 网硕互联帮助中心
网硕互联帮助中心llama-2大模型结构
llama大模型是Meta公司开源的大语言模型,目前最新的为llama3.1参数量达到了405B,非常恐怖
以7B模型为例,梳理llama-2的模型结构,重点关注其对传统Transformer模型的结构修改
LlamaConfig {
"_name_or_path": "llama2/llama-2-7b",
"architectures": [
"LlamaForCausalLM"
],
"attention_bias": false,
"bos_token_id": 1,
"eos_token_id": 2,
"hidden_act": "silu",
"hidden_size": 4096,
"initializer_range": 0.02,
"intermediate_size": 11008,
"max_position_embeddings": 2048,
"model_type": "llama",
"num_attention_heads": 32,
"num_hidden_layers": 32,
"num_key_value_heads": 32,
"pad_token_id": 0,
"pretraining_tp": 1,
"rms_norm_eps": 1e-05,
"rope_scaling": null,
"rope_theta": 10000.0,
"tie_word_embeddings": false,
"torch_dtype": "bfloat16",
"transformers_version": "4.31.0",
"use_cache": true,
"vocab_size": 32000
}
从上述config文件可以看到,
- llama2 采用的激活函数是 silu
- 词表大小为 32000
- 预训练参数的数据类型是 bfloat16
Pytorch定义好模型后,print(model) 的输出:
LlamaForCausalLM(
(model): LlamaModel(
(embed_tokens): Embedding(32000, 4096, padding_idx=0)
(layers): ModuleList(
(0–31): 32 x LlamaDecoderLayer(
(self_attn): LlamaAttention(
(q_proj): Linear(in_features=4096, out_features=4096, bias=False)
(k_proj): Linear(in_features=4096, out_features=4096, bias=False)
(v_proj): Linear(in_features=4096, out_features=4096, bias=False)
(o_proj): Linear(in_features=4096, out_features=4096, bias=False)
(rotary_emb): LlamaRotaryEmbedding()
)
(mlp): LlamaMLP(
(gate_proj): Linear(in_features=4096, out_features=11008, bias=False)
(up_proj): Linear(in_features=4096, out_features=11008, bias=False)
(down_proj): Linear(in_features=11008, out_features=4096, bias=False)
(act_fn): SiLUActivation()
)
(input_layernorm): LlamaRMSNorm()
(post_attention_layernorm): LlamaRMSNorm()
)
)
(norm): LlamaRMSNorm()
)
(lm_head): Linear(in_features=4096, out_features=32000, bias=False)
)
可以看到 LLama-2 7b 是由 32 个 LLamaDecoderLayer 堆叠而成;
LLamaDecoderLayer 结构图: 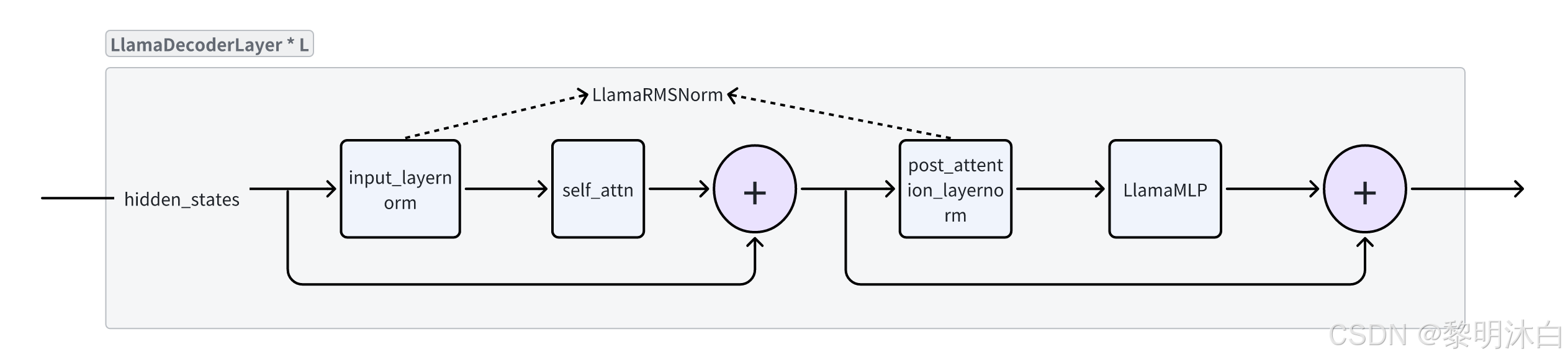 LLama中采用了 RMSNorm 而非传统的 LayerNorm;
LLama中采用了 RMSNorm 而非传统的 LayerNorm;
LLamaAttention结构图: 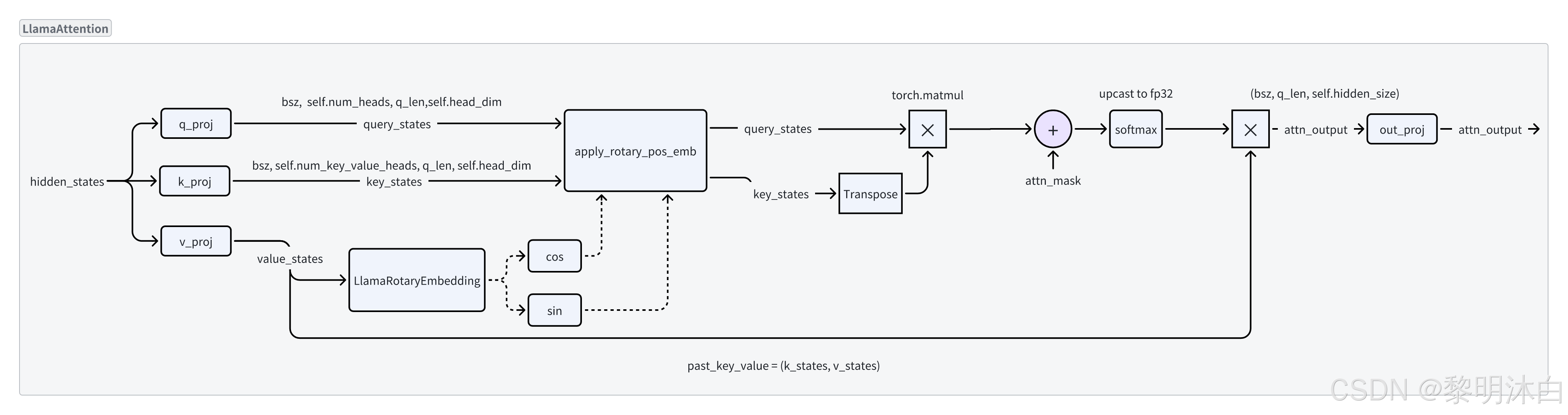 LLama将传统Transformer中Transformer Block前的 position embedding 放入到了 Transformer Block中;
LLama将传统Transformer中Transformer Block前的 position embedding 放入到了 Transformer Block中;
并且采用了 LlamaRotaryEmbedding ;
LLamaMLP结构: 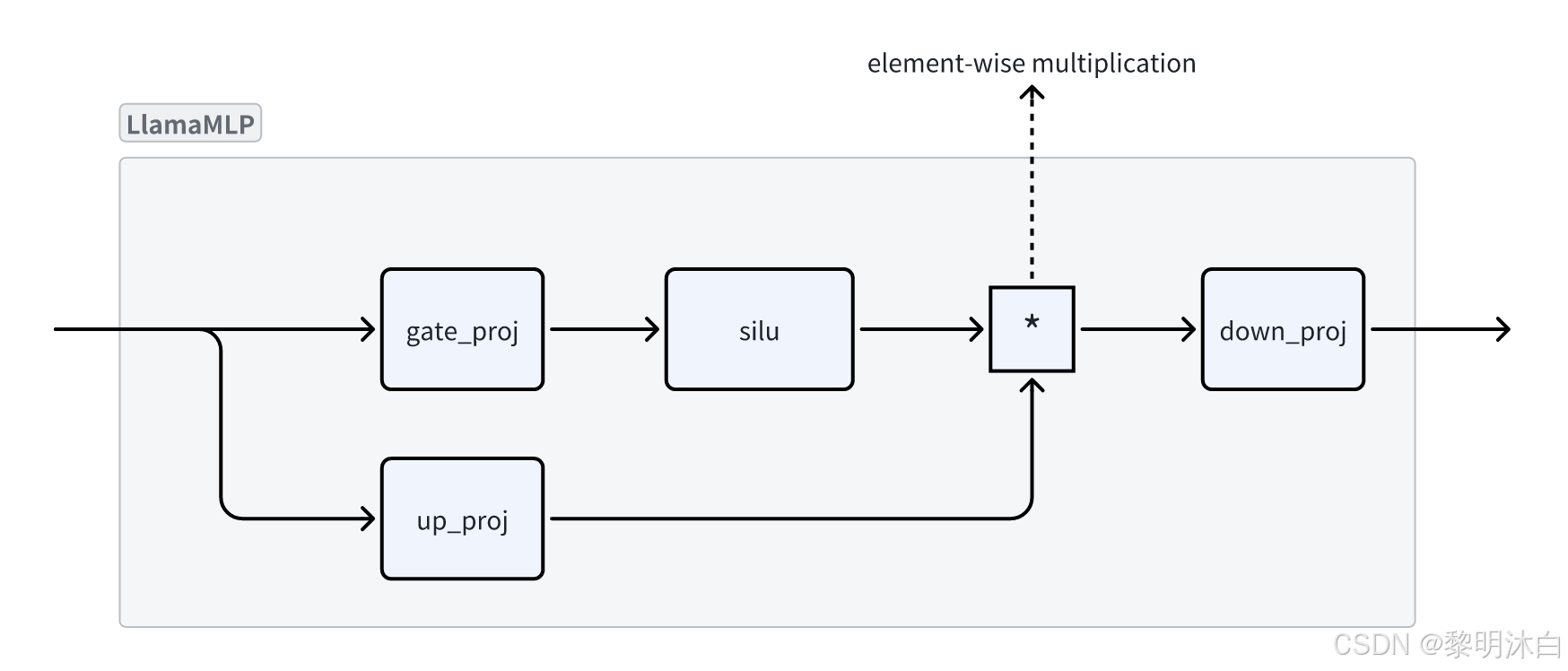 对MLP结果也做了修改;
对MLP结果也做了修改;
传统的MLP只包含两个FC层,第一个FC层后有激活函数,第一个FC层起到了隐式地 gating 作用;
而,LLamaMLP中引入了显式地 gate_proj 层,其后接激活函数,其结果与 up_proj 进行 element-wise 乘法,起到 gating 的作用;



评论前必须登录!
注册