 网硕互联帮助中心
网硕互联帮助中心关注gongzhonghao【图灵学术SCI科研圈】,解锁更多SCI相关资讯!
想让聚类算法突破传统边界?CVPR顶会研究正用K-Means重构AI认知!顶尖论文解锁三大维度:无监督模型评估利器、视频生成的聚类密码、复杂场景的时空解耦!从特征一致性对齐到动态语义压缩,K-Means的潜力正在被重新定义!
它不仅是数学工具,更是驱动生成模型、提升分割精度、突破评估瓶颈的核心引擎!
点击关注,一键拆解CVPR顶会如何用K-Means魔力,点燃下一代AI落地的无限可能!
关注gongzhonghao【图灵学术SCI科研圈】,获取K-Means最新选题和idea
Improving Autoregressive Visual Generation with Cluster-Oriented Token Prediction
方法:
作者先利用平衡 K-means 把 VQGAN 的码本重排成若干大小相等的簇,使簇内嵌入高度相似;再在自回归训练阶段对每一 token 额外预测其所属簇,并用簇级交叉熵损失与原 token 级损失联合优化;最终即使模型预测的具体 token 索引有误,只要簇正确,生成的图像仍与目标高度一致,从而以几乎零额外开销实现训练提速 40% 以上、生成质量显著提升。
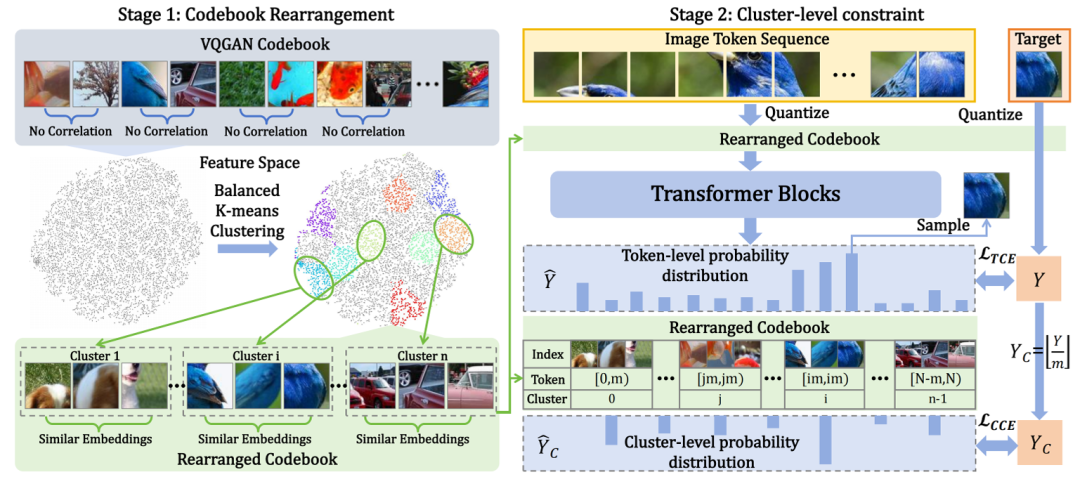
创新点:
-
首次揭示并量化视觉 token 嵌入空间的局部相似性可直接影响解码图像质量。
-
设计平衡 K-means 重排策略,把原本无序的码本重组成高内聚、等大小的簇,让相邻索引天然携带语义连贯性。
-
提出簇导向交叉熵损失,将“必须命中确切 token”松弛为“命中正确簇即可”,在训练中同时优化 token 级与簇级目标,显著提升鲁棒性与收敛速度。
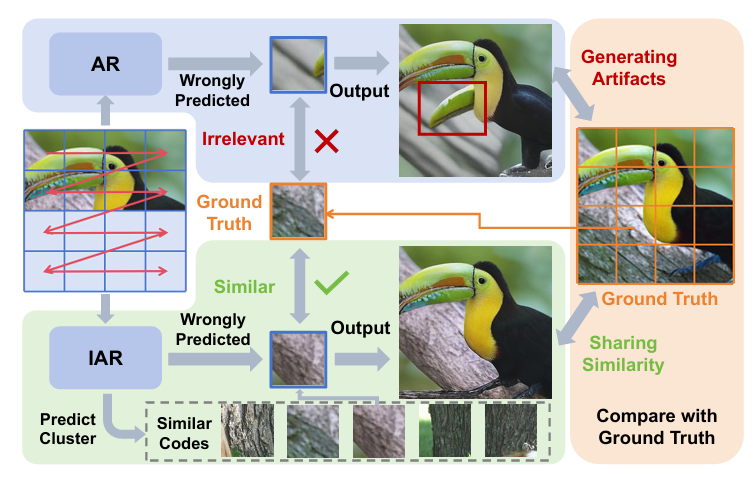
论文链接:
https://arxiv.org/pdf/2501.00880
关注gongzhonghao【图灵学术SCI科研圈】,获取K-Means最新选题和idea
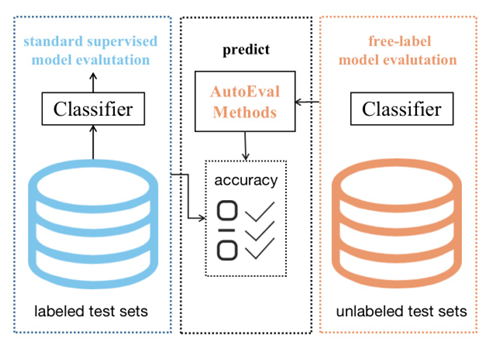
K-means Clustering Based Feature Consistency Alignment for Label-free Model Evaluation
方法:
作者首先用预训练网络提取训练集与测试集特征,分别执行 K-means 聚类获得中心表示,并以 Fréchet 距离刻画分布偏移;随后将该距离送入由线性、KNN、SVR、随机森林等多个基回归器构成的动态回归框架,元回归器实时学习各基模型的权重并输出最终精度预测;最后通过迭代计算各自动评估模型与中心结果的偏离度剔除离群方法,仅保留稳定模型做加权融合,在 DataCV 挑战中以 6.8526 的 RMSE 夺得第二名,显著优于最佳基线。
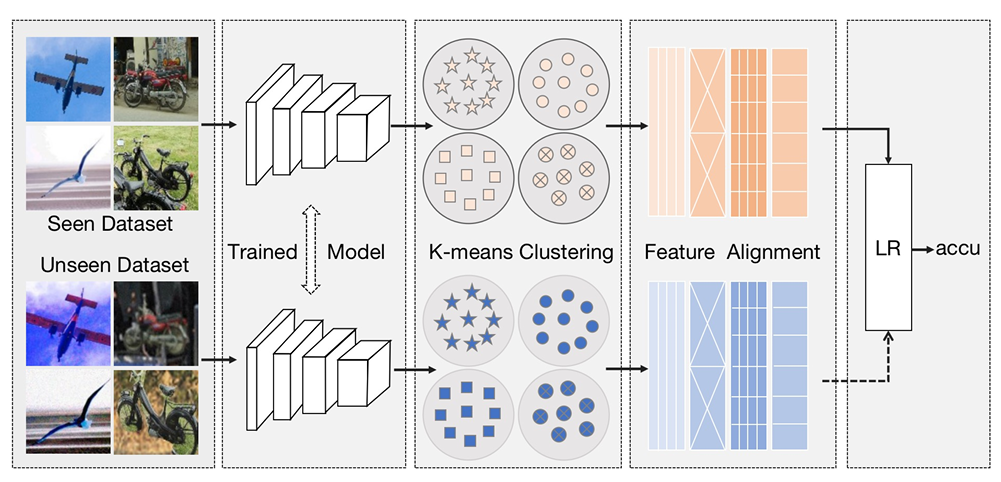
创新点:
-
提出 K-means Clustering Based Feature Consistency Alignment(KCFCA),用聚类中心之间的 Fréchet 距离量化分布偏移,实现无标签场景下的可解释漂移度量。
-
设计 Dynamic Regression Model(DRM),通过元回归器在线融合多种基回归器,自动捕捉漂移与准确率之间非线性且随任务变化的映射关系。
-
引入 Outlier Model Factor Discovery(OMFD)算法,基于稳定性距离阈值自动检测并剔除表现异常的自动评估模型,确保多模型融合始终处于最优子集。
论文链接:
https://arxiv.org/pdf/2304.09758
关注gongzhonghao【图灵学术SCI科研圈】,获取K-Means最新选题和idea
Learning Local and Global Temporal Contexts for Video Semantic Segmentation
方法:
作者先以 SegFormer 为骨干,对输入的 3 个参考帧和目标帧提取特征后,通过 CFFA 按帧距由粗到细地生成多尺度上下文 token;随后 CFM 以目标帧窗口特征为查询、以参考帧 token 为键值,用轻量级非自注意力迭代精炼目标特征完成局部分割;最后在 CFFM++ 中,利用已训练好的编码器对均匀采样的 10 帧做 k-means 聚类得到 100 个全局原型,再次用 CFM 将全局上下文融入目标帧,并以 0.5 权重融合局部分割结果,实现又快又准的视频语义分割。
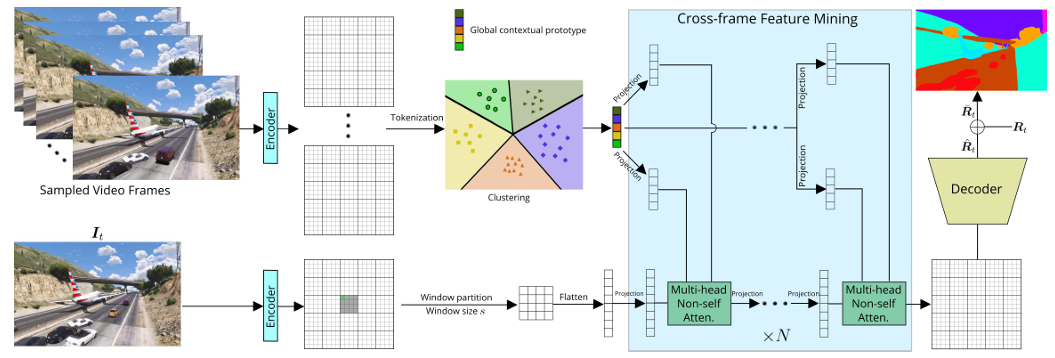
创新点:
-
提出“静态-动态局部上下文统一建模”思想,用一个 Coarse-to-Fine Feature Assembling(CFFA)模块按帧距动态调整感受野与池化粒度,首次显式融合邻居帧的静景与动景信息。
-
设计跨帧非自注意力的 Cross-frame Feature Mining(CFM),仅用 1–2 层即可在窗口级高效挖掘参考帧与目标帧的依赖,计算量从 O((l+1)²h²w²c) 降到 O(hwmc)。
-
在 CFFM 基础上升级为 CFFM++,引入 k-means 对全视频采样帧特征聚类得到 100 个全局原型,再用 CFM 把长程全局上下文注入目标帧,仅增加 1 M 参数就带来额外 1% mIoU。
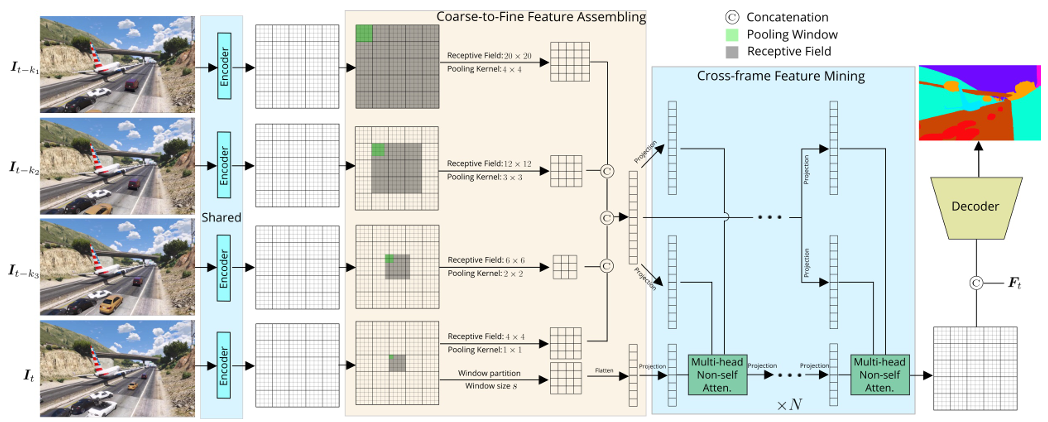
论文链接:
https://arxiv.org/pdf/2204.03330
► 论文发表难题,一站式解决!
TURING
选题是论文的第一步,非常重要!
但很多学生找到了热门的选题,却卡在代码和写作上!可见论文要录用,选题-idea-代码-写作都缺一不可!
图灵学术论文辅导,汇聚经验丰富的实战派导师团队,针对计算机各类领域提供1v1专业指导,直至论文录用!
关注gongzhonghao【图灵学术SCI科研圈】,解锁更多SCI相关资讯!









评论前必须登录!
注册