 网硕互联帮助中心
网硕互联帮助中心作者:昇腾实战派
背景概述
本文档旨在提供DeepSeek-R1-0528模型在Atlas 800I A2 推理服务器双机环境下的完整部署与测试指导。作为开发者,在将大语言模型部署到分布式NPU环境时,面临配置复杂、性能调优等挑战。
本文基于实际部署经验,系统性地介绍了从环境准备到性能测试的全流程,帮助读者高效完成模型部署与验证。
配置选择
| 16k+1k | 开启 | 开启 | 关闭 | 关闭 |
| 64k+1k | 开启 | 开启 | 开启 | 开启 |
| 128k+1k | 关闭 | 开启 | 开启 | 开启 |
拉起步骤
1. 配置ranktable.json
根据机器配置ranktable,分别在2台机器上执行
for i in {0..7};do hccn_tool -i $i -ip -g; done
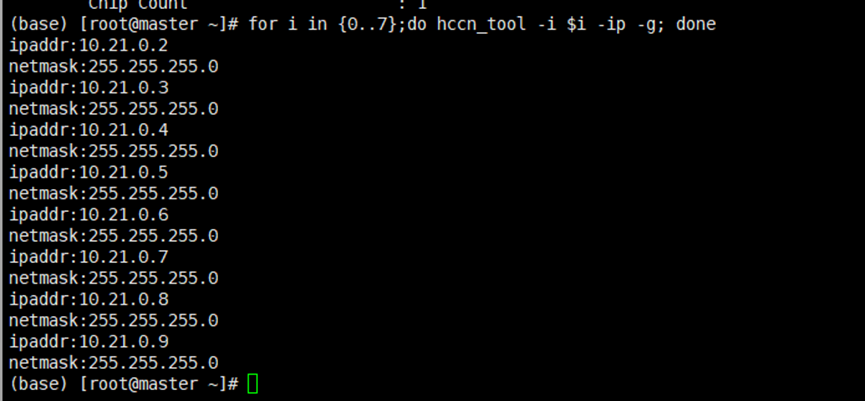
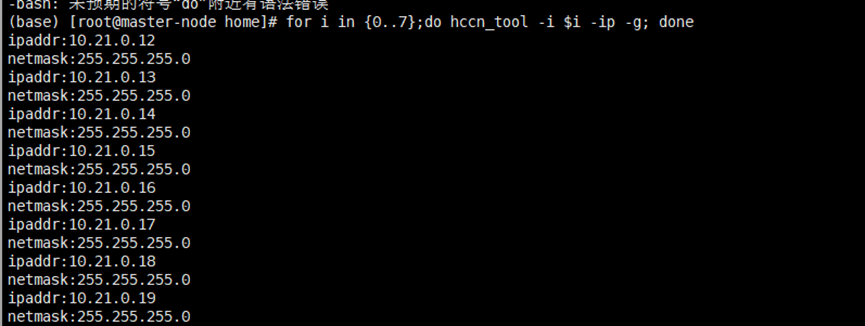
根据查找信息配置ranktable文件,当前机器配置如下:
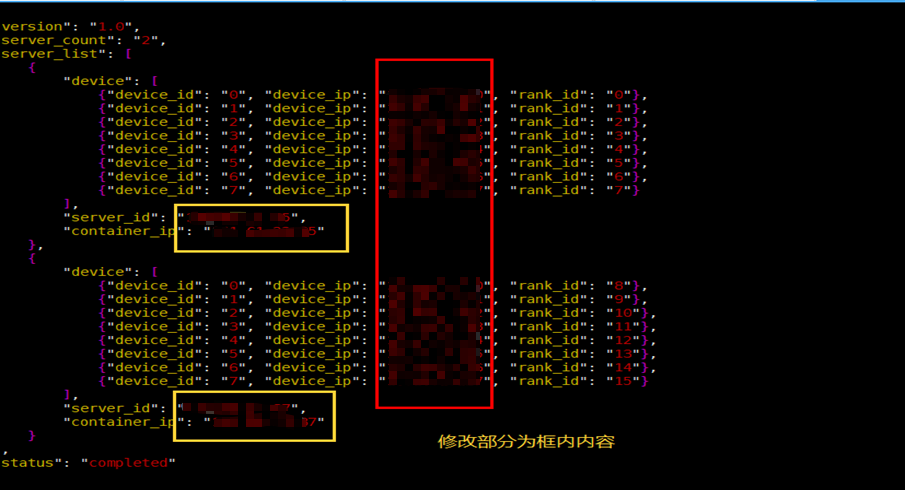
2. 下载模型权重:
V3.1_w8a8c8_rot:https://modelers.cn/models/Modelers_Park/DeepSeek-V3.1-w8a8c8-QuaRot 0528_w8a8c8_rot:https://www.modelscope.cn/models/Eco-Tech/DeepSeek-R1-0528-w8a8c8 V3.1_w4a8c8_rot:https://www.modelscope.cn/models/Eco-Tech/DeepSeek-V3.1-w4a8c8 0528_w4a8c8_rot:https://www.modelscope.cn/models/Eco-Tech/DeepSeek-R1-0528-w4a8c8
3. 下载镜像
推荐使用社区提供的mindie2.2rc1镜像,具体版本可根据实际需求选择。
4. 启动容器
#!/bin/bash
# ===================== 用户可配置参数 =====================
# 容器名称(自定义,例如 deepseekr1/v3)
CONTAINER_NAME="deepseekr1/v3"
# 镜像ID(替换为你的实际镜像ID或镜像名:标签)
IMAGE_ID="your-image-id-or-name:tag"
# ==========================================================
docker run -itd –privileged –name=${CONTAINER_NAME} \\
–net=host \\
–shm-size 500g \\
–device=/dev/davinci0 \\
–device=/dev/davinci1 \\
–device=/dev/davinci2 \\
–device=/dev/davinci3 \\
–device=/dev/davinci4 \\
–device=/dev/davinci5 \\
–device=/dev/davinci6 \\
–device=/dev/davinci7 \\
–device=/dev/davinci_manager \\
–device=/dev/hisi_hdc \\
–device /dev/devmm_svm \\
-v /usr/local/Ascend/driver:/usr/local/Ascend/driver \\
-v /usr/local/Ascend/firmware:/usr/local/Ascend/firmware \\
-v /usr/local/sbin/npu-smi:/usr/local/sbin/npu-smi \\
-v /usr/local/sbin:/usr/local/sbin \\
-v /etc/hccn.conf:/etc/hccn.conf \\
-v /home:/home \\
-v /data:/data:ro \\
${IMAGE_ID} \\
bash
5. 服务端参数配置
配置文件默认路径:/usr/local/Ascend/mindie/latest/mindie-service/conf/config.json 配置较为冗长,建议直接下载打包好的配置文件复制使用或参考文件内容逐行配置。
5.1 A2双机配置下载
v3.1_w8a8c8模型配置文件: v31模型A2双机服务端配置文件归档.zip 0528_w8a8c8模型配置文件:
0528模型A2双机服务端配置文件归档.zip
所有上下文的用例采取以下分布:
- a. 上下文<=17k的测试用例,采用16k+1k档位,保持其余配置不变,根据需要将maxSeqLen、maxInputTokenLen、maxPrefillTokens、maxIterTimes四个参数调整为实际所需的上下文长度,这里建议多加100保证输出长度能打满,例如: 输入3500,输出1500,maxSeqLen、maxInputTokenLen、maxPrefillTokens、maxIterTimes四个参数可配置为3500+1500+100=5100
- b. 17k<上下文<=65k的测试用例,采用64k+1k档位,保持其余配置不变,根据需要将maxSeqLen、maxInputTokenLen、maxPrefillTokens、maxIterTimes四个参数调整为实际所需的上下文长度,这里建议多加100保证输出长度能打满,例如: 输入32768,输出4096,maxSeqLen、maxInputTokenLen、maxPrefillTokens、maxIterTimes四个参数可配置为32768+4096+100=36964
- c. 65k<上下文<=129k的测试用例,采用128k+1k档位,保持其余配置不变,根据需要将maxSeqLen、maxInputTokenLen、maxPrefillTokens、maxIterTimes四个参数调整为实际所需的上下文长度,这里建议多加100保证输出长度能打满,例如: 输入131072,输出1024,maxSeqLen、maxInputTokenLen、maxPrefillTokens、maxIterTimes四个参数可配置为131072+1024+100=132196
5.2 修改config.json
5.2.1 常规参数修改
5.2.2 function_call 参数修改
两个权重各有对应的function call传参及jinja文件配置的差异 需在服务化的如下层级下根据所跑权重设置对应tool_call_parser和chat_template
"ModelConfig":[{
…
"model": {
"deepseekv2": {
"tool_call_options": {
"tool_call_parser": ""
},
"chat_template": "path_to_chat_template/tool_chat_template_deepseekr1.jinja"
}
}
}]
0528权重: “tool_call_parser”: “” “chat_template”:tool_chat_template_deepseekr1.zip
6.环境变量配置
A2双机(请仔细阅读每一项,其中包含需要根据自己的环境信息修改的,建议在环境上建一个set_env.sh文件保存这份环境变量,修改配置完成后可以直接执行
source set_env.sh
完成配置):
source /usr/local/Ascend/mindie/set_env.sh
source /usr/local/Ascend/ascend-toolkit/set_env.sh
source /usr/local/Ascend/nnal/atb/set_env.sh
source /usr/local/Ascend/atb-models/set_env.sh
export RANK_TABLE_FILE={双机ranktable的路径}
export MIES_CONTAINER_IP={服务器ip}
export MASTER_IP={主节点ip}
export PYTORCH_NPU_ALLOC_CONF=expandable_segments:True
export ATB_WORKSPACE_MEM_ALLOC_ALG_TYPE=3
export ATB_WORKSPACE_MEM_ALLOC_GLOBAL=1
export HCCL_OP_EXPANSION_MODE="AIV"
export NPU_MEMORY_FRACTION=0.96
export ATB_LLM_HCCL_ENABLE=1
export INF_NAN_MODE_ENABLE=1
# 8244特性防止oom开关
export ATB_LAYER_INTERNAL_TENSOR_REUSE=1
export HCCL_CONNECT_TIMEOUT=3600
export WORLD_SIZE=16
export HCCL_EXEC_TIMEOUT=0
# A3到15,A3双机到33
export ASCEND_RT_VISIBLE_DEVICES=0,1,2,3,4,5,6,7
export ATB_OPERATION_EXECUTE_ASYNC=1
export ATB_LLM_ENABLE_AUTO_TRANSPOSE=0
export HCCL_RDMA_PCIE_DIRECT_POST_NOSTRICT=TRUE
export HCCL_INTRA_PCIE_ENABLE=1
export HCCL_INTRA_ROCE_ENABLE=0
export HCCL_BUFFSIZE=64
# 异步发射
export MINDIE_ASYNC_SCHEDULING_ENABLE=1
# jemalloc优化,社区镜像中的路径为/usr/lib64/libjemalloc.so.2;研发镜像中的路径为/usr/lib/aarch64-linux-gnu/libjemalloc.so.2
export LD_PRELOAD={libjemalloc.so在本环境上的路径}
# 队列优化特性
export TASK_QUEUE_ENABLE=1
for var in $(compgen -e | grep 'STDOUT$'); do
export "$var=0"
done
for var in $(compgen -e | grep 'LOG_TO_FILE$'); do
export "$var=0"
done
# 遇到config.json文件权限问题
find /usr/local/lib/python3.11/site-packages/mindie* -name config.json |xargs chmod -R 640
chmod -R 640 {双机ranktable的路径}
export MINDIE_LOG_TO_STDOUT=0
export OMP_NUM_THREADS=10
#HCCL显存分配策略,配置后不会跑着跑着继续申请显存。
export HCCL_ALGO="level0:NA;level1:pipeline"
7. 服务拉起
确保source完所有环境变量后执行如下命令启动服务化,确保容器无代理,且需绑核拉起,可使用
lscpu
查询第一个numa的核数,典配800IA2服务器的第一个numa核数为0-31,非典配可能是192核,第一个numa为0-24:
unset http_proxy
unset https_proxy
taskset -c 0-31 /usr/local/Ascend/mindie/latest/mindie-service/bin/mindieservice_daemon
等待服务拉起,若出现Daemon start Success!字样,则服务拉起成功。
性能测试
1. aisbench配置
在主节点新开一个窗口,完成aisbench配置。
aisbench容器内路径:/usr/local/lib/python3.11/site-packages/ais_bench 以使用vllm_api_stream_chat为例,配置文件:
vim /usr/local/lib/python3.11/site-packages/ais_bench/benchmark/configs/models/vllm_api/vllm_api_stream_chat.py
from ais_bench.benchmark.models import VLLMCustomAPIChatStream
models = [
dict(
attr="service",
type=VLLMCustomAPIChatStream,
abbr='vllm-api-stream-chat',
path={与服务端配置的modelWeightPath对齐},
model={与服务端配置的modelName对齐},
request_rate = 10,
retry = 2,
host_ip = {与服务端配置的ipAddress对齐,双机一般为主节点ip,可在主节点的物理机上执行netstat –tuln查询},
host_port = {与服务端配置的port对齐,可在主节点的物理机上执行netstat –tuln查询},
max_out_len ={输出长度},
batch_size={并发数},
trust_remote_code=False,
generation_kwargs = dict(
ignore_eos = True,
temperature = 0,
chat_template_kwargs={"enable_thinking": True},
)
)
]
2. 生成自定义语义数据集
可下载并解压以下脚本 make_data.zip
使用方式:
在容器中,进入到解压后的make_data文件夹中,在命令行输入以下指令进行生成:
python3 ./creat_dataset.py –input_len $1 –max_lines $2 –input_filename ./GSM8K.jsonl –model_path $3 –output_filename ./generate_dataset/generate_dataset_input_len$2_$1_lines.jsonl
- –input_len 输入所需生成每条数据的输入长度,脚本会以此从GSM8K.jsonl文件提取短序列问题拼接生成对应长度的输入问题
- –max_lines 输入需要生成对应序列长度的数据多少条,及生成多少条数据
- –model_path 输入模型权重,判断token长度的方式是需要与模型的tokenizer比对,因此需要与模型权重绑定
3. aisbench使用
此处展示使用GSM8k拼凑的符合输入长度的数据集的测试方法。
#创建gsm8k文件夹并创建train.jsonl空文件
mkdir ais_bench/datasets/gsm8k
echo {} > train.json
#将测试数据集jsonl拷贝至gsm8k路径底下,并改名为test.jsonl
cp -r 【“100条输入长度32768纯A.zip”所在路径】 ais_bench/datasets/gsm8k/test.jsonl
执行性能测试
#可通过$num的值调整测试的数据条数
ais_bench –models vllm_api_stream_chat –datasets gsm8k_gen_0_shot_cot_str_perf –debug –summarizer default_perf –mode perf –num-prompts $num
通过调整$num参数控制测试请求数量,获取相应的性能指标。








评论前必须登录!
注册