 网硕互联帮助中心
网硕互联帮助中心作为一名 Java 初学者,我常常会好奇:我们在代码里写下的字符、数字,在计算机里到底长什么样?为什么敲一个 “W” 能显示出来,输入 “f” 能跳出一串汉字?直到昨天的 Java 课上,老师拆解了数据在底层的存储逻辑,我才恍然大悟 —— 原来那些看似简单的字符和数字,背后藏着一套严谨的编码规则和存储机制。这篇博客整理了我课堂笔记里最核心的内容,从 char 类型的本质到进制转换的细节,力求用最通俗的语言讲清底层原理。如果你也和我一样,对 “数据在计算机里如何存在” 充满好奇,那这篇文章或许能帮你少走弯路,一起夯实 Java 基础~
char 类型的存储本质与编码查看方法
首先,我们从 Java 中的 char 类型说起。很多人直观上会认为,char 类型存储的就是我们看到的那些字符图形,比如 'W'、'a' 这些,但实际上并非如此。char 类型在计算机中的存储本质,是这些字符对应的编码,而这些编码本质上就是一串数字。正因为 char 类型存储的是数字,所以它才能像普通数字一样进行加减乘除等运算,这一点对于理解 char 类型的特性非常关键。
那么,我们如何查看一个字符对应的具体编码呢?其实可以通过一段简单的 Java 程序来实现。比如我们想知道字符 'W' 的编码,就可以这样写代码:
char k1 = 'W'; // 定义一个 char 类型变量 k1,赋值为字符 'W'
int k2 = k1; // 将 char 类型的 k1 赋值给 int 类型的 k2
System.out.println(k2); // 打印 k2 的值
运行这段程序后,控制台会输出 87,这就意味着字符 'W' 对应的编码是 87。通过这种方式,我们可以轻松获取任意字符的编码值,从而更直观地理解 “char 类型存储的是编码数字” 这一原理。
文本数据在磁盘与内存中的存储及解析流程
接下来,我们聊聊文本数据在存储和解析过程中的底层逻辑。我们平时用记事本编辑文字时,看到的是一个个字符图形,但这些内容在磁盘中的存储形式并不是这些图形本身。磁盘作为计算机的存储设备,只能存储由 0 和 1 组成的比特流,而文本数据在磁盘中存储的,正是这些字符对应的编码,这些编码最终也会转化为比特流的形式存在。这里需要明确的是,我们常听到的 “网络流”“字符流”“文件流”“字节流” 等概念,本质上都是这种由 0 和 1 组成的比特流,只是在不同场景下有了不同的称呼。
当我们打开一个文本文件时,磁盘中的比特流数据会被加载到计算机的内存中,内存会对这些比特流进行解析,最终转化为我们能看懂的字符图形。这个解析过程是有明确规则的,不同的编码方式(比如 ASCII 码)会决定内存如何截取和解析比特流。以 ASCII 码为例,它规定了每 8 位比特作为一个基本单位进行截取,然后将截取后的比特片段转换为对应的数字,形成一个数组。比如一段比特流可能被解析成数组 {20, 58, 46, 80}:
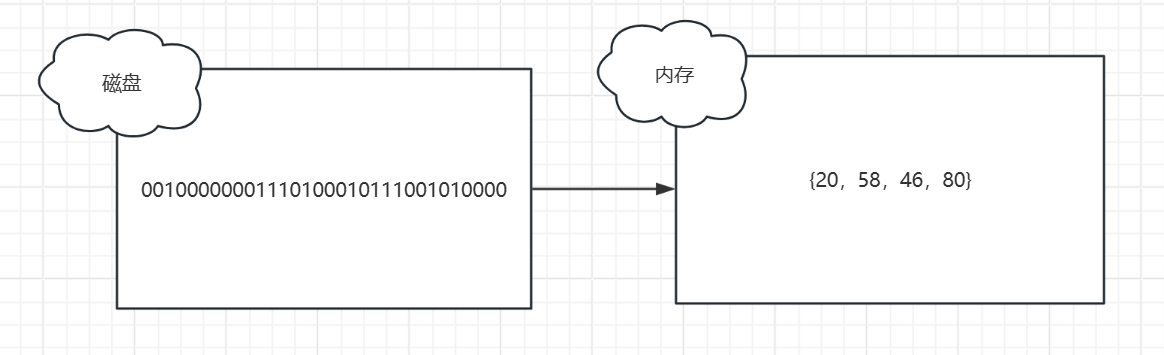
得到这个数字数组后,内存会根据数组中的每个数字,到对应的编码表中查找对应的字符图形,最后将这些图形展示在屏幕上。为了更直观地理解这个过程,我们可以通过一段代码来模拟解析:
byte[] arr = {54, 76, 98, 88}; // 定义一个 byte 数组,存储数字 54、76、98、88
for (int i = 0; i < arr.length; i++) { // 遍历数组
int x1 = arr[i]; // 将 byte 类型的数组元素转换为 int 类型
char x2 = (char) x1; // 将 int 类型的数字强制转换为 char 类型
System.out.println(x2); // 打印转换后的字符
}
运行这段代码后,控制台会依次输出 6、L、b、x。这清晰地展示了数字 54 对应字符 '6'、76 对应 'L'、98 对应 'b'、88 对应 'x' 的过程,也就是内存根据数字到编码表中查找对应图形的具体体现。
输入法的工作原理(基于编码映射)
我们在使用输入法输入汉字时,背后也离不开编码的作用。以输入拼音 “f” 为例,当我们在键盘上敲下 “f” 后,系统会首先获取 “f” 这个字符对应的编码(这里我们假设为 01,实际编码会根据具体编码规则确定)。

接着,系统会在预设的数据库中,找到所有以 “f” 开头的拼音,比如 “fa”“fen”“fang”“fa” 等,这些拼音在计算机中同样是以编码形式存在的。我们可以假设 “fa” 对应的编码是 1001,“fen” 对应的编码是 1011,“fang” 对应的编码是 10011,这些编码就像拼音的 “身份证号”,唯一标识着对应的拼音。
然后,输入法会根据这些拼音编码,到汉字图形库中找到对应的汉字图形,比如 “fa” 对应的 “发”“法”“罚” 等,“fen” 对应的 “分”“粉”“芬” 等,并将这些图形呈现到屏幕上供我们选择。我们最终选定的汉字,本质上也是通过编码从图形库中调取出来的图形形式,整个过程都依赖于编码与图形之间的映射关系。
数字的存储形式与 Java 中的进制表示
与字符不同,数字在计算机中存储的是数据本身,但这并不意味着数字可以直接以我们熟悉的形式存储。因为计算机的硬件电路特性,它只能识别和存储二进制数据,也就是由 0 和 1 组成的数字串。但在日常生活和编程中,我们还会用到十进制、八进制、十六进制等不同的进制形式,所以需要明确这些进制在 Java 中的表示方法以及它们与二进制之间的关系。
首先,我们来明确不同进制的基本规则:十进制是我们最常用的进制,每一位上的数字可以是 0 – 9;二进制每一位上的数字只能是 0 或 1;八进制每一位上的数字可以是 0 – 7;十六进制每一位上的数字可以是 0 – 9 以及 a – f(其中 a – f 分别表示 10 – 15,且不区分大小写)。
在 Java 代码中,不同进制的数字有其特定的表示规则,这是我们编写代码时必须掌握的:
-
十进制:在 Java 中,默认情况下直接书写的数字就是十进制,不需要添加任何前缀。例如 int x1 = 10,这里的 10 就是十进制数字,它表示我们日常生活中所理解的 “十”。
-
二进制:如果要表示二进制数字,需要在数字前面加上前缀 0b(注意是数字 0 和小写字母 b)。例如 int x2 = 0b10,这里的 0b10 就是二进制数字,转换为十进制后等于 2(计算过程:1×2¹ + 0×2⁰ = 2)。
-
八进制:表示八进制数字时,需要在数字前面加上前缀 0(数字 0)。例如 int x3 = 010,这里的 010 就是八进制数字,转换为十进制后等于 8(计算过程:1×8¹ + 0×8⁰ = 8)。
-
十六进制:表示十六进制数字时,需要在数字前面加上前缀 0x(数字 0 和小写字母 x)。例如 int x4 = 0x4ac,这里的 0x4ac 就是十六进制数字,其中 a 代表 10,c 代表 12,转换为十进制后等于 1196(计算过程:4×16² + 10×16¹ + 12×16⁰ = 4×256 + 10×16 + 12×1 = 1024 + 160 + 12 = 1196)。
理解这些进制的表示方法,有助于我们在编写代码时更清晰地表达数字,尤其是在涉及底层操作或需要与硬件交互的场景中,二进制、十六进制的使用非常普遍。
回顾这些知识点,从 char 类型存储的编码数字,到磁盘里流动的 0 和 1 比特流,再到输入法背后的编码映射和进制表示规则,每一个细节都在告诉我们:Java 编程的底层逻辑并不神秘,只要抓住 “编码” 和 “存储” 这两个核心,很多疑问都会迎刃而解。这篇笔记既是对自己学习的复盘,也希望能给同样在入门阶段的你一点启发 —— 学习编程就像拆积木,把底层原理吃透了,后续的知识大厦才能搭得更稳。如果你觉得这些内容对你有帮助,欢迎点赞收藏,也期待在评论区和大家一起交流更多 Java 学习心得~ 让我们一起在编程的路上慢慢打怪升级吧!






评论前必须登录!
注册