 网硕互联帮助中心
网硕互联帮助中心 conda create -n querydet python=3.7 -y
source activate querydet
python版本3.7.16
CUDA release 11.3, V11.3.58 最高12.5
下载pytorch1.8.1
conda install pytorch==1.8.1 torchvision==0.9.1 torchaudio==0.8.1 cudatoolkit=11.3 -c pytorch -c conda-forge
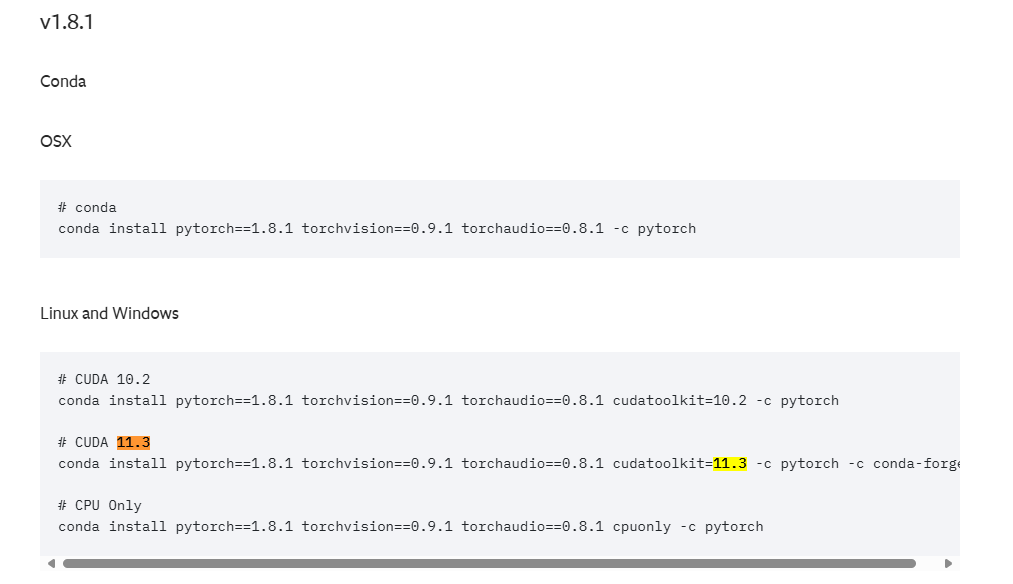
一直卡solve
下载pytorch1.11 cuda11.3
pip install torch==1.11.0+cu113 torchvision==0.12.0+cu113 torchaudio==0.11.0 –extra-index-url https://download.pytorch.org/whl/cu113
下载好coco visdrone数据集
预处理visdrone:python visdrone/data_prepare.py –visdrone-root data/visdrone
安装CV2
pip install opencv-python
训练报错
python train_coco.py –config-file configs/coco/retinanet_train.yaml –num-gpu 8 OUTPUT_DIR work_dirs/coco_retinanet
Traceback (most recent call last): File "train_coco.py", line 3, in <module> from detectron2.engine import launch File "/home/liuyadong/.conda/envs/querydet/lib/python3.7/site-packages/detectron2/engine/__init__.py", line 11, in <module> from .hooks import * File "/home/liuyadong/.conda/envs/querydet/lib/python3.7/site-packages/detectron2/engine/hooks.py", line 18, in <module> from detectron2.evaluation.testing import flatten_results_dict File "/home/liuyadong/.conda/envs/querydet/lib/python3.7/site-packages/detectron2/evaluation/__init__.py", line 2, in <module> from .cityscapes_evaluation import CityscapesInstanceEvaluator, CityscapesSemSegEvaluator File "/home/liuyadong/.conda/envs/querydet/lib/python3.7/site-packages/detectron2/evaluation/cityscapes_evaluation.py", line 11, in <module> from detectron2.data import MetadataCatalog File "/home/liuyadong/.conda/envs/querydet/lib/python3.7/site-packages/detectron2/data/__init__.py", line 4, in <module> from .build import ( File "/home/liuyadong/.conda/envs/querydet/lib/python3.7/site-packages/detectron2/data/build.py", line 12, in <module> from detectron2.structures import BoxMode File "/home/liuyadong/.conda/envs/querydet/lib/python3.7/site-packages/detectron2/structures/__init__.py", line 7, in <module> from .masks import BitMasks, PolygonMasks, polygons_to_bitmask File "/home/liuyadong/.conda/envs/querydet/lib/python3.7/site-packages/detectron2/structures/masks.py", line 9, in <module> from detectron2.layers.roi_align import ROIAlign File "/home/liuyadong/.conda/envs/querydet/lib/python3.7/site-packages/detectron2/layers/__init__.py", line 3, in <module> from .deform_conv import DeformConv, ModulatedDeformConv File "/home/liuyadong/.conda/envs/querydet/lib/python3.7/site-packages/detectron2/layers/deform_conv.py", line 11, in <module> from detectron2 import _C ImportError: libcudart.so.10.2: cannot open shared object file: No such file or directory 应该是dectron2版本不对,我是cuda11.3 卸载pip uninstall detectron2
重新下载【Detectron2】踩坑实记 – 知乎 git clone https://github.com/facebookresearch/detectron2.git python -m pip install -e detectron2
成功安装2.0.6
![]()
运行报错
Traceback (most recent call last): File "train_coco.py", line 3, in <module> from detectron2.engine import launch File "/home/liuyadong/QueryDet-PyTorch/detectron2/detectron2/engine/__init__.py", line 4, in <module> from .train_loop import * File "/home/liuyadong/QueryDet-PyTorch/detectron2/detectron2/engine/train_loop.py", line 13, in <module> from detectron2.utils.events import EventStorage, get_event_storage File "/home/liuyadong/QueryDet-PyTorch/detectron2/detectron2/utils/events.py", line 9, in <module> from functools import cached_property ImportError: cannot import name 'cached_property' from 'functools' (/home/liuyadong/.conda/envs/querydet/lib/python3.7/functools.py)
应该是dectron2版本和cuda torch版本不对
| python -m pip install detectron2 -f \\ https://dl.fbaipublicfiles.com/detectron2/wheels/cu113/torch1.10/index.html |
卸载pip uninstall detectron2
按照deepseek方案
还是报错
重新创环境
安装torch1.10 cuda11.3 python3.8
conda create -n querydet python=3.7 -y
安装torch1.10.1
conda install pytorch==1.10.1 torchvision==0.11.2 torchaudio==0.10.1 cudatoolkit=11.3 -c pytorch -c conda-forge
卡solve
安装离线包1.10.0
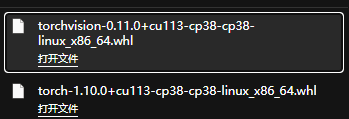
去服务器安装
pip install /home/liuyadong/QueryDet-PyTorch/torch-1.10.0+cu113-cp38-cp38-linux_x86_64.whl
pip install /home/liuyadong/QueryDet-PyTorch/torchvision-0.11.0+cu113-cp38-cp38-linux_x86_64.whl
安装dectron2
| python -m pip install detectron2 -f \\ https://dl.fbaipublicfiles.com/detectron2/wheels/cu113/torch1.10/index.html |
本地下载好安装
安装完成
安装spconv
pip install spconv-cu113==2.3.6
报错Traceback (most recent call last): File "train_coco.py", line 3, in <module> from detectron2.engine import launch File "/home/liuyadong/.conda/envs/querydet/lib/python3.8/site-packages/detectron2/engine/__init__.py", line 11, in <module> from .hooks import * File "/home/liuyadong/.conda/envs/querydet/lib/python3.8/site-packages/detectron2/engine/hooks.py", line 22, in <module> from detectron2.evaluation.testing import flatten_results_dict File "/home/liuyadong/.conda/envs/querydet/lib/python3.8/site-packages/detectron2/evaluation/__init__.py", line 2, in <module> from .cityscapes_evaluation import CityscapesInstanceEvaluator, CityscapesSemSegEvaluator File "/home/liuyadong/.conda/envs/querydet/lib/python3.8/site-packages/detectron2/evaluation/cityscapes_evaluation.py", line 11, in <module> from detectron2.data import MetadataCatalog File "/home/liuyadong/.conda/envs/querydet/lib/python3.8/site-packages/detectron2/data/__init__.py", line 2, in <module> from . import transforms # isort:skip File "/home/liuyadong/.conda/envs/querydet/lib/python3.8/site-packages/detectron2/data/transforms/__init__.py", line 4, in <module> from .transform import * File "/home/liuyadong/.conda/envs/querydet/lib/python3.8/site-packages/detectron2/data/transforms/transform.py", line 36, in <module> class ExtentTransform(Transform): File "/home/liuyadong/.conda/envs/querydet/lib/python3.8/site-packages/detectron2/data/transforms/transform.py", line 46, in ExtentTransform def __init__(self, src_rect, output_size, interp=Image.LINEAR, fill=0): AttributeError: module 'PIL.Image' has no attribute 'LINEAR'
deepseek方案
降级 Pillow 到兼容版本 当前10.4.0
# 卸载当前 Pillow pip uninstall pillow -y
# 安装 Pillow 9.0.1(仍支持 Image.LINEAR) pip install pillow==9.0.1
报错没CV2
pip install opencv-python
报错
Command Line Args: Namespace(config_file='configs/coco/retinanet_train.yaml', dist_url='tcp://127.0.0.1:50158', eval_only=False, machine_rank=0, no_pretrain=False, num_gpus=2, num_machines=1, opts=['OUTPUT_DIR', 'work_dirs/coco_retinanet'], resume=False) Traceback (most recent call last): File "train_coco.py", line 13, in <module> launch( File "/home/liuyadong/.conda/envs/querydet/lib/python3.8/site-packages/detectron2/engine/launch.py", line 67, in launch mp.spawn( File "/home/liuyadong/.conda/envs/querydet/lib/python3.8/site-packages/torch/multiprocessing/spawn.py", line 230, in spawn return start_processes(fn, args, nprocs, join, daemon, start_method='spawn') File "/home/liuyadong/.conda/envs/querydet/lib/python3.8/site-packages/torch/multiprocessing/spawn.py", line 188, in start_processes while not context.join(): File "/home/liuyadong/.conda/envs/querydet/lib/python3.8/site-packages/torch/multiprocessing/spawn.py", line 150, in join raise ProcessRaisedException(msg, error_index, failed_process.pid) torch.multiprocessing.spawn.ProcessRaisedException:
— Process 1 terminated with the following error: Traceback (most recent call last): File "/home/liuyadong/.conda/envs/querydet/lib/python3.8/site-packages/torch/multiprocessing/spawn.py", line 59, in _wrap fn(i, *args) File "/home/liuyadong/.conda/envs/querydet/lib/python3.8/site-packages/detectron2/engine/launch.py", line 126, in _distributed_worker main_func(*args) File "/home/liuyadong/QueryDet-PyTorch/train_tools/coco_train.py", line 190, in start_train cfg = setup(args) File "/home/liuyadong/QueryDet-PyTorch/train_tools/coco_train.py", line 182, in setup cfg.merge_from_file(args.config_file) File "/home/liuyadong/.conda/envs/querydet/lib/python3.8/site-packages/detectron2/config/config.py", line 46, in merge_from_file loaded_cfg = self.load_yaml_with_base(cfg_filename, allow_unsafe=allow_unsafe) File "/home/liuyadong/.conda/envs/querydet/lib/python3.8/site-packages/fvcore/common/config.py", line 61, in load_yaml_with_base cfg = yaml.safe_load(f) File "/home/liuyadong/.conda/envs/querydet/lib/python3.8/site-packages/yaml/__init__.py", line 125, in safe_load return load(stream, SafeLoader) File "/home/liuyadong/.conda/envs/querydet/lib/python3.8/site-packages/yaml/__init__.py", line 81, in load return loader.get_single_data() File "/home/liuyadong/.conda/envs/querydet/lib/python3.8/site-packages/yaml/constructor.py", line 49, in get_single_data node = self.get_single_node() File "/home/liuyadong/.conda/envs/querydet/lib/python3.8/site-packages/yaml/composer.py", line 36, in get_single_node document = self.compose_document() File "/home/liuyadong/.conda/envs/querydet/lib/python3.8/site-packages/yaml/composer.py", line 55, in compose_document node = self.compose_node(None, None) File "/home/liuyadong/.conda/envs/querydet/lib/python3.8/site-packages/yaml/composer.py", line 84, in compose_node node = self.compose_mapping_node(anchor) File "/home/liuyadong/.conda/envs/querydet/lib/python3.8/site-packages/yaml/composer.py", line 127, in compose_mapping_node while not self.check_event(MappingEndEvent): File "/home/liuyadong/.conda/envs/querydet/lib/python3.8/site-packages/yaml/parser.py", line 98, in check_event self.current_event = self.state() File "/home/liuyadong/.conda/envs/querydet/lib/python3.8/site-packages/yaml/parser.py", line 438, in parse_block_mapping_key raise ParserError("while parsing a block mapping", self.marks[-1], yaml.parser.ParserError: while parsing a block mapping in "configs/coco/retinanet_train.yaml", line 1, column 1 expected <block end>, but found '<scalar>' in "configs/coco/retinanet_train.yaml", line 2, column 15
训练前面正常,后面报错
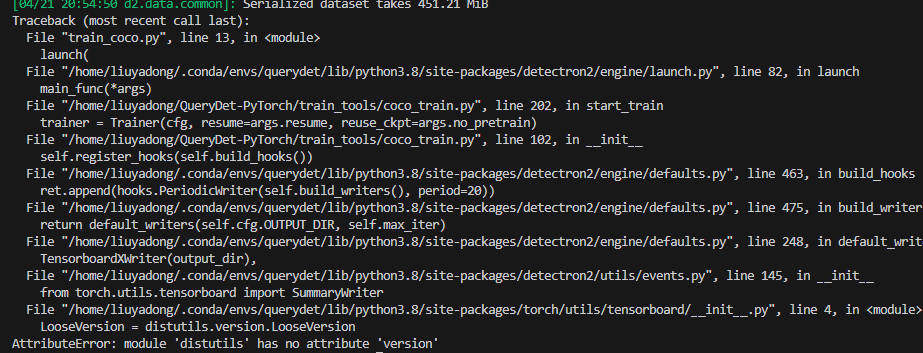
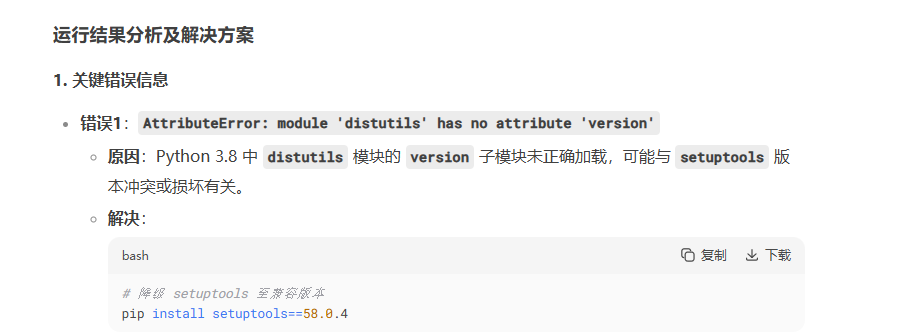
采用deepseek方案
# 降级 setuptools 至兼容版本 pip install setuptools==58.0.4
将GPU数量设置为1
然后运行训练成功
20小时……….
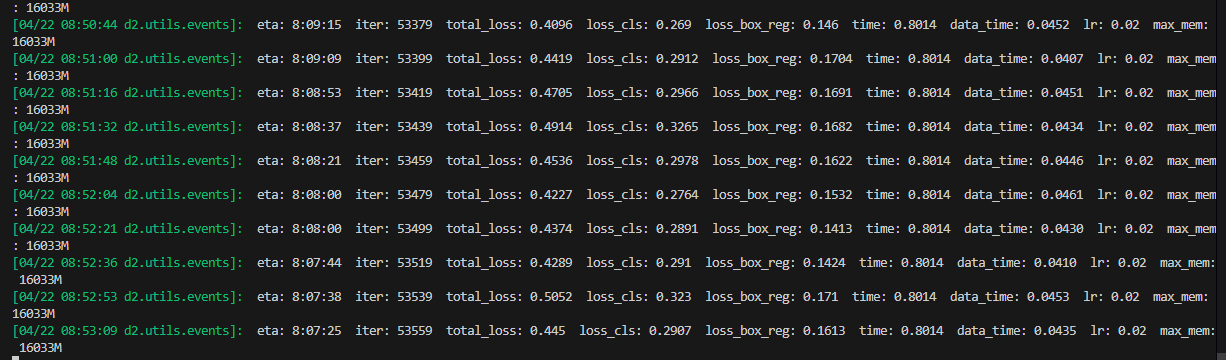
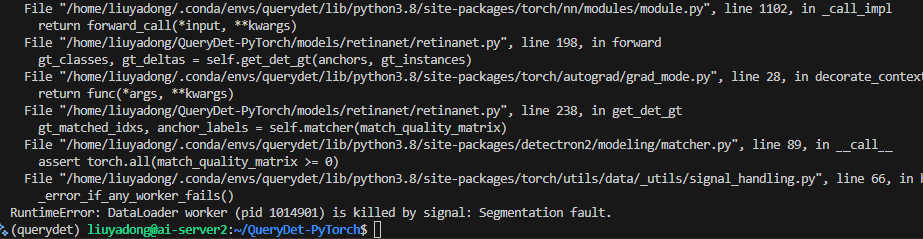
妈的报错RuntimeError: DataLoader worker (pid 1014901) is killed by signal: Segmentation fault.
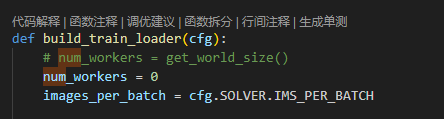
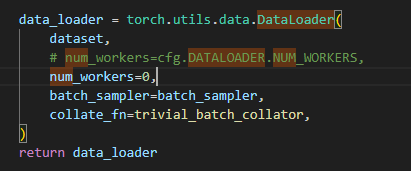
 修改visdrone-dataloader.py
修改visdrone-dataloader.py
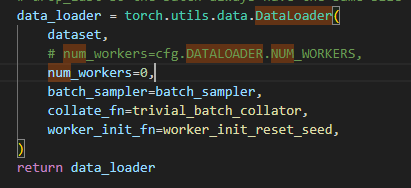
恢复
python train_coco.py –config-file configs/coco/retinanet_train.yaml –num-gpu 2 –resume OUTPUT_DIR work_dirs/coco_retinanet
显存减半 11小时
从检查点训练
python train_coco.py –config-file configs/coco/retinanet_train.yaml –num-gpu 2 MODEL.WEIGHTS work_dirs/coco_retinanet/model_0064999.pth OUTPUT_DIR work_dirs/coco_retinanet
报错
Traceback (most recent call last): File "/home/liuyadong/.conda/envs/querydet/lib/python3.8/site-packages/torch/utils/data/dataloader.py", line 990, in _try_get_data data = self._data_queue.get(timeout=timeout) File "/home/liuyadong/.conda/envs/querydet/lib/python3.8/multiprocessing/queues.py", line 107, in get if not self._poll(timeout): File "/home/liuyadong/.conda/envs/querydet/lib/python3.8/multiprocessing/connection.py", line 257, in poll return self._poll(timeout) File "/home/liuyadong/.conda/envs/querydet/lib/python3.8/multiprocessing/connection.py", line 424, in _poll r = wait([self], timeout) File "/home/liuyadong/.conda/envs/querydet/lib/python3.8/multiprocessing/connection.py", line 931, in wait ready = selector.select(timeout) File "/home/liuyadong/.conda/envs/querydet/lib/python3.8/selectors.py", line 415, in select fd_event_list = self._selector.poll(timeout) File "/home/liuyadong/.conda/envs/querydet/lib/python3.8/site-packages/torch/utils/data/_utils/signal_handling.py", line 66, in handler _error_if_any_worker_fails() RuntimeError: DataLoader worker (pid 2297896) is killed by signal: Aborted.
The above exception was the direct cause of the following exception:
Traceback (most recent call last): File "/home/liuyadong/.conda/envs/querydet/lib/python3.8/site-packages/detectron2/engine/train_loop.py", line 149, in train self.run_step() File "/home/liuyadong/.conda/envs/querydet/lib/python3.8/site-packages/detectron2/engine/defaults.py", line 494, in run_step self._trainer.run_step() File "/home/liuyadong/.conda/envs/querydet/lib/python3.8/site-packages/detectron2/engine/train_loop.py", line 391, in run_step data = next(self._data_loader_iter) File "/home/liuyadong/.conda/envs/querydet/lib/python3.8/site-packages/detectron2/data/common.py", line 234, in __iter__ for d in self.dataset: File "/home/liuyadong/.conda/envs/querydet/lib/python3.8/site-packages/torch/utils/data/dataloader.py", line 521, in __next__ data = self._next_data() File "/home/liuyadong/.conda/envs/querydet/lib/python3.8/site-packages/torch/utils/data/dataloader.py", line 1186, in _next_data idx, data = self._get_data() File "/home/liuyadong/.conda/envs/querydet/lib/python3.8/site-packages/torch/utils/data/dataloader.py", line 1152, in _get_data success, data = self._try_get_data() File "/home/liuyadong/.conda/envs/querydet/lib/python3.8/site-packages/torch/utils/data/dataloader.py", line 1003, in _try_get_data raise RuntimeError('DataLoader worker (pid(s) {}) exited unexpectedly'.format(pids_str)) from e RuntimeError: DataLoader worker (pid(s) 2297896) exited unexpectedly
禁用opencv的多线程再试试
 …
…
重新训练
python train_coco.py –config-file configs/coco/retinanet_train.yaml –num-gpu 1 –resume OUTPUT_DIR work_dirs/coco_retinanet
检查点开始 2张卡
python train_coco.py –config-file configs/coco/retinanet_train.yaml –num-gpu 2 MODEL.WEIGHTS work_dirs/coco_retinanet/model_0064999.pth OUTPUT_DIR work_dirs/coco_retinanet
 10小时
10小时
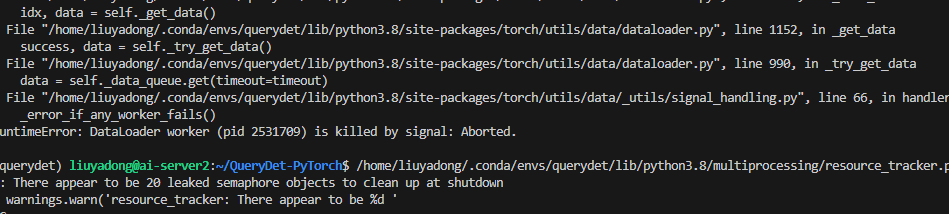

batch改为8试试
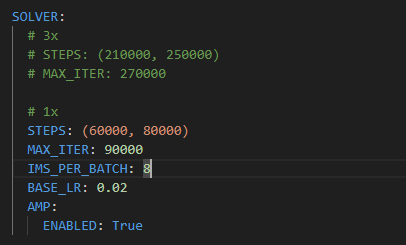
只要5小时

FloatingPointError: Loss became infinite or NaN at iteration=982!
训练结束
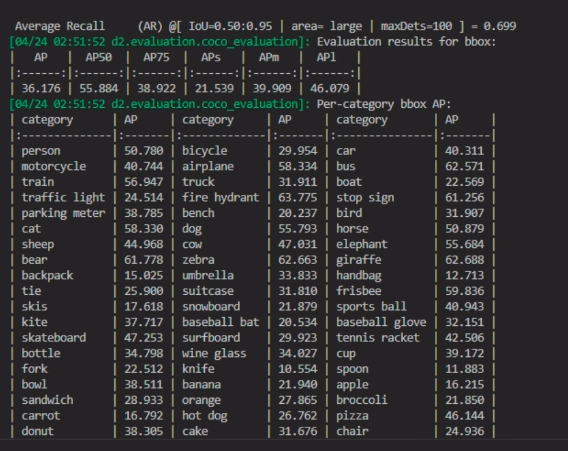
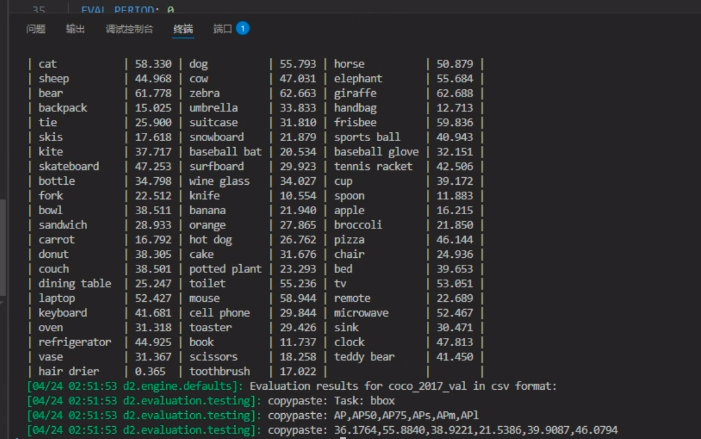
训练第二条
python train_coco.py –config-file configs/coco/querydet_train.yaml –num-gpu 2 OUTPUT_DIR work_dirs/coco_querydet

batch改成8 还是一样
设置分配32
importosimport os os.environ['PYTORCH_CUDA_ALLOC_CONF'] = 'max_split_size_mb:32'


同时设置终端
export PYTORCH_CUDA_ALLOC_CONF='max_split_size_mb:32'
设置opencv train_coco.py
训练还是报错
export PYTORCH_CUDA_ALLOC_CONF='max_split_size_mb:128'
清理

batch改8 可以跑了


终于找到num_works了 修改6处



训练试试
python train_coco.py –config-file configs/coco/querydet_train.yaml –num-gpu 2 OUTPUT_DIR work_dirs/coco_querydet
大功告成

报错outofmem
batch设为8 17小时

已杀死妈的
将num_works设为1试试 改detectron2的默认default

10速度最快
注释检查点置零



跑完


训练第三条 batch改16 num_works改2
python train_visdrone.py –config-file configs/visdrone/retinanet_train.yaml –num-gpu 2 OUTPUT_DIR work_dirs/visdrone_retinanet

把visdrone dataloader num_workers改了

 还是8
还是8
 2
2

训练完了 评估bash eval_visdrone.sh /path/to/visdrone_infer.json

bash eval_visdrone.sh work_dirs/visdrone_retinanet/visdrone_infer.json

安装评估工具pip install -e .

先训练第4条
python train_visdrone.py –config-file configs/visdrone/querydet_train.pyaml –num-gpu 2 OUTPUT_DIR work_dirs/visdrone_querydet

12半小时

— Process 0 terminated with the following error: Traceback (most recent call last): File "/home/liuyadong/.conda/envs/querydet/lib/python3.8/site-packages/torch/multiprocessing/spawn.py", line 59, in _wrap fn(i, *args) File "/home/liuyadong/.conda/envs/querydet/lib/python3.8/site-packages/detectron2/engine/launch.py", line 126, in _distributed_worker main_func(*args) File "/home/liuyadong/QueryDet-PyTorch/train_tools/visdrone_train.py", line 250, in start_train return trainer.train() File "/home/liuyadong/.conda/envs/querydet/lib/python3.8/site-packages/detectron2/engine/defaults.py", line 484, in train super().train(self.start_iter, self.max_iter) File "/home/liuyadong/.conda/envs/querydet/lib/python3.8/site-packages/detectron2/engine/train_loop.py", line 149, in train self.run_step() File "/home/liuyadong/.conda/envs/querydet/lib/python3.8/site-packages/detectron2/engine/defaults.py", line 494, in run_step self._trainer.run_step() File "/home/liuyadong/.conda/envs/querydet/lib/python3.8/site-packages/detectron2/engine/train_loop.py", line 405, in run_step self._write_metrics(loss_dict, data_time) File "/home/liuyadong/.conda/envs/querydet/lib/python3.8/site-packages/detectron2/engine/train_loop.py", line 302, in _write_metrics SimpleTrainer.write_metrics(loss_dict, data_time, prefix) File "/home/liuyadong/.conda/envs/querydet/lib/python3.8/site-packages/detectron2/engine/train_loop.py", line 338, in write_metrics raise FloatingPointError( FloatingPointError: Loss became infinite or NaN at iteration=665! loss_dict = {'loss_cls': 1.8113356828689575, 'loss_box_reg': 6.629820704460144, 'loss_query': nan}
重新训练剩4小时已杀死妈的
num_workers改为1试试
使用gemini方案试试,看看参数能不能继续使用

原代码
def __init__(self, cfg, resume=False, reuse_ckpt=False):
"""
Args:
cfg (CfgNode):
"""
super(DefaultTrainer, self).__init__()
logger = logging.getLogger("detectron2")
if not logger.isEnabledFor(logging.INFO): # setup_logger is not called for d2
setup_logger()
cfg = DefaultTrainer.auto_scale_workers(cfg, comm.get_world_size())
# Assume these objects must be constructed in this order.
model = self.build_model(cfg)
ckpt = DetectionCheckpointer(model)
self.start_iter = 0
self.start_iter = ckpt.resume_or_load(cfg.MODEL.WEIGHTS, resume=resume).get("iteration", -1) + 1
self.iter =self.start_iter
optimizer = self.build_optimizer(cfg, model)
data_loader = self.build_train_loader(cfg)
# For training, wrap with DDP. But don't need this for inference.
if comm.get_world_size() > 1:
model = DistributedDataParallel(
model, device_ids=[comm.get_local_rank()], broadcast_buffers=False
)
self._trainer = (AMPTrainer if cfg.SOLVER.AMP.ENABLED else SimpleTrainer)(
model, data_loader, optimizer
)
self.scheduler = self.build_lr_scheduler(cfg, optimizer)
self.checkpointer = DetectionCheckpointer(
model,
cfg.OUTPUT_DIR,
optimizer=optimizer,
scheduler=self.scheduler,
)
self.start_iter = 0
self.max_iter = cfg.SOLVER.MAX_ITER
self.cfg = cfg
self.register_hooks(self.build_hooks())
改后代码
def __init__(self, cfg, resume=False, reuse_ckpt=False): # 注意这里传入 resume 标志
"""
Args:
cfg (CfgNode):
resume (bool): Whether to resume from the checkpoint directory.
Passed from the command line args.resume.
"""
# super(DefaultTrainer, self).__init__() # 调用父类的 __init__ 不是标准做法,通常直接写逻辑
logger = logging.getLogger("detectron2")
# setup_logger is handled by default_setup, no need to call here usually
# if not logger.isEnabledFor(logging.INFO):
# setup_logger()
cfg = DefaultTrainer.auto_scale_workers(cfg, comm.get_world_size())
# 1. 构建模型
model = self.build_model(cfg)
# 2. 构建优化器
optimizer = self.build_optimizer(cfg, model)
# 3. 构建数据加载器
data_loader = self.build_train_loader(cfg)
# — 处理分布式训练 —
if comm.get_world_size() > 1:
model = DistributedDataParallel(
model, device_ids=[comm.get_local_rank()], broadcast_buffers=False
)
# ——————–
# 4. 初始化底层的 Trainer (SimpleTrainer or AMPTrainer)
# 注意:这里先不传递 optimizer,因为 resume_or_load 可能会加载优化器状态覆盖它
self._trainer = (AMPTrainer if cfg.SOLVER.AMP.ENABLED else SimpleTrainer)(
model, data_loader, optimizer # 优化器在这里传递是 Detectron2 的标准做法
)
# 5. 构建学习率调度器
self.scheduler = self.build_lr_scheduler(cfg, optimizer)
# 6. 构建 Checkpointer (关联模型、优化器、调度器)
self.checkpointer = DetectionCheckpointer(
model,
cfg.OUTPUT_DIR,
optimizer=optimizer,
scheduler=self.scheduler,
)
# 7. 加载检查点或预训练权重,并获取起始迭代次数
# resume_or_load 会处理 resume=True 的情况 (加载最新检查点)
# 和 resume=False 的情况 (加载 cfg.MODEL.WEIGHTS)
# 它会正确地加载模型、优化器、调度器状态(如果 resume=True 且检查点存在)
checkpoint_data = self.checkpointer.resume_or_load(cfg.MODEL.WEIGHTS, resume=resume)
# — 处理分布式 resume 时的同步 —
if resume and self.checkpointer.has_checkpoint():
# checkpoint.get("iteration", -1) 返回的是刚完成的迭代,所以+1
self.start_iter = checkpoint_data.get("iteration", -1) + 1
else:
# 如果不是 resume 或没有检查点,则从 0 开始
self.start_iter = 0
# 确保所有 rank 的 start_iter 一致
if comm.get_world_size() > 1:
self.start_iter = comm.all_gather(self.start_iter)[0]
# ——————————-
# 8. 设置最大迭代次数
self.max_iter = cfg.SOLVER.MAX_ITER
# 9. 保存配置
self.cfg = cfg
# 10. 注册训练钩子 (Hooks)
self.register_hooks(self.build_hooks())
# — 不再需要单独的 resume_or_load 方法,逻辑已合并到 __init__ —
# def resume_or_load(self, resume=True):
# … (可以删除这个方法) …
# — 其他方法保持不变 —

报错
采纳试试

报错

采纳试试

能正常运行,但是速度很慢,而且时间很长,每次输出了2轮,之前都只输出一轮的
[04/27 10:26:09 d2.utils.events]: eta: 14:00:17 iter: 30019 total_loss: 0.8324 loss_cls: 0.4716 loss_box_reg: 0.3239 loss_query: 0.02985 time: 2.5858 data_time: 0.0037 lr: 0.001 max_mem: 20413M [04/27 10:26:09 d2.utils.events]: eta: 13:58:30 iter: 30019 total_loss: 0.8324 loss_cls: 0.4716 loss_box_reg: 0.3239 loss_query: 0.02985 time: 2.5831 data_time: 0.0037 lr: 0.001 max_mem: 20413M [04/27 10:26:58 d2.utils.events]: eta: 13:52:30 iter: 30039 total_loss: 0.4814 loss_cls: 0.2563 loss_box_reg: 0.1968 loss_query: 0.02421 time: 2.5382 data_time: 0.0034 lr: 0.001 max_mem: 20413M [04/27 10:26:58 d2.utils.events]: eta: 13:51:39 iter: 30039 total_loss: 0.4814 loss_cls: 0.2563 loss_box_reg: 0.1968 loss_query: 0.02421 time: 2.5372 data_time: 0.0034 lr: 0.001 max_mem: 20413M [04/27 10:27:49 d2.utils.events]: eta: 13:55:01 iter: 30059 total_loss: 0.5486 loss_cls: 0.3166 loss_box_reg: 0.2069 loss_query: 0.02835 time: 2.5330 data_time: 0.0035 lr: 0.001 max_mem: 20413M [04/27 10:27:49 d2.utils.events]: eta: 13:54:52 iter: 30059 total_loss: 0.5486 loss_cls: 0.3166 loss_box_reg: 0.2069 loss_query: 0.02835 time: 2.5324 data_time: 0.0035 lr: 0.001 max_mem: 20413M [04/27 10:28:39 d2.utils.events]: eta: 13:51:56 iter: 30079 total_loss: 0.4665 loss_cls: 0.2634 loss_box_reg: 0.1752 loss_query: 0.02661 time: 2.5200 data_time: 0.0034 lr: 0.001 max_mem: 20413M [04/27 10:28:39 d2.utils.events]: eta: 13:51:40 iter: 30079 total_loss: 0.4665 loss_cls: 0.2634 loss_box_reg: 0.1752 loss_query: 0.02661 time: 2.5194 data_time: 0.0034 lr: 0.001 max_mem: 20413M [04/27 10:29:29 d2.utils.events]: eta: 13:51:06 iter: 30099 total_loss: 0.4453 loss_cls: 0.2529 loss_box_reg: 0.1687 loss_query: 0.02287 time: 2.5201 data_time: 0.0036 lr: 0.001 max_mem: 20413M [04/27 10:29:29 d2.utils.events]: eta: 13:50:50 iter: 30099 total_loss: 0.4453 loss_cls: 0.2529 loss_box_reg: 0.1687 loss_query: 0.02287 time: 2.5196 data_time: 0.0036 lr: 0.001 max_mem: 20413M
把问题丢给gemini 他说


把之前采纳的注释掉,然后采取gemini方案



手动注册后,确实不会输出两次重复的了,但是速度还是很慢
采用他之前的解决方案试试
原代码
def __init__(self, cfg, resume=False, reuse_ckpt=False): # 注意这里传入 resume 标志
"""
Args:
cfg (CfgNode):
resume (bool): Whether to resume from the checkpoint directory.
Passed from the command line args.resume.
"""
# super().__init__(cfg) # 正确调用父类初始化方法
logger = logging.getLogger("detectron2")
# setup_logger is handled by default_setup, no need to call here usually
# if not logger.isEnabledFor(logging.INFO):
# setup_logger()
cfg = DefaultTrainer.auto_scale_workers(cfg, comm.get_world_size())
# 1. 构建模型
model = self.build_model(cfg)
# 2. 构建优化器
optimizer = self.build_optimizer(cfg, model)
# 3. 构建数据加载器
data_loader = self.build_train_loader(cfg)
# — 处理分布式训练 —
if comm.get_world_size() > 1:
model = DistributedDataParallel(
model, device_ids=[comm.get_local_rank()], broadcast_buffers=False
)
# ——————–
# 4. 初始化底层的 Trainer (SimpleTrainer or AMPTrainer)
# 注意:这里先不传递 optimizer,因为 resume_or_load 可能会加载优化器状态覆盖它
self._trainer = (AMPTrainer if cfg.SOLVER.AMP.ENABLED else SimpleTrainer)(
model, data_loader, optimizer # 优化器在这里传递是 Detectron2 的标准做法
)
# 5. 构建学习率调度器
self.scheduler = self.build_lr_scheduler(cfg, optimizer)
# 6. 构建 Checkpointer (关联模型、优化器、调度器)
self.checkpointer = DetectionCheckpointer(
model,
cfg.OUTPUT_DIR,
optimizer=optimizer,
scheduler=self.scheduler,
)
# 7. 加载检查点或预训练权重,并获取起始迭代次数
# resume_or_load 会处理 resume=True 的情况 (加载最新检查点)
# 和 resume=False 的情况 (加载 cfg.MODEL.WEIGHTS)
# 它会正确地加载模型、优化器、调度器状态(如果 resume=True 且检查点存在)
checkpoint_data = self.checkpointer.resume_or_load(cfg.MODEL.WEIGHTS, resume=resume)
# — 处理分布式 resume 时的同步 —
if resume and self.checkpointer.has_checkpoint():
# checkpoint.get("iteration", -1) 返回的是刚完成的迭代,所以+1
self.start_iter = checkpoint_data.get("iteration", -1) + 1
else:
# 如果不是 resume 或没有检查点,则从 0 开始
self.start_iter = 0
# 确保所有 rank 的 start_iter 一致
if comm.get_world_size() > 1:
self.start_iter = comm.all_gather(self.start_iter)[0]
# ——————————-
# 8. 设置最大迭代次数
self.max_iter = cfg.SOLVER.MAX_ITER
# 9. 保存配置
self.cfg = cfg
# — FIX: Manually initialize the _hooks list —
self._hooks = []
# ————————————————-
# 10. 注册训练钩子 (Hooks)
self.register_hooks(self.build_hooks())
# — 不再需要单独的 resume_or_load 方法,逻辑已合并到 __init__ —
# def resume_or_load(self, resume=True):
# … (可以删除这个方法) …
# — 其他方法保持不变 —
修改后
运行报错

缩进不对
手动修改试试

并且把注释掉的恢复

还是报错

采用gemin试试

改之前
trainer = Trainer(cfg, resume=args.resume, reuse_ckpt=args.no_pretrain)
return trainer.train()
改后
# 1. 创建 Trainer 实例,只传递 cfg
trainer = Trainer(cfg)
# 2. 在创建实例后,调用 resume_or_load 方法处理恢复逻辑
# 将命令行传入的 resume 标志用在这里!
trainer.resume_or_load(resume=args.resume)
# 3. 开始训练
return trainer.train()

改完报错

恢复到训练很慢,但是不重复输出那一步
改试试

恢复init代码,取消注释resumeload
从0开始训练还报错oom
试一下
改之前

改之后

改visdrone_train.py 改之前和原原原代码一样
改之后
class Trainer(DefaultTrainer):
"""
用于 VisDrone 的自定义 Trainer 类,继承自 DefaultTrainer。
重写了数据加载和评估方法。
"""
# __init__ 方法继承自 DefaultTrainer
# resume_or_load 方法继承自 DefaultTrainer
@classmethod
def build_evaluator(cls, cfg, dataset_name, output_folder=None):
"""
为 VisDrone 数据集构建评估器。
创建一个用于保存检测结果的 JSON 文件。
可选地添加 GPU 时间评估器。
"""
if output_folder is None:
# 默认输出文件夹位于主输出目录下
output_folder = os.path.join(cfg.OUTPUT_DIR, "inference")
os.makedirs(output_folder, exist_ok=True) # 确保文件夹存在
evaluator_list = []
# 使用 JsonEvaluator 保存 COCO JSON 格式的检测结果,适用于 VisDrone 的评估脚本
evaluator_list.append(JsonEvaluator(os.path.join(output_folder, 'visdrone_infer.json'))) #
if cfg.META_INFO.EVAL_GPU_TIME: #
# 如果配置了,添加一个评估器来测量 GPU 推理时间
evaluator_list.append(GPUTimeEvaluator(True, 'minisecond')) #
# 返回一个包含所有指定评估器的 DatasetEvaluators 对象
return DatasetEvaluators(evaluator_list)
@classmethod
def build_train_loader(cls, cfg):
"""
使用自定义的 VisDrone 加载器构建用于训练的数据加载器。
"""
# 使用 VisDrone 训练数据的特定数据加载器实现
return build_train_loader(cfg) #
@classmethod
def build_test_loader(cls, cfg, dataset_name):
"""
使用自定义的 VisDrone 加载器构建用于测试/验证的数据加载器。
注意:如果配置已经指定了测试数据集的详细信息,`dataset_name` 可能不是必需的。
"""
# 使用 VisDrone 测试/验证数据的特定数据加载器实现
return build_test_loader(cfg) #
@classmethod
def test(cls, cfg, model, evaluators=None):
"""
在 VisDrone 测试数据集上运行推理。
Args:
cfg: Detectron2 配置对象。
model: 用于推理的已训练模型。
evaluators: 可选;如果为 None,则使用 `build_evaluator` 构建的评估器。
Returns:
一个空列表,因为结果由 JsonEvaluator 保存到文件中。
(Detectron2 的标准 test 返回一个字典,但这里我们专注于文件输出)。
"""
logger = logging.getLogger(__name__)
# 假设 'VisDrone_Test' 或类似名称是测试数据集的注册名称
# 如果 build_test_loader 完全依赖于 cfg,则此名称可能不会直接使用
dataset_name = 'VisDrone_Test' # 占位符名称,实际数据来自 cfg
# 使用自定义方法构建测试数据加载器
data_loader = cls.build_test_loader(cfg, dataset_name)
# 使用自定义方法构建评估器
if evaluators is None:
evaluators = cls.build_evaluator(cfg, dataset_name)
# 使用 detectron2 的工具函数运行推理
results = inference_on_dataset(model, data_loader, evaluators)
# 标准的 detectron2 结果验证(可选,但是好的实践)
# verify_results(cfg, results) # 如果需要可以启用
# 返回空列表,因为结果被 JsonEvaluator 保存到文件
return []
# 注意:default_argument_parser, setup, 和 launch 逻辑通常位于
# 你的主脚本(例如 train_visdrone.py)中,而不是通常在 Trainer 定义文件内部。
报错oom 训练从1开始
恢复到很慢那一步 逆天

bc改为4 11小时,训练完成


测试
python infer_coco.py –config-file configs/coco/retinanet_test.yaml –num-gpu 2 –eval-only MODEL.WEIGHTS work_dirs/coco_retinanet/model_final.pth OUTPUT_DIR work_dirs/model_test
报错Traceback (most recent call last): File "infer_coco.py", line 4, in <module> from train_tools.coco_infer import default_argument_parser, start_train File "/home/liuyadong/QueryDet-PyTorch/train_tools/coco_infer.py", line 45, in <module> from detectron2_backbone.config import add_backbone_config ModuleNotFoundError: No module named 'detectron2_backbone'
运行
git clone https://github.com/sxhxliang/detectron2_backbone.git
cd detectron2_backbone
python setup.py build develop
error: numpy 1.18.5 is installed but numpy<2,>=1.20 is required by {'matplotlib'}
pip install –upgrade "numpy>=1.20,<2.0"
推理结束 和第一次训练一样


运行
python infer_coco.py –config-file configs/coco/querydet_test.yaml –num-gpu 2 –eval-only MODEL.WEIGHTS work_dirs/coco_querydet/model_final.pth OUTPUT_DIR work_dirs/model_test
报错
添加

推理结束


666

需要重新训练

跳过CSQ![]()
第三条
python infer_coco.py –config-file configs/visdrone/retinanet_test.yaml –num-gpu 2 –eval-only MODEL.WEIGHTS work_dirs/visdrone_retinanet/model_final.pth OUTPUT_DIR work_dirs/model_test
逆天




修改测试命令
—————————————-VISdrone————————————————————-
评估基线模型retinanet
python infer_visdrone.py –config-file configs/visdrone/retinanet_test.yaml –num-gpu 2 –eval-only MODEL.WEIGHTS work_dirs/visdrone_retinanet/model_final.pth OUTPUT_DIR work_dirs/model_test
报错找不到

改绝对路径
python infer_visdrone.py –config-file configs/visdrone/retinanet_test.yaml –num-gpu 2 –eval-only MODEL.WEIGHTS /home/liuyadong/QueryDet-PyTorch/work_dirs/visdrone_retinanet/model_final.pth OUTPUT_DIR work_dirs/model_test
可以了

运行bash eval_visdrone.sh work_dirs/model_test/visdrone_infer.json评估
报错

修改这里

评估结束

评估querydet visdrone
python infer_visdrone.py –config-file configs/visdrone/querydet_test.yaml –num-gpu 2 –eval-only MODEL.WEIGHTS work_dirs/visdrone_querydet/model_final.pth OUTPUT_DIR work_dirs/model_test

评估bash eval_visdrone.sh work_dirs/model_test/visdrone_infer.json
基线模型结果和querydet结果都比论文好




评估一下加CSQ的vis
export SPCONV_FILTER_HWIO="1"; python infer_visdrone.py –config-file configs/visdrone/querydet_test.yaml –num-gpu 2 –eval-only MODEL.WEIGHTS work_dirs/visdrone_querydet/model_final.pth OUTPUT_DIR work_dirs/model_test MODEL.QUERY.QUERY_INFER True
报错Traceback (most recent call last): File "infer_visdrone.py", line 4, in <module> from train_tools.visdrone_infer import default_argument_parser, start_train File "/home/liuyadong/QueryDet-PyTorch/train_tools/visdrone_infer.py", line 47, in <module> from models.querydet.detector import RetinaNetQueryDet File "/home/liuyadong/QueryDet-PyTorch/models/querydet/detector.py", line 38, in <module> import models.querydet.qinfer as qf File "/home/liuyadong/QueryDet-PyTorch/models/querydet/qinfer.py", line 4, in <module> import spconv.pytorch as spconv File "/home/liuyadong/.conda/envs/querydet/lib/python3.8/site-packages/spconv/__init__.py", line 15, in <module> from . import build as _build File "/home/liuyadong/.conda/envs/querydet/lib/python3.8/site-packages/spconv/build.py", line 21, in <module> from .constants import PACKAGE_NAME, PACKAGE_ROOT, DISABLE_JIT, SPCONV_INT8_DEBUG File "/home/liuyadong/.conda/envs/querydet/lib/python3.8/site-packages/spconv/constants.py", line 30, in <module> raise NotImplementedError("SPCONV_FILTER_HWIO is deprecated. use SPCONV_SAVED_WEIGHT_LAYOUT instead.") NotImplementedError: SPCONV_FILTER_HWIO is deprecated. use SPCONV_SAVED_WEIGHT_LAYOUT instead.
先取消
unset SPCONV_FILTER_HWIO
在运行
export SPCONV_SAVED_WEIGHT_LAYOUT="RSCK"

python infer_visdrone.py –config-file configs/visdrone/querydet_test.yaml –num-gpu 2 –eval-only MODEL.WEIGHTS work_dirs/visdrone_querydet/model_final.pth OUTPUT_DIR work_dirs/model_test_csq MODEL.QUERY.QUERY_INFER True
报错



评估FPS

AP 运行bash eval_visdrone.sh work_dirs/model_test_csq/visdrone_infer.json

结果分析


————————————————————————————————————–
接下来,重新训练COCO 带query的 之前训练结果有问题
batch=4 num_workers=2
python train_coco.py –config-file configs/coco/querydet_train.yaml –num-gpu 2 OUTPUT_DIR work_dirs/coco_querydet
8小时 batch改8试试 16小时….
改6试试 12小时….
还是改4
跑完了




看看带CSQ的
python infer_coco.py –config-file configs/coco/querydet_test.yaml –num-gpu 2 –eval-only MODEL.WEIGHTS work_dirs/coco_querydet/model_final.pth OUTPUT_DIR work_dirs/model_test MODEL.QUERY.QUERY_INFER True


寄



评论前必须登录!
注册