的位置信息就行了。而且它是动态可扩展的,用多少就申请多少,删除节点后顺便释放内存,这样不会造成内存的浪费。
1.2 链表的容器式设计
在教科书中,我们通常看到的是容器式的设计思路。简单来说,就是节点结构体把数据包裹在里面。
用一个最常见的例子,假设我们要使用双向链表管理一个学生信息系统,包含 ID 和姓名,我们通常这样定义结构体:
typedef struct StudentNode {
//数据域,我们要管理的实际数据
int id;
char name[32];
//指针域,用来连接各个节点
struct StudentNode *prev; // 指向前一个节点
struct StudentNode *next; // 指向后一个节点
} StudentNode;
这样看起来是非常符合直觉的,节点就是数据,数据就是节点。
它的内存模型图如下:

图中我只画了四个节点,其中 Node A 和 Node D 分别是头结点和尾节点,头结点的 prev 指针为 NULL ,尾节点的 next 指针为 NULL,这时符合常识的,代表头结点的前面和尾节点的后面都没有节点。
其余节点中,他们的prev指针都指向前一个节点,next指针都指向后一个节点。在上面的结构体定义中我们也可以看到,prev 和 next 指针的数据类型都是struct StudentNode *,说明这两个指针指向的都是完整的节点。
图中的折线箭头是为了方便理解加上去的,实际中,两个逻辑上的相邻的节点可能在内存中相距了十万八千里,举个例子:
Node A: 0x00007FFF5FBFF820
Node B: 0x0000558A7C241E90
Node C: 0x00007FFF5FBFF340
Node D: 0x0000558A7C242150
假设我们程序运行的某个时刻,操作系统给这四个节点分配的实际内存地址可能是这样的,如上面代码块所示,这些地址是我随意编的,但实际上操作系统分配地址时也是无逻辑可言的。
拿 Node A 和Node B来看,它们之间可能相隔几 MB 甚至几十 MB 的地址空间,中间不知道夹杂了多少别的变量,但这完全不影响链表的正常使用。因为链表根本不依赖地址连续,它只依赖每个节点里保存的前一个节点地址和后一个节点地址,通过这个地址再去找别的节点。
他们的节点地址与指针指向的地址的关系如下:
Node A(头结点)
地址:0x00007FFF5FBFF820
prev = NULL
next = 0x0000558A7C241E90 指向 Node B 的真实地址
Node B
地址:0x0000558A7C241E90
prev = 0x00007FFF5FBFF820 指回 Node A
next = 0x00007FFF5FBFF340 指向 Node C 的真实地址
Node C
地址:0x00007FFF5FBFF340
prev = 0x0000558A7C241E90
next = 0x0000558A7C242150
Node D(尾结点)
地址:0x0000558A7C242150
prev = 0x00007FFF5FBFF340
next = NULL
到这里,相信大家应该都能明白在链表中,各个节点的前驱和后继指针与节点地址之间的关系了。
1.3 数组与链表总结
经过上面分析,我们知道了,数组是依靠位置连续和偏移量计算来实现快速定位一个元素的。而链表靠的是每个节点记住自己相邻节点的地址来实现将所有节点串联起来的。
所以即使 Node A 和 Node B 的地址差了十万八千里,只要它们互相指着对方,逻辑上它们就是相邻的节点,遍历、插入、删除时都不会有任何问题。
这正是链表最核心的的思想,也是它能做到任意位置高效增删的根本原因,当然,代价就是随机访问变得非常慢,必须从头节点或者尾节点开始一个一个顺着指针走过去才能找到目标位置,这也就是课本上反复强调过的——链表擅长插入删除,不擅长随机访问。
2. 双向链表的 C 语言实现
在学习内核中的链表之前,我们需要先回到用户态,用标准 C 语言写一个双向链表。其一,能复习一下链表相关的知识,如果没接触过链表在这里也可以先学习一下链表的常规实现,其二,这还能让我们清楚当不使用内核提供的工具时,我们需要怎样管理数据。
2.1 创建节点
链表和数组最大的区别在于内存的动态分配。数组是静态的,在定义时一次性分配固定大小的内存,而链表节点是用的时候才向操作系统申请。
该操作的实现代码如下:
StudentNode *create_node(int id, const char *name)
{
StudentNode *new_node = (StudentNode *)malloc(sizeof(StudentNode));//为要创建的新节点申请内存
if(new_node == NULL)
{
printf("内存分配失败\\n");
return NULL;
}
//一定要分配内存后再初始化数据域,否则会发生段错误
new_node->id = id;
strcpy(new_node->name,name);//使用strcpy来拷贝字符串
//这是创建的一个新节点,他的前驱和后继指针都为NULL
new_node->prev = NULL;
new_node->next = NULL;
return new_node;//返回指向这个新创建的节点的指针
}
先来看看这个用来创建节点的函数怎么使用,我们要传入两个参数,分别是学生 id 和学生姓名,然后它会返回一个StudentNode *类型的值,这个值是一个指针,它指向我们要添加到双向链表中的新节点。
再来看看这个函数的具体实现。
函数在执行时,首先一定要为这个新节点分配内存,如果我们只是定义了一个StudentNode *new_node,而不给它分配内存,这个时候 new_node 只是一个野指针,它的值是未定义的,根本没有指向任何合法的内存区域。如果这时像上面的代码块中操作id和name这两个成员,程序几乎百分之百会崩溃,发生段错误。因为正在试图往一个根本不存在的,或者没有权限访问的内存地址里写东西。
再来看malloc的函数原型:
void *malloc(size_t size);
我们要传入的参数类型是size_t,也就是一个单位为字节的值,如果我们要申请 8 个字节的内存,那就传入 8。
它的返回值是void *类型,在现代 C 语言中,void * 可以自动隐式转换为任何指针类型,所以通常可以直接赋值给 StudentNode *类型的变量 ,不过很多教材和老代码里仍然会写上 StudentNode * 显式转换,这两种写法在 C 语言里都是合法的。
然后,在申请内存之后,一定要检查一下内存是否分配成功,如果没有分配成功,还要去操作结构体成员,那一样会触发段错误。
在保证了内存分配成功之后,我们将前面通过函数传参得到的id和name赋值给这个节点结构体的对应成员。id直接进行赋值就行了,没什么需要注意的。但是name的值是一个字符串,我们结构体里定义的是一个固定长度的字符数组 char name[32],因此,像下面这样写是错误的:
new_node->name = name;
我们仔细来分析一下这行代码为什么是错的,等号左边 new_node->name 是一个数组类型即char[32],等号右边 name 是一个 const char *类型的值。数组类型是不能直接赋值的,C 语言不允许把一个数组整体赋值给另一个数组,也不能把指针赋值给数组,因为类型是不匹配的。
因此,我们要使用字符串拷贝函数,把内容一份一份复制过来,这样节点就拥有了自己独立的字符串副本。
再看后面的代码,将这个新节点的前驱指针和后继指针都设为 NULL ,因为这里我们只是先把这个节点创建出来,具体的指针操作要在将这个节点插入到链表里面的时候实现。
最后,将这个新节点返回出去。
2.2 从头部插入
这是构建链表最简单的方式,新来的节点总是在最前面。代码实现如下:
//在链表头部插入一个新节点
void insert_at_head(StudentNode **head_ptr,StudentNode *new_node)//第一个参数是指向头指针的指针,是个二重指针
{
//如果链表为空
if(*head_ptr == NULL)
{
*head_ptr = new_node;
return;
}
//如果链表不为空
new_node->next = *head_ptr;
(*head_ptr)->prev = new_node;
*head_ptr = new_node;//更新头指针,让他指向新的头节点
}
这个函数我们把它返回值设为空,如果想插入后检测是否成功,设置为int类型的也是可以的。
由于我们这里是头插法,也就是说插入之后头结点会发生变化,原来的头结点会变成第二个节点,而新插入的节点会变成新的头节点,因此,我们需要改变头结点指针的指向,这也是为什么我们传入的第一个参数是指向头结点指针的指针,是个二重指针,这样能保证我们修改的确实是头结点指针本身的指向。如果这里把头节点指针传进来,也就是一级指针,对他进行修改时修改的只是头结点指针的复印件,而头结点指针的真身还是原来的样子,并没有改变,也就是说头结点指针还是指向原来的头结点,也就是现在的第二个节点。
我们要传入的第二个参数是一个StudentNode *类型的变量,也就是上面新创建的节点,我们要把这个新创建的节点插入到链表的最前面。
再来看函数内部,我们在进行插入之前首先要判断这个链表是否为空,也就是看看这个链表是不是一个节点都没有,如果这个链表为空,那么我们即将插入的这个新节点就是链表唯一的一个节点,也就是头节点,我们直接让头结点指针指向它就行了。这里要注意,我们传进来的是指向头节点指针的指针,也就是二级指针,我们要改变头节点指针的指向就要先对它进行解引用。改变头节点指针的指向之后就什么也不用做了,因为这是链表唯一的一个节点,它既没有前驱结点,有没有后继节点,所以它的prev和next指针为NULL就可以了。
如果链表不为空的话,由于是头插法,我们要插入的这个新节点它没有前驱节点,但是有一个后继节点,也就是原先的头节点。我们首先要做的是让这个新节点的next指针指向原先的头结点,代码中是new_node->next = *head_ptr,翻译过来就是让新节点的next指针指向原先头节点指针指向的节点,也就是原先的头节点。
我们知道,原先的那个头节点,它是没有前驱节点的,也就是说它的prev指针为NULL,但是当我们将这个新节点插入之后,他就有前驱结点了,所以我们得让它的prev指针指向我们新插入的节点,代码实现是(*head_ptr)->prev = new_node。
最后我们需要更新头节点指针的指向,让它指向我们新插入的节点,也就是新的头节点。
2.3 从尾部插入
有时候我们需要保持数据的顺序的先来后到,这时就需要尾部插入,即后插入的节点在最后面。
void insert_at_tail(StudentNode **head_ptr,StudentNode *new_node)
{
//如果链表为空
if(*head_ptr == NULL)
{
*head_ptr = new_node;
return;
}
//如果链表不为空
StudentNode *current = *head_ptr;
while(current->next != NULL)//先遍历找到最后一个节点
{
current = current->next;
}
current->next = new_node;
new_node->prev = current;
new_node->next = NULL;
}
函数的返回值和参数与前面是相同的,就不再多讲了。
直接看函数内部,如果链表为空,我们依然让头节点指针指向这个新插入的节点,和前面的情况也是一样的。
如果链表不为空,这里我们需要先遍历找到最后一个节点,在进行插入操作。我们首先定义一个StudentNode *类型的变量current,让它指向头节点。然后利用while循环进行遍历,只要current所指向的节点的next指针不为NULL,那么就让current指向该节点的下一个节点,一直循环,直到current指针指向最后一个节点,也就是尾节点,我们知道,尾节点的next指针为NULL,因此,到这里就会跳出while循环,我们也就找到了最后一个节点。
找到最后一个节点之后,我们下面就要把新节点插入进去了。当前,current指针是指向原本的最后一个节点的,我们新插入的节点要放在这个节点后面,因此要把原本最后一个节点的next指针指向新节点new_node,再让new_node这个新的尾节点的prev指针指向它的前驱节点,也就是原来的尾节点,即current指向的节点。最后,new_node作为新的尾节点,把他的next指针设为NULL就好了。
2.4 查找节点
查找本质上就是一次遍历,这里我们从头节点开始遍历。
StudentNode *find_node(StudentNode *head,int id)
{
StudentNode *current = head;
while(current != NULL)
{
if(current->id == id)
{
return current;
}
current = current->next;
}
return NULL;
}
查找某个节点时,我们需要传入链表的头结点指针和要查找的节点的 id 成员。函数执行完后会返回指向该节点的指针。
函数内部,我们首先定义一个current指针并让它指向头节点。
然后执行while循环,当current指针指向的节点不为NULL时,进行if判断,看看该节点的id成员和通过参数传递进来的id是否相同,如果相同,那就返回该节点的指针,如果不相同,那就让current指向该节点的下一个节点。
如果遍历完整个链表都没有找到,那就返回NULL,表示要查找的节点不存在。
2.5 删除节点
删除是链表操作中最容易出错的地方,因为它涉及到节点前后指针的断开与重连,必须处理好所有可能出现的边界情况。
//删除节点
void delete_node(StudentNode **head_ptr,int id)
{
StudentNode *node_to_delete = find_node(*head_ptr,id);
if(node_to_delete == NULL)//如果没有找到这个节点就返回
{
printf("你希望删除的节点(id = %d)不存在\\n",id);
return;
}
//如果要删除的节点是头节点
if(*head_ptr == node_to_delete)
{
*head_ptr = node_to_delete->next;//把头节点指针移到下一个节点
}
if(node_to_delete->prev != NULL)//如果节点的前驱指针不为空
{
node_to_delete->prev->next = node_to_delete->next;
}
if(node_to_delete->next != NULL)//如果节点的后继指针不为空
{
node_to_delete->next->prev = node_to_delete->prev;
}
printf("成功删除节点 [ID:%d, Name:%s],并释放内存\\n",node_to_delete->id,node_to_delete->name);
free(node_to_delete);
}
由于删除节点这个操作可能需要改变头结点指针的指向,所以我们需要传入指向头结点指针的指针,此外,还需要传入想要删除的节点的id成员。返回值类型是void。
函数内部,我们首先需要找到要删除的节点,直接使用前面的查找函数就可以了。然后判断一下,看看这个要删除的节点是否存在。
如果存在,下面要进行就是各种边界条件的判断了。
我们首先看看要删除的节点是不是头结点,如果是头节点,我们就让头节点指针指向头节点的下一个节点。
我们再来看看要删除的节点的prev指针是否为NULL,如果不为NULL,那就让该节点的前面一个节点的next指针指向该节点的后一个节点。
然后再看要删除节点的next指针是否为NULL,如果不为NULL,就让该节点下一个节点的prev指针指向该节点的前一个节点。
最后释放要删除的节点占用的空间。
下面我画个图来描述一下整个删除过程:

如图,这个链表现在只有三个节点,A 和 C 分别是头节点和尾节点,B 是中间节点。head_ptr是一个二级指针,它是一个指向头结点指针的指针,* head_ptr就是一级指针,它指向头结点,如图中画的那样。
假如我们要删除的节点是 B,如下图:
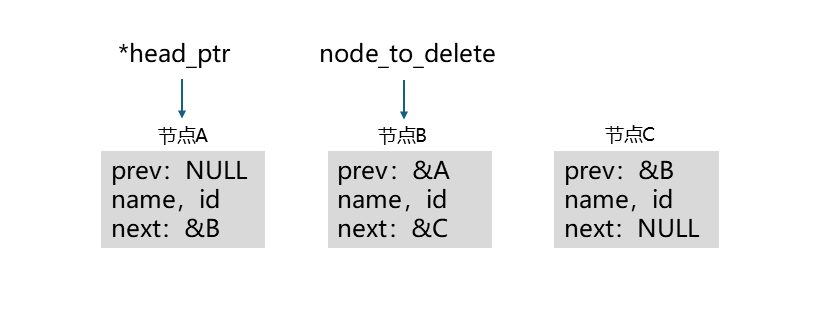
我们首先要判断* head_ptr和node_to_delete指向的是不是同一个节点,这里显然不是。
然后我们要判断node_to_delete指向的节点的prev是否为NULL,这里prev为&A,不为NULL。if条件成立,我们需要执行下面语句:
node_to_delete->prev->next = node_to_delete->next
执行后的结果如下图所示:
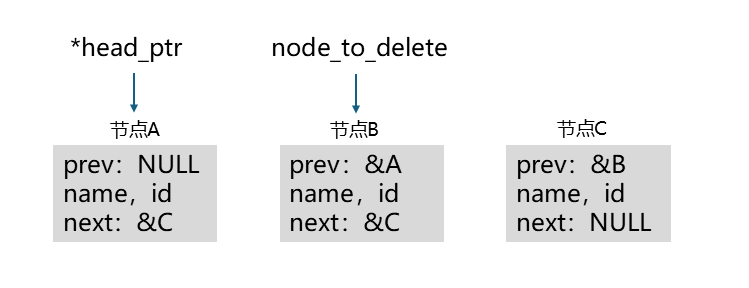
然后要判断node_to_delete指向的节点的next指针是否为NULL,这里next为&C,不为NULL,if条件成立,执行下面语句:
node_to_delete->next->prev = node_to_delete->prev;
执行后结果如下:
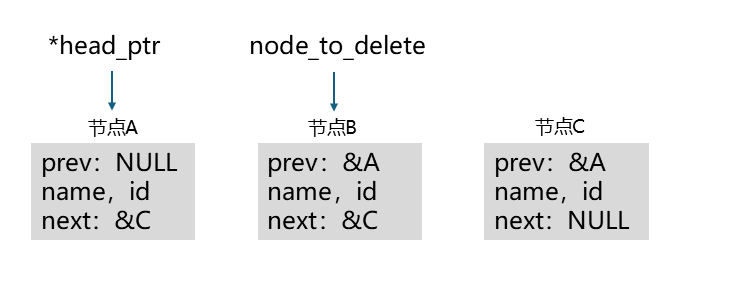
至此,节点 A 和节点 C 已经绕过节点 B 连接上了。
然后我们释放节点 B 占用的内存:

删除操作完成,节点 B 彻底消失。
这里我只是用节点 B 举个例子,如果用节点 A 和节点 C 的话效果也是相同的,大家可以按照这个流程推一下节点 A 和节点 C 的代码执行过程。
2.6 打印链表内容
代码如下:
void print_list(StudentNode *head)
{
printf("链表内容如下:\\n");
StudentNode *current = head;
while(current != NULL)
{
printf("[ID]:%d [姓名]:%s\\n",current->id,current->name);
current = current->next;//每次打印完成,就让current指向他的下一个节点
}
printf("打印完毕\\n\\n");
}
这个函数由于不需要改变链表本身的结构,所以只需要传头指针就行了,不需要像前面那样把指向头指针的指针传进来。
这里我们定义了一个StudentNode *类型的指针current来进行遍历,让它先指向头节点。
然后执行while循环,只要current不为NULL,就打印它指向的节点的id和name,然后让current指向下一个节点。
这里还有一点需要提一下,实际上我们直接使用函数传进来的参数head进行遍历也是可以的,因为C 语言函数传参的一个核心机制是值传递。head的本体是在main函数里面的,我们把它传给函数print_list,只是将head复制了一份传进去,而在函数里面对他进行修改,实际上改变的只是这个复制品的值,原本的head的值是不会改变的。所以,这里直接使用head进行遍历是完全可以的。
但是习惯上,我们通常定义一个current来接收head的值,head语义上表示指向头节点的指针,current表示指向正在处理的节点的指针,这是符合我们语言逻辑的。
2.7 整表释放
程序结束时,必须释放所有申请的内存,否则就会造成内存泄漏。代码如下:
void free_list(StudentNode **head_ptr)//传入指向头节点指针的指针
{
StudentNode *current = *head_ptr;
StudentNode *next_node;
while(current != NULL)
{
next_node = current->next;
free(current);
current = next_node;
}
*head_ptr = NULL;
printf("链表释放完成\\n\\n");
}
我们释放整个链表内存时需要传入指向头节点指针的指针,这才能改变真实头结点指针的值,否则改变的还是副本。
此外,由于我们释放顺序是从前往后释放,但是实际上释放掉前一个节点后,就找不到它后面的节点了,所以我们除了需要指向当前正在处理的节点的指针current之外,还需要一个指向该节点下一个节点的指针next_node。
然后执行while循环,当current指针不为NULL时,执行循环体里面的内容,先让next_node指向当前正在处理的节点的下一个节点,然后释放掉正在处理的节点,最后再让current指向next_node指向的那个节点。这样一轮循环就完成了,一直循环,就可以释放掉所有的节点。
最后我们把头节点指针置为NULL,防止野指针。
下面我画图来描述一下整个释放流程,在进入while循环之前,如下图:
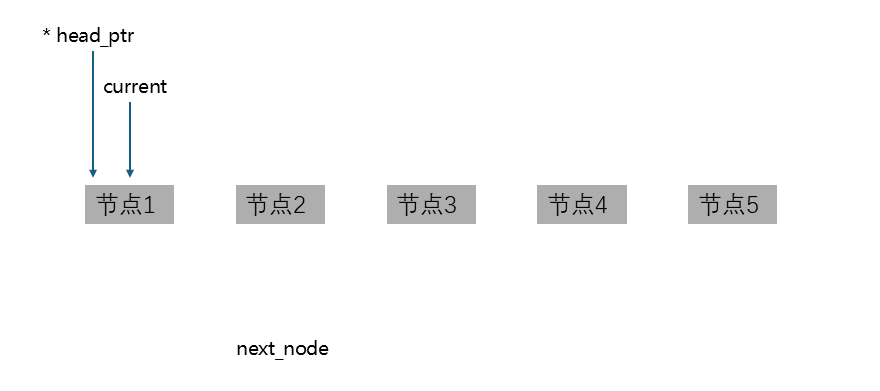
此时,current指向头节点,next_node还未指向任何节点。
进入while循环之后,next_node先指向current所指向节点的下一个节点:
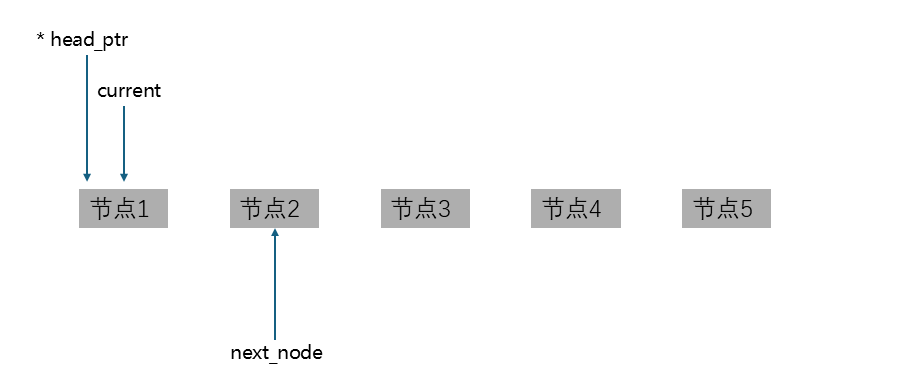
现在我们已经记住了,下一个节点的位置,就可以把current指向的节点释放了:
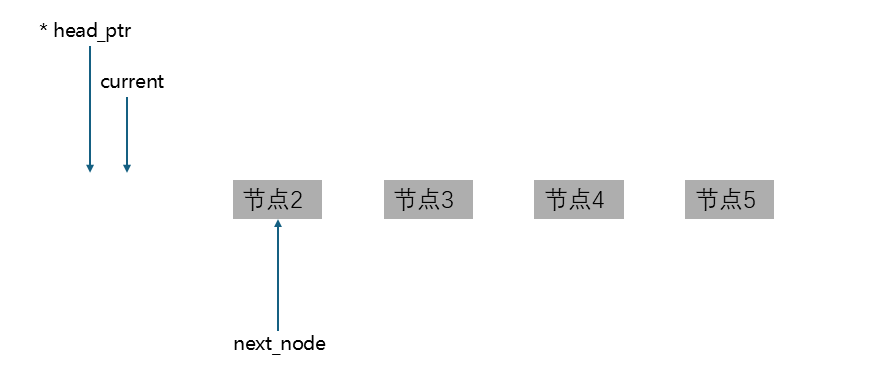
然后再让current指向next_node指向的那个节点:
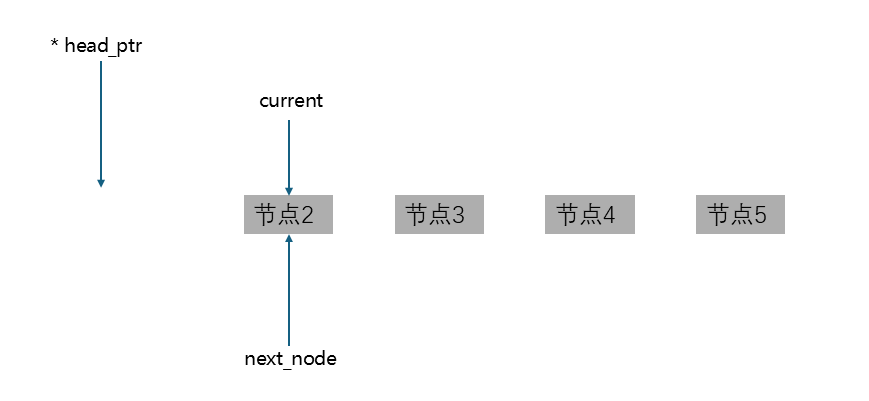
循环往复,最后所有的节点都会被释放,current和next_node也都会指向尾节点的next指针指向的位置,也就是NULL。
但还有一个问题,就是*head_ptr还指向原来的位置,但是这个位置已经被释放了,所以我们要把他置为NULL,否则它会变成野指针。
到这里,双向链表的 C 语言实现的基本操作我们基本都熟悉了,下一章我们会使用这个双向链表写一个微型的学生信息管理系统。
3. C语言双向链表实战
上一章我们学习了双向链表的基本操作的实现,这一章我们直接用起来。
完整代码如下:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#define NAME_SIZE 32
typedef struct StudentNode{
int id; //学生id
char name[NAME_SIZE]; //学生姓名
struct StudentNode *prev; //指向前一个节点
struct StudentNode *next; //指向下一个节点
}StudentNode;
//创建一个节点
StudentNode *create_node(int id, const char *name)
{
StudentNode *new_node = (StudentNode *)malloc(sizeof(StudentNode));//为要创建的新节点申请内存
if(new_node == NULL)
{
printf("内存分配失败\\n");
return NULL;
}
//一定要分配内存后再初始化数据域,否则会发生段错误
new_node->id = id;
strcpy(new_node->name,name);//使用strcpy来拷贝字符串
//这是创建的一个新节点,他的前驱和后继指针都为NULL
new_node->prev = NULL;
new_node->next = NULL;
return new_node;//返回指向这个新创建的节点的指针
}
//在链表头部插入一个新节点
void insert_at_head(StudentNode **head_ptr,StudentNode *new_node)//第一个参数是指向头指针的指针,是个二重指针
{
//如果链表为空
if(*head_ptr == NULL)
{
*head_ptr = new_node;
return;
}
//如果链表不为空
new_node->next = *head_ptr;
(*head_ptr)->prev = new_node;
*head_ptr = new_node;//更新头指针,让他指向新的头节点
}
//在链表尾部插入一个新的节点
void insert_at_tail(StudentNode **head_ptr,StudentNode *new_node)
{
//如果链表为空
if(*head_ptr == NULL)
{
*head_ptr = new_node;
return;
}
//如果链表不为空
StudentNode *current = *head_ptr;
while(current->next != NULL)//先遍历找到最后一个节点
{
current = current->next;
}
current->next = new_node;
new_node->prev = current;
new_node->next = NULL;
}
//查找节点
StudentNode *find_node(StudentNode *head,int id)
{
StudentNode *current = head;
while(current != NULL)
{
if(current->id == id)
{
return current;
}
current = current->next;
}
return NULL;
}
//从头到尾打印整个链表,函数参数为头指针
void print_list(StudentNode *head)
{
printf("链表内容如下:\\n");
StudentNode *current = head;
while(current != NULL)
{
printf("[ID]:%d [姓名]:%s\\n",current->id,current->name);
current = current->next;//每次打印完成,就让current指向他的下一个节点
}
printf("打印完毕\\n\\n");
}
//删除节点
void delete_node(StudentNode **head_ptr,int id)
{
StudentNode *node_to_delete = find_node(*head_ptr,id);
if(node_to_delete == NULL)//如果没有找到这个节点就返回
{
printf("你希望删除的节点(id = %d)不存在\\n",id);
return;
}
//如果要删除的节点是头节点
if(*head_ptr == node_to_delete)
{
*head_ptr = node_to_delete->next;//把头节点指针移到下一个节点
}
if(node_to_delete->prev != NULL)//如果节点的前驱指针不为空
{
node_to_delete->prev->next = node_to_delete->next;
}
if(node_to_delete->next != NULL)//如果节点的后继指针不为空
{
node_to_delete->next->prev = node_to_delete->prev;
}
printf("成功删除节点 [ID:%d, Name:%s],并释放内存\\n",node_to_delete->id,node_to_delete->name);
free(node_to_delete);
}
//释放内存
void free_list(StudentNode **head_ptr)//传入头节点指针
{
StudentNode *current = *head_ptr;
StudentNode *next_node;
while(current != NULL)
{
next_node = current->next;
free(current);
current = next_node;
}
*head_ptr = NULL;
printf("链表释放完成\\n\\n");
}
int main()
{
StudentNode* head = NULL;
//准备一个链表
insert_at_tail(&head, create_node(104, "XLP4"));
insert_at_tail(&head, create_node(103, "XLP3"));
insert_at_tail(&head, create_node(102, "XLP2"));
insert_at_tail(&head, create_node(101, "XLP1"));
printf("初始链表:\\n");
print_list(head);
printf("测试1:删除节点(103)\\n");
delete_node(&head, 103);
print_list(head);
printf("测试2:删除头节点(104)\\n");
delete_node(&head, 104);
print_list(head);
printf("测试3:删除尾节点(101)\\n");
delete_node(&head, 101);
print_list(head);
printf("测试4:删除一个不存在的节点(999)\\n");
delete_node(&head, 999);
print_list(head);
printf("测试5:删除仅剩的一个节点(102)\\n");
delete_node(&head, 102);
print_list(head); // 此时应该没有内容
printf("释放链表\\n");
free_list(&head);
return 0;
}
代码中的所有函数都是我们前面详细解释过的,此外,我还编写了一个main函数用来测试,都是一些很基础的 C 语言操作,函数调用什么的,这里就不详细解释了。代码运行结果如下:


可以看到,已经运行成功了。
到这里,我们已经写出了一个比较健壮的双向链表。但是,如果内核中需要管理 100 种不同的对象(进程、文件、驱动等等),难道我们要把上面的代码复制粘贴 100 遍,然后把 StudentNode 改成 ProcessNode,或者FileNode 吗?
这种数据与链表逻辑强耦合的写法,在小规模程序中没问题,但在操作系统内核中是不可接受的。
下一章,我们将进入 Linux 内核来学习侵入式链表是如何解决这个问题的。
4. Linux 内核的侵入式链表
在上一章的结尾,我们提到了传统的容器式链表虽然直观,但它的通用性极差。
如果 Linux 内核沿用这种写法,每当开发者定义一个新的数据结构,就不得不为它专门写一套 insert, delete, search 函数,考虑到内核中包含成千上万种不同的数据结构,这种代码重复将会是灾难性的。
因此 Linux 内核的开发者们采用了一种别出心裁的设计思路,被称为侵入式链表。
4.1 核心定义
我们直接打开内核源码,看看内核标准的链表节点长什么样子,位置如下:
/include/linux/types.h
打开这个文件,我们可以看到下面的定义:

第一眼看上去给人一种简洁的美的印象,仔细观察一下,就会发现它与前面容器式链表的区别,他没有数据域,只有两个指向的数据类型为本身的指针。这就有一点反直觉了,一个不能存储数据的链表有什么用呢?
这正是我们需要转变观念的关键之处。对于传统的容器式链表,节点是主,数据是客,节点把数据包裹起来。而对于这种侵入式链表,数据是主,节点是客,节点嵌在数据结构内部。
4.2 内存布局
如果我们用内核的方式重写之前的 Student 结构体,它应该是这样的:
struct Student {
int id;
char name[32];
//链表节点只是学生结构体的一个成员变量
struct list_head list;
};
正如我们上一节所说的,链表节点嵌在数据结构的内部。
为了更直观地理解这种差异,我们对比观察一下侵入式链表和容器式链表的结构图:
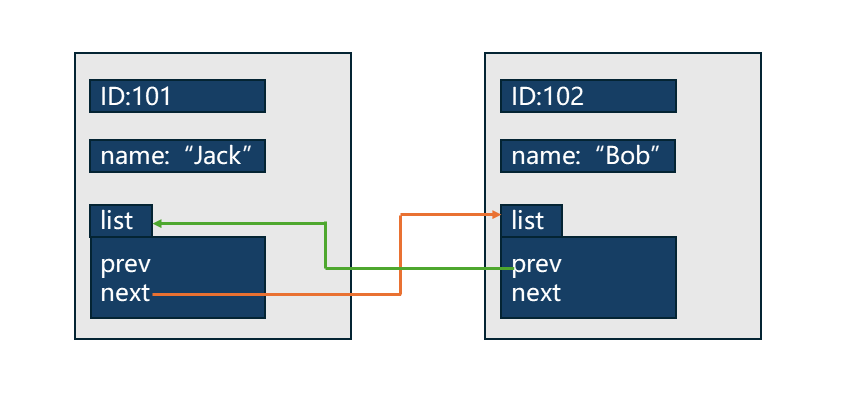
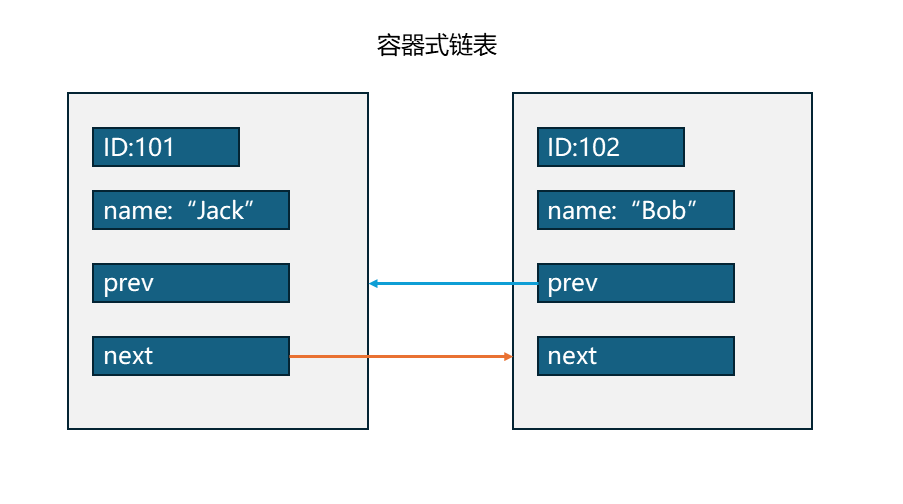
我们先看容器式链表,这在前面已经讲过很多了,最关键的是它的prev和next指针都是指向一整个节点的,而整个节点又包含数据域和指针域,整个节点就像是一个容器,里面装着数据和指针,这应该就是他这样命名的原因把。
再来看侵入式链表,如图,list结构体是内核标准的struct list_head结构体,内部有两个成员,即prev和next,这就是节点。再看整个大方框本身包含数据和这个节点,整个大方框就是数据结构,节点嵌在数据结构里面,这样一看,它名字叫做侵入式链表似乎也是有原因的。
最关键之处就是侵入式链表中prev和next指针的指向,这两个指针都是指向另一个数据结构中的节点,从内核源码中struct list_head的定义也可以看出来。
在学习侵入式链表时,会看到有一个流传很久的妙喻,它把整个数据结构比做一个书包,书包里面装的是数据,书包上还挂着一个钩子,这个钩子就是struct list_head,那么链表中节点的连接就可以比做是两个书包直接通过这个钩子进行连接。
到这里,我们基本已经明白了容器式链表和侵入式链表结构的区别了。
4.3 侵入式链表的优势
这种设计为内核带来了巨大的工程优势。
首先是极致的代码复用,因为 struct list_head 里只有指针,它不关心宿主是谁。内核只需要基于 struct list_head 写好一套 list_add, list_del 函数。那么无论是管理进程,还是管理文件 ,只要你的结构体里嵌入了 struct list_head,就可以直接使用这套标准的 API。
第二个优势是多重链表,这是侵入式链表最强大的地方,一个数据结构可以同时存在于多个不同的链表中。举个例子,一个学生既属于数学小组,又属于足球队,在传统链表中,可能需要复制两份学生数据放到两个不同的链表里,或者设计极其复杂的指针结构。
但在内核中,只需要这样写:
struct Student {
int id;
char name[32];
struct list_head math_group;
struct list_head soccer_team;
};
同一个学生对象,在内存里只有一份,但可以通过不同的挂钩被组织进完全不同的逻辑链表中,这在操作系统中管理进程状态时(既在运行队列,又在等待队列)非常关键。
4.4 一个新的问题
看到这里,一个新的问题有浮出水面了,既然链表里面连起来的都是list这个成员的地址,那么我们遍历时拿到的也是list的地址啊,怎样通过这个list的地址,来找到学生信息,也就是数据的地址呢?
在传统链表中,Node 节点内部本身就是数据,我们可以直接通过指针拿到节点,拿到节点就拿到了数据。但在内核链表中,我们手里只有 &Student.list,而我们想要的是 &Student。
这就引出了 Linux 内核中一个著名的宏—— container_of,我们将在下一章详细拆解它。
5. 解析 container_of
在上一章的结尾,我们面临着一个棘手的问题:在内核链表中,我们手中的指针指向的是结构体内部的 list 成员,而不是结构体本身的起始地址。
要想解决这个问题就得用到一个著名的宏—— container_of,它的功能也非常简单,就是通过容器内的一个成员找到这个容器本身。
5.1 结构体的存储特点
在 C 语言中,结构体在内存中是连续存储的。
让我们回到前面的那个例子:
struct Student {
int id; //偏移量 0
char name[32]; //偏移量 4
struct list_head list; //偏移量 36 (4 + 32)
};
假设有一个Student类型的变量s1,它在内存中的起始地址是 1000 ,那么它的所有成员在内存中的地址就是确定的:
s1.id 的地址 :1000 + 0 = 1000
s1.name 的地址 :1000 + 4 = 1004
s1.list 的地址 :1000 + 4 + 32 = 1036
现在,我们在遍历链表时,拿到的指针ptr的值是 1036 ,也就是&s1.list,我们想得到s1的起始地址,该怎么做?
这其实就是一个简单的减法题:
结构体起始地址 = 成员变量地址 – 该成员的偏移量
1000 = 1036 – 36
这就是 container_of的全部秘密。
5.2 container_of 的实现原理
在详细学习这个宏之前,我们需要先看看它长什么样,大家可以在内核源码中下面这个目录找到这个宏:
include/linux/kernel.h
如下图:
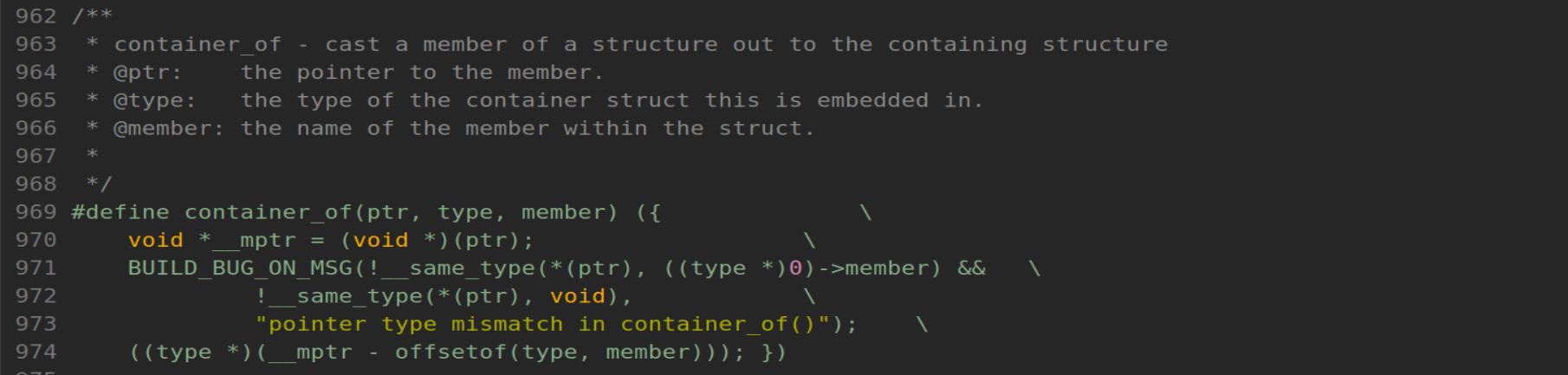
第一眼看上去,可能会觉得太复杂了,但是实际上,就像上面讲的那样,他只是完成了一个减法的操作。
我们先来看看这个宏的外壳:
#define container_of(...) ({ ... })
这不是标准的 C 语言,这是 GNU C 的扩展语法,叫做语句表达式。它允许你在宏里面写多行代码,最重要的是它会把最后一行语句的值,作为整个宏的返回值。
再来看 970 行:
void *__mptr = (void *)(ptr);
它把传进来的指针 ptr,先赋值给一个临时的 void * 指针,名字叫 __mptr。
第 971 到 973 行:
BUILD_BUG_ON_MSG(!__same_type(*(ptr), ((type *)0)->member) && \\
!__same_type(*(ptr), void), \\
"pointer type mismatch in container_of()");
这实际上是一个编译时断言,用来判断传进来的这个指针 ptr 的类型,和结构体里那个成员 member 的类型是不是同一个类型,如果不是同一个类型,在编译时就会报错并显示双引号里面的警告信息。
第 974 行:
((type *)(__mptr – offsetof(type, member)));
这才是真正发挥作用的内容。__mptr是我们手里拿到的指针,也就是前面提到的list的地址,offsetof(type, member)是list成员距离Student头部的偏移量。
__mptr – offsetof(type, member)就是上面公式里面的内容,即成员变量地址 – 该成员的偏移量。
(type *)会把最后算出来的地址,强制转换为Student *类型。
5.3 container_of 的用法
理解了原理之后,使用起来就非常简单了,这个宏需要传入三个参数:
第一个参数是ptr,它是我们手里的指针,指向成员变量。
第二个参数是type,它是宿主结构体的类型。
第三个参数是member,它是这个成员变量在结构体里面的名称。
对应到我们上面的例子里面:
struct Student {
int id;
char name[32];
struct list_head list; //成员变量名 list
};
// 假设 ptr 是我们得到的一个指向 struct list_head 的指针
// 此时,我们想找回 Student 结构体
struct Student *s = container_of(ptr, struct Student, list);
这样,我们就通过结构体的成员list,得到了这个结构体的起始地址。
6. 编写一个并发安全的字符设备驱动
到这里我们已经洞悉了内核链表的设计原理,现在是时候进入真正的内核态编写程序了。
我们将构建一个字符设备驱动模块,他可以通过字符设备接口(/dev/mylist),让用户空间程序能直接写入数据,并使用内核链表动态管理这些数据,此外,还引入了互斥锁,确保即使有多个进程同时疯狂写入,链表也不会崩溃。
6.1 完整代码详解
这里先直接给出完整的代码。
#include <linux/module.h> //所有模块都需要这个
#include <linux/kernel.h> //printk函数和container_of宏
#include <linux/init.h> //module_init和module_exit
#include <linux/list.h> //内核链表
#include <linux/slab.h> //kmalloc,kfree
#include <linux/fs.h> //包含文件操作相关的结构体
#include <linux/uaccess.h> //包含copy_from_user
#include <linux/miscdevice.h> //包含miscdevice结构体
#include <linux/mutex.h> //互斥锁
//定义数据结构
struct my_node {
int val;
struct list_head list;
};
static LIST_HEAD(my_list_head); //链表头
static DEFINE_MUTEX(my_mutex); //定义并初始化一把互斥锁
//核心功能是当用户写入数据时,内核会调用这个 write 函数
static ssize_t my_driver_write(struct file *file, const char __user *buf, size_t count, loff_t *ppos)
{
char kbuf[32]; //定义一个内核缓冲区
int user_val;
struct my_node *node;
//防止写入太长的数据导致溢出
if (count >= sizeof(kbuf))
{
return –EINVAL;
}
// 从用户空间拷贝数据到内核空间,成功返回0,失败返回未拷贝的字节数
if (copy_from_user(kbuf, buf, count))
{
return –EFAULT;
}
kbuf[count] = '\\0'; //字符串结束符
//将字符串"123\\n" 转换成整数 123
if (kstrtoint(kbuf, 10, &user_val))
{
return –EINVAL;
}
//典型的链表操作
node = kmalloc(sizeof(struct my_node), GFP_KERNEL);
if (!node)
{
return –ENOMEM;
}
node->val = user_val;
INIT_LIST_HEAD(&node->list);//到这里依然是线程私有的,不需要加锁进行保护
mutex_lock(&my_mutex);//这里加锁
list_add_tail(&node->list, &my_list_head); //插入链表
printk(KERN_INFO "[CharDriver] 收到用户数据: %d, 已加入链表\\n", user_val);
mutex_unlock(&my_mutex);//这里解锁
return count; //告诉系统处理了多少数据
}
//定义文件操作集合,把函数绑定到系统调用上
static const struct file_operations my_fops = {
.owner = THIS_MODULE,
.write = my_driver_write, // 绑定write操作
};
//定义杂项设备结构体
static struct miscdevice my_misc_dev = {
.minor = MISC_DYNAMIC_MINOR, // 自动分配次设备号
.name = "mylist", // 设备节点名称: /dev/mylist
.fops = &my_fops, // 绑定上面的操作集合
};
//模块加载
static int __init my_driver_init(void)
{
int ret;
//注册杂项设备
ret = misc_register(&my_misc_dev);
if (ret)
{
printk(KERN_ERR "无法注册杂项设备\\n");
return ret;
}
printk(KERN_INFO "[CharDriver] 模块加载成功!请查看 /dev/mylist\\n");
return 0;
}
//模块卸载
static void __exit my_driver_exit(void)
{
struct my_node *ptr, *tmp;
//注销设备
misc_deregister(&my_misc_dev);
//清理链表内存
list_for_each_entry_safe(ptr, tmp, &my_list_head, list)
{
printk(KERN_INFO "[CharDriver] 删除节点: %d\\n", ptr->val);
list_del(&ptr->list);
kfree(ptr);
}
printk(KERN_INFO "[CharDriver] 再见!\\n");
}
module_init(my_driver_init);
module_exit(my_driver_exit);
MODULE_LICENSE("GPL");
MODULE_AUTHOR("XLP");
下面详细讲解一下这段代码,从我们定义的数据结构开始。
6.1.1 数据结构定义
我们定义的数据结构中,存储的数据是一个int类型的val,另一个就是内核标准的挂钩。
6.1.2 LIST_HEAD 宏
下一行代码是定义链表头:
static LIST_HEAD(my_list_head);
这个宏定义在内核源码目录include/linux/list.h中可以找到,如下图:

因此,这个宏就相当于:
struct list_head my_list_head = { &my_list_head, &my_list_head };
这行代码定义了一个list_head类型的变量my_list_head,并将他的两个成员next和prev都赋值为&my_list_head,也就是说初始化后,这两个指针都指向这个结构体本身。这是内核中的惯用做法,这样初始化无论链表是不是空的,我们在插入时都不需要进行判断。
6.1.3 DEFINE_MUTEX 宏
static DEFINE_MUTEX(my_mutex);
这个宏展开后,定义了一个名为my_mutex的互斥锁,并初始化为未上锁的状态。
6.1.4 函数 my_driver_write
当在用户空间执行 echo "100" > /dev/mylist 时,内核就会自动调用这个函数。
char kbuf[32];
int user_val;
struct my_node *node;
kbuf数组是内核空间的临时缓冲区,用来接用户发来的字符串。user_val是解析出来的整数,由于接收到的是用户发来的字符串,这个变量用来存放由这个字符串解析出来的数字。node是指向新节点的指针。
if (copy_from_user(kbuf, buf, count))
{
return –EFAULT;
}
函数的参数 buf 是用户空间的指针,内核不能直接读写,这是因为内存隔离且不安全。我们需要用copy_from_user将数据从用户空间搬到内核空间的kbuf数组中。然后要手动加上字符串结束符。
if (kstrtoint(kbuf, 10, &user_val))
{
return –EINVAL;
}
kstrtoint 是内核版的 atoi,可以把字符串 "100" 转成整数 100。第二个参数10 表示十进制。
node = kmalloc(sizeof(struct my_node), GFP_KERNEL);
kmalloc 是内核版的 malloc。GFP_KERNEL 表示分配内存时,如果内存不够,允许内核进行睡眠等待,这是常规操作。
node->val = user_val;
INIT_LIST_HEAD(&node->list);
填入数据并初始化节点里面的挂钩。
mutex_lock(&my_mutex);
list_add_tail(&node->list, &my_list_head);
printk(KERN_INFO "[CharDriver] 收到用户数据: %d, 已加入链表\\n", user_val);
mutex_unlock(&my_mutex);
这里要往链表里面插入节点了,需要加锁。然后用printk向dmesg打印一个添加节点成功的消息。
6.1.5 设备注册信息
static const struct file_operations my_fops = {
.owner = THIS_MODULE,
.write = my_driver_write,
};
static struct miscdevice my_misc_dev = {
.minor = MISC_DYNAMIC_MINOR,
.name = "mylist",
.fops = &my_fops,
};
struct file_operations结构体用来管理文件操作的集合,它会告诉内核当用户对这个文件执行某种操作时,对应调用哪个函数。.owner = THIS_MODULE是固定写法,表示指向当前模块。.write = my_driver_write绑定了写操作,当用户对该文件执行写操作时会调用my_driver_write函数。这里没写 .read,所以用户读这个设备时会报错或读不到东西,因为压根就没有绑定相应的函数。
struct miscdevice是杂项设备结构体,可以自动帮我们管理设备号,.minor = MISC_DYNAMIC_MINOR让内核自动分配一个次设备号。.name = "mylist"是设备名字,加载该模块后会在 /dev/ 下生成 /dev/mylist。.fops = &my_fops绑定上面的操作集合。
6.1.6 模块加载与卸载函数
模块加载函数在insmod时调用,模块卸载函数在rmmod时调用。
int ret = misc_register(&my_misc_dev);
向内核注册这个杂项设备。
misc_deregister(&my_misc_dev);
从内核注销这个设备。执行后/dev/mylist 会消失。
list_for_each_entry_safe用来遍历链表清理内存,这个宏会在处理 ptr 之前,先把下一个节点保存到 tmp 里,这样即使我们 kfree(ptr) 删掉了当前节点,下一轮循环还能找到下一个要删除的节点。
6.1.7 宏标记
module_init(my_driver_init);
module_exit(my_driver_exit);
MODULE_LICENSE("GPL");
MODULE_AUTHOR("XLP");
前两行告诉内核入口和出口分别是哪个函数。第三行是许可证,必须为GPL,否则内核会报警。第四行是作者信息,引号里面想填什么都行。
6.2 编写Makefile
# 模块名称,对应 .c 文件名
obj-m += simple_char_drv.o
# 获取当前运行内核的路径
KDIR := /lib/modules/$(shell uname -r)/build
# 获取当前目录
PWD := $(shell pwd)
# 默认目标:编译模块
all:
make -C $(KDIR) M=$(PWD) modules
# 清理目标
clean:
make -C $(KDIR) M=$(PWD) clean
6.3 运行代码
我们在命令行执行下面命令,加载这个模块。
sudo insmod simple_char_drv.ko
然后查看内核日志的最后几行:
sudo dmesg | tail
结果如下,模块已经加载成功。

然后执行下面命令查看设备:
ls -l /dev/mylist

可以看到这个设备已经出现了。
这里我们使用下面命令为这个文件添加权限:
sudo chmod 777 /dev/mylist

然后向这个文件写入数据,并再次查看内核日志:
sudo echo "100" > /dev/mylist

可以看到,数据已经成功加入链表了。
可以多尝试写入几次,然后在卸载模块:
sudo rmmod simple_char_drv

可以看到,卸载模块时,我们的删除节点和释放内存操作也可以顺利执行。
7. 结语
到这里,整篇文章就结束了,从最开始复习教科书式的 C 语言双向链表,到深入 Linux 内核源码剖析 list_head 的侵入式设计,再到最后亲手实现一个带有互斥锁保护的字符设备驱动,这一路走来,我们跨越的不仅仅是用户态与内核态的界限,更是思维模式的蜕变。








评论前必须登录!
注册