 网硕互联帮助中心
网硕互联帮助中心XPath和xml详细讲解
感受第一次使用XPath提取数据
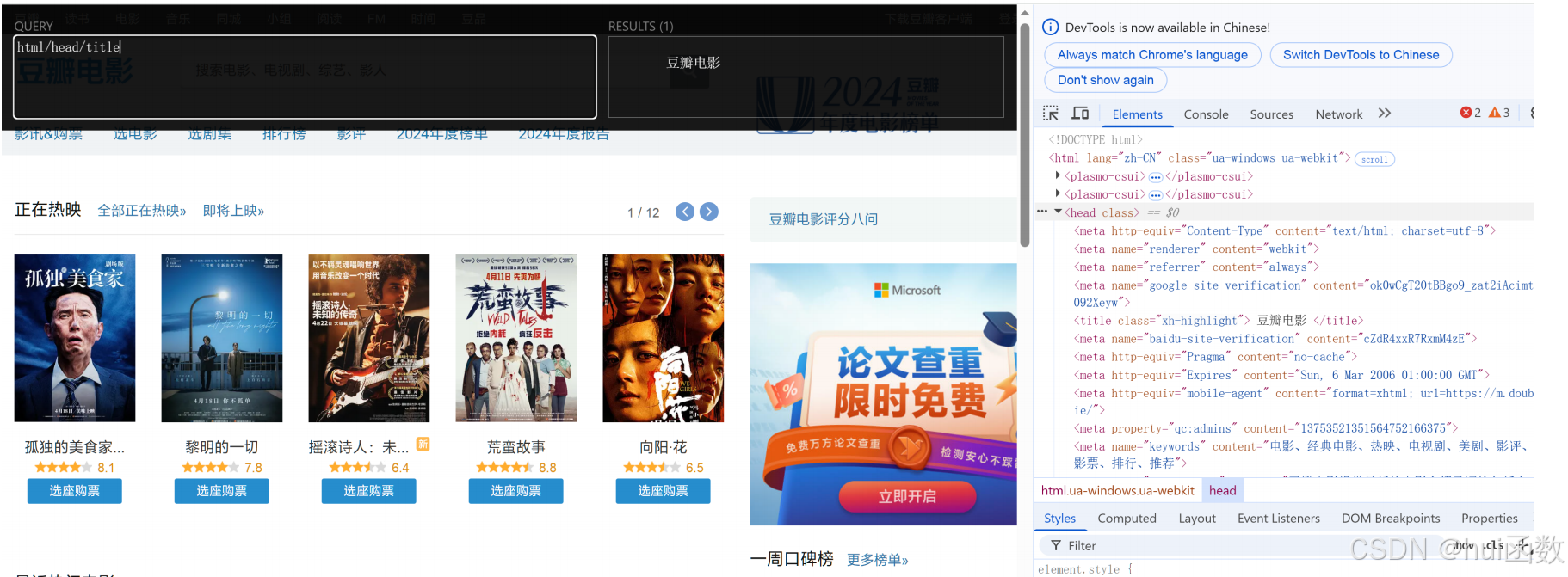
目的:在浏览器中打开豆瓣电影首页,试一下能否能找到title。
打开XPath Helper工具,在左侧的编辑区域中输入上述路径表达式,此时右侧区域中展示了选取的
结果及数目。
语法:
绝对路径:html/head/title
相对路径:html//title
直接写://title
XPath的节点关系
学习XPath语法需要先了解XPath中的节点关系
XPath中的节点是什么
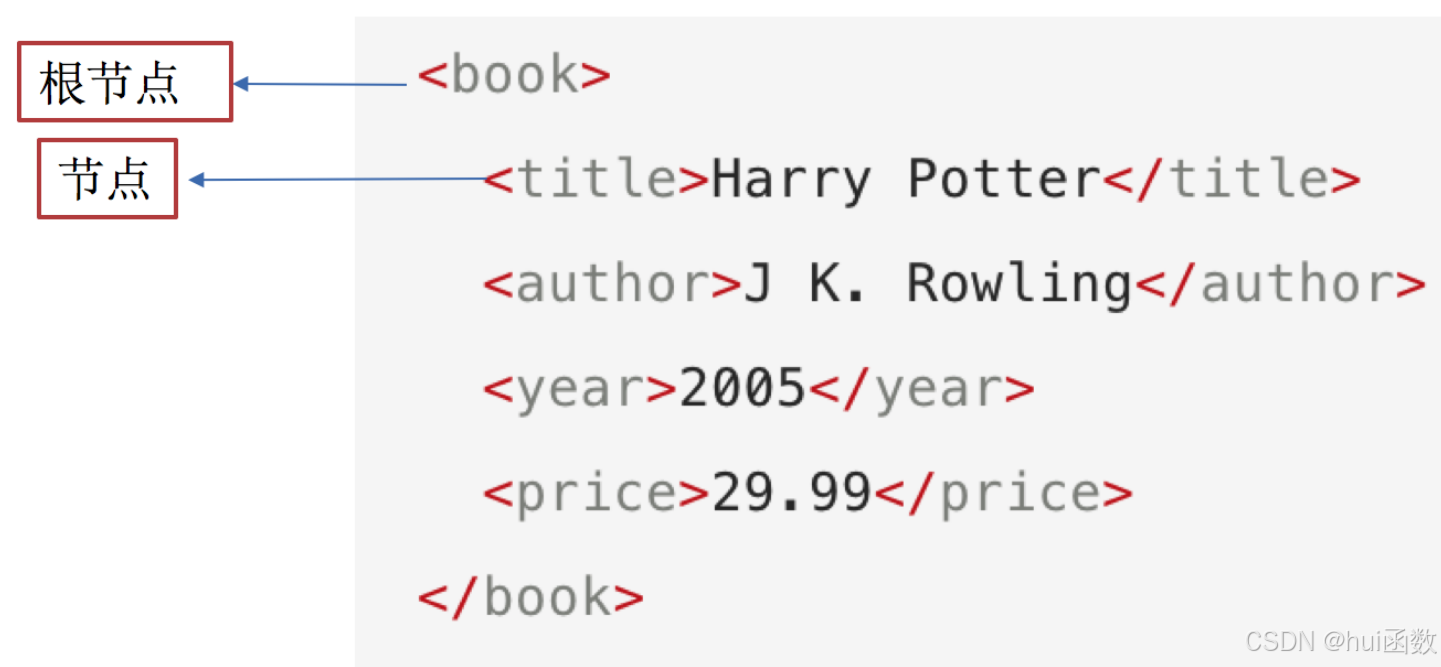
每个html、xml的标签我们都称之为节点,其中最顶层的节点称为根节点。我们以xml为例,html也是一样的
XPath中节点的关系

author 是 title 的第一个兄弟节点
XPath语法-基础节点选择语法
XPath 使用路径表达式来选取 XML 文档中的节点或者节点集。
这些路径表达式和我们在常规的电脑文件系统中看到的表达式非常相似。
使用chrome插件选择标签时候,选中时,选中的标签会添加属性class=\”xh-highlight\”
XPath定位节点以及提取属性或文本内容的语法
| nodename | 选中该元素 |
| / | 从根节点选取,或者元素和元素间的过度 |
| // | 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置 |
| . | 选取当前节点 |
| .. | 选取当前节点的父节点 |
| @ | 选取属性 |
| text() | 选取文本 |
语法练习
接下来我们通过豆瓣的页面来练习上述语法:豆瓣电影
-
选择所有的h2下的文本
-
//h2/text()
-
-
获取所有a标签下的href
-
//a/@href
-
-
获取html下的head下的title的文本
-
html/head/title/text()
-
-
获取html下的head下的link标签的href
-
html/head/link/@href
-
知识点:掌握 XPath语法-选取节点以及提取属性或文本内容的语法
XPath语法-节点修饰语法
可以根据标签的属性值、下标等来获取特定的节点
节点修饰语法
| //title[@lang=\”eng\”] | 选择lang属性值为eng的所有title元素 |
| /bookstore/book[1] | 选择属于bookstore子元素名为book的第一个book元素 |




评论前必须登录!
注册