 网硕互联帮助中心
网硕互联帮助中心众所周知,Rocketmq从优秀的Kafka演绎改造而成,那为什么Kafka的高吞吐这么亮眼特性没有"借鉴"过来呢? 这就来探讨一下吧!
——深入理解sendfile与mmap的实践差异
本文聚焦《零拷贝》技术!
带着两个问题我们进入接下来的旅程吧~
1.为什么Rocketmq的吞吐量还是小于Kafka呢?
2.为什么不都“借鉴”过来呢?
拉开序幕
背景
我们要做到消息的持久化,防止消息丢失,我们必然要将信息存储到磁盘当中。
我们操作系统划分用户空间和内核空间,程序MQ在用户空间,磁盘属于硬件,依靠操作系统调度,整体分为三层,程序-操作系统(用户控制、内核空间)-硬盘,
那你在用户态要将磁盘中的信息通过网络发送给消费者消费,就得经过:
A:用户程序调用read()方法
1.磁盘内容先拷贝到内核空间的内核缓冲区,然后再
2.从内核缓冲区拷贝到用户空间的用户缓冲区,然后再调用
B.调用write()方法,
3.将用户缓冲区的内容拷贝到内核空间的socket缓存区中,
4.然后再从socket缓冲区拷贝到网卡发送经过网络发送给消费者。
期间会发送2次系统调用(read()、和write()),对于四次用户空间和内核空间的切换、以及四次数据拷贝
流程:
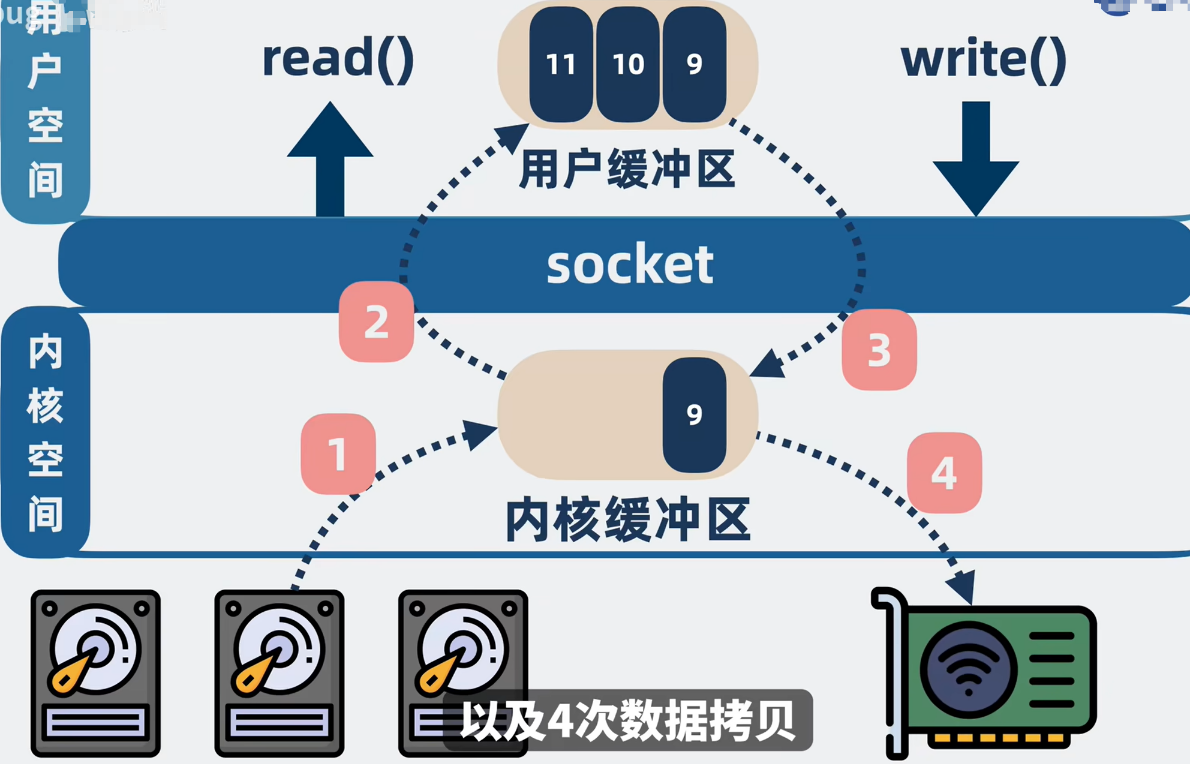
同一份数据来回拷贝4次,性能太低了!零拷贝来解决。
零拷贝升级
命令的齿轮开始转动~
mmap技术
RocketMq采用mmap技术(操作系统提供的一个方法),他可以将内核空间缓冲区的内容映射到 用户空间(这里是不用拷贝的,减少一次拷贝成本)
流程变成:
A.用户空间调用mmap()方法,
1.将磁盘信息拷贝到内核缓冲区,后将内核缓冲区的内容映射到用户缓冲区(不用拷贝就可以实现)
B.然后程序调用write()方法
2.将内核缓冲区的数据拷贝到socket发送缓冲区中(原本是从用户空间缓冲区拷贝过去的),
3.再将socket缓冲区中的数据拷贝到网卡中。
流程:

整个过程发生两次系统调用,3次拷贝,4次用户空间和内核空间的切换(mmap调用、mmap返回、write调用、write返回),整体剩下一次拷贝(内核缓冲区拷贝到用户缓冲区)
整个零拷贝指的是用户空间到内核空间这个过程是零拷贝。而不是指数据从磁盘到网卡整个过程。
sendfile技术
Kafka采用sendfile技术(也是内核提供的一个方法)
流程变成,程序调用
A.调用sendfile方法,然后
1.将磁盘中的内容拷贝到内容缓冲区,
2.然后将内核缓冲区的数据直接拷贝到网卡。
整个过程就1次系统调用,两次用户空间和内核空间的切换(sendfile调用、sendfile返回),两次数据拷贝
流程:
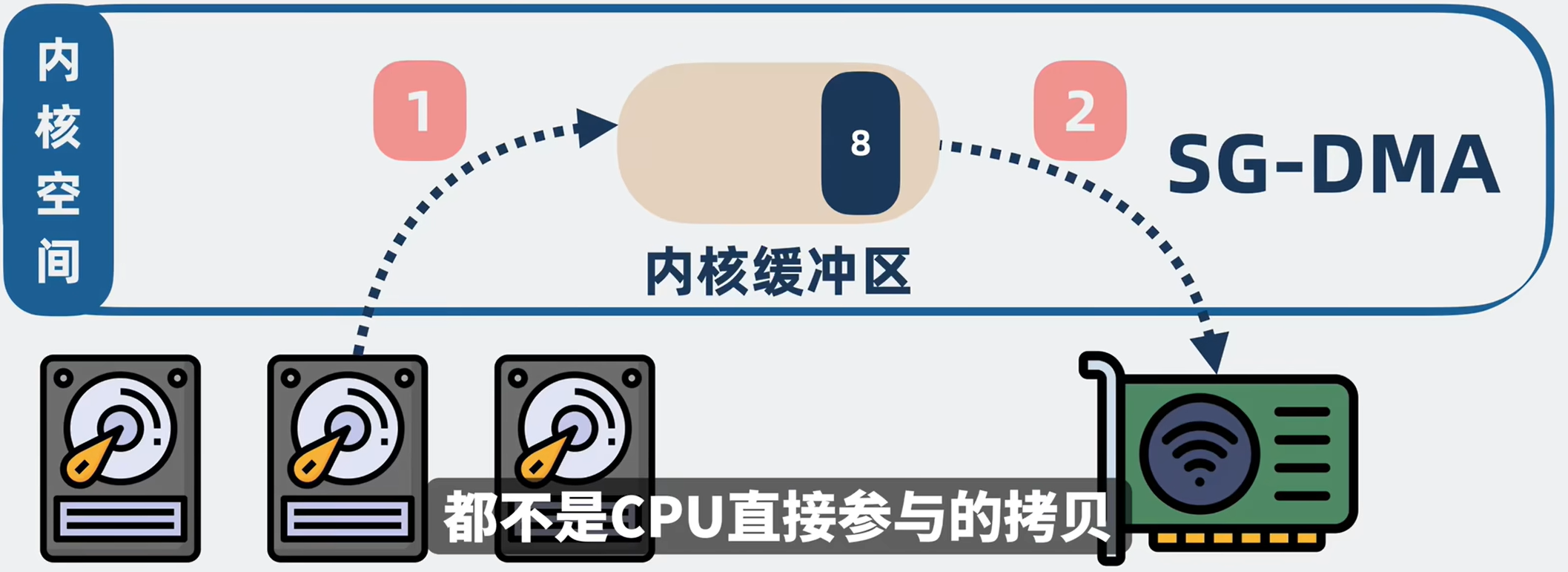
ps:喂喂喂!还是有两次拷贝,说好的0拷贝呢!其实这边的零拷贝指的是0(cpu)拷贝,sendfile的两次拷贝都是不需要cpu直接参与的,而是MDA控制器在干活,不耽误我们cpu跑程序,sendfile以更少的和拷贝次数、内核切换次数获得更好的性能。
那为什么Rocketmq不同sendfile技术呢
世界上没有银弹,没有一种架构是完美的。这种的优化带来的是一点的代价:
mmap技术返回的是数据具体的内容(buf),应用层能获取到具体的消息内容,并进行一些逻辑处理
而sendfile技术直接返回了这次成功发送了几个字节数(num),具体发了什么内容,应用层根本不知道,
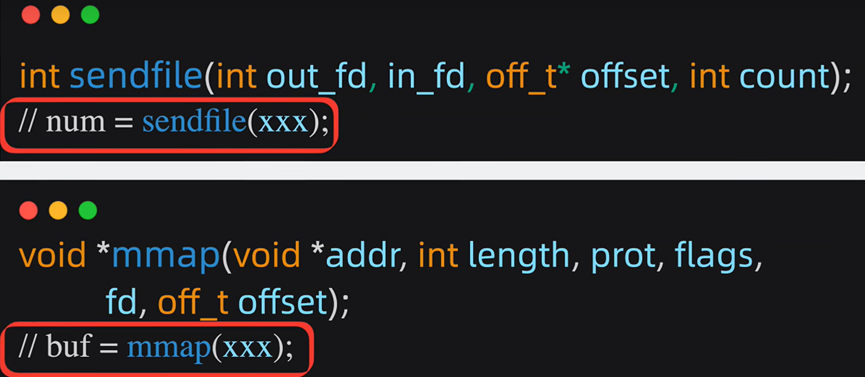
而RocketMQ的一些功能却是需要了解具体的消息内容,方便二次投递等,
比如将消费失败的数据重新投递到死信队列,如果用sendfile就拿不到了,就没办法实现一些比较好的功能.
kafka就直接没这些顾虑,因为他设置这些功能,他追求的是极致的性能!那就使用sendfile风一样的男子呐!当然不是只是这些,比如批处理、数据压缩啊,这些方法rocketmq都可以借鉴,唯独整个零拷贝不行!
没有银弹,没有一种架构是完美的,一种架构往往用于适配某些场景,通过牺牲一部分能力换取另一部分能力,折中折中,可能在所有功能中取一个最优平衡点是个发展方向吧
那么什么场景用kakfa/rocketMq
很宏观的说:
大数据(涉及什么spark\\flink)你就用kafka
其他用rocketmq




评论前必须登录!
注册