 网硕互联帮助中心
网硕互联帮助中心一、模型介绍
OutsTTS是基于Qwen3 0.6B 构建的基础模型,经过持续的预训练和微调,主要用于克隆和合成语音,由英语、中文、荷兰语、法语、格鲁吉亚语、德语、匈牙利语、意大利语、日语、韩语、拉脱维亚语、波兰语、俄语、西班牙语训练而成,该模型设计用于与发言人参考一起使用。如果没有参考,它会生成随机的语音特征,通常会导致较低质量的输出。
该模型继承了参考发言人的感情、风格和口音。 当将同一发言人的语音转换为其他语言时,您可能会发现模型保留了原始口音,比如将英式口音发言人转换成中文时,会带有明显的英式口音。
最佳性能: 在单次运行中生成大约 42 秒 的音频(约 8,192 个标记)。建议不要接近此窗口的极限。通常,最佳结果不超过 7,000 个标记。
使用发言人参考时的上下文减少: 如果发言人参考为 10 秒长,则有效上下文减少到大约 32 秒。
模型快速搭建方法请参考算家云“镜像社区”
二、模型部署步骤
模型部署环境
| cuda | 12.4.1 |
| python | 3.10 |
| NVIDIA Corporation | RTX4090 |
1.更新基础的软件包
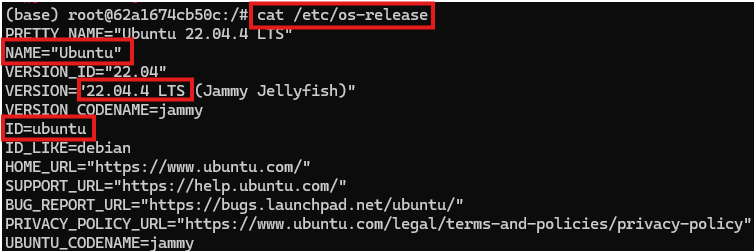
查看系统版本信息
#查看系统的版本信息,包括ID(如ubuntu、centos等)、版本号、名称、版本号ID等
cat /etc/os-release
配置国内源
#更新软件列表
apt-get update
apt配置阿里源
vim /etc/apt/sources.list
![]()
将以下内容粘贴进文件中
deb http://mirrors.aliyun.com/debian/ bullseye main non-free contrib
deb-src http://mirrors.aliyun.com/debian/ bullseye main non-free contrib
deb http://mirrors.aliyun.com/debian-security/ bullseye-security main
deb-src http://mirrors.aliyun.com/debian-security/ bullseye-security main
deb http://mirrors.aliyun.com/debian/ bullseye-updates main non-free contrib
deb-src http://mirrors.aliyun.com/debian/ bullseye-updates main non-free contrib
deb http://mirrors.aliyun.com/debian/ bullseye-backports main non-free contrib
deb-src http://mirrors.aliyun.com/debian/ bullseye-backports main non-free contrib
2.基础Miniconda3环境
查看系统是否有miniconda的环境
conda -V
![]()
显示如上输出,即安装了相应环境,若没有miniconda的环境,通过以下方法进行安装
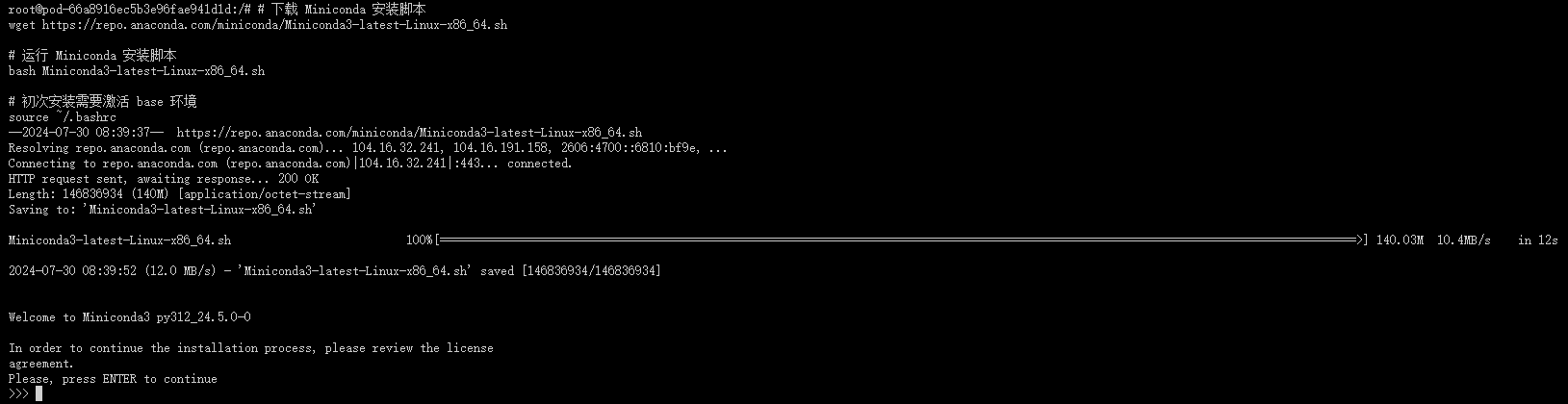
# 下载 Miniconda 安装脚本
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh
# 运行 Miniconda 安装脚本
bash Miniconda3-latest-Linux-x86_64.sh
# 初次安装需要激活 base 环境
source ~/.bashrc
按下回车键(enter)
输入 yes
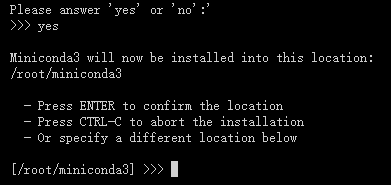
输入 yes
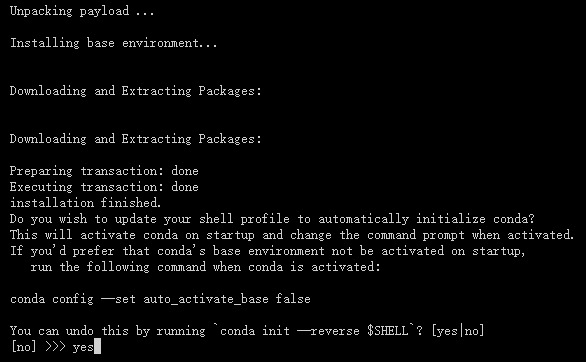
安装成功如下图所示
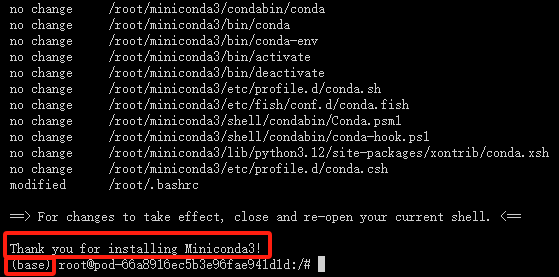
3.创建虚拟环境
创建名为“Outetts”的虚拟环境
conda create -n OuteTTs python=3.10 -y

激活虚拟环境
conda activate OuteTTs
![]()
4.从github仓库克隆项目
输入命令克隆OuteTTS存储库并进入到项目之中
git clone https://github.com/edwko/OuteTTS.git
cd OuteTTS
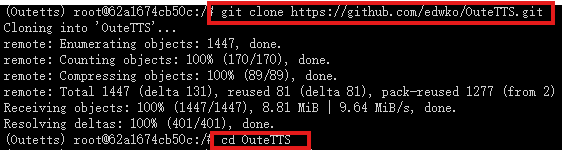
5.安装对应的pytorch环境
安装pytorch,选择合适的版本安装,建议python版本至少为3.9及以上
pip3 install torch torchvision torchaudio –index-url https://download.pytorch.org/whl/cu118

持续等待直至出现“successfully”,显示安装成功

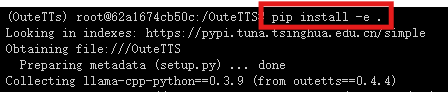
6.下载依赖库
pip install -e .
依赖库下载时间较长,直至出现“successfully”显示下载成功
7.存储模型运行命令
创建demo.py文件用以存储命令
vim demo.py
![]()
cat demo.py
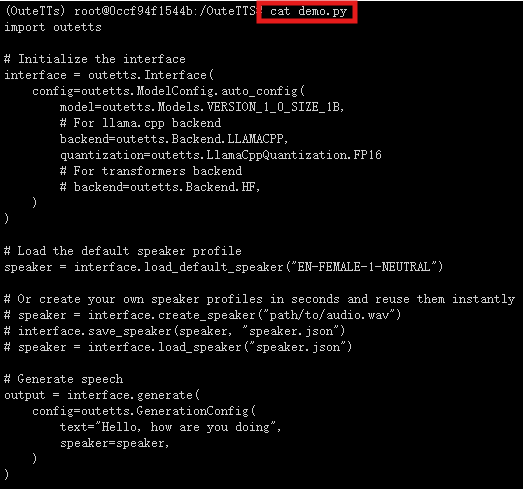
可以看到模型命令已经存储好了
运行模型命令
python demo.py
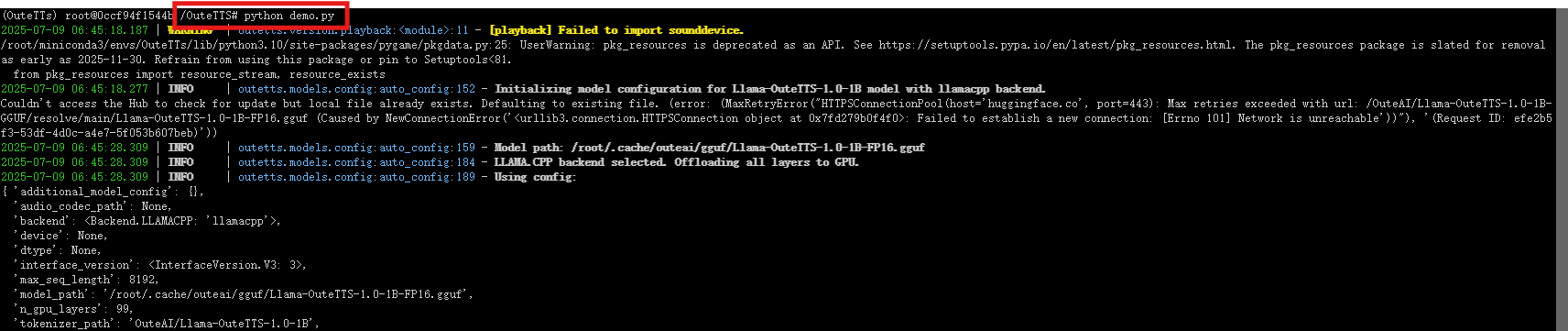
三、通过gradio进行演示
下载其他缺失依赖包
pip install gradio

通过gradio来运行写好的ui界面
访问界面
python app.py

出现如上显示可通过项目实例的开放端口进行访问
输入需要生成语音的文本(中文/英文)即可合成
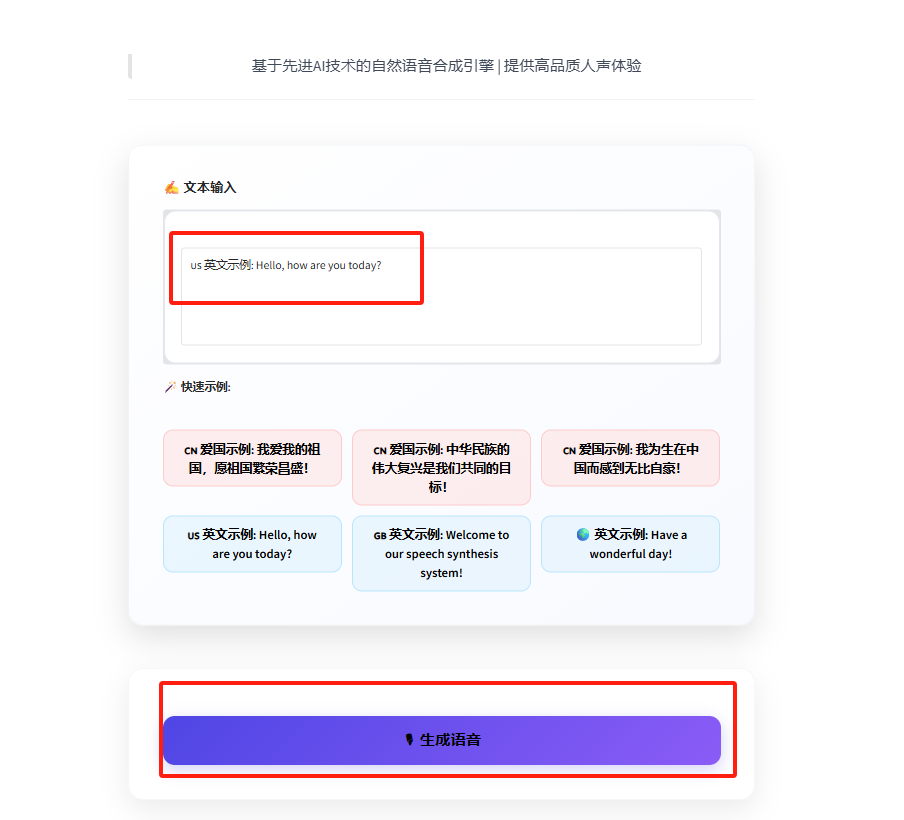
输出结果








评论前必须登录!
注册