 网硕互联帮助中心
网硕互联帮助中心
01 引言
前两天预研了中文分词器相关的工具包,原本打算使用IK分词器的,但是面对产品的需求IK已经不能满足了,最终选型HanLP 1.x。
HanLP是一系列模型与算法组成的NLP工具包,目标是普及自然语言处理在生产环境中的应用。HanLP具备功能完善、性能高效、架构清晰、语料时新、可自定义的特点。
而HanLP 2.x是基于深度学习的,提供轻量级的RESTful API,需要接入https://www.hanlp.com/api或者自己部署。海量级native API更适合专业的NLP工程师。部署成本相对较高,所以本文仍然以HanLP 1.x为例,介绍使用时可能遇到的问题。
文档地址:https://github.com/hankcs/HanLP/tree/1.x
02 最佳实践
Maven依赖
<dependency>
<groupId>com.hankcs</groupId>
<artifactId>hanlp</artifactId>
<version>portable-1.8.6</version>
</dependency>
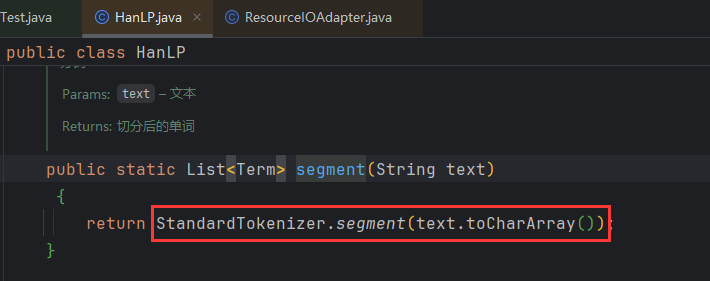
HanLP中有一系列“开箱即用”的静态分词器,以Tokenizer结尾。
2.1 标准分词
标准分词已经可以应用到通用的场景,主要的静态类:
com.hankcs.hanlp.tokenizer.StandardTokenizer
案例:
@Test
void test01() {
String text = "小米su7特斯拉modelY比亚042025款";
System.out.println(StandardTokenizer.segment(text));
// [小米/n, su/nx, 7/m, 特斯拉/nrf, modelY/nx, 比/p, 亚/b, 042025/m, 款/q, 6575767670908/m]
}
我们可以看到,分词的结果是按照[分词/词性 ]来输出结果的。
具体的词性说明:
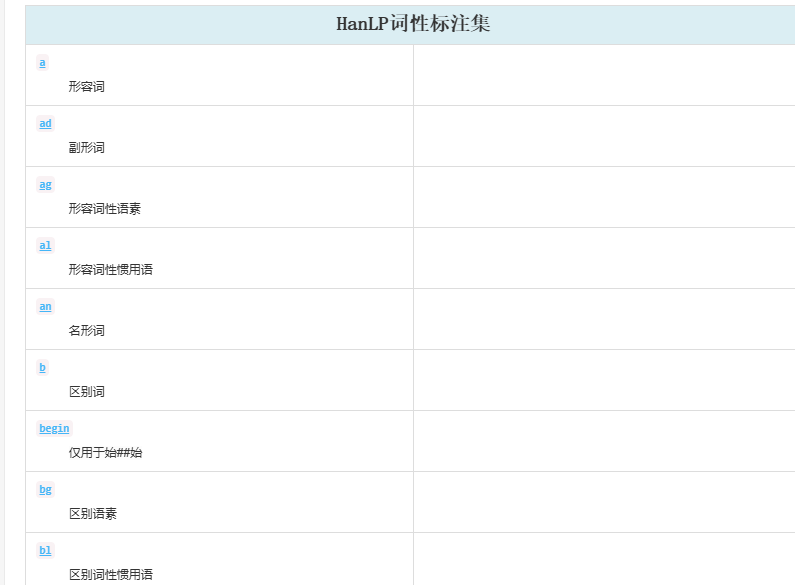
详细词性:
https://www.hankcs.com/nlp/part-of-speech-tagging.html#h2-8
快捷使用
@Test
void test01() {
String text = "小米su7特斯拉modelY比亚042025款";
System.out.println(HanLP.segment(text));
}
HanLP.segment()默认使用的就是StandardTokenizer。
2.2 索引分词
主要的静态类:com.hankcs.hanlp.tokenizer.IndexTokenizer
索引分词IndexTokenizer是面向搜索引擎的分词器,能够对长词全切分,另外通过term.offset可以获取单词在文本中的偏移量。
@Test
void test02() {
List<Term> termList = IndexTokenizer.segment("主副食品");
for (Term term : termList){
System.out.println(term + " [" + term.offset + ":" + (term.offset + term.word.length()) + "]");
}
}
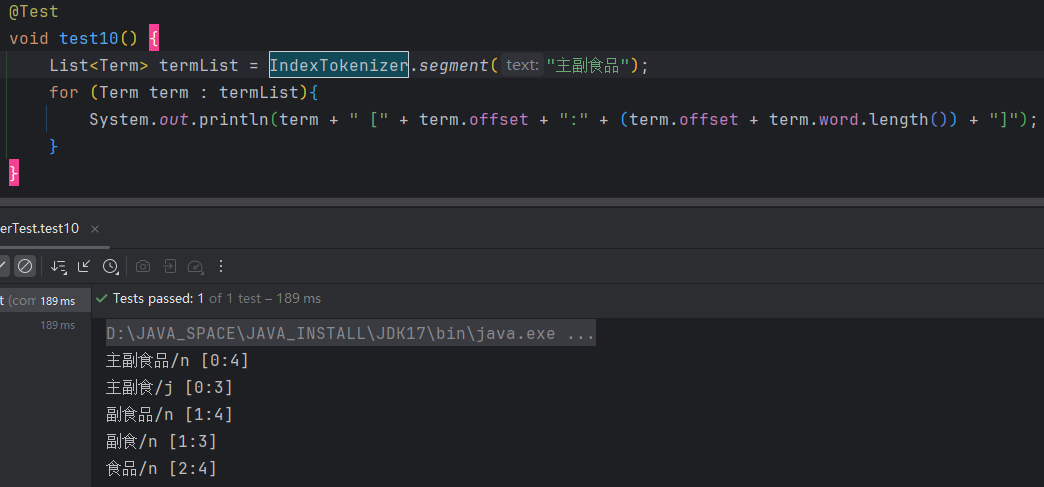
索引分词是按照索引的递增,依次分词,直到分出所有的词。同时还可以获取分词的索引位置。
2.3 N-最短路径分词
主要的静态类:
- com.hankcs.hanlp.seg.NShort.NShortSegment
- com.hankcs.hanlp.seg.Dijkstra.DijkstraSegment
N最短路分词器NShortSegment比最短路分词器慢,但是效果稍微好一些,对命名实体识别能力更强,一般场景下最短路分词的精度已经足够,而且速度比N最短路分词器快几倍,请酌情选择。
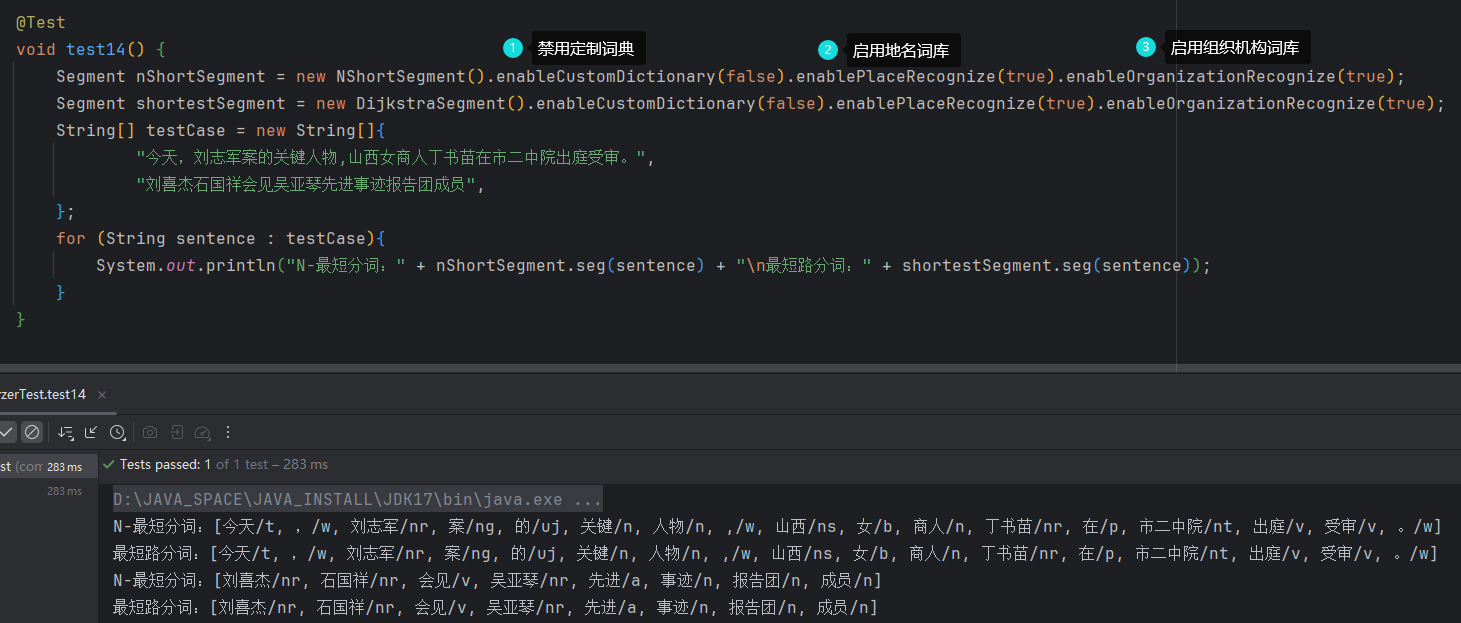
最短路径分词相比索引分词,似乎更细粒度,只是分出的词,后面的词将不会复用。效率应该更高。
2.4 极速词典分词
主要的静态类:
com.hankcs.hanlp.tokenizer.SpeedTokenizer
极速分词是词典最长分词,速度极其快,精度一般,适用于高吞吐量、精度一般的场合。
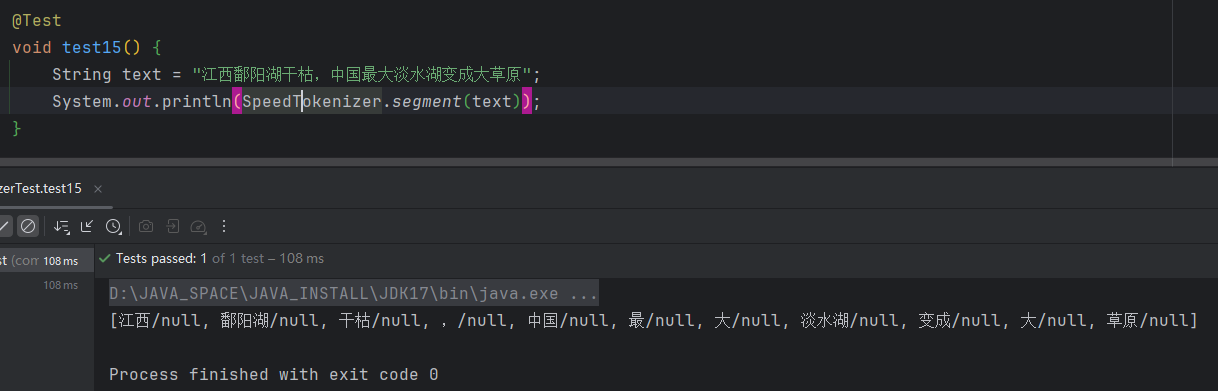
优点就是快,哈哈…
2.5 中国人名识别
分词器基本上都默认开启了中国人名识别,比如HanLP.segment()接口中使用的分词器等等,用户不必手动开启。
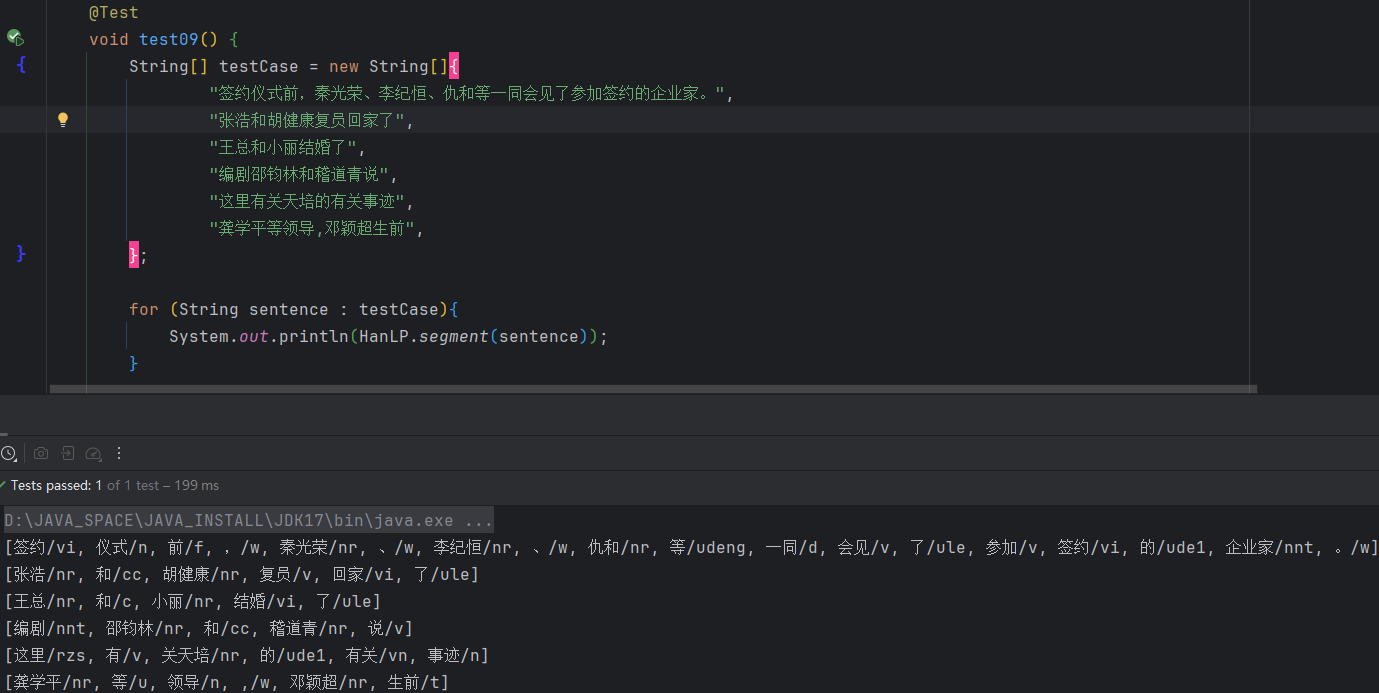
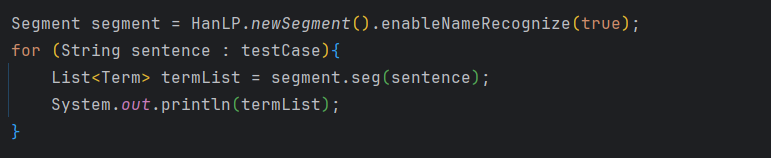
如果分要手动开启,则修改如下:
2.5 音译人名识别
分词器基本上都默认开启了音译人名识别,用户不必手动开启。下面的代码只是为了强调。
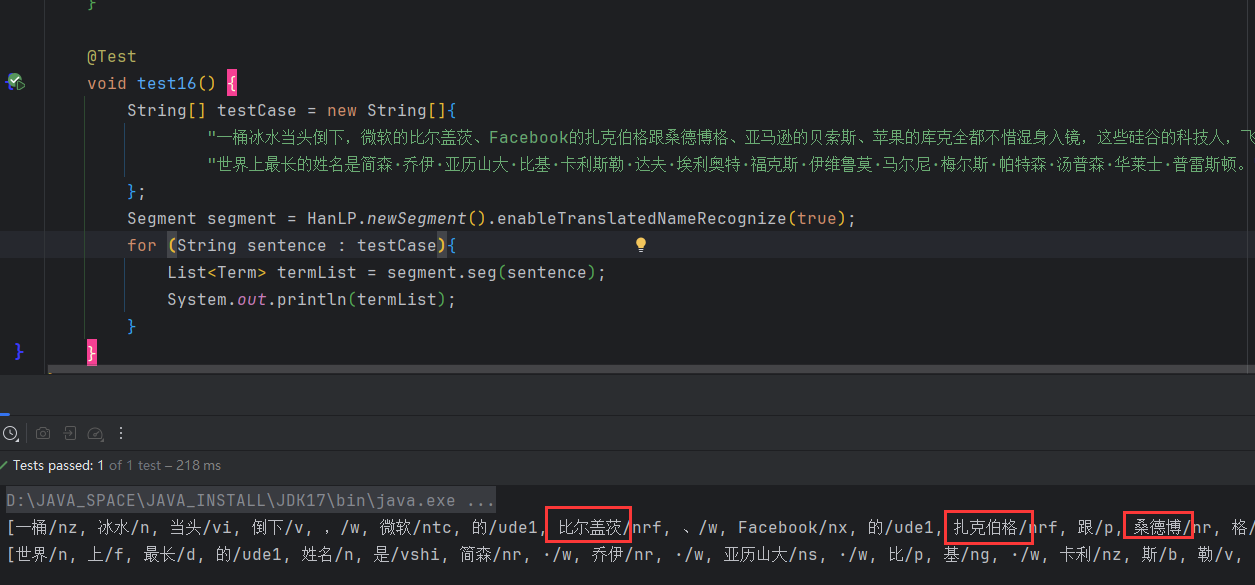
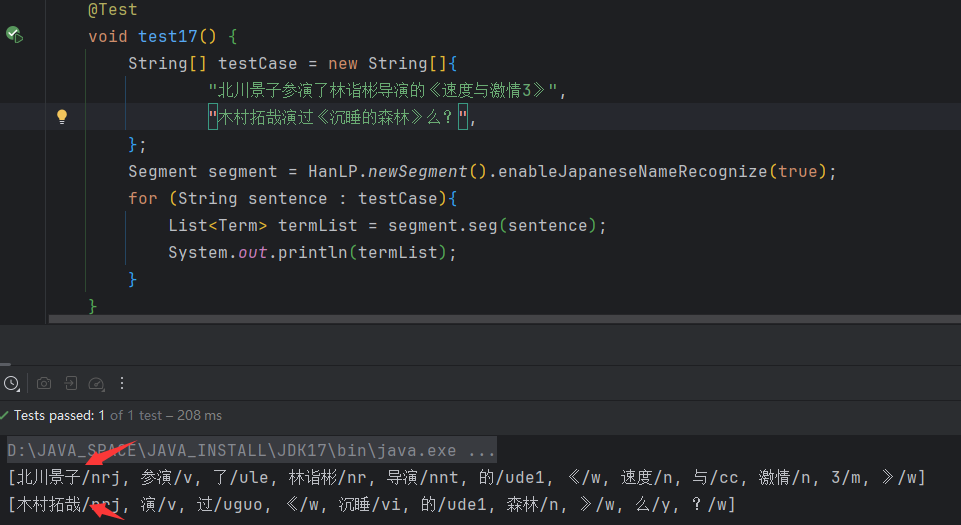
2.6 日本人名识别
标准分词器默认关闭了日本人名识别,用户需要手动开启;这是因为日本人名的出现频率较低,但是又消耗性能。
2.7 地名识别
分词器都默认关闭了地名识别,用户需要手动开启;这是因为消耗性能,其实多数地名都收录在核心词典和用户自定义词典中.在生产环境中,能靠词典解决的问题就靠词典解决,这是最高效稳定的方法。
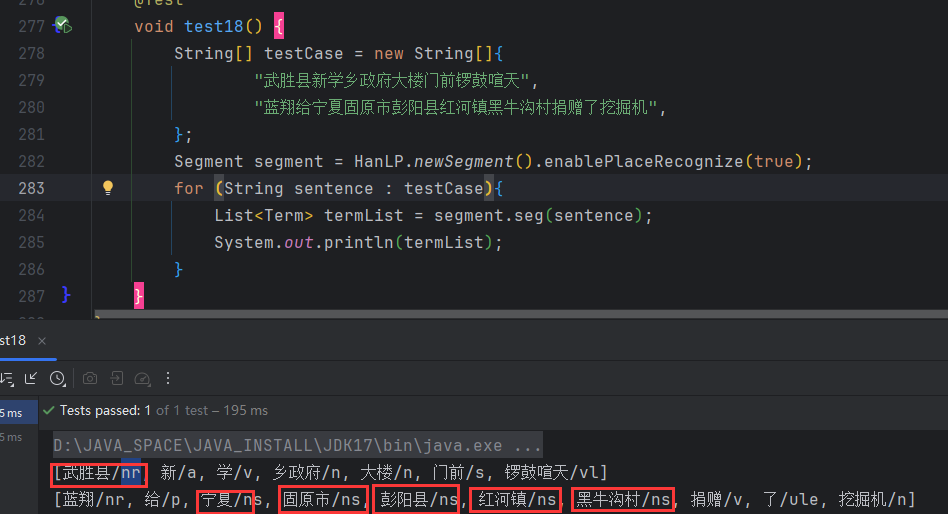
其中ns就表示地名,但是并不是所有分出的地名标注都是ns。
2.8 机构名识别
使用同地名识别,默认关闭,需要手动开启。生产最好使用词典。
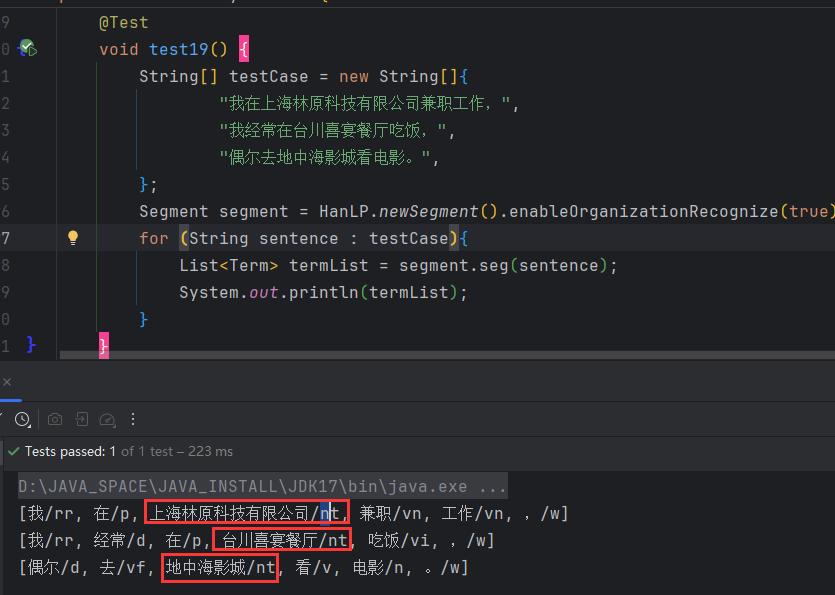
其中nt代表的就是机构名。
2.9 关键词提取
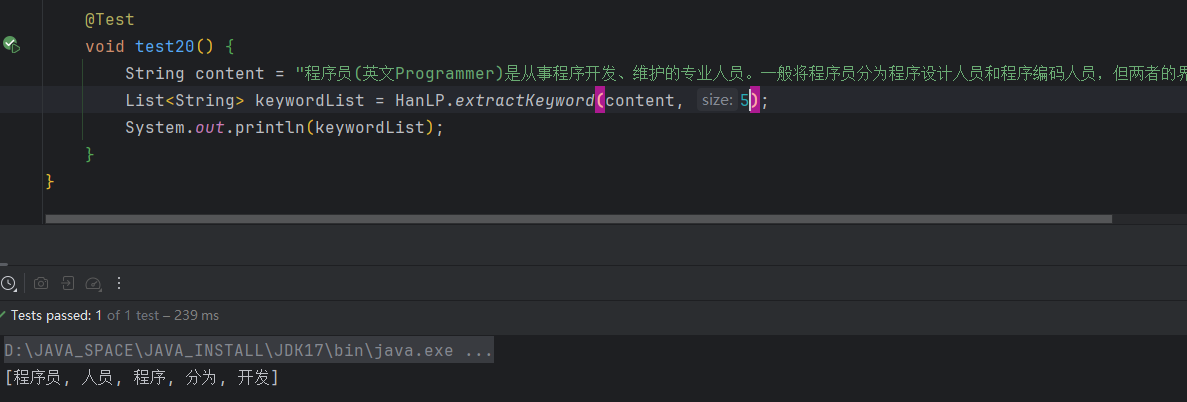
提取指定数量的关键词,我们可以看到提取的关键词并不是非常准确。
2.10 自动摘要
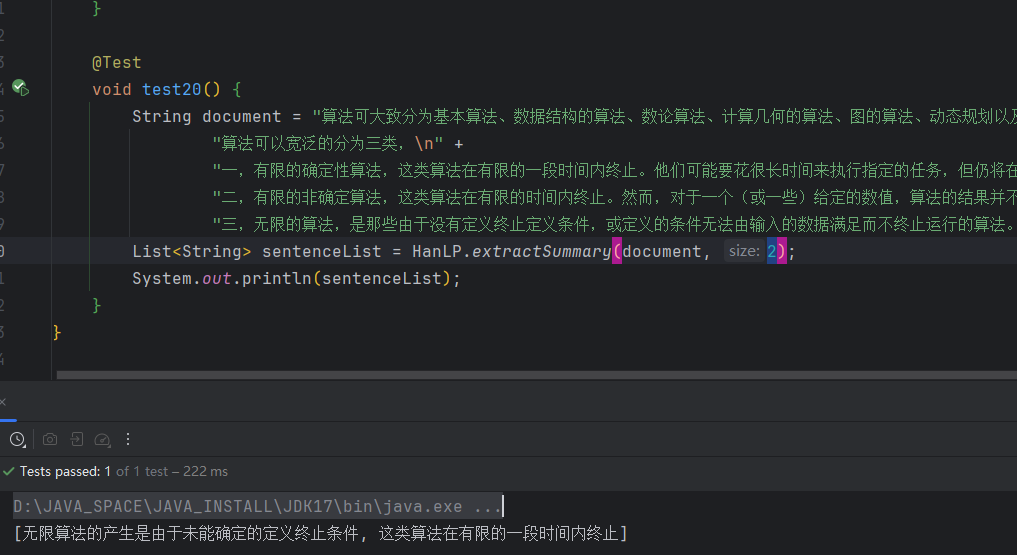
提取指定数量的摘要。
2.11 拼音转化
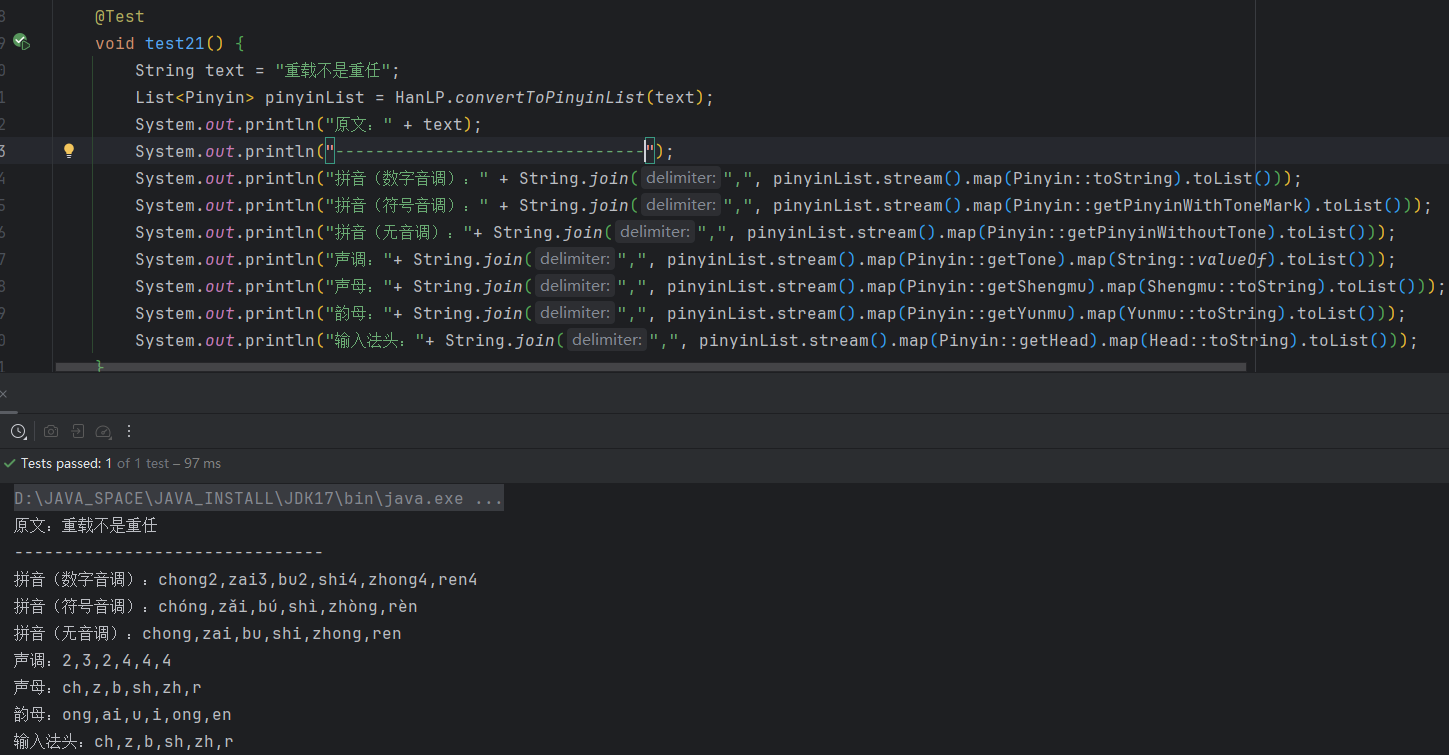
HanLP不仅支持基础的汉字转拼音,还支持声母、韵母、音调、音标和输入法首字母首声母功能,HanLP能够识别多音字,也能给繁体中文注拼音,最重要的是,HanLP采用的模式匹配升级到AhoCorasickDoubleArrayTrie,性能大幅提升,能够提供毫秒级的响应速度!
使用起来感觉比pinyin4j这样的工具包更好用。
2.12 简繁转换
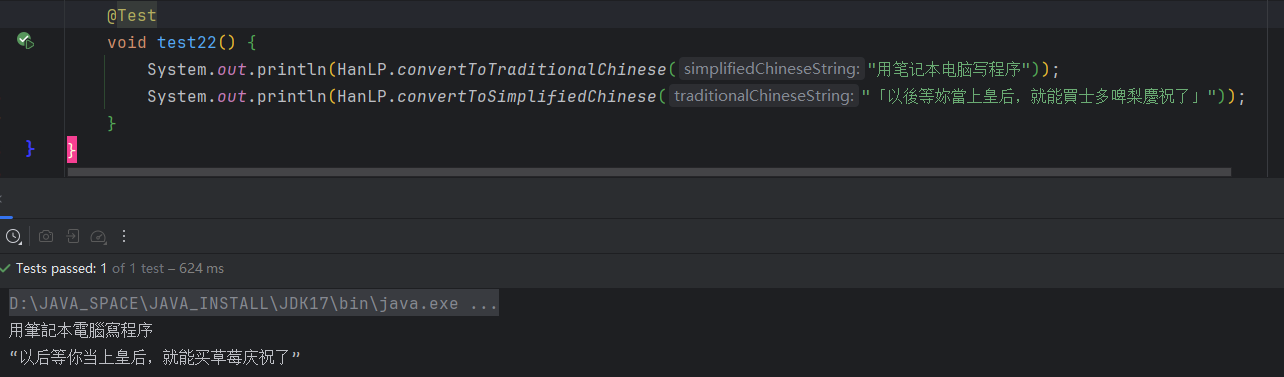
HanLP能够识别简繁分歧词,比如打印机=印表機。许多简繁转换工具不能区分“以后”“皇后”中的两个“后”字,HanLP可以。
简繁转化用起来就是爽!
2.13 文本推荐
在搜索引擎的输入框中,用户输入一个词,搜索引擎会联想出最合适的搜索词,HanLP实现了类似的功能。
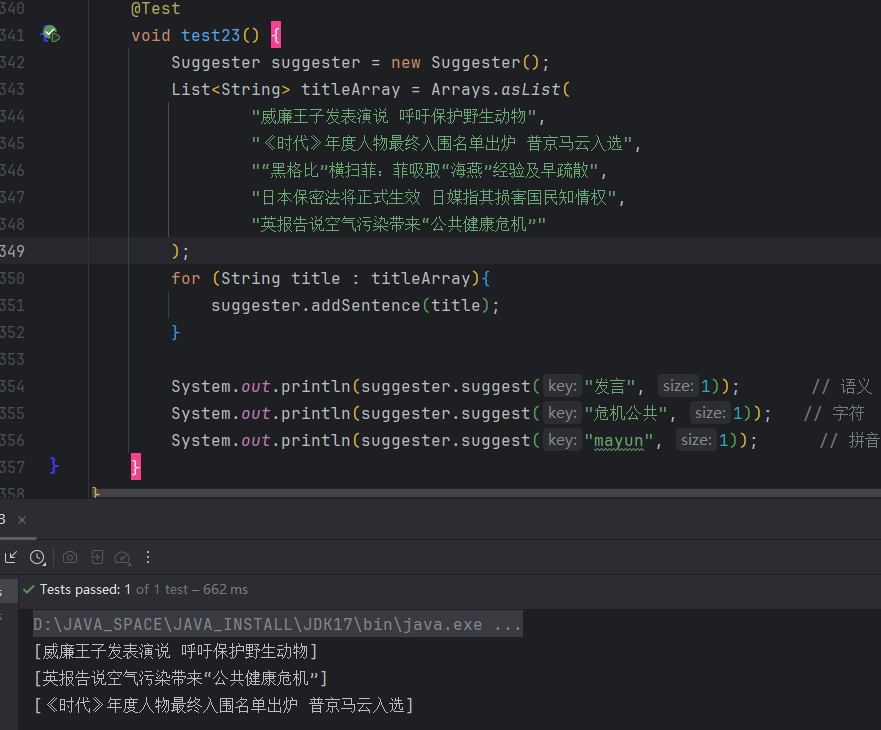
这个功能对于语义的搜索,提供了可能。很赞!
2.14 其他
上面13种对于词语的处理方法,都是可以直接使用的。但是还有一些是需要额外的词典和模型的
官方提供的data.zip:https://file.hankcs.com/hanlp/data-for-1.7.5.zip
- NLP分词
- CRF分词
- 语义距离
- 依存句法分析
这些都是在案例中都需要你用额外模型或词典。小写在总结时,对应的包还没有下载下来。暂时就不做测试了。
03 自定义词典
自定义词典为什么要单独领出来讲呢?因为在我们的业务开发中,可能分词的效果并不理想,需要定制自己的词库,索引更加常用。
例如:小米su7特斯拉modelY比亚042025款6575767670908
我们需要分出小米su7、2025款等词。我们分别看看用字典和不用字典的效果。
3.1 不用字典
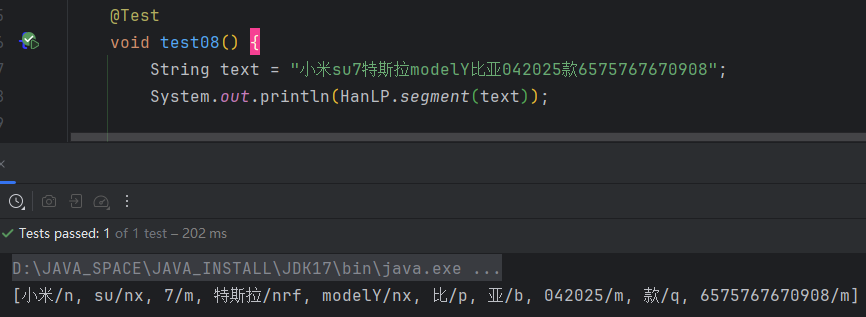
默认的词典会讲su、7以及2025和款分开。这样明显不能满足我们的业务场景。
使用定制词典可以通过配置文件或者动态添加的方式实现。
3.2 动态增删定制词典
动态增删的方法主要由com.hankcs.hanlp.dictionary.CustomDictionary的静态方法提供:
- add():增加临时词,不会持久化到词典
- insert():覆盖插入词库,会持久化到词典
- remove():删除缓存中词典的词,不会持久化到词库
- reload():重新加载词库
这里我们演示一下add()即可,其他的按需使用。
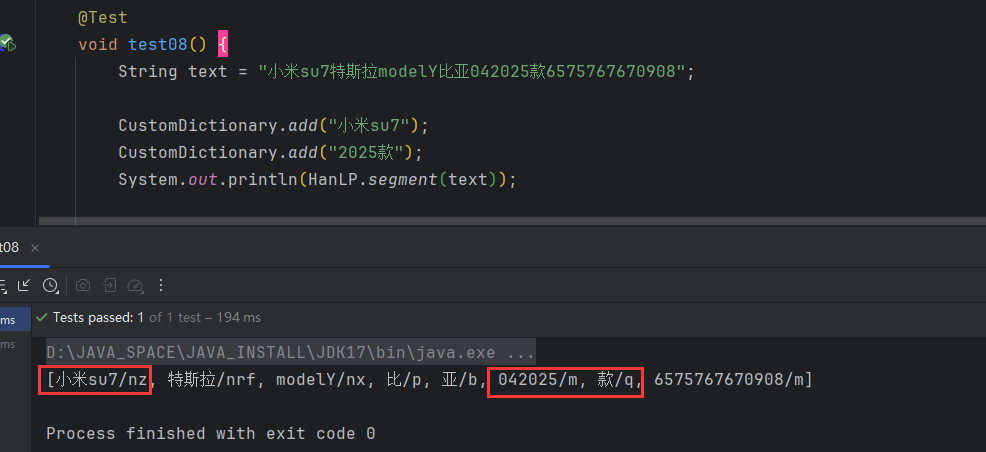
我们动态添加了临时词,发现部分已经生效了,但是年款却没有生效。这样应该是我们经常会遇到的问题。
我还测试其他分词工具,也会遇到同样的问题。我们看看官方的解释:

官方已经说明:
HanLP坚持的是以统计为主,规则词典为辅的思路, 算法不保证词典中的词语一定分出来,世界上不存在这样的算法。
当然官方也给出解决方案:在v1.3.5之后,通过com.hankcs.hanlp.seg.Segment#enableCustomDictionaryForcing可以手动开启。
我们继续改造:

成功。
3.3 配置词典文件
配置词典文件有两种方式:
- 直接指定词典路径
- 配置文件
**直接指定词典路径 **

关键代码块:

配置文件
使用配置文件,需要在classpath下引入hanlp.properties,然后在引入的配置中配置对应的地址即可:
CustomDictionaryPath=dictionary/ext.txt
IOAdapter=com.hankcs.hanlp.corpus.io.ResourceIOAdapter
这里一定要指定IOAdapter,否则会报错。
同样可以达到相同的效果。

portable版本本身就是便携版,虽然支持hanlp.properties配置,明显需要加载的东西的就会变多。

具体可以参考配置类:
com.hankcs.hanlp.HanLP.Config
3.4 停用词的使用
停用词的使用和自定义词典大致一样,但是用法上稍有不同。类似IK分词器是默认启用停用词的,只要配置停用词,分词结果就不会展示。
而HanLP默认是不启用的。需要手动调用方法:
CoreStopWordDictionary.apply(分词结果);

04 小结
HanLP 1.x 使用起来还是非常方便的,足够满足日常的业务需求。它不仅能满足基础的分词,还扩展了大模型相关的功能。中文分词你会选用它么?


评论前必须登录!
注册