 网硕互联帮助中心
网硕互联帮助中心多播路由是网络通信的核心技术之一,Linux内核通过精密的多层设计实现了高性能的IPv4多播路由功能。本文将深入剖析其核心实现机制,揭示其高效运转的秘密。
一、核心数据结构:路由系统的基石
1. 多播路由表(struct mr_table)
struct mr_table {
struct list_head list;
struct rhltable mfc_hash; // MFC哈希表
struct list_head mfc_cache_list;
struct list_head mfc_unres_queue; // 未解析队列
struct vif_device vif_table[MAXVIFS]; // 虚拟接口表
int maxvif; // 当前最大VIF索引
atomic_t cache_resolve_queue_len; // 未解析队列长度
struct timer_list ipmr_expire_timer; // 超时定时器
};
路由表通过双结构存储策略实现高效检索:哈希表用于快速查找,链表用于顺序遍历。未解析队列则临时存放等待路由决策的数据包。
2. 虚拟接口(struct vif_device)
struct vif_device {
struct net_device *dev; // 关联的网络设备
unsigned long bytes_in, bytes_out; // 流量统计
unsigned long pkt_in, pkt_out;
__be32 local, remote; // 隧道端点地址
int flags; // 类型标记
};
支持三种接口类型:
-
物理接口:直接绑定网络设备
-
隧道接口(VIFF_TUNNEL):用于跨网络转发
-
注册接口(VIFF_REGISTER):与用户态守护进程通信
3. 多播转发缓存(struct mfc_cache)
struct mfc_cache {
struct mfc_common _c;
__be32 mfc_origin; // 源地址
__be32 mfc_mcastgrp; // 组地址
struct mfc_cache_cmp_arg cmparg; // 哈希比较参数
};
关键字段res.ttls[MAXVIFS]存储每个出口的TTL阈值,实现精细化的出口控制。
二、数据包转发流程:速度与精确的平衡
转发路径(ip_mr_forward)
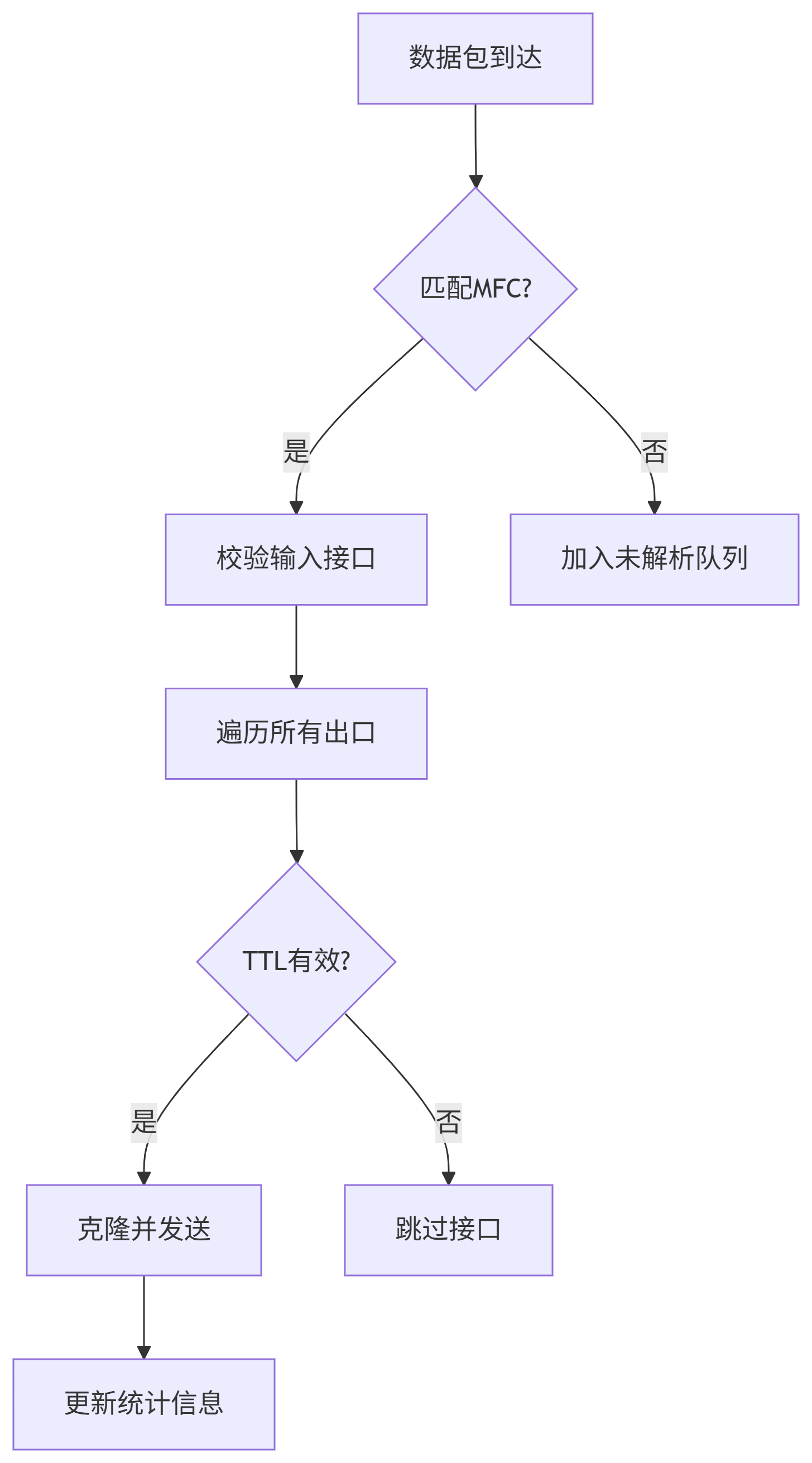
graph TD
A[数据包到达] –> B{匹配MFC?}
B –>|是| C[校验输入接口]
B –>|否| D[加入未解析队列]
C –> E[遍历所有出口]
E –> F{TTL有效?}
F –>|是| G[克隆并发送]
F –>|否| H[跳过接口]
G –> I[更新统计信息]
关键优化点:
快速克隆机制:对每个有效出口只克隆包头,避免数据复制
if (psend != -1) {
struct sk_buff *skb2 = skb_clone(skb, GFP_ATOMIC);
ipmr_queue_xmit(…, skb2, …);
}
智能TTL管理:跳过TTL不足的接口,减少无效操作
统计原子更新:无锁更新计数器确保高性能
三、控制平面:动态路由管理
1. MFC生命周期管理
-
动态学习:通过PIM/IGMP消息自动创建条目
-
静态配置:Netlink命令手动添加
ip mroute add 192.168.1.100 224.0.0.1 dev eth0
-
超时清理:10秒未解析自动丢弃(可配置)
#define MFC_UNRES_TIMEOUT (10*HZ)
2. 用户态协同机制
内核通过原始套接字与mrouted/pimd交互:
static void igmpmsg_netlink_event(struct mr_table *mrt, struct sk_buff *pkt)
{
// 构造IGMPMSG_NOCACHE消息
// 通过NETLINK发送到用户态
}
实现实时路由更新和未解析包通知。
四、协议支持:灵活的处理框架
1. PIM协议处理
// PIMv2处理函数
static int pim_rcv(struct sk_buff *skb)
{
if (pim->type != ((PIM_VERSION<<4)|PIM_TYPE_REGISTER))
goto drop;
// 验证校验和
// 转发到注册接口
}
支持PIM-SM/PIM-DM关键特性,包括注册停止机制。
2. IGMP代理
static int ipmr_cache_report(struct mr_table *mrt,
struct sk_buff *pkt, vifi_t vifi, int assert)
{
// 构造IGMPMSG_WHOLEPKT消息
// 发送到用户态套接字
}
实现组播组成员关系的跨网络传播。
五、创新设计:性能与扩展性
多表支持(CONFIG_IP_MROUTE_MULTIPLE_TABLES)
struct mr_table *ipmr_new_table(struct net *net, u32 id)
{
// 创建独立路由表
}
支持VRF场景,实现网络隔离。
RCU+哈希表检索
struct mfc_cache *ipmr_cache_find(struct mr_table *mrt,
__be32 origin, __be32 mcastgrp)
{
// RCU保护的哈希查找
}
实现百万级路由条目下的微秒级检索。
动态定时器管理
仅当存在未解析条目时激活定时器,减少空转开销。
六、实战洞察:定位多播问题的关键点
查看路由表
cat /proc/net/ip_mr_cache
# 输出示例:
# Group Origin Iif Pkts Bytes Wrong Oifs
# E0000001 C0A80101 2 104 8576 0 1:3
关注"Wrong Oifs"计数,高数值表明接口配置错误。
监控虚拟接口
cat /proc/net/ip_mr_vif
# 输出示例:
# Interface BytesIn PktsIn BytesOut PktsOut Flags
# vif0 15MB 1200 12MB 900 VIFF_TUNNEL
异常字节数指示路由环路或配置错误。
动态调试
启用内核调试选项:
echo 1 > /proc/sys/net/ipv4/route/mcast_debug
结语
Linux的IPv4多播路由通过分层架构和动态管理机制,在复杂网络环境中实现了高效稳定的数据分发。其核心设计思想包括:
控制与转发分离:用户态协议处理+内核态快速转发
时间空间平衡:哈希表+链表的混合存储结构
惰性计算:按需激活处理流程
这些设计使得Linux成为从数据中心到电信网络的多播解决方案基石,为5G网络、IPTV等场景提供了关键基础设施支持。

/*
*IP multicast routing support for mrouted 3.6/3.8
*
*(c) 1995 Alan Cox, <alan@lxorguk.ukuu.org.uk>
* Linux Consultancy and Custom Driver Development
*
*This program is free software; you can redistribute it and/or
*modify it under the terms of the GNU General Public License
*as published by the Free Software Foundation; either version
*2 of the License, or (at your option) any later version.
*
*Fixes:
*Michael Chastain:Incorrect size of copying.
*Alan Cox:Added the cache manager code
*Alan Cox:Fixed the clone/copy bug and device race.
*Mike McLagan:Routing by source
*Malcolm Beattie:Buffer handling fixes.
*Alexey Kuznetsov:Double buffer free and other fixes.
*SVR Anand:Fixed several multicast bugs and problems.
*Alexey Kuznetsov:Status, optimisations and more.
*Brad Parker:Better behaviour on mrouted upcall
*overflow.
* Carlos Picoto : PIMv1 Support
*Pavlin Ivanov Radoslavov:PIMv2 Registers must checksum only PIM header
*Relax this requirement to work with older peers.
*
*/
#include <linux/uaccess.h>
#include <linux/types.h>
#include <linux/cache.h>
#include <linux/capability.h>
#include <linux/errno.h>
#include <linux/mm.h>
#include <linux/kernel.h>
#include <linux/fcntl.h>
#include <linux/stat.h>
#include <linux/socket.h>
#include <linux/in.h>
#include <linux/inet.h>
#include <linux/netdevice.h>
#include <linux/inetdevice.h>
#include <linux/igmp.h>
#include <linux/proc_fs.h>
#include <linux/seq_file.h>
#include <linux/mroute.h>
#include <linux/init.h>
#include <linux/if_ether.h>
#include <linux/slab.h>
#include <net/net_namespace.h>
#include <net/ip.h>
#include <net/protocol.h>
#include <linux/skbuff.h>
#include <net/route.h>
#include <net/icmp.h>
#include <net/udp.h>
#include <net/raw.h>
#include <linux/notifier.h>
#include <linux/if_arp.h>
#include <linux/netfilter_ipv4.h>
#include <linux/compat.h>
#include <linux/export.h>
#include <linux/rhashtable.h>
#include <net/ip_tunnels.h>
#include <net/checksum.h>
#include <net/netlink.h>
#include <net/fib_rules.h>
#include <linux/netconf.h>
#include <net/nexthop.h>
#include <net/switchdev.h>
#include <linux/nospec.h>
struct ipmr_rule {
struct fib_rulecommon;
};
struct ipmr_result {
struct mr_table*mrt;
};
/* Big lock, protecting vif table, mrt cache and mroute socket state.
* Note that the changes are semaphored via rtnl_lock.
*/
static DEFINE_RWLOCK(mrt_lock);
/* Multicast router control variables */
/* Special spinlock for queue of unresolved entries */
static DEFINE_SPINLOCK(mfc_unres_lock);
/* We return to original Alan's scheme. Hash table of resolved
* entries is changed only in process context and protected
* with weak lock mrt_lock. Queue of unresolved entries is protected
* with strong spinlock mfc_unres_lock.
*
* In this case data path is free of exclusive locks at all.
*/
static struct kmem_cache *mrt_cachep __ro_after_init;
static struct mr_table *ipmr_new_table(struct net *net, u32 id);
static void ipmr_free_table(struct mr_table *mrt);
static void ip_mr_forward(struct net *net, struct mr_table *mrt,
struct net_device *dev, struct sk_buff *skb,
struct mfc_cache *cache, int local);
static int ipmr_cache_report(struct mr_table *mrt,
struct sk_buff *pkt, vifi_t vifi, int assert);
static void mroute_netlink_event(struct mr_table *mrt, struct mfc_cache *mfc,
int cmd);
static void igmpmsg_netlink_event(struct mr_table *mrt, struct sk_buff *pkt);
static void mroute_clean_tables(struct mr_table *mrt, bool all);
static void ipmr_expire_process(struct timer_list *t);
#ifdef CONFIG_IP_MROUTE_MULTIPLE_TABLES
#define ipmr_for_each_table(mrt, net) \\
list_for_each_entry_rcu(mrt, &net->ipv4.mr_tables, list)
static struct mr_table *ipmr_mr_table_iter(struct net *net,
struct mr_table *mrt)
{
struct mr_table *ret;
if (!mrt)
ret = list_entry_rcu(net->ipv4.mr_tables.next,
struct mr_table, list);
else
ret = list_entry_rcu(mrt->list.next,
struct mr_table, list);
if (&ret->list == &net->ipv4.mr_tables)
return NULL;
return ret;
}
static struct mr_table *ipmr_get_table(struct net *net, u32 id)
{
struct mr_table *mrt;
ipmr_for_each_table(mrt, net) {
if (mrt->id == id)
return mrt;
}
return NULL;
}
static int ipmr_fib_lookup(struct net *net, struct flowi4 *flp4,
struct mr_table **mrt)
{
int err;
struct ipmr_result res;
struct fib_lookup_arg arg = {
.result = &res,
.flags = FIB_LOOKUP_NOREF,
};
/* update flow if oif or iif point to device enslaved to l3mdev */
l3mdev_update_flow(net, flowi4_to_flowi(flp4));
err = fib_rules_lookup(net->ipv4.mr_rules_ops,
flowi4_to_flowi(flp4), 0, &arg);
if (err < 0)
return err;
*mrt = res.mrt;
return 0;
}
static int ipmr_rule_action(struct fib_rule *rule, struct flowi *flp,
int flags, struct fib_lookup_arg *arg)
{
struct ipmr_result *res = arg->result;
struct mr_table *mrt;
switch (rule->action) {
case FR_ACT_TO_TBL:
break;
case FR_ACT_UNREACHABLE:
return -ENETUNREACH;
case FR_ACT_PROHIBIT:
return -EACCES;
case FR_ACT_BLACKHOLE:
default:
return -EINVAL;
}
arg->table = fib_rule_get_table(rule, arg);
mrt = ipmr_get_table(rule->fr_net, arg->table);
if (!mrt)
return -EAGAIN;
res->mrt = mrt;
return 0;
}
static int ipmr_rule_match(struct fib_rule *rule, struct flowi *fl, int flags)
{
return 1;
}
static const struct nla_policy ipmr_rule_policy[FRA_MAX + 1] = {
FRA_GENERIC_POLICY,
};
static int ipmr_rule_configure(struct fib_rule *rule, struct sk_buff *skb,
struct fib_rule_hdr *frh, struct nlattr **tb,
struct netlink_ext_ack *extack)
{
return 0;
}
static int ipmr_rule_compare(struct fib_rule *rule, struct fib_rule_hdr *frh,
struct nlattr **tb)
{
return 1;
}
static int ipmr_rule_fill(struct fib_rule *rule, struct sk_buff *skb,
struct fib_rule_hdr *frh)
{
frh->dst_len = 0;
frh->src_len = 0;
frh->tos = 0;
return 0;
}
static const struct fib_rules_ops __net_initconst ipmr_rules_ops_template = {
.family= RTNL_FAMILY_IPMR,
.rule_size= sizeof(struct ipmr_rule),
.addr_size= sizeof(u32),
.action= ipmr_rule_action,
.match= ipmr_rule_match,
.configure= ipmr_rule_configure,
.compare= ipmr_rule_compare,
.fill= ipmr_rule_fill,
.nlgroup= RTNLGRP_IPV4_RULE,
.policy= ipmr_rule_policy,
.owner= THIS_MODULE,
};
static int __net_init ipmr_rules_init(struct net *net)
{
struct fib_rules_ops *ops;
struct mr_table *mrt;
int err;
ops = fib_rules_register(&ipmr_rules_ops_template, net);
if (IS_ERR(ops))
return PTR_ERR(ops);
INIT_LIST_HEAD(&net->ipv4.mr_tables);
mrt = ipmr_new_table(net, RT_TABLE_DEFAULT);
if (IS_ERR(mrt)) {
err = PTR_ERR(mrt);
goto err1;
}
err = fib_default_rule_add(ops, 0x7fff, RT_TABLE_DEFAULT, 0);
if (err < 0)
goto err2;
net->ipv4.mr_rules_ops = ops;
return 0;
err2:
ipmr_free_table(mrt);
err1:
fib_rules_unregister(ops);
return err;
}
static void __net_exit ipmr_rules_exit(struct net *net)
{
struct mr_table *mrt, *next;
rtnl_lock();
list_for_each_entry_safe(mrt, next, &net->ipv4.mr_tables, list) {
list_del(&mrt->list);
ipmr_free_table(mrt);
}
fib_rules_unregister(net->ipv4.mr_rules_ops);
rtnl_unlock();
}
static int ipmr_rules_dump(struct net *net, struct notifier_block *nb)
{
return fib_rules_dump(net, nb, RTNL_FAMILY_IPMR);
}
static unsigned int ipmr_rules_seq_read(struct net *net)
{
return fib_rules_seq_read(net, RTNL_FAMILY_IPMR);
}
bool ipmr_rule_default(const struct fib_rule *rule)
{
return fib_rule_matchall(rule) && rule->table == RT_TABLE_DEFAULT;
}
EXPORT_SYMBOL(ipmr_rule_default);
#else
#define ipmr_for_each_table(mrt, net) \\
for (mrt = net->ipv4.mrt; mrt; mrt = NULL)
static struct mr_table *ipmr_mr_table_iter(struct net *net,
struct mr_table *mrt)
{
if (!mrt)
return net->ipv4.mrt;
return NULL;
}
static struct mr_table *ipmr_get_table(struct net *net, u32 id)
{
return net->ipv4.mrt;
}
static int ipmr_fib_lookup(struct net *net, struct flowi4 *flp4,
struct mr_table **mrt)
{
*mrt = net->ipv4.mrt;
return 0;
}
static int __net_init ipmr_rules_init(struct net *net)
{
struct mr_table *mrt;
mrt = ipmr_new_table(net, RT_TABLE_DEFAULT);
if (IS_ERR(mrt))
return PTR_ERR(mrt);
net->ipv4.mrt = mrt;
return 0;
}
static void __net_exit ipmr_rules_exit(struct net *net)
{
rtnl_lock();
ipmr_free_table(net->ipv4.mrt);
net->ipv4.mrt = NULL;
rtnl_unlock();
}
static int ipmr_rules_dump(struct net *net, struct notifier_block *nb)
{
return 0;
}
static unsigned int ipmr_rules_seq_read(struct net *net)
{
return 0;
}
bool ipmr_rule_default(const struct fib_rule *rule)
{
return true;
}
EXPORT_SYMBOL(ipmr_rule_default);
#endif
static inline int ipmr_hash_cmp(struct rhashtable_compare_arg *arg,
const void *ptr)
{
const struct mfc_cache_cmp_arg *cmparg = arg->key;
struct mfc_cache *c = (struct mfc_cache *)ptr;
return cmparg->mfc_mcastgrp != c->mfc_mcastgrp ||
cmparg->mfc_origin != c->mfc_origin;
}
static const struct rhashtable_params ipmr_rht_params = {
.head_offset = offsetof(struct mr_mfc, mnode),
.key_offset = offsetof(struct mfc_cache, cmparg),
.key_len = sizeof(struct mfc_cache_cmp_arg),
.nelem_hint = 3,
.locks_mul = 1,
.obj_cmpfn = ipmr_hash_cmp,
.automatic_shrinking = true,
};
static void ipmr_new_table_set(struct mr_table *mrt,
struct net *net)
{
#ifdef CONFIG_IP_MROUTE_MULTIPLE_TABLES
list_add_tail_rcu(&mrt->list, &net->ipv4.mr_tables);
#endif
}
static struct mfc_cache_cmp_arg ipmr_mr_table_ops_cmparg_any = {
.mfc_mcastgrp = htonl(INADDR_ANY),
.mfc_origin = htonl(INADDR_ANY),
};
static struct mr_table_ops ipmr_mr_table_ops = {
.rht_params = &ipmr_rht_params,
.cmparg_any = &ipmr_mr_table_ops_cmparg_any,
};
static struct mr_table *ipmr_new_table(struct net *net, u32 id)
{
struct mr_table *mrt;
/* "pimreg%u" should not exceed 16 bytes (IFNAMSIZ) */
if (id != RT_TABLE_DEFAULT && id >= 1000000000)
return ERR_PTR(-EINVAL);
mrt = ipmr_get_table(net, id);
if (mrt)
return mrt;
return mr_table_alloc(net, id, &ipmr_mr_table_ops,
ipmr_expire_process, ipmr_new_table_set);
}
static void ipmr_free_table(struct mr_table *mrt)
{
del_timer_sync(&mrt->ipmr_expire_timer);
mroute_clean_tables(mrt, true);
rhltable_destroy(&mrt->mfc_hash);
kfree(mrt);
}
/* Service routines creating virtual interfaces: DVMRP tunnels and PIMREG */
static void ipmr_del_tunnel(struct net_device *dev, struct vifctl *v)
{
struct net *net = dev_net(dev);
dev_close(dev);
dev = __dev_get_by_name(net, "tunl0");
if (dev) {
const struct net_device_ops *ops = dev->netdev_ops;
struct ifreq ifr;
struct ip_tunnel_parm p;
memset(&p, 0, sizeof(p));
p.iph.daddr = v->vifc_rmt_addr.s_addr;
p.iph.saddr = v->vifc_lcl_addr.s_addr;
p.iph.version = 4;
p.iph.ihl = 5;
p.iph.protocol = IPPROTO_IPIP;
sprintf(p.name, "dvmrp%d", v->vifc_vifi);
ifr.ifr_ifru.ifru_data = (__force void __user *)&p;
if (ops->ndo_do_ioctl) {
mm_segment_t oldfs = get_fs();
set_fs(KERNEL_DS);
ops->ndo_do_ioctl(dev, &ifr, SIOCDELTUNNEL);
set_fs(oldfs);
}
}
}
/* Initialize ipmr pimreg/tunnel in_device */
static bool ipmr_init_vif_indev(const struct net_device *dev)
{
struct in_device *in_dev;
ASSERT_RTNL();
in_dev = __in_dev_get_rtnl(dev);
if (!in_dev)
return false;
ipv4_devconf_setall(in_dev);
neigh_parms_data_state_setall(in_dev->arp_parms);
IPV4_DEVCONF(in_dev->cnf, RP_FILTER) = 0;
return true;
}
static struct net_device *ipmr_new_tunnel(struct net *net, struct vifctl *v)
{
struct net_device *dev;
dev = __dev_get_by_name(net, "tunl0");
if (dev) {
const struct net_device_ops *ops = dev->netdev_ops;
int err;
struct ifreq ifr;
struct ip_tunnel_parm p;
memset(&p, 0, sizeof(p));
p.iph.daddr = v->vifc_rmt_addr.s_addr;
p.iph.saddr = v->vifc_lcl_addr.s_addr;
p.iph.version = 4;
p.iph.ihl = 5;
p.iph.protocol = IPPROTO_IPIP;
sprintf(p.name, "dvmrp%d", v->vifc_vifi);
ifr.ifr_ifru.ifru_data = (__force void __user *)&p;
if (ops->ndo_do_ioctl) {
mm_segment_t oldfs = get_fs();
set_fs(KERNEL_DS);
err = ops->ndo_do_ioctl(dev, &ifr, SIOCADDTUNNEL);
set_fs(oldfs);
} else {
err = -EOPNOTSUPP;
}
dev = NULL;
if (err == 0 &&
(dev = __dev_get_by_name(net, p.name)) != NULL) {
dev->flags |= IFF_MULTICAST;
if (!ipmr_init_vif_indev(dev))
goto failure;
if (dev_open(dev))
goto failure;
dev_hold(dev);
}
}
return dev;
failure:
unregister_netdevice(dev);
return NULL;
}
#if defined(CONFIG_IP_PIMSM_V1) || defined(CONFIG_IP_PIMSM_V2)
static netdev_tx_t reg_vif_xmit(struct sk_buff *skb, struct net_device *dev)
{
struct net *net = dev_net(dev);
struct mr_table *mrt;
struct flowi4 fl4 = {
.flowi4_oif= dev->ifindex,
.flowi4_iif= skb->skb_iif ? : LOOPBACK_IFINDEX,
.flowi4_mark= skb->mark,
};
int err;
err = ipmr_fib_lookup(net, &fl4, &mrt);
if (err < 0) {
kfree_skb(skb);
return err;
}
read_lock(&mrt_lock);
dev->stats.tx_bytes += skb->len;
dev->stats.tx_packets++;
ipmr_cache_report(mrt, skb, mrt->mroute_reg_vif_num, IGMPMSG_WHOLEPKT);
read_unlock(&mrt_lock);
kfree_skb(skb);
return NETDEV_TX_OK;
}
static int reg_vif_get_iflink(const struct net_device *dev)
{
return 0;
}
static const struct net_device_ops reg_vif_netdev_ops = {
.ndo_start_xmit= reg_vif_xmit,
.ndo_get_iflink = reg_vif_get_iflink,
};
static void reg_vif_setup(struct net_device *dev)
{
dev->type= ARPHRD_PIMREG;
dev->mtu= ETH_DATA_LEN – sizeof(struct iphdr) – 8;
dev->flags= IFF_NOARP;
dev->netdev_ops= ®_vif_netdev_ops;
dev->needs_free_netdev= true;
dev->features|= NETIF_F_NETNS_LOCAL;
}
static struct net_device *ipmr_reg_vif(struct net *net, struct mr_table *mrt)
{
struct net_device *dev;
char name[IFNAMSIZ];
if (mrt->id == RT_TABLE_DEFAULT)
sprintf(name, "pimreg");
else
sprintf(name, "pimreg%u", mrt->id);
dev = alloc_netdev(0, name, NET_NAME_UNKNOWN, reg_vif_setup);
if (!dev)
return NULL;
dev_net_set(dev, net);
if (register_netdevice(dev)) {
free_netdev(dev);
return NULL;
}
if (!ipmr_init_vif_indev(dev))
goto failure;
if (dev_open(dev))
goto failure;
dev_hold(dev);
return dev;
failure:
unregister_netdevice(dev);
return NULL;
}
/* called with rcu_read_lock() */
static int __pim_rcv(struct mr_table *mrt, struct sk_buff *skb,
unsigned int pimlen)
{
struct net_device *reg_dev = NULL;
struct iphdr *encap;
encap = (struct iphdr *)(skb_transport_header(skb) + pimlen);
/* Check that:
* a. packet is really sent to a multicast group
* b. packet is not a NULL-REGISTER
* c. packet is not truncated
*/
if (!ipv4_is_multicast(encap->daddr) ||
encap->tot_len == 0 ||
ntohs(encap->tot_len) + pimlen > skb->len)
return 1;
read_lock(&mrt_lock);
if (mrt->mroute_reg_vif_num >= 0)
reg_dev = mrt->vif_table[mrt->mroute_reg_vif_num].dev;
read_unlock(&mrt_lock);
if (!reg_dev)
return 1;
skb->mac_header = skb->network_header;
skb_pull(skb, (u8 *)encap – skb->data);
skb_reset_network_header(skb);
skb->protocol = htons(ETH_P_IP);
skb->ip_summed = CHECKSUM_NONE;
skb_tunnel_rx(skb, reg_dev, dev_net(reg_dev));
netif_rx(skb);
return NET_RX_SUCCESS;
}
#else
static struct net_device *ipmr_reg_vif(struct net *net, struct mr_table *mrt)
{
return NULL;
}
#endif
static int call_ipmr_vif_entry_notifiers(struct net *net,
enum fib_event_type event_type,
struct vif_device *vif,
vifi_t vif_index, u32 tb_id)
{
return mr_call_vif_notifiers(net, RTNL_FAMILY_IPMR, event_type,
vif, vif_index, tb_id,
&net->ipv4.ipmr_seq);
}
static int call_ipmr_mfc_entry_notifiers(struct net *net,
enum fib_event_type event_type,
struct mfc_cache *mfc, u32 tb_id)
{
return mr_call_mfc_notifiers(net, RTNL_FAMILY_IPMR, event_type,
&mfc->_c, tb_id, &net->ipv4.ipmr_seq);
}
/**
*vif_delete – Delete a VIF entry
*@notify: Set to 1, if the caller is a notifier_call
*/
static int vif_delete(struct mr_table *mrt, int vifi, int notify,
struct list_head *head)
{
struct net *net = read_pnet(&mrt->net);
struct vif_device *v;
struct net_device *dev;
struct in_device *in_dev;
if (vifi < 0 || vifi >= mrt->maxvif)
return -EADDRNOTAVAIL;
v = &mrt->vif_table[vifi];
if (VIF_EXISTS(mrt, vifi))
call_ipmr_vif_entry_notifiers(net, FIB_EVENT_VIF_DEL, v, vifi,
mrt->id);
write_lock_bh(&mrt_lock);
dev = v->dev;
v->dev = NULL;
if (!dev) {
write_unlock_bh(&mrt_lock);
return -EADDRNOTAVAIL;
}
if (vifi == mrt->mroute_reg_vif_num)
mrt->mroute_reg_vif_num = -1;
if (vifi + 1 == mrt->maxvif) {
int tmp;
for (tmp = vifi – 1; tmp >= 0; tmp–) {
if (VIF_EXISTS(mrt, tmp))
break;
}
mrt->maxvif = tmp+1;
}
write_unlock_bh(&mrt_lock);
dev_set_allmulti(dev, -1);
in_dev = __in_dev_get_rtnl(dev);
if (in_dev) {
IPV4_DEVCONF(in_dev->cnf, MC_FORWARDING)–;
inet_netconf_notify_devconf(dev_net(dev), RTM_NEWNETCONF,
NETCONFA_MC_FORWARDING,
dev->ifindex, &in_dev->cnf);
ip_rt_multicast_event(in_dev);
}
if (v->flags & (VIFF_TUNNEL | VIFF_REGISTER) && !notify)
unregister_netdevice_queue(dev, head);
dev_put(dev);
return 0;
}
static void ipmr_cache_free_rcu(struct rcu_head *head)
{
struct mr_mfc *c = container_of(head, struct mr_mfc, rcu);
kmem_cache_free(mrt_cachep, (struct mfc_cache *)c);
}
static void ipmr_cache_free(struct mfc_cache *c)
{
call_rcu(&c->_c.rcu, ipmr_cache_free_rcu);
}
/* Destroy an unresolved cache entry, killing queued skbs
* and reporting error to netlink readers.
*/
static void ipmr_destroy_unres(struct mr_table *mrt, struct mfc_cache *c)
{
struct net *net = read_pnet(&mrt->net);
struct sk_buff *skb;
struct nlmsgerr *e;
atomic_dec(&mrt->cache_resolve_queue_len);
while ((skb = skb_dequeue(&c->_c.mfc_un.unres.unresolved))) {
if (ip_hdr(skb)->version == 0) {
struct nlmsghdr *nlh = skb_pull(skb,
sizeof(struct iphdr));
nlh->nlmsg_type = NLMSG_ERROR;
nlh->nlmsg_len = nlmsg_msg_size(sizeof(struct nlmsgerr));
skb_trim(skb, nlh->nlmsg_len);
e = nlmsg_data(nlh);
e->error = -ETIMEDOUT;
memset(&e->msg, 0, sizeof(e->msg));
rtnl_unicast(skb, net, NETLINK_CB(skb).portid);
} else {
kfree_skb(skb);
}
}
ipmr_cache_free(c);
}
/* Timer process for the unresolved queue. */
static void ipmr_expire_process(struct timer_list *t)
{
struct mr_table *mrt = from_timer(mrt, t, ipmr_expire_timer);
struct mr_mfc *c, *next;
unsigned long expires;
unsigned long now;
if (!spin_trylock(&mfc_unres_lock)) {
mod_timer(&mrt->ipmr_expire_timer, jiffies+HZ/10);
return;
}
if (list_empty(&mrt->mfc_unres_queue))
goto out;
now = jiffies;
expires = 10*HZ;
list_for_each_entry_safe(c, next, &mrt->mfc_unres_queue, list) {
if (time_after(c->mfc_un.unres.expires, now)) {
unsigned long interval = c->mfc_un.unres.expires – now;
if (interval < expires)
expires = interval;
continue;
}
list_del(&c->list);
mroute_netlink_event(mrt, (struct mfc_cache *)c, RTM_DELROUTE);
ipmr_destroy_unres(mrt, (struct mfc_cache *)c);
}
if (!list_empty(&mrt->mfc_unres_queue))
mod_timer(&mrt->ipmr_expire_timer, jiffies + expires);
out:
spin_unlock(&mfc_unres_lock);
}
/* Fill oifs list. It is called under write locked mrt_lock. */
static void ipmr_update_thresholds(struct mr_table *mrt, struct mr_mfc *cache,
unsigned char *ttls)
{
int vifi;
cache->mfc_un.res.minvif = MAXVIFS;
cache->mfc_un.res.maxvif = 0;
memset(cache->mfc_un.res.ttls, 255, MAXVIFS);
for (vifi = 0; vifi < mrt->maxvif; vifi++) {
if (VIF_EXISTS(mrt, vifi) &&
ttls[vifi] && ttls[vifi] < 255) {
cache->mfc_un.res.ttls[vifi] = ttls[vifi];
if (cache->mfc_un.res.minvif > vifi)
cache->mfc_un.res.minvif = vifi;
if (cache->mfc_un.res.maxvif <= vifi)
cache->mfc_un.res.maxvif = vifi + 1;
}
}
cache->mfc_un.res.lastuse = jiffies;
}
static int vif_add(struct net *net, struct mr_table *mrt,
struct vifctl *vifc, int mrtsock)
{
int vifi = vifc->vifc_vifi;
struct switchdev_attr attr = {
.id = SWITCHDEV_ATTR_ID_PORT_PARENT_ID,
};
struct vif_device *v = &mrt->vif_table[vifi];
struct net_device *dev;
struct in_device *in_dev;
int err;
/* Is vif busy ? */
if (VIF_EXISTS(mrt, vifi))
return -EADDRINUSE;
switch (vifc->vifc_flags) {
case VIFF_REGISTER:
if (!ipmr_pimsm_enabled())
return -EINVAL;
/* Special Purpose VIF in PIM
* All the packets will be sent to the daemon
*/
if (mrt->mroute_reg_vif_num >= 0)
return -EADDRINUSE;
dev = ipmr_reg_vif(net, mrt);
if (!dev)
return -ENOBUFS;
err = dev_set_allmulti(dev, 1);
if (err) {
unregister_netdevice(dev);
dev_put(dev);
return err;
}
break;
case VIFF_TUNNEL:
dev = ipmr_new_tunnel(net, vifc);
if (!dev)
return -ENOBUFS;
err = dev_set_allmulti(dev, 1);
if (err) {
ipmr_del_tunnel(dev, vifc);
dev_put(dev);
return err;
}
break;
case VIFF_USE_IFINDEX:
case 0:
if (vifc->vifc_flags == VIFF_USE_IFINDEX) {
dev = dev_get_by_index(net, vifc->vifc_lcl_ifindex);
if (dev && !__in_dev_get_rtnl(dev)) {
dev_put(dev);
return -EADDRNOTAVAIL;
}
} else {
dev = ip_dev_find(net, vifc->vifc_lcl_addr.s_addr);
}
if (!dev)
return -EADDRNOTAVAIL;
err = dev_set_allmulti(dev, 1);
if (err) {
dev_put(dev);
return err;
}
break;
default:
return -EINVAL;
}
in_dev = __in_dev_get_rtnl(dev);
if (!in_dev) {
dev_put(dev);
return -EADDRNOTAVAIL;
}
IPV4_DEVCONF(in_dev->cnf, MC_FORWARDING)++;
inet_netconf_notify_devconf(net, RTM_NEWNETCONF, NETCONFA_MC_FORWARDING,
dev->ifindex, &in_dev->cnf);
ip_rt_multicast_event(in_dev);
/* Fill in the VIF structures */
vif_device_init(v, dev, vifc->vifc_rate_limit,
vifc->vifc_threshold,
vifc->vifc_flags | (!mrtsock ? VIFF_STATIC : 0),
(VIFF_TUNNEL | VIFF_REGISTER));
attr.orig_dev = dev;
if (!switchdev_port_attr_get(dev, &attr)) {
memcpy(v->dev_parent_id.id, attr.u.ppid.id, attr.u.ppid.id_len);
v->dev_parent_id.id_len = attr.u.ppid.id_len;
} else {
v->dev_parent_id.id_len = 0;
}
v->local = vifc->vifc_lcl_addr.s_addr;
v->remote = vifc->vifc_rmt_addr.s_addr;
/* And finish update writing critical data */
write_lock_bh(&mrt_lock);
v->dev = dev;
if (v->flags & VIFF_REGISTER)
mrt->mroute_reg_vif_num = vifi;
if (vifi+1 > mrt->maxvif)
mrt->maxvif = vifi+1;
write_unlock_bh(&mrt_lock);
call_ipmr_vif_entry_notifiers(net, FIB_EVENT_VIF_ADD, v, vifi, mrt->id);
return 0;
}
/* called with rcu_read_lock() */
static struct mfc_cache *ipmr_cache_find(struct mr_table *mrt,
__be32 origin,
__be32 mcastgrp)
{
struct mfc_cache_cmp_arg arg = {
.mfc_mcastgrp = mcastgrp,
.mfc_origin = origin
};
return mr_mfc_find(mrt, &arg);
}
/* Look for a (*,G) entry */
static struct mfc_cache *ipmr_cache_find_any(struct mr_table *mrt,
__be32 mcastgrp, int vifi)
{
struct mfc_cache_cmp_arg arg = {
.mfc_mcastgrp = mcastgrp,
.mfc_origin = htonl(INADDR_ANY)
};
if (mcastgrp == htonl(INADDR_ANY))
return mr_mfc_find_any_parent(mrt, vifi);
return mr_mfc_find_any(mrt, vifi, &arg);
}
/* Look for a (S,G,iif) entry if parent != -1 */
static struct mfc_cache *ipmr_cache_find_parent(struct mr_table *mrt,
__be32 origin, __be32 mcastgrp,
int parent)
{
struct mfc_cache_cmp_arg arg = {
.mfc_mcastgrp = mcastgrp,
.mfc_origin = origin,
};
return mr_mfc_find_parent(mrt, &arg, parent);
}
/* Allocate a multicast cache entry */
static struct mfc_cache *ipmr_cache_alloc(void)
{
struct mfc_cache *c = kmem_cache_zalloc(mrt_cachep, GFP_KERNEL);
if (c) {
c->_c.mfc_un.res.last_assert = jiffies – MFC_ASSERT_THRESH – 1;
c->_c.mfc_un.res.minvif = MAXVIFS;
c->_c.free = ipmr_cache_free_rcu;
refcount_set(&c->_c.mfc_un.res.refcount, 1);
}
return c;
}
static struct mfc_cache *ipmr_cache_alloc_unres(void)
{
struct mfc_cache *c = kmem_cache_zalloc(mrt_cachep, GFP_ATOMIC);
if (c) {
skb_queue_head_init(&c->_c.mfc_un.unres.unresolved);
c->_c.mfc_un.unres.expires = jiffies + 10 * HZ;
}
return c;
}
/* A cache entry has gone into a resolved state from queued */
static void ipmr_cache_resolve(struct net *net, struct mr_table *mrt,
struct mfc_cache *uc, struct mfc_cache *c)
{
struct sk_buff *skb;
struct nlmsgerr *e;
/* Play the pending entries through our router */
while ((skb = __skb_dequeue(&uc->_c.mfc_un.unres.unresolved))) {
if (ip_hdr(skb)->version == 0) {
struct nlmsghdr *nlh = skb_pull(skb,
sizeof(struct iphdr));
if (mr_fill_mroute(mrt, skb, &c->_c,
nlmsg_data(nlh)) > 0) {
nlh->nlmsg_len = skb_tail_pointer(skb) –
(u8 *)nlh;
} else {
nlh->nlmsg_type = NLMSG_ERROR;
nlh->nlmsg_len = nlmsg_msg_size(sizeof(struct nlmsgerr));
skb_trim(skb, nlh->nlmsg_len);
e = nlmsg_data(nlh);
e->error = -EMSGSIZE;
memset(&e->msg, 0, sizeof(e->msg));
}
rtnl_unicast(skb, net, NETLINK_CB(skb).portid);
} else {
ip_mr_forward(net, mrt, skb->dev, skb, c, 0);
}
}
}
/* Bounce a cache query up to mrouted and netlink.
*
* Called under mrt_lock.
*/
static int ipmr_cache_report(struct mr_table *mrt,
struct sk_buff *pkt, vifi_t vifi, int assert)
{
const int ihl = ip_hdrlen(pkt);
struct sock *mroute_sk;
struct igmphdr *igmp;
struct igmpmsg *msg;
struct sk_buff *skb;
int ret;
if (assert == IGMPMSG_WHOLEPKT || assert == IGMPMSG_WRVIFWHOLE)
skb = skb_realloc_headroom(pkt, sizeof(struct iphdr));
else
skb = alloc_skb(128, GFP_ATOMIC);
if (!skb)
return -ENOBUFS;
if (assert == IGMPMSG_WHOLEPKT || assert == IGMPMSG_WRVIFWHOLE) {
/* Ugly, but we have no choice with this interface.
* Duplicate old header, fix ihl, length etc.
* And all this only to mangle msg->im_msgtype and
* to set msg->im_mbz to "mbz" 🙂
*/
skb_push(skb, sizeof(struct iphdr));
skb_reset_network_header(skb);
skb_reset_transport_header(skb);
msg = (struct igmpmsg *)skb_network_header(skb);
memcpy(msg, skb_network_header(pkt), sizeof(struct iphdr));
msg->im_msgtype = assert;
msg->im_mbz = 0;
if (assert == IGMPMSG_WRVIFWHOLE)
msg->im_vif = vifi;
else
msg->im_vif = mrt->mroute_reg_vif_num;
ip_hdr(skb)->ihl = sizeof(struct iphdr) >> 2;
ip_hdr(skb)->tot_len = htons(ntohs(ip_hdr(pkt)->tot_len) +
sizeof(struct iphdr));
} else {
/* Copy the IP header */
skb_set_network_header(skb, skb->len);
skb_put(skb, ihl);
skb_copy_to_linear_data(skb, pkt->data, ihl);
/* Flag to the kernel this is a route add */
ip_hdr(skb)->protocol = 0;
msg = (struct igmpmsg *)skb_network_header(skb);
msg->im_vif = vifi;
skb_dst_set(skb, dst_clone(skb_dst(pkt)));
/* Add our header */
igmp = skb_put(skb, sizeof(struct igmphdr));
igmp->type = assert;
msg->im_msgtype = assert;
igmp->code = 0;
ip_hdr(skb)->tot_len = htons(skb->len);/* Fix the length */
skb->transport_header = skb->network_header;
}
rcu_read_lock();
mroute_sk = rcu_dereference(mrt->mroute_sk);
if (!mroute_sk) {
rcu_read_unlock();
kfree_skb(skb);
return -EINVAL;
}
igmpmsg_netlink_event(mrt, skb);
/* Deliver to mrouted */
ret = sock_queue_rcv_skb(mroute_sk, skb);
rcu_read_unlock();
if (ret < 0) {
net_warn_ratelimited("mroute: pending queue full, dropping entries\\n");
kfree_skb(skb);
}
return ret;
}
/* Queue a packet for resolution. It gets locked cache entry! */
static int ipmr_cache_unresolved(struct mr_table *mrt, vifi_t vifi,
struct sk_buff *skb, struct net_device *dev)
{
const struct iphdr *iph = ip_hdr(skb);
struct mfc_cache *c;
bool found = false;
int err;
spin_lock_bh(&mfc_unres_lock);
list_for_each_entry(c, &mrt->mfc_unres_queue, _c.list) {
if (c->mfc_mcastgrp == iph->daddr &&
c->mfc_origin == iph->saddr) {
found = true;
break;
}
}
if (!found) {
/* Create a new entry if allowable */
if (atomic_read(&mrt->cache_resolve_queue_len) >= 10 ||
(c = ipmr_cache_alloc_unres()) == NULL) {
spin_unlock_bh(&mfc_unres_lock);
kfree_skb(skb);
return -ENOBUFS;
}
/* Fill in the new cache entry */
c->_c.mfc_parent = -1;
c->mfc_origin= iph->saddr;
c->mfc_mcastgrp= iph->daddr;
/* Reflect first query at mrouted. */
err = ipmr_cache_report(mrt, skb, vifi, IGMPMSG_NOCACHE);
if (err < 0) {
/* If the report failed throw the cache entry
out – Brad Parker
*/
spin_unlock_bh(&mfc_unres_lock);
ipmr_cache_free(c);
kfree_skb(skb);
return err;
}
atomic_inc(&mrt->cache_resolve_queue_len);
list_add(&c->_c.list, &mrt->mfc_unres_queue);
mroute_netlink_event(mrt, c, RTM_NEWROUTE);
if (atomic_read(&mrt->cache_resolve_queue_len) == 1)
mod_timer(&mrt->ipmr_expire_timer,
c->_c.mfc_un.unres.expires);
}
/* See if we can append the packet */
if (c->_c.mfc_un.unres.unresolved.qlen > 3) {
kfree_skb(skb);
err = -ENOBUFS;
} else {
if (dev) {
skb->dev = dev;
skb->skb_iif = dev->ifindex;
}
skb_queue_tail(&c->_c.mfc_un.unres.unresolved, skb);
err = 0;
}
spin_unlock_bh(&mfc_unres_lock);
return err;
}
/* MFC cache manipulation by user space mroute daemon */
static int ipmr_mfc_delete(struct mr_table *mrt, struct mfcctl *mfc, int parent)
{
struct net *net = read_pnet(&mrt->net);
struct mfc_cache *c;
/* The entries are added/deleted only under RTNL */
rcu_read_lock();
c = ipmr_cache_find_parent(mrt, mfc->mfcc_origin.s_addr,
mfc->mfcc_mcastgrp.s_addr, parent);
rcu_read_unlock();
if (!c)
return -ENOENT;
rhltable_remove(&mrt->mfc_hash, &c->_c.mnode, ipmr_rht_params);
list_del_rcu(&c->_c.list);
call_ipmr_mfc_entry_notifiers(net, FIB_EVENT_ENTRY_DEL, c, mrt->id);
mroute_netlink_event(mrt, c, RTM_DELROUTE);
mr_cache_put(&c->_c);
return 0;
}
static int ipmr_mfc_add(struct net *net, struct mr_table *mrt,
struct mfcctl *mfc, int mrtsock, int parent)
{
struct mfc_cache *uc, *c;
struct mr_mfc *_uc;
bool found;
int ret;
if (mfc->mfcc_parent >= MAXVIFS)
return -ENFILE;
/* The entries are added/deleted only under RTNL */
rcu_read_lock();
c = ipmr_cache_find_parent(mrt, mfc->mfcc_origin.s_addr,
mfc->mfcc_mcastgrp.s_addr, parent);
rcu_read_unlock();
if (c) {
write_lock_bh(&mrt_lock);
c->_c.mfc_parent = mfc->mfcc_parent;
ipmr_update_thresholds(mrt, &c->_c, mfc->mfcc_ttls);
if (!mrtsock)
c->_c.mfc_flags |= MFC_STATIC;
write_unlock_bh(&mrt_lock);
call_ipmr_mfc_entry_notifiers(net, FIB_EVENT_ENTRY_REPLACE, c,
mrt->id);
mroute_netlink_event(mrt, c, RTM_NEWROUTE);
return 0;
}
if (mfc->mfcc_mcastgrp.s_addr != htonl(INADDR_ANY) &&
!ipv4_is_multicast(mfc->mfcc_mcastgrp.s_addr))
return -EINVAL;
c = ipmr_cache_alloc();
if (!c)
return -ENOMEM;
c->mfc_origin = mfc->mfcc_origin.s_addr;
c->mfc_mcastgrp = mfc->mfcc_mcastgrp.s_addr;
c->_c.mfc_parent = mfc->mfcc_parent;
ipmr_update_thresholds(mrt, &c->_c, mfc->mfcc_ttls);
if (!mrtsock)
c->_c.mfc_flags |= MFC_STATIC;
ret = rhltable_insert_key(&mrt->mfc_hash, &c->cmparg, &c->_c.mnode,
ipmr_rht_params);
if (ret) {
pr_err("ipmr: rhtable insert error %d\\n", ret);
ipmr_cache_free(c);
return ret;
}
list_add_tail_rcu(&c->_c.list, &mrt->mfc_cache_list);
/* Check to see if we resolved a queued list. If so we
* need to send on the frames and tidy up.
*/
found = false;
spin_lock_bh(&mfc_unres_lock);
list_for_each_entry(_uc, &mrt->mfc_unres_queue, list) {
uc = (struct mfc_cache *)_uc;
if (uc->mfc_origin == c->mfc_origin &&
uc->mfc_mcastgrp == c->mfc_mcastgrp) {
list_del(&_uc->list);
atomic_dec(&mrt->cache_resolve_queue_len);
found = true;
break;
}
}
if (list_empty(&mrt->mfc_unres_queue))
del_timer(&mrt->ipmr_expire_timer);
spin_unlock_bh(&mfc_unres_lock);
if (found) {
ipmr_cache_resolve(net, mrt, uc, c);
ipmr_cache_free(uc);
}
call_ipmr_mfc_entry_notifiers(net, FIB_EVENT_ENTRY_ADD, c, mrt->id);
mroute_netlink_event(mrt, c, RTM_NEWROUTE);
return 0;
}
/* Close the multicast socket, and clear the vif tables etc */
static void mroute_clean_tables(struct mr_table *mrt, bool all)
{
struct net *net = read_pnet(&mrt->net);
struct mr_mfc *c, *tmp;
struct mfc_cache *cache;
LIST_HEAD(list);
int i;
/* Shut down all active vif entries */
for (i = 0; i < mrt->maxvif; i++) {
if (!all && (mrt->vif_table[i].flags & VIFF_STATIC))
continue;
vif_delete(mrt, i, 0, &list);
}
unregister_netdevice_many(&list);
/* Wipe the cache */
list_for_each_entry_safe(c, tmp, &mrt->mfc_cache_list, list) {
if (!all && (c->mfc_flags & MFC_STATIC))
continue;
rhltable_remove(&mrt->mfc_hash, &c->mnode, ipmr_rht_params);
list_del_rcu(&c->list);
cache = (struct mfc_cache *)c;
call_ipmr_mfc_entry_notifiers(net, FIB_EVENT_ENTRY_DEL, cache,
mrt->id);
mroute_netlink_event(mrt, cache, RTM_DELROUTE);
mr_cache_put(c);
}
if (atomic_read(&mrt->cache_resolve_queue_len) != 0) {
spin_lock_bh(&mfc_unres_lock);
list_for_each_entry_safe(c, tmp, &mrt->mfc_unres_queue, list) {
list_del(&c->list);
cache = (struct mfc_cache *)c;
mroute_netlink_event(mrt, cache, RTM_DELROUTE);
ipmr_destroy_unres(mrt, cache);
}
spin_unlock_bh(&mfc_unres_lock);
}
}
/* called from ip_ra_control(), before an RCU grace period,
* we dont need to call synchronize_rcu() here
*/
static void mrtsock_destruct(struct sock *sk)
{
struct net *net = sock_net(sk);
struct mr_table *mrt;
rtnl_lock();
ipmr_for_each_table(mrt, net) {
if (sk == rtnl_dereference(mrt->mroute_sk)) {
IPV4_DEVCONF_ALL(net, MC_FORWARDING)–;
inet_netconf_notify_devconf(net, RTM_NEWNETCONF,
NETCONFA_MC_FORWARDING,
NETCONFA_IFINDEX_ALL,
net->ipv4.devconf_all);
RCU_INIT_POINTER(mrt->mroute_sk, NULL);
mroute_clean_tables(mrt, false);
}
}
rtnl_unlock();
}
/* Socket options and virtual interface manipulation. The whole
* virtual interface system is a complete heap, but unfortunately
* that's how BSD mrouted happens to think. Maybe one day with a proper
* MOSPF/PIM router set up we can clean this up.
*/
int ip_mroute_setsockopt(struct sock *sk, int optname, char __user *optval,
unsigned int optlen)
{
struct net *net = sock_net(sk);
int val, ret = 0, parent = 0;
struct mr_table *mrt;
struct vifctl vif;
struct mfcctl mfc;
bool do_wrvifwhole;
u32 uval;
/* There's one exception to the lock – MRT_DONE which needs to unlock */
rtnl_lock();
if (sk->sk_type != SOCK_RAW ||
inet_sk(sk)->inet_num != IPPROTO_IGMP) {
ret = -EOPNOTSUPP;
goto out_unlock;
}
mrt = ipmr_get_table(net, raw_sk(sk)->ipmr_table ? : RT_TABLE_DEFAULT);
if (!mrt) {
ret = -ENOENT;
goto out_unlock;
}
if (optname != MRT_INIT) {
if (sk != rcu_access_pointer(mrt->mroute_sk) &&
!ns_capable(net->user_ns, CAP_NET_ADMIN)) {
ret = -EACCES;
goto out_unlock;
}
}
switch (optname) {
case MRT_INIT:
if (optlen != sizeof(int)) {
ret = -EINVAL;
break;
}
if (rtnl_dereference(mrt->mroute_sk)) {
ret = -EADDRINUSE;
break;
}
ret = ip_ra_control(sk, 1, mrtsock_destruct);
if (ret == 0) {
rcu_assign_pointer(mrt->mroute_sk, sk);
IPV4_DEVCONF_ALL(net, MC_FORWARDING)++;
inet_netconf_notify_devconf(net, RTM_NEWNETCONF,
NETCONFA_MC_FORWARDING,
NETCONFA_IFINDEX_ALL,
net->ipv4.devconf_all);
}
break;
case MRT_DONE:
if (sk != rcu_access_pointer(mrt->mroute_sk)) {
ret = -EACCES;
} else {
/* We need to unlock here because mrtsock_destruct takes
* care of rtnl itself and we can't change that due to
* the IP_ROUTER_ALERT setsockopt which runs without it.
*/
rtnl_unlock();
ret = ip_ra_control(sk, 0, NULL);
goto out;
}
break;
case MRT_ADD_VIF:
case MRT_DEL_VIF:
if (optlen != sizeof(vif)) {
ret = -EINVAL;
break;
}
if (copy_from_user(&vif, optval, sizeof(vif))) {
ret = -EFAULT;
break;
}
if (vif.vifc_vifi >= MAXVIFS) {
ret = -ENFILE;
break;
}
if (optname == MRT_ADD_VIF) {
ret = vif_add(net, mrt, &vif,
sk == rtnl_dereference(mrt->mroute_sk));
} else {
ret = vif_delete(mrt, vif.vifc_vifi, 0, NULL);
}
break;
/* Manipulate the forwarding caches. These live
* in a sort of kernel/user symbiosis.
*/
case MRT_ADD_MFC:
case MRT_DEL_MFC:
parent = -1;
/* fall through */
case MRT_ADD_MFC_PROXY:
case MRT_DEL_MFC_PROXY:
if (optlen != sizeof(mfc)) {
ret = -EINVAL;
break;
}
if (copy_from_user(&mfc, optval, sizeof(mfc))) {
ret = -EFAULT;
break;
}
if (parent == 0)
parent = mfc.mfcc_parent;
if (optname == MRT_DEL_MFC || optname == MRT_DEL_MFC_PROXY)
ret = ipmr_mfc_delete(mrt, &mfc, parent);
else
ret = ipmr_mfc_add(net, mrt, &mfc,
sk == rtnl_dereference(mrt->mroute_sk),
parent);
break;
/* Control PIM assert. */
case MRT_ASSERT:
if (optlen != sizeof(val)) {
ret = -EINVAL;
break;
}
if (get_user(val, (int __user *)optval)) {
ret = -EFAULT;
break;
}
mrt->mroute_do_assert = val;
break;
case MRT_PIM:
if (!ipmr_pimsm_enabled()) {
ret = -ENOPROTOOPT;
break;
}
if (optlen != sizeof(val)) {
ret = -EINVAL;
break;
}
if (get_user(val, (int __user *)optval)) {
ret = -EFAULT;
break;
}
do_wrvifwhole = (val == IGMPMSG_WRVIFWHOLE);
val = !!val;
if (val != mrt->mroute_do_pim) {
mrt->mroute_do_pim = val;
mrt->mroute_do_assert = val;
mrt->mroute_do_wrvifwhole = do_wrvifwhole;
}
break;
case MRT_TABLE:
if (!IS_BUILTIN(CONFIG_IP_MROUTE_MULTIPLE_TABLES)) {
ret = -ENOPROTOOPT;
break;
}
if (optlen != sizeof(uval)) {
ret = -EINVAL;
break;
}
if (get_user(uval, (u32 __user *)optval)) {
ret = -EFAULT;
break;
}
if (sk == rtnl_dereference(mrt->mroute_sk)) {
ret = -EBUSY;
} else {
mrt = ipmr_new_table(net, uval);
if (IS_ERR(mrt))
ret = PTR_ERR(mrt);
else
raw_sk(sk)->ipmr_table = uval;
}
break;
/* Spurious command, or MRT_VERSION which you cannot set. */
default:
ret = -ENOPROTOOPT;
}
out_unlock:
rtnl_unlock();
out:
return ret;
}
/* Getsock opt support for the multicast routing system. */
int ip_mroute_getsockopt(struct sock *sk, int optname, char __user *optval, int __user *optlen)
{
int olr;
int val;
struct net *net = sock_net(sk);
struct mr_table *mrt;
if (sk->sk_type != SOCK_RAW ||
inet_sk(sk)->inet_num != IPPROTO_IGMP)
return -EOPNOTSUPP;
mrt = ipmr_get_table(net, raw_sk(sk)->ipmr_table ? : RT_TABLE_DEFAULT);
if (!mrt)
return -ENOENT;
switch (optname) {
case MRT_VERSION:
val = 0x0305;
break;
case MRT_PIM:
if (!ipmr_pimsm_enabled())
return -ENOPROTOOPT;
val = mrt->mroute_do_pim;
break;
case MRT_ASSERT:
val = mrt->mroute_do_assert;
break;
default:
return -ENOPROTOOPT;
}
if (get_user(olr, optlen))
return -EFAULT;
olr = min_t(unsigned int, olr, sizeof(int));
if (olr < 0)
return -EINVAL;
if (put_user(olr, optlen))
return -EFAULT;
if (copy_to_user(optval, &val, olr))
return -EFAULT;
return 0;
}
/* The IP multicast ioctl support routines. */
int ipmr_ioctl(struct sock *sk, int cmd, void __user *arg)
{
struct sioc_sg_req sr;
struct sioc_vif_req vr;
struct vif_device *vif;
struct mfc_cache *c;
struct net *net = sock_net(sk);
struct mr_table *mrt;
mrt = ipmr_get_table(net, raw_sk(sk)->ipmr_table ? : RT_TABLE_DEFAULT);
if (!mrt)
return -ENOENT;
switch (cmd) {
case SIOCGETVIFCNT:
if (copy_from_user(&vr, arg, sizeof(vr)))
return -EFAULT;
if (vr.vifi >= mrt->maxvif)
return -EINVAL;
vr.vifi = array_index_nospec(vr.vifi, mrt->maxvif);
read_lock(&mrt_lock);
vif = &mrt->vif_table[vr.vifi];
if (VIF_EXISTS(mrt, vr.vifi)) {
vr.icount = vif->pkt_in;
vr.ocount = vif->pkt_out;
vr.ibytes = vif->bytes_in;
vr.obytes = vif->bytes_out;
read_unlock(&mrt_lock);
if (copy_to_user(arg, &vr, sizeof(vr)))
return -EFAULT;
return 0;
}
read_unlock(&mrt_lock);
return -EADDRNOTAVAIL;
case SIOCGETSGCNT:
if (copy_from_user(&sr, arg, sizeof(sr)))
return -EFAULT;
rcu_read_lock();
c = ipmr_cache_find(mrt, sr.src.s_addr, sr.grp.s_addr);
if (c) {
sr.pktcnt = c->_c.mfc_un.res.pkt;
sr.bytecnt = c->_c.mfc_un.res.bytes;
sr.wrong_if = c->_c.mfc_un.res.wrong_if;
rcu_read_unlock();
if (copy_to_user(arg, &sr, sizeof(sr)))
return -EFAULT;
return 0;
}
rcu_read_unlock();
return -EADDRNOTAVAIL;
default:
return -ENOIOCTLCMD;
}
}
#ifdef CONFIG_COMPAT
struct compat_sioc_sg_req {
struct in_addr src;
struct in_addr grp;
compat_ulong_t pktcnt;
compat_ulong_t bytecnt;
compat_ulong_t wrong_if;
};
struct compat_sioc_vif_req {
vifi_tvifi;/* Which iface */
compat_ulong_t icount;
compat_ulong_t ocount;
compat_ulong_t ibytes;
compat_ulong_t obytes;
};
int ipmr_compat_ioctl(struct sock *sk, unsigned int cmd, void __user *arg)
{
struct compat_sioc_sg_req sr;
struct compat_sioc_vif_req vr;
struct vif_device *vif;
struct mfc_cache *c;
struct net *net = sock_net(sk);
struct mr_table *mrt;
mrt = ipmr_get_table(net, raw_sk(sk)->ipmr_table ? : RT_TABLE_DEFAULT);
if (!mrt)
return -ENOENT;
switch (cmd) {
case SIOCGETVIFCNT:
if (copy_from_user(&vr, arg, sizeof(vr)))
return -EFAULT;
if (vr.vifi >= mrt->maxvif)
return -EINVAL;
vr.vifi = array_index_nospec(vr.vifi, mrt->maxvif);
read_lock(&mrt_lock);
vif = &mrt->vif_table[vr.vifi];
if (VIF_EXISTS(mrt, vr.vifi)) {
vr.icount = vif->pkt_in;
vr.ocount = vif->pkt_out;
vr.ibytes = vif->bytes_in;
vr.obytes = vif->bytes_out;
read_unlock(&mrt_lock);
if (copy_to_user(arg, &vr, sizeof(vr)))
return -EFAULT;
return 0;
}
read_unlock(&mrt_lock);
return -EADDRNOTAVAIL;
case SIOCGETSGCNT:
if (copy_from_user(&sr, arg, sizeof(sr)))
return -EFAULT;
rcu_read_lock();
c = ipmr_cache_find(mrt, sr.src.s_addr, sr.grp.s_addr);
if (c) {
sr.pktcnt = c->_c.mfc_un.res.pkt;
sr.bytecnt = c->_c.mfc_un.res.bytes;
sr.wrong_if = c->_c.mfc_un.res.wrong_if;
rcu_read_unlock();
if (copy_to_user(arg, &sr, sizeof(sr)))
return -EFAULT;
return 0;
}
rcu_read_unlock();
return -EADDRNOTAVAIL;
default:
return -ENOIOCTLCMD;
}
}
#endif
static int ipmr_device_event(struct notifier_block *this, unsigned long event, void *ptr)
{
struct net_device *dev = netdev_notifier_info_to_dev(ptr);
struct net *net = dev_net(dev);
struct mr_table *mrt;
struct vif_device *v;
int ct;
if (event != NETDEV_UNREGISTER)
return NOTIFY_DONE;
ipmr_for_each_table(mrt, net) {
v = &mrt->vif_table[0];
for (ct = 0; ct < mrt->maxvif; ct++, v++) {
if (v->dev == dev)
vif_delete(mrt, ct, 1, NULL);
}
}
return NOTIFY_DONE;
}
static struct notifier_block ip_mr_notifier = {
.notifier_call = ipmr_device_event,
};
/* Encapsulate a packet by attaching a valid IPIP header to it.
* This avoids tunnel drivers and other mess and gives us the speed so
* important for multicast video.
*/
static void ip_encap(struct net *net, struct sk_buff *skb,
__be32 saddr, __be32 daddr)
{
struct iphdr *iph;
const struct iphdr *old_iph = ip_hdr(skb);
skb_push(skb, sizeof(struct iphdr));
skb->transport_header = skb->network_header;
skb_reset_network_header(skb);
iph = ip_hdr(skb);
iph->version=4;
iph->tos=old_iph->tos;
iph->ttl=old_iph->ttl;
iph->frag_off=0;
iph->daddr=daddr;
iph->saddr=saddr;
iph->protocol=IPPROTO_IPIP;
iph->ihl=5;
iph->tot_len=htons(skb->len);
ip_select_ident(net, skb, NULL);
ip_send_check(iph);
memset(&(IPCB(skb)->opt), 0, sizeof(IPCB(skb)->opt));
nf_reset(skb);
}
static inline int ipmr_forward_finish(struct net *net, struct sock *sk,
struct sk_buff *skb)
{
struct ip_options *opt = &(IPCB(skb)->opt);
IP_INC_STATS(net, IPSTATS_MIB_OUTFORWDATAGRAMS);
IP_ADD_STATS(net, IPSTATS_MIB_OUTOCTETS, skb->len);
if (unlikely(opt->optlen))
ip_forward_options(skb);
return dst_output(net, sk, skb);
}
#ifdef CONFIG_NET_SWITCHDEV
static bool ipmr_forward_offloaded(struct sk_buff *skb, struct mr_table *mrt,
int in_vifi, int out_vifi)
{
struct vif_device *out_vif = &mrt->vif_table[out_vifi];
struct vif_device *in_vif = &mrt->vif_table[in_vifi];
if (!skb->offload_mr_fwd_mark)
return false;
if (!out_vif->dev_parent_id.id_len || !in_vif->dev_parent_id.id_len)
return false;
return netdev_phys_item_id_same(&out_vif->dev_parent_id,
&in_vif->dev_parent_id);
}
#else
static bool ipmr_forward_offloaded(struct sk_buff *skb, struct mr_table *mrt,
int in_vifi, int out_vifi)
{
return false;
}
#endif
/* Processing handlers for ipmr_forward */
static void ipmr_queue_xmit(struct net *net, struct mr_table *mrt,
int in_vifi, struct sk_buff *skb,
struct mfc_cache *c, int vifi)
{
const struct iphdr *iph = ip_hdr(skb);
struct vif_device *vif = &mrt->vif_table[vifi];
struct net_device *dev;
struct rtable *rt;
struct flowi4 fl4;
int encap = 0;
if (!vif->dev)
goto out_free;
if (vif->flags & VIFF_REGISTER) {
vif->pkt_out++;
vif->bytes_out += skb->len;
vif->dev->stats.tx_bytes += skb->len;
vif->dev->stats.tx_packets++;
ipmr_cache_report(mrt, skb, vifi, IGMPMSG_WHOLEPKT);
goto out_free;
}
if (ipmr_forward_offloaded(skb, mrt, in_vifi, vifi))
goto out_free;
if (vif->flags & VIFF_TUNNEL) {
rt = ip_route_output_ports(net, &fl4, NULL,
vif->remote, vif->local,
0, 0,
IPPROTO_IPIP,
RT_TOS(iph->tos), vif->link);
if (IS_ERR(rt))
goto out_free;
encap = sizeof(struct iphdr);
} else {
rt = ip_route_output_ports(net, &fl4, NULL, iph->daddr, 0,
0, 0,
IPPROTO_IPIP,
RT_TOS(iph->tos), vif->link);
if (IS_ERR(rt))
goto out_free;
}
dev = rt->dst.dev;
if (skb->len+encap > dst_mtu(&rt->dst) && (ntohs(iph->frag_off) & IP_DF)) {
/* Do not fragment multicasts. Alas, IPv4 does not
* allow to send ICMP, so that packets will disappear
* to blackhole.
*/
IP_INC_STATS(net, IPSTATS_MIB_FRAGFAILS);
ip_rt_put(rt);
goto out_free;
}
encap += LL_RESERVED_SPACE(dev) + rt->dst.header_len;
if (skb_cow(skb, encap)) {
ip_rt_put(rt);
goto out_free;
}
vif->pkt_out++;
vif->bytes_out += skb->len;
skb_dst_drop(skb);
skb_dst_set(skb, &rt->dst);
ip_decrease_ttl(ip_hdr(skb));
/* FIXME: forward and output firewalls used to be called here.
* What do we do with netfilter? — RR
*/
if (vif->flags & VIFF_TUNNEL) {
ip_encap(net, skb, vif->local, vif->remote);
/* FIXME: extra output firewall step used to be here. –RR */
vif->dev->stats.tx_packets++;
vif->dev->stats.tx_bytes += skb->len;
}
IPCB(skb)->flags |= IPSKB_FORWARDED;
/* RFC1584 teaches, that DVMRP/PIM router must deliver packets locally
* not only before forwarding, but after forwarding on all output
* interfaces. It is clear, if mrouter runs a multicasting
* program, it should receive packets not depending to what interface
* program is joined.
* If we will not make it, the program will have to join on all
* interfaces. On the other hand, multihoming host (or router, but
* not mrouter) cannot join to more than one interface – it will
* result in receiving multiple packets.
*/
NF_HOOK(NFPROTO_IPV4, NF_INET_FORWARD,
net, NULL, skb, skb->dev, dev,
ipmr_forward_finish);
return;
out_free:
kfree_skb(skb);
}
static int ipmr_find_vif(struct mr_table *mrt, struct net_device *dev)
{
int ct;
for (ct = mrt->maxvif-1; ct >= 0; ct–) {
if (mrt->vif_table[ct].dev == dev)
break;
}
return ct;
}
/* "local" means that we should preserve one skb (for local delivery) */
static void ip_mr_forward(struct net *net, struct mr_table *mrt,
struct net_device *dev, struct sk_buff *skb,
struct mfc_cache *c, int local)
{
int true_vifi = ipmr_find_vif(mrt, dev);
int psend = -1;
int vif, ct;
vif = c->_c.mfc_parent;
c->_c.mfc_un.res.pkt++;
c->_c.mfc_un.res.bytes += skb->len;
c->_c.mfc_un.res.lastuse = jiffies;
if (c->mfc_origin == htonl(INADDR_ANY) && true_vifi >= 0) {
struct mfc_cache *cache_proxy;
/* For an (*,G) entry, we only check that the incomming
* interface is part of the static tree.
*/
cache_proxy = mr_mfc_find_any_parent(mrt, vif);
if (cache_proxy &&
cache_proxy->_c.mfc_un.res.ttls[true_vifi] < 255)
goto forward;
}
/* Wrong interface: drop packet and (maybe) send PIM assert. */
if (mrt->vif_table[vif].dev != dev) {
if (rt_is_output_route(skb_rtable(skb))) {
/* It is our own packet, looped back.
* Very complicated situation…
*
* The best workaround until routing daemons will be
* fixed is not to redistribute packet, if it was
* send through wrong interface. It means, that
* multicast applications WILL NOT work for
* (S,G), which have default multicast route pointing
* to wrong oif. In any case, it is not a good
* idea to use multicasting applications on router.
*/
goto dont_forward;
}
c->_c.mfc_un.res.wrong_if++;
if (true_vifi >= 0 && mrt->mroute_do_assert &&
/* pimsm uses asserts, when switching from RPT to SPT,
* so that we cannot check that packet arrived on an oif.
* It is bad, but otherwise we would need to move pretty
* large chunk of pimd to kernel. Ough… –ANK
*/
(mrt->mroute_do_pim ||
c->_c.mfc_un.res.ttls[true_vifi] < 255) &&
time_after(jiffies,
c->_c.mfc_un.res.last_assert +
MFC_ASSERT_THRESH)) {
c->_c.mfc_un.res.last_assert = jiffies;
ipmr_cache_report(mrt, skb, true_vifi, IGMPMSG_WRONGVIF);
if (mrt->mroute_do_wrvifwhole)
ipmr_cache_report(mrt, skb, true_vifi,
IGMPMSG_WRVIFWHOLE);
}
goto dont_forward;
}
forward:
mrt->vif_table[vif].pkt_in++;
mrt->vif_table[vif].bytes_in += skb->len;
/* Forward the frame */
if (c->mfc_origin == htonl(INADDR_ANY) &&
c->mfc_mcastgrp == htonl(INADDR_ANY)) {
if (true_vifi >= 0 &&
true_vifi != c->_c.mfc_parent &&
ip_hdr(skb)->ttl >
c->_c.mfc_un.res.ttls[c->_c.mfc_parent]) {
/* It's an (*,*) entry and the packet is not coming from
* the upstream: forward the packet to the upstream
* only.
*/
psend = c->_c.mfc_parent;
goto last_forward;
}
goto dont_forward;
}
for (ct = c->_c.mfc_un.res.maxvif – 1;
ct >= c->_c.mfc_un.res.minvif; ct–) {
/* For (*,G) entry, don't forward to the incoming interface */
if ((c->mfc_origin != htonl(INADDR_ANY) ||
ct != true_vifi) &&
ip_hdr(skb)->ttl > c->_c.mfc_un.res.ttls[ct]) {
if (psend != -1) {
struct sk_buff *skb2 = skb_clone(skb, GFP_ATOMIC);
if (skb2)
ipmr_queue_xmit(net, mrt, true_vifi,
skb2, c, psend);
}
psend = ct;
}
}
last_forward:
if (psend != -1) {
if (local) {
struct sk_buff *skb2 = skb_clone(skb, GFP_ATOMIC);
if (skb2)
ipmr_queue_xmit(net, mrt, true_vifi, skb2,
c, psend);
} else {
ipmr_queue_xmit(net, mrt, true_vifi, skb, c, psend);
return;
}
}
dont_forward:
if (!local)
kfree_skb(skb);
}
static struct mr_table *ipmr_rt_fib_lookup(struct net *net, struct sk_buff *skb)
{
struct rtable *rt = skb_rtable(skb);
struct iphdr *iph = ip_hdr(skb);
struct flowi4 fl4 = {
.daddr = iph->daddr,
.saddr = iph->saddr,
.flowi4_tos = RT_TOS(iph->tos),
.flowi4_oif = (rt_is_output_route(rt) ?
skb->dev->ifindex : 0),
.flowi4_iif = (rt_is_output_route(rt) ?
LOOPBACK_IFINDEX :
skb->dev->ifindex),
.flowi4_mark = skb->mark,
};
struct mr_table *mrt;
int err;
err = ipmr_fib_lookup(net, &fl4, &mrt);
if (err)
return ERR_PTR(err);
return mrt;
}
/* Multicast packets for forwarding arrive here
* Called with rcu_read_lock();
*/
int ip_mr_input(struct sk_buff *skb)
{
struct mfc_cache *cache;
struct net *net = dev_net(skb->dev);
int local = skb_rtable(skb)->rt_flags & RTCF_LOCAL;
struct mr_table *mrt;
struct net_device *dev;
/* skb->dev passed in is the loX master dev for vrfs.
* As there are no vifs associated with loopback devices,
* get the proper interface that does have a vif associated with it.
*/
dev = skb->dev;
if (netif_is_l3_master(skb->dev)) {
dev = dev_get_by_index_rcu(net, IPCB(skb)->iif);
if (!dev) {
kfree_skb(skb);
return -ENODEV;
}
}
/* Packet is looped back after forward, it should not be
* forwarded second time, but still can be delivered locally.
*/
if (IPCB(skb)->flags & IPSKB_FORWARDED)
goto dont_forward;
mrt = ipmr_rt_fib_lookup(net, skb);
if (IS_ERR(mrt)) {
kfree_skb(skb);
return PTR_ERR(mrt);
}
if (!local) {
if (IPCB(skb)->opt.router_alert) {
if (ip_call_ra_chain(skb))
return 0;
} else if (ip_hdr(skb)->protocol == IPPROTO_IGMP) {
/* IGMPv1 (and broken IGMPv2 implementations sort of
* Cisco IOS <= 11.2(8)) do not put router alert
* option to IGMP packets destined to routable
* groups. It is very bad, because it means
* that we can forward NO IGMP messages.
*/
struct sock *mroute_sk;
mroute_sk = rcu_dereference(mrt->mroute_sk);
if (mroute_sk) {
nf_reset(skb);
raw_rcv(mroute_sk, skb);
return 0;
}
}
}
/* already under rcu_read_lock() */
cache = ipmr_cache_find(mrt, ip_hdr(skb)->saddr, ip_hdr(skb)->daddr);
if (!cache) {
int vif = ipmr_find_vif(mrt, dev);
if (vif >= 0)
cache = ipmr_cache_find_any(mrt, ip_hdr(skb)->daddr,
vif);
}
/* No usable cache entry */
if (!cache) {
int vif;
if (local) {
struct sk_buff *skb2 = skb_clone(skb, GFP_ATOMIC);
ip_local_deliver(skb);
if (!skb2)
return -ENOBUFS;
skb = skb2;
}
read_lock(&mrt_lock);
vif = ipmr_find_vif(mrt, dev);
if (vif >= 0) {
int err2 = ipmr_cache_unresolved(mrt, vif, skb, dev);
read_unlock(&mrt_lock);
return err2;
}
read_unlock(&mrt_lock);
kfree_skb(skb);
return -ENODEV;
}
read_lock(&mrt_lock);
ip_mr_forward(net, mrt, dev, skb, cache, local);
read_unlock(&mrt_lock);
if (local)
return ip_local_deliver(skb);
return 0;
dont_forward:
if (local)
return ip_local_deliver(skb);
kfree_skb(skb);
return 0;
}
#ifdef CONFIG_IP_PIMSM_V1
/* Handle IGMP messages of PIMv1 */
int pim_rcv_v1(struct sk_buff *skb)
{
struct igmphdr *pim;
struct net *net = dev_net(skb->dev);
struct mr_table *mrt;
if (!pskb_may_pull(skb, sizeof(*pim) + sizeof(struct iphdr)))
goto drop;
pim = igmp_hdr(skb);
mrt = ipmr_rt_fib_lookup(net, skb);
if (IS_ERR(mrt))
goto drop;
if (!mrt->mroute_do_pim ||
pim->group != PIM_V1_VERSION || pim->code != PIM_V1_REGISTER)
goto drop;
if (__pim_rcv(mrt, skb, sizeof(*pim))) {
drop:
kfree_skb(skb);
}
return 0;
}
#endif
#ifdef CONFIG_IP_PIMSM_V2
static int pim_rcv(struct sk_buff *skb)
{
struct pimreghdr *pim;
struct net *net = dev_net(skb->dev);
struct mr_table *mrt;
if (!pskb_may_pull(skb, sizeof(*pim) + sizeof(struct iphdr)))
goto drop;
pim = (struct pimreghdr *)skb_transport_header(skb);
if (pim->type != ((PIM_VERSION << 4) | (PIM_TYPE_REGISTER)) ||
(pim->flags & PIM_NULL_REGISTER) ||
(ip_compute_csum((void *)pim, sizeof(*pim)) != 0 &&
csum_fold(skb_checksum(skb, 0, skb->len, 0))))
goto drop;
mrt = ipmr_rt_fib_lookup(net, skb);
if (IS_ERR(mrt))
goto drop;
if (__pim_rcv(mrt, skb, sizeof(*pim))) {
drop:
kfree_skb(skb);
}
return 0;
}
#endif
int ipmr_get_route(struct net *net, struct sk_buff *skb,
__be32 saddr, __be32 daddr,
struct rtmsg *rtm, u32 portid)
{
struct mfc_cache *cache;
struct mr_table *mrt;
int err;
mrt = ipmr_get_table(net, RT_TABLE_DEFAULT);
if (!mrt)
return -ENOENT;
rcu_read_lock();
cache = ipmr_cache_find(mrt, saddr, daddr);
if (!cache && skb->dev) {
int vif = ipmr_find_vif(mrt, skb->dev);
if (vif >= 0)
cache = ipmr_cache_find_any(mrt, daddr, vif);
}
if (!cache) {
struct sk_buff *skb2;
struct iphdr *iph;
struct net_device *dev;
int vif = -1;
dev = skb->dev;
read_lock(&mrt_lock);
if (dev)
vif = ipmr_find_vif(mrt, dev);
if (vif < 0) {
read_unlock(&mrt_lock);
rcu_read_unlock();
return -ENODEV;
}
skb2 = skb_clone(skb, GFP_ATOMIC);
if (!skb2) {
read_unlock(&mrt_lock);
rcu_read_unlock();
return -ENOMEM;
}
NETLINK_CB(skb2).portid = portid;
skb_push(skb2, sizeof(struct iphdr));
skb_reset_network_header(skb2);
iph = ip_hdr(skb2);
iph->ihl = sizeof(struct iphdr) >> 2;
iph->saddr = saddr;
iph->daddr = daddr;
iph->version = 0;
err = ipmr_cache_unresolved(mrt, vif, skb2, dev);
read_unlock(&mrt_lock);
rcu_read_unlock();
return err;
}
read_lock(&mrt_lock);
err = mr_fill_mroute(mrt, skb, &cache->_c, rtm);
read_unlock(&mrt_lock);
rcu_read_unlock();
return err;
}
static int ipmr_fill_mroute(struct mr_table *mrt, struct sk_buff *skb,
u32 portid, u32 seq, struct mfc_cache *c, int cmd,
int flags)
{
struct nlmsghdr *nlh;
struct rtmsg *rtm;
int err;
nlh = nlmsg_put(skb, portid, seq, cmd, sizeof(*rtm), flags);
if (!nlh)
return -EMSGSIZE;
rtm = nlmsg_data(nlh);
rtm->rtm_family = RTNL_FAMILY_IPMR;
rtm->rtm_dst_len = 32;
rtm->rtm_src_len = 32;
rtm->rtm_tos = 0;
rtm->rtm_table = mrt->id;
if (nla_put_u32(skb, RTA_TABLE, mrt->id))
goto nla_put_failure;
rtm->rtm_type = RTN_MULTICAST;
rtm->rtm_scope = RT_SCOPE_UNIVERSE;
if (c->_c.mfc_flags & MFC_STATIC)
rtm->rtm_protocol = RTPROT_STATIC;
else
rtm->rtm_protocol = RTPROT_MROUTED;
rtm->rtm_flags = 0;
if (nla_put_in_addr(skb, RTA_SRC, c->mfc_origin) ||
nla_put_in_addr(skb, RTA_DST, c->mfc_mcastgrp))
goto nla_put_failure;
err = mr_fill_mroute(mrt, skb, &c->_c, rtm);
/* do not break the dump if cache is unresolved */
if (err < 0 && err != -ENOENT)
goto nla_put_failure;
nlmsg_end(skb, nlh);
return 0;
nla_put_failure:
nlmsg_cancel(skb, nlh);
return -EMSGSIZE;
}
static int _ipmr_fill_mroute(struct mr_table *mrt, struct sk_buff *skb,
u32 portid, u32 seq, struct mr_mfc *c, int cmd,
int flags)
{
return ipmr_fill_mroute(mrt, skb, portid, seq, (struct mfc_cache *)c,
cmd, flags);
}
static size_t mroute_msgsize(bool unresolved, int maxvif)
{
size_t len =
NLMSG_ALIGN(sizeof(struct rtmsg))
+ nla_total_size(4)/* RTA_TABLE */
+ nla_total_size(4)/* RTA_SRC */
+ nla_total_size(4)/* RTA_DST */
;
if (!unresolved)
len = len
+ nla_total_size(4)/* RTA_IIF */
+ nla_total_size(0)/* RTA_MULTIPATH */
+ maxvif * NLA_ALIGN(sizeof(struct rtnexthop))
/* RTA_MFC_STATS */
+ nla_total_size_64bit(sizeof(struct rta_mfc_stats))
;
return len;
}
static void mroute_netlink_event(struct mr_table *mrt, struct mfc_cache *mfc,
int cmd)
{
struct net *net = read_pnet(&mrt->net);
struct sk_buff *skb;
int err = -ENOBUFS;
skb = nlmsg_new(mroute_msgsize(mfc->_c.mfc_parent >= MAXVIFS,
mrt->maxvif),
GFP_ATOMIC);
if (!skb)
goto errout;
err = ipmr_fill_mroute(mrt, skb, 0, 0, mfc, cmd, 0);
if (err < 0)
goto errout;
rtnl_notify(skb, net, 0, RTNLGRP_IPV4_MROUTE, NULL, GFP_ATOMIC);
return;
errout:
kfree_skb(skb);
if (err < 0)
rtnl_set_sk_err(net, RTNLGRP_IPV4_MROUTE, err);
}
static size_t igmpmsg_netlink_msgsize(size_t payloadlen)
{
size_t len =
NLMSG_ALIGN(sizeof(struct rtgenmsg))
+ nla_total_size(1)/* IPMRA_CREPORT_MSGTYPE */
+ nla_total_size(4)/* IPMRA_CREPORT_VIF_ID */
+ nla_total_size(4)/* IPMRA_CREPORT_SRC_ADDR */
+ nla_total_size(4)/* IPMRA_CREPORT_DST_ADDR */
/* IPMRA_CREPORT_PKT */
+ nla_total_size(payloadlen)
;
return len;
}
static void igmpmsg_netlink_event(struct mr_table *mrt, struct sk_buff *pkt)
{
struct net *net = read_pnet(&mrt->net);
struct nlmsghdr *nlh;
struct rtgenmsg *rtgenm;
struct igmpmsg *msg;
struct sk_buff *skb;
struct nlattr *nla;
int payloadlen;
payloadlen = pkt->len – sizeof(struct igmpmsg);
msg = (struct igmpmsg *)skb_network_header(pkt);
skb = nlmsg_new(igmpmsg_netlink_msgsize(payloadlen), GFP_ATOMIC);
if (!skb)
goto errout;
nlh = nlmsg_put(skb, 0, 0, RTM_NEWCACHEREPORT,
sizeof(struct rtgenmsg), 0);
if (!nlh)
goto errout;
rtgenm = nlmsg_data(nlh);
rtgenm->rtgen_family = RTNL_FAMILY_IPMR;
if (nla_put_u8(skb, IPMRA_CREPORT_MSGTYPE, msg->im_msgtype) ||
nla_put_u32(skb, IPMRA_CREPORT_VIF_ID, msg->im_vif) ||
nla_put_in_addr(skb, IPMRA_CREPORT_SRC_ADDR,
msg->im_src.s_addr) ||
nla_put_in_addr(skb, IPMRA_CREPORT_DST_ADDR,
msg->im_dst.s_addr))
goto nla_put_failure;
nla = nla_reserve(skb, IPMRA_CREPORT_PKT, payloadlen);
if (!nla || skb_copy_bits(pkt, sizeof(struct igmpmsg),
nla_data(nla), payloadlen))
goto nla_put_failure;
nlmsg_end(skb, nlh);
rtnl_notify(skb, net, 0, RTNLGRP_IPV4_MROUTE_R, NULL, GFP_ATOMIC);
return;
nla_put_failure:
nlmsg_cancel(skb, nlh);
errout:
kfree_skb(skb);
rtnl_set_sk_err(net, RTNLGRP_IPV4_MROUTE_R, -ENOBUFS);
}
static int ipmr_rtm_getroute(struct sk_buff *in_skb, struct nlmsghdr *nlh,
struct netlink_ext_ack *extack)
{
struct net *net = sock_net(in_skb->sk);
struct nlattr *tb[RTA_MAX + 1];
struct sk_buff *skb = NULL;
struct mfc_cache *cache;
struct mr_table *mrt;
struct rtmsg *rtm;
__be32 src, grp;
u32 tableid;
int err;
err = nlmsg_parse(nlh, sizeof(*rtm), tb, RTA_MAX,
rtm_ipv4_policy, extack);
if (err < 0)
goto errout;
rtm = nlmsg_data(nlh);
src = tb[RTA_SRC] ? nla_get_in_addr(tb[RTA_SRC]) : 0;
grp = tb[RTA_DST] ? nla_get_in_addr(tb[RTA_DST]) : 0;
tableid = tb[RTA_TABLE] ? nla_get_u32(tb[RTA_TABLE]) : 0;
mrt = ipmr_get_table(net, tableid ? tableid : RT_TABLE_DEFAULT);
if (!mrt) {
err = -ENOENT;
goto errout_free;
}
/* entries are added/deleted only under RTNL */
rcu_read_lock();
cache = ipmr_cache_find(mrt, src, grp);
rcu_read_unlock();
if (!cache) {
err = -ENOENT;
goto errout_free;
}
skb = nlmsg_new(mroute_msgsize(false, mrt->maxvif), GFP_KERNEL);
if (!skb) {
err = -ENOBUFS;
goto errout_free;
}
err = ipmr_fill_mroute(mrt, skb, NETLINK_CB(in_skb).portid,
nlh->nlmsg_seq, cache,
RTM_NEWROUTE, 0);
if (err < 0)
goto errout_free;
err = rtnl_unicast(skb, net, NETLINK_CB(in_skb).portid);
errout:
return err;
errout_free:
kfree_skb(skb);
goto errout;
}
static int ipmr_rtm_dumproute(struct sk_buff *skb, struct netlink_callback *cb)
{
return mr_rtm_dumproute(skb, cb, ipmr_mr_table_iter,
_ipmr_fill_mroute, &mfc_unres_lock);
}
static const struct nla_policy rtm_ipmr_policy[RTA_MAX + 1] = {
[RTA_SRC]= { .type = NLA_U32 },
[RTA_DST]= { .type = NLA_U32 },
[RTA_IIF]= { .type = NLA_U32 },
[RTA_TABLE]= { .type = NLA_U32 },
[RTA_MULTIPATH]= { .len = sizeof(struct rtnexthop) },
};
static bool ipmr_rtm_validate_proto(unsigned char rtm_protocol)
{
switch (rtm_protocol) {
case RTPROT_STATIC:
case RTPROT_MROUTED:
return true;
}
return false;
}
static int ipmr_nla_get_ttls(const struct nlattr *nla, struct mfcctl *mfcc)
{
struct rtnexthop *rtnh = nla_data(nla);
int remaining = nla_len(nla), vifi = 0;
while (rtnh_ok(rtnh, remaining)) {
mfcc->mfcc_ttls[vifi] = rtnh->rtnh_hops;
if (++vifi == MAXVIFS)
break;
rtnh = rtnh_next(rtnh, &remaining);
}
return remaining > 0 ? -EINVAL : vifi;
}
/* returns < 0 on error, 0 for ADD_MFC and 1 for ADD_MFC_PROXY */
static int rtm_to_ipmr_mfcc(struct net *net, struct nlmsghdr *nlh,
struct mfcctl *mfcc, int *mrtsock,
struct mr_table **mrtret,
struct netlink_ext_ack *extack)
{
struct net_device *dev = NULL;
u32 tblid = RT_TABLE_DEFAULT;
struct mr_table *mrt;
struct nlattr *attr;
struct rtmsg *rtm;
int ret, rem;
ret = nlmsg_validate(nlh, sizeof(*rtm), RTA_MAX, rtm_ipmr_policy,
extack);
if (ret < 0)
goto out;
rtm = nlmsg_data(nlh);
ret = -EINVAL;
if (rtm->rtm_family != RTNL_FAMILY_IPMR || rtm->rtm_dst_len != 32 ||
rtm->rtm_type != RTN_MULTICAST ||
rtm->rtm_scope != RT_SCOPE_UNIVERSE ||
!ipmr_rtm_validate_proto(rtm->rtm_protocol))
goto out;
memset(mfcc, 0, sizeof(*mfcc));
mfcc->mfcc_parent = -1;
ret = 0;
nlmsg_for_each_attr(attr, nlh, sizeof(struct rtmsg), rem) {
switch (nla_type(attr)) {
case RTA_SRC:
mfcc->mfcc_origin.s_addr = nla_get_be32(attr);
break;
case RTA_DST:
mfcc->mfcc_mcastgrp.s_addr = nla_get_be32(attr);
break;
case RTA_IIF:
dev = __dev_get_by_index(net, nla_get_u32(attr));
if (!dev) {
ret = -ENODEV;
goto out;
}
break;
case RTA_MULTIPATH:
if (ipmr_nla_get_ttls(attr, mfcc) < 0) {
ret = -EINVAL;
goto out;
}
break;
case RTA_PREFSRC:
ret = 1;
break;
case RTA_TABLE:
tblid = nla_get_u32(attr);
break;
}
}
mrt = ipmr_get_table(net, tblid);
if (!mrt) {
ret = -ENOENT;
goto out;
}
*mrtret = mrt;
*mrtsock = rtm->rtm_protocol == RTPROT_MROUTED ? 1 : 0;
if (dev)
mfcc->mfcc_parent = ipmr_find_vif(mrt, dev);
out:
return ret;
}
/* takes care of both newroute and delroute */
static int ipmr_rtm_route(struct sk_buff *skb, struct nlmsghdr *nlh,
struct netlink_ext_ack *extack)
{
struct net *net = sock_net(skb->sk);
int ret, mrtsock, parent;
struct mr_table *tbl;
struct mfcctl mfcc;
mrtsock = 0;
tbl = NULL;
ret = rtm_to_ipmr_mfcc(net, nlh, &mfcc, &mrtsock, &tbl, extack);
if (ret < 0)
return ret;
parent = ret ? mfcc.mfcc_parent : -1;
if (nlh->nlmsg_type == RTM_NEWROUTE)
return ipmr_mfc_add(net, tbl, &mfcc, mrtsock, parent);
else
return ipmr_mfc_delete(tbl, &mfcc, parent);
}
static bool ipmr_fill_table(struct mr_table *mrt, struct sk_buff *skb)
{
u32 queue_len = atomic_read(&mrt->cache_resolve_queue_len);
if (nla_put_u32(skb, IPMRA_TABLE_ID, mrt->id) ||
nla_put_u32(skb, IPMRA_TABLE_CACHE_RES_QUEUE_LEN, queue_len) ||
nla_put_s32(skb, IPMRA_TABLE_MROUTE_REG_VIF_NUM,
mrt->mroute_reg_vif_num) ||
nla_put_u8(skb, IPMRA_TABLE_MROUTE_DO_ASSERT,
mrt->mroute_do_assert) ||
nla_put_u8(skb, IPMRA_TABLE_MROUTE_DO_PIM, mrt->mroute_do_pim) ||
nla_put_u8(skb, IPMRA_TABLE_MROUTE_DO_WRVIFWHOLE,
mrt->mroute_do_wrvifwhole))
return false;
return true;
}
static bool ipmr_fill_vif(struct mr_table *mrt, u32 vifid, struct sk_buff *skb)
{
struct nlattr *vif_nest;
struct vif_device *vif;
/* if the VIF doesn't exist just continue */
if (!VIF_EXISTS(mrt, vifid))
return true;
vif = &mrt->vif_table[vifid];
vif_nest = nla_nest_start(skb, IPMRA_VIF);
if (!vif_nest)
return false;
if (nla_put_u32(skb, IPMRA_VIFA_IFINDEX, vif->dev->ifindex) ||
nla_put_u32(skb, IPMRA_VIFA_VIF_ID, vifid) ||
nla_put_u16(skb, IPMRA_VIFA_FLAGS, vif->flags) ||
nla_put_u64_64bit(skb, IPMRA_VIFA_BYTES_IN, vif->bytes_in,
IPMRA_VIFA_PAD) ||
nla_put_u64_64bit(skb, IPMRA_VIFA_BYTES_OUT, vif->bytes_out,
IPMRA_VIFA_PAD) ||
nla_put_u64_64bit(skb, IPMRA_VIFA_PACKETS_IN, vif->pkt_in,
IPMRA_VIFA_PAD) ||
nla_put_u64_64bit(skb, IPMRA_VIFA_PACKETS_OUT, vif->pkt_out,
IPMRA_VIFA_PAD) ||
nla_put_be32(skb, IPMRA_VIFA_LOCAL_ADDR, vif->local) ||
nla_put_be32(skb, IPMRA_VIFA_REMOTE_ADDR, vif->remote)) {
nla_nest_cancel(skb, vif_nest);
return false;
}
nla_nest_end(skb, vif_nest);
return true;
}
static int ipmr_rtm_dumplink(struct sk_buff *skb, struct netlink_callback *cb)
{
struct net *net = sock_net(skb->sk);
struct nlmsghdr *nlh = NULL;
unsigned int t = 0, s_t;
unsigned int e = 0, s_e;
struct mr_table *mrt;
s_t = cb->args[0];
s_e = cb->args[1];
ipmr_for_each_table(mrt, net) {
struct nlattr *vifs, *af;
struct ifinfomsg *hdr;
u32 i;
if (t < s_t)
goto skip_table;
nlh = nlmsg_put(skb, NETLINK_CB(cb->skb).portid,
cb->nlh->nlmsg_seq, RTM_NEWLINK,
sizeof(*hdr), NLM_F_MULTI);
if (!nlh)
break;
hdr = nlmsg_data(nlh);
memset(hdr, 0, sizeof(*hdr));
hdr->ifi_family = RTNL_FAMILY_IPMR;
af = nla_nest_start(skb, IFLA_AF_SPEC);
if (!af) {
nlmsg_cancel(skb, nlh);
goto out;
}
if (!ipmr_fill_table(mrt, skb)) {
nlmsg_cancel(skb, nlh);
goto out;
}
vifs = nla_nest_start(skb, IPMRA_TABLE_VIFS);
if (!vifs) {
nla_nest_end(skb, af);
nlmsg_end(skb, nlh);
goto out;
}
for (i = 0; i < mrt->maxvif; i++) {
if (e < s_e)
goto skip_entry;
if (!ipmr_fill_vif(mrt, i, skb)) {
nla_nest_end(skb, vifs);
nla_nest_end(skb, af);
nlmsg_end(skb, nlh);
goto out;
}
skip_entry:
e++;
}
s_e = 0;
e = 0;
nla_nest_end(skb, vifs);
nla_nest_end(skb, af);
nlmsg_end(skb, nlh);
skip_table:
t++;
}
out:
cb->args[1] = e;
cb->args[0] = t;
return skb->len;
}
#ifdef CONFIG_PROC_FS
/* The /proc interfaces to multicast routing :
* /proc/net/ip_mr_cache & /proc/net/ip_mr_vif
*/
static void *ipmr_vif_seq_start(struct seq_file *seq, loff_t *pos)
__acquires(mrt_lock)
{
struct mr_vif_iter *iter = seq->private;
struct net *net = seq_file_net(seq);
struct mr_table *mrt;
mrt = ipmr_get_table(net, RT_TABLE_DEFAULT);
if (!mrt)
return ERR_PTR(-ENOENT);
iter->mrt = mrt;
read_lock(&mrt_lock);
return mr_vif_seq_start(seq, pos);
}
static void ipmr_vif_seq_stop(struct seq_file *seq, void *v)
__releases(mrt_lock)
{
read_unlock(&mrt_lock);
}
static int ipmr_vif_seq_show(struct seq_file *seq, void *v)
{
struct mr_vif_iter *iter = seq->private;
struct mr_table *mrt = iter->mrt;
if (v == SEQ_START_TOKEN) {
seq_puts(seq,
"Interface BytesIn PktsIn BytesOut PktsOut Flags Local Remote\\n");
} else {
const struct vif_device *vif = v;
const char *name = vif->dev ?
vif->dev->name : "none";
seq_printf(seq,
"%2td %-10s %8ld %7ld %8ld %7ld %05X %08X %08X\\n",
vif – mrt->vif_table,
name, vif->bytes_in, vif->pkt_in,
vif->bytes_out, vif->pkt_out,
vif->flags, vif->local, vif->remote);
}
return 0;
}
static const struct seq_operations ipmr_vif_seq_ops = {
.start = ipmr_vif_seq_start,
.next = mr_vif_seq_next,
.stop = ipmr_vif_seq_stop,
.show = ipmr_vif_seq_show,
};
static void *ipmr_mfc_seq_start(struct seq_file *seq, loff_t *pos)
{
struct net *net = seq_file_net(seq);
struct mr_table *mrt;
mrt = ipmr_get_table(net, RT_TABLE_DEFAULT);
if (!mrt)
return ERR_PTR(-ENOENT);
return mr_mfc_seq_start(seq, pos, mrt, &mfc_unres_lock);
}
static int ipmr_mfc_seq_show(struct seq_file *seq, void *v)
{
int n;
if (v == SEQ_START_TOKEN) {
seq_puts(seq,
"Group Origin Iif Pkts Bytes Wrong Oifs\\n");
} else {
const struct mfc_cache *mfc = v;
const struct mr_mfc_iter *it = seq->private;
const struct mr_table *mrt = it->mrt;
seq_printf(seq, "%08X %08X %-3hd",
(__force u32) mfc->mfc_mcastgrp,
(__force u32) mfc->mfc_origin,
mfc->_c.mfc_parent);
if (it->cache != &mrt->mfc_unres_queue) {
seq_printf(seq, " %8lu %8lu %8lu",
mfc->_c.mfc_un.res.pkt,
mfc->_c.mfc_un.res.bytes,
mfc->_c.mfc_un.res.wrong_if);
for (n = mfc->_c.mfc_un.res.minvif;
n < mfc->_c.mfc_un.res.maxvif; n++) {
if (VIF_EXISTS(mrt, n) &&
mfc->_c.mfc_un.res.ttls[n] < 255)
seq_printf(seq,
" %2d:%-3d",
n, mfc->_c.mfc_un.res.ttls[n]);
}
} else {
/* unresolved mfc_caches don't contain
* pkt, bytes and wrong_if values
*/
seq_printf(seq, " %8lu %8lu %8lu", 0ul, 0ul, 0ul);
}
seq_putc(seq, '\\n');
}
return 0;
}
static const struct seq_operations ipmr_mfc_seq_ops = {
.start = ipmr_mfc_seq_start,
.next = mr_mfc_seq_next,
.stop = mr_mfc_seq_stop,
.show = ipmr_mfc_seq_show,
};
#endif
#ifdef CONFIG_IP_PIMSM_V2
static const struct net_protocol pim_protocol = {
.handler=pim_rcv,
.netns_ok=1,
};
#endif
static unsigned int ipmr_seq_read(struct net *net)
{
ASSERT_RTNL();
return net->ipv4.ipmr_seq + ipmr_rules_seq_read(net);
}
static int ipmr_dump(struct net *net, struct notifier_block *nb)
{
return mr_dump(net, nb, RTNL_FAMILY_IPMR, ipmr_rules_dump,
ipmr_mr_table_iter, &mrt_lock);
}
static const struct fib_notifier_ops ipmr_notifier_ops_template = {
.family= RTNL_FAMILY_IPMR,
.fib_seq_read= ipmr_seq_read,
.fib_dump= ipmr_dump,
.owner= THIS_MODULE,
};
static int __net_init ipmr_notifier_init(struct net *net)
{
struct fib_notifier_ops *ops;
net->ipv4.ipmr_seq = 0;
ops = fib_notifier_ops_register(&ipmr_notifier_ops_template, net);
if (IS_ERR(ops))
return PTR_ERR(ops);
net->ipv4.ipmr_notifier_ops = ops;
return 0;
}
static void __net_exit ipmr_notifier_exit(struct net *net)
{
fib_notifier_ops_unregister(net->ipv4.ipmr_notifier_ops);
net->ipv4.ipmr_notifier_ops = NULL;
}
/* Setup for IP multicast routing */
static int __net_init ipmr_net_init(struct net *net)
{
int err;
err = ipmr_notifier_init(net);
if (err)
goto ipmr_notifier_fail;
err = ipmr_rules_init(net);
if (err < 0)
goto ipmr_rules_fail;
#ifdef CONFIG_PROC_FS
err = -ENOMEM;
if (!proc_create_net("ip_mr_vif", 0, net->proc_net, &ipmr_vif_seq_ops,
sizeof(struct mr_vif_iter)))
goto proc_vif_fail;
if (!proc_create_net("ip_mr_cache", 0, net->proc_net, &ipmr_mfc_seq_ops,
sizeof(struct mr_mfc_iter)))
goto proc_cache_fail;
#endif
return 0;
#ifdef CONFIG_PROC_FS
proc_cache_fail:
remove_proc_entry("ip_mr_vif", net->proc_net);
proc_vif_fail:
ipmr_rules_exit(net);
#endif
ipmr_rules_fail:
ipmr_notifier_exit(net);
ipmr_notifier_fail:
return err;
}
static void __net_exit ipmr_net_exit(struct net *net)
{
#ifdef CONFIG_PROC_FS
remove_proc_entry("ip_mr_cache", net->proc_net);
remove_proc_entry("ip_mr_vif", net->proc_net);
#endif
ipmr_notifier_exit(net);
ipmr_rules_exit(net);
}
static struct pernet_operations ipmr_net_ops = {
.init = ipmr_net_init,
.exit = ipmr_net_exit,
};
int __init ip_mr_init(void)
{
int err;
mrt_cachep = kmem_cache_create("ip_mrt_cache",
sizeof(struct mfc_cache),
0, SLAB_HWCACHE_ALIGN | SLAB_PANIC,
NULL);
err = register_pernet_subsys(&ipmr_net_ops);
if (err)
goto reg_pernet_fail;
err = register_netdevice_notifier(&ip_mr_notifier);
if (err)
goto reg_notif_fail;
#ifdef CONFIG_IP_PIMSM_V2
if (inet_add_protocol(&pim_protocol, IPPROTO_PIM) < 0) {
pr_err("%s: can't add PIM protocol\\n", __func__);
err = -EAGAIN;
goto add_proto_fail;
}
#endif
rtnl_register(RTNL_FAMILY_IPMR, RTM_GETROUTE,
ipmr_rtm_getroute, ipmr_rtm_dumproute, 0);
rtnl_register(RTNL_FAMILY_IPMR, RTM_NEWROUTE,
ipmr_rtm_route, NULL, 0);
rtnl_register(RTNL_FAMILY_IPMR, RTM_DELROUTE,
ipmr_rtm_route, NULL, 0);
rtnl_register(RTNL_FAMILY_IPMR, RTM_GETLINK,
NULL, ipmr_rtm_dumplink, 0);
return 0;
#ifdef CONFIG_IP_PIMSM_V2
add_proto_fail:
unregister_netdevice_notifier(&ip_mr_notifier);
#endif
reg_notif_fail:
unregister_pernet_subsys(&ipmr_net_ops);
reg_pernet_fail:
kmem_cache_destroy(mrt_cachep);
return err;
}
net/ipv4/ipmr.c 是 Linux 内核中实现 IPv4 多播路由的核心文件,主要支持 mrouted 和 PIM(Protocol Independent Multicast)协议。以下是对其关键部分的详细分析:
1. 核心数据结构
a) 多播路由表 (struct mr_table)
管理多播路由信息,包含:
-
虚拟接口表 (vif_table): 存储所有虚拟接口(VIF)信息。
-
多播转发缓存 (MFC): 使用哈希表 (mfc_hash) 存储已解析的路由条目。
-
未解析队列 (mfc_unres_queue): 临时存放待处理的多播包。
-
定时器 (ipmr_expire_timer): 清理超时未解析的条目。
b) 虚拟接口 (struct vif_device)
表示一个多播虚拟接口:
-
设备指针 (dev): 关联的网络设备。
-
本地/远程地址 (local, remote): 隧道端点地址。
-
统计信息: 收发包数、字节数等。
-
标志位 (flags):
VIFF_TUNNEL(隧道接口)、VIFF_REGISTER(注册到用户态)、VIFF_STATIC(静态配置)。
c) 多播转发缓存 (struct mfc_cache)
存储多播路由条目:
-
源地址/组地址 (mfc_origin, mfc_mcastgrp): 标识流。
-
输入接口 (mfc_parent): 接收流量的 VIF。
-
输出接口 TTL 映射 (res.ttls): 每个 VIF 的 TTL 阈值。
-
统计信息: 转发包数、字节数、错误计数。
2. 核心功能实现
a) 虚拟接口管理
-
创建 (vif_add)
支持三种类型接口:-
VIFF_REGISTER: 注册到用户态守护进程(如 pimd)。
-
VIFF_TUNNEL: 创建 IP-in-IP 隧道(如 DVMRP)。
-
物理接口: 绑定到实际网络设备。
-
-
删除 (vif_delete)
解除设备绑定,更新统计,清理关联资源。
b) MFC 条目管理
-
动态学习 (ipmr_cache_find)
通过哈希表快速查找 MFC 条目。 -
静态配置 (ipmr_mfc_add)
通过 Netlink 或 Socket 添加静态路由。 -
超时处理 (ipmr_expire_process)
清理未解析的 MFC 条目(默认 10 秒超时)。
c) 数据包转发 (ip_mr_forward)
处理流程:
查找 MFC: 匹配源地址和组地址。
验证输入接口: 检查包是否从正确 VIF 进入。
TTL 检查: 跳过 TTL 不足的出口。
克隆包多播转发:
-
隧道接口:封装 IP-in-IP 头。
-
物理接口:直接发送。
-
注册接口:提交给用户态守护进程。
d) 未解析包处理 (ipmr_cache_unresolved)
当 MFC 不存在时:
创建临时 MFC 条目并加入未解析队列。
发送 IGMPMSG_NOCACHE 通知用户态。
收到响应后解析条目并转发缓存的包。
3. 关键协议支持
a) PIM 协议处理
-
PIMv1 (pim_rcv_v1)
处理 PIM 注册消息,封装包转发到 RP。 -
PIMv2 (pim_rcv)
校验消息有效性,转发到注册接口。
b) IGMP 消息
-
缓存报告 (ipmr_cache_report)
发送 IGMPMSG_WHOLEPKT 通知用户态新流量。
4. 控制平面接口
a) Netlink 操作
-
路由操作 (ipmr_rtm_route)
处理 RTM_NEWROUTE/RTM_DELROUTE 添加/删除 MFC。 -
信息查询 (ipmr_rtm_dumplink)
通过 RTM_GETLINK 返回 VIF 和 MFC 表信息。
b) Sysctl / Procfs
-
/proc/net/ip_mr_vif
显示所有 VIF 的统计信息。 -
/proc/net/ip_mr_cache
列出 MFC 条目,包括源组地址、转发计数。
c) Socket IOCTL
-
SIOCGETVIFCNT
获取指定 VIF 的流量统计。 -
SIOCGETSGCNT
查询特定多播流的转发统计。
5. 初始化和清理
-
初始化 (ip_mr_init)
-
注册网络子系统 (register_pernet_subsys)。
-
创建 MFC 缓存内存池 (kmem_cache_create)。
-
注册 Netlink 操作和 PIM 协议处理器。
-
挂载 Procfs 文件。
-
退出清理
释放所有路由表、定时器、Procfs 项。
6. 设计亮点
-
多表支持 (CONFIG_IP_MROUTE_MULTIPLE_TABLES)
允许创建多个独立的多播路由表。 -
高效查找
使用 RCU 保护的哈希表管理 MFC。 -
用户态协作
通过原始套接字 (mroute_sk) 与 mrouted/pimd 交互。 -
模块化结构
分离转发/控制逻辑,支持动态扩展。
总结
ipmr.c 实现了完整的 IPv4 多播路由框架,核心功能包括:
虚拟接口管理:支持物理接口、隧道和注册接口。
转发引擎:基于 MFC 条目高效克隆转发包。
协议支持:与 PIM/DVMRP 守护进程协同工作。
控制接口:提供 Netlink、IOCTL、Procfs 等管理方式。
其设计平衡了性能和灵活性,是 Linux 多播路由的基石。









评论前必须登录!
注册