 网硕互联帮助中心
网硕互联帮助中心AI驱动的网页内容提取革命:Crawl4AI让数据采集智能化
关键词:Crawl4AI, AI爬虫, 网页内容提取, 大语言模型, 智能爬虫, Python爬虫, 机器学习爬虫, 自动化数据采集
摘要:Crawl4AI是一个革命性的AI驱动网页内容提取框架,它结合了大语言模型的智能理解能力与传统爬虫的高效性能。本文将深入探讨Crawl4AI的核心原理、实际应用场景,以及如何利用这一工具实现智能化的数据采集,为开发者提供从入门到精通的完整指南。
文章目录
- AI驱动的网页内容提取革命:Crawl4AI让数据采集智能化
-
- 为什么传统爬虫已经不够用了?
-
- 传统爬虫的三大痛点
- 什么是Crawl4AI?
-
- Crawl4AI的核心特性
- 快速上手:第一个Crawl4AI程序
-
- 安装Crawl4AI
- 基础使用示例
- AI智能提取:让爬虫理解内容含义
-
- 使用LLM提取策略
- 智能内容过滤
- 高级应用:构建智能数据采集系统
-
- 多页面批量采集
- 处理动态内容
- 实战案例:构建电商商品监控系统
-
- 项目结构设计
- 性能优化与最佳实践
-
- 1. 并发控制
- 2. 缓存策略
- 3. 错误处理与重试
- 与其他框架的对比
-
- Crawl4AI vs 传统爬虫框架
- 选择建议
- 常见问题与解决方案
-
- Q1: 如何处理需要登录的网站?
- Q2: 如何处理反爬虫机制?
- Q3: 如何优化大规模爬取的内存使用?
- 未来发展趋势
-
- 1. 多模态内容提取
- 2. 更智能的反爬虫绕过
- 3. 实时流式处理
- 总结与展望
-
- 核心优势回顾
- 应用前景
- 学习建议
- 参考资料与扩展阅读
为什么传统爬虫已经不够用了?
想象一下,你是一名图书管理员,每天需要从数千本书中找出特定信息。传统的方法是逐页翻阅,寻找关键词,这就像我们传统的网页爬虫——只能通过CSS选择器和XPath来"盲目"地提取预定义位置的内容。
但是,如果有一个智能助手能够理解书籍内容的含义,自动识别你真正需要的信息呢?这就是Crawl4AI带来的革命性变化。
传统爬虫的三大痛点
什么是Crawl4AI?
Crawl4AI是一个开源的Python框架,它将大语言模型(LLM)的智能理解能力与网页爬取技术完美结合。简单来说,它就像给传统爬虫装上了"大脑",让爬虫能够像人类一样理解网页内容。
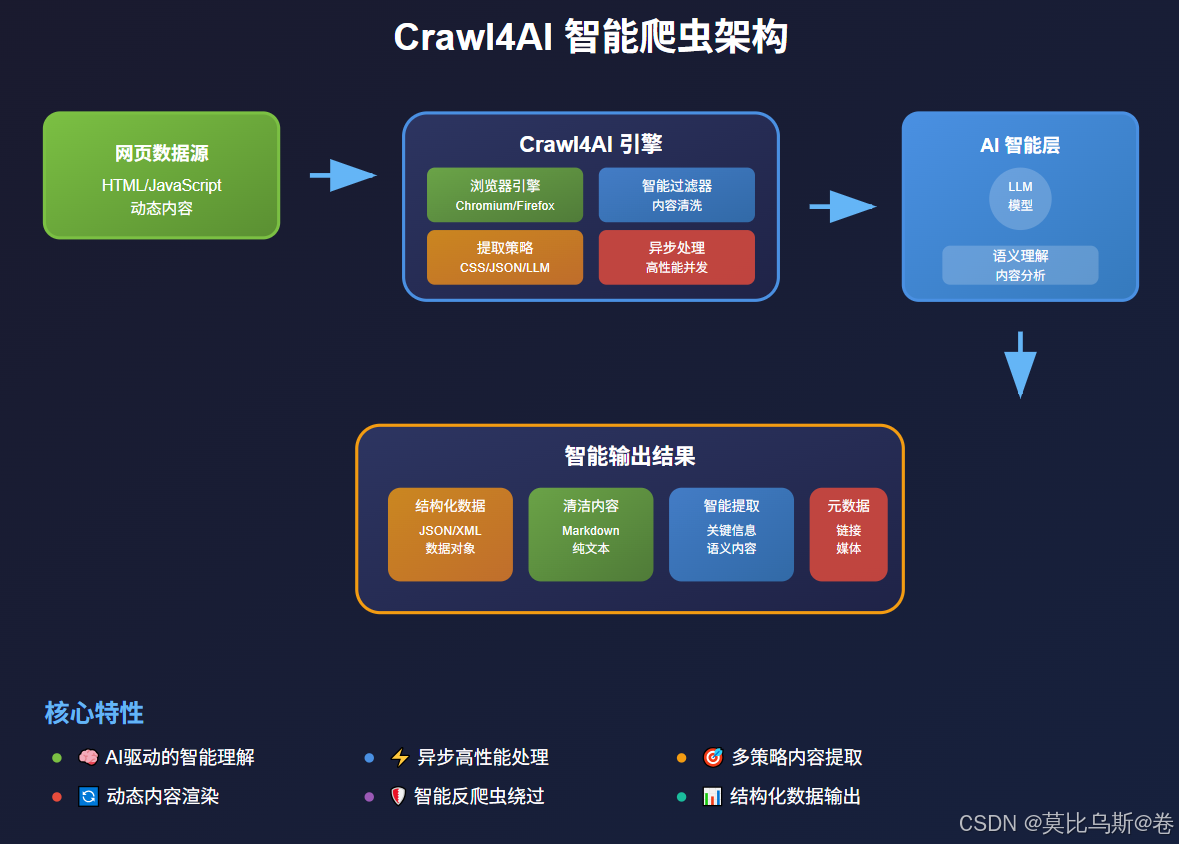
Crawl4AI的核心特性
- AI驱动的内容提取:使用LLM理解和提取网页内容
- 智能内容过滤:自动识别并提取有价值的信息
- 多种提取策略:支持LLM、CSS选择器、JavaScript等多种方式
- 异步处理:高性能的异步爬取能力
- 多媒体支持:可处理文本、图片、链接等多种内容类型
快速上手:第一个Crawl4AI程序
让我们从最简单的例子开始,看看Crawl4AI是如何工作的。
安装Crawl4AI
pip install crawl4ai
基础使用示例
import asyncio
from crawl4ai import AsyncWebCrawler
async def basic_crawl():
async with AsyncWebCrawler(verbose=True) as crawler:
# 简单爬取网页
result = await crawler.arun(url="https://www.example.com")
print(result.markdown)
# 运行爬虫
asyncio.run(basic_crawl())
这个简单的例子就能将网页内容转换为结构化的Markdown格式。但这只是冰山一角!
AI智能提取:让爬虫理解内容含义
传统爬虫就像是用固定模板套取内容,而Crawl4AI更像是一个智能阅读者。让我们看看如何利用AI进行智能内容提取。
使用LLM提取策略
import asyncio
from crawl4ai import AsyncWebCrawler
from crawl4ai.extraction_strategy import LLMExtractionStrategy
async def llm_extraction():
# 定义提取策略
strategy = LLMExtractionStrategy(
provider="ollama/llama2", # 可以使用本地模型
api_token="your-api-token",
instruction="""
从这个网页中提取所有产品信息,包括:
1. 产品名称
2. 价格
3. 产品描述
4. 用户评分
请以JSON格式返回结果。
"""
)
async with AsyncWebCrawler(verbose=True) as crawler:
result = await crawler.arun(
url="https://example-shop.com",
extraction_strategy=strategy
)
print("提取的产品信息:")
print(result.extracted_content)
asyncio.run(llm_extraction())
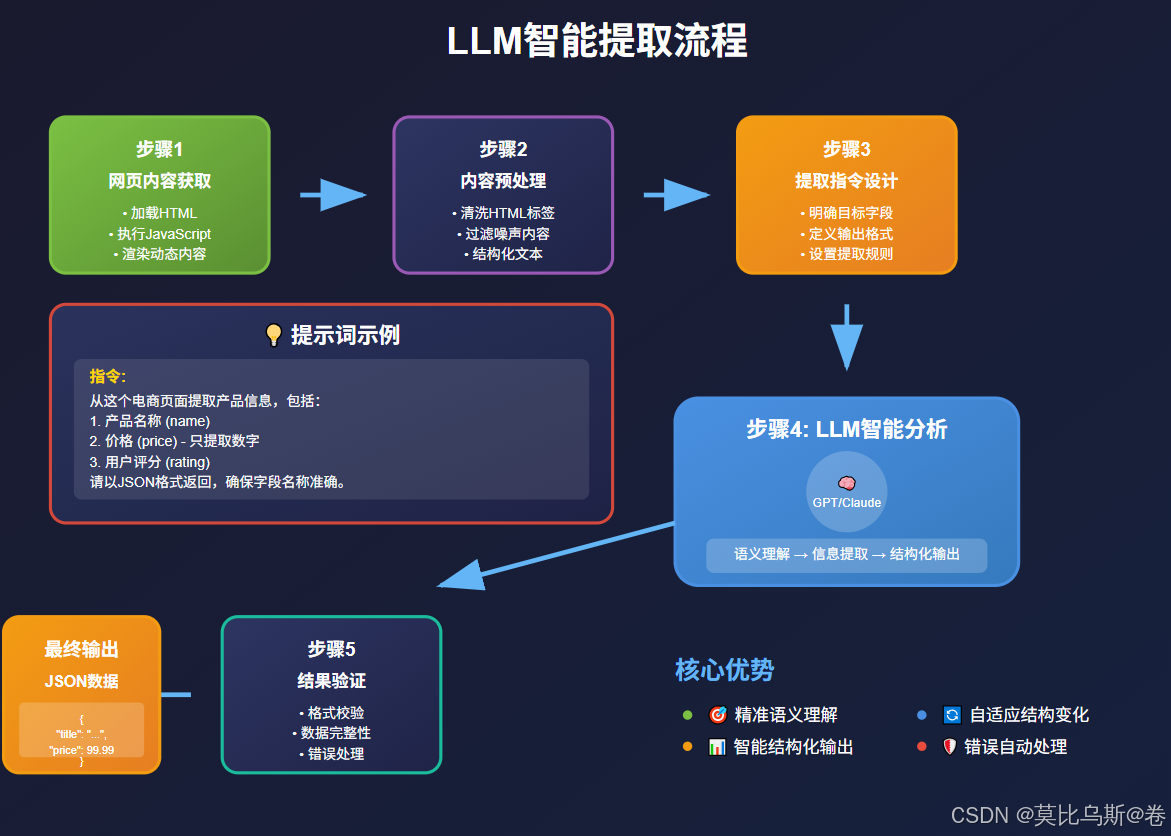
智能内容过滤
Crawl4AI还能智能地过滤掉广告、导航栏等无关内容:
from crawl4ai.content_filter import PruningContentFilter
async def smart_filtering():
# 创建内容过滤器
content_filter = PruningContentFilter(
threshold=0.48, # 内容相关性阈值
threshold_type="fixed",
min_word_threshold=0
)
async with AsyncWebCrawler(verbose=True) as crawler:
result = await crawler.arun(
url="https://news-website.com",
content_filter=content_filter
)
# 只返回高质量的主要内容
print(result.cleaned_html)
高级应用:构建智能数据采集系统
现在让我们构建一个更复杂的应用——智能新闻采集系统。
多页面批量采集
import asyncio
from crawl4ai import AsyncWebCrawler
from crawl4ai.extraction_strategy import JsonCssExtractionStrategy
async def news_crawler():
# 定义新闻提取规则
schema = {
"name": "新闻文章",
"baseSelector": "article",
"fields": [
{"name": "标题", "selector": "h1", "type": "text"},
{"name": "作者", "selector": ".author", "type": "text"},
{"name": "发布时间", "selector": ".publish-date", "type": "text"},
{"name": "内容", "selector": ".content", "type": "text"},
{"name": "标签", "selector": ".tags a", "type": "list"}
]
}
extraction_strategy = JsonCssExtractionStrategy(schema)
news_urls = [
"https://news-site.com/article1",
"https://news-site.com/article2",
"https://news-site.com/article3"
]
async with AsyncWebCrawler(verbose=True) as crawler:
# 批量爬取新闻
tasks = []
for url in news_urls:
task = crawler.arun(
url=url,
extraction_strategy=extraction_strategy
)
tasks.append(task)
results = await asyncio.gather(*tasks)
# 处理结果
all_articles = []
for result in results:
if result.success:
articles = json.loads(result.extracted_content)
all_articles.extend(articles)
return all_articles
处理动态内容
对于需要JavaScript渲染的页面,Crawl4AI同样游刃有余:
async def dynamic_content_crawl():
async with AsyncWebCrawler(
browser_type="chromium", # 使用Chromium浏览器
headless=True,
verbose=True
) as crawler:
# 等待页面完全加载
result = await crawler.arun(
url="https://spa-website.com",
js_code="""
// 等待数据加载完成
await new Promise(resolve => {
const checkData = () => {
if (document.querySelector('.data-loaded')) {
resolve();
} else {
setTimeout(checkData, 100);
}
};
checkData();
});
""",
wait_for="networkidle"
)
return result.markdown
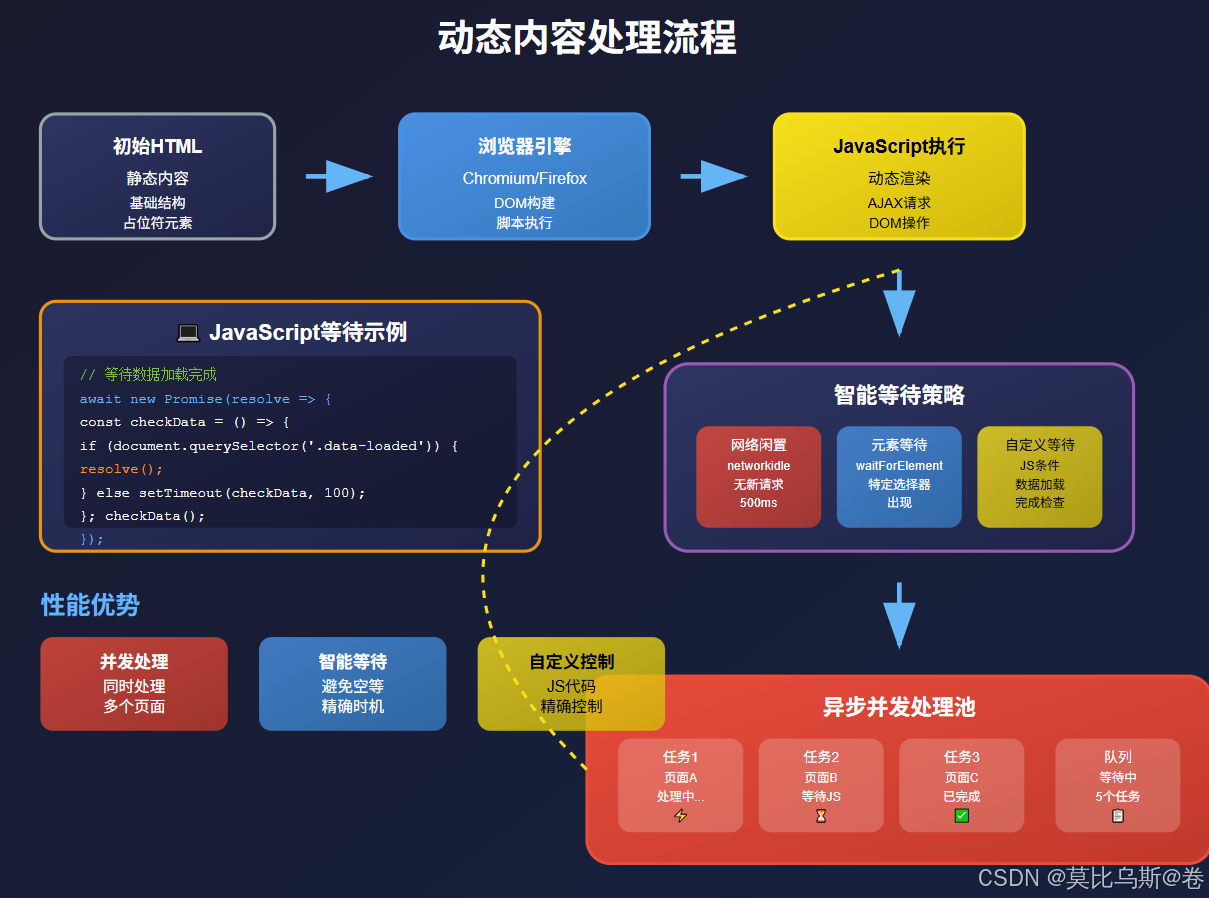
实战案例:构建电商商品监控系统
让我们通过一个完整的实战案例来展示Crawl4AI的强大功能。我们将构建一个电商商品价格监控系统。
项目结构设计
import asyncio
import json
import sqlite3
from datetime import datetime
from crawl4ai import AsyncWebCrawler
from crawl4ai.extraction_strategy import LLMExtractionStrategy
class ProductMonitor:
def __init__(self, db_path="products.db"):
self.db_path = db_path
self.init_database()
def init_database(self):
"""初始化数据库"""
conn = sqlite3.connect(self.db_path)
cursor = conn.cursor()
cursor.execute("""
CREATE TABLE IF NOT EXISTS products (
id INTEGER PRIMARY KEY,
name TEXT,
price REAL,
url TEXT,
last_checked TIMESTAMP,
price_history TEXT
)
""")
conn.commit()
conn.close()
async def extract_product_info(self, url):
"""提取商品信息"""
strategy = LLMExtractionStrategy(
provider="ollama/llama2",
instruction="""
从这个商品页面提取以下信息:
1. 商品名称
2. 当前价格(只提取数字)
3. 商品描述
4. 库存状态
请以JSON格式返回:
{
"name": "商品名称",
"price": 价格数字,
"description": "商品描述",
"in_stock": true/false
}
"""
)
async with AsyncWebCrawler(verbose=True) as crawler:
result = await crawler.arun(
url=url,
extraction_strategy=strategy
)
if result.success:
return json.loads(result.extracted_content)
return None
async def monitor_products(self, urls):
"""监控商品价格变化"""
for url in urls:
try:
product_info = await self.extract_product_info(url)
if product_info:
self.save_product_data(url, product_info)
print(f"✅ 成功监控商品: {product_info['name']}")
else:
print(f"❌ 无法提取商品信息: {url}")
except Exception as e:
print(f"❌ 监控出错 {url}: {str(e)}")
def save_product_data(self, url, product_info):
"""保存商品数据到数据库"""
conn = sqlite3.connect(self.db_path)
cursor = conn.cursor()
# 检查商品是否已存在
cursor.execute(
"SELECT price_history FROM products WHERE url = ?",
(url,)
)
result = cursor.fetchone()
if result:
# 更新现有商品
price_history = json.loads(result[0] or "[]")
price_history.append({
"price": product_info["price"],
"timestamp": datetime.now().isoformat()
})
cursor.execute("""
UPDATE products
SET price = ?, last_checked = ?, price_history = ?
WHERE url = ?
""", (
product_info["price"],
datetime.now(),
json.dumps(price_history),
url
))
else:
# 插入新商品
price_history = [{
"price": product_info["price"],
"timestamp": datetime.now().isoformat()
}]
cursor.execute("""
INSERT INTO products (name, price, url, last_checked, price_history)
VALUES (?, ?, ?, ?, ?)
""", (
product_info["name"],
product_info["price"],
url,
datetime.now(),
json.dumps(price_history)
))
conn.commit()
conn.close()
# 使用示例
async def main():
monitor = ProductMonitor()
# 要监控的商品URL列表
product_urls = [
"https://shop.example.com/product1",
"https://shop.example.com/product2",
"https://shop.example.com/product3"
]
# 开始监控
await monitor.monitor_products(product_urls)
if __name__ == "__main__":
asyncio.run(main())
性能优化与最佳实践
1. 并发控制
import asyncio
from asyncio import Semaphore
async def controlled_crawling(urls, max_concurrent=5):
"""控制并发数量的爬取"""
semaphore = Semaphore(max_concurrent)
async def crawl_single(url):
async with semaphore:
async with AsyncWebCrawler() as crawler:
return await crawler.arun(url=url)
# 创建并发任务
tasks = [crawl_single(url) for url in urls]
results = await asyncio.gather(*tasks, return_exceptions=True)
return results
2. 缓存策略
from crawl4ai.cache_strategy import CacheMode
async def cached_crawling():
async with AsyncWebCrawler(
cache_strategy=CacheMode.ENABLED, # 启用缓存
verbose=True
) as crawler:
# 第一次访问会缓存结果
result1 = await crawler.arun(url="https://example.com")
# 第二次访问会使用缓存
result2 = await crawler.arun(url="https://example.com")
print(f"缓存命中: {result2.from_cache}")
3. 错误处理与重试
import asyncio
from tenacity import retry, stop_after_attempt, wait_exponential
class RobustCrawler:
def __init__(self):
self.crawler = None
@retry(
stop=stop_after_attempt(3),
wait=wait_exponential(multiplier=1, min=4, max=10)
)
async def safe_crawl(self, url, **kwargs):
"""带重试机制的安全爬取"""
try:
async with AsyncWebCrawler(verbose=True) as crawler:
result = await crawler.arun(url=url, **kwargs)
if not result.success:
raise Exception(f"爬取失败: {result.error_message}")
return result
except Exception as e:
print(f"爬取出错,准备重试: {str(e)}")
raise
与其他框架的对比
Crawl4AI vs 传统爬虫框架
| AI理解能力 | ✅ 内置LLM支持 | ❌ 需要额外集成 | ❌ 无 |
| 学习成本 | 🟡 中等 | 🔴 较高 | 🟢 较低 |
| 性能 | 🟢 高(异步) | 🟢 高 | 🟡 中等 |
| 维护成本 | 🟢 低 | 🔴 高 | 🟡 中等 |
| 灵活性 | 🟢 高 | 🟢 高 | 🟡 中等 |
选择建议
选择Crawl4AI的场景:
- 需要理解网页内容语义
- 网站结构经常变化
- 需要提取复杂的非结构化数据
选择传统框架的场景:
- 网站结构稳定
- 对性能要求极高
- 不需要AI理解能力
常见问题与解决方案
Q1: 如何处理需要登录的网站?
async def login_crawl():
async with AsyncWebCrawler(
browser_type="chromium",
headless=False # 可视化调试
) as crawler:
# 首先访问登录页面
await crawler.arun(url="https://example.com/login")
# 执行登录操作
await crawler.arun(
url="https://example.com/login",
js_code="""
document.querySelector('#username').value = 'your_username';
document.querySelector('#password').value = 'your_password';
document.querySelector('#login-btn').click();
""",
wait_for="networkidle"
)
# 访问需要登录的页面
result = await crawler.arun(url="https://example.com/protected")
return result
Q2: 如何处理反爬虫机制?
import random
async def anti_detection_crawl():
# 随机User-Agent
user_agents = [
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36"
]
headers = {
"User-Agent": random.choice(user_agents),
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
"Accept-Language": "en-US,en;q=0.5",
"Accept-Encoding": "gzip, deflate",
"DNT": "1",
"Connection": "keep-alive",
"Upgrade-Insecure-Requests": "1"
}
async with AsyncWebCrawler(
headers=headers,
delay_before_return_html=random.uniform(2, 5) # 随机延迟
) as crawler:
result = await crawler.arun(url="https://example.com")
return result
Q3: 如何优化大规模爬取的内存使用?
async def memory_efficient_crawl(urls):
"""内存高效的大规模爬取"""
results = []
# 分批处理,避免内存溢出
batch_size = 10
for i in range(0, len(urls), batch_size):
batch_urls = urls[i:i + batch_size]
async with AsyncWebCrawler() as crawler:
batch_tasks = [
crawler.arun(url=url)
for url in batch_urls
]
batch_results = await asyncio.gather(*batch_tasks)
# 处理结果并清理内存
for result in batch_results:
if result.success:
# 只保存需要的数据
results.append({
'url': result.url,
'title': extract_title(result.html),
'content_length': len(result.markdown)
})
# 强制垃圾回收
import gc
gc.collect()
return results
未来发展趋势
1. 多模态内容提取
未来的Crawl4AI将支持更多类型的内容提取:
- 图片内容理解(OCR + 图像识别)
- 视频内容分析
- 音频内容转文本
2. 更智能的反爬虫绕过
- 基于ML的行为模拟
- 动态指纹伪造
- 智能代理轮换
3. 实时流式处理
- 支持WebSocket实时数据
- 增量更新机制
- 流式LLM处理
总结与展望
Crawl4AI代表了网页数据提取技术的一个重要里程碑。它不仅解决了传统爬虫的痛点,还为我们提供了一种全新的思路:让机器像人类一样理解网页内容。
核心优势回顾
应用前景
- 内容聚合平台:智能新闻、博客内容采集
- 价格监控系统:电商商品价格追踪
- 市场情报收集:竞品分析、市场趋势监控
- 学术研究:大规模网络数据收集与分析
学习建议
在这个AI时代,掌握Crawl4AI这样的智能工具,将让我们在数据采集领域拥有更强的竞争力。让我们一起拥抱这个智能爬虫的新时代!









评论前必须登录!
注册