 网硕互联帮助中心
网硕互联帮助中心前言
在嵌入式 Linux 开发中,字符设备驱动可以算得上是一个入门关卡。它看似简单,实则蕴含着一些 Linux 内核编程的精髓,比如模块加载与卸载,文件操作接口,设备注册,中断处理等等,几乎所有更复杂一点的驱动都是建立在这些内容的基础之上。
那么关于字符设备驱动这个内容的重要性我就不再赘述了。写这篇文章的初衷其实很简单:初学字符设备驱动时,我也是一头雾水,甚至要把“字符设备驱动”这六个字细细品味一下,生怕遗漏什么重要的知识点,后面也遇到过编译问题和模块加载问题,好在最后通过反复实践,也是非常艰难的算是过了关,对字符设备驱动有了一个比较浅显的认知。回想最初接触字符设备驱动,最困难的时期莫过于对字符设备驱动的框架没有一个比较清晰的认知,不知道它的出现是为了解决什么问题,不知道它是怎样解决问题的,不知道为什么对文件的一个操作最终能反应在一个实实在在的设备上面。细细思考之后,我想这些问题可能并不是只有我一个人才会有。
于是,本文就出现了。本文会从字符设备驱动最浅显的层面也就是它的名字入手,一步一步深入,逐渐提升大家对于字符设备驱动的的理解,这可能有助于帮助大家在内心中构建一个比较完善的框架,从而在后面知识的学习中更加的如履平地。
措辞有误,表达不当之处请大家谅解。下面我们进入正题。
1. 初识字符设备
1.1 名字的含义
本小节我们将拆解一下字符设备驱动为什么会叫做字符设备驱动。
Linux 内核把设备驱动分为三大类:字符设备(character device)、块设备(block device) 和 网络设备(network device)。其中字符设备是最基础,最常见的一类。
字符设备这几个字带给我和大家的第一印象我想应该是没有太大区别的:这种设备在接收和发送数据时应该是以单个字符为单位的。
后来我查阅了一些资料,发现这个名字的由来既有历史渊源,也有一些现代的设计理念。
历史渊源:字符设备最早可以追溯到 1970 年代的 Unix 系统,那时候有一种比较常见的外部设备是电传打字机,其实就是一个键盘和打印机组合起来的终端设备,用户敲键盘时,设备一次发送一个字符到计算机,计算机输出时也是一个字符一个字符打印出来。这种设备天然就是逐字符处理的,没有随机访问的需求。在 Unix 设计中,这类设备统一称为 character devices(字符设备),以区别于另一种类似于磁带,磁盘的设备,这些设备每次读写固定大小的块。所以,在一定程度上,我们可以认为“字符”这个词直接来源于早期最典型的字符终端的工作方式:按字符流传输数据。
设计理念:Linux 继承了 Unix 的设备模型,把设备抽象成文件,但在不同设备类型的访问方式上有本质的区别。字符设备的核心理念是提供一个无结构的,连续的字节流接口,就像水管里流出的水一样,我们只管读写字节,不关心块或结构。而块设备有固定大小的块,支持随机访问,并且有内核缓冲。在早期的 ASCII 编码时代,一个字符就是一个字节,字符流也就等于字节流。但是字符这个词更能体现面向文本的含义,所以即使后来出现了 Unicode、多字节编码,还是延续了字符设备的叫法。
现在,我们写一个控制 LED 或者读取传感器数据的驱动,他也叫字符设备驱动,因为它符合同样的抽象模型,即用户空间通过 read 或write或 ioctl 操作一个流。
理解了这个名字的来龙去脉,当你再看字符设备代码时就会更有感觉。它并不是随意起的名字,而是古人智慧的结晶,承载着设备模型的核心理念。
1.2 字符设备在 Linux 中的体现
下面我们看看字符设备在实际的 Linux 系统中是如何呈现的,这有助于我们在用户空间快速识别和操作字符设备。
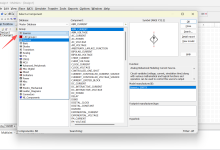
Linux 将几乎所有设备都抽象为文件,这些文件通常位于 /dev 目录下,我们可以用 ls 命令查看,我截取了一部分输出内容如下:
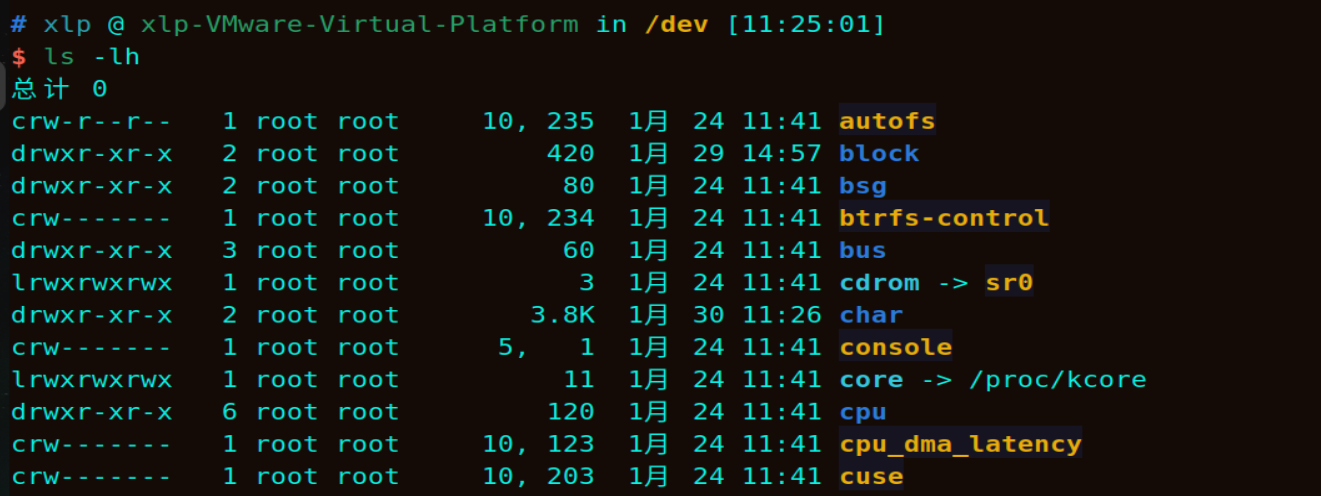
可以看到,最前面字母为c,就代表这是一个字符设备。若最前面字母为b,则代表这是一个块设备。
此外,每个设备文件都有一个主设备号和一个次设备号。主设备号标识驱动类型,次设备号标识具体的设备实例。
上图中第一个字符设备autofs,主设备号为 10,次设备号为 235。
上面的截图中只有部分的字符设备,下面我再简单介绍一些比较常见的字符设备:
这些都是典型的字符设备,用户空间程序通过 open/read/write/close 操作它们,就像操作普通文件一样。
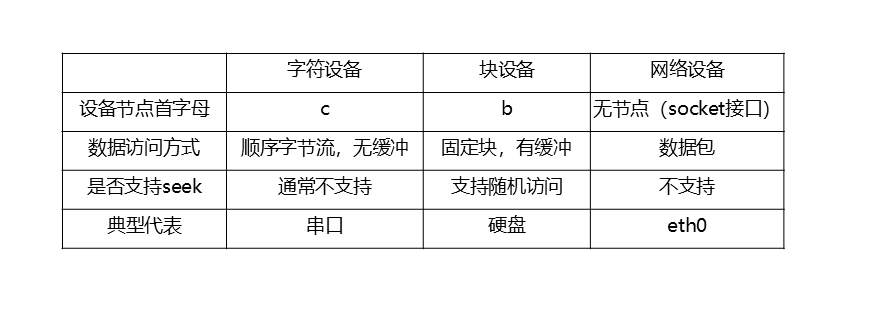
1.3 三大设备简单对比
为了能更好地区分字符设备与其他两种设备,本小结我们简单对比一下这三者的特点。
2. 字符设备驱动的抽象模型与核心结构体
在第一章中,我们看到了字符设备在用户空间的表现形式,他们是一个个位于 /dev 下的特殊文件。用户程序通过熟悉的 open()、read()、write()、close() 系统调用操作它们,就好像在操作普通文件一样。
但这些操作最终是如何落实到真实硬件上的呢?这就涉及 Linux 内核对设备驱动的抽象模型。理解这个抽象模型,是写好字符设备驱动的关键,也是我们真正理解这个框架的关键。
2.1 字符设备的抽象
Linux 内核虽然用纯 C 语言编写,但设备驱动的设计却充满了面向对象编程(OOP)的味道。我们可以把一个字符设备驱动想象成一个类,设备本身就像一个类,比如 LED 驱动类或者某种传感器驱动类,而每个打开的设备文件就像这个类的一个实例,用户空间的 read/write/ioctl 调用就像调用这个实例的方法。
内核通过结构体和函数指针的方式,巧妙的在 C 语言中实现了类似面向对象的多态,封装和继承。比如同一个 file_operations 结构体可以被多个不同设备共享,不同设备的实例可以通过 private_data 携带自己专属的状态,函数指针表使不同设备可以实现不同的 read/write 行为。
在 Linux 内核中,字符设备被抽象为一个具体的数据结构struct cdev,可以把它看作字符设备对象,cdev 记录了字符设备的相关信息,比如设备号等。file_operations 记录了字符设备的打开,读写,关闭等操作接口。当我们想添加一个字符设备时,就要将这个对象注册到内核中,通过创建一个文件 (第一张截图中的设备节点) 绑定对象的 cdev,当我们对这个文件进行读写操作时,就可以通过虚拟文件系统,在内核中找到这个对象及其操作接口,从而能控制实实在在的设备。
这种设计让驱动框架高度模块化。内核只关心接口,不关心具体的实现。这也是为什么字符设备驱动的代码看起来那么规整,它本质上是在 C 语言中模拟 OOP 。
2.2 一些概念及重要结构体
前面简单提到过,Linux 使用设备编号来表示设备,主设备号用来区分设备类别,次设备号标识具体的设备。内核使用 cdev 结构体来记录设备号,在使用设备时,我们打开设备节点对应的文件,通过该文件的inode结构体,file 结构体可以找到 file_operations 结构体,并且从中获得操作设备的具体方法。
dev_t是一个 32 位的数,用来表示设备编号,高 12 位表示主设备号,低 20 位表示次设备号。
在 Linux 中,所有的设备访问都是通过文件的方式进行的,一般的存放数据的文件成为普通文件,而设备节点成为设备文件。所有设备都以文件的形式存放在/dev 目录下,并且通过文件的方式进行访问,每个文件都是一个设备节点,这些设备节点是连接内核与用户空间的枢纽。
2.2.1 cdev 结构体
内核用 struct cdev 结构体来描述一个字符设备,该结构体在内核源码中定义如下:

struct kobject kobj是内嵌的内核对象,就是通过它才将设备统一加入到 Linux 设备驱动模型中管理。
struct module *owner,这是驱动程序所在的内核模块对象的指针。
const struct file_operations *ops结构体中定义了文件操作,包含了对文件进行打开,关闭,读写等操作的函数指针。
struct list_head list将系统中的字符设备用这个链表集中起来,这是侵入式链表,内核源码中经常能看到它。
dev_t dev是字符设备的设备号。
unsigned int count表示属于同一主设备号的次设备号的个数。
2.2.2 file_operations 结构体
简单概括一下这个结构体,这个结构体中的成员都是函数指针,我们在编写驱动程序时需要编写对应的函数并让相应的函数指针指向这个函数,从而使得用户空间执行某个操作时,最终控制权会通过 file_operations 结构体中的函数指针交到对应的执行函数手中。
该结构体在内核源码中的定义如下:
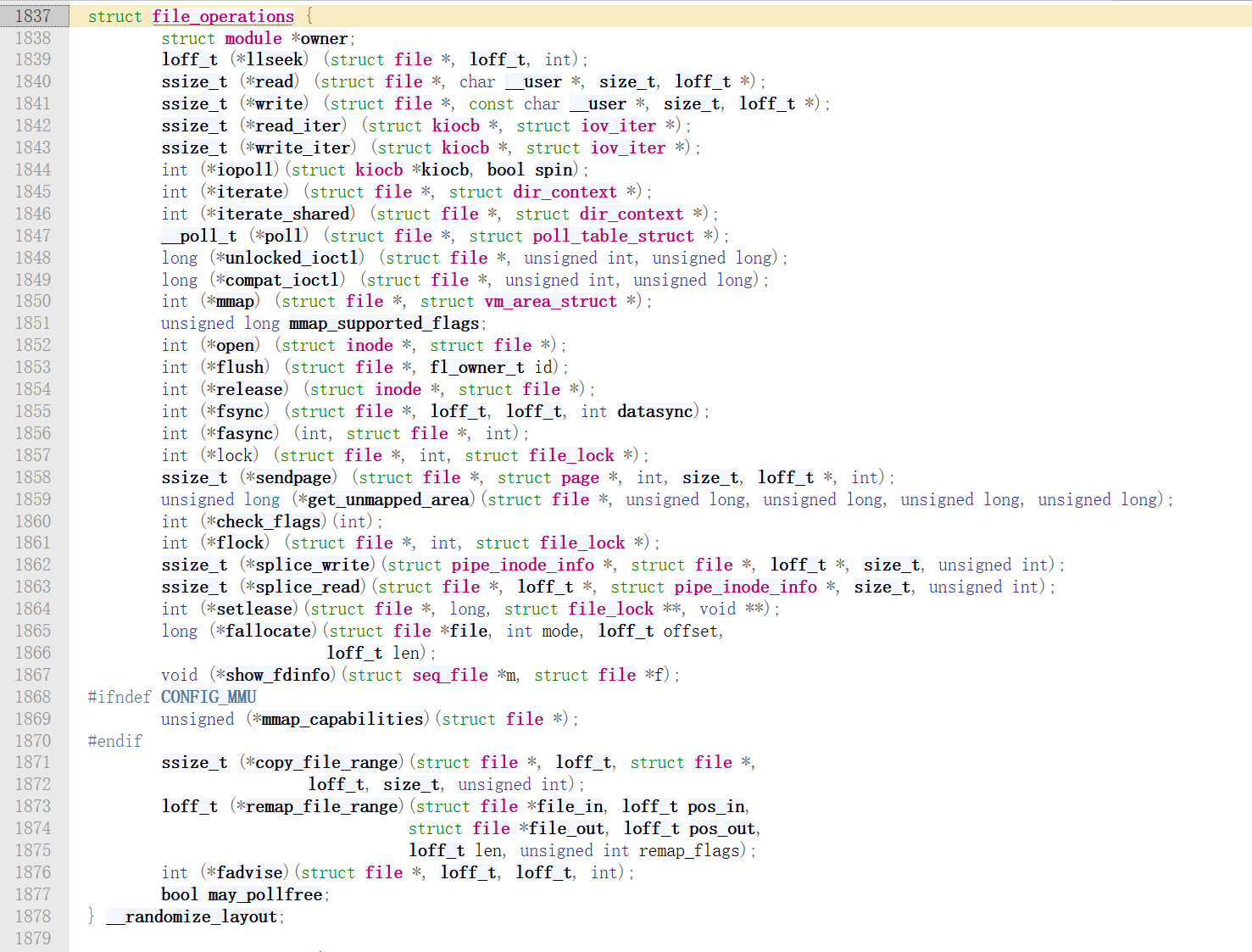
可以看到它的成员非常多,但是实际上我们只会用到其中的一小部分,其他未用到的函数指针置位NULL。下面简单介绍一个最常用的:
struct module *owner一般填THIS_MODULE,用来防止模块被卸载。
llseek用于修改当前文件的读写位置,返回值位偏移后的位置。第一个参数struct file *为对应的文件指针,第二个参数loff_t指定偏移量的大小,第三个参数int用于说明从文件的哪个位置开始偏移,比如SEEK_CUR 表示从当前位置开始偏移。
read用于读取设备中的数据,并返回成功读取的字节数。该函数指针被置位NULL时,在用户程序中对该文件进行系统调用read就会报错。第一个参数依然是要读取文件的文件指针。第二个参数是char __user *类型的缓冲区,__user 用于修饰变量,表明该变量所在的地址空间属于用户空间,内核模块不能直接使用该数据,需要使用 copy_to_user 函数来进行操作。第三个参数指定要读取数据的字节数。第四个参数表示读取的偏移位置,从文件的哪个地方开始读。
write用于向设备写入数据,并返回成功写入的字节数,在访问 __user 修饰的数据缓冲区时,需要先使用copy_from_user函数将数据从用户空间拷贝到内核空间的缓冲区,然后再将内核缓冲区中的数据写入到设备文件。
open指向的函数是设备驱动第一个被执行的函数,在这个函数中一般要初始化硬件。如果这个指针被置位NULL,则说明打开这个设备的操作将会永远成功。
release指针指向的函数在file结构体被释放时就会被调用。
2.2.3 struct file 结构体
内核中使用struct file结构体来表示每个打开的文件。也就是说每打开一个文件,内核都会创建一个struct file结构体,并将对
该文件的操作函数传递给该结构体的成员变量 f_op,当文件所有实例被关闭后,内核才会释放这个结构体。
该结构体在内核源码中的定义如下:
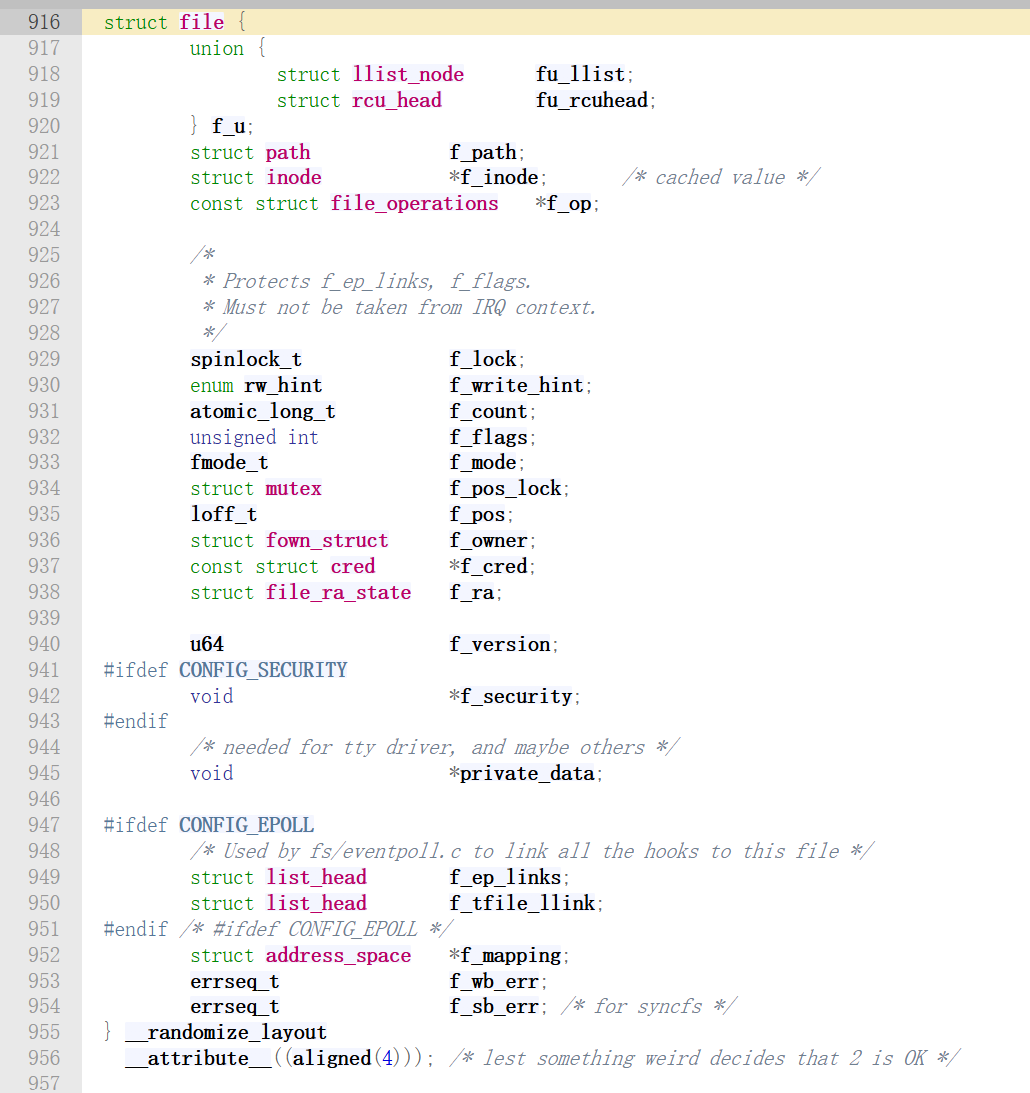
这个结构体成员也很多,但我们只需要关注其中的两个。分别是f_op和private_data。
f_op就是用来存放文件操作相关函数指针的。
private_data 指针变量只会用于设备驱动程序中,内核并不会对该成员进行操作。因此,在驱动程序中,通常用于指向描述设备的结构体。比如,可以在 open() 中分配一个结构体,保存设备状态,比如缓冲区、锁等,在 release() 中释放。
2.2.4 inode 结构体
inode 结构体在内核内部表示一个文件,是 Linux 管理文件系统的最基本的单位。它与struct file结构体是完全不同的,struct file 表示一个已经打开的文件描述符,而文件描述符表是进城私有的,这样说吧,对于硬盘上的一个文件实体,它可以被不同的进程同时打开,也可以被同一个进程打开多次,而这每一次打开内核都会创建一个 struct file 结构体,用于表示这个文件本次打开的实例。而在上面的struct file结构体的内核源码截图中我们可以看到有一个成员f_inode,上面提到的那么多次打开对应的那么多struct file结构体,实际上他们的f_inode成员指向的是同一个struct inode结构体。这就是二者的区别,一个代表文件一次打开的实例,另一个代表文件在硬盘上的实体。
这里我们只简单介绍一下这个结构体的成员,就不贴源码了。
inode结构体包含文件的访问权限,所有者,大小,创建时间,修改时间,访问时间等信息,都是一个文件最基本的信息。
2.3 协作流程
现在我们已经对struct file_operations、struct cdev、struct file 和 struct inode 这几个核心结构体有了一个初步的认识,但是这还不够,我们需要把这些结构体串起来,看看他们各自负责哪些操作。
它们之间的协作流程究其本质还要归功于 VFS 虚拟文件系统,VFS 把所有的文件统一抽象,使得用户层可以使用最平常的read和write来操作设备文件,这也是 Linux 究极哲学“一切皆文件”的体现。
这部分可以说是全文最关键的部分,理解了这个协作流程就可以说是理解了字符设备驱动开发的底层原理,并且对后面一些内容的学习也能起到触类旁通的效果。本来打算在这部分放一个流程框图,但是思来想去,流程框图的直观的抽象就意味着对细节的模糊化,所以我最终还是决定用通俗的文字描述,我会尽可能的将每个细节描述清晰。
下面请大家跟着我文字描述的思路走。假设我们有一个简单的字符设备驱动,叫my_chrdev,我们默认驱动程序已经写好,并且编译好了,仔细分析一下在加载模块后,底层到底发生了什么。
至此,整个生命周期结束。了解了这个流程,你再看任何字符设备驱动代码时,都能快速定位每个函数在整个流程中的位置。
3. 总结
本文详细讲解了字符设备的抽象和一些重要的结构体,最核心的内容莫过于这些结构体之间的协作方式,是否理解协作方式直接决定了你心中是否能有一个框架,这个框架能够帮助你在编写驱动程序时行云流水的操作,而不是走一步想一步。
本文作为上篇主要讲解概念层面的东西,下篇将会介绍一些重要的函数极其使用方法,同时会亲手写一个字符设备驱动程序,并编写用户程序进行验证。
本文完。




评论前必须登录!
注册