 网硕互联帮助中心
网硕互联帮助中心EchoMimicV2是阿里巴巴蚂蚁集团开发的一个非常酷的技术项目,它能够创造出像真人一样的半身数字人。想象一下,你有一张喜欢的照片、一段音频,还有一些手部动作的视频片段,EchoMimicV2就能利用这些东西,帮你生成一个动画视频。
在这个动画视频里,数字人会根据音频里的声音,做出逼真的动作和表情,就像他真的在说话一样。而且,不仅中文、英文,只要是音频里的声音,数字人都能相应地做出动作。
比起之前的技术(我们叫它EchoMimicV1),EchoMimicV2更加厉害。它不仅能做出人头部的动画,现在还能让整个半身都动起来,手势、表情、身体动作都配合得天衣无缝。这就像有了一个真正的数字人演员,能够根据你说的话,做出最自然的反应。
所以,简单来说,EchoMimicV2就是一个能把照片、声音和手部动作结合起来,生成逼真半身数字人动画的神奇技术。
正文
1.克隆项目
git clone https://github.com/CMU-Perceptual-Computing-Lab/openpose.git
2.创建环境
conda create -n echo python=3.10
3.进入环境
conda activate echo
4.下载所需要的库
pip install pip -U
pip install torch==2.5.1 torchvision==0.20.1 torchaudio==2.5.1 xformers==0.0.28.post3 –index-url https://download.pytorch.org/whl/cu124
pip install torchao –index-url https://download.pytorch.org/whl/nightly/cu124
pip install -r requirements.txt
pip install –no-deps facenet_pytorch==2.6.0
5.下载ffmpeg-static
wget https://www.johnvansickle.com/ffmpeg/old-releases/ffmpeg-4.4-amd64-static.tar.xz
解压
tar -xvf ffmpeg-4.4-amd64-static.tar.xz
6.下载预训练权重
git lfs install
git clone https://huggingface.co/BadToBest/EchoMimicV2 pretrained_weights
并将内容按照以下格式准备好(尤其注意还是需要sd-image-variations-diffusers,否则会报错)
./pretrained_weights/
├── denoising_unet.pth
├── reference_unet.pth
├── motion_module.pth
├── pose_encoder.pth
├── sd-vae-ft-mse
│ └── …
├── audio_processor
│ └── tiny.pt
└── sd-image-variations-diffusers
└── diffusion_pytorch_model.bin
└── …
sd-vae-ft-mse
https
git clone https://huggingface.co/stabilityai/sd-vae-ft-mse
ssh
git clone git@hf.co:stabilityai/sd-vae-ft-mse
如无法克隆可取网站自行下载
stabilityai/sd-vae-ft-mse · Hugging Face
audio_processor,点击就会下载tiny.py,需要自行创建文件夹放进去
- audio_processor(whisper)
sd-image-variations-diffusers
https
git clone https://huggingface.co/lambdalabs/sd-image-variations-diffusers
ssh
git clone https://huggingface.co/lambdalabs/sd-image-variations-diffusers
如无法克隆可取网站自行下载
lambdalabs/sd-image-variations-diffusers · Hugging Face
———————————————————————————————————————————
运行
gradio
python app,py
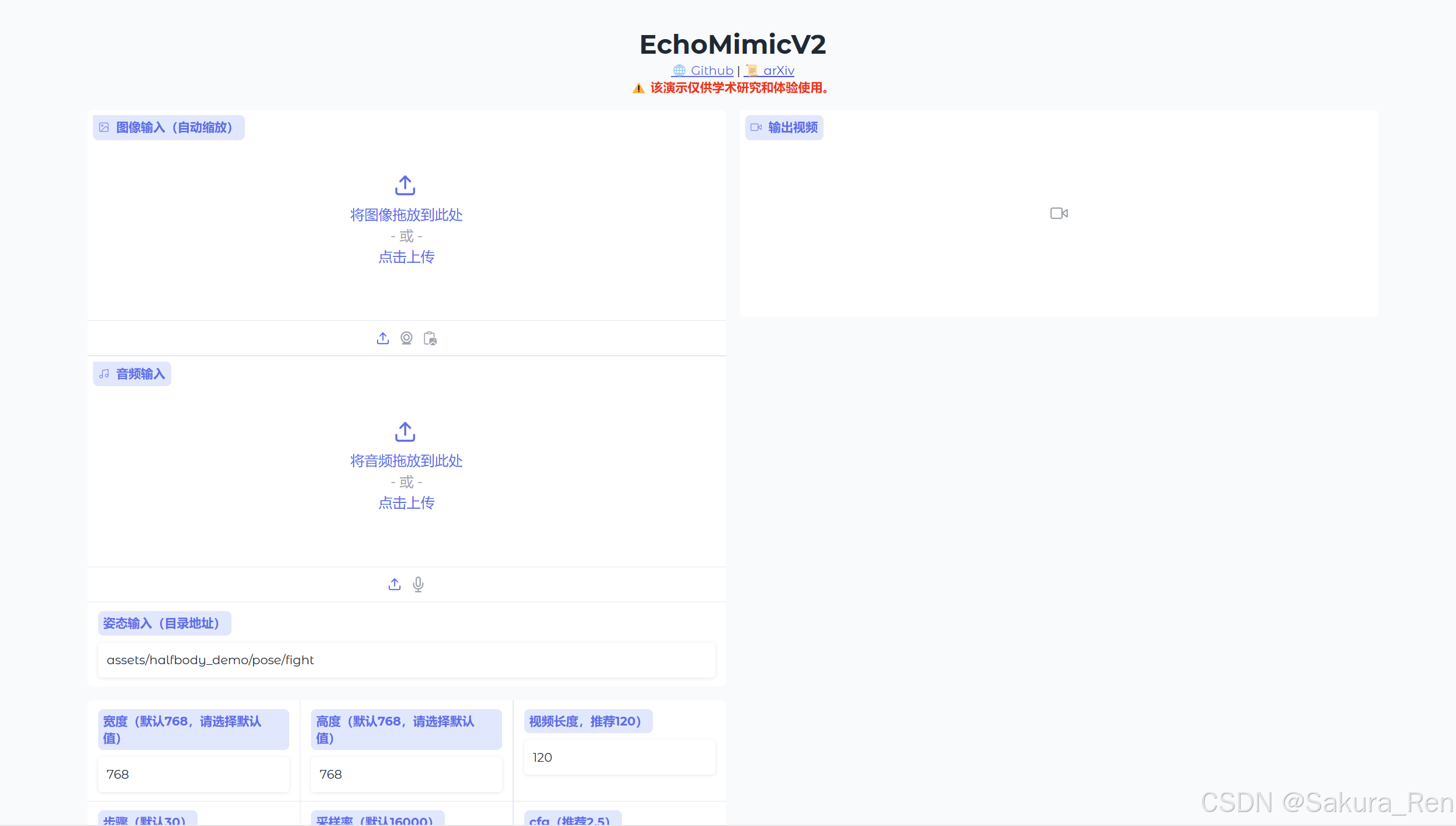
代码运行
python infer.py
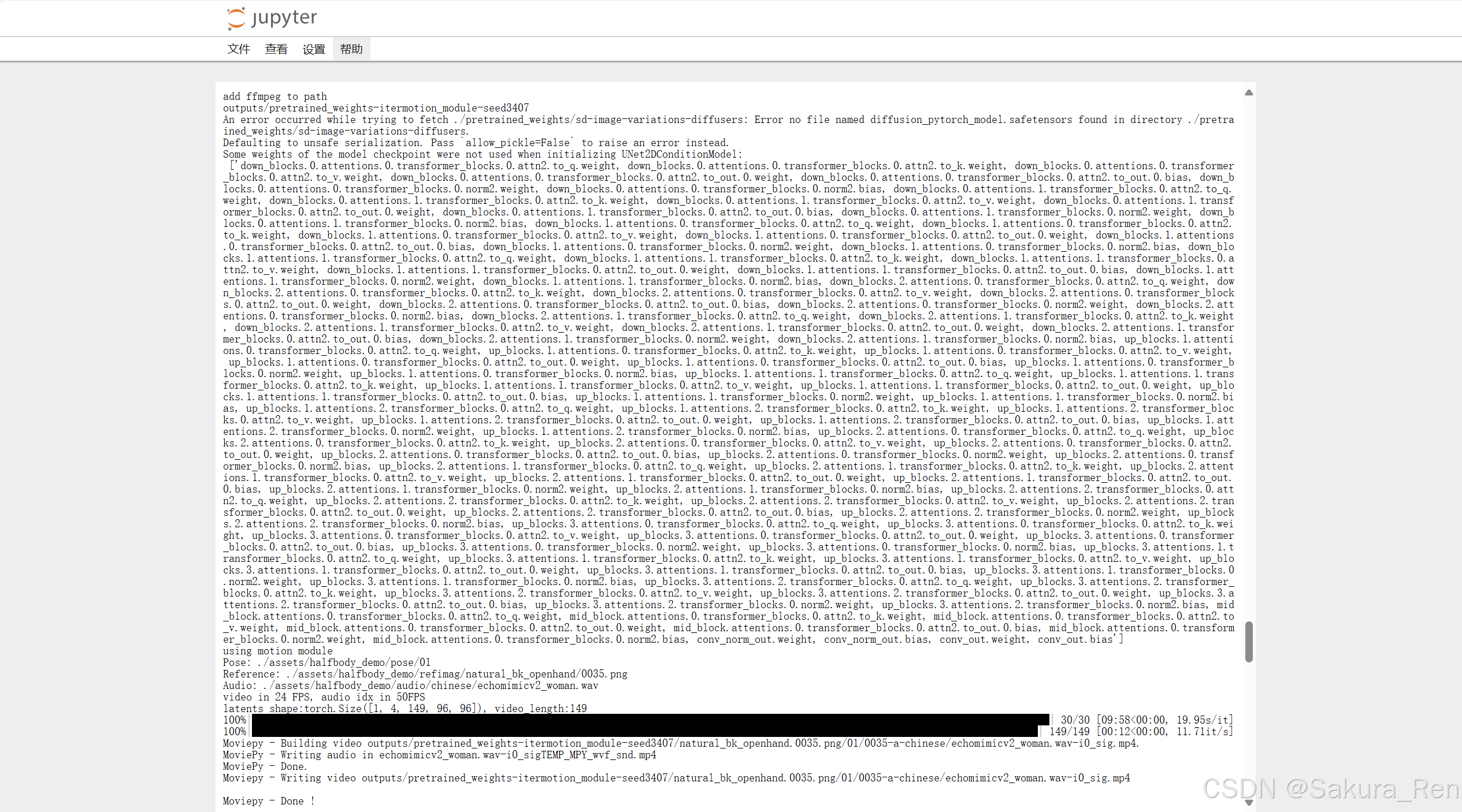
——————————————————————————————————————————–
自己的数字人
打开infer.py
将53行更改为自己需要的照片,但只能是jpg或png格式,且分辨率建议为 768×768
parser.add_argument("–refimg_name", type=str, default='natural_bk_openhand/0035.png')
图片路径为../assets/halfbody_demo/refimag/
注意:如果你的图片直接存放在refimag/后,那么default='你自己的照片.png',不要输入完整路径,因为后续代码有前面的路径,如果这里输入完整路径,运行时就会报路径错误
将54行更改为自己需要的音频,但只能是wav格式,且推荐采样率为16kHz
parser.add_argument("–audio_name", type=str, default='chinese/echomimicv2_woman.wav')
音频路径为../assets/halfbody_demo/audio/chinese/
还是需要注意路径问题,同上
姿势数据
需通过姿势估计工具(如 OpenPose 或 MMPose)生成 .npy 文件
我还没有进行实验,仅仅使用了自己的图片和音频,生成了一段
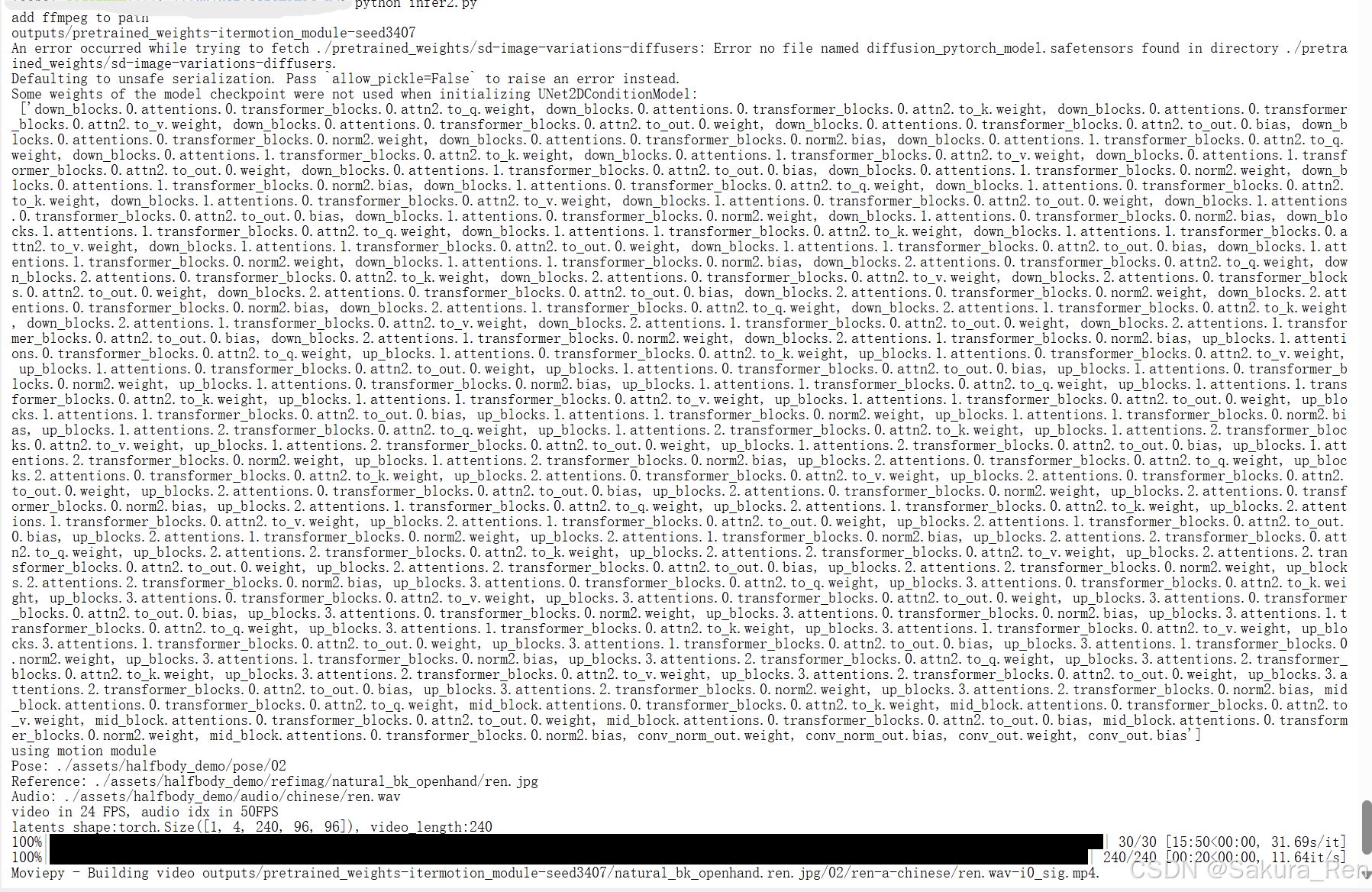
结束
至此,echominicV2小白教程就暂时告一段落了,我后面还会书写更多小白教程。希望通过这篇教程,即便是初次接echominicV2的朋友们也能对其有一个清晰的认识和基本的使用能力。echominicV2作为一个功能强大的工具/平台(根据echominicV2的实际功能进行描述),在数据处理、分析或者特定领域的应用上都有着不可忽视的优势。
在学习的过程中,难免会遇到一些困惑和挑战,但请记住,每一步的尝试都是向前迈进的重要一步。如果在学习过程中有任何疑问或需要进一步深入探讨的地方,欢迎在CSDN的评论区留言,与我和其他读者一起交流心得。如果我哪里有错误,欢迎各位指正批评,我一定积极修改。
此外,技术总是在不断进步和发展的,echominicV2也不例外。因此,建议大家持续关注官方文档和社区更新,以便及时了解并掌握最新的功能和优化。
最后,感谢大家的阅读和支持,希望这篇教程能对你的学习和工作有所帮助。在技术的道路上,愿我们都能不断进步,共同成长!




评论前必须登录!
注册