 网硕互联帮助中心
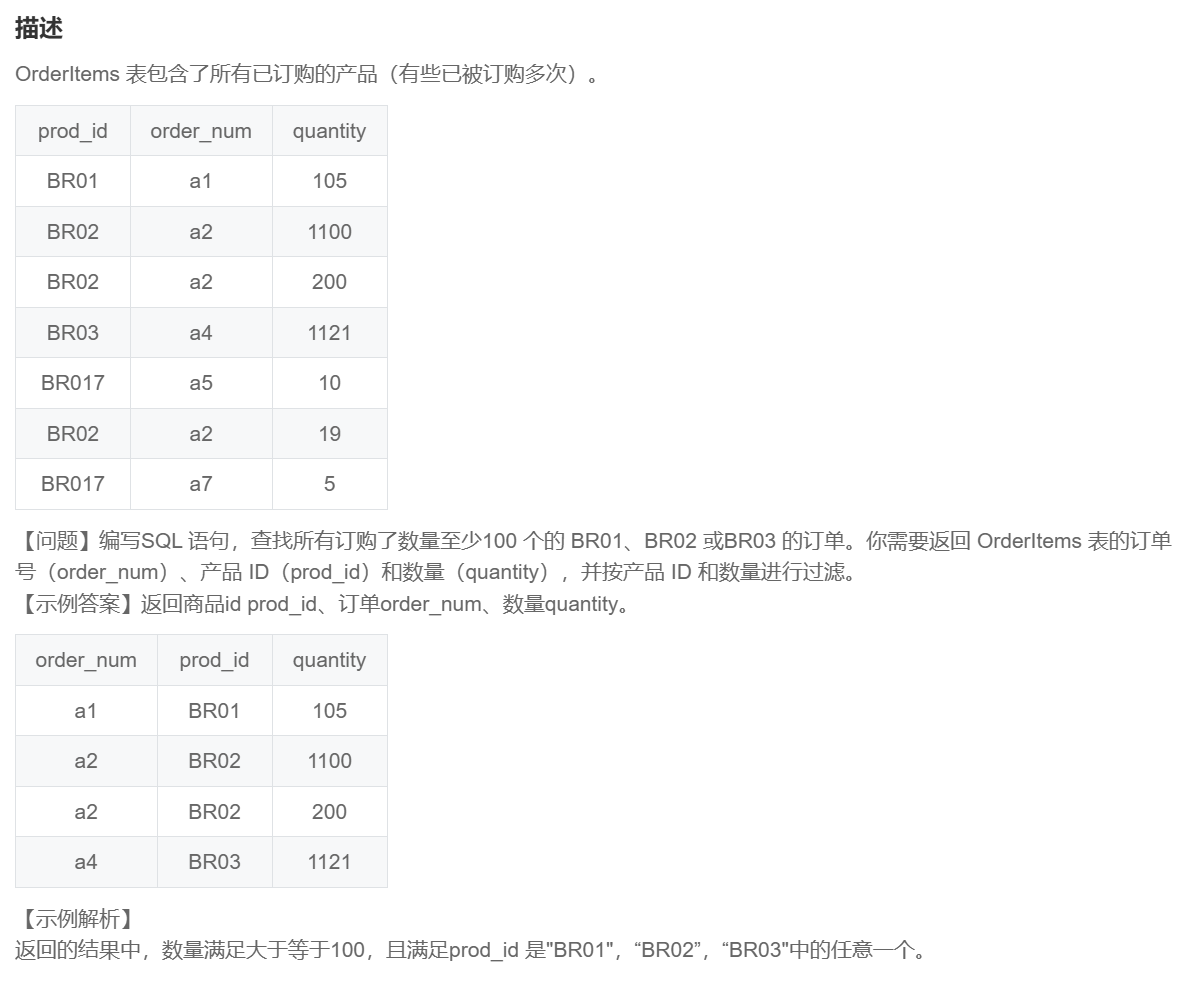
网硕互联帮助中心SQL72 检索并列出已订购产品的清单
# 方法一:
select order_num,prod_id,quantity
from OrderItems
where (prod_id = 'BR01' or prod_id = 'BR02' or prod_id = 'BR03')
and quantity >=100;
# 方法二:
select order_num,prod_id,quantity
from OrderItems
where prod_id in('BR01','BR02','BR03')
and quantity >=100;
# 方法三
select order_num,prod_id,quantity
from OrderItems
where prod_id between 'BR01' and 'BR03'
and quantity >=100;
| OR 多条件 | 任意一个等值匹配 | 少量固定值、教学演示 |
| IN (值列表) | 多 OR 简写,离散等值匹配 | 离散枚举值、固定多值匹配 |
| BETWEEN AND | 闭区间范围比较 | 连续数值 / 日期 / 连续编码 |
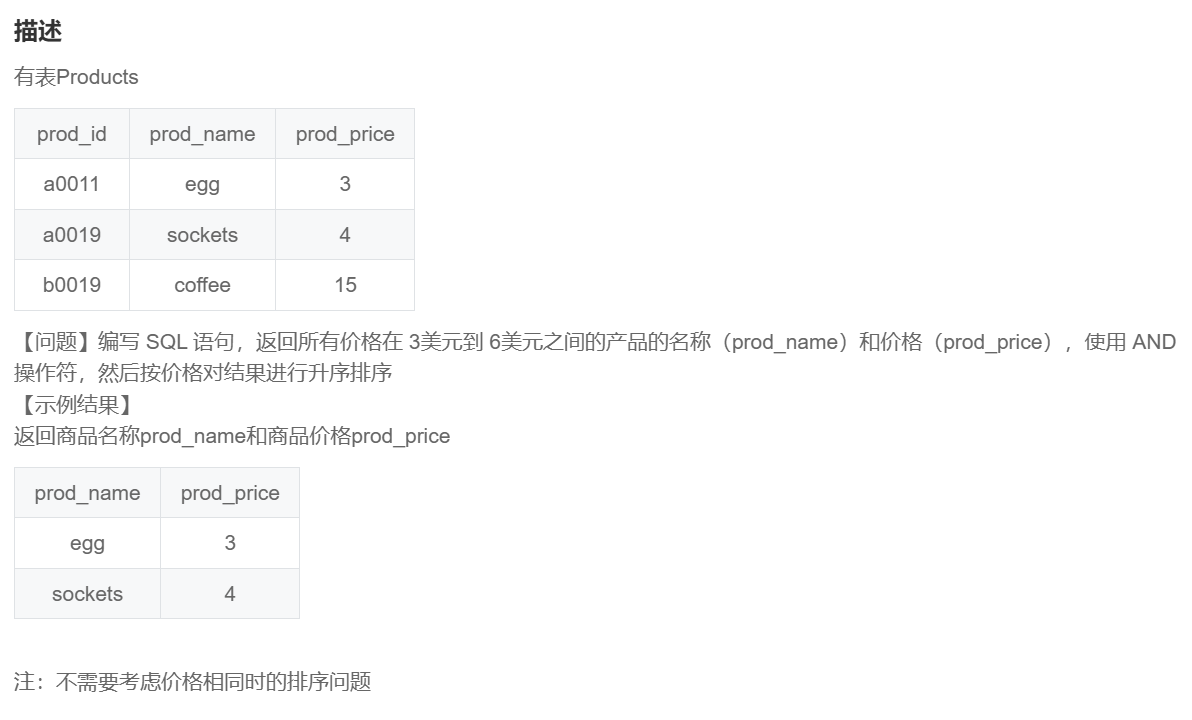
SQL73 返回所有价格在 3美元到 6美元之间的产品的名称和价格
方法一:
select prod_name,prod_price from Products
where prod_price>=3 and prod_price<=6
order by prod_price asc;
方法二:
select prod_name,prod_price from Products
where prod_price BETWEEN 3 AND 6
order by prod_price asc;
SQL74 纠错2
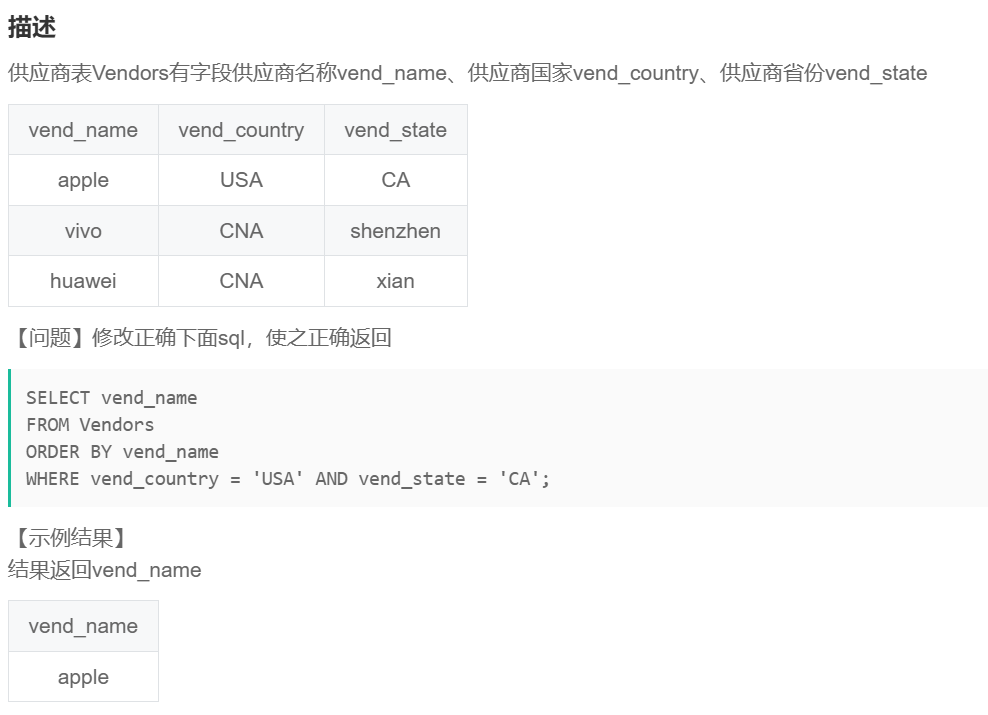
SELECT vend_name
FROM Vendors
WHERE vend_country = 'USA' AND vend_state = 'CA'
ORDER BY vend_name;
一、Mysql 语法顺序
| 1 | SELECT [DISTINCT] | 指定查询的列、去重、聚合函数 | 查询结果列定义,可搭配 DISTINCT 去重 |
| 2 | FROM | 指定数据来源的主表 | 必选子句,定义操作的基础表 |
| 3 | JOIN | 关联其他表(内连接、左连接、右连接等) | 多表查询使用,拼接关联表 |
| 4 | ON | 多表连接的匹配条件 | 配合 JOIN 使用,不可单独写在 WHERE 前 |
| 5 | WHERE | 对原始数据行进行过滤 | 过滤基础表数据,不支持聚合函数 |
| 6 | GROUP BY | 对数据进行分组统计 | 配合聚合函数(SUM/COUNT/AVG 等)使用 |
| 7 | HAVING | 对分组后的结果进行过滤 | 仅能过滤分组 / 聚合后数据,可使用聚合函数 |
| 8 | UNION | 合并多个查询结果集 | 合并去重,UNION ALL 为不去重合并 |
| 9 | ORDER BY | 对最终结果集进行排序 | 升序 ASC、降序 DESC,默认 ASC |
| 10 | LIMIT | 限制查询返回的行数(分页) | MySQL 特有,用于截取结果条数 |
二、Mysql执行顺序
| 1 | FROM | 加载主表到内存,确定数据基础源 | 执行第一步,先找表 |
| 2 | ON | 执行多表连接的匹配条件过滤 | 先匹配关联条件,再生成临时表 |
| 3 | JOIN | 拼接关联表,生成多表联合临时表 | ON 和 JOIN 联动,完成表连接 |
| 4 | WHERE | 过滤连接后的原始行数据 | 过滤未分组的基础数据,效率最高 |
| 5 | GROUP BY | 对过滤后的数据进行分组 | 分组后形成分组聚合的临时结果 |
| 6 | HAVING | 过滤分组完成后的聚合结果 | 针对分组后数据,WHERE 无法替代 |
| 7 | SELECT | 确定最终要展示的列、计算列、聚合列 | 执行到这一步才确定查询列 |
| 8 | DISTINCT | 对查询结果进行去重处理 | 在 SELECT 之后,对结果集去重 |
| 9 | UNION | 合并多个查询的结果集 | 合并所有满足条件的查询结果 |
| 10 | ORDER BY | 对最终结果集进行排序 | 最后排序,排序是耗时操作,放最后 |
- 书写顺序 ≠ 执行顺序,WHERE 先执行,SELECT 后执行,所以 WHERE 里不能用 SELECT 定义的别名。
- ON 🆚 WHERE:ON 是表连接时过滤,WHERE 是连接完成后过滤,左连接 / 右连接时,二者结果会不同。
- WHERE 🆚 HAVING:WHERE 过滤原始行,不能用聚合函数;HAVING 过滤分组结果,只能配合 GROUP BY 使用。
- ORDER BY、LIMIT 永远在执行的最后阶段,是对最终结果集操作。
SQL75 检索产品名称和描述(一)
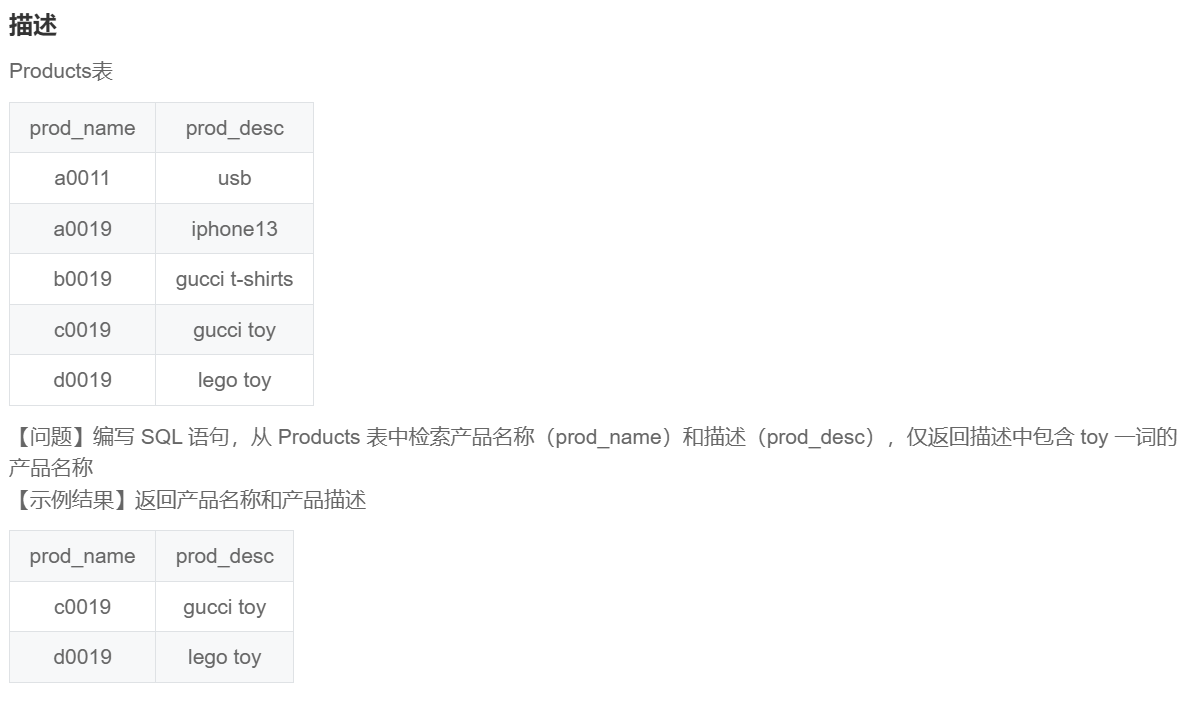
select prod_name,prod_desc from Products
where prod_desc like '%toy%';
关键词:like
用法:[字符] like '%_[]字符'
- %表示任何字符出现任意次数
- _表示单个字符
- []表示一个字符集
SQL76 检索产品名称和描述(二)

方法1: INSTR函数用法
mysql 进行模糊查询时,可使用内部函数 instr,替代传统的 like 方式,并且速度更快。
instr(field, str) 函数,第一个参数 field 是字段,第二个参数 str 是要查询的串,返回串 str 的位置,没找到就是0
select prod_name,prod_desc from Products
where instr(prod_desc,"toy")=0
order by prod_name;
方法2:not like
select prod_name,prod_desc from Products
where prod_desc not like '%toy%'
order by prod_name;
方法3:locate(str,sub)
Locate(str,sub) > 0,表示sub字符串包含str字符串;
Locate(str,sub) = 0,表示sub字符串不包含str字符串。
select prod_name,prod_desc from Products
where locate("toy",prod_desc)=0
order by prod_name;
SQL77 检索产品名称和描述(三)

select prod_name,prod_desc
from Products
where prod_desc like "%toy%" and prod_desc like "%carrots%";
LIKE操作符
LIKE 是 SQL 中用于模糊匹配字符串的操作符,它和 = 不同:
- = 要求完全相等(精确匹配)
- LIKE 允许用通配符来匹配符合某种模式的字符串
% 是 LIKE 中常用的通配符
| "toy%" | 以 toy 开头的字符串 | toy car, toys |
| "%toy" | 以 toy 结尾的字符串 | stuffed toy, action toy |
| "%toy%" | 包含 toy 的字符串(位置不限) | the toy box, toy story |
| "%" | 匹配任意字符串(相当于没有限制) | 所有非空字符串 |
另一个常用通配符 _
| 't_y' | 第 1 位是 t,第 3 位是 y,中间任意 | tay, tby, tcy |
| 'to_' | 以 to 开头,后面跟 1 个字符 | too, top, toy |
SQL78 检索产品名称和描述(四)
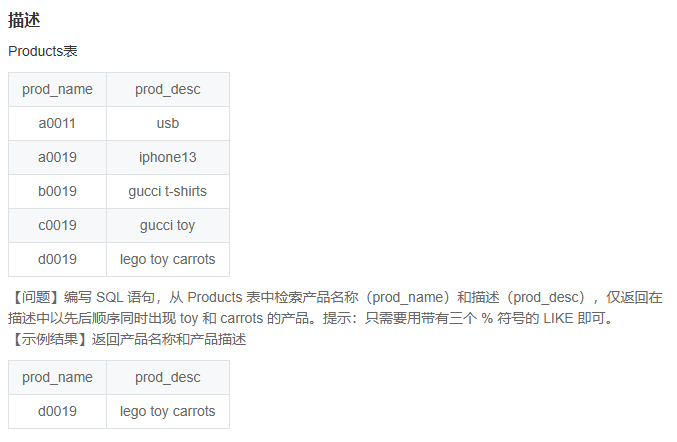
select prod_name,prod_desc
from Products
where prod_desc like "%toy%carrots%";
SQL79 别名

select vend_id,
vend_name as vname,
vend_address as vaddress,
vend_city as vcity from Vendors
order by vname;
AS可以省略:
select vend_id,
vend_name vname,
vend_address vaddress,
vend_city vcity
from Vendors
order by vname;
易错点:vcity 在最后边,位置也会导致错误
SQL80 打折

select prod_id,
prod_price,
prod_price*0.9 sale_price
from Products;
与SQL79别名知识点相似
SQL81 顾客登录名

select cust_id,
cust_name,
upper(concat(substring(cust_contact,1,2),substring(cust_city,1,3))) user_login
from Customers;
关键词:substing,concat,upper
- 字符串的截取:substring(字符串,起始位置,截取字符数)
- 字符串的拼接:concat(字符串1,字符串2,字符串3,…)
- 字母大写:upper(字符串) 补充:lower(字符串)小写




评论前必须登录!
注册