 网硕互联帮助中心
网硕互联帮助中心Fine-tuning对于接触过大模型原理的同学来说是一个不陌生的词,通常来说我们会首先加载一个预训练好的基座模型,再用自己的数据对其进行微调训练。如果我们希望继续保持他的文本对话功能,一般通过构建对应的微调指令+提示工程对齐进行指令微调;如果我们希望将其变成一个分类模型,我们可以在原模型基础上增加映射层等等。各式各样的方式,都面向我们的需求。
相比传统的Fine-tuning,LoRA(Low-Rank Adaptation)通过引入低秩矩阵分解来调整预训练模型的权重。传统微调需要更新所有参数,而 LoRA 仅训练注入的小型低秩矩阵,冻结原始模型参数。
LoRA
我们在预训练模型增加由两个低秩矩阵组成的权重矩阵A和B,在微调过程中对A和B进行训练,冻结W。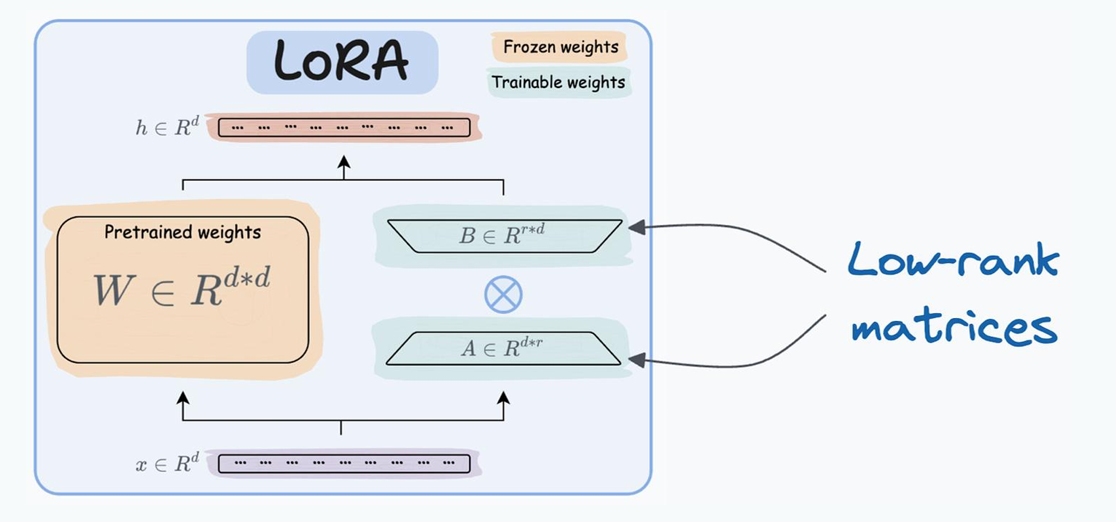
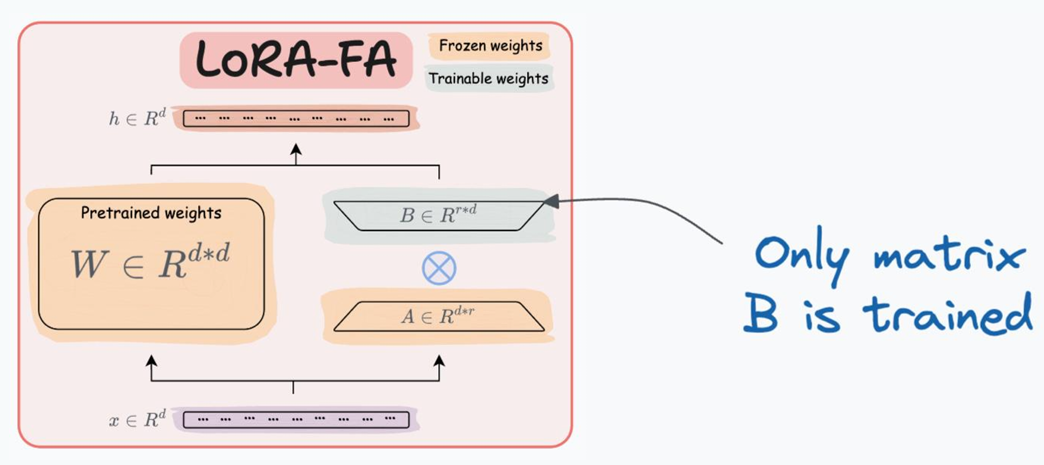
LoRA-FA(Frozen-A)
相比值 LoRA,LoRA-FA通过冻结矩阵A只对B训练进一步减小激活值的内存占用
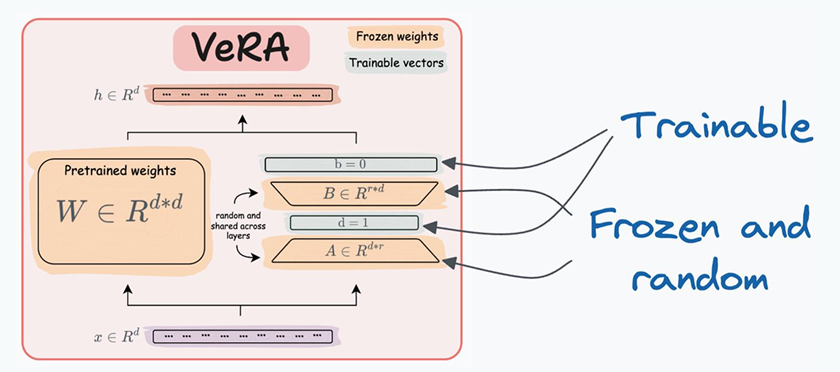
VeRA
还能不能继续减少训练的参数? VeRA将A和B一起冻结,只对A和B紧接着的两个层特定缩放向量进行训练,对于A和B保持随机化的冻结状态。
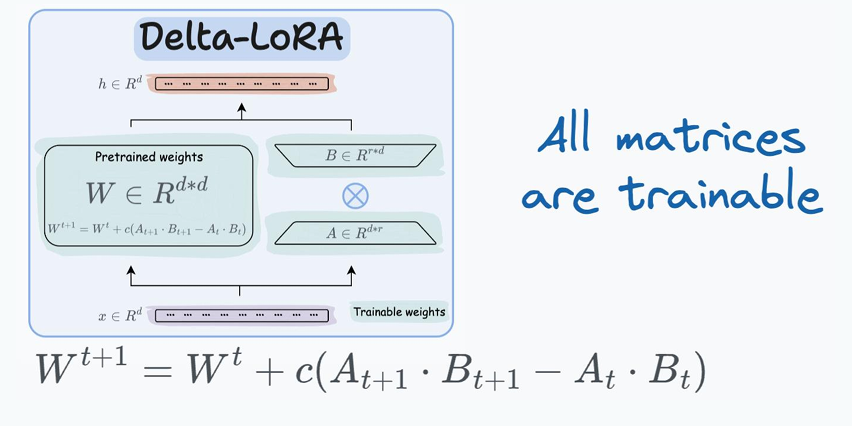
Delta-LoRA
一直在做减法,现在来个加法,Delta-LoRA把包括训练好的矩阵W一同纳入训练范围。
LoRA+
在LoRA中,A和B使用相同的学习率进行更新,学者莫研究发现对B矩阵才需更高的学习率能够有更好的收敛效果。

对于上述多种LoRA方式,我们在做科研或项目对照实验中均可采纳,择优采用。


评论前必须登录!
注册