 网硕互联帮助中心
网硕互联帮助中心模板进阶
- 一、非类型模板参数
-
- 1、模板参数的分类
- 2、应用场景
- 3、array
- 4、注意
- 二、模板的特化
-
- 1、概念
- 2、函数模板特化
- 3、类模板特化
-
- (1)、全特化:全部模板参数都特化成具体的类型
- (2)、偏/半特化:部分模板参数特化成具体的类型,还可以是对参数的进一步限制
- (3)、priority_queue中使用类模板特化
- 三、typename的特性
- 四、模板的分离编译
- 五、模板的优缺点
一、非类型模板参数
1、模板参数的分类
- 模板参数分为非类型模板参数和类型模板参数:
类型模板参数:出现在模板参数列表中,跟在class或者typename之后的参数类型名称。我们之前定义的都是类型模板参数。
非类型模板参数:常量作为类(函数)模板的参数,在类(函数)模板中可将该参数当成常量来使用。
2、应用场景
为什么要有非类型模板参数?
例如,定义一个静态的栈。静态栈需要确定大小,假设两个栈分别是10、100个空间,但是静态栈不能同时做到一个是10个,一个是100个,宏常量只能是一个大小;与typedef是一样的道理,只能保证是一个类型。若将N改成100#define N 100,对于第一个栈就浪费了90个空间。
#define N 10
template<class T>
class Stack
{
private:
T _a[N];
size_t _top;
};
int main()
{
Stack<int> st1;// 10
Stack<int> st2;// 100
return 0;
}
所以C++又增加了一个非类型模板参数,非类型模板参数与宏很类似但是比宏更灵活,本质还是由Stack实例化出的两个类:
template<class T, size_t N>
class Stack
{
private:
T _a[N];
size_t _top;
};
int main()
{
Stack<int, 10> st1;// 10
Stack<int, 100> st2;// 100
return 0;
}

非类型模板参数也可以给缺省值:
template<class T, size_t N = 10>
class Stack
{
private:
T _a[N];
size_t _top;
};
int main()
{
Stack<int> st1;// 10
Stack<int, 100> st2;// 100
return 0;
}
3、array
看看库里面使用非类型模板参数的容器:C++11新增的容器array(静态数组),与vector形成对照。

没有提供头插头删尾插尾删接口,因为空间是一定的,用下标随机访问就行。
严格来说,array对比的不是vector,因为vector是动态的,二者本质还是不一样的,array对比的是C语言中的静态数组。
array与C中的静态数组很像:存储的数据类型可以是自定义类型,也可以是内置类型的;sizeof出来的大小是一样的;只不过array中多了个迭代器,其实就是原生指针,C中静态数组可以用范围for,也是可以转换成原生指针。
int main()
{
// C++中用类封装的静态数组array
array<int, 10> a1;
array<int, 100> a2;
array<string, 100> a3;
// C中静态数组
int aa1[10];
int aa2[100];
string aa3[100];
cout << sizeof(a1) << endl;
cout << sizeof(aa1) << endl;
return 0;
}

array与C中静态数组真正的区别只有一个:越界的检查方式不同。
- 原生数组,越界读,不检查。
- 原生数组,越界写,抽查。一般在结束位置附近可以检查出来,但是再往后的位置越界就会检查不出来。
- array对于越界读写都能检查
那么array是怎么做到越界读写都能检查到的?自定义类型对象调用 operator[] ,函数里面有assert断言检查,所以报错报的是断言错误。

但是array用的很少,一般用的是vector。vector有初始化;array连初始化都没有,都是随机值。而且array实参N的值不能太大,栈空间不大,会栈溢出。若就想用静态数组,那么就可以用array替代C中静态数组。
4、注意

二、模板的特化
1、概念
特化:特殊化处理。
通常情况下,使用模板可以实现一些与类型无关的代码,但对于一些特殊类型可能会得到一些错误的结果,需要特殊处理,比如:实现了一个专门用来进行小于比较的函数模板。
// 函数模板 — 参数匹配
template<class T>
bool Less(T left, T right)
{
return left < right;
}
int main()
{
cout << Less(1, 2) << endl;// 可以比较,结果正确
Date d1(2025, 5, 11);
Date d2(2025, 5, 12);
cout << Less(d1, d2) << endl;// 可以比较,结果正确
Date* p1 = &d1;
Date* p2 = &d2;
cout << Less(p1, p2) << endl;// 可以比较,结果错误
return 0;
}
 可以看到,Less绝大多数情况下都可以正常比较,但是在特殊场景下就得到错误的结果。上述示例中,p1指向的d1显然小于p2指向的d2对象,但是Less内部并没有比较p1和p2指向的对象内容,而比较的是p1和p2指针的地址,这就无法达到预期而错误。
可以看到,Less绝大多数情况下都可以正常比较,但是在特殊场景下就得到错误的结果。上述示例中,p1指向的d1显然小于p2指向的d2对象,但是Less内部并没有比较p1和p2指向的对象内容,而比较的是p1和p2指针的地址,这就无法达到预期而错误。
此时,就需要对模板进行特化。即:在原模板的基础上,对特殊类型进行特殊化的处理。模板特化分为函数模板特化与类模板特化。
2、函数模板特化
函数模板的特化步骤:
(类模板的特化步骤与之类似,不过类模板特化和类模板里的函数参数列表没有必要完全相同)
函数模板本质是一种参数匹配,对函数模板进行特化本质也是一种参数匹配。
// 函数模板 — 参数匹配
template<class T>
bool Less(T left, T right)
{
return left < right;
}
// 对Less函数模板进行特化 — 参数匹配
template<>
bool Less<Date*>(Date* left, Date* right)// T实例化成Date*
{
return *left < *right;
}
int main()
{
cout << Less(1, 2) << endl;
Date d1(2025, 5, 11);
Date d2(2025, 5, 12);
cout << Less(d1, d2) << endl;
Date* p1 = &d1;
Date* p2 = &d2;
cout << Less(p1, p2) << endl;// 调用特化之后的版本,而不走模板生成了
return 0;
}
注意:一般情况下如果函数模板遇到不能处理或者处理有误的类型,为了实现简单通常都是将该函数直接给出。普通函数可以与函数模板同时存在,有现成吃现成,就会直接调用现有的函数,所以函数模板不建议特化,直接写普通函数即可。
bool Less(Date* left, Date* right)
{
return *left < *right;
}
为什么不建议函数模板特化呢?函数模板的坑:
传值传参,若T是有深拷贝的自定义类型,代价太大了,所以会加引用。加了引用一般就会加const,这样普通对象、const对象都可以作为参数传递过来。对上述函数模板改造如下:
但是报错了,会不会是参数列表没有对上?但是加上了引用也还是报错了。

问题出现在const上,"不是函数模板的专用化"的原因是const修饰的匹配不上。所以特化的const的正确位置如右图。

所以函数模板特化是很容易出现问题的,直接写成普通函数即可。
借助调试理解普通函数与函数模板特化同时存在时,会优先匹配普通函数。

3、类模板特化
(1)、全特化:全部模板参数都特化成具体的类型
函数模板可以特化,也可以写出普通函数。而对于类模板特化,没有普通类的概念,必须走类模板特化。因为函数与函数模板可以参数匹配,而类模板必须显示实例化。

Data<int, double> d1;实例化出的类的数据类型T1是int、T2是double,就会优先匹配上面类模板特化的版本。
(2)、偏/半特化:部分模板参数特化成具体的类型,还可以是对参数的进一步限制
部分模板参数特化成具体的类型:
// 将第二个参数特化为char
template<class T1>
class Data<T1, char>
{
public:
Data() { cout << "Data<T1, char>" << endl; }
};
对模板参数的进一步限制:
// 特化 — 偏特化,实例化出的模板参数只要都是指针就会走这个版本
// 两个参数偏特化为指针类型
template<class T1, class T2>
class Data<T1*, T2*>
{
public:
Data() { cout << "Data<T1*, T2*>" << endl; }
private:
T1 _d1;
T2 _d2;
};
// 特化 — 偏特化,实例化出的模板参数只要都是引用就会走这个版本
// 两个参数偏特化为引用类型
template<class T1, class T2>
class Data<T1&, T2&>
{
public:
Data() { cout << "Data<T1&, T2&>" << endl; }
private:
T1 _d1;
T2 _d2;
};
// 特化 — 偏特化,还能特化成指针和引用混在一起的版本
// 实例化出的模板参数只要前一个是指针、后一个是引用就会走这个版本
template<class T1, class T2>
class Data<T1*, T2&>
{
public:
Data() { cout << "Data<T1*, T2&>" << endl; }
private:
T1 _d1;
T2 _d2;
};
上面所有的类模板特化与类模板是同时存在的。

(3)、priority_queue中使用类模板特化
例如上一讲中的内容,是需要显示给出模板参数的:

这里给的模板参数解决了日期类指针的问题,但是要是有int*等其他类型的指针呢?都去写仿函数就太多了,内容繁琐,而特化就能解决。
int main()
{
zsy::priority_queue<Date> pq1;
pq1.push({ 2025, 5, 10 });
pq1.push({ 2025, 5, 19 });
pq1.push({ 2025, 5, 23 });
while (!pq1.empty())
{
cout << pq1.top() << " ";
pq1.pop();
}
cout << endl;
zsy::priority_queue<Date*> pq2;
pq2.push(new Date(2025, 5, 10));
pq2.push(new Date(2025, 5, 19));
pq2.push(new Date(2025, 5, 23));
while (!pq2.empty())
{
cout << *pq2.top() << " ";
pq2.pop();
}
cout << endl;
zsy::priority_queue<int*> pq3;
pq3.push(new int(1));
pq3.push(new int(2));
pq3.push(new int(3));
while (!pq3.empty())
{
cout << *pq3.top() << " ";
pq3.pop();
}
cout << endl;
return 0;
}
模拟实现的less仿函数:
template<class T>
class less
{
public:
bool operator()(const T& x, const T& y)
{
return x < y;
}
};
这样写会报错,因为当T是指针时,const修饰的不是指针,而是指向的内容,前面讲解过了解决办法。
// 特化
template<class T>
class less<T*>
{
public:
bool operator()(const T& x, const T& y)
{
return *x < *y;
}
};
这里还有一个解决办法:
// 特化
template<class T>// 这里的T保留
class less<T*>// 意思是T是指针T*时,就按照指向的内容去比较
{
public:
bool operator()(const T* const & x, const T* const & y)
{
return *x < *y;
}
};
 所以上一讲中对于priority_queue的模拟实现的仿函数改进如下:
所以上一讲中对于priority_queue的模拟实现的仿函数改进如下:
template<class T>
class less
{
public:
bool operator()(const T& x, const T& y)
{
return x < y;
}
};
// 特化
template<class T>
class less<T*>
{
public:
bool operator()(const T* const & x, const T* const & y)
{
return *x < *y;
}
};
template<class T>
class greater
{
public:
bool operator()(const T& x, const T& y)
{
return x > y;
}
};
// 特化
template<class T>
class greater<class T*>
{
public:
bool operator()(const T* const& x, const T* const& y)
{
return *x > *y;
}
};
三、typename的特性
定义模板参数用关键字class/typename都行。最常用class,例如库里面的模板声明中大多都是用class定义模板参数的:

但是有一个场景下必须用typename定义:模板参数里面取内嵌类型时前面必须加typename,无论是用这个内嵌类型定义/声明对象。
示例1,想打印一些容器。vector、list提供了迭代器但是没有提供cout打印,我们现在想写一个通用的函数去对它们进行打印,比如写一个通用的打印容器的Print函数模板,但是会报编译错误:
#include <iostream>
#include <list>
#include <vector>
using namespace std;
template<class Container>
void Print(const Container& con)
{
Container::const_iterator it = con.begin();
while (it != con.end())
{
cout << *it << " ";
++it;
}
cout << endl;
}
int main()
{
vector<int> v = { 1, 2, 3, 4, 5 };
list<int> lt = { 10, 20, 30 };
Print(v);
Print(lt);
return 0;
}

问题所在:

前面加typename才会通过:

原因:从上往下编译,编译到Container::const_iterator it = con.begin();时,因为Container是模板参数,在未实例化时,编译器不知道Container到底是什么东西,根据域作用限定符,猜测Container可能是命名空间/类,因为是从上往下编译的,知道class后面是类型参数名,所以知道Container是个类型,故而编译器确定Container是个类。但是编译器不知道 :: 取的const_iterator是类型还是静态成员变量,既然不确定是什么,那么const_iterator就是不合法的。若const_iterator是个类型,编译就能通过,也不敢去Container里面找,因为不确定Container实例化是什么。而前面加个typename就是程序员先告诉编译器typename后面的Container::const_iterator肯定是个类型,让编译先通过,等到Container实例化时编译器再去确认Container::const_iterator具体的类型。
示例2:
虽然知道容器是vector,但是vector< T >还是没有实例化的。所以只要记住模板参数里面取内嵌类型前加typename即可。
typename vector<T>::const_iterator it = con.begin();
#include <iostream>
#include <list>
#include <vector>
using namespace std;
template<class Container>
void Print(const Container& con)
{
typename Container::const_iterator it = con.begin();
while (it != con.end())
{
cout << *it << " ";
++it;
}
cout << endl;
}
template<class T>
void Print(const vector<T>& con)
{
typename vector<T>::const_iterator it = con.begin();
while (it != con.end())
{
cout << *it << " ";
++it;
}
cout << endl;
}
int main()
{
vector<int> v = { 1, 2, 3, 4, 5 };
list<int> lt = { 10, 20, 30 };
Print(v);
Print(lt);
return 0;
}
库里用到typename的容器:

四、模板的分离编译
分离编译:一个程序(项目)由若干个源文件共同实现,而每个源文件单独编译生成目标文件,最后将所有目标文件链接起来形成单一的可执行文件的过程称为分离编译模式。
模板的定义和声明可以分离在同一个文件中,但是不能分离在两个文件中,会有链接错误。
我们从简单的声明和定义的分离再逐渐过渡到为什么模板不支持声明和定义分离到两个文件进行讲解。
不支持分离在.h和.cpp里。
- 简单的声明和定义的分离:
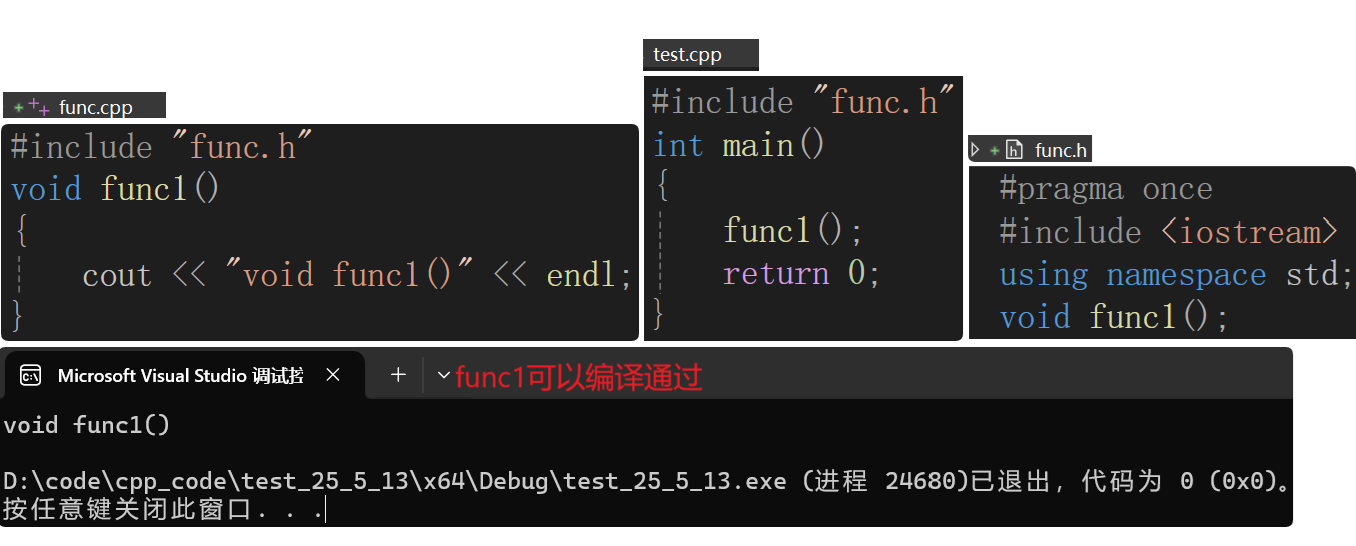
以下编译链接的过程按照Linux来讲:

条件编译:#ifdef、#ifndef、#endif等。写了一个需要跨平台的代码,例如分别在Windows、Linux调用,那么这个代码中就有条件编译。由于Windows、Linux接口不同,需要借助条件编译跨平台。例如:
在预处理阶段,如果满足if后面的宏,就会把这段代码放出来,否则就不放:
 预处理期间,满足后面的条件,代码留下,否则就相当于把这段代码删去:
预处理期间,满足后面的条件,代码留下,否则就相当于把这段代码删去:

预处理阶段:.h在func.cpp和test.cpp下分别展开,展开头文件,相当于在新的文件中把.h文件拷贝到.cpp中,这一过程不在源文件中处理。所以编译时就没有.h了:

编译后会生成汇编代码,但是CPU看不懂汇编代码,"汇编代码"是一种"符号指令"级别的语言,是人们能看懂的符号,例如call、jump、add…,但是这些符号机器(CPU)看不懂,CPU(机器)只认识二进制语言0、1。所以我们还需要对符号指令进行翻译(翻译的例子:move指令假如叫111、add指令叫112,CPU看到112就知道是add)。所以编译后生成的.s文件需要进行汇编(与"汇编代码"区分),汇编是编译链接中的一个步骤,是将汇编代码转换成二进制机器码,CPU认识二进制机器码,这一步骤生成.o文件。
发现除了在"预处理"阶段会有.h的展开,func.h和func.cpp一起生成func.i、test.cpp和func.h一起生成test.i。其他步骤中.cpp与.cpp之间是各自生成各自的。"链接"是生成可执行程序,不是仅仅把它们合并在一起,而是把它们"链接"在一起。链接后,Linux下会生成a.out(具体会在学习到Linux时讲解),Windows下会生成xxx.exe,a.out和xxx.exe就是可执行程序了。
链接错误通常就是没有定义
这里报链接错误的原因是只有函数声明,没有函数定义。那么为什么会有这样的问题呢?

.h在预处理阶段会在func.cpp和test.cpp下分别展开,展开了之后func.i和test.i各有一份声明:

func.i没有问题,有func1函数的定义和声明;但是test.i会有问题,"编译"阶段检查语法,调用函数时,要找到它的出处,要有函数的定义,或者至少有函数的声明。调用函数func1()时,有它的函数声明,所以语法没有问题。
之后要在test.s中生成汇编代码,函数调用生成的汇编代码是"call一个地址",形象一点就是"call func1(?)"。函数的地址类似数组的地址,数组的地址就是第一个数据的地址,函数的定义被编译后是一串指令(好多句指令),每一句指令都会对应一个地址,第一句指令就是函数的地址。所以call这个函数的地址就是,先到一个jump指令,再跳转过去执行函数,再函数建立栈帧…
之前除预处理阶段各个.cpp之间不会交互,只有在链接阶段交互。
若.h里有这个函数的定义,预处理.cpp文件包了定义,有了定义就有这个函数的地址,函数定义被编译成一段指令,取第一句指令填写到"call func1(?)"中的?上,指令完整,即有了定义那么函数地址在编译阶段就能确定。但是示例中的情况是没有函数定义,只有函数声明,首先语法没有问题"编译"直接通过了,由于只有函数声明,所以不可能有函数地址,那么(定义)地址在哪里呢?在其他文件。这时会在"链接"阶段确定地址:利用func1函数名去其他文件找,为了更快速找到,每个.o文件都会有对应的一个符号表,每个符号表会把对应.o文件中的函数及其地址填进来,这样就不用在文件里找了,直接拿func1函数名去符号表找func1地址0x00112233,填在call func1(?)里call func1(0x00112233),这句指令才算完整。所以"链接"阶段不止把多个.o链接到一起,还有本段落的过程。然后就生成了可执行程序。
所以上面的链接错误的原因:拿func1函数名找不到函数的地址,没有定义所以没有函数的地址,所以链接错误通常就是没有定义。
顺便提一句编译好的动态库,平时编译链接程序就直接生成的是可执行程序,Windows下可以设置编译链接后生成的是动态库。比如一个多人写的项目,有多个动态库,只走链接的部分,可以加快编译的速度。(Linux讲解)

- 为什么模板不能声明和定义分离在.h和.cpp?
若声明和定义不分离,程序没问题;若声明和定义分离在.h文件是没问题的,.cpp包了.h既有声明,又有定义;

若声明和定义分离在两个文件,会出现链接错误,即找不到定义。func1链接错误是因为没有定义,但是为什么定义了Print模板还报链接错误?—— Contianer没有实例化。模板不能直接调用,是需要实例化模板参数Container的。

调用的地方Print()语法没有问题,出处是Print的声明,编译通过。

由于链接之前不会交互不会有问题,而在链接阶段会交互,用Print函数名去找定义会找不到,因为Print函数的定义没有实例化,在链接阶段出现的错误,即链接错误。
解决方案:
- 方法一:显示实例化
上面出现链接错误的原因就是Print函数的定义中的模板参数Contianer没有实例化,那就告诉编译器模板参数Container实例化为vector< int >

只会报一个链接错误了:

说明函数调用 Print(v); 找到对应的定义了,能链接上。
显示实例化,实例化生成一份Container为vector< int >的Print,知道了Print的实例化定义,编译生成它的地址,链接时在test.o的符号表里找Print<vector< int >>地址,call 一个地址。所以模板的定义和声明可以分离到两个文件中,不过实际上不会这么做的,太麻烦了,还有其他的类型就还需要显示实例化。
因此,"显示实例化"这种方式可行但不可取。
- 方法二,正确解决办法:模板直接在.h里定义,或者定义和声明在.h/.hpp里,不要分离到.cpp里。
为什么这样可以解决问题?
首先明确什么情况下需要链接?.h只有声明,哪个.cpp包含了这个.h在预处理后也只包了声明,编译阶段语法没有问题,但是(没有实例化)就没办法生成对应的指令,这时需要链接。
若.h就有模板定义,哪个.cpp包含了这个.h就会在预处理后也有定义,那么在调用的地方就知道实例化成什么,实例化后模板定义经过编译直接生成指令,这样编译阶段就有了地址,这时就不用链接确认地址了。所以没有链接错误,因为根本不用链接、不用到符号表里找。
看一个list的源代码。模板没有.cpp,list是个模板,模板只会声明和定义都在.h里:

短小函数直接定义在类里,成为内联:

长一点的函数,在当前文件做了声明和定义的分离:

普通的函数和类都需要写.h、.cpp声明和定义的分离;模板就只定义在.h,后缀是.h,还有一些模板后缀是.hpp,就是.h和.cpp的合体,把声明和定义放在了一起,例如,boost库里好多模板就是这样的:

弄清楚: 1、模板的声明和定义分离在.h、.cpp为什么会报错? 2、解决方案?有两种:(1)、显示实例化 (2)、模板直接定义在.h
五、模板的优缺点
【优点】
【缺陷】
代码膨胀避免不了,比如写了一个vector模板有100行代码,实例化成多个不同类型时,就会导致有更多代码。






评论前必须登录!
注册