 网硕互联帮助中心
网硕互联帮助中心一、长短链接
1、短连接
对于短链接,在写完这个项目的理解是这样的,对于发给后端的每一个请求都有一个新建socket,当完成前端和后端的通信或者断开时即可给这个socket关闭。还有写的过程中查询资料室知的一些知识点。
(1)短链接的优点
a.对于服务器的资源占用较少
b.相对长连接实现起来相对简单
c.服务器不需要记录用户端的状态
(2)短链接的缺点
a.会频繁的和后端建立链接,断开连接
b.延迟高,不利于实时通信
c.不适用于高并发,很消耗后端的CPU和内存
(3)短链接的应用场景
a.低频请求
b.无状态服务(包括静态资源请求下载,登录注册忘记密码)
c.高安全性要求(银行等交易场所,避免信息被盗窃)
以下就是短链接的基本实现代码
用户端
import java.io.*;
import java.net.Socket;
public class ShortConnectionClient {
public static void main(String[] args) {
String serverAddress = "localhost";
int port = 8080;
try {
// 每次请求都创建新的Socket连接
Socket socket = new Socket(serverAddress, port);
// 获取输出流,向服务器发送数据
PrintWriter out = new PrintWriter(socket.getOutputStream(), true);
out.println("Hello Server!");
// 获取输入流,读取服务器响应
BufferedReader in = new BufferedReader(
new InputStreamReader(socket.getInputStream()));
String response = in.readLine();
System.out.println("Server response: " + response);
// 关闭连接
socket.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
后端接收
import java.io.*; import java.net.ServerSocket; import java.net.Socket;
public class ShortConnectionServer { public static void main(String[] args) { int port = 8080; try (ServerSocket serverSocket = new ServerSocket(port)) { System.out.println("Server started on port " + port); while (true) { // 接受客户端连接(每次都是新的连接) Socket clientSocket = serverSocket.accept(); System.out.println("Client connected: " + clientSocket.getInetAddress()); // 处理客户端请求 handleClient(clientSocket); } } catch (IOException e) { e.printStackTrace(); } } private static void handleClient(Socket clientSocket) { try ( BufferedReader in = new BufferedReader( new InputStreamReader(clientSocket.getInputStream())); PrintWriter out = new PrintWriter(clientSocket.getOutputStream(), true) ) { // 读取客户端消息 String message = in.readLine(); System.out.println("Received from client: " + message); // 发送响应 out.println("Hello Client! Your message: " + message); // 关闭连接(短链接特点) clientSocket.close(); } catch (IOException e) { e.printStackTrace(); } } }
观了别人写的代码后我自己又突然有了想法,是不是后端可以有多个端口,负责不同的业务,于是我进行了查询,以下便是我的理解。
后端多端口
对于后端多个端口,每个端口都有自己负责的业务,可以有短链接请求端口,长连接建立端口,以及资源等其他业务请求端口。
(1)优点
a.业务需求多样化
b.性能优化
c.安全性 && 隔离
2.长连接
对于长连接,我的理解是当用户登录之后进入了主界面时,长连接也要建立了,而建立长连接,则是通过前端和后端while循环来建立,源源不断的看是否有请求的传递。
(1)长连接的优点
a.减少连接建立和断开的开销
b.适合频繁通信的场景
c.保持会话状态
d.更快的响应速度
(2)长连接的缺点
a.占用服务器资源
b.需要心跳机制维护
c.网络环境适应性较
d.复杂性较高
(3)长连接的应用场景
a.实时通信(qq,微信这种聊天软件等)
b.高频短数据交互
c.数据库/缓存连接池
d.API网关/微服务通信
长连接基本代码实现
用户端
import java.io.*; import java.net.*; import java.util.concurrent.*;
public class LongConnectionClient { private static final String HOST = "localhost"; private static final int PORT = 8888; private static final ScheduledExecutorService scheduler = Executors.newScheduledThreadPool(1);
public static void main(String[] args) { try { Socket socket = new Socket(HOST, PORT); socket.setSoTimeout(5000); // 设置读取超时 PrintWriter out = new PrintWriter(socket.getOutputStream(), true); BufferedReader in = new BufferedReader( new InputStreamReader(socket.getInputStream())); // 发送业务消息 for (int i = 0; i < 5; i++) { String message = "业务消息_" + i; out.println(message); String response = in.readLine(); System.out.println("收到响应:" + response); Thread.sleep(2000); } // 关闭连接 scheduler.shutdown(); socket.close(); } catch (Exception e) { e.printStackTrace(); } }
private static void startHeartbeat(PrintWriter out) { // 每10秒发送一次心跳 scheduler.scheduleAtFixedRate(() -> { try { out.println("HEARTBEAT"); System.out.println("发送心跳"); } catch (Exception e) { e.printStackTrace(); } }, 0, 10, TimeUnit.SECONDS); } }
服务器
import java.io.*; import java.net.*; import java.util.concurrent.*;
public class LongConnectionServer { private static final int PORT = 8888; private static final int MAX_THREADS = 100; private static final ExecutorService threadPool = Executors.newFixedThreadPool(MAX_THREADS);
public static void main(String[] args) { try (ServerSocket serverSocket = new ServerSocket(PORT)) { System.out.println("长连接服务端启动,监听端口:" + PORT); while (true) { Socket clientSocket = serverSocket.accept(); // 设置读写超时时间(毫秒) clientSocket.setSoTimeout(30000); // 长连接线程 threadPool.execute(new ClientHandler(clientSocket)); } } catch (IOException e) { e.printStackTrace(); } }
static class ClientHandler implements Runnable { private final Socket socket; private long lastHeartbeatTime;
public ClientHandler(Socket socket) { this.socket = socket; this.lastHeartbeatTime = System.currentTimeMillis(); }
@Override public void run() { try (BufferedReader in = new BufferedReader( new InputStreamReader(socket.getInputStream())); PrintWriter out = new PrintWriter( socket.getOutputStream(), true)) { System.out.println("客户端连接:" + socket.getRemoteSocketAddress());
String inputLine; while ((inputLine = in.readLine()) != null) { // 心跳检测 if ("HEARTBEAT".equals(inputLine)) { lastHeartbeatTime = System.currentTimeMillis(); out.println("HEARTBEAT_ACK"); continue; } // 处理业务逻辑 System.out.println("收到消息:" + inputLine); String response = "处理结果:" + inputLine; out.println(response); // 检查连接是否超时(30秒无心跳) if (System.currentTimeMillis() – lastHeartbeatTime > 30000) { System.out.println("连接超时,关闭连接"); break; } } } catch (SocketTimeoutException e) { System.out.println("读取超时,关闭连接"); } catch (IOException e) { e.printStackTrace(); } finally { try { socket.close(); System.out.println("连接关闭:" + socket.getRemoteSocketAddress()); } catch (IOException e) { e.printStackTrace(); } } } } }
二、序列化
1.序列化是将对象转换为字节流的过程,以便存储或传输;
2.反序列化则是将字节流恢复为对象。它在分布式系统、数据持久化和网络通信中起着关键作用。
3. 序列化的核心作用
(1)对象持久化(存储到文件/数据库)
-
将内存中的对象保存到磁盘,程序重启后可恢复。
-
示例:游戏存档、用户会话保存。
(2)网络传输(跨进程/跨机器通信)
-
对象 → 字节流 → 网络传输 → 字节流 → 对象。
-
示例:RPC调用、微服务通信。
(3)深拷贝(Deep Copy)
-
通过序列化/反序列化实现对象的完全复制。
-
示例:避免Java的浅拷贝问题。
(4)跨语言数据交换
-
通用序列化格式(如JSON、Protocol Buffers)支持不同语言解析。
-
示例:Java服务与Python客户端通信。
4. 序列化的核心意义
(1)解决对象传输问题
-
网络只能传输字节流,序列化是对象传输的基础。
(2)实现分布式系统通信
-
微服务、RPC、消息队列(如Kafka)依赖序列化传递对象。
(3)保证数据一致性
-
序列化协议定义了数据的编码规则,避免解析错误。
(4)提高系统扩展性
-
通过版本兼容的序列化协议(如Protobuf),支持字段动态增减。
四、IO流
在项目中,IO流主要用于文件读写和网络数据传输,核心使用了以下类:
1. 字节流(Byte Streams)
FileInputStream`/`FileOutputStream 用于读写二进制文件(如图片、视频)。
// 读取文件 try (FileInputStream fis = new FileInputStream("file.bin")) { byte[] buffer = new byte[1024]; int bytesRead; while ((bytesRead = fis.read(buffer)) != -1) { // 处理数据 } }
// 写入文件 try (FileOutputStream fos = new FileOutputStream("output.bin")) { fos.write(dataBytes); }
2. 字符流(Character Streams)
BufferedReader`/`BufferedWriter
// 读取文本文件 try (BufferedReader br = new BufferedReader(new FileReader("config.txt"))) { String line; while ((line = br.readLine()) != null) { System.out.println(line); } }
// 写入文本文件 try (BufferedWriter bw = new BufferedWriter(new FileWriter("log.txt"))) { bw.write("Log message"); bw.newLine(); }
3. 对象流(Object Streams)
ObjectInputStream`/`ObjectOutputStream 用于序列化和反序列化Java对象(如用户数据持久化)。
// 序列化对象到文件 try (ObjectOutputStream oos = new ObjectOutputStream( new FileOutputStream("user.dat"))) { oos.writeObject(user); }
// 从文件反序列化对象 try (ObjectInputStream ois = new ObjectInputStream( new FileInputStream("user.dat"))) { User user = (User) ois.readObject(); }
4. 网络IO(Socket流)
Socket.getInputStream()`/`Socket.getOutputStream() 用于网络通信,结合`BufferedReader`和`PrintWriter`处理文本协议。
// 服务端读取客户端数据 try (BufferedReader in = new BufferedReader( new InputStreamReader(socket.getInputStream()))) { String message = in.readLine(); }
// 客户端发送数据到服务端 try (PrintWriter out = new PrintWriter( socket.getOutputStream(), true)) { out.println("Hello Server!"); }
五、多线程在项目中的应用
多线程主要用于并发处理客户端请求和异步任务。
1. 线程池管理
ExecutorService 避免频繁创建/销毁线程,提升性能。
ExecutorService threadPool = Executors.newFixedThreadPool(10); threadPool.execute(() -> { // 处理客户端请求 });
2. 线程同步
synchronized`关键字 保护共享资源(如数据库连接池)。
public synchronized void updateData() { // 线程安全操作 }
六、文件分片上传/下载
通过IO流实现大文件的分块处理。
1. 文件分片上传
// 客户端分片发送 try (FileInputStream fis = new FileInputStream("large_file.zip"); BufferedInputStream bis = new BufferedInputStream(fis)) { byte[] buffer = new byte[1024 * 1024]; // 1MB分片 int bytesRead; while ((bytesRead = bis.read(buffer)) != -1) { socket.getOutputStream().write(buffer, 0, bytesRead); } }
2. 服务端分片接收
try (FileOutputStream fos = new FileOutputStream("received_file.zip"); BufferedOutputStream bos = new BufferedOutputStream(fos)) { byte[] buffer = new byte[1024 * 1024]; int bytesRead; while ((bytesRead = socket.getInputStream().read(buffer)) != -1) { bos.write(buffer, 0, bytesRead); } }
七、MySQL数据库操作
使用JDBC进行CRUD操作。
1. 数据库连接
String url = "jdbc:mysql://localhost:3306/mydb"; String user = "root"; String password = "123456"; try (Connection conn = DriverManager.getConnection(url, user, password)) { // 执行SQL }
2. 查询数据
String sql = "SELECT * FROM users WHERE id = ?"; try (PreparedStatement stmt = conn.prepareStatement(sql)) { stmt.setInt(1, 1001); ResultSet rs = stmt.executeQuery(); while (rs.next()) { String name = rs.getString("name"); } }
3. 插入/更新数据
String sql = "INSERT INTO users (name, age) VALUES (?, ?)"; try (PreparedStatement stmt = conn.prepareStatement(sql)) { stmt.setString(1, "Alice"); stmt.setInt(2, 25); stmt.executeUpdate(); }
总结
| 技术 | 在项目中的应用 | |————-|——————————————————————| | IO流 | 文件读写、网络数据传输、对象序列 | | 多线程 | 并发处理客户端请求任务执行 | | 文件分片 | 大文件的上传与下载 | | MySQL | 用户数据存储、查询和更新 | | JavaFX | 构建图形界面,与后端Socket/数据库交互 |
通过结合这些技术,项目实现了:
1.客户端与服务端的稳定通信(长短链接结合) 2.高效文件传输(分片处理) 3.数据持久化(MySQL + 序列化) 4.用户友好的图形界面(JavaFX)
一、算法题
1.

解题思路:正常的并查集,加一个map来实现string->int即可
#include <iostream>
#include <vector>
#include <stack>
#include <queue>
#include <climits>
#include <algorithm>
#include <map>
#define ll long long
using namespace std;
int n, m, p;
int find(int x, vector<int>& parent) {
if (parent[x] != x)
parent[x] = find(parent[x], parent);
return parent[x];
}
void setUnion(int a, int b, vector<int>& parent, vector<int>& rank) {
a = find(a,parent);
b = find(b,parent);
if (a == b)
return;
int x1 = min(a, b);
int x2 = max(a, b);
if (rank[x1] > rank[x2])
parent[x2] = x1;
else if (rank[x1] < rank[x2])
parent[x2] = x1;
else {
parent[x1] = x2;
rank[x2]++;
}
}
bool isConnect(int a, int b, vector<int>& parent) {
a = find(a, parent);
b = find(b, parent);
return a == b;
}
int main() {
cin >> n >> m;
vector<int>parent(n + 1, 0); // 节点的上一级
map<string,int> tt;
vector<int>rank(n + 1, 0); // 建立最小的树
for (int i = 1; i <= n; i++) { // 先指向自身
parent[i] = i;
string s; cin >> s;
tt[s] = i;
}
for (int i = 1; i <= m; i++) { // 建立亲戚关系
string a, b; cin >> a >> b;
int x1 = tt[a], x2 = tt[b];
setUnion(x1, x2, parent, rank);
}
cin >> p;
for (int i = 1; i <= p; i++) {
string a, b; cin >> a >> b;
int x1 = tt[a], x2 = tt[b];
if (isConnect(x1, x2, parent))
cout << "Yes." << endl;
else
cout << "No." << endl;
}
return 0;
}
2.
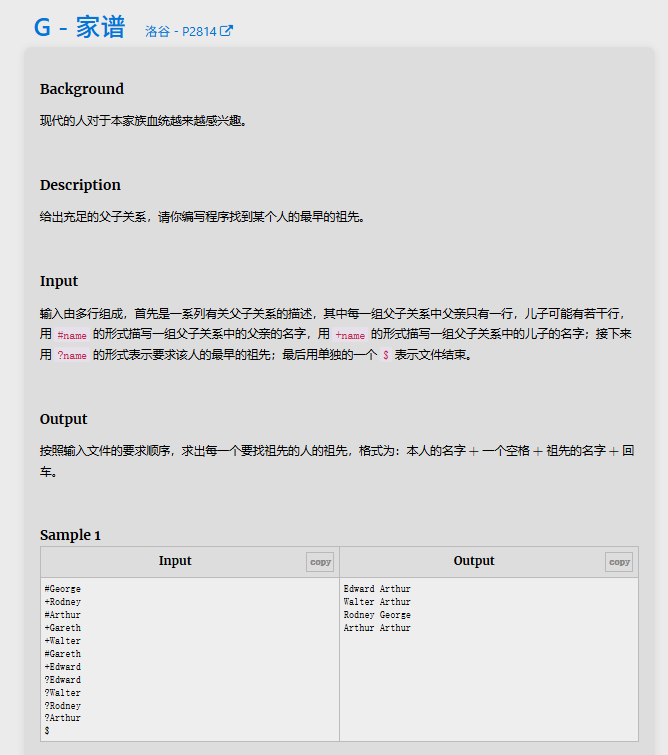
解题思路: 并查集,限定了合并条件,根据题目的合并条件合成即可
#include <iostream>
#include <vector>
#include <stack>
#include <queue>
#include <climits>
#include <algorithm>
#include <map>
#define ll long long
using namespace std;
map<string, string> parent;
// 查找并返回name的最早祖先,并进行路径压缩
string findAncestor(string name) {
if (name != parent[name]) {
parent[name] = findAncestor(parent[name]);
}
return parent[name];
}
int main() {
char prefix;
string name;
string current_parent;
cin >> prefix;
while (prefix != '$') {
cin >> name;
if (prefix == '#') {
current_parent = name;
if (parent.find(name) == parent.end()) {
parent[name] = name; // 初始化父亲为自身
}
} else if (prefix == '+') {
parent[name] = current_parent;
} else if (prefix == '?') {
cout << name << ' ' << findAncestor(name) << endl;
}
cin >> prefix;
}
return 0;
}
3.

解题思路:把题目看成图,每个点都是顶点,距离都是权重,就可以用kruskal了。
#include <iostream>
#include <algorithm>
#include <vector>
#include <cmath>
#include <iomanip>
using namespace std;
struct Edge {
int u, v;
double w;
bool operator<(const Edge& other) const {
return w < other.w;
}
};
vector<Edge> edges;
vector<int> parent;
int S, P;
vector<pair<int, int>> d;
int find(int x) {
if (parent[x] != x) {
parent[x] = find(parent[x]);
}
return parent[x];
}
void unionset(int x, int y) {
int rootX = find(x);
int rootY = find(y);
if (rootX != rootY) {
parent[rootY] = rootX;
}
}
double kruskal() {
parent.resize(P + 1);
for (int i = 1; i <= P; i++) {
parent[i] = i;
}
sort(edges.begin(), edges.end());
double ans = 0.0;
int k = P – S;
for (const auto& edge : edges) {
if (find(edge.u) != find(edge.v)) {
unionset(edge.u, edge.v);
ans = edge.w;
k–;
if (k == 0) {
break;
}
}
}
return ans;
}
int main() {
cin >> S >> P;
d.resize(P + 1);
for (int i = 1; i <= P; i++) {
cin >> d[i].first >> d[i].second;
}
for (int i = 1; i <= P; i++) {
for (int j = i + 1; j <= P; j++) {
double dx = d[i].first – d[j].first;
double dy = d[i].second – d[j].second;
double dis = sqrt(dx * dx + dy * dy);
edges.push_back({ i, j, dis });
}
}
double ans = kruskal();
cout << fixed << setprecision(2) << ans << endl;
return 0;
}
4.
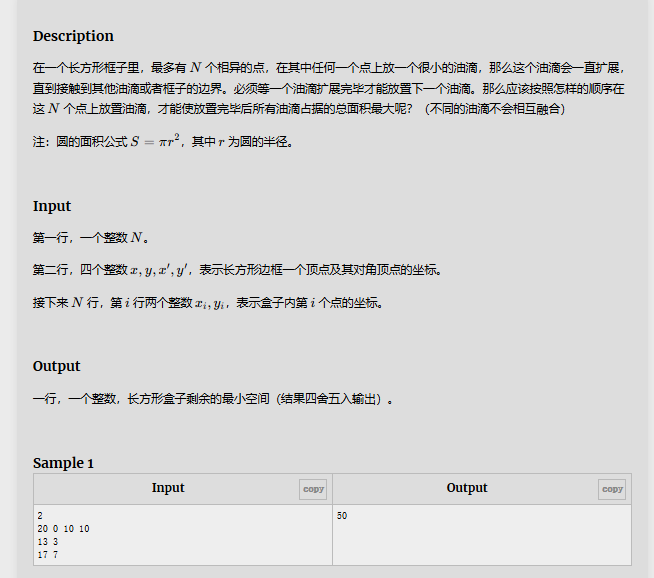
解题思路:开始想了好久,发现N<=6,这个数量好像可以直接遍历所有的情况来讨论,但是对于面积的计算还是有点迷,就看了下别人的思路。让放下的油滴尽可能的扩大,相加所有的面积,每次枚举都取面积的最大值
#include <iostream>
#include <vector>
#include <cmath>
#include <algorithm>
#include <iomanip>
using namespace std;
double area(int N, const vector<pair<int, int>>& points, int left, int right, int bottom, int top) {
double max_total_area = 0.0;
vector<int> indices(N);
for (int i = 0; i < N; ++i) {
indices[i] = i;
}
do {
vector<double> radii(N, 0.0);
double total_area = 0.0;
for (int i = 0; i < N; ++i) {
int x = points[indices[i]].first;
int y = points[indices[i]].second;
double min_r = min({x – left, right – x, y – bottom, top – y});
for (int j = 0; j < i; ++j) {
int xj = points[indices[j]].first;
int yj = points[indices[j]].second;
double dx = x – xj;
double dy = y – yj;
double distance = sqrt(dx * dx + dy * dy);
min_r = min(min_r, distance – radii[j]);
if (min_r <= 0) break;
}
if (min_r > 0) {
radii[i] = min_r;
total_area += M_PI * min_r * min_r;
}
}
if (total_area > max_total_area) {
max_total_area = total_area;
}
} while (next_permutation(indices.begin(), indices.end()));
double area_rect = (right – left) * (top – bottom);
return area_rect – max_total_area;
}
int main() {
int N;
cin >> N;
int x1, y1, x2, y2;
cin >> x1 >> y1 >> x2 >> y2;
int left = min(x1, x2);
int right = max(x1, x2);
int bottom = min(y1, y2);
int top = max(y1, y2);
vector<pair<int, int>> points(N);
for (int i = 0; i < N; ++i) {
cin >> points[i].first >> points[i].second;
}
sort(points.begin(), points.end());
double remaining_area = area(N, points, left, right, bottom, top);
cout << static_cast<int>(round(remaining_area)) << endl;
return 0;
}
5.
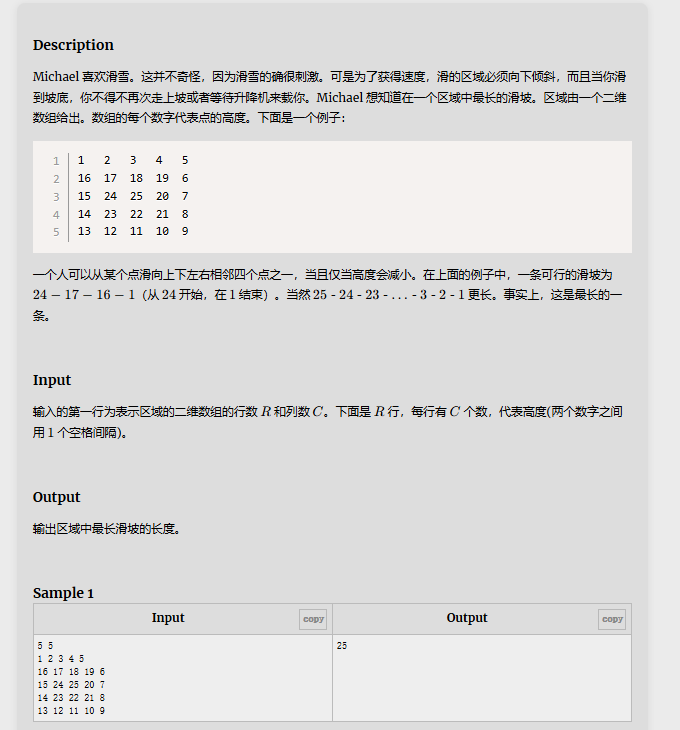
解题思路:第一次写这种题,我最开始就是直接用dfs来搜索,但是时间超限,然后我看了一下别人的思路,可以用个二维数组存储已经知道的每个的位置的最大值,当dfs到这个位置,直接从二维数组里取出来就行了,这个方法也是记忆化搜索
#include <iostream>
#include <vector>
#include <stack>
#include <queue>
#include <climits>
#include <algorithm>
#include <map>
#define ll long long
using namespace std;
// 定义四个方向
int dirs[4][2] = {{-1, 0}, {1, 0}, {0, -1}, {0, 1}};
// 全局变量存储矩阵和dp数组
vector<vector<int>> matrix;
vector<vector<int>> dp;
int R, C;
// DFS函数,返回从(x, y)出发的最长滑坡长度
int dfs(int x, int y) {
// 如果已经计算过,直接返回结果
if (dp[x][y] != -1) {
return dp[x][y];
}
// 初始化为1,因为至少可以滑到自己
dp[x][y] = 1;
// 遍历四个方向
for (int i = 0; i < 4; ++i) {
int newX = x + dirs[i][0];
int newY = y + dirs[i][1];
// 检查边界条件和高度是否下降
if (newX >= 0 && newX < R && newY >= 0 && newY < C && matrix[newX][newY] < matrix[x][y]) {
// 递归计算相邻点的最长滑坡长度,并更新当前点的dp值
dp[x][y] = max(dp[x][y], dfs(newX, newY) + 1);
}
}
return dp[x][y];
}
int main() {
// 读取行数和列数
cin >> R >> C;
matrix.assign(R, vector<int>(C));
for (int i = 0; i < R; ++i) {
for (int j = 0; j < C; ++j) {
cin >> matrix[i][j];
}
}
// 初始化dp数组为-1,表示未计算
dp.assign(R, vector<int>(C, -1));
// 遍历所有点,计算最长滑坡长度
int maxLength = 0;
for (int i = 0; i < R; ++i) {
for (int j = 0; j < C; ++j) {
if (dp[i][j] == -1) { // 如果尚未计算
dfs(i, j);
}
maxLength = max(maxLength, dp[i][j]);
}
}
// 输出结果
cout << maxLength << endl;
return 0;
}





评论前必须登录!
注册