 网硕互联帮助中心
网硕互联帮助中心在学习 PyTorch 做图像任务时,torchvision.transforms 是一个绕不开、但一开始又容易混乱的模块。最近系统学完了 transforms,这里简单记录一下自己的学习路线和一些关键体会,希望能帮到同样刚入门的小伙伴。
1. 什么是 Transforms?
在深度学习中,原始数据(如 JPG 图片)无法直接送入神经网络。torchvision.transforms 就好比一个工具箱,里面装满了各种“小工具”(函数),专门用于对输入数据进行:
-
格式转换:例如从 PIL 图片转为 Tensor 向量。
-
数据增强:例如缩放、裁剪、翻转等,增加模型的泛化能力。
⚠️ 核心关注点:数据格式
在使用 transforms 时,必须时刻关注:输入是什么,输出是什么?
-
有些工具接收 PIL Image (通过 Image.open 读取)
-
有些工具接收 Tensor (通过 ToTensor 转化)
2. 理解 Python 中的 __call__ 方法
在深入源码前,我们需要理解为什么可以像调用函数一样使用对象(如 tensor_trans(img))。
class Myperson:
def __call__(self, name):
print("__call__被调用: hello " + name)
def hello(self, name):
print("普通方法: hello " + name)
person = Myperson()
person("李四") # 调用__call__方法
person.hello("张三") # 调用普通方法
结论:Transforms 里的各类工具(如 Resize)本质上都是实现了 __call__ 方法的类,方便我们直接调用。
3. 常用工具实战演示
🛠️ 工具一:ToTensor (最基础的操作)
将 PIL Image 或 ndarray 转换为 Tensor,并将像素值归一化到 [0, 1] 之间。
from torchvision import transforms
from PIL import Image
img = Image.open("path/to/img.jpg")
tensor_trans = transforms.ToTensor()
tensor_img = tensor_trans(img) # PIL -> Tensor
🛠️ 工具二:Normalize (标准化,只能处理 Tensor)
使用均值和标准差对 Tensor 进行标准化,加速模型收敛。
计算公式: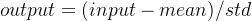
norm_trans = transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])
norm_img = norm_trans(tensor_img)
⚠️ 注意点:
-
Normalize 的输入必须是 Tensor
-
常见用法是把数据归一化到 [-1, 1]
🛠️ 工具三:Resize尺寸变换(PIL / Tensor 都支持)
resize_trans = transforms.Resize((512, 512))
resize_img = resize_trans(tensor_img)
writer.add_image("resize_img", resize_img)
Resize 比较友好的一点是:
-
PIL Image 可以用
-
Tensor 也可以用
但实际工程中,建议统一流程,避免混用导致错误。
🛠️ 工具四:Compose把“工具”串起来用(非常重要)
resize2_trans = transforms.Resize(512)
compose_trans = transforms.Compose([
resize2_trans,
tensor_trans
])
compose_img = compose_trans(img)
writer.add_image("compose_img", compose_img)
我的理解
-
Compose 将多个 transform 步骤打包成一个流水线。
-
前一个 transform 的输出,必须是后一个的合法输入
这也是为什么一般写成:
PIL → Resize → ToTensor → Normalize
🛠️ 工具五:RandomCrop数据增强的第一步
常用于训练集的数据增强,通过从原图中随机切下一块,让模型“见多识广”。
random_crop = transforms.Compose([
transforms.RandomCrop((300, 300)),
transforms.ToTensor()
])
# 循环10次,每次生成的图像都不同
for i in range(10):
crop_img = random_crop(img)
效果是:👉 每一次裁剪的位置都不一样,用于增强模型泛化能力
4. 学习路线建议
看官方文档:重点看每个类(工具)的 Input 和 Output 类型。
| ToTensor() | PIL/numpy | Tensor | 无 |
| Normalize() | Tensor | Tensor | mean, std |
| Resize() | PIL/Tensor | 同输入 | size |
| RandomCrop() | PIL/Tensor | 同输入 | size, padding |
| RandomHorizontalFlip() | PIL/Tensor | 同输入 | p |
结合 TensorBoard:将处理后的 Tensor 实时显示出来,观察数据的变化过程。
注意顺序:Compose 中的列表是有序的,比如一定要先 Resize(PIL 阶段)再 ToTensor,或者顺序反过来,但这取决于具体工具对输入类型的支持。
5. 总结
transforms 学习的关键不在于死记硬背参数,而在于观察输入输出类型。把图片丢进“工具箱”,出来后变成模型喜欢的模样,这就是它的全部意义。
通过合理使用transforms,你可以:
-
统一数据格式
-
提高训练效率
-
增强模型鲁棒性
-
加速模型收敛







评论前必须登录!
注册