 网硕互联帮助中心
网硕互联帮助中心1.鲲鹏处理器和Intel处理器的区别
| 处理器/对比项 | Intel | Kunpeng |
| 厂家 | 因特尔(美国) | 华为(中国) |
| 指令集 | X86架构 | ARM-V8 |
| 架构与指令集 | – x86 CISC复杂指令集 – 单核性能强(如至强8380主频3.8GHz) – 三级缓存优化,支持DDR4-3200和Optane内存 | – ARMv8-A RISC精简指令集 – 64核设计(超线程至128线程) – 多级缓存优化,支持PCIe 4.0和高速内存 |
| 单核性能 | – 单核主频高(3.8GHz+),单线程性能强 | – 主频2.6GHz,NEON指令优化 |
| 多核性能 | 28~40核主流型号,依赖超线程优化多任务 | 64核整数运算性能领先33%(对比28核Intel) |
| 能效与功耗 | 10/14nm工艺,TDP较高(如至强8180达205W),但支持动态功耗优化 | 7nm工艺,TDP低,适合绿色数据中心 |
| 兼容性 | – 全球90%服务器生态支持 – 原生兼容Windows/Linux及专业软件(如Oracle、VMware) | – 依赖ARM生态适配(如欧拉OS) – 需二进制翻译运行x86应用 |
| 硬件扩展 | 支持PCIe 5.0和Optane持久内存 | 集成昇腾NPU和RoCEv2网络加速 |
| 典型应用场景 | – 高性能计算(HPC) – 实时性工业控制 – CUDA加速的深度学习 | – 云计算(高并发虚拟化) – AI推理/大数据处理 – 国产化数据中心 |
| 安全性 | – 依赖软件层安全(如SGX) – 全球化供应链风险 | – 硬件级加密引擎(HiSec 3.0) – 国产化供应链可控 |
2.欧拉系统系统
Intel服务器可以使用windows或者linux(centos、ubuntu等都可支持)。
首先是系统安装,鲲鹏服务器使用的是华为鲲鹏处理器,基于ARM架构,也可安装centos等,建议安装华为欧拉系统。
sudo dnf groupinstall "UKUI Desktop" # UKUI界面[5](@ref)
sudo systemctl set-default graphical.target # 默认启动图形模式
3.安装qt
qt我们使用5.9.8,当然其他版本也是OK的,因为服务器找不到对应的QT-ARM安装包。所以我们从源码编译:参考鲲鹏官方文档:
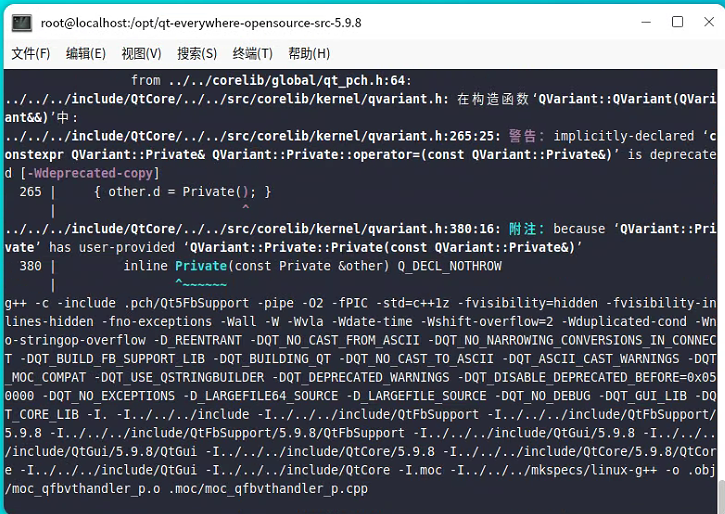
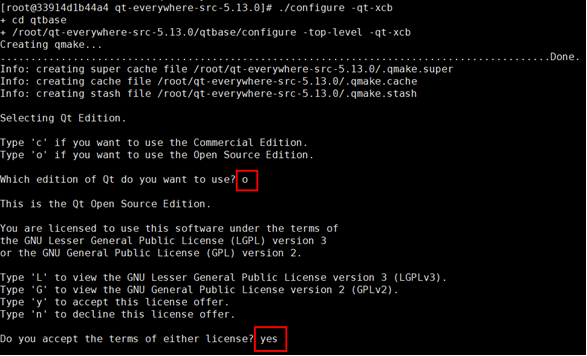
gmake install
export PATH=$QTDIR/bin:$PATH
export MANPATH=$QTDIR/man:$MANPATH
export LD_LIBRARY_PATH=$QTDIR/lib:$LD_LIBRARY_PATH
编译和安装-Qt 5.13.0 移植指南(openEuler 20.03)-生命科学-开源应用软件移植指南-HPC行业应用-鲲鹏HPC开发文档-鲲鹏社区
安装QT会有各种编译问题,需要挨个去网络上查找问题修改代码和宏定义解决
4安装svn或git等相关工具
yum install svn -y
5安装devkit工具查看迁移方案
从鲲鹏社区下载Devkit
鲲鹏DevKit开发套件-学习资源-鲲鹏社区
选择立即下载,然后解压安装包,其中“x.x.x”表示版本号,请用实际情况代替
tar –no-same-owner -zxvf DevKit-All-x.x.x-Linux-Kunpeng.tar.gz
安装 ,其中“x.x.x”表示版本号,请用实际情况代替
cd DevKit-All-x.x.x-Linux-Kunpeng
./install.sh
安装过程中有很多配置,具体见官方文档:安装-安装鲲鹏DevKit-WebUI-用户指南-鲲鹏开发套件开发文档-鲲鹏社区
安装后通过IP:8086访问WEBUI

通过devadmin和安装过程中设置的密码登录
可通过应用评估,选择对应操作系统,编译器版本额构建工具等,上传源码查看应用迁移建议
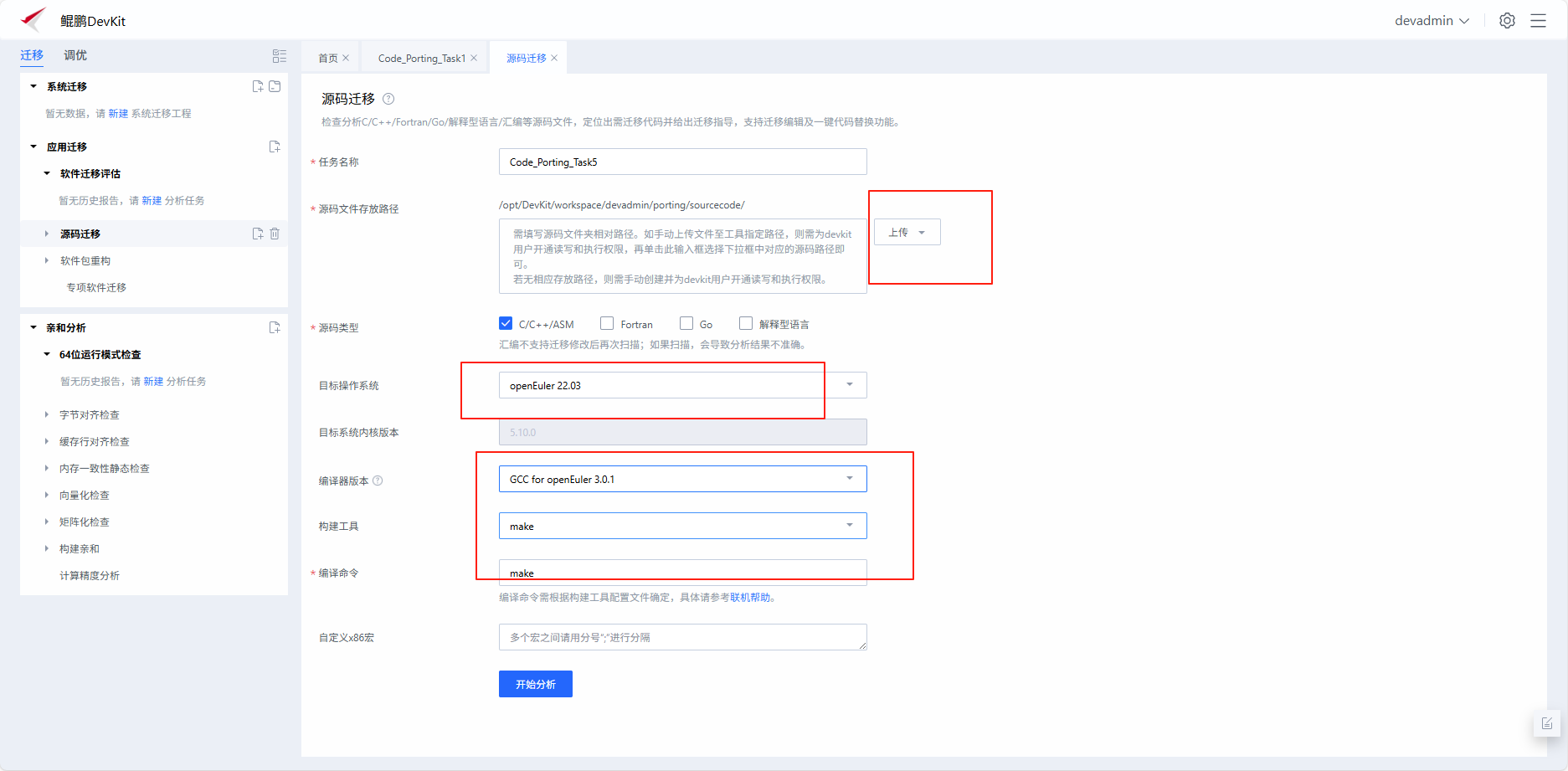
扫描完成后,查看依赖库可源码修改建议
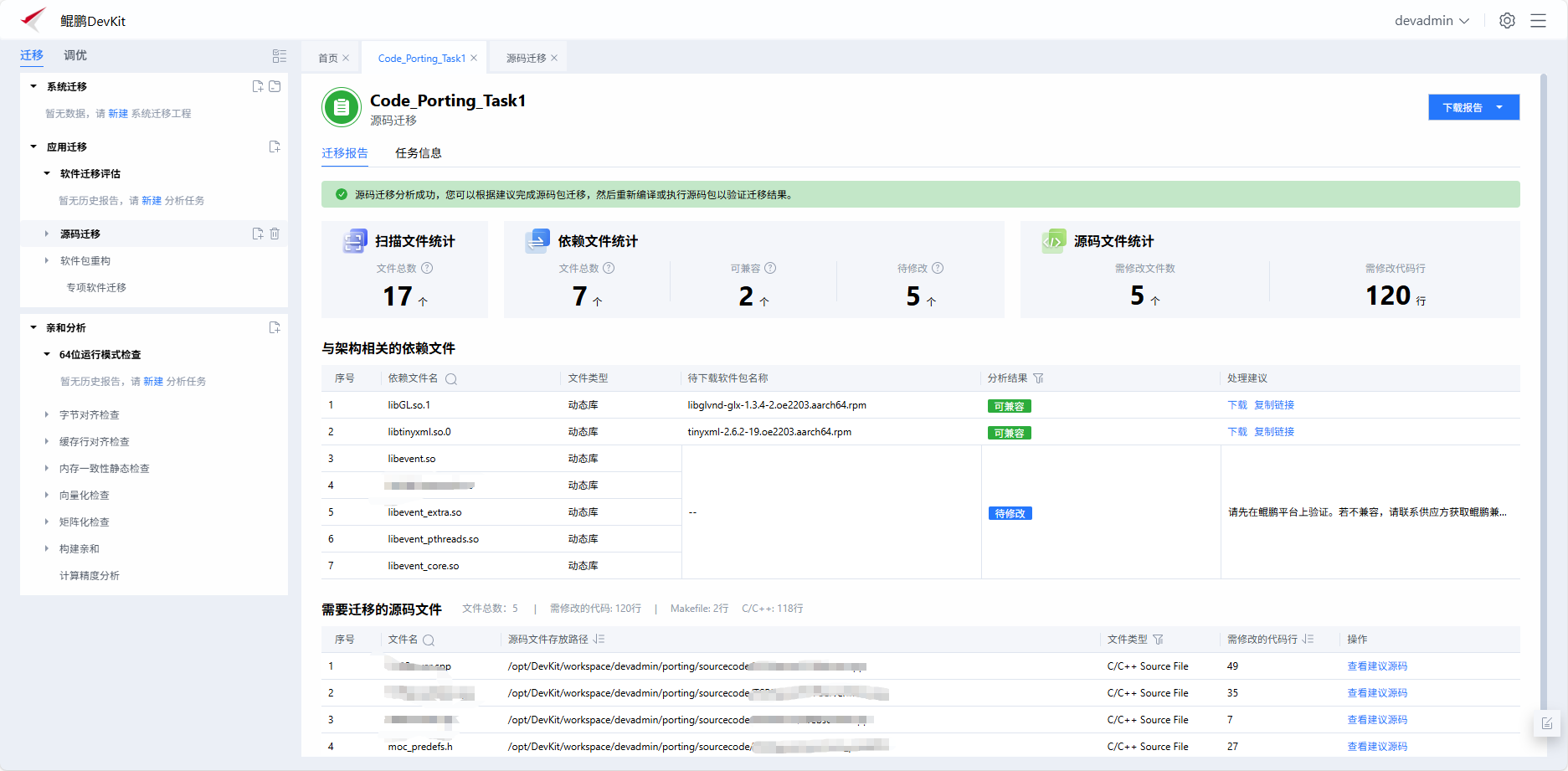
按照建议下载对应库和修改源码。
6.加速库替代
在程序中使用了大量Intel相关加速库,如ipp库
| Intel-ipp库接口定义 | 函数接口定义 |
| pp8u、Ipp32f、Ipp32fc等 | 数据类型: |
| ippsMalloc_32f等 | 开辟空间函数 |
| ippsFree | 空间释放函数 |
| ippsMeanStdDev_64f等 | 均值方差计算 |
| ippsSortAscend_64f_I等 | 排序 |
| ippsReplaceNAN_32f_I等 | 替换无效值 |
| ippsCplxToReal_32fc等 | FFT相关 |
| ippsPowerSpectr_32f等 | FFT相关 |
| ippsCopy_64fc等 | FFT相关 |
| ippsRealToCplx_64f | FFT相关 |
| ippsCplxToReal_64fc | FFT相关 |
| ippsDFTInit_C_64fc | FFT相关 |
| ippsDFTFwd_CToC_64fc | FFT相关 |
| ippsFFTFwd_CToC_64fc | FFT相关 |
参考文档定义,intel-ipp库专为intel服务器设计,鲲鹏基于鲲鹏处理器,这些函数全部要重新替代,查看鲲鹏服务器相关文档、发现鲲鹏服务器在FFT的计算上有KML-FFT库可对FFT进行加速计算。
函数说明-KML_FFT库函数说明-基础数学库-鲲鹏数学库 开发指南-开发指南-HPCKit-鲲鹏HPC开发文档-鲲鹏社区
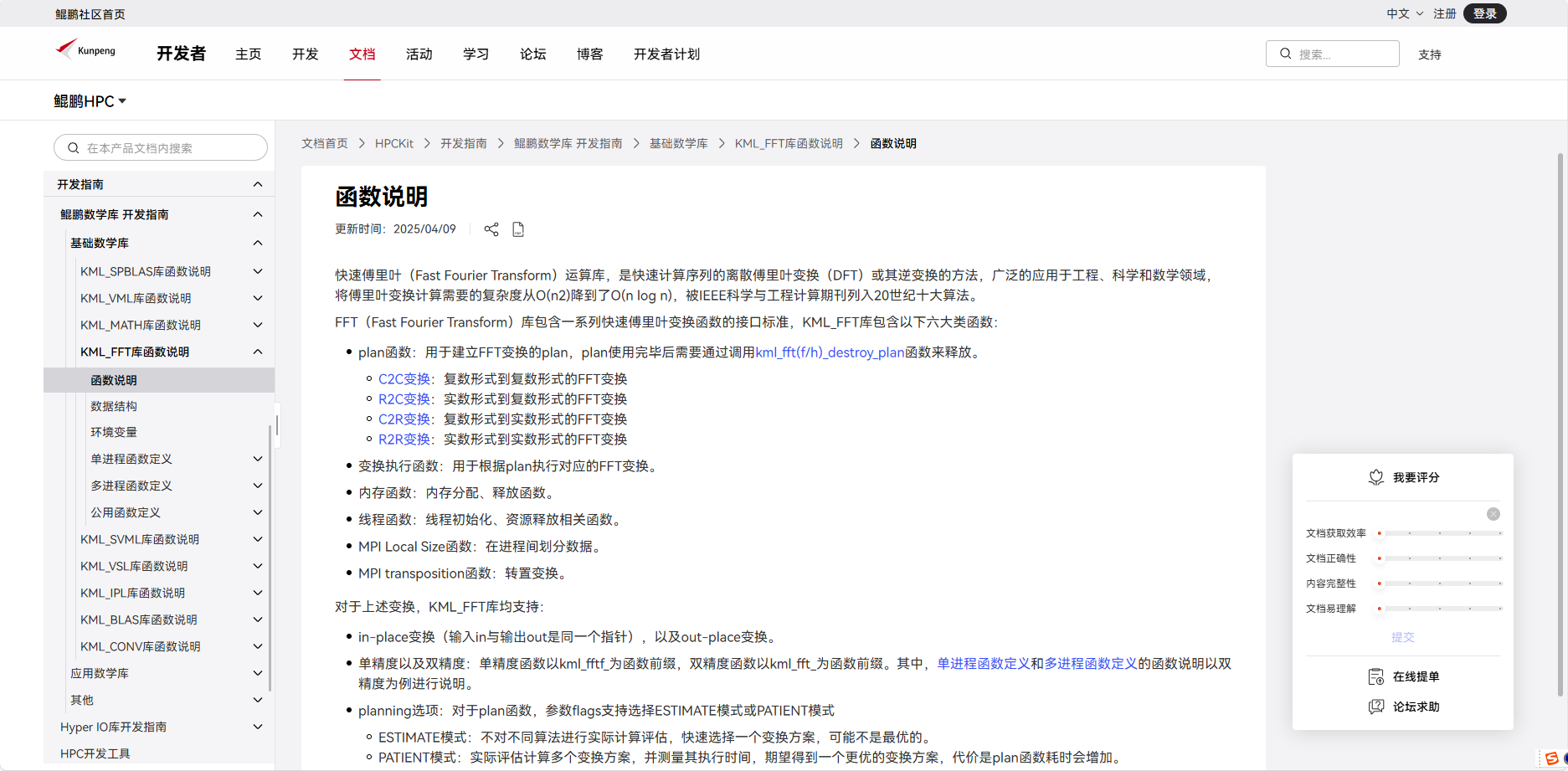
得、空间开辟用C++标准库替代,求和方差等可通过std库搞定,其他的通过KML-FFT替换。
现在要测试下Intel相关函数与标准c++提升了多少呢,代码如下:
#include <QCoreApplication>
#include <QElapsedTimer>
#include <iostream>
#include "./Include/ipp/ipp.h"
#include <cstring> // 标准库函数
#include <random>
#include <algorithm>
#include <iterator>
// Windows环境需要显式链接IPP库
#pragma comment(lib, "ippsmt.lib")
#pragma comment(lib, "ippcoremt.lib")
constexpr int SIZE = 1 << 20; // 1MB数据(262,144个float)
constexpr int TRIALS = 1000; // 测试次数
// 测试IPP函数
void testIPP() {
Ipp32f* src = nullptr, * dst = nullptr;
QElapsedTimer timer;
// 内存分配
timer.start();
for (int i = 0; i < TRIALS; ++i) {
src = ippsMalloc_32f(SIZE);
ippsFree(src);
}
auto mallocTime = timer.nsecsElapsed() / TRIALS;
// 内存赋值
src = ippsMalloc_32f(SIZE);
timer.start();
for (int i = 0; i < TRIALS; ++i) {
ippsSet_32f(3.14159f, src, SIZE);
}
auto setTime = timer.nsecsElapsed() / TRIALS;
ippsFree(src);
// 内存置零
src = ippsMalloc_32f(SIZE);
timer.start();
for (int i = 0; i < TRIALS; ++i) {
ippsZero_32f(src, SIZE);
}
auto zeroTime = timer.nsecsElapsed() / TRIALS;
ippsFree(src);
// 内存拷贝
src = ippsMalloc_32f(SIZE);
dst = ippsMalloc_32f(SIZE);
ippsSet_32f(2.71828f, src, SIZE);
timer.start();
for (int i = 0; i < TRIALS; ++i) {
ippsCopy_32f(src, dst, SIZE);
}
auto copyTime = timer.nsecsElapsed() / TRIALS;
ippsFree(src);
ippsFree(dst);
std::cout << "[IPP] Malloc: " << mallocTime << " ns\\n"
<< "[IPP] Set: " << setTime << " ns\\n"
<< "[IPP] Zero: " << zeroTime << " ns\\n"
<< "[IPP] Copy: " << copyTime << " ns\\n";
}
// 测试标准库
void testSTD() {
float* src = nullptr, * dst = nullptr;
QElapsedTimer timer;
// 内存分配
timer.start();
for (int i = 0; i < TRIALS; ++i) {
src = new float[SIZE];
delete[] src;
}
auto mallocTime = timer.nsecsElapsed() / TRIALS;
// 内存赋值(循环)
src = new float[SIZE];
timer.start();
for (int i = 0; i < TRIALS; ++i) {
#pragma omp simd for
for (int i = 0; i < SIZE; ++i)
src[i] = 3.14159f;
//std::fill_n(src, SIZE, 3.14159f);
}
auto setTime = timer.nsecsElapsed() / TRIALS;
delete[] src;
// 内存置零(memset)
src = new float[SIZE];
timer.start();
for (int i = 0; i < TRIALS; ++i) {
memset(src, 0, SIZE * sizeof(float));
}
auto zeroTime = timer.nsecsElapsed() / TRIALS;
delete[] src;
// 内存拷贝(memcpy)
src = new float[SIZE];
dst = new float[SIZE];
memset(src, 0, SIZE * sizeof(float));
timer.start();
for (int i = 0; i < TRIALS; ++i) {
memcpy(dst, src, SIZE * sizeof(float));
}
auto copyTime = timer.nsecsElapsed() / TRIALS;
delete[] src;
delete[] dst;
std::cout << "[STD] Malloc: " << mallocTime << " ns\\n"
<< "[STD] Set: " << setTime << " ns\\n"
<< "[STD] Zero: " << zeroTime << " ns\\n"
<< "[STD] Copy: " << copyTime << " ns\\n";
}
// 生成随机浮点数组
void generateRandomData(float* data, size_t size) {
std::random_device rd;
std::mt19937 gen(rd());
std::uniform_real_distribution<float> dist(0.0f, 1000.0f);
for (size_t i = 0; i < size; ++i) {
data[i] = dist(gen);
}
}
// 标准库计算均值与标准差
void stdMeanStdDev(const float* data, size_t size, float& mean, float& stdDev) {
double sum = 0.0, sumSq = 0.0;
for (size_t i = 0; i < size; ++i) {
sum += data[i];
sumSq += data[i] * data[i];
}
mean = sum / size;
stdDev = std::sqrt((sumSq – sum * sum / size) / (size – 1)); // 样本标准差
}
// 性能测试主函数
void performanceTest(size_t dataSize, int iterations) {
// 内存分配与数据初始化
Ipp32f* ippData = ippsMalloc_32f(dataSize);
std::vector<float> stdData(dataSize);
generateRandomData(ippData, dataSize);
std::copy(ippData, ippData + dataSize, stdData.begin());
// 预热缓存(可选)
std::sort(stdData.begin(), stdData.end());
// 测试排序性能
auto start = std::chrono::high_resolution_clock::now();
for (int i = 0; i < iterations; ++i) {
ippsSortAscend_32f_I(ippData, dataSize); // IPP原地排序
}
auto ippSortTime = std::chrono::duration_cast<std::chrono::milliseconds>(
std::chrono::high_resolution_clock::now() – start
).count();
start = std::chrono::high_resolution_clock::now();
for (int i = 0; i < iterations; ++i) {
std::sort(stdData.begin(), stdData.end()); // 标准库排序
}
auto stdSortTime = std::chrono::duration_cast<std::chrono::milliseconds>(
std::chrono::high_resolution_clock::now() – start
).count();
// 测试均值与标准差计算性能
float ippMean, ippStdDev;
start = std::chrono::high_resolution_clock::now();
for (int i = 0; i < iterations; ++i) {
ippsMeanStdDev_32f(ippData, dataSize, &ippMean, &ippStdDev, ippAlgHintFast); // IPP计算
}
auto ippStatTime = std::chrono::duration_cast<std::chrono::milliseconds>(
std::chrono::high_resolution_clock::now() – start
).count();
float stdMean, stdStdDev;
start = std::chrono::high_resolution_clock::now();
for (int i = 0; i < iterations; ++i) {
stdMeanStdDev(stdData.data(), dataSize, stdMean, stdStdDev); // 标准库计算
}
auto stdStatTime = std::chrono::duration_cast<std::chrono::milliseconds>(
std::chrono::high_resolution_clock::now() – start
).count();
// 输出结果
std::cout << "===== 性能对比 (数据量: " << dataSize << ", 迭代次数: " << iterations << ") =====\\n";
std::cout << "排序:\\n"
<< " IPP ippsSortAscend_32f_I: " << ippSortTime << " ms\\n"
<< " std::sort: " << stdSortTime << " ms\\n";
std::cout << "统计计算:\\n"
<< " IPP ippsMeanStdDev_32f: " << ippStatTime << " ms\\n"
<< " 标准库实现: " << stdStatTime << " ms\\n";
ippsFree(ippData);
}
int main(int argc, char* argv[])
{
QCoreApplication a(argc, argv);
std::cout << "=== Intel IPP Performance ===\\n";
testIPP();
std::cout << "\\n=== Standard Library Performance ===\\n";
testSTD();
performanceTest(1e6, 10); // 测试100万数据,迭代10次
return 0;
}
使用1000次对1MB数据(262,144个float)的效率对比。对比结果如下:
Windows系统Debug模式
=== Intel IPP Performance ===
[IPP] Malloc: 1293522 ns
[IPP] Set: 174418 ns
[IPP] Zero: 94937 ns
[IPP] Copy: 501033 ns
=== Standard Library Performance ===
[STD] Malloc: 1202868 ns
[STD] Set: 1940080 ns
[STD] Zero: 93922 ns
[STD] Copy: 190766 ns
===== 性能对比 (数据量: 1000000, 迭代次数: 10) =====
排序:
IPP ippsSortAscend_32f_I: 240 ms
std::sort: 1404 ms
统计计算:
IPP ippsMeanStdDev_32f: 2 ms
标准库实现: 26 ms
F:\\Workspace\\Code\\Qt\\TestIntelIpps\\x64\\Debug\\TestIntelIpps.exe (进程 21008)已退出,代码为 0 (0x0)。
要在调试停止时自动关闭控制台,请启用“工具”->“选项”->“调试”->“调试停止时自动关闭控制台”。
按任意键关闭此窗口. . .
Windows系统Release模式
=== Intel IPP Performance ===
[IPP] Malloc: 48886 ns
[IPP] Set: 301834 ns
[IPP] Zero: 87169 ns
[IPP] Copy: 544983 ns
=== Standard Library Performance ===
[STD] Malloc: 44820 ns
[STD] Set: 710 ns
[STD] Zero: 85777 ns
[STD] Copy: 211307 ns
===== 性能对比 (数据量: 1000000, 迭代次数: 10) =====
排序:
IPP ippsSortAscend_32f_I: 229 ms
std::sort: 109 ms
统计计算:
IPP ippsMeanStdDev_32f: 3 ms
标准库实现: 0 ms
F:\\Workspace\\Code\\Qt\\TestIntelIpps\\x64\\Release\\TestIntelIpps.exe (进程 26764)已退出,代码为 0 (0x0)。
要在调试停止时自动关闭控制台,请启用“工具”->“选项”->“调试”->“调试停止时自动关闭控制台”。
按任意键关闭此窗口. . .
Linux系统(Centos 7.9) Debug模式
=== Intel IPP Performance ===
[IPP] Malloc: 350 ns
[IPP] Set: 206298 ns
[IPP] Zero: 104632 ns
[IPP] Copy: 766895 ns
=== Standard Library Performance ===
[STD] Malloc: 145 ns
[STD] Set: 2213560 ns
[STD] Zero: 143366 ns
[STD] Copy: 837936 ns
===== 性能对比 (数据量: 1000000, 迭代次数: 10) =====
排序:
IPP ippsSortAscend_32f_I: 300 ms
std::sort: 1437 ms
统计计算:
IPP ippsMeanStdDev_32f: 3 ms
标准库实现: 31 ms
按 <RETURN> 来关闭窗口…
Linux系统(Centos 7.9) Release模式
=== Intel IPP Performance ===
[IPP] Malloc: 214 ns
[IPP] Set: 230157 ns
[IPP] Zero: 88688 ns
[IPP] Copy: 509544 ns
=== Standard Library Performance ===
[STD] Malloc: 42 ns
[STD] Set: 725504 ns
[STD] Zero: 274262 ns
[STD] Copy: 614060 ns
===== 性能对比 (数据量: 1000000, 迭代次数: 10) =====
排序:
IPP ippsSortAscend_32f_I: 231 ms
std::sort: 109 ms
统计计算:
IPP ippsMeanStdDev_32f: 3 ms
标准库实现: 12 ms
按 <RETURN> 来关闭窗口…
本机系统为Windows 11 专业版 24H2 CPU类型为Intel(R) Core(TM) i7-7700 CPU @ 3.60GHz 3.60 GHz。
综合对比下来,除Set外、其余函数标准库优化相当不错。接近与IPP库的性能。而SET函数IPP库有10倍以上的速度提升。
好像也可以接受,接下下开始验证FFT。
查看官网说明,天塌了
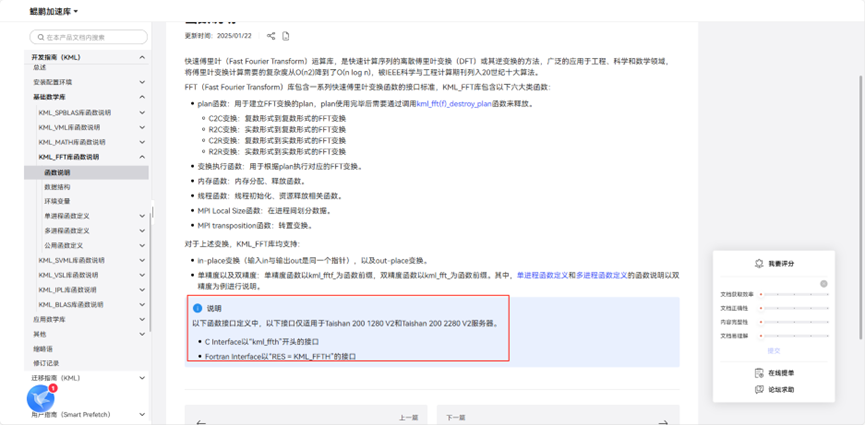
不行,紧急社区求助。
查看本机服务器

等等,这里好像是kml_fft开头接口,而文档说的是kml_ffth,是不是这里不展示还是写错了,继续追问
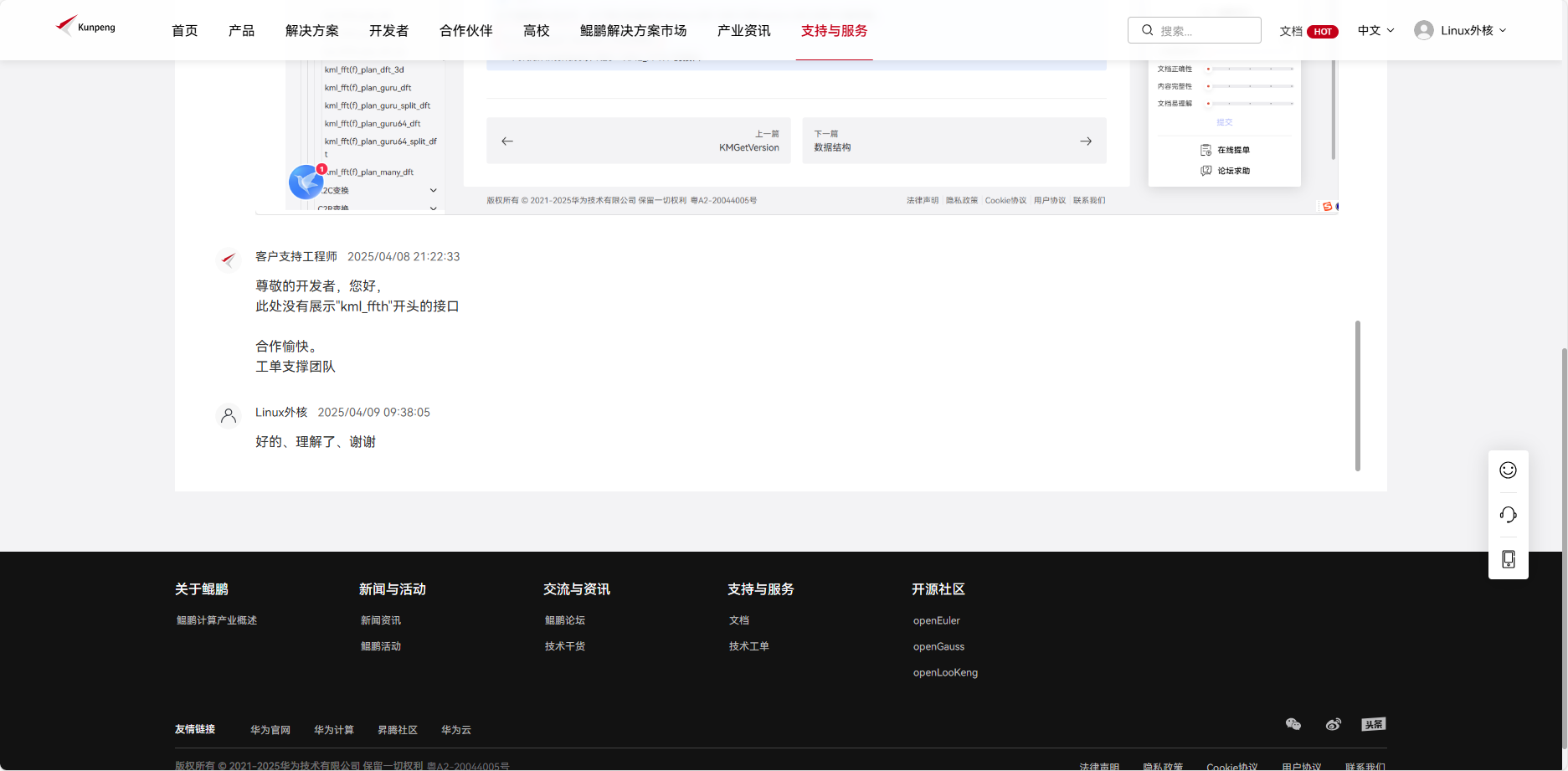
整个记录如下:
工单详情-鲲鹏社区
得到支持的回复、接下来验证FFT结果吧,代码如下:
int rank = 2;
int *n;
n = (int*)kml_fft_malloc(sizeof(int) * rank);
n[0] = 2;
n[1] = 3;
double init[6][2] = {{120, 0}, {8, 8}, {0, 0}, {0, 16}, {0, 16}, {-8, 8}};
kml_fft_complex *in;
in = (kml_fft_complex*)kml_fft_malloc(sizeof(kml_fft_complex) * n[0] * n[1]);
for (int i = 0; i < n[0] * n[1]; i++) {
in[i][0] = init[i][0];
in[i][1] = init[i][1];
}
kml_fft_complex *out;
out = (kml_fft_complex*)kml_fft_malloc(sizeof(kml_fft_complex) * n[0] * n[1]);
kml_fft_plan plan;
plan = kml_fft_plan_dft(rank, n, in, out, KML_FFT_FORWARD, KML_FFT_ESTIMATE);
kml_fft_execute_dft(plan, in, out);
kml_fft_destroy_plan(plan);
kml_fft_free(n);
kml_fft_free(in);
kml_fft_free(out);
/*
* out = {{1.200000e+02, 4.800000e+01}, {1.338564e+02, -1.385641e+01},
* {1.061436e+02, 1.385641e+01}, {1.360000e+02, -3.200000e+01},
* {1.120000e+02, -8.000000e+00}, {1.120000e+02, -8.000000e+00}}
*/
保存结果文件使用matlab验证,matlab代码如下:
clear; clc;
data = importdata('F:\\Workspace\\input_signal.txt'); % 快速读取数值矩阵[6](@ref)
M = data(:,1)+1j*data(:,2);
CV = abs(fft(M));
data1 = importdata('F:\\Workspace\\fft_output.txt'); % 快速读取数值矩阵[6](@ref)
M1 = data1(:,1)+1j*data1(:,2);
CV1 = abs(M1);
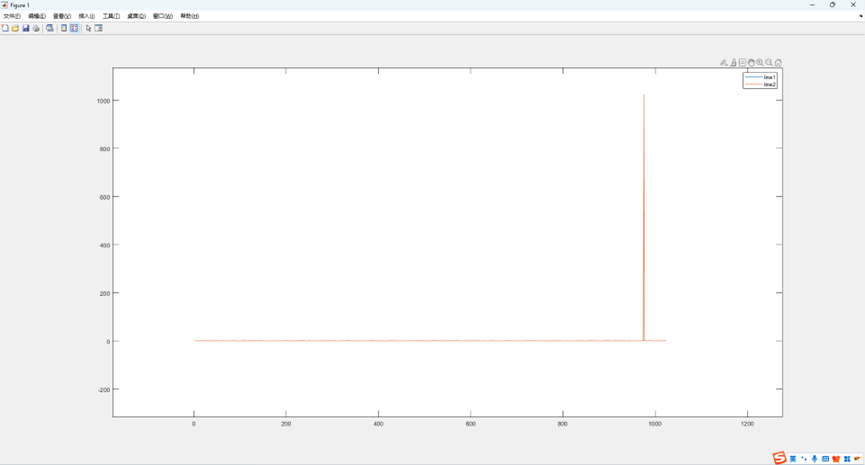
plot(1:1024,CV,1:1024,CV1); legend('line1', 'line2');
结果完全一致:








评论前必须登录!
注册