 网硕互联帮助中心
网硕互联帮助中心Qwen-Image深度解析:突破文本渲染与图像编辑的视觉生成大模型
1 引言:视觉生成模型的挑战与突破
在AI生成内容领域,图像生成模型面临两大核心挑战:复杂文本渲染和编辑一致性。传统模型在字母文字(如英语)上表现尚可,但在表意文字(如中文)场景中常出现文字扭曲、缺失问题。同时,图像编辑任务中保持原始图像语义连贯性和视觉细节一致性更是业界难题。
Qwen-Image作为Qwen系列首个图像生成基础模型,通过三大创新突破这些瓶颈:
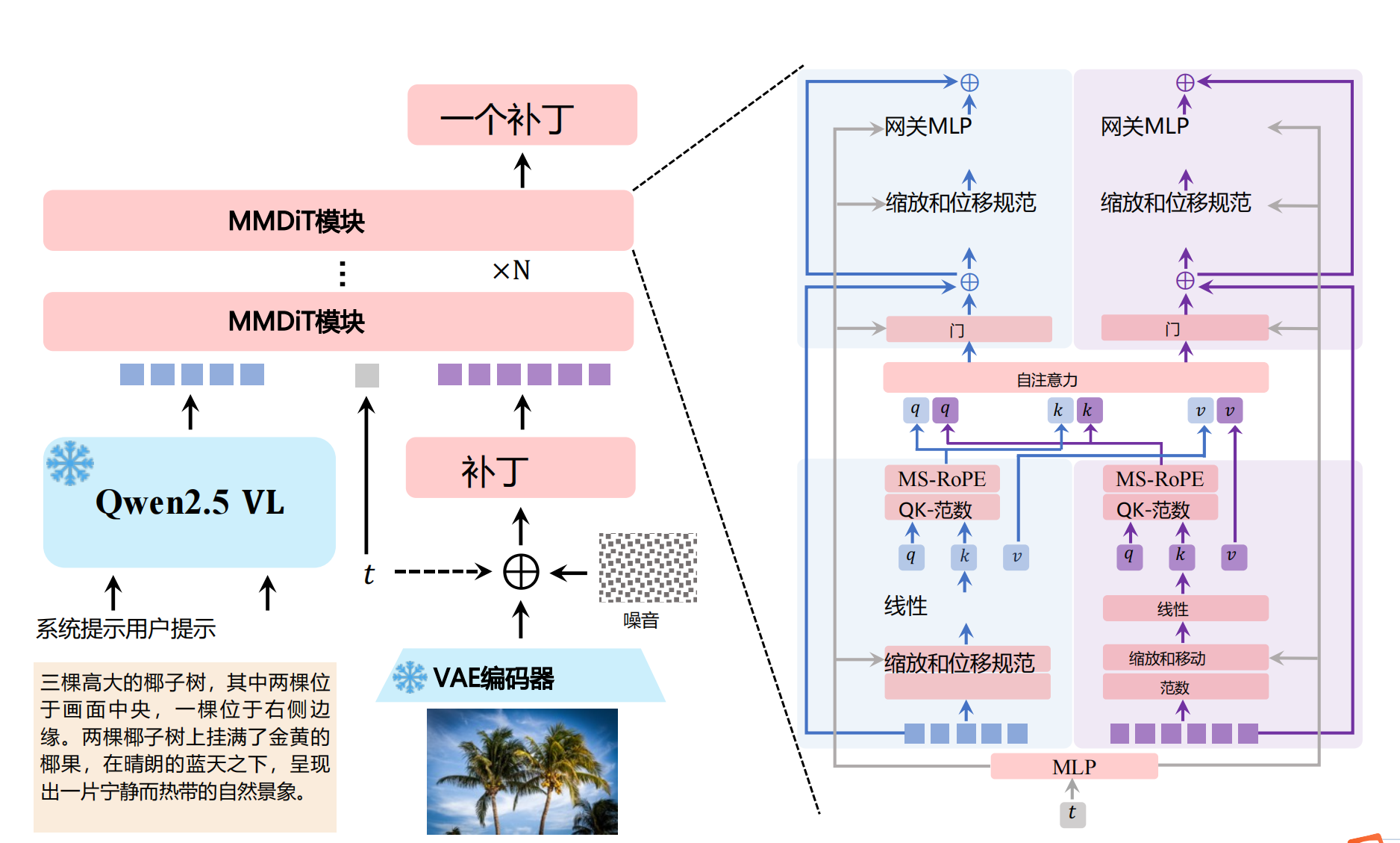
图1:Qwen-Image双流架构:文本流(左)与图像流(右)的协同工作
2 模型架构设计
2.1 整体框架
Qwen-Image基于三模块协同架构:
class QwenImage(nn.Module):
def __init__(self):
super().__init__()
self.mllm = Qwen2_5VL() # 多模态语言模型
self.vae = HybridVAE() # 混合变分自编码器
self.mmdit = MMDiT() # 多模态扩散变换器
def forward(self, text, image=None):
# 语义特征提取
h_text = self.mllm(text)
# 视觉特征提取
if image is not None:
z_vae = self.vae.encode(image)
h_image = self.mllm.visual_encoder(image)
h = torch.cat([h_text, h_image], dim=1)
else:
h = h_text
# 扩散生成
return self.mmdit(h, z_vae)
2.2 多模态语言模型(Qwen2.5-VL)
作为条件编码器,其核心优势在于:
系统提示模板设计:
# 文本到图像任务提示
t2i_prompt = """
<|im_start|>system
描述图像,详细说明颜色、数量、文字、形状、大小、纹理、物体和背景的空间关系:<|im_end|>
<|im_start|>user
{user_text}<|im_end|>
<|im_start|>assistant
"""
# 图像编辑任务提示
t12i_prompt = """
<|im_start|>system
描述输入图像的关键特征,然后说明用户的文字指令如何修改图像<|im_end|>
<|im_start|>user
{user_image}{user_text}<|im_end|>
<|im_start|>assistant
"""
2.3 变分自编码器创新
采用单编码器双解码器架构,解决传统VAE的文本重建缺陷:
class HybridVAE(nn.Module):
def __init__(self):
super().__init__()
self.encoder = 3DConvEncoder() # 共享编码器
self.image_decoder = ImageDecoder()
self.video_decoder = VideoDecoder()
def forward(self, x, mode='image'):
z = self.encoder(x)
if mode == 'image':
return self.image_decoder(z)
else: # video
return self.video_decoder(z)
训练关键发现:
- 平衡重建损失(L1)与感知损失(VGG)减少伪影
- 对抗损失在高质量重建时效果减弱
- 仅微调解码器即可提升小文本渲染
2.4 多模态扩散变换器
采用MMDiT架构并创新MSRoPE位置编码:
class MMDiT(nn.Module):
def __init__(self, dim=1024, heads=16):
super().__init__()
self.layers = nn.ModuleList([
DiTBlock(dim, heads, use_msrope=True)
for _ in range(24)
])
def forward(self, h, z):
x = self.ms_rope(h, z) # 多模态位置编码
for layer in self.layers:
x = layer(x)
return x
def ms_rope(text_emb, image_emb):
"""
多模态可扩展旋转位置编码
text_emb: [B, L_t, D]
image_emb: [B, H, W, D]
"""
# 文本视为对角线布局
text_pos = diag_position(text_emb.shape[1])
text_rot = apply_rope(text_emb, text_pos)
# 图像中心起始编码
img_pos = center_position(image_emb.shape[1:3])
img_rot = apply_rope(image_emb, img_pos)
return torch.cat([text_rot, img_rot], dim=1)
图2:MSRoPE位置编码策略(文本沿对角线,图像从中心辐射)
3 数据处理流程
3.1 数据收集策略
构建百亿级图文对数据集,四类数据分布:
#mermaid-svg-NgVuZR1w6VrznDR7 {font-family:\”trebuchet ms\”,verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-NgVuZR1w6VrznDR7 .error-icon{fill:#552222;}#mermaid-svg-NgVuZR1w6VrznDR7 .error-text{fill:#552222;stroke:#552222;}#mermaid-svg-NgVuZR1w6VrznDR7 .edge-thickness-normal{stroke-width:2px;}#mermaid-svg-NgVuZR1w6VrznDR7 .edge-thickness-thick{stroke-width:3.5px;}#mermaid-svg-NgVuZR1w6VrznDR7 .edge-pattern-solid{stroke-dasharray:0;}#mermaid-svg-NgVuZR1w6VrznDR7 .edge-pattern-dashed{stroke-dasharray:3;}#mermaid-svg-NgVuZR1w6VrznDR7 .edge-pattern-dotted{stroke-dasharray:2;}#mermaid-svg-NgVuZR1w6VrznDR7 .marker{fill:#333333;stroke:#333333;}#mermaid-svg-NgVuZR1w6VrznDR7 .marker.cross{stroke:#333333;}#mermaid-svg-NgVuZR1w6VrznDR7 svg{font-family:\”trebuchet ms\”,verdana,arial,sans-serif;font-size:16px;}#mermaid-svg-NgVuZR1w6VrznDR7 .pieCircle{stroke:black;stroke-width:2px;opacity:0.7;}#mermaid-svg-NgVuZR1w6VrznDR7 .pieTitleText{text-anchor:middle;font-size:25px;fill:black;font-family:\”trebuchet ms\”,verdana,arial,sans-serif;}#mermaid-svg-NgVuZR1w6VrznDR7 .slice{font-family:\”trebuchet ms\”,verdana,arial,sans-serif;fill:#333;font-size:17px;}#mermaid-svg-NgVuZR1w6VrznDR7 .legend text{fill:black;font-family:\”trebuchet ms\”,verdana,arial,sans-serif;font-size:17px;}#mermaid-svg-NgVuZR1w6VrznDR7 :root{–mermaid-font-family:\”trebuchet ms\”,verdana,arial,sans-serif;}
3.2 七阶段数据过滤
精密的多级过滤流程:
def multi_stage_filter(images, texts, stage):
if stage == 1: # 初始清理
images = filter_corrupted(images)
images = filter_low_res(images, min_res=256)
texts = filter_invalid_text(texts)
elif stage == 2: # 质量优化
images = filter_blur(images, threshold=0.7)
images = filter_low_entropy(images, threshold=2.0)
elif stage == 3: # 图文对齐
pairs = clip_alignment(images, texts, threshold=0.85)
elif stage == 4: # 文本渲染增强
images, texts = augment_text_rendering(images, texts)
# 阶段5-7处理高分辨率平衡
return refined_data
3.3 结构化数据标注
创新标注框架同步生成描述与元数据:
{
"caption": "咖啡馆内景,木桌上放着白色马克杯,杯身印有'Hello World'字样",
"image_type": "室内摄影",
"image_style": "写实风格",
"watermark_list": [],
"abnormal_elements": false
}
3.4 文本渲染增强
三阶段合成策略解决中文长尾分布问题:
def render_text_synthesis(mode, text, background):
if mode == "pure": # 纯文本渲染
return render_on_plain_bg(text, font_size=24)
elif mode == "composite": # 情境合成
canvas = place_on_realistic_bg(text, background)
caption = generate_context_caption(canvas)
return canvas, caption
elif mode == "complex": # 复杂布局
template = select_template("ppt")
return fill_template(template, text)
4 训练策略详解
4.1 预训练阶段
采用流匹配目标函数:
v
t
=
d
x
t
d
t
=
x
0
−
x
1
v_t = \\frac{dx_t}{dt} = x_0 – x_1
vt=dtdxt=x0−x1
L
=
E
∣
∣
v
θ
(
x
t
,
t
,
h
)
−
v
t
∣
∣
2
\\mathcal{L} = \\mathbb{E}||v_\\theta(x_t,t,h) – v_t||^2
L=E∣∣vθ(xt,t,h)−vt∣∣2
4.1.1 生产者-消费者框架
# 生产者节点
def producer_process(data_queue):
while True:
raw_data = load_raw_data()
filtered = stage_filter(raw_data, current_stage)
processed = {
'h': mllm.encode(filtered['text']),
'z': vae.encode(filtered['image'])
}
data_queue.put(processed)
# 消费者节点
def consumer_process(data_queue, model):
while True:
batch = data_queue.get_batch(32)
loss = model(batch)
loss.backward()
optimizer.step()
4.1.2 分布式训练优化 关键技术创新:
- 4路张量并行
- bfloat16梯度聚合+float32归约
- 禁用激活检查点(节省11.3%显存)
4.1.3 渐进式训练策略 五维渐进学习:
training_strategy = {
'resolution': ['256×256', '640×640', '1328×1328'],
'text_rendering': ['none', 'single', 'paragraph'],
'data_quality': ['mass', 'curated'],
'data_balance': ['imbalanced', 'balanced'],
'data_source': ['real', 'synthetic']
}
4.2 后训练优化
4.2.1 监督微调(SFT) 构建分层语义数据集:
- 精选高清晰度、细节丰富的图像
- 人工标注突出关键视觉特征
- 平衡艺术风格与真实感样本
4.2.2 强化学习优化 融合DPO与GRPO:
# DPO损失函数
def dpo_loss(policy_model, ref_model, win_data, lose_data):
t = uniform_sample(0, 1)
x_t_win = t * win_data.x0 + (1–t) * noise
v_t_win = win_data.x0 – noise
diff_policy = policy_model(x_t_win, t).mse(v_t_win) – policy_model(x_t_lose, t).mse(v_t_lose)
diff_ref = ref_model(x_t_win, t).mse(v_t_win) – ref_model(x_t_lose, t).mse(v_t_lose)
return –torch.log(torch.sigmoid(–beta*(diff_policy – diff_ref)))
# GRPO训练流程
def grpo_train(policy, ref_model, prompt):
trajectories = [policy.generate(prompt) for _ in range(8)]
rewards = reward_model(trajectories)
advantages = (rewards – rewards.mean()) / rewards.std()
for traj in trajectories:
for t in range(len(traj)):
ratio = policy_prob(traj[t]) / ref_model_prob(traj[t])
kl_div = compute_kl(policy, ref_model, traj[t])
loss = min(ratio*advantages, clip(ratio, 0.8, 1.2)*advantages – beta*kl_div
loss.backward()
4.3 多任务训练扩展
统一处理框架支持:
def multitask_forward(task_type, text, image=None):
if task_type == 'T2I':
return model.generate_from_text(text)
elif task_type == 'TI2I':
h_image = model.encode_image(image)
return model.edit_image(text, h_image)
elif task_type == 'depth_estimation':
return model.predict_depth(image)
elif task_type == 'novel_view':
return model.render_new_view(image, text)
5 实验评估
5.1 人类评估(AI竞技场)
建立开放评估平台:
#mermaid-svg-PLgN2WOAD9AKTmOV {font-family:\”trebuchet ms\”,verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-PLgN2WOAD9AKTmOV .error-icon{fill:#552222;}#mermaid-svg-PLgN2WOAD9AKTmOV .error-text{fill:#552222;stroke:#552222;}#mermaid-svg-PLgN2WOAD9AKTmOV .edge-thickness-normal{stroke-width:2px;}#mermaid-svg-PLgN2WOAD9AKTmOV .edge-thickness-thick{stroke-width:3.5px;}#mermaid-svg-PLgN2WOAD9AKTmOV .edge-pattern-solid{stroke-dasharray:0;}#mermaid-svg-PLgN2WOAD9AKTmOV .edge-pattern-dashed{stroke-dasharray:3;}#mermaid-svg-PLgN2WOAD9AKTmOV .edge-pattern-dotted{stroke-dasharray:2;}#mermaid-svg-PLgN2WOAD9AKTmOV .marker{fill:#333333;stroke:#333333;}#mermaid-svg-PLgN2WOAD9AKTmOV .marker.cross{stroke:#333333;}#mermaid-svg-PLgN2WOAD9AKTmOV svg{font-family:\”trebuchet ms\”,verdana,arial,sans-serif;font-size:16px;}#mermaid-svg-PLgN2WOAD9AKTmOV .label{font-family:\”trebuchet ms\”,verdana,arial,sans-serif;color:#333;}#mermaid-svg-PLgN2WOAD9AKTmOV .cluster-label text{fill:#333;}#mermaid-svg-PLgN2WOAD9AKTmOV .cluster-label span{color:#333;}#mermaid-svg-PLgN2WOAD9AKTmOV .label text,#mermaid-svg-PLgN2WOAD9AKTmOV span{fill:#333;color:#333;}#mermaid-svg-PLgN2WOAD9AKTmOV .node rect,#mermaid-svg-PLgN2WOAD9AKTmOV .node circle,#mermaid-svg-PLgN2WOAD9AKTmOV .node ellipse,#mermaid-svg-PLgN2WOAD9AKTmOV .node polygon,#mermaid-svg-PLgN2WOAD9AKTmOV .node path{fill:#ECECFF;stroke:#9370DB;stroke-width:1px;}#mermaid-svg-PLgN2WOAD9AKTmOV .node .label{text-align:center;}#mermaid-svg-PLgN2WOAD9AKTmOV .node.clickable{cursor:pointer;}#mermaid-svg-PLgN2WOAD9AKTmOV .arrowheadPath{fill:#333333;}#mermaid-svg-PLgN2WOAD9AKTmOV .edgePath .path{stroke:#333333;stroke-width:2.0px;}#mermaid-svg-PLgN2WOAD9AKTmOV .flowchart-link{stroke:#333333;fill:none;}#mermaid-svg-PLgN2WOAD9AKTmOV .edgeLabel{background-color:#e8e8e8;text-align:center;}#mermaid-svg-PLgN2WOAD9AKTmOV .edgeLabel rect{opacity:0.5;background-color:#e8e8e8;fill:#e8e8e8;}#mermaid-svg-PLgN2WOAD9AKTmOV .cluster rect{fill:#ffffde;stroke:#aaaa33;stroke-width:1px;}#mermaid-svg-PLgN2WOAD9AKTmOV .cluster text{fill:#333;}#mermaid-svg-PLgN2WOAD9AKTmOV .cluster span{color:#333;}#mermaid-svg-PLgN2WOAD9AKTmOV div.mermaidTooltip{position:absolute;text-align:center;max-width:200px;padding:2px;font-family:\”trebuchet ms\”,verdana,arial,sans-serif;font-size:12px;background:hsl(80, 100%, 96.2745098039%);border:1px solid #aaaa33;border-radius:2px;pointer-events:none;z-index:100;}#mermaid-svg-PLgN2WOAD9AKTmOV :root{–mermaid-font-family:\”trebuchet ms\”,verdana,arial,sans-serif;}
生成提示词
模型A匿名生成
模型B匿名生成
人类评估
Elo评分更新
Qwen-Image在主流闭源模型中排名第二:
| Imagen 4 Ultra | 1250 |
| Qwen-Image | 1220 |
| GPT Image 1 | 1190 |
| FLUX.1 Kontext | 1185 |
5.2 定量分析
5.2.1 VAE重建性能 在文本重建任务中显著领先:
| 模型 | Text PSNR | SSIM |
|—————–|———–|——–|
| Wan2.1-VAE | 26.77 | 0.9386 |
| FLUX-VAE | 32.65 | 0.9792 |
| Qwen-Image-VAE | 36.63 | 0.9839 |
5.2.2 文本生成性能 中文渲染碾压级优势:
| 模型 | 一级汉字 | 二级汉字 | 三级汉字 |
|—————|———|———|———|
| Seedream 3.0 | 53.48 | 26.23 | 1.25 |
| GPT Image 1 | 68.37 | 15.97 | 3.55 |
| Qwen-Image | 97.29 | 40.53 | 6.48 |
5.3 定性分析
5.3.1 中文文本渲染 
图3:Qwen-Image精准生成复杂中文对联
5.3.2 多对象生成
提示词:“十二生肖毛绒玩具整齐排列,三行四列”
Qwen-Image唯一正确生成所有12个生肖形象并保持材质一致性。
6 代码实现关键模块
6.1 流匹配训练核心
def flow_matching_loss(model, x0, h):
# 采样随机噪声和时间步
x1 = torch.randn_like(x0)
t = torch.rand(x0.size(0), device=x0.device)
# 计算中间状态
xt = t[:, None, None, None] * x0 + (1–t)[:, None, None, None] * x1
vt = x0 – x1
# 模型预测
v_pred = model(xt, t, h)
return F.mse_loss(v_pred, vt)
6.2 生产者-消费者框架
class DataPipeline:
def __init__(self, num_producers=8):
self.queue = PriorityQueue(maxsize=1000)
self.producers = [Producer(self.queue) for _ in range(num_producers)]
self.consumer = Consumer(self.queue)
def start(self):
for p in self.producers:
p.start()
self.consumer.start()
class Producer(Thread):
def run(self):
while True:
data = self.load_next_batch()
processed = self.process(data)
self.queue.put(processed, priority=data['quality_score'])
class Consumer(Thread):
def run(self):
model = build_model()
while True:
batch = self.queue.get_batch(32)
loss = model.train_step(batch)
update_model(loss)
6.3 渐进式训练调度器
class ProgressiveScheduler:
def __init__(self, total_steps):
self.stage_schedule = {
'resolution': [
(0, 0.3, 256),
(0.3, 0.7, 640),
(0.7, 1.0, 1328)
],
'text_complexity': [
(0, 0.4, 'word'),
(0.4, 0.8, 'line'),
(0.8, 1.0, 'paragraph')
]
}
def update(self, step, total):
progress = step / total
config = {}
for key, stages in self.stage_schedule.items():
for start, end, value in stages:
if start <= progress < end:
config[key] = value
break
return config
7 应用场景与未来方向
7.1 产业应用价值
elements=["折扣标签", "产品图片", "联系方式"],
style="现代简约")
7.2 技术演进方向
创新启示:Qwen-Image的技术突破证明,生成模型可通过对底层分布的建模实现深度理解,这模糊了生成与理解的界限,为多模态AGI开辟了新路径。
结论
Qwen-Image通过三项根本性创新重塑图像生成范式:
其技术影响已超越图像生成领域,预示了三个未来方向:
随着代码开源(GitHub链接和模型权重释放,Qwen-Image将成为生成式AI发展的重要里程碑。
参考文献:









评论前必须登录!
注册