 网硕互联帮助中心
网硕互联帮助中心服务器限流方案
本节参考资料:https://blog.csdn.net/XZB119211/article/details/125646060 https://zhuanlan.zhihu.com/p/479956069 https://blog.csdn.net/billgates_wanbin/article/details/123556273
1、固定窗口法
原理

缺点:
假设我们设置了时间窗口为10秒,请求阈值为1000 
- 无法应对流量更突发的场景,比如前1秒就有1000个请求打进来
- 一段时间内(不超过时间窗口)系统服务不可用,系统资源无法充分利用。一旦流量进入速度有所波动,要么计数器会被提前计满,导致这个周期内剩下时间段的请求被限制。要么就是计数器计不满,导致资源无法充分利用。
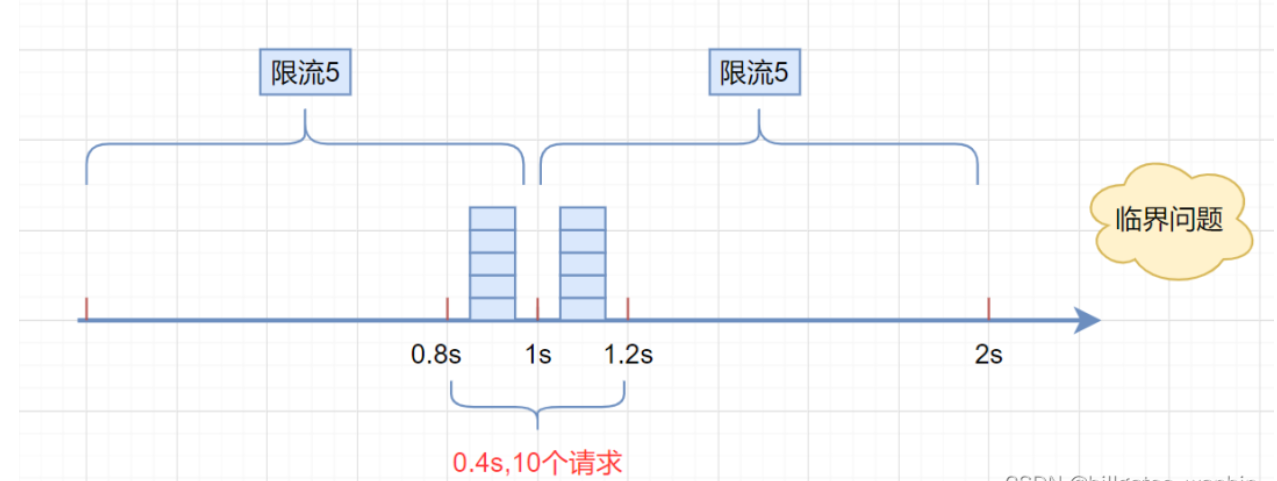
对问题2 也可通过多个窗口 比如1分钟的 和1秒的 来控制
2、滑动窗口法
原理
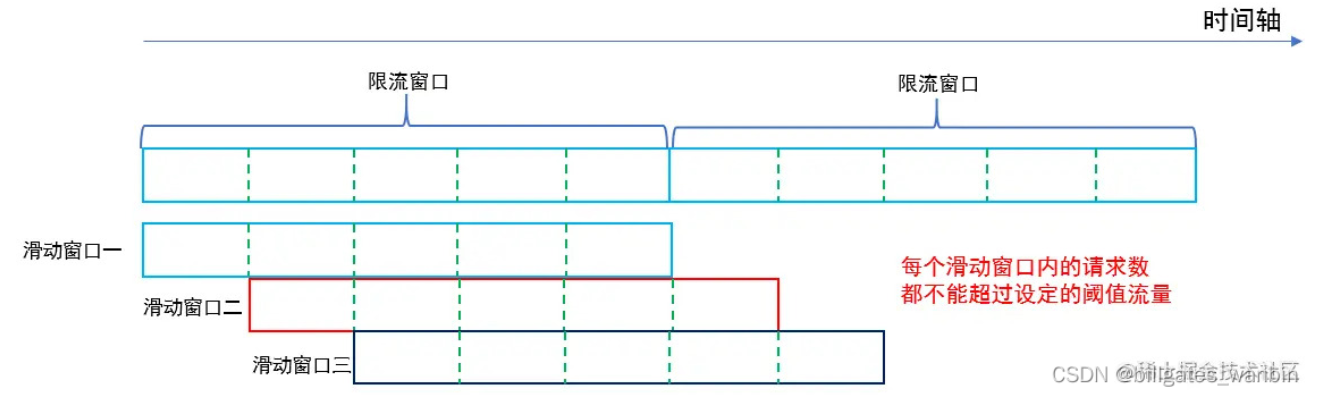
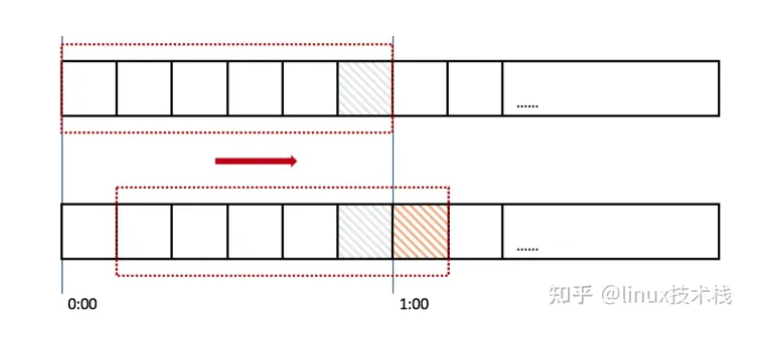 在上图中,整个红色的矩形框表示一个时间窗口,在我们的例子中,一个时间窗口就是一分钟。
在上图中,整个红色的矩形框表示一个时间窗口,在我们的例子中,一个时间窗口就是一分钟。然后我们将时间窗口进行划分,比如图中,我们就将滑动窗口划成了6格,所以每格代表的是10秒钟。每过10秒钟,我们的时间窗口就会往右滑动一格。
每一个格子都有自己独立的计数器counter,比如当一个请求 在0:35秒的时候到达,那么0:30~0:39对应的counter就会加1。
缺点:
早期的网络通信中,通信双方不会考虑网络的 拥挤情况直接发送数据。由于大家不知道网络拥塞状况,同时发送数据,导致中间节点阻塞掉包, 谁也发不了数据,所以就有了滑动窗口机制来解决此问题。滑动窗口协议是用来改善吞吐量的一种 技术,即容许发送方在接收任何应答之前传送附加的包。接收方告诉发送方在某一时刻能送多少包 (称窗口尺寸)。 TCP 中采用滑动窗口来进行传输控制,滑动窗口的大小意味着接收方还有多大的缓冲区可以用于 接收数据。发送方可以通过滑动窗口的大小来确定应该发送多少字节的数据。当滑动窗口为 0 时,发送方一般不能再发送数据报。
3、计数器算法
计数器算法是限流算法里最简单也是最容易实现的一种算法。
带计时器的计数器
计数器算法是使用计数器在周期内累加访问次数,当达到设定的限流值时,触发限流策略。下一个周期开始时,进行清零,重新计数。
- 比如我们规定,对于A接口来说,我们1分钟的访问次数不能超过100个。
- 那么我们可以这么做:在一开始的时候,我们可以设置一个计数器counter,每当一个请求过来的时候,counter就加1,如果counter的值大于100并且该请求与第一个 请求的间隔时间还在1分钟之内,那么说明请求数过多;
- 如果该请求与第一个请求的间隔时间大于1分钟,且counter的值还在限流范围内,那么就重置 counter,具体算法的示意图如下:
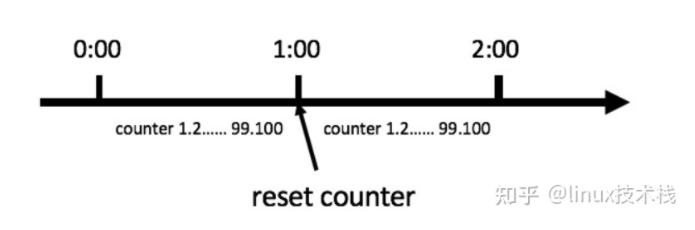
缺点和之前的固定窗口法一样。假设定时器60秒,第一秒1个请求,最后一秒突然很多个请求,然后下一秒又很多个。只是相对固定时间法以用户第一次访问的时间为基准而已。
计数器算法其实就是滑动窗口算法。只是它没有对时间窗口做进一步地划分,所以只有1格。
不带计时器的计数器
例如系统能同时处理100个请求,保存一个计数器,处理了一个请求,计数器加一,一个请求处理完毕之后计数器减一。
每次请求来的时候看看计数器的值,如果超过阈值要么拒绝。
非常的简单粗暴,计数器的值要是存内存中就算单机限流算法。存中心存储里,例如 Redis 中,集群机器访问就算分布式限流算法。
优点就是:简单粗暴,单机在 Java 中可用 Atomic 等原子类、分布式就 Redis incr。
缺点:
- 如果计数器减1操作出问题,则……
- 假设我们允许的阈值是1万,此时计数器的值为0, 当1万个请求在前1秒内一股脑儿的都涌进来,这突发的流量可是顶不住的。缓缓的增加处理和一下子涌入对于程序来说是不一样的。
4、漏桶算法
漏桶算法,它可以解决时间窗口类的痛点,使得流量更加的平滑。
原理
漏桶算法思路很简单,请求先进入到漏桶里,漏桶以固定的速度出水,也就是处理请求,当水加的过快,则会直接溢出,也就是拒绝请求,可以看出漏桶算法能强行限制数据的传输速率。
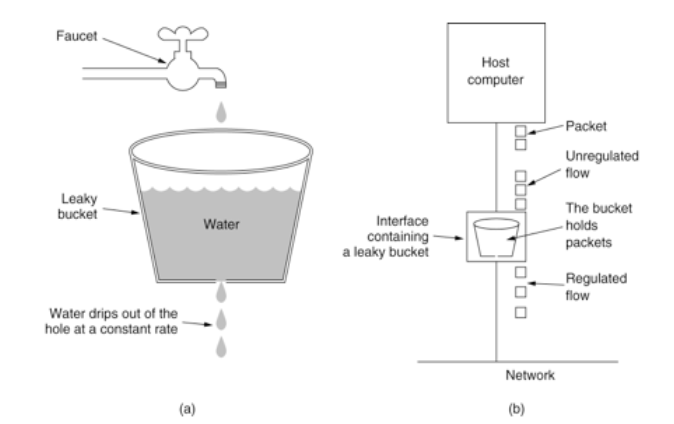
漏洞的容量是有限的,如果将漏嘴堵住,然后一直往里面灌水,它就会变满,直至再也装不进去。 如果将漏嘴放开,水就会往下流,流走一部分之后,就又可以继续往里面灌水。 如果漏嘴流水的速率大于灌水的速率,那么漏斗永远都装不满。 如果漏嘴流水速率小于灌水的速率,那么一旦漏斗满了,灌水就需要暂停并等待漏斗腾空。
所以,漏斗的剩余空间就代表着当前行为可以持续进行的数量,漏嘴的流水速率代表着系统允许该行为的最大频率
缺点:
- 当短时间内有大量的突发请求时,某些情况下,比如即便此时服务器没有任何负载或者网络没有任何的不畅通,每个请求也都得在队列中等待一段时间才能被响应。
漏桶算法和消息队列思想有点像,削峰填谷。经过漏洞这么一过滤,请求就能平滑的流出,看起来很像很挺完美的?实际上它的优点也即缺点。
面对突发请求,服务的处理速度和平时是一样的,这其实不是我们想要的,在面对突发流量我们希望在系统平稳的同时,提升用户体验即能更快的处理请求,而不是和正常流量一样,循规蹈矩的处理
看看,之前滑动窗口说流量不够平滑,现在太平滑了又不行,难搞啊。
对于很多场景来说,除了要求能够限制数据的平均传输速率外,还要求允许某种程度的突发传输。这时候漏桶算法可能就不合适了,令牌桶算法更为适合。
5、令牌桶算法
令牌桶算法的原理是系统会以一个恒定的速度往桶里放入令牌,而如果请求需要被处理,则需要先从桶里获取一个令牌,当桶里没有令牌可取时,则拒绝服务。
从原理上看,令牌桶算法和漏桶算法是相反的,一个“进水”,一个是“漏水”。 令牌桶算法是对漏斗算法的一种改进,除了能够起到限流的作用外,还允许一定程度的流量突发。
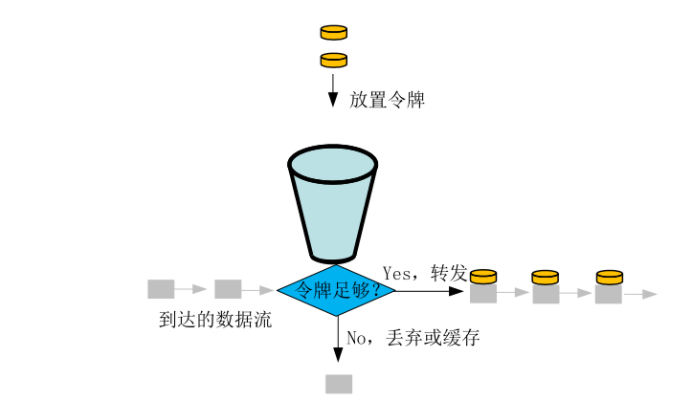
令牌桶算法的描述如下:
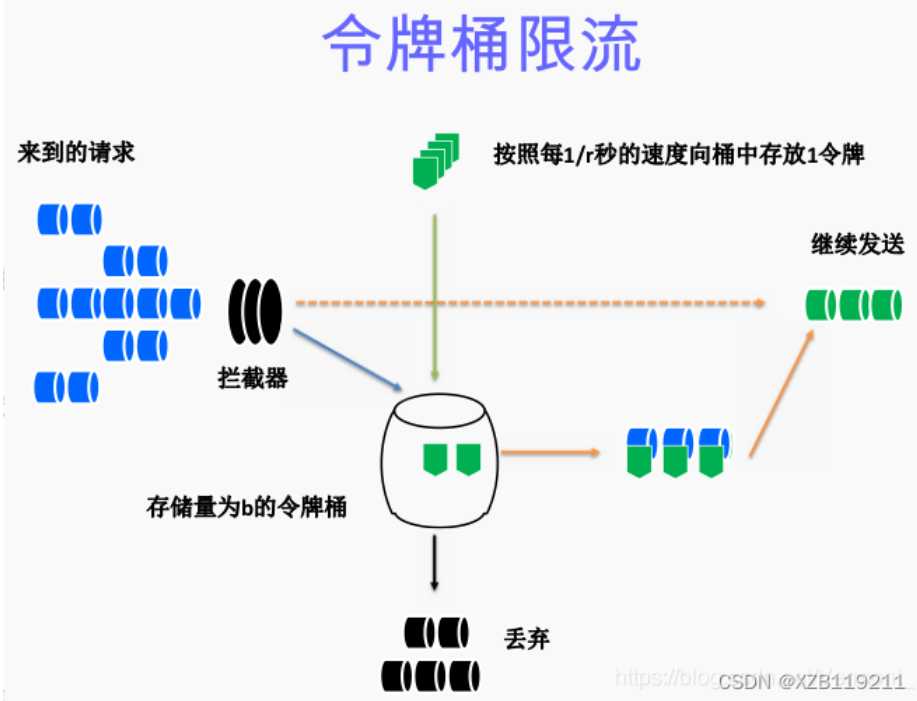
总结:令牌桶算法是比较科学,机制更全面的一个限流算法,放入令牌的速度是一定的,如果短时间有大量请求,令牌桶中的令牌可以支持一下全部用完,这样就解决了漏桶算法的缺点。
虽然也能通过代码实现,但是有人就会怀疑自己写的不靠谱,写在服务里面使用内存这更不靠谱。比如我们无法保证整个过程的原子性。从 hash 结构中取值,然后在 内存里运算,再回填到 hash 结构,这三个过程无法原子化,意味着需要进行适 当的加锁控制。而一旦加锁,就意味着会有加锁失败,加锁失败就需要选择重试 或者放弃。如果重试的话,就会导致性能下降。如果放弃的话,就会影响用户体验。同时, 代码的复杂度也跟着升高很多。这真是个艰难的选择,我们该如何解决这个问题 呢? 救星来了!有没有可以使用的中间件,被人造好的轮子。还真有,redis-cell
总结
固定窗口算法实现简单,性能高,但是会有临界突发流量问题,瞬时流量最大可以达到阈值的2倍。
为了解决临界突发流量,可以将窗口划分为多个更细粒度的单元,每次窗口向右移动一个单元,于是便有了滑动窗口算法。
滑动窗口当流量到达阈值时会瞬间掐断流量,所以导致流量不够平滑。
想要达到限流的目的,又不会掐断流量,使得流量更加平滑?可以考虑漏桶算法!需要注意的是,漏桶算法通常配置一个FIFO的队列使用以达到允许限流的作用。
由于速率固定,即使在某个时刻下游处理能力过剩,也不能得到很好的利用,这是漏桶算法的一个短板。
限流和瞬时流量其实并不矛盾,在大多数场景中,短时间突发流量系统是完全可以接受的。令牌桶算法就是不二之选了,令牌桶以固定的速率v产生令牌放入一个固定容量为n的桶中,当请求到达时尝试从桶中获取令牌。
当桶满时,允许最大瞬时流量为n;当桶中没有剩余流量时则限流速率最低,为令牌生成的速率v。
如何实现更加灵活的多级限流呢?滑动日志限流算法了解一下!这里的日志则是请求的时间戳,通过计算制定时间段内请求总数来实现灵活的限流。
当然,由于需要存储时间戳信息,其占用的存储空间要比其他限流算法要大得多。
限流算法总结 经过上述的描述,好像漏桶、令牌桶比时间窗口类算法好多了,那么时间窗口类算法是不是就没啥用了呢?
其实并不是,虽然漏桶、令牌桶对比时间窗口类算法对流量的整形效果更好,但是它们也有各自的缺点, 例如令牌桶,假如系统上线时没有预热,那么可能会出现由于此时桶中还没有令牌,而导致请求被误杀的情况; 而漏桶中由于请求是暂存在桶中的,所以请求什么时候能被处理,则是有延时的,这并不符合互联网业务低延时的要求。 所以令牌桶、漏桶算法更适合阻塞式限流的场景,即后台任务类的限流。
而基于时间窗口的限流则更适合互联网实施业务限流的场景,即能处理快速处理,不能处理及时响应调用方,避免请求出现过长的等待时间。
微服务限流组件 如果你有兴趣实际上也是可以自己实现一个限流组件的,只不过这种轮子已经早有人造好了。
目前市面上比较流行的限流组件主要有:Google Guava提供的限流工具类“RateLimiter”、阿里开源的Sentinel。
其中Google Guava提供的限流工具类“RateLimiter”,是基于令牌桶实现的,并且扩展了算法,支持了预热功能。
而阿里的Sentinel中的匀速限流策略,就是采用了漏桶算法。
单机限流和分布式限流 本质上单机限流和分布式限流的区别其实就在于 “阈值” 存放的位置。
单机限流就上面所说的算法直接在单台服务器上实现就好了,而往往我们的服务是集群部署的。因此需要多台机器协同提供限流功能。
像上述的计数器或者时间窗口的算法,可以将计数器存放至 Tair 或 Redis 等分布式 K-V 存储中。
例如滑动窗口的每个请求的时间记录可以利用 Redis 的 zset 存储,利用ZREMRANGEBYSCORE 删除时间窗口之外的数据,再用 ZCARD计数。
像令牌桶也可以将令牌数量放到 Redis 中。
不过这样的方式等于每一个请求我们都需要去Redis判断一下能不能通过,在性能上有一定的损耗,所以有个优化点就是 「批量」。例如每次取令牌不是一个一取,而是取一批,不够了再去取一批。这样可以减少对 Redis 的请求。
不过要注意一点,批量获取会导致一定范围内的限流误差。比如你取了 10 个此时不用,等下一秒再用,那同一时刻集群机器总处理量可能会超过阈值。
其实「批量」这个优化点太常见了,不论是 MySQL 的批量刷盘,还是 Kafka 消息的批量发送还是分布式 ID 的高性能发号,都包含了「批量」的思想。
当然分布式限流还有一种思想是平分,假设之前单机限流 500,现在集群部署了 5 台,那就让每台继续限流 500 呗,即在总的入口做总的限流限制,然后每台机子再自己实现限流。
限流的难点 可以看到每个限流都有个阈值,这个阈值如何定是个难点。
定大了服务器可能顶不住,定小了就“误杀”了,没有资源利用最大化,对用户体验不好。
我能想到的就是限流上线之后先预估个大概的阈值,然后不执行真正的限流操作,而是采取日志记录方式,对日志进行分析查看限流的效果,然后调整阈值,推算出集群总的处理能力,和每台机子的处理能力(方便扩缩容)。
然后将线上的流量进行重放,测试真正的限流效果,最终阈值确定,然后上线。
我之前还看过一篇耗子叔的文章,讲述了在自动化伸缩的情况下,我们要动态地调整限流的阈值很难,于是基于TCP拥塞控制的思想,
根据请求响应在一个时间段的响应时间P90或者P99值来确定此时服务器的健康状况,来进行动态限流。
在他的 Ease Gateway 产品中实现了这套算法,有兴趣的同学可以自行搜索。
其实真实的业务场景很复杂,需要限流的条件和资源很多,每个资源限流要求还不一样。所以我上面就是嘴强王者。
限流组件 一般而言我们不需要自己实现限流算法来达到限流的目的,不管是接入层限流还是细粒度的接口限流其实都有现成的轮子使用,其实现也是用了上述我们所说的限流算法。
比如Google Guava 提供的限流工具类 RateLimiter,是基于令牌桶实现的,并且扩展了算法,支持预热功能。
阿里开源的限流框架Sentinel 中的匀速排队限流策略,就采用了漏桶算法。
Nginx 中的限流模块 limit_req_zone,采用了漏桶算法,还有 OpenResty 中的 resty.limit.req库等等。
具体的使用还是很简单的,有兴趣的同学可以自行搜索,对内部实现感兴趣的同学可以下个源码看看,学习下生产级别的限流是如何实现的。






评论前必须登录!
注册