 网硕互联帮助中心
网硕互联帮助中心C++对象的JSON序列化与反序列化
基于JsonCpp库实现C++对象序列化与反序列化
JSON 介绍
JSON作为一种轻量级的数据交换格式,在Web服务和应用程序中广泛使用。
JSON(JavaScript Object Notation)是一种轻量级的数据交换格式,易于人阅读和编写,同时也易于机器解析和生成。它基于JavaScript的一个子集,但是JSON是独立于语言的,许多编程语言都支持JSON格式数据的生成和解析。
两个关键点: 对象和数组
对象由键值对组成 键 -> 字符串 值->字符串(string),数字(number),布尔值(boolean),对象(object)(就可以组成对象的对象,一直嵌套下去)或null
数组由有序的值的集合组成
eg.
{
"_comment": "2025年配置文件版本v2.0 – 数据源:企业ERP系统",
"company": "Tech Corp",
"departments": [
{
"_comment": "部门对象注释 – name:部门名称(必填),employees:员工列表(至少1人)",
"name": "Engineering",
"employees": [
{
"id": 101,
"name": "Alice",
"skills": ["Java", "Python", "Docker"],
"isManager": false,
"contact": {
"email": "alice@tech.com",
"phone": ["123-456-7890", "987-654-3210"]
}
}
]
}
]
}
2.JSON 与 XML 比较
在SQL Server 2014这本书上,我看见看XML的身影:
|
维度 |
JSON优势场景 |
XML优势场景 |
|
速度 |
高频数据交换(如实时API) |
非性能敏感场景(如文档存储) |
|
复杂度 |
简单到中等数据结构 |
多层次嵌套、需验证的复杂数据 |
|
生态 |
现代Web开发、JavaScript生态 |
传统企业系统、跨平台协议(如RSS) |
JSON与XML(Extensible Markup Language)都是用于数据交换的有效格式。与XML相比,JSON更加轻量级,结构简单,解析速度快,且易于在JavaScript环境中操作。由于这些优势,JSON在Web API设计中越来越受欢迎,逐渐取代了XML成为主流的数据交换格式。
JSON 字符串与C++对象转换
在c++后端开发中,我们会有需求: 从c++对象与JSON字符串的相互转换
JSON作为一种轻量级的数据交换格式,与C++等强类型语言之间的转换,涉及了数据模型的适配与映射问题。
JSON数据模型与C++数据模型对比
JSON(JavaScript Object Notation)是一种轻量级的数据交换格式,JSON数据模型的核心是键值对集合,即对象。
C++是一种静态类型、编译式语言,具备复杂的类型系统,包含结构体(Structs)、类(Classes)以及各种基本数据类型和容器。
显而易见,两种数据模型之间进行转换,我们需要将JSON对象转换为C++的类或结构体实例,反之亦然。由于JSON是动态的,通常需要为每个JSON对象创建一个相应的C++类,这个类定义了与JSON对象相对应的成员变量,并提供序列化与反序列化的接口。
JSON 对象序列化与反序列化原理
对象的序列化是指将对象的状态信息转换为可以存储或传输的形式的过程
数据转换机制
JSON与C++类型系统的映射是序列化的基础,主要依赖以下机制实现:
基本类型映射
JSON的number对应C++的int/double,string对应std::string,boolean对应bool,null通过std::optional或指针类型处理。
容器类型映射
JSON数组可映射到std::vector、std::list等线性容器,对象映射到std::map或自定义结构体。例如,{"skills": ["C++", "Python"]}可自动转换为std::vector<std::string>。
自定义对象映射
侵入式:通过类的to_json/from_json方法手动定义字段映射关系。
非侵入式:利用宏(如NLOHMANN_DEFINE_TYPE_NON_INTRUSIVE)自动生成映射代码,通过反射获取成员变量信息。
静态反射:借助Boost.PFR或结构化绑定,在编译期遍历结构体成员,实现零代码入侵的序列化。
关键步骤
遍历对象的成员变量,将它们转换为JSON可识别的键值对格式。
对于基本数据类型,直接转换即可;对于复杂类型,则需要递归调用序列化函数。反序列化的过程则相反,解析JSON字符串,并根据解析结果创建C++对象的实例。
接下来我们来看代码
转换实践案例(基于nlohmann/json)
首先,我的MinGW中没有默认有json库,本人在GitHub上找到了该库,将其载入我的cpp配置文件,更新我的配置文档
库函数位置:nlohmann/json
而后更新我的
![]()
我们来看代码:
#include <nlohmann/json.hpp>
using json = nlohmann::json;
using namespace std;
// 结构体定义
struct Person
{
string name;
int age;
bool isStu;
};
// 序列化适配器的实现
void to_json(json& j, const Person& p) {
j = json{{"name", p.name}, {"age", p.age}, {"isStu", p.isStu}};
}
// 反序列化适配器的实现
void fron_json(const json& j, Person& p) {
j.at("name").get_to(p.name);
j.at("age").get_to(p.age);
j.at("isStu").get_to(p.isStu);
}
当然,如果+=stdc++11及其以上,我们还能使用宏来做
像这样:
我们跳转到库函数来看看
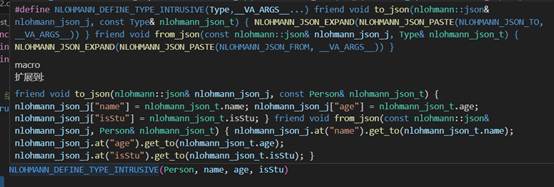
/*!
@brief macro
@def NLOHMANN_DEFINE_TYPE_INTRUSIVE
@since version 3.9.0
*/
#define NLOHMANN_DEFINE_TYPE_INTRUSIVE(Type, …) \\
friend void to_json(nlohmann::json& nlohmann_json_j, const Type& nlohmann_json_t) { NLOHMANN_JSON_EXPAND(NLOHMANN_JSON_PASTE(NLOHMANN_JSON_TO, __VA_ARGS__)) } \\
friend void from_json(const nlohmann::json& nlohmann_json_j, Type& nlohmann_json_t) { NLOHMANN_JSON_EXPAND(NLOHMANN_JSON_PASTE(NLOHMANN_JSON_FROM, __VA_ARGS__)) }
我们使用宏就可以这样来写代码
#include <nlohmann/json.hpp>
using json = nlohmann::json;
using namespace std;
// 结构体定义
struct Person
{
string name;
int age;
bool isStu;
NLOHMANN_DEFINE_TYPE_INTRUSIVE(Person, name, age, isStu)
};
上述是在我们包含了json库的情况下可以那么去做
当然,为了代码可以更加灵活 我们可以自己来实现序列化和反序列化函数
见下:
// 手动实现c++对象与JSON字符串的转换
#include <iostream>
#include <string>
using namespace std;
class Person
{
private:
string name;
int age;
bool isStu;
public:
Person(const string& name, int age, bool isStu) : name(name), age(age), isStu(isStu) {}
Person() {}
~Person() {}
// 序列化函数
string serialize() {
string ans = "{\\"name\\":\\"" + name + "\\", \\"age\\":" + std::to_string(age) + ", \\"isStudent\\":" + std::to_string(isStu) + "}";
return ans;
}
// 反序列化函数
static Person deserialize(const string& json) {
// 解析JSON字符串 填充Person对象
Person p;
size_t nameStart = json.find("\\"name\\":\\"") + 8;
size_t nameEnd = json.find("\\"", nameStart);
p.name = json.substr(nameStart, nameEnd – nameStart);
size_t ageStart = json.find("\\"age\\":") + 6;
size_t ageEnd = json.find(",", ageStart);
p.age = stoi(json.substr(ageStart, ageEnd – ageStart));
size_t isStuStart = json.find("\\"isStu\\":") + 8;
p.isStu = (json.substr(isStuStart, 4) == "true");
return p;
}
};
int main(int argc, char const *argv[])
{
Person p = {"Kyrie Irving", 30, false};
string serialized = p.serialize();
Person pDeserialized = Person::deserialize(serialized);
return 0;
}
对比分析 转换效率与资源消耗分析
手动实现
转换效率
- 优点:手动实现可以针对特定的应用场景进行高度优化,避免了不必要的函数调用和数据复制。在处理简单的 JSON 结构时,手动实现的代码可以非常高效,因为它直接操作数据,没有额外的开销。
- 缺点:手动实现的代码通常缺乏通用性,对于复杂的 JSON 结构,编写和维护代码的难度会大大增加。而且,手动实现很难处理一些复杂的情况,如嵌套的 JSON 对象和数组,这可能会导致代码的效率下降。
资源消耗
- 优点:手动实现可以精确控制内存的使用,避免了第三方库可能带来的额外内存开销。在资源受限的环境中,手动实现可能是更好的选择。
- 缺点:手动实现需要开发者自己处理各种边界情况和错误处理,这可能会增加代码的复杂度和内存泄漏的风险。而且,手动实现的代码通常不够健壮,容易出现错误。
第三方库
转换效率
- 优点:第三方库通常经过了高度优化,具有较高的转换效率。它们使用了各种算法和数据结构来提高序列化和反序列化的速度,特别是在处理复杂的 JSON 结构时,第三方库的优势更加明显。
- 缺点:第三方库可能会有一些额外的开销,如内存分配和函数调用。在处理简单的 JSON 结构时,这些开销可能会显得比较明显。
资源消耗
- 优点:第三方库通常会处理各种边界情况和错误处理,代码更加健壮,减少了内存泄漏的风险。而且,一些库还提供了内存池等机制来优化内存使用。
- 缺点:第三方库可能会引入额外的依赖和开销,增加了可执行文件的大小。在资源受限的环境中,这可能是一个问题。
转换效率与资源消耗分析工具
使用性能分析工具(如gprof、Valgrind等)来监测程序的 CPU 使用情况和内存分配情况。
显然,我们发现,手动实现,更需要我们注意错误处理机制
错误处理机制
JSON解析错误通常发生在JSON格式不正确时,比如缺少闭合的括号、逗号使用错误、或键值对未正确配对等。在C++中解析JSON字符串,当遇到错误时,需要具体分析错误类型,以便采取相应的处理措施。
我们来看看 nlohmann/json 这样的库是如何解决的,学习 一下其解析错误处理的方式
我们来看看这个库中的 parse_error 异常 的实现
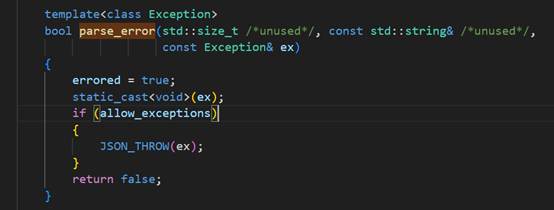
我们来解析一下该模板函数
模板参数 Exception
该函数是一个模板函数,允许接收不同类型的异常对象(如 parse_error 或 exception),体现了库的灵活性和对多种异常类型的支持。
参数说明
核心逻辑分析
标记错误状态
errored = true;
设置布尔变量 errored 为 true,用于记录解析过程中发生了错误。此变量可能在后续流程中用于判断是否需要终止解析或回滚操作。
异常对象的处理
static_cast<void>(ex);
此操作仅为避免编译器对未使用变量 ex 的警告,无实际功能影响。
异常抛出条件
if (allow_exceptions)
{
JSON_THROW(ex);
}
返回值
return false;
返回 false 表示解析失败,通知上层解析器终止当前解析流程。
错误处理分层
异常信息传递
通过异常对象 ex 传递具体错误信息(如 parse_error::create(101, …)),包含错误代码、位置和描述,便于开发者定位问题。例如,用户遇到的空输入错误会触发 [json.exception.parse_error.101],明确提示问题原因。
与解析流程的集成
此函数通常由词法分析器(lexer)或语法分析器(parser)在检测到非法 Token 或结构时调用,构成完整的错误处理链路。
与其他机制的协作
assert_invariant 检查
在解析过程中,库通过 assert_invariant 函数校验 JSON 对象状态(如指针非空),确保错误不会进一步传播到不一致的状态。
错误日志记录
用户可通过自定义回调函数或捕获异常后记录日志(如 log_error 函数),实现错误追踪。
依托于 nlohmann/json 库 我们可以处理多种异常错误
错误类型及检测
#include <iostream>
#include <fstream>
#include <nlohmann/json.hpp>
using json = nlohmann::json;
using namespace std;
// 日志记录函数
void log_error(const string& message, int error_code = 0) {
cerr << "[ERROR] Code " << error_code << ": " << message << endl;
// 可拓展 将错误写入文件
}
int main()
{
try {
// condition1: 文件中读取JSON
ifstream file("data.json");
if (!file) {
log_error("打开文件异常", 1001);
exit(1);
}
json j;
file >> j; // 抛出parse_error 可能
// condition2: 从字符串解析JSON
string json_str = R"({"name": "Kevin", "age": "invalid_value"})";
json j2 = json::parse(json_str); // 抛出 type_error
// condition3: 访问不存在的字段
cout << j["nonexistent_key"]; // 可能抛出 out_of_range
} catch (const json::parse_error& e) {
// 捕获 parse_error
// 解析错误(如语法错误、空输入)
log_error("Parse error: " + string(e.what()), e.id);
// 错误位置 按字节定位
cerr << "Error position: byte " << e.byte << endl;
} catch (const json::type_error& e) {
// 类型错误
log_error("Type error: " + string(e.what()), e.id);
} catch (const json::out_of_range& e) {
// 访问不存在的键或索引
log_error("Key not found: " + string(e.what()), e.id);
} catch (const std::exception& e) {
// 通用错误
log_error("Unexpected error: " + string(e.what()));
}
return 0;
}
1. JSON解析错误
在处理JSON数据时,解析错误是最常见也是最直接的问题。JSON解析错误通常发生在JSON格式不正确时,比如缺少闭合的括号、逗号使用错误、或键值对未正确配对等。在C++中解析JSON字符串,当遇到错误时,需要具体分析错误类型,以便采取相应的处理措施。
上述代码段中
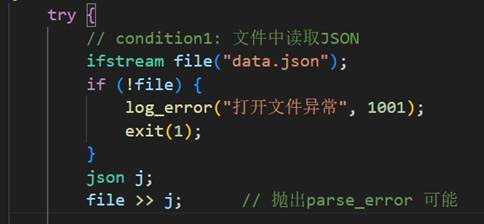
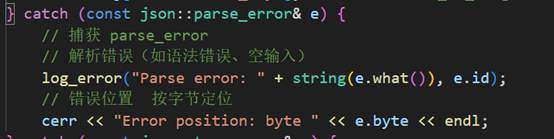
这两种情况就是最常遇见的异常
2. 数据类型转换错误
JSON数据包括六种基本类型:对象、数组、字符串、数字、布尔值和null。在将JSON字符串转换为C++对象时,可能会遇到数据类型不匹配的问题。比如,尝试将一个数字类型的JSON值转换为字符串类型C++对象,或者将一个字符串类型的JSON值转换为数字类型对象。
来看一段代码:
#include <iostream>
#include <nlohmann/json.hpp>
using json = nlohmann::json;
int main() {
std::string json_str = R"({"number": "123", "string": "hello", "bool": true})";
json j;
try {
j = json::parse(json_str);
// 检查字段存在性(避免 out_of_range)
if (j.contains("number") && j["number"].is_number()) {
int number = j["number"];
} else {
std::cerr << "number 字段缺失或类型错误" << std::endl;
}
std::string str = j.value("string", "default_str");
bool bool_val = j["bool"].get<bool>();
} catch (const json::type_error& e) {
std::cerr << "类型错误: " << e.what() << std::endl;
} catch (const json::parse_error& e) {
std::cerr << "JSON解析失败: " << e.what() << std::endl;
}
return 0;
}
结合该代码与上文,我们可以发现 捕获到 json::type_error 中的异常
当然,nlohmann/json 库,其提供了 get<T>() 方法来尝试进行安全类型转换,并通过异常来报告类型转换错误:
我们在库函数中也能看见其定义:
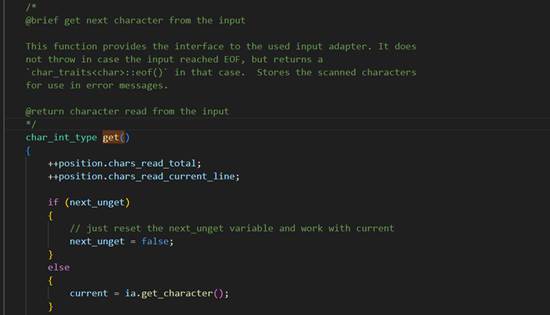
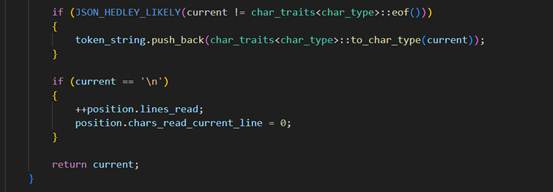
我将其扒下来具体看看:
nlohmann/json.hpp
/*
@brief get next character from the input
This function provides the interface to the used input adapter. It does
not throw in case the input reached EOF, but returns a
`char_traits<char>::eof()` in that case. Stores the scanned characters
for use in error messages.
@return character read from the input
*/
char_int_type get()
{
++position.chars_read_total;
++position.chars_read_current_line;
if (next_unget)
{
// just reset the next_unget variable and work with current
next_unget = false;
}
else
{
current = ia.get_character();
}
if (JSON_HEDLEY_LIKELY(current != char_traits<char_type>::eof()))
{
token_string.push_back(char_traits<char_type>::to_char_type(current));
}
if (current == '\\n')
{
++position.lines_read;
position.chars_read_current_line = 0;
}
return current;
}
我们来翻译一下该函数的@brief注释
/ *
从输入中获取下一个字符
这个函数为使用的输入适配器提供接口。它
如果输入达到EOF,则不抛出,而是返回a
‘ char_traits<char>::eof() ’在这种情况下。存储扫描的字符
用于错误消息。
@返回从输入中读取的字符
* /
get<T>() 的实现结合了类型安全、异常安全和模板元编程技术,其核心在于:
#include <nlohmann/json.hpp>
#include <iostream>
using json = nlohmann::json;
using namespace std;
template<typename T>
bool SafeGet(const json& j, const string& key, T& val, const T& default_val = T{}) {
if (!j.contains(key))
return false;
try {
val = j.at(key).get<T>();
return true;
} catch(const std::exception& e) {
val = default_val;
return false;
}
}
int main() {
json j = json::parse(R"({"number": "123", "bool": true})");
int num = 0;
if (!SafeGet(j, "number", num)) {
cerr << "num 字段无效,使用默认值: " << num << endl;
}
bool flag = false;
SafeGet(j, "bool", flag, false); // 带默认值的重载
return 0;
}
这就是可以安全使用的get<T>()的示例
3. 编码/解码错误
JSON数据的编码和解码错误通常涉及到字符编码问题,比如在使用非UTF-8编码的JSON数据时,如果没有正确处理,就会出现乱码或解析失败的问题。在C++中处理JSON数据时,需要确保JSON字符串和C++程序使用相同的字符编码。
在我们的nlohmann/json库中,内部默认使用UTF-8编码进行处理。如果遇到非UTF-8编码的字符串,需要在解析之前进行转码。这通常可以通过专门的编码转换库来完成。
我们还是来看代码
#include <iconv.h>
#include <stdexcept>
#include <string>
#include <iostream>
#include <nlohmann/json.hpp>
using json = nlohmann::json;
using namespace std;
// 调用iconv.h库 转换编码格式
/**
* @brief 将输入字符串从一种字符编码转换为另一种字符编码。
*
* @param input 输入的字符串,待转换的文本内容。
* @param from_encoding 源字符编码格式,例如 "GBK"。
* @param to_encoding 目标字符编码格式,默认为 "UTF-8"。
* @return string 转换后的字符串,编码格式为目标编码。
*
* @throws runtime_error 如果初始化 iconv 或编码转换失败,将抛出异常。
*
* @note 使用 iconv 库进行字符编码转换。iconv_open 用于初始化转换描述符,
* iconv 执行实际的编码转换,iconv_close 释放资源。
*
* @details
* – iconv_open: 初始化一个用于字符编码转换的转换描述符。
* – iconv: 执行字符编码转换。
* – iconv_close: 释放转换描述符资源。
*
* @example
* string input = "你好";
* string output = convert_encoding(input, "GBK", "UTF-8");
* std::cout << output << std::endl;
*/
string convert_encoding(const string& input, const char* from_encoding, const char* to_encoding = "UTF-8") {
/**
* iconv_t iconv_open (const char* tocode, const char* fromcode)
* 功能: 初始化一个用于字符编码转换的转换描述符
* 参数:
* const char* tocode: 目标编码格式,例如 "UTF-8"
* const char* fromcode: 源编码格式,例如 "GBK"
* 返回值:
* iconv_t: 转换描述符,类型为 void*,用于后续的编码转换操作
*/
iconv_t cd = iconv_open(to_encoding, from_encoding);
if (cd == (iconv_t)-1) {
throw runtime_error("iconv 初始化失败");
}
char* in_buf = const_cast<char*>(input.data());
size_t in_len = input.size();
string output(input.size() * 4, '\\0');
char* out_buf = output.data();
size_t out_len = output.size();
/**
* size_t iconv (iconv_t cd, char** inbuf, size_t *inbytesleft, char** outbuf, size_t outbytesleft);
* 功能: 执行字符编码转换,将输入缓冲区中的数据从源编码转换为目标编码。
* 参数:
* iconv_t cd: 转换描述符,由 iconv_open 初始化。
* char** inbuf: 输入缓冲区的指针,指向待转换的字符串。
* size_t *inbytesleft: 输入缓冲区剩余的字节数。
* char** outbuf: 输出缓冲区的指针,存储转换后的字符串。
* size_t *outbytesleft: 输出缓冲区剩余的字节数。
* 返回值:
* size_t: 成功转换的字节数。如果发生错误,返回 (size_t)-1。
* 注意:
* – 转换过程中,inbuf 和 outbuf 的指针会被更新,指向未处理的部分。
* – inbytesleft 和 outbytesleft 会被更新,表示剩余的字节数。
*/
if (iconv(cd, &in_buf, &in_len,&out_buf, &out_len) == (size_t)-1) {
iconv_close(cd);
throw runtime_error("编码转换失败");
}
iconv_close(cd);
output.resize(output.size() – out_len);
return output;
}
struct Product {
string name_gbk; // gbk编码字符串
double price;
};
// 带编码转换的to_json
void to_json(json& j, const Product& p) {
// GBK -> UTF-8
string utf8_name = convert_encoding(p.name_gbk, "GBK");
j = json{{"name", utf8_name}, {"price", p.price}};
}
int main() {
Product product{"IPhone", 4999}; // GBK存储
try {
json j = product;
cout << "JSON数据:\\n" << j.dump(4) << endl;
} catch (const exception& e) {
cerr << "错误: " << e.what() << endl;
}
return 0;
}
错误处理策略
1. 异常处理
异常处理是C++中处理错误的一种常见方式。在解析JSON和执行数据类型转换时,我们可以使用try-catch块来捕获并处理各种异常。异常处理应该恰当地使用,避免过度捕获异常,因为这可能会隐藏程序的其他错误。
异常处理策略在实际操作中应该包括异常类型的选择,如何抛出异常,以及如何恰当地捕获和处理异常。
还是来看代码
#include <iostream>
#include <nlohmann/json.hpp>
using json = nlohmann::json;
// JSON数据处理函数(支持嵌套结构解析)
void process_json(const json& j) {
// 防御性检查:验证必需字段存在性
if (!j.contains("user") || !j["user"].is_object()) {
throw std::runtime_error("缺失user对象字段");
}
// 嵌套对象解析
const auto& user = j["user"];
std::string username = user.value("name", "unknown"); // 安全获取字段
// 类型严格验证[3](@ref)
if (user["age"].is_number()) {
int age = user["age"];
std::cout << "用户年龄: " << age << std::endl;
} else {
throw json::type_error::create(302, "age字段类型无效", &user);
}
// 数组处理[8](@ref)
if (j.contains("tags") && j["tags"].is_array()) {
std::cout << "关联标签: ";
for (const auto& tag : j["tags"]) {
std::cout << tag.get<std::string>() << " ";
}
std::cout << std::endl;
}
}
int main() {
// 含嵌套结构的JSON测试数据
std::string json_str = R"(
{
"user": {
"name": "John",
"age": "thirty", // 故意设置错误类型
"email": "john@example.com"
},
"tags": ["tech", "c++", "json"]
}
)";
try {
json j = json::parse(json_str); // 可能抛出parse_error
process_json(j);
}
// 分层捕获异常类型
catch (const json::parse_error& e) {
std::cerr << "[解析错误] 字节位置 " << e.byte << " 错误详情: " << e.what() << std::endl;
} catch (const json::type_error& e) {
std::cerr << "[类型错误] ID:" << e.id << " 错误上下文: " << e.what() << std::endl;
} catch (const json::out_of_range& e) {
std::cerr << "[字段缺失] " << e.what() << std::endl;
} catch (const json::exception& e) {
std::cerr << "[JSON异常] 错误码 " << e.id << " : " << e.what() << std::endl;
}
return 0;
}
2. 回调函数
除了运用异常处理机制,还可借助错误回调函数来应对错误情况。此方法允许我们自行定义一个函数,一旦出现错误,该函数便会执行一系列预先设定的操作,而无需依赖异常机制。在某些特定场景下,这种方式不仅能提升代码的执行效率,还能够处理一些异常处理难以应对的状况,比如内存不足问题。
在采用错误回调函数时,首先要定义专门的错误处理函数,然后在错误发生的地方调用这个函数。值得注意的是,这个回调函数应具备高度的灵活性,能够依据不同类型的错误,执行相应的差异化逻辑。
来看代码:
#include <iostream>
#include <functional>
#include <nlohmann/json.hpp>
using json = nlohmann::json;
using namespace std;
// 错误类型枚举
enum class ErrorType {
ParseError, // JSON解析失败
FieldMissing, // 字段缺失
TypeMismatch, // 类型不匹配
InvalidValue // 值非法
};
// 错误回调函数类型
using ErrorBack = function<void(ErrorType, const string&)>;
// 错误处理函数(全局)
void defaultErrorHandler(ErrorType type, const string& msg) {
const char* typeStr = "";
switch (type) {
case ErrorType::ParseError: typeStr = "[解析错误]"; break;
case ErrorType::FieldMissing: typeStr = "[字段缺失]"; break;
case ErrorType::TypeMismatch: typeStr = "[类型错误]"; break;
case ErrorType::InvalidValue: typeStr = "[非法值]"; break;
}
cerr << typeStr << " " << msg << endl;
}
// 带错误回调的JSON处理函数
bool process_json(const string& json_str, const ErrorBack& cb = defaultErrorHandler) {
// 解析JSON 禁用异常
auto ans = json::parse(json_str, nullptr, false);
if (ans.is_discarded()) {
cb(ErrorType::ParseError, "JSON语法错误");
return false;
}
const json& j = ans;
// 字段验证
if (!j.contains("user") || !j["user"].is_object()) {
cb(ErrorType::FieldMissing, "缺失user对象");
return false;
}
const auto& user = j["user"];
if (!user.contains("age") || !user["age"].is_number()) {
cb(ErrorType::TypeMismatch, "user.age需要数值类型");
return false;
}
int age = user["age"];
if (age < 0 || age > 150) {
cb(ErrorType::InvalidValue, "年龄值超出合理范围: " + std::to_string(age));
return false;
}
// 正常处理逻辑…
cout << "验证通过,用户年龄: " << age << endl;
return true;
}
int main(int argc, char const *argv[])
{
// 测试用例1:合法数据
std::string valid_json = R"({
"user": {"name": "John", "age": 30}
})";
process_json(valid_json);
// 测试用例2:非法年龄值
std::string invalid_age = R"({
"user": {"name": "Alice", "age": -5}
})";
process_json(invalid_age);
// 测试用例3:自定义错误处理
std::string missing_field = R"({"profile": {}})";
process_json(missing_field, [](ErrorType t, const std::string& msg) {
std::cerr << "自定义处理 => " << msg << std::endl;
});
return 0;
}
在这里,我的代码是通过GBK来保存的
运行效果如下:

如果开始保存方式不对,则会是:

3. 日志记录与错误报告
日志记录在程序运行中起着关键作用,它如同为开发者配备的 “透视镜”,能够精准追踪程序的运行状态,助力高效排查问题。在错误处理机制里,将错误信息记录至日志文件,或者直接输出到控制台,是一项不可或缺的基本要求。
一份完整的错误报告,通常涵盖多个关键要素。
首先是错误发生的精确时间,它能为问题追溯提供时间轴线索;
错误类型明确指出问题的性质,方便快速定位问题方向;
错误描述则详细阐述问题细节,帮助开发者深入理解问题所在;
调用堆栈信息就像一张 “导航图”,清晰展示程序执行路径,辅助分析错误产生的过程;
影响范围界定了错误波及的区域,有助于评估问题的严重程度。
日志级别是对日志信息进行分类管理的重要方式,常见的包括 ERROR(错误)、WARN(警告)、INFO(信息)、DEBUG(调试)等。依据不同的日志级别,系统会有针对性地记录相应级别的错误信息。
以处理 JSON 数据为例,一旦出现错误,除了记录常见的错误信息外,还应特别关注错误发生的具体位置,这如同在程序代码 “地图” 上精准标注出问题点;详细的错误具体描述,确保对错误有全面清晰的认识;以及错误上下文信息,它为理解错误在特定环境下产生的原因提供了关键线索。
还是来看代码:
#include <iostream>
#include <fstream>
#include <ctime>
#include <iomanip>
#include <nlohmann/json.hpp>
#include <mutex>
#include <sstream> // 字符串流处理
#include <cstring> // 用于strerror函数
using json = nlohmann::json;
using namespace std;
// 日志枚举
enum LogLevel {
DEBUG,
INFO,
WARN,
ERROR
};
// DEBUG: 调试信息,INFO: 常规信息,WARN: 警告,ERROR: 错误
// 单例日志
class Logger {
private:
Logger(/* args */) = default; // 禁止外部构造
~Logger() {
if (logFile_.is_open()) logFile_.close();
}
Logger(const Logger&) = delete;
Logger& operator=(const Logger&) = delete;
// 转换日志级别为字符串
string levelToString(LogLevel level) {
switch (level) {
case DEBUG: return "DEBUG";
case INFO: return "INFO";
case WARN: return "WARN";
case ERROR: return "ERROR";
default: return "UNKNOWN";
}
}
/* 字段 */
ofstream logFile_; // 日志文件流
LogLevel curLevel_; // 当前的日志级别
mutex mutex_; // 互斥锁保证线程安全
public:
// 单例实例(线程安全)
static Logger& getInstance() {
// c++ 11 保证静态局部变量初始化 线程安全
static Logger instance;
return instance;
}
// 初始化日志系统
/**
* @brief 初始化日志系统,设置日志文件和日志级别。
*
* 此函数用于打开指定的日志文件,并设置日志记录的最低级别。
* 如果日志文件无法打开,会输出错误信息到标准错误流。
* enum _Ios_Openmode
{
_S_app = 1L << 0,
_S_ate = 1L << 1,
_S_bin = 1L << 2,
_S_in = 1L << 3,
_S_out = 1L << 4,
_S_trunc = 1L << 5,
_S_noreplace = 1L << 6,
_S_ios_openmode_end = 1L << 16,
_S_ios_openmode_max = __INT_MAX__,
_S_ios_openmode_min = ~__INT_MAX__
};
*
* @param filename 日志文件名,默认为 "Log.log"。
* @param level 日志级别,默认为 INFO。
*/
void init(const string& filename = "Log.log", LogLevel level = INFO) {
lock_guard<mutex> lock(mutex_); // 确保线程安全
// 打开日志文件,模式为 ios::out(输出模式)和 ios::app(追加模式)
logFile_.open(filename, ios::out | ios::app);
if (!logFile_.is_open()) {
// 如果日志文件打开失败,输出错误信息
cerr << "日志文件打开失败: " << filename << " 错误: " << strerror(errno) << endl;
}
// 设置当前日志级别
curLevel_ = level;
}
// 记录日志 核心
/**
* @brief 记录日志信息到控制台和文件。
*
* 此函数根据日志级别过滤日志信息,并将日志信息格式化后输出到控制台和日志文件。
* 日志格式为:[时间戳][日志级别] 文件名:行号 – 日志消息。
*
* @param level 日志级别(DEBUG, INFO, WARN, ERROR)。
* @param message 日志消息内容。
* @param file 记录日志的源文件名(默认使用预定义宏 __FILE__)。
* @param line 记录日志的行号(默认使用预定义宏 __LINE__)。
*/
void log(LogLevel level, const string& message, const char* file = __FILE__, int line = __LINE__) {
// 如果日志级别低于当前设置的日志级别,则直接返回
if (level < curLevel_) return;
// 使用互斥锁保证多线程环境下的线程安全
lock_guard<mutex> lock(mutex_);
// 获取当前时间戳
auto now = chrono::system_clock::now();
time_t now_time = chrono::system_clock::to_time_t(now);
tm now_tm = *localtime(&now_time);
// 格式化日志信息
ostringstream oss;
oss << "[" << put_time(&now_tm, "%Y-%m-%d %H:%M:%S") << "]" // 时间戳
<< "[" << levelToString(level) << "] " // 日志级别
<< file << ":" << line << " – " // 文件名和行号
<< message; // 日志消息
const string logMsg = oss.str();
// 输出到控制台(DEBUG 级别使用青色显示)
if (level == DEBUG) cout << "\\033[36m"; // 青色
cout << logMsg << "\\033[0m" << endl;
// 如果日志文件已打开,将日志写入文件
if (logFile_.is_open()) {
logFile_ << logMsg << endl;
// 立即刷新缓冲区,确保日志数据不会丢失
logFile_.flush();
}
}
};
// 宏
#define LOG_DEBUG(msg) Logger::getInstance().log(DEBUG, msg, __FILE__, __LINE__)
#define LOG_INFO(msg) Logger::getInstance().log(INFO, msg, __FILE__, __LINE__)
#define LOG_WARN(msg) Logger::getInstance().log(WARN, msg, __FILE__, __LINE__)
#define LOG_ERROR(msg) Logger::getInstance().log(ERROR, msg, __FILE__, __LINE__)
// 获取JSON的错误上下文
/**
* @brief 获取 JSON 字符串中错误位置的上下文信息。
*
* 此函数用于从给定的 JSON 字符串中提取错误位置附近的一段上下文信息,
* 以便更好地理解错误发生的具体位置和内容。
*
* @param json_str 输入的 JSON 字符串。
* @param error_pos 错误发生的位置(索引)。
* @return string 返回包含错误位置上下文的字符串,格式为 "…上下文内容…"。
* 如果错误位置在字符串的开头或结尾,可能会省略部分上下文。
*/
string get_json_context(const string& json_str, size_t error_pos) {
const size_t context_size = 0;
size_t start = (error_pos > context_size) ? error_pos – context_size : 0; // 未越界就是直接相减
size_t end = min(error_pos + context_size, json_str.size());
return "…" + json_str.substr(start, end – start) + "…";
}
int main(int argc, char const *argv[])
{
// 初始化
Logger::getInstance().init("runtime.log", DEBUG);
// (const char [101])"{\\n \\"name\\": \\"Alice\\",\\n \\"age\\": \\"thirty\\", \\n \\"address\\": { \\"city\\": \\"Beijing\\" }\\n }"
string json_str = R"({
"name": "Alice",
"age": "thirty",
"address": { "city": "Beijing" }
})";
try {
json j = json::parse(json_str);
// 数据校验
if (!j["age"].is_number()) {
LOG_WARN("类型异常: age字段应为数值类型,当前值: " + j["age"].dump());
j["age"] = 30; // 自动修正示例
}
LOG_INFO("JSON解析成功,用户: " + j["name"].get<string>());
} catch (const json::parse_error& e) {
// 详细错误日志
ostringstream errorMsg;
errorMsg << "JSON解析失败: " << e.what() << "\\n"
<< "错误位置: 字节偏移 " << e.byte << "\\n"
<< "错误上下文: " << get_json_context(json_str, e.byte);
LOG_ERROR(errorMsg.str());
} catch (const exception& e) {
LOG_ERROR("未捕获异常: " + string(e.what()));
}
return 0;
}
追加模式写入保证不覆盖。
这样可以帮助开发人员了解错误发生的上下文,便于后续问题分析和解决。
JSON Schema验证和C++ 11 特性应用
JSON Schema验证机制
JSON Schema概念
JSON Schema 是用于描述 JSON 数据结构的元数据标准,核心功能是验证 JSON 数据是否符合预设模式,防止数据解析错误。Schema 本身以 JSON 对象形式存在,可定义数据结构、类型、取值范围、默认值等规则,确保数据格式正确与一致性。
C++ 实现JSON Schema验证
在 C++ 中实现 JSON Schema 验证,可借助第三方库,还是nlohmann/json。nlohmann/json用于将JSON Schema解析为一个验证器,然后使用验证器来校验具体的JSON数据
也有两种方式 手动基础校验和 拓展库实现自动校验
来看代码
#include <nlohmann/json.hpp>
#include <iostream>
#include <stdexcept>
using namespace std;
using json = nlohmann::json;
// ================== 方法1:手动校验函数 ==================
// 手动校验函数 根据 Schema 规则逐项检查字段类型、必填项等约束 实现基础校验
bool validateSchema(const json& data, const json& schema, string &error) {
// 检查顶层对象的类型是否匹配
if (schema.contains("type") && schema["type"] != data.type_name()) {
error = "类型不匹配,期望类型: " + schema["type"].get<string>();
return false;
}
// 检查必填字段是否存在
if (schema.contains("required")) {
for (const auto& field : schema["required"]) {
// 如果必填字段在数据中不存在,则返回错误
if (!data.contains(field)) {
error = "缺少必填字段: " + field.get<std::string>();
return false;
}
}
}
// 检查对象的属性是否符合 Schema 定义
if (schema.contains("properties")) {
for (const auto& [key, propSchema] : schema["properties"].items()) {
// 如果字段是可选的且数据中不存在,则跳过检查
if (!data.contains(key))
continue;
// 检查字段的类型是否匹配
if (propSchema.contains("type")) {
// 如果字段类型与 Schema 定义的类型不匹配,则返回错误
if (data[key].type_name() != propSchema["type"]) {
error = "字段 '" + key + "' 类型错误,期望类型: " + propSchema["type"].get<string>();
return false;
}
}
// 检查数值字段的最小值约束
if (propSchema.contains("minimum") && data[key].is_number()) {
// 如果字段值小于 Schema 定义的最小值,则返回错误
if (data[key] < propSchema["minimum"]) {
error = "字段 '" + key + "' 的值必须 >= " + propSchema["minimum"].dump();
return false;
}
}
// 检查字段值是否在枚举范围内
if (propSchema.contains("enum")) {
bool isValid = false;
// 遍历枚举值,检查字段值是否匹配其中之一
for (const auto& val : propSchema["enum"]) {
if (data[key] == val)
isValid = true;
}
// 如果字段值不在枚举范围内,则返回错误
if (!isValid) {
error = "字段 '" + key + "' 的值不在枚举范围内";
return false;
}
}
}
}
// 如果所有检查都通过,则返回 true
return true;
}
// ================== 方法2:扩展类校验 ==================
/**
* 继承 json 类添加校验方法,实现更灵活的链式调用
*/
class SchemaValidator : public json {
private:
/* 对内没有字段 */
public:
// 重载 operator[] 以返回 SchemaValidator 引用
// 重载[]
SchemaValidator& operator[](const char* key) {
return static_cast<SchemaValidator&>(json::operator[](key));
}
SchemaValidator& operator[](const string& key) {
return static_cast<SchemaValidator&>(json::operator[](key));
}
// 构造函数,接受一个 json 对象
SchemaValidator(const json& j) : json(j) {}
// 链式调用 类型检查
SchemaValidator& checkType(const string& type) {
if (this->type_name() != type) {
// 直接抛出
// 如果类型不匹配,抛出异常并提示期望的类型
throw runtime_error("类型错误: 期望类型为 " + type);
}
return *this;
}
// 链式调用 数值范围检查
SchemaValidator& checkMin(int minNum) {
// 如果当前值是数字且小于最小值,抛出异常并提示错误信息
if (this->is_number() && *this < minNum) {
throw runtime_error("数值过小: 必须 >= " + to_string(minNum));
}
return *this;
}
SchemaValidator& checkEnum(const json& allowedVal) {
// 链式调用 枚举值检查
// 遍历允许的枚举值,检查当前值是否匹配其中之一
bool valid = false;
for (const auto& val : allowedVal) {
if (*this == val)
valid = true;
}
// 如果当前值不在枚举范围内,抛出异常并提示错误信息
if (!valid) {
throw runtime_error("无效的枚举值");
}
return *this;
}
};
/**
* @brief 主函数演示 JSON Schema 校验和数据转换。
*
* 本程序实现了两种 JSON 校验方式:
* 1. 使用 `validateSchema` 函数进行手动校验。
* 2. 使用自定义的 `SchemaValidator` 类,通过链式调用进行校验。
*
* 主要步骤:
* – 定义用于校验的 JSON Schema。
* – 根据 Schema 校验输入的 JSON 数据。
* – 将校验通过的 JSON 数据转换为 `SchemaValidator` 对象,并对字段进行进一步校验。
*
* – 修正了 try 块中 `SchemaValidator validatedData` 的冗余声明。
* 将 `SchemaValidator validatedData(inputData);` 替换为正确的初始化,
* 避免重复声明并确保 `SchemaValidator` 对象的正确使用。
*
* @param argc 命令行参数的数量。
* @param argv 命令行参数的数组。
* @return int 程序的退出状态。
*/
int main(int argc, char const *argv[])
{
// 定义Schema(可以动态加载)
json schema = R"({
"type": "object",
"properties": {
"name": {"type": "string"},
"age": {"type": "number", "minimum": 0},
"status": {"enum": ["active", "inactive"]}
},
"required": ["name", "status"]
})"_json;
// 需要验证的数据
json testData = R"({
"name": "Stephen Curry",
"age": 37,
"status": "active"
})"_json;
// 手动校验 代码段
string errorMsg;
if(!validateSchema(testData, schema, errorMsg)) {
cerr << "[手动校验] 失败:" << errorMsg << endl;
} else {
cout << "[手动校验] 通过!" << endl;
}
// ————– 方法2:扩展类校验 ————–
// SchemaValidator validatedData(inputData); // 将数据转换为扩展类
try {
SchemaValidator data = testData; // 将数据转换为扩展类
// 逐字段链式校验
/**
* 不明白的点是: data 的类型是 SchemaValidator
* 但是还需要将 data["name"] 的类型 转换成 SchemaValidator 才能调用check方法
* SchemaValidator 继承自nlohmann::json,但当访问data["name"]时,返回的是 nlohmann::json 的引用,而非SchemaValidator的引用,因此需要显式转换才能调用自定义的校验方法。
* 两种解决方法:
* 1. 重载[]
* 2. 显示转换
*/
// 2. 显式转换
// static_cast<SchemaValidator&>(data["name"]).checkType("string");
// static_cast<SchemaValidator&>(data["age"]).checkType("number").checkMin(0);
// static_cast<SchemaValidator&>(data["status"]).checkEnum({"active", "inactive"});
// 1. 重载
// 链式调用(无需显式转换)
// 此处的都是 (const char [5]) 类型 所以重载传参要传 const char* key
// SchemaValidator& operator[](const char* key)
data["name"].checkType("string");
data["age"].checkType("number").checkMin(0);
data["status"].checkEnum({"active", "inactive"});
cout << "[扩展类校验] 成功!" << endl;
} catch (const exception &exception) {
cerr << "[扩展类校验] 失败: " << exception.what() << endl;
}
return 0;
}
我们将main中的年龄改成负数
会得到:

改成正常数字,自然就是:

我们首先定义了要验证的JSON数据和一个JSON Schema。
通过手动实现和继承json添加自定义方法 验证器来对数据进行验证,并捕获可能的验证异常。
验证的效率与准确性
一、效率影响因素
Schema 的复杂度
数据规模
二、准确性影响因素
Schema 的完善性
数据规范性
校验策略
C++11及以上特性应用
C++11 引入多个特性,更加方便易于处理JSON对象
自动类型推导
C++11 引入了 auto 关键字,允许编译器自动推断变量的类型。JSON的结构往往是动态且复杂的,使用 auto 可以让代码更加简洁。
Lambda与JSON处理
Lambda表达式是C++11的另一个强大的特性。它允许定义匿名函数,非常适合于JSON数据处理。
还是来看代码:
#include <vector>
#include <iostream>
#include <string>
#include <nlohmann/json.hpp>
using json = nlohmann::json;
using namespace std;
// 自定义结构体
struct User
{
string name;
int age;
vector<string> addr;
};
int main(int argc, char const *argv[])
{
User user{"Lzj", 20, {"Yibin", "Chengdu"}};
// lambda 来实现序列化
/**
* 报错日志
* 没有与参数列表匹配的 重载函数 "nlohmann::json_abi_v3_11_3::basic_json<ObjectType, ArrayType, StringType, BooleanType, NumberIntegerType, NumberUnsignedType, NumberFloatType, AllocatorType, JSONSerializer, BinaryType, CustomBaseClass>::update [其中 ObjectType=std::map, ArrayType=std::vector, StringType=std::string, BooleanType=bool, NumberIntegerType=int64_t, NumberUnsignedType=uint64_t, NumberFloatType=double, AllocatorType=std::allocator, JSONSerializer=nlohmann::json_abi_v3_11_3::adl_serializer, BinaryType=std::vector<uint8_t, std::allocator<uint8_t>>, CustomBaseClass=void]" 实例C/C++(304)
*/
// auto serializeUser = [](const User& u) -> json {
// return json{
// {"name", u.name},
// {"age", u.age},
// {"addr", json::array()} // 初始化的空数组
// }.update([&u](json& j) {
// // lambda 来动态填充初始化的空数组 也就是addr
// for (const auto& address : u.addr)
// j["addr"].push_back(address);
// });
// };
auto serializeUser = [](const User& u) -> json {
return json{
{"name", u.name},
{"age", u.age},
{"addr", u.addr} // 直接赋值 vector<string> → JSON 数组
};
};
// 序列化之后输出
json userJson = serializeUser(user);
cout << "序列化结果: \\n" << userJson.dump(2) << endl;
return 0;
}
运行出来就是:
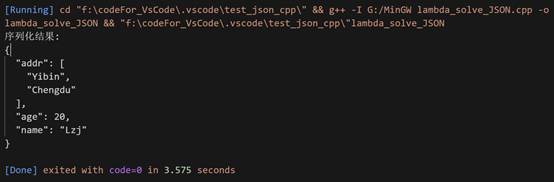
优势也十分明显:
消除中间变量:不需要通过函数参数传递 json 对象
避免数据拷贝:按引用捕获结构体成员(隐式使用 const User&),性能也得到提升
并发与JSON数据处理
我们在多线程下,实现JSON数据处理
借助于线程,原子操作,加锁等并发控制机制结合JSON处理库
来看代码:
#include <nlohmann/json.hpp>
#include <iostream>
#include <vector>
#include <thread>
#include <mutex>
#include <shared_mutex>
#include <atomic>
#include <memory>
using namespace std;
using json = nlohmann::json;
/**
* 原子操作可以用来安全地更新计数器,这样避免了互斥锁的开销,适合简单的计数场景。
*/
// 原子操作计数器(无锁设计)
atomic<int> processed_count{0};
atomic<int> error_count{0};
// 智能指针管理共享数据 确保线程安全
struct SharedData {
shared_ptr<json> dataSets; // 共享JSON数据集合
shared_mutex rw_mutex; // 读写锁控制
};
using SharedDataPtr = shared_ptr<SharedData>;
// 模板结构体的typedef
// 处理线程 (包含智能指针与锁机制)
void process_chunk(SharedDataPtr data, size_t start, size_t end) {
try {
// 读锁 共享访问,确保在读取数据时不会被其他线程修改
{
// 读锁的生命周期开始
shared_lock lock(data->rw_mutex);
if (!data->dataSets || data->dataSets->empty())
throw runtime_error("JSON数据集合为空"); // 如果数据为空,抛出异常
// 读锁的生命周期结束
}
// 创建线程局部的处理副本,使用 unique_ptr 确保独占资源
auto local_json = make_unique<json>();
{
// 读锁的生命周期开始
shared_lock lock(data->rw_mutex);
// 深拷贝共享数据到线程局部副本,确保线程安全
// 这里使用深拷贝是为了避免线程之间共享同一份数据,
// 从而防止在处理过程中出现数据竞争或不一致的问题。
// 每个线程都拥有自己的独立副本,可以安全地进行修改或读取。
*local_json = *data->dataSets;
// 读锁的生命周期结束
}
// 遍历指定范围内的 JSON 数据
for (size_t i = start; i < end; i++) {
// 修改数据时需要获取写锁,确保互斥访问
{
// 写锁的生命周期开始
unique_lock lock(data->rw_mutex);
auto& entry = (*data->dataSets)[i];
entry["processed"] = true; // 标记数据为已处理
// 写锁的生命周期结束
}
// 使用原子操作更新处理计数器,避免竞争条件
processed_count.fetch_add(1, memory_order_relaxed);
}
} catch (const exception& e) {
// 捕获异常并使用原子操作更新错误计数器
error_count.fetch_add(1);
}
}
int main(int argc, char const *argv[])
{
// 初始化共享数据 使用智能指针
SharedDataPtr shared_data = make_shared<SharedData>();
shared_data->dataSets = make_shared<json>(json::parse(R"([{"id": 1}, {"id": 2}, {"id": 3}, {"id": 4}])"));
// 线程池 启动
/**
* inline unsigned int thread::hardware_concurrency() noexcept { return 0; }
*/
const auto thread_num = thread::hardware_concurrency();
vector<thread> workers;
const size_t chunk_size = shared_data->dataSets->size() / thread_num;
for (size_t i = 0; i < thread_num; i++)
{
const size_t start = i * chunk_size;
const size_t end = (i == thread_num – 1) ? shared_data->dataSets->size() : start + chunk_size;
workers.emplace_back(process_chunk, shared_data, start, end);
}
// 等待线程全部完成
for (auto& tmp : workers)
tmp.join();
// 打印到控制台
cout << "已处理: " << processed_count
<< " 项, 错误: " << error_count << " 项" << endl;
cout << "最终的 JSON 数据:\\n" << shared_data->dataSets->dump(2) << endl;
return 0;
}
运行效果如图:
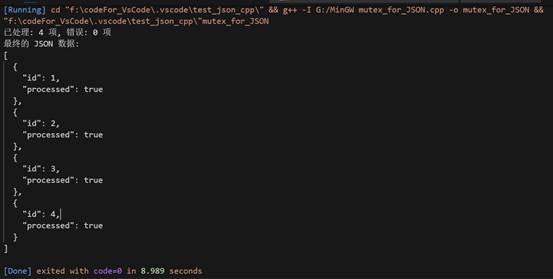
这段代码实现了一个多线程并行处理JSON数据的程序,结合了现代C++的并发控制机制和JSON库的高效处理能力。这个实现典型适用于需要高吞吐量处理结构化数据的场景(如日志分析、批量数据转换等),通过并发处理机制可以显著提升处理效率。
SUMMARY
通过整合JSON Schema的强类型验证体系与C++11的现代化语言特性,能够显著提升JSON数据处理的可靠性和执行效率。
结构化数据验证机制
JSON Schema通过定义严格的字段类型、格式约束和业务规则,结合C++的编译时类型检查,形成双重数据校验屏障。通过JSON Schema可自动拦截缺失必填字段或类型不符的请求,而C++11的static_assert等特性能在编译阶段提前发现潜在类型错误。
高性能并发处理能力
利用C++11的线程库和原子操作,配合JSON库的多线程优化设计(,可实现JSON数据的并行化处理。典型场景包括:通过std::async异步处理大规模JSON数据集,或使用读写锁(shared_mutex)实现高吞吐量的实时数据流解析。
开发效率提升策略
C++11的自动类型推导(auto)和Lambda表达式,结合JSON Schema的自动化测试框架,可减少样板代码量。例如使用nlohmann::json库时,通过auto推导复杂JSON结构,配合Schema验证器的预定义规则,能快速构建健壮的数据管道。
安全增强机制
JSON Schema的格式验证(如正则表达式约束)可防范非法数据注入,而C++11的智能指针(shared_ptr)和移动语义则有效避免内存泄漏。在数据反序列化过程中,这种组合能实现网络协议层到内存管理的全链路安全保障。
附录
安装包






评论前必须登录!
注册