 网硕互联帮助中心
网硕互联帮助中心
📖标题:Checklists Are Better Than Reward Models For Aligning Language Models 🌐来源:arXiv, 2507.18624
🌟摘要
语言模型必须适应理解和遵循用户指令。强化学习被广泛用于促进这一点——通常使用“帮助”和“伤害”等固定标准。在我们的工作中,我们建议使用灵活的、特定于指令的标准作为扩大强化学习在引发指令跟随方面可能产生的影响的一种手段。我们提出了“从清单反馈强化学习”(RLCF)。从指令中,我们提取清单并评估响应满足每个项目的程度——同时使用 AI 法官和专门的验证者程序——然后将这些分数组合起来计算 RL 的奖励。我们在五个广泛研究的基准上将 RLCF 与其他应用于强指令跟随模型 (Qwen2.5-7B-Instruct) 的对齐方法进行比较——RLCF 是提高每个基准性能的唯一方法,包括 FollowerBench 上的硬满意度提高 4 点,InFoBench 增加 6 点,Arena-Hard 上的胜率提高 3 点。这些结果建立了清单反馈作为改进语言模型支持表达大量需求的查询的关键工具。
🛎️文章简介
🔸研究问题:如何以自动化、灵活、直观且适用于任何指令或响应的方式对语言模型的响应进行评分,以提高语言模型的对齐能力? 🔸主要贡献:论文提出了一种通过提取动态检查表来进行强化学习的新方法,即“基于检查表反馈的强化学习”(RLCF),并展示该方法在不同基准测试中的有效性。
📝重点思路
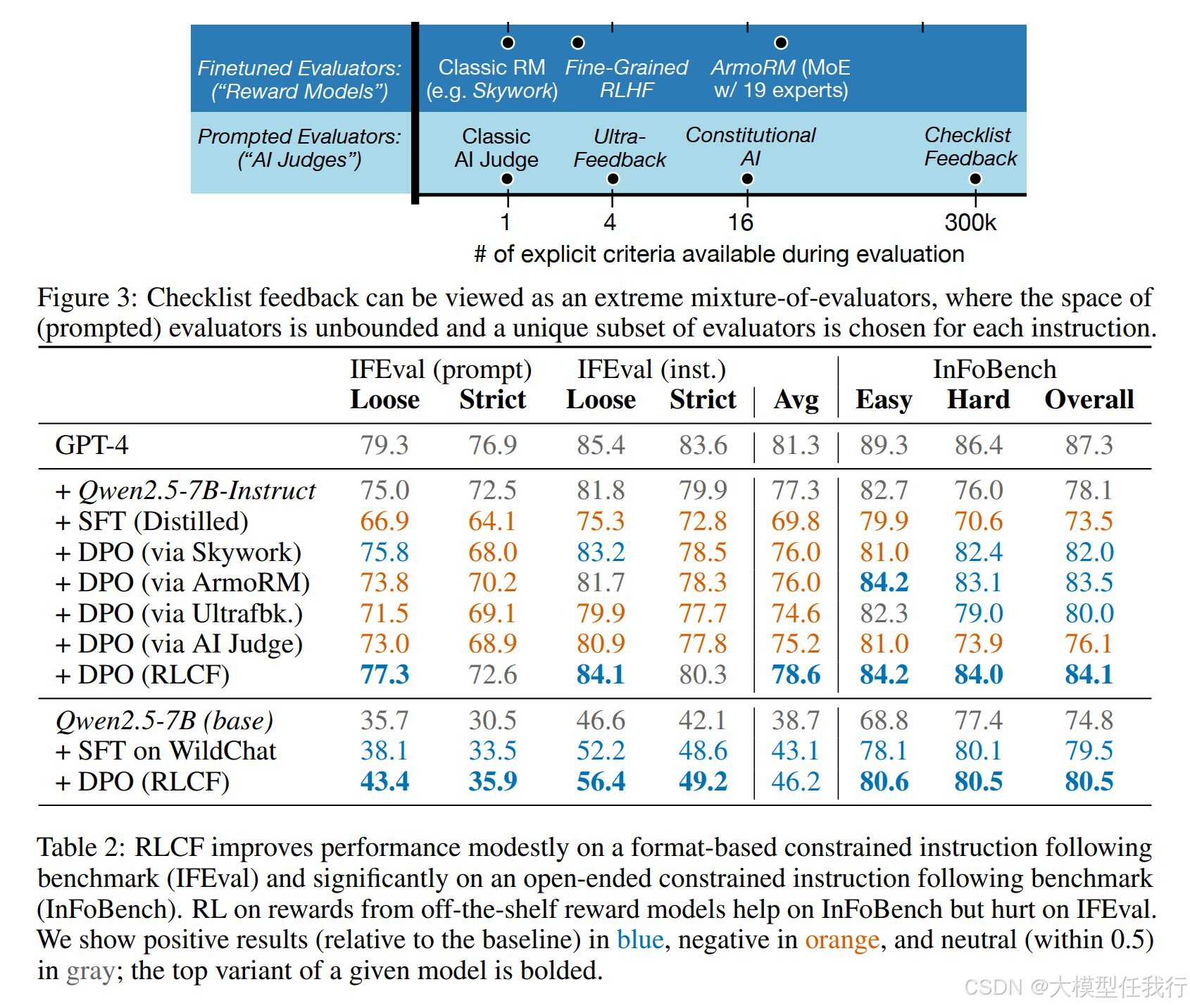
🔸使用两种方法提取检查表:直接方法和候选方法。直接方法通过提示语言模型从给定指令中提取检查表,候选方法则通过生成不同质量的响应来写出可能的失败模式,从而构建检查表。 🔸提出“强化学习从检查表反馈” (RLCF)的原则,通过保持响应对中最大差异的40%来提供有信息的学习信号,以便进行偏好优化。 🔸引入了一种新的响应评分算法,该算法结合了语言模型和验证程序,根据检查表中的每个项目对响应进行打分。 🔸在多个基准上进行评估,包括IFEval、InFoBench、FollowBench、AlpacaEval和Arena-Hard,以验证RLCF的有效性。
🔎分析总结
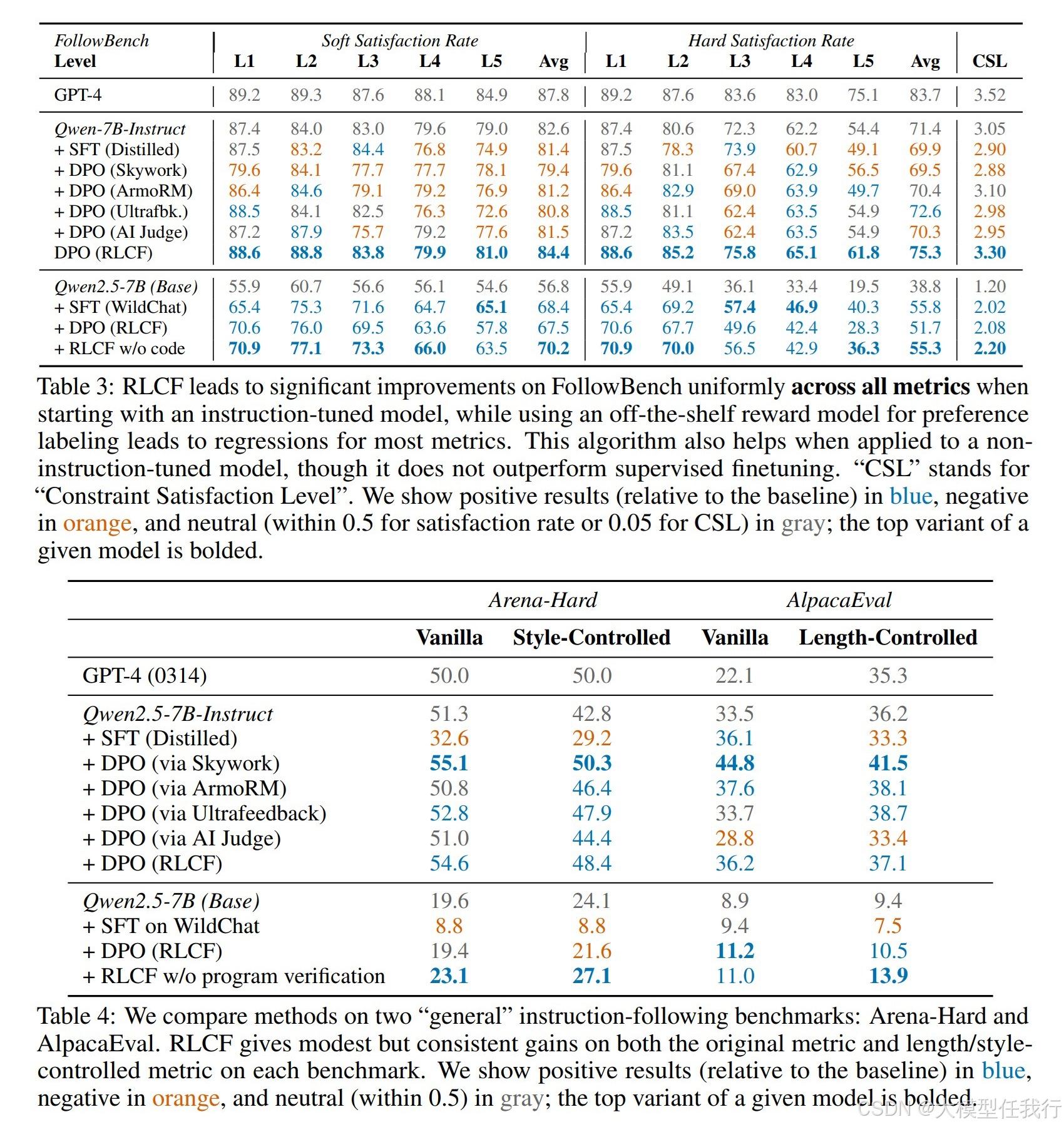
🔸RLCF在所有指令遵循基准上均表现出一致的性能提升,相较于基线模型在FollowBench上平均硬满意率提升5.4%,在InFoBench上提升6.9%,在Arena-Hard上提升6.4%。 🔸检查表生成的候选方式比直接提示生成的检查表在客观性、原子性和整体质量上表现更佳,从而在后续的强化学习训练中产生积极效果。 🔸RLCF的强大之处在于可以仅通过教师模型,无需额外数据或人工标注,适用于多种语言和领域,从而证明了检查表反馈与人类偏好判断之间的良好相关性。
💡个人观点
论文的创新点在于将动态检查表的生成和使用引入语言模型的训练过程中,严格关注指令的各个方面,通过客观的标准提升了模型响应的质量。
🧩附录



评论前必须登录!
注册