 网硕互联帮助中心
网硕互联帮助中心机器学习
机器学习01——初识机器学习
文章目录
- 机器学习
- 一、数据降维
-
- 1.1 特征选择
-
- (a) VarianceThreshold 低方差过滤特征选择
- (b) 根据相关系数的特征选择
-
- <1>理论
- <2>皮尔逊相关系数:
- <3>api:
- <4>示例:
- 1.2 主成分分析(PCA)
-
- (a) 原理
- (b) 步骤
- api
- 二、KNN算法
-
- 2.1 预估器
- 2.2 KNN分类
-
- 2.2.1 样本距离分析
- 2.2.2 原理
- 2.2.3 api与示例
- 三、模型选择与调优
-
- 3.1 交叉验证
-
- (1) 保留交叉验证HoldOut
- (2) K-折交叉验证(K-fold)
- (3) 分层k-折交叉验证Stratified k-fold
- (4) api
- 3.2 超参数搜索
- 四、朴素贝叶斯分类
-
- 4.1 贝叶斯分类理论
- 4.2 条件概率
- 4.3 全概率公式
- 4.4 贝叶斯推断
- 4.5 朴素贝叶斯推断
- 4.6 拉普拉斯平滑系数
- 4.7 api与示例
- 总结
一、数据降维
实际数据中,有时候特征很多,会增加计算量,降维就是去掉一些特征,或者转化多个特征为少量个特征
- 特征降维其目的:是减少数据集的维度,同时尽可能保留数据的重要信息。
- 特征降维的好处:
- 减少计算成本:在高维空间中处理数据可能非常耗时且计算密集。降维可以简化模型,降低训练时间和资源需求。
- 去除噪声:高维数据可能包含许多无关或冗余特征,这些特征可能引入噪声并导致过拟合。降维可以帮助去除这些不必要的特征。
- 特征降维的方式:
- 特征选择:从原始特征集中挑选出最相关的特征
- 主成份分析(PCA):主成分分析就是把之前的特征通过一系列数学计算,形成新的特征,新的特征数量会小于之前特征数量
1.1 特征选择
(a) VarianceThreshold 低方差过滤特征选择
如果一个特征的方差很小,说明这个特征的值在样本中几乎相同或变化不大,包含的信息量很少,模型很难通过该特征区分不同的对象,比如区分甜瓜子和咸瓜子还是蒜香瓜子,如果有一个特征是长度,这个特征相差不大可以去掉。
api:
# 创建对象,准备把方差为等于小于2的去掉,threshold的缺省值为2.0
sklearn.feature_selection.VarianceThreshold(threshold=2.0)
# 把x中低方差特征去掉, x的类型可以是DataFrame、ndarray和list
VananceThreshold.fit_transform(x)
# fit_transform函数的返回值为ndarray
示例:
from sklearn.feature_selection import VarianceThreshold
import numpy as np
# 生成一个4*5列表,要求数字为整数,范围为1-9
data=np.random.randint(1,10,(4,5))
print(data)
transfer=VarianceThreshold(threshold=6)
data=transfer.fit_transform(data)
print(data)
print(transfer.variances_)
# 使用上一次特征值来过滤特征,即直接认为新数据的方差就是上一次计算出来的方差
data1=np.random.randint(1,10,(4,5))
print(data1)
data1=transfer.transform(data1)
print(data1)
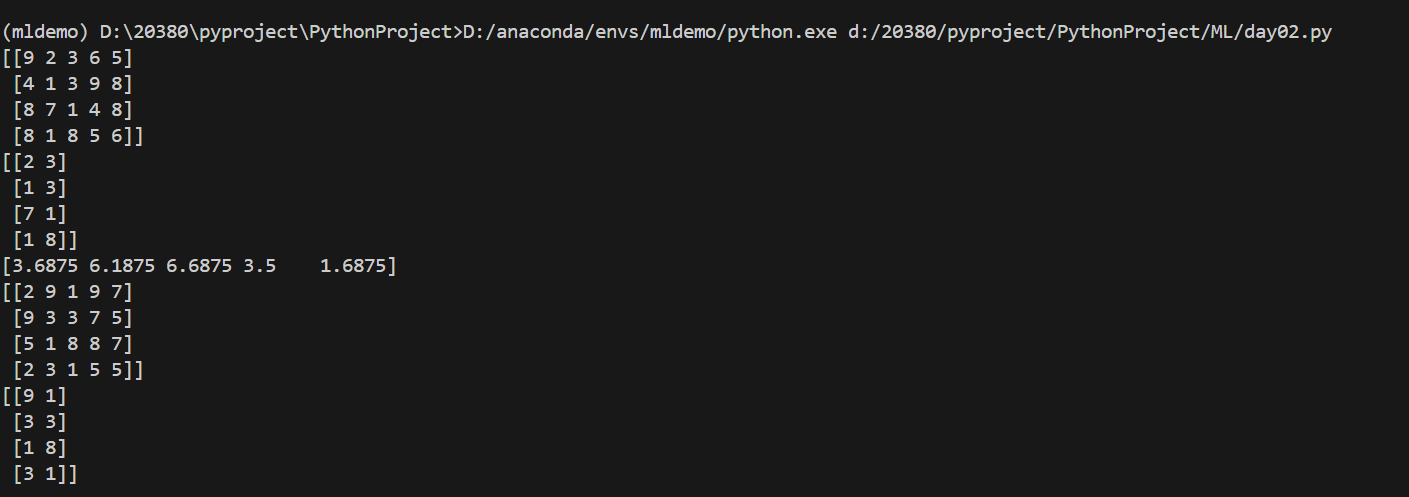
(b) 根据相关系数的特征选择
<1>理论
正相关性(Positive Correlation)是指两个变量之间的一种统计关系,其中一个变量的增加通常伴随着另一个变量的增加,反之亦然。在正相关的关系中,两个变量的变化趋势是同向的。当我们说两个变量正相关时,意味着:
- 如果第一个变量增加,第二个变量也有很大的概率会增加。
- 同样,如果第一个变量减少,第二个变量也很可能会减少。
正相关性并不意味着一个变量的变化直接引起了另一个变量的变化,它仅仅指出了两个变量之间存在的一种统计上的关联性。这种关联性可以是因果关系,也可以是由第三个未观察到的变量引起的,或者是纯属巧合。
在数学上,正相关性通常用正值的相关系数来表示,这个值介于0和1之间。当相关系数等于1时,表示两个变量之间存在完美的正相关关系,即一个变量的值可以完全由另一个变量的值预测。
皮尔逊相关系数(Pearson correlation coefficient)是一种度量两个变量之间线性相关性的统计量。它提供了两个变量间关系的方向(正相关或负相关)和强度的信息。皮尔逊相关系数的取值范围是[−1,1],其中:
-
ρ
=
1
\\rho=1
ρ=1 表示完全正相关,即随着一个变量的增加,另一个变量也线性增加。 -
ρ
=
−
1
\\rho=-1
ρ=−1 表示完全负相关,即随着一个变量的增加,另一个变量线性减少。 -
ρ
=
0
\\rho=0
ρ=0 表示两个变量之间不存在线性关系。
相关系数
ρ
\\rho
ρ的绝对值为0-1之间,绝对值越大,表示越相关,当两特征完全相关时,两特征的值表示的向量是同一条直线上;当两特征的相关系数绝对值很小时,两特征值表示的向量接近在同一条直线上。当相关系值为负数时,表示负相关。
<2>皮尔逊相关系数:
对于两组数据 𝑋={𝑥1,𝑥2,…,𝑥𝑛} 和 𝑌={𝑦1,𝑦2,…,𝑦𝑛},皮尔逊相关系数可以用以下公式计算:
ρ
=
Cos
(
x
,
y
)
D
x
⋅
D
y
=
E
[
(
x
−
E
x
)
(
y
−
E
y
)
]
D
x
⋅
D
y
\\rho=\\frac{\\operatorname{Cos}(x, y)}{\\sqrt{D x} \\cdot \\sqrt{D y}}=\\frac{E[(x_-E x)(y-E y)]}{\\sqrt{D x} \\cdot \\sqrt{D y}}
ρ=Dx
⋅Dy
Cos(x,y)=Dx
⋅Dy
E[(x−Ex)(y−Ey)]
=
∑
i
=
1
n
(
x
−
x
~
)
(
y
−
y
ˉ
)
/
(
n
−
1
)
∑
i
=
1
n
(
x
−
x
ˉ
)
2
/
(
n
−
1
)
⋅
∑
i
=
1
n
(
y
−
y
ˉ
)
2
/
(
n
−
1
)
=
cov
(
X
,
Y
)
σ
X
σ
Y
=\\frac{\\sum_{i=1}^{n}(x-\\tilde{x})(y-\\bar{y}) /(n-1)}{\\sqrt{\\sum_{i=1}^{n}(x-\\bar{x})^{2} /(n-1)} \\cdot \\sqrt{\\sum_{i=1}^{n}(y-\\bar{y})^{2} /(n-1)}} = \\frac{\\text{cov}(X,Y)}{\\sigma_X \\sigma_Y}
=∑i=1n(x−xˉ)2/(n−1)
⋅∑i=1n(y−yˉ)2/(n−1)
∑i=1n(x−x~)(y−yˉ)/(n−1)=σXσYcov(X,Y)
x
ˉ
\\bar{x}
xˉ和
y
ˉ
\\bar{y}
yˉ 分别是𝑋和𝑌的平均值。
该公式可以看作对x,y的协方差作标准化,即将其协方差除以各自的标准差。
|ρ|<0.4为低度相关; 0.4<=|ρ|<0.7为显著相关; 0.7<=|ρ|<1为高度相关。
<3>api:
scipy.stats.personr(x, y) # 计算两特征之间的相关性
返回对象有两个属性:
- statistic皮尔逊相关系数[-1,1]。
- pvalue零假设(了解),统计上评估两个变量之间的相关性,越小越相关。
<4>示例:
from scipy.stats import pearsonr
x=[1,2,3,4,5,6,7,8,9,10]
y=[2,4,5,6,7,8,9,10,11,12]
print(pearsonr(x,y))
print(pearsonr(x,y[::–1]))

开发中一般不使用求相关系数的方法,一般使用主成分分析,因为主成分分样过程中就包括了求相关系数了。
1.2 主成分分析(PCA)
PCA的核心目标是从原始特征空间中找到一个新的坐标系统,使得数据在新坐标轴上的投影能够最大程度地保留数据的方差,同时减少数据的维度。
(a) 原理
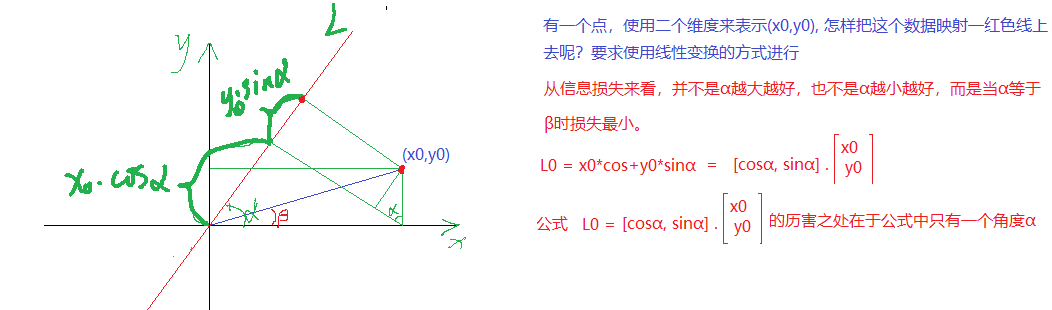
x
0
x_0
x0投影到L的大小为
x
0
∗
c
o
s
α
x_0*cos \\alpha
x0∗cosα
y
0
y_0
y0投影到L的大小为
y
0
∗
s
i
n
α
y_0*sin\\alpha
y0∗sinα
使用
(
x
0
,
y
0
)
(x_0,y_0)
(x0,y0)表示一个点, 表明该点有两个特征, 而映射到L上有一个特征就可以表示这个点了。这就达到了降维的功能 。
投影到L上的值就是降维后保留的信息,投影到与L垂直的轴上的值就是丢失的信息。保留信息/原始信息=信息保留的比例
(b) 步骤
得到矩阵
用矩阵P对原始数据进行线性变换,得到新的数据矩阵Z,每一列就是一个主成分, 如下图就是把10维降成了2维,得到了两个主成分 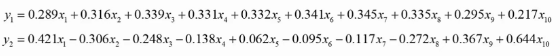
根据主成分的方差等,确定最终保留的主成分个数, 方差大的要留下。一个特征的多个样本的值如果都相同,则方差为0, 则说明该特征值不能区别样本,所以该特征没有用。
比如下图的二维数据要降为一维数据,图形法是把所在数据在二维坐标中以点的形式标出,然后给出一条直线,让所有点垂直映射到直线上,该直线有很多,只有点到线的距离之和最小的线才能让之前信息损失最小。
这样之前所有的二维表示的点就全部变成一条直线上的点,从二维降成了一维。 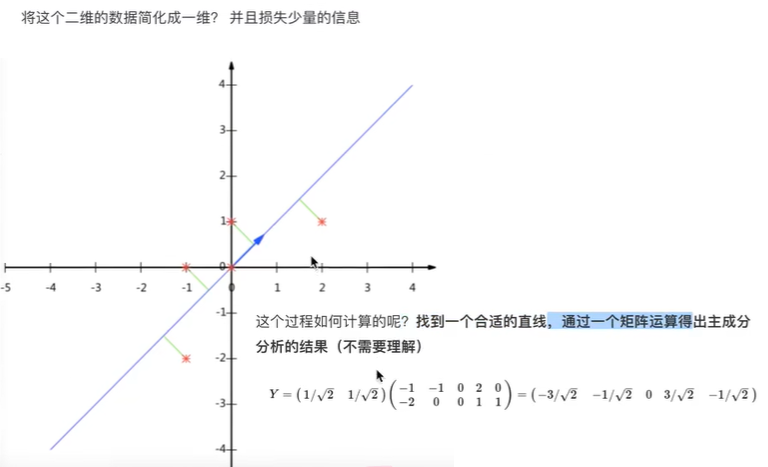
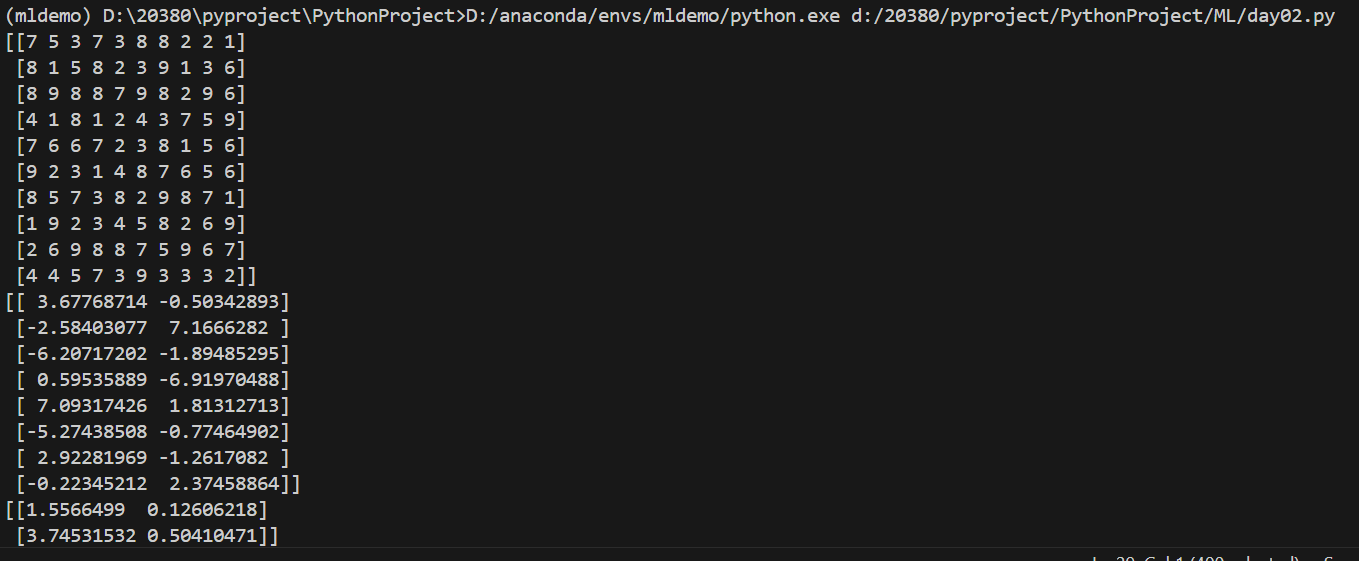
api
示例:
from sklearn.decomposition import PCA
from sklearn.model_selection import train_test_split
# 生成一个10*10列表,要求数字为整数,范围为1-9
data=np.random.randint(1,10,(10,10))
print(data)
# 划分训练集和测试集
x_train, x_test = train_test_split(data, test_size=0.2,random_state=22,shuffle=True)
# 值为整数表示降到多少维,为小数表示保留多少比例的信息
transfer=PCA(n_components=2)
train=transfer.fit_transform(x_train)
print(train)
test=transfer.transform(x_test)
print(test)
二、KNN算法
2.1 预估器
获取数据、数据处理、特征工程后,就可以交给预估器进行机器学习,流程和常用API如下。
1.实例化预估器(估计器)对象(estimator), 预估器对象很多,都是estimator的子类
(1)用于分类的预估器
sklearn.neighbors.KNeighborsClassifier k-近邻
sklearn.naive_bayes.MultinomialNB 贝叶斯
sklearn.linear_model.LogisticRegressioon 逻辑回归
sklearn.tree.DecisionTreeClassifier 决策树
sklearn.ensemble.RandomForestClassifier 随机森林
(2)用于回归的预估器
sklearn.linear_model.LinearRegression 线性回归
sklearn.linear_model.Ridge 岭回归
(3)用于无监督学习的预估器
sklearn.cluster.KMeans 聚类
2.进行训练,训练结束后生成模型
estimator.fit(x_train, y_train)
3.模型评估
(1)方式1,直接对比
y_predict = estimator.predict(x_test)
y_test == y_predict
(2)方式2, 计算准确率
accuracy = estimator.score(x_test, y_test)
4.使用模型(预测)
y_predict = estimator.predict(x_true)
2.2 KNN分类
2.2.1 样本距离分析
通常我们可以将一个有着n个特征值的样本看作一个n维向量。而样本间的相似度就可以用样本间的距离来度量。
而用来度量样本间相似度的常用距离有以下几种:
- 闵可夫斯基距离 计算公式:
d
(
x
,
y
)
=
(
∑
i
=
1
n
∣
x
i
−
y
i
∣
p
)
1
/
p
d(\\mathbf{x}, \\mathbf{y}) = \\left( \\sum_{i=1}^n |x_i – y_i|^p \\right)^{1/p}
d(x,y)=(∑i=1n∣xi−yi∣p)1/p - 欧氏距离 计算公式:
d
(
x
,
y
)
=
∑
i
=
1
n
(
x
i
−
y
i
)
2
d(\\mathbf{x}, \\mathbf{y}) = \\sqrt{\\sum_{i=1}^n (x_i – y_i)^2}
d(x,y)=∑i=1n(xi−yi)2,闵可夫斯基距离中p
=
2
p=2
p=2的特殊情况。 - 曼哈顿距离 计算公式:
d
(
x
,
y
)
=
∑
i
=
1
n
∣
x
i
−
y
i
∣
d(\\mathbf{x}, \\mathbf{y}) = \\sum_{i=1}^n |x_i – y_i|
d(x,y)=∑i=1n∣xi−yi∣,闵可夫斯基距离中p
=
1
p=1
p=1的特殊情况。 - 切比雪夫距离 计算公式:
d
(
x
,
y
)
=
max
i
∣
x
i
−
y
i
∣
d(\\mathbf{x}, \\mathbf{y}) = \\max_{i} |x_i – y_i|
d(x,y)=maxi∣xi−yi∣,闵可夫斯基距离中p
p
p趋于无穷的特殊情况。 - 余弦相似度 计算公式:
sim
(
x
,
y
)
=
x
⋅
y
∥
x
∥
∥
y
∥
\\text{sim}(\\mathbf{x}, \\mathbf{y}) = \\frac{\\mathbf{x} \\cdot \\mathbf{y}}{\\|\\mathbf{x}\\| \\|\\mathbf{y}\\|}
sim(x,y)=∥x∥∥y∥x⋅y,(距离常定义为d
=
1
−
s
i
m
d=1−sim
d=1−sim)。 - 汉明距离 计算公式:
d
(
x
,
y
)
=
∑
i
=
1
n
1
(
x
i
≠
y
i
)
d(\\mathbf{x}, \\mathbf{y}) = \\sum_{i=1}^n \\mathbb{1}(x_i \\neq y_i)
d(x,y)=∑i=1n1(xi=yi),计算等长字符串的差异位置数。 - 马氏距离 计算公式:
d
(
x
,
y
)
=
(
x
−
y
)
T
Σ
−
1
(
x
−
y
)
d(\\mathbf{x}, \\mathbf{y}) = \\sqrt{(\\mathbf{x} – \\mathbf{y})^T \\Sigma^{-1} (\\mathbf{x} – \\mathbf{y})}
d(x,y)=(x−y)TΣ−1(x−y),通过协方差矩阵考虑特征间的相关性。
2.2.2 原理
K-近邻算法(K-Nearest Neighbors,简称KNN),根据K个邻居样本的类别来判断当前样本的类别;如果一个样本在特征空间中的k个最相似(最邻近)样本中的大多数属于某个类别,则该类本也属于这个类别。 
KNN算法具有以下缺点:
- 对于大规模数据集,计算量大,因为需要计算测试样本与所有训练样本的距离。
- 对于高维数据,距离度量可能变得不那么有意义,这就是所谓的“维度灾难”。
- 需要选择合适的k值和距离度量,这可能需要一些实验和调整。
2.2.3 api与示例
from sklearn.neighbors import KNeighborsClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
iris = load_iris()
x = iris.data
y = iris.target
x_train,x_test,y_train,y_test = train_test_split(x,y,test_size=0.2,random_state=22)
# 特征工程-标准化
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)
# 模型训练
model=KNeighborsClassifier(n_neighbors=7)
model.fit(x_train,y_train)
# 模型保存
joblib.dump(model,'./ML/model/knn.pkl')
joblib.dump(transfer,'./ML/model/std.pkl')
# 预测
y_p=model.predict(x_test)
print("预测结果为:",y_p)
print("实际结果为:",y_test)
# 模型评估
def accuracy_score(y_true,y_predict):
"""准确率"""
return np.sum(y_true==y_predict)/len(y_true)
print("准确率:",accuracy_score(y_test,y_p))
print("准确率:",model.score(x_test,y_test))
# 新数据预测
new_x=[[1.1,1.2,0.3,0.4],
[0.5,0.6,0.7,0.8],
[0.9,1.0,0.1,0.2]]
x_new=transfer.transform(new_x)
y_new=model.predict(x_new)
print("预测结果为:",iris.target_names[y_new])

三、模型选择与调优
3.1 交叉验证
(1) 保留交叉验证HoldOut
在这种交叉验证技术中,整个数据集被随机地划分为训练集和验证集。根据经验法则,整个数据集的近70%被用作训练集,其余30%被用作验证集。也就是我们最常使用的,直接划分数据集的方法。
- 优点:很简单很容易执行。
- 缺点1:不适用于不平衡的数据集。假设我们有一个不平衡的数据集,有0类和1类。假设80%的数据属于 “0 “类,其余20%的数据属于 “1 “类。这种情况下,训练集的大小为80%,测试数据的大小为数据集的20%。可能发生的情况是,所有80%的 “0 “类数据都在训练集中,而所有 “1 “类数据都在测试集中。因此,我们的模型将不能很好地概括我们的测试数据,因为它之前没有见过 “1 “类的数据。
- 缺点2:一大块数据被剥夺了训练模型的机会。
在小数据集的情况下,有一部分数据将被保留下来用于测试模型,这些数据可能具有重要的特征,而我们的模型可能会因为没有在这些数据上进行训练而错过。但在大数据集上,这种方法仍然是最优先考虑的。
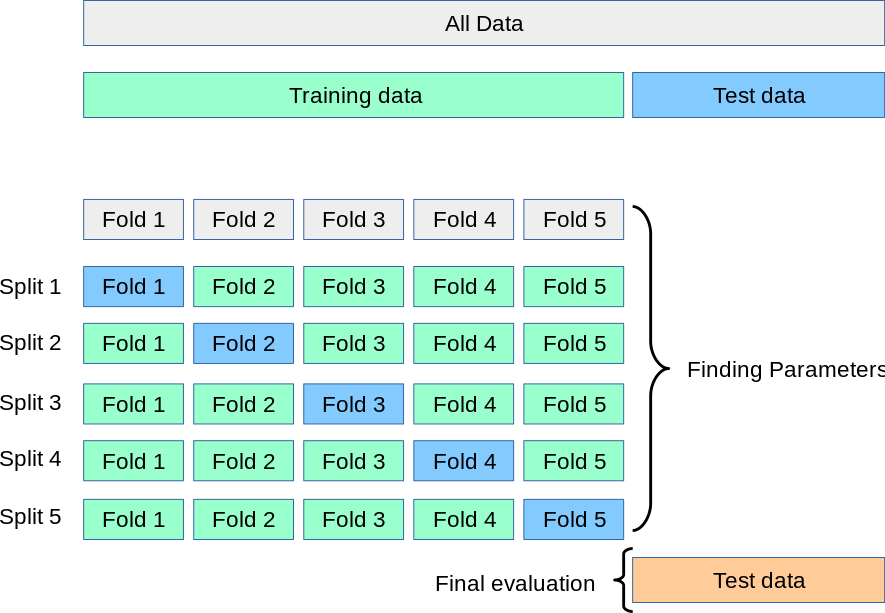
(2) K-折交叉验证(K-fold)
K-Fold交叉验证技术中,整个数据集被划分为K个大小相同的部分。每个分区被称为 一个”Fold”。所以我们有K个部分,我们称之为K-Fold。一个Fold被用作验证集,其余的K-1个Fold被用作训练集。
该技术重复K次,直到每个Fold都被用作验证集,其余的作为训练集。模型的最终准确度是通过取k个模型验证数据的平均准确度来计算的。
由于knn算法性质,其不适用K-fold验证。
(3) 分层k-折交叉验证Stratified k-fold
K-折交叉验证的变种, 分层的意思是说在每一折中都保持着原始数据中各个类别的比例关系,比如说:原始数据有3类,比例为1:2:1,采用3折分层交叉验证,那么划分的3折中,每一折中的数据类别保持着1:2:1的比例,这样的验证结果更加可信。
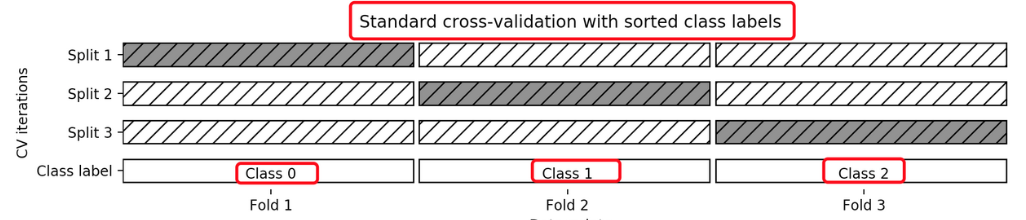
- 其它验证
去除p交叉验证、留一交叉验证、蒙特卡罗交叉验证、时间序列交叉验证。
(4) api
from sklearn.model_selection import StratifiedKFold
说明:普通K折交叉验证和分层K折交叉验证的使用是一样的 只是引入的类不同
from sklearn.model_selection import KFold
使用时只是KFold这个类名不一样其他代码完全一样
strat_k_fold=sklearn.model_selection.StratifiedKFold(n_splits=5, shuffle=True, random_state=42)
n_splits划分为几个折叠
shuffle是否在拆分之前被打乱(随机化),False则按照顺序拆分
random_state随机因子
indexs=strat_k_fold.split(X,y)
返回一个可迭代对象,一共有5个折叠,每个折叠对应的是训练集和测试集的下标
然后可以用for循环取出每一个折叠对应的X和y下标来访问到对应的测试数据集和训练数据集 以及测试目标集和训练目标集
for train_index, test_index in indexs:
X[train_index] y[train_index] X[test_index ] y[test_index ]
3.2 超参数搜索
超参数搜索也叫网格搜索(Grid Search),比如在KNN算法中,k是一个可以人为设置的参数,所以就是一个超参数。网格搜索能自动的帮助我们找到最好的超参数值。
api
class sklearn.model_selection.GridSearchCV(estimator, param_grid)
说明:
同时进行交叉验证(CV)、和网格搜索(GridSearch),GridSearchCV实际上也是一个估计器(estimator),
同时它有几个重要属性:
best_params_ 最佳参数
best_score_ 在训练集中的准确率
best_estimator_ 最佳估计器
cv_results_ 交叉验证过程描述
best_index_最佳k在列表中的下标
参数:
estimator: scikit-learn估计器实例
param_grid:以参数名称(str)作为键,将参数设置列表尝试作为值的字典
示例: {"n_neighbors": [1, 3, 5, 7, 9, 11]}
cv: 确定交叉验证切分策略,值为:
(1)None 默认5折
(2)integer 设置多少折
如果估计器是分类器,使用"分层k-折交叉验证(StratifiedKFold)"。
在所有其他情况下,使用KFold。
示例:
from sklearn.model_selection import GridSearchCV
x,y=load_iris(return_X_y=True)
knn=KNeighborsClassifier()
model=GridSearchCV(knn,param_grid={'n_neighbors':[1,2,3,4,5,6,7,8,9,10]},cv=10)
model.fit(x,y)
print(model.best_score_)
print(model.best_params_)
print(model.best_index_)
print(model.best_estimator_==knn)

四、朴素贝叶斯分类
4.1 贝叶斯分类理论
假设现在我们有一个数据集,它由两类数据组成,数据分布如下图所示: 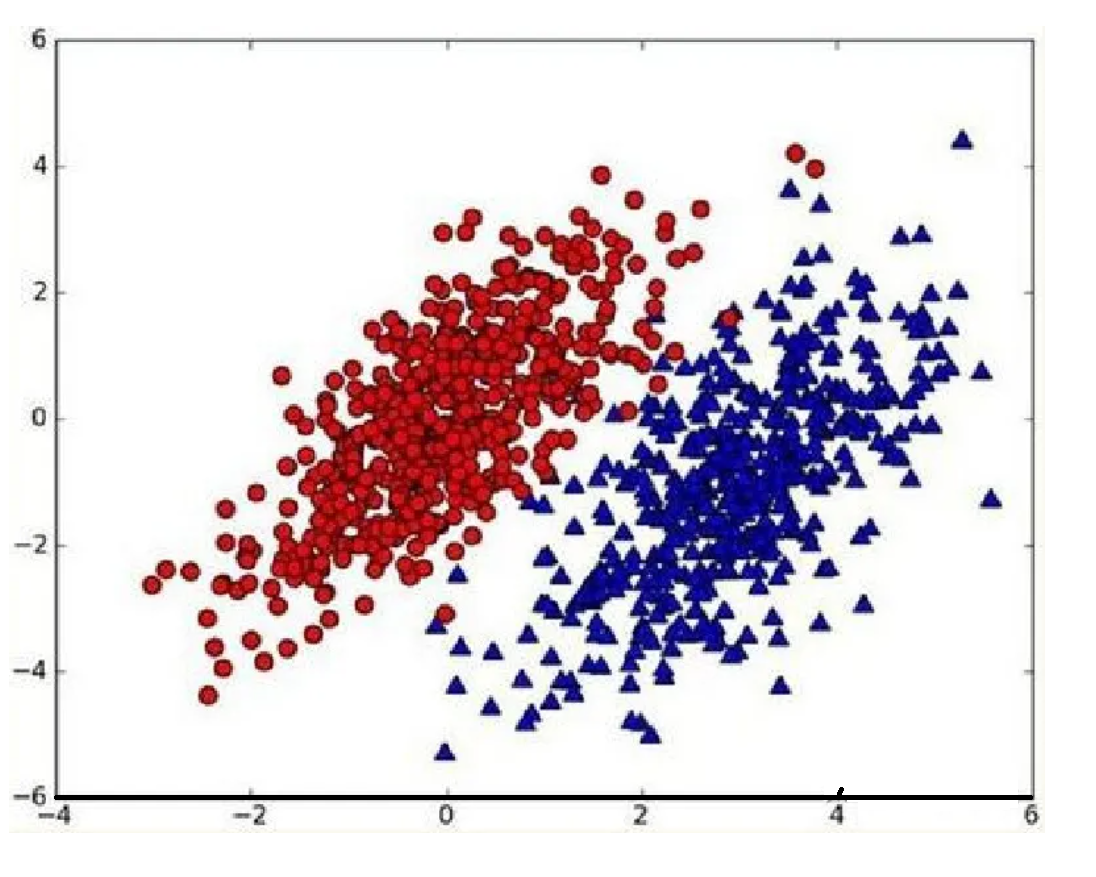 我们现在用p1(x,y)表示数据点(x,y)属于类别1(图中红色圆点表示的类别)的概率,用p2(x,y)表示数据点(x,y)属于类别2(图中蓝色三角形表示的类别)的概率,那么对于一个新数据点(x,y),可以用下面的规则来判断它的类别:
我们现在用p1(x,y)表示数据点(x,y)属于类别1(图中红色圆点表示的类别)的概率,用p2(x,y)表示数据点(x,y)属于类别2(图中蓝色三角形表示的类别)的概率,那么对于一个新数据点(x,y),可以用下面的规则来判断它的类别:
- 如果p1(x,y)>p2(x,y),那么类别为1
- 如果p1(x,y)<p2(x,y),那么类别为2
也就是说,我们会选择高概率对应的类别。这就是贝叶斯决策理论的核心思想,即选择具有最高概率的决策。已经了解了贝叶斯决策理论的核心思想,那么接下来,就是学习如何计算p1和p2概率。
4.2 条件概率
在学习计算p1 和p2概率之前,我们需要了解什么是条件概率(Conditional probability),就是指在事件B发生的情况下,事件A发生的概率,用P(A|B)来表示。 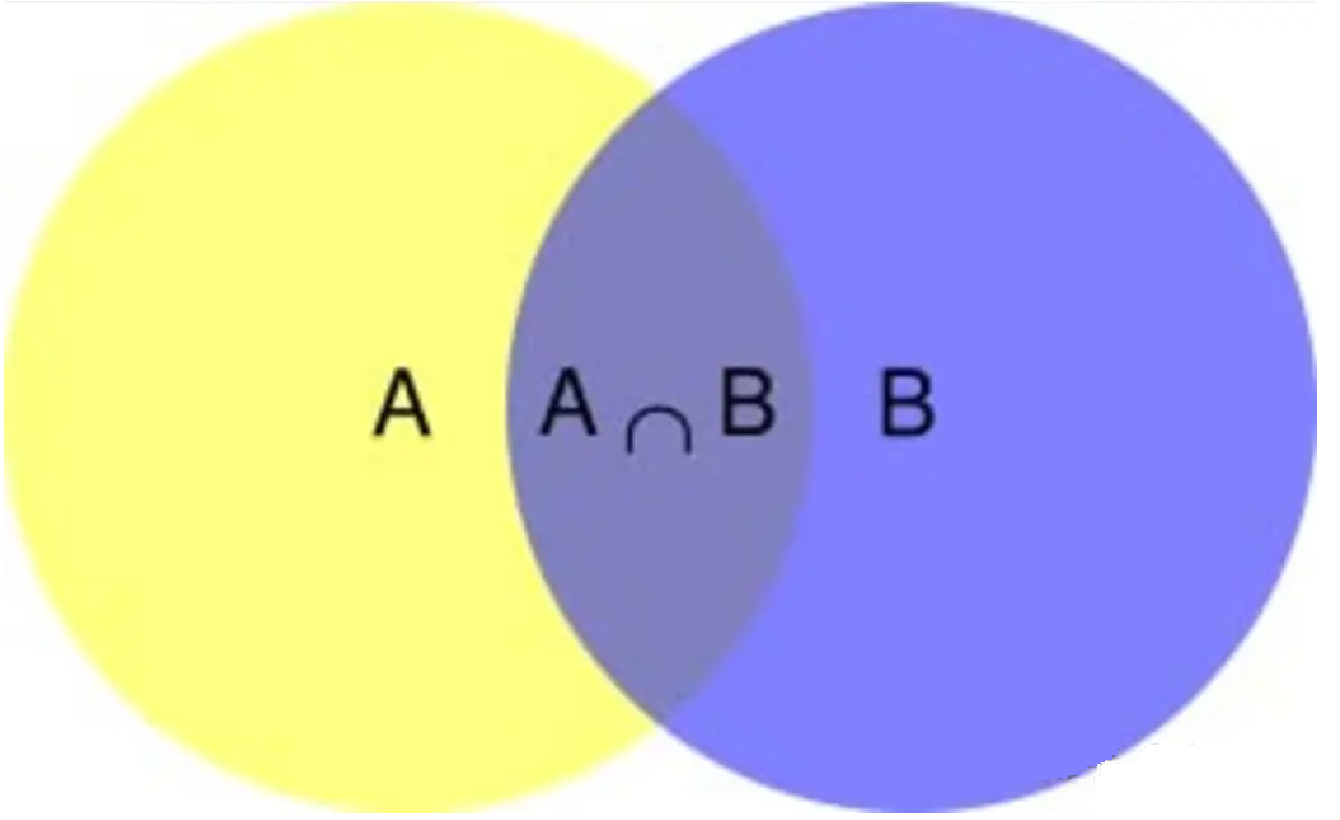 根据文氏图,可以很清楚地看到在事件B发生的情况下,事件A发生的概率就是P(A∩B)除以P(B),即
根据文氏图,可以很清楚地看到在事件B发生的情况下,事件A发生的概率就是P(A∩B)除以P(B),即
P
(
A
∣
B
)
=
P
(
A
∩
B
)
P
(
B
)
P(A \\mid B) = \\frac{P(A \\cap B)}{P(B)}
P(A∣B)=P(B)P(A∩B)。
因此,
P
(
A
∩
B
)
=
P
(
A
∣
B
)
P
(
B
)
P(A \\cap B) = P(A \\mid B)P(B)
P(A∩B)=P(A∣B)P(B), 同理可得,
P
(
A
∩
B
)
=
P
(
B
∣
A
)
P
(
A
)
P(A \\cap B) = P(B \\mid A)P(A)
P(A∩B)=P(B∣A)P(A),
即
P
(
A
∣
B
)
=
P
(
B
∣
A
)
P
(
A
)
P
(
B
)
P(A \\mid B) = \\frac{P(B \\mid A)P(A)}{P(B)}
P(A∣B)=P(B)P(B∣A)P(A) ,这就是条件概率的计算公式。
4.3 全概率公式
除了条件概率以外,在计算p1和p2的时候,还要用到全概率公式,因此,这里继续推导全概率公式。
假定样本空间S,是两个事件A与A’的和。 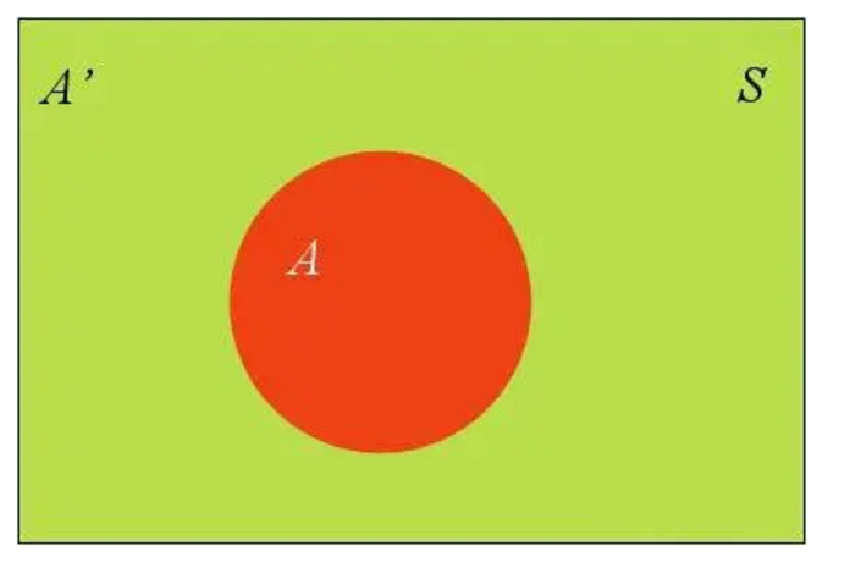 上图中,红色部分是事件A,绿色部分是事件A’,它们共同构成了样本空间S。
上图中,红色部分是事件A,绿色部分是事件A’,它们共同构成了样本空间S。
在这种情况下,事件B可以划分成两个部分。 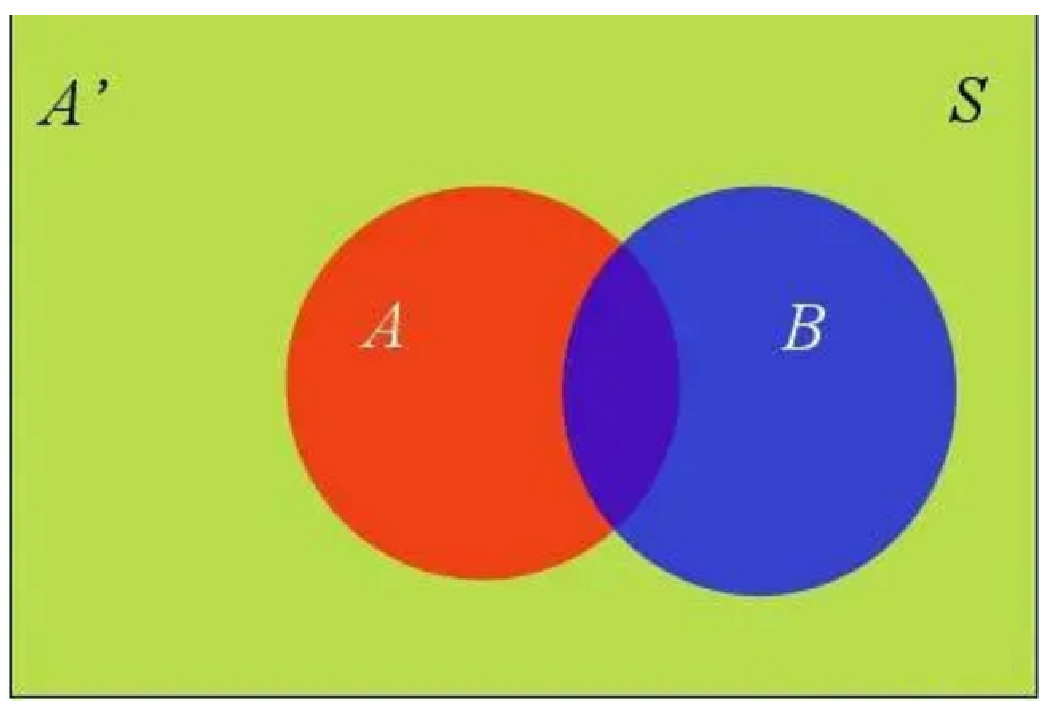 即:
即:
P
(
B
)
=
P
(
B
∩
A
)
+
P
(
B
∩
A
′
)
P(B) = P(B \\cap A) + P(B \\cap A')
P(B)=P(B∩A)+P(B∩A′)
在上面的推导当中,我们已知
P
(
B
∩
A
)
=
P
(
B
∣
A
)
P
(
A
)
P(B \\cap A) = P(B|A)P(A)
P(B∩A)=P(B∣A)P(A)
所以:
P
(
B
)
=
P
(
B
∣
A
)
P
(
A
)
+
P
(
B
∣
A
′
)
P
(
A
′
)
P(B) = P(B|A)P(A) + P(B|A')P(A')
P(B)=P(B∣A)P(A)+P(B∣A′)P(A′)
这就是全概率公式。它的含义是,如果A和A’构成样本空间的一个划分,那么事件B的概率,就等于A和A’的概率分别乘以B对这两个事件的条件概率之和。
将这个公式代入上一节的条件概率公式,就得到了条件概率的另一种写法:
P
(
A
∣
B
)
=
P
(
B
∣
A
)
P
(
A
)
P
(
B
∣
A
)
P
(
A
)
+
P
(
B
∣
A
′
)
P
(
A
′
)
P(A|B)=\\frac{P(B|A)P(A)}{P(B|A)P(A)+P(B|A')P(A')}
P(A∣B)=P(B∣A)P(A)+P(B∣A′)P(A′)P(B∣A)P(A)
4.4 贝叶斯推断
对条件概率公式进行变形,可以得到如下形式:
P
(
A
∣
B
)
=
P
(
A
)
P
(
B
∣
A
)
P
(
B
)
P(A \\mid B) = P(A)\\frac{P(B \\mid A)}{P(B)}
P(A∣B)=P(A)P(B)P(B∣A)
我们把P(A)称为"先验概率"(Prior probability),即在B事件发生之前,我们对A事件概率的一个判断。
P(A|B)称为"后验概率"(Posterior probability),即在B事件发生之后,我们对A事件概率的重新评估。
P(B|A)/P(B)称为"可能性函数"(Likelyhood),这是一个调整因子,使得预估概率更接近真实概率。
所以,条件概率可以理解成式子:后验概率=先验概率x调整因子
这就是贝叶斯推断的含义。我们先预估一个"先验概率",然后加入实验结果,看这个实验到底是增强还是削弱了"先验概率",由此得到更接近事实的"后验概率"。
4.5 朴素贝叶斯推断
理解了贝叶斯推断,那么让我们继续看看朴素贝叶斯。贝叶斯和朴素贝叶斯的概念是不同的,区别就在于“朴素”二字,朴素贝叶斯对条件概率分布做了条件独立性的假设。 比如下面的公式,假设有n个特征:
根据贝叶斯定理,后验概率 P(a|X) 可以表示为:
P
(
a
∣
X
)
=
P
(
X
∣
a
)
P
(
a
)
P
(
X
)
P(a|X) = \\frac{P(X|a)P(a)}{P(X)}
P(a∣X)=P(X)P(X∣a)P(a)
其中:
- P(X|a) 是给定类别 ( a ) 下观测到特征向量
X
=
(
x
1
,
x
2
,
.
.
.
,
x
n
)
X=(x_1, x_2, …, x_n)
X=(x1,x2,…,xn)的概率; - P(a) 是类别 a 的先验概率;
- P(X) 是观测到特征向量 X 的边缘概率,通常作为归一化常数处理。
朴素贝叶斯分类器的关键假设是特征之间的条件独立性,即给定类别 a ,特征
x
i
x_i
xi 和
x
j
x_j
xj (其中
i
≠
j
i \\neq j
i=j 相互独立。)
因此,我们可以将联合概率 P(X|a) 分解为各个特征的概率乘积:
P
(
X
∣
a
)
=
P
(
x
1
,
x
2
,
.
.
.
,
x
n
∣
a
)
=
P
(
x
1
∣
a
)
P
(
x
2
∣
a
)
.
.
.
P
(
x
n
∣
a
)
P(X|a) = P(x_1, x_2, …, x_n|a) = P(x_1|a)P(x_2|a)…P(x_n|a)
P(X∣a)=P(x1,x2,…,xn∣a)=P(x1∣a)P(x2∣a)…P(xn∣a)
将这个条件独立性假设应用于贝叶斯公式,我们得到:
P
(
a
∣
X
)
=
P
(
x
1
∣
a
)
P
(
x
2
∣
a
)
.
.
.
P
(
x
n
∣
a
)
P
(
a
)
P
(
X
)
P(a|X) = \\frac{P(x_1|a)P(x_2|a)…P(x_n|a)P(a)}{P(X)}
P(a∣X)=P(X)P(x1∣a)P(x2∣a)…P(xn∣a)P(a)
这样,朴素贝叶斯分类器就可以通过计算每种可能类别的条件概率和先验概率,然后选择具有最高概率的类别作为预测结果。
这里给出一个例子:
| 1 | 清晰 | 清绿 | 清脆 | 好瓜 |
| 2 | 模糊 | 乌黑 | 浊响 | 坏瓜 |
| 3 | 模糊 | 清绿 | 浊响 | 坏瓜 |
| 4 | 清晰 | 乌黑 | 沉闷 | 好瓜 |
| 5 | 清晰 | 清绿 | 浊响 | 好瓜 |
| 6 | 模糊 | 乌黑 | 沉闷 | 坏瓜 |
| 7 | 清晰 | 乌黑 | 清脆 | 好瓜 |
| 8 | 模糊 | 清绿 | 沉闷 | 好瓜 |
| 9 | 清晰 | 乌黑 | 浊响 | 坏瓜 |
| 10 | 模糊 | 清绿 | 清脆 | 好瓜 |
| 11 | 清晰 | 清绿 | 沉闷 | ? |
| 12 | 模糊 | 乌黑 | 浊响 | ? |
示例:
p(a|X) = p(X|a)* p(a)/p(X) #贝叶斯公式
p(X|a) = p(x1,x2,x3…xn|a) = p(x1|a)*p(x2|a)*p(x3|a)…p(xn|a)
p(X) = p(x1,x2,x3…xn) = p(x1)*p(x2)*p(x3)…p(xn)
p(a|X) = p(x1|a)*p(x2|a)*p(x3|a)…p(xn|a) * p(a) / p(x1)*p(x2)*p(x3)…p(xn) #朴素贝叶斯公式
P(好瓜)=(好瓜数量)/所有瓜
P(坏瓜)=(坏瓜数量)/所有瓜
p(纹理清晰)=(纹理清晰数量)/所有瓜
p(纹理清晰|好瓜)= 好瓜中纹理清晰数量/好瓜数量
p(纹理清晰|坏瓜)= 坏瓜中纹理清晰数量/坏瓜数量
p(好瓜|纹理清晰,色泽清绿,鼓声沉闷)
=【p(好瓜)】*【p(纹理清晰,色泽清绿,鼓声沉闷|好瓜)】/【p(纹理清晰,色泽清绿,鼓声沉闷)】
=【p(好瓜)】*【p(纹理清晰|好瓜)*p(色泽清绿|好瓜)*p(鼓声沉闷|好瓜)】/【p(纹理清晰)*p(色泽清绿)*p(鼓声沉闷)】
p(坏瓜|纹理清晰,色泽清绿,鼓声沉闷)
=【p(坏瓜)*p(纹理清晰|坏瓜)*p(色泽清绿|坏瓜)*p(鼓声沉闷|坏瓜)】/【p(纹理清晰)*p(色泽清绿)*p(鼓声沉闷)】
从公式中判断"p(好瓜|纹理清晰,色泽清绿,鼓声沉闷)"和"p(坏瓜|纹理清晰,色泽清绿,鼓声沉闷)"时,因为它们的分母
值是相同的,[值都是p(纹理清晰)*p(色泽清绿)*p(鼓声沉闷)],所以只要计算它们的分子就可以判断是"好瓜"还是"坏瓜"之间谁大谁小了,所以没有必要计算分母
p(好瓜) = 6/10
p(坏瓜)=4/10
p(纹理清晰|好瓜) = 4/6
p(色泽清绿|好瓜) = 4/6
p(鼓声沉闷|好瓜) = 2/6
p(纹理清晰|坏瓜) = 1/4
p(色泽清绿|坏瓜) = 1/4
p(鼓声沉闷|坏瓜) = 1/4
把以上计算代入公式的分子
p(好瓜)*p(纹理清晰|好瓜)*p(色泽清绿|好瓜)*p(鼓声沉闷|好瓜) = 4/45
p(坏瓜)*p(纹理清晰|坏瓜)*p(色泽清绿|坏瓜)*p(鼓声沉闷|坏瓜) = 1/160
所以
p(好瓜|纹理清晰,色泽清绿,鼓声沉闷) > p(坏瓜|纹理清晰,色泽清绿,鼓声沉闷),
所以把(纹理清晰,色泽清绿,鼓声沉闷)的样本归类为好瓜
4.6 拉普拉斯平滑系数
某些事件或特征可能从未出现过,这会导致它们的概率被估计为零。然而,在实际应用中,即使某个事件或特征没有出现在训练集中,也不能完全排除它在未来样本中出现的可能性。拉普拉斯平滑技术可以避免这种“零概率陷阱”
公式为: 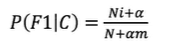
一般α取值1,m的值为总特征数量
通过这种方法,即使某个特征在训练集中从未出现过,它的概率也不会被估计为零,而是会被赋予一个很小但非零的值,从而避免了模型在面对新数据时可能出现的过拟合或预测错误。
比如计算判断新瓜(纹理清晰,色泽淡白,鼓声沉闷)是好和坏时,因为在样本中色泽淡白没有出现,导致出现0值,会影响计算结果,要采用拉普拉斯平滑系数。
p(好瓜|纹理清晰,色泽淡白,鼓声沉闷)
=【p(好瓜)】*【p(纹理清晰|好瓜)*p(色泽淡白|好瓜)*p(鼓声沉闷|好瓜)】/【p(纹理清晰)*p(色泽淡白)*p(鼓声沉闷)】
p(坏瓜|纹理清晰,色泽淡白,鼓声沉闷)
=【p(坏瓜)】*【p(纹理清晰|坏瓜)*p(色泽淡白|坏瓜)*p(鼓声沉闷|坏瓜)】/【p(纹理清晰)*p(色泽淡白)*p(鼓声沉闷)】
p(纹理清晰|好瓜)= (4+1)/(6+3) # +1是因为防止零概率 +3是因为有3个特征(纹理,色泽,鼓声)
p(色泽淡白|好瓜)= (0+1)/(6+3)
p(鼓声沉闷|好瓜) = (2+1)/(6+3)
p(纹理清晰|坏瓜)= (1+1)/(4+3)
p(色泽淡白|坏瓜)= (0+1)/(4+3)
p(鼓声沉闷|坏瓜) = (1+1)/(4+3)
4.7 api与示例
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split
from sklearn.naive_bayes import MultinomialNB
wine=load_wine()
x=wine.data
y=wine.target
x_train,x_test,y_train,y_test=train_test_split(wine.data,wine.target,test_size=0.2,random_state=22)
model=MultinomialNB()
model.fit(x_train,y_train)
print(model.score(x_test,y_test))
# 新数据预测
data_new=[[i for i in range(13)]]
print(model.predict(data_new))

总结
本文简单讲解了机器学习中数据降维、KNN算法、交叉验证、超参数搜索以及贝叶斯算法。









评论前必须登录!
注册