 网硕互联帮助中心
网硕互联帮助中心自注意力机制,它是现代深度学习,尤其是Transformer模型(如BERT、GPT)的核心组件。
第一部分:核心思想——它不是“注意力”,是“关联力”
普通注意力:像手电筒,你主动把光(注意力)打到某个地方。比如“注意听那个人的发言”。
自注意力:像一张智能关系网。你同时分析会议室里每个人与其他人之间的关系,然后更新你对每个人的理解。
核心目标:为房间里的每个人,重新计算一个“升级版的身份牌”。这个新身份牌,融合了他与房间里所有人的关系信息。
第二部分:用一场“相亲大会”来模拟整个过程
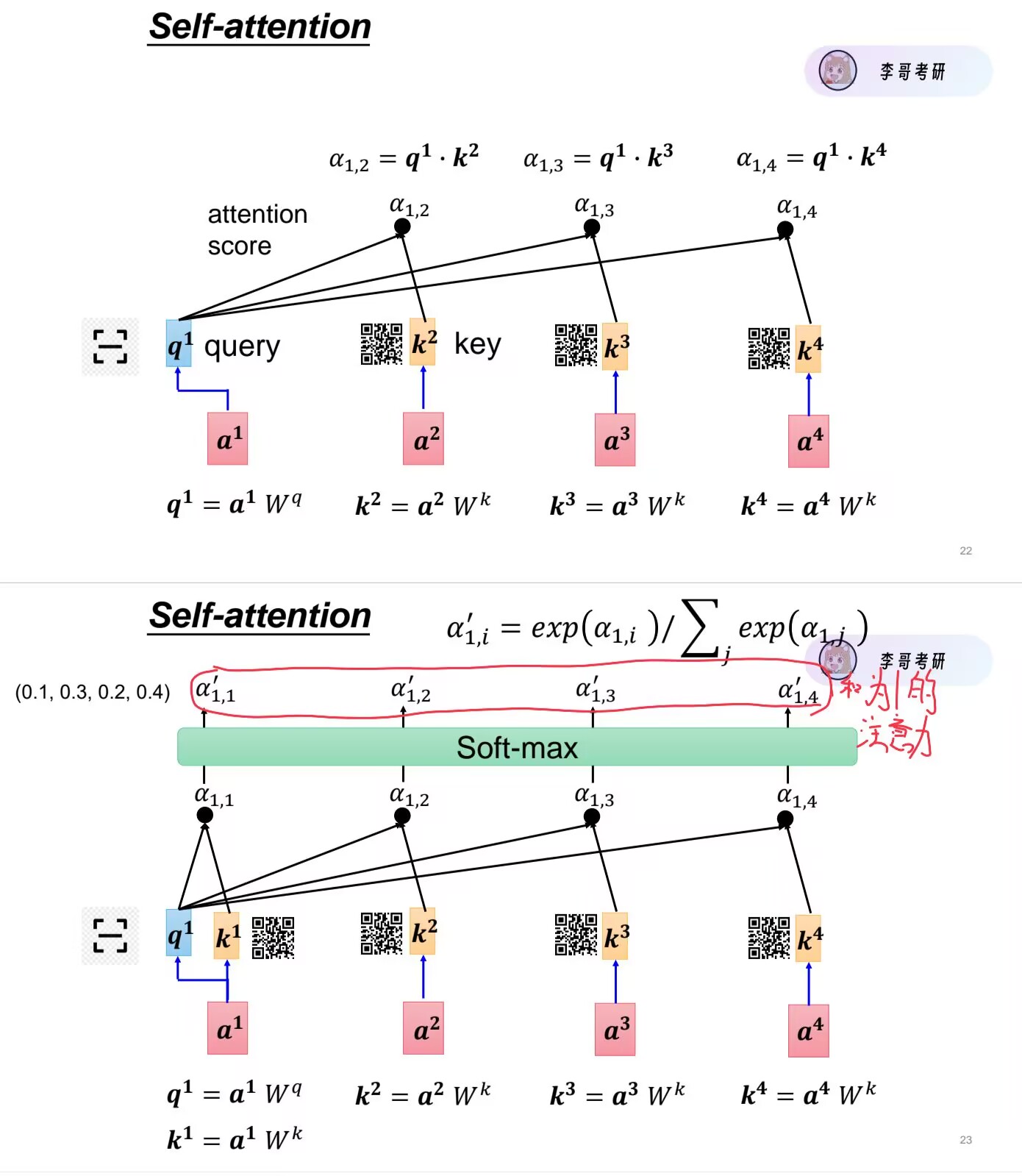
假设输入是一句话:“苹果很好吃,我买了三斤。”
我们把每个词(加上一个开始标记[CLS])想象成相亲大会上的一个嘉宾:
-
嘉宾名单: [CLS], 苹果, 很, 好吃, 我, 买了, 三斤
每个嘉宾刚入场时,只带着自己的基本资料卡(这就是“词向量”,比如[0.2, -0.5, 1.1, …])。
现在,大会要启动“自注意力”环节,让每个嘉宾重新认识自己。
第一步:每个人都准备三张新名片(Q K V)
大会组织者(模型)发给每个人三个可定制的印章(三个可学习的权重矩阵):
查询印章 :盖出 “我想找什么样的人” 的名片。(Query)
键印章 :盖出 “我自己的特质标签” 的名片。(Key)
值印章 :盖出 “我的完整详细资料” 的名片。(Value)
-
苹果用这三个印章,把自己的基本资料卡加工成了三张新名片:Q苹果, K苹果, V苹果。
-
同样,好吃、我等其他嘉宾也各自做出了自己的三张名片。
第二步:互相匹配(计算关系分)
现在,大会进入核心环节。我们以 “苹果” 这位嘉宾为主角,看看他如何更新自己。
苹果拿出自己的 “查询”名片(Q苹果),上面写着他的需求:“我想找和味道、食物、数量相关的人”。
他把这张“查询”名片,依次去和全场每一个人(包括他自己)的 “键”名片(Kxxx) 进行比对。
-
比对好吃的“键”名片:上面可能写着“特质:味道、评价、正面”。哇,匹配度很高!因为都涉及“味道”。关系分:+8分(很高)。
-
比对三斤的“键”名片:上面写着“特质:数量、单位”。有联系!关系分:+5分。
-
比对我的“键”名片:上面写着“特质:人称、主体”。好像不太相关。关系分:+1分(很低)。
-
比对[CLS]的“键”名片:(这是一个特殊嘉宾,代表整个句子的概括)。关系分:+3分。
-
… 以此类推,和全场所有人都比一遍。

第三步:归一化与聚焦(Softmax)
现在,“苹果”手里有一张打分表,记录了他和全场每个人的关系分(8, 5, 1, 3, …)。
但是这些分数大小不一,没法用。所以他要做两件事:
缩放:把所有的分数都除以一个固定值(为了计算稳定,暂时不用深究)。
归一化(Softmax):把分数转换成百分比权重,并且让所有权重加起来等于100%。
-
和好吃的关系分,可能变成了 60% 的权重。
-
和三斤的关系,变成了 25% 的权重。
-
和我的关系,变成了 2% 的权重。
-
… 其他以此类推。
这意味着,在更新“苹果”的认知时,他会用60%的精力去参考“好吃”的信息,用25%的精力参考“三斤”的信息。
第四步:合成新身份(加权求和)
现在,“苹果”拿着这份注意力权重表(60%, 25%, 2%…),开始收集信息。
他走到每个人面前,不是看对方的“键”名片了,而是索要对方的“值”名片(Value),这才是每个人的详细资料。
-
从好吃那里,拿到了关于“美味、甜、可口”的详细资料(V好吃)。
-
从三斤那里,拿到了关于“重量、多、具体”的详细资料(V三斤)。
-
从其他人那里,也拿到了一些资料。
最后,他进行合成:
新“苹果”身份 = 60% × V好吃+ 25% × V三斤+ 2% × V我+ …(其他人的微小贡献)
这个全新的“苹果”身份,不再仅仅是“一种水果”的冰冷概念,而是一个融合了上下文的鲜活概念:“一种被评价为美味、且被购买了特定数量的可食用苹果”。它成功地区别于“苹果公司”的那个“苹果”。

第三部分:升级版——多头注意力(多角度专家团)
你可能会说:一个人做判断可能片面。没错!所以现实中,大会会给每个嘉宾配备一个专家团,比如:
-
语法专家:专门看主谓宾关系。(“苹果”是“好吃”的主语吗?)
-
语义专家:专门看含义关联。(“苹果”和“好吃”是修饰关系。)
-
指代专家:专门看谁买了谁。(“我”买了“苹果”。)
这就是“多头注意力”! 上面的整个过程,只是一个头(一个专家)的做法。
在实际模型中(例如8个头):
同时启动8个独立的“相亲大会”(即8个并行的自注意力计算)。
每个大会(每个头)专注于学习一种类型的关系(如语法、语义、指代等)。
最后,把8个专家分别给“苹果”更新的8个新身份,拼接在一起,形成一个信息量极大、视角极其丰富的 “终极升级版身份牌”。
第四部分:为什么它这么厉害?
-
一步到位,看清全局:不像读句子要一个字一个字读(像RNN),自注意力让每个词瞬间和全句所有词“交换眼神”,立刻建立全局理解。
-
并行高效:因为每个嘉宾更新自己的过程是独立的,所以可以同时进行,计算速度飞快。
-
关系可视化:我们可以画出那个“关系权重表”(注意力热图),看到模型在理解“苹果”时,到底有多关注“好吃”和“三斤”,这带来了可解释性。
-
解决长距离依赖:即使句子很长,“苹果”在句首,“好吃”在句尾,它们也能直接建立强连接,不会被中间词干扰。
RNN(循环神经网络)
RNN是一种拥有“记忆”的神经网络,专门设计用来处理序列数据。它的核心特点是:当前时刻的输出不仅取决于当前的输入,还取决于网络过去所有时刻的“状态”。
为什么需要RNN?—— 序列数据的挑战
很多数据是有顺序的、前后关联的:
-
自然语言:“我 吃 苹果”, “苹果 吃 我” 顺序不同,意思天差地别。
-
时间序列:股票价格、天气数据、语音信号。
-
视频流:连续的图像帧。
对于这种数据,传统的神经网络(如全连接网络、CNN)存在巨大缺陷:
无法处理可变长度输入:固定大小的网络难以处理不同长度的句子。
无视顺序信息:如果把一句话的单词打乱输入,传统网络得到的结果可能一样,因为它没有“顺序”的概念。
无法共享序列中的模式:学习到“在‘我’后面出现‘吃’是合理的”这个规律,无法应用到句子的其他位置。
RNN就是为了解决这些问题而生的。
RNN的工作原理:一个带“记忆包”的加工站
我们用一个简化模型来解释。假设我们要处理一句话:“我爱人工智能”。
关键概念:
-
Xt: 时间步 t的输入(例如,第t个词的词向量)。
-
ht: 时间步 t的隐藏状态(就是那个“记忆包”或“工作笔记”)。它承载了到当前时刻为止,网络所“记住”的所有历史信息。
-
Yt: 时间步 t的输出(例如,预测的下一个词)。
核心公式(可以直观理解):新的记忆 (ht) = 激活函数( [旧的记忆(ht-1), 新的输入(Xt)] * 权重 + 偏置 )

这意味着,在每个时刻,RNN都会做两件事:
融合:将新的输入(Xt) 和上一刻的记忆(ht-1) 结合起来。
更新:产生一个新的记忆(ht),并(可选地)产生一个输出(Yt)。
RNN的致命缺陷
核心缺陷:长期依赖问题(“遗忘症”)
RNN的“记忆” ht是通过反复迭代计算得到的。在反向传播训练时,梯度(用于更新权重的信号)需要沿着时间步一步步回溯。
-
梯度消失:当序列很长时,梯度会像连乘一个小于1的小数一样,指数级地缩小到近乎为0。导致网络无法学习到长距离的依赖关系。早期的记忆(h1)对后期(h100)的影响微乎其微。
-
梯度爆炸:相对少见,梯度指数级增大,导致训练不稳定。
(RNN不利于长序列)
LSTM(长短期记忆网络)
故事背景:普通RNN的“健忘症”问题
想象一个普通员工(标准RNN),他只有一张工作笔记(隐藏状态h)。每天,他:
收到新任务(输入X)。
在旧笔记(h-1) 上直接修改,加入新信息,形成新笔记(h)。
根据新笔记汇报工作(输出Y)。
问题来了:笔记就一张纸,每天涂涂改改。一周后,上周一的重要信息已经被覆盖得模糊不清了。这就是RNN的“梯度消失”——无法记住长期的、重要的信息。
LSTM的解决方案:一个三权分立的智能工作系统
LSTM说:不行,我们需要一个更科学的系统。于是,它给自己配备了三样法宝,构成了一个智能工作流:
核心工作笔记(细胞状态C):像一块可擦写的白板,贯穿整个工作周期。它专门用来记录需要长期记忆的核心要点。修改它需要严格的流程。
每日草稿纸(隐藏状态h):每天对外汇报的摘要。它从核心笔记中提取当天相关的信息生成。
三位智能秘书(三道门):决定信息如何流入、留存和流出这个系统的门控机制。这是LSTM的灵魂。
三位秘书(门)分别是:
-
遗忘门:“哪些旧信息该扔掉了?”
-
它查看上一份对外摘要(h-1) 和新任务(X),然后决定在核心笔记(C-1) 上擦除哪些过时、无用的信息。输出一个0到1之间的数(0表示“全忘”,1表示“全留”)。
-
-
输入门:“哪些新信息值得记入核心笔记?”
-
它有两部分工作:
-
输入门层:判断新任务(X) 的哪些部分重要,值得记录。
-
候选值层:生成一份备选更新内容,也就是新信息应该长什么样。
-
输出门:“今天该对外汇报什么?”
-
它决定基于更新后的核心笔记(C),要生成一份怎样的对外摘要(h)。
工作流程:一步一步看LSTM如何“办公”
假设我们在处理句子:“我 在 法国 学习 了 十年 法语”, 目标是理解整个句子。现在我们看LSTM单元如何处理“法语”这个词。
当前时刻输入:Xt = “法语”
上一时刻的:对外摘要 h-1, 核心笔记 C-1
第一步:遗忘门决定“擦除”什么
-
秘书看到:之前的摘要(h-1)提到了“在法国”、“学习十年”,新词是“法语”。
-
秘书决策:核心笔记(C-1)里记录的“我”、“在”这些信息虽然对理解整个句子背景有用,但和当前要重点理解“法语”的直接关联性降低了。但它绝对不会擦除“法国”、“学习”、“十年”,因为这些是理解“法语”的关键长期背景。
-
结果:生成一个遗忘向量 ft,准备擦除一些次要的长期信息。
第二步:输入门决定“写入”什么
-
输入门层秘书看到“法语”这个词,判断它非常重要,必须写入核心笔记。
-
候选值层秘书生成“法语”这个词的核心含义表示,比如“一种语言”。
-
结果:得到输入向量 it(决定写多少)和候选值 ~Ct(决定写什么)。
第三步:更新核心笔记
-
这是最关键的一步!旧核心笔记C-1 在遗忘门的控制下被有选择地擦除。
-
新信息(候选值) 在输入门的控制下被有选择地加入。
-
更新公式(直观版):新核心笔记 Ct = 遗忘门 * 旧笔记 + 输入门 * 新信息
-
即:Ct = ft * C-1 + it * ~Ct
-
-
结果:现在,核心笔记Ct上清晰地保留着“法国”、“十年”、“学习”这些长期关键信息,并新加入了“法语”。“我在”这些早期信息可能被淡化了,但关键的长期上下文被完美保留了下来。
第四步:输出门决定“汇报”什么
-
秘书基于全新的核心笔记(Ct) 和当前输入(Xt),决定今天输出什么样的摘要。
-
它用tanh函数将核心笔记“激活”一下,然后过滤出与当前最相关的部分。
-
结果:生成此刻的对外摘要 ht。这个ht包含了理解“法语”一词所需的全部精华上下文:在法国、学了十年、一种语言。这个ht会传递给下一个单元,也会用于生成当前时刻的输出(如预测下一个词)。
为什么LSTM能解决长期依赖?
核心笔记的“高速公路”:核心状态C的更新主要是线性操作(加和乘)。这使得梯度在反向传播时可以平缓地流动,不易消失。信息(如“法国”)可以轻松地在这条高速公路上“行驶”很长的距离而不被损耗。
门的精妙控制:三道门都是可学习的。网络通过训练学会:对于长期重要的信息(如“法国”),遗忘门始终保持接近1(完全保留),输入门也小心更新。而对于次要的过渡信息,遗忘门会将其清除。
比喻:就像一个作家在写长篇小说。他有一个主线大纲(细胞状态C),记录着核心情节和人物设定。他还有每日草稿(隐藏状态h)。每写新一章,他会:
-
(遗忘门)决定大纲里哪些早期支线情节可以收尾了。
-
(输入门)决定新一章的重要情节,并写入大纲。
-
(输出门)根据最新大纲,写出当前这一章的详细内容。
大纲保证了故事的核心框架(长期依赖)从头到尾连贯一致。
一个LSTM单元的内部结构可以简化如下:
输入: [旧的摘要h-1, 新任务Xt]
↓
|—-遗忘门—-| (决定从旧笔记C-1中忘掉啥)
|—-输入门—-| (决定新信息~Ct哪些重要)
|—-输出门—-| (决定新摘要ht输出啥)
↓
新笔记 Ct = 遗忘门*旧笔记C-1 + 输入门*新信息~Ct
↓
新摘要 ht = 输出门 * tanh(Ct)
↓
输出: [新摘要ht, 新笔记Ct] (传给下一时刻)
关键创新点总结:
-
细胞状态: 信息传递的“高速公路”,保障长程梯度流动。
-
门控机制: 对信息流进行选择性控制(读、写、擦除),实现了对记忆的精细化管理。
-
加法更新: 核心状态的更新是“旧+新”,而非覆盖,保留了历史。
LSTM的简化版:GRU
GRU(门控循环单元)是LSTM的流行变体,它将遗忘门和输入门合并为一个更新门,同时将细胞状态C和隐藏状态h合并。结构更简单,参数更少,训练更快,效果在多数情况下与LSTM相当。你可以把它理解为LSTM的“精简高效版”。



评论前必须登录!
注册