 网硕互联帮助中心
网硕互联帮助中心一. 函数定义和功能
get_html(url, timeout=3)
-
功能:
-
获取网页的HTML内容。
-
参数:
-
url:目标网页的URL。
-
timeout:请求超时时间,默认为3秒。
-
-
实现:
-
使用requests.get发送HTTP GET请求。
-
设置编码为页面的实际编码(r.apparent_encoding)。
-
检查请求是否成功(r.raise_for_status())。
-
如果成功,返回HTML内容;如果失败,打印错误信息并返回None。
-
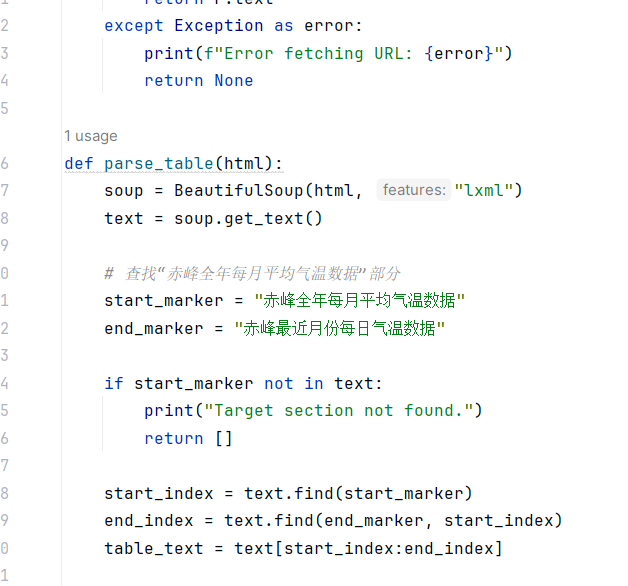
parse_table(html)
-
功能:
-
从HTML中解析出“赤峰全年每月平均气温数据”部分,并提取表格数据。
-
参数:
-
html:网页的HTML内容。
-
-
实现:
-
使用BeautifulSoup解析HTML。
-
查找“赤峰全年每月平均气温数据”部分的起始和结束标记。
-
提取这部分文本内容。
-
使用正则表达式提取表格中的数据(月份、高温、低温、空气、能见度、风速、总降雨)。
-
将提取的数据存储为二维列表(第一行为表头)。
-
save_csv(data, path)
-
功能:
-
将提取的数据保存为CSV文件。
-
参数:
-
data:提取的数据,以二维列表形式存储。
-
path:保存的文件路径。
-
-
实现:
-
使用csv.writer将数据写入CSV文件。
-
二. 主程序逻辑
if __name__ == "__main__":
url = "https://www.tianqi24.com/chifeng/history.html"
html = get_html(url)
if html:
data = parse_table(html)
if data:
save_csv(data, "chifeng.csv")
print("Data saved to chifeng.csv")
else:
print("No data to save.")
-
流程:
-
定义目标URL。
-
调用get_html获取网页HTML内容。
-
如果成功获取HTML内容,调用parse_table解析数据。
-
如果解析到数据,调用save_csv将数据保存为CSV文件。
-
打印保存成功或失败的信息。
三. 代码的关键点
get_html函数
-
通过requests.get获取网页内容。
-
检查请求是否成功(r.raise_for_status())。
-
设置编码为页面的实际编码(r.apparent_encoding)。
parse_table函数
-
使用BeautifulSoup解析HTML。
-
使用正则表达式提取表格数据。
-
正则表达式r"(\\d{4}年\\d{2}月)\\s+(-?\\d+℃)\\s+(-?\\d+℃)\\s+(\\d+ \\w+)\\s+(\\d+\\.\\d+km)\\s+(\\d+\\.\\d+km/h)\\s+(\\d+\\.?\\d*)":
-
匹配月份(如2024年01月)。
-
匹配高温和低温(如-3℃)。
-
匹配空气质量(如53 优)。
-
匹配能见度(如29.7km)。
-
匹配风速(如9.5km/h)。
-
匹配总降雨量(如0)。
-
-
save_csv函数
-
使用csv.writer将数据写入CSV文件。
四. 代码的运行结果
-
如果网页内容正常获取且解析成功,会生成一个名为chifeng.csv的文件,内容如下:
月份,高温,低温,空气,能见度,风速,总降雨
2024年01月,-3℃,-16℃,53 优,29.7km,9.5km/h,0
2024年02月,1℃,-13℃,58 优,28.2km,10.9km/h,0.4
… -
如果网页内容获取失败或解析失败,会打印相应的错误信息。

五、数据处理
1.删除包含有零的行
import pandas as pd
import numpy as np
# 读取 CSV 文件
df = pd.read_csv("chifeng.csv")
# 将 0 替换为 NaN
df.replace(0, np.nan, inplace=True)
# 删除包含 NaN 的行
new_df = df.dropna()
# 打印处理后的数据
print(new_df.to_string())
2.用指定内容来替换一些空字段
#用指定内容来替换一些空字段
import pandas as pd
# 读取 CSV 文件
df = pd.read_csv("chifeng.csv")
# 将 0 替换为 '零'
new_df = df.replace(0, '零')
# 打印处理后的数据
print(new_df.to_string())
3.计算列的均值替换空单元格
#计算列的均值替换空单元格
import pandas as pd
# 读取 CSV 文件
df = pd.read_csv("chifeng.csv")
# 计算每一列的均值,忽略非数值列和 NaN 值
column_means = df.mean()
# 遍历每一列,将 0 替换为该列的均值
for column in df.columns:
# 检查列是否为数值类型
if pd.api.types.is_numeric_dtype(df[column]):
# 将 0 替换为该列的均值
df[column] = df[column].replace(0, column_means[column])
# 打印处理后的数据
print(df.to_string())
4.计算列的中位数替换空单元格
#计算列的中位数替换空单元格
import pandas as pd
# 读取 CSV 文件
df = pd.read_csv("chifeng.csv")
# 计算每一列的中位数,忽略非数值列和 NaN 值
column_medians = df.median()
# 遍历每一列,将 0 替换为该列的中位数
for column in df.columns:
# 检查列是否为数值类型
if pd.api.types.is_numeric_dtype(df[column]):
# 将 0 替换为该列的中位数
df[column] = df[column].replace(0, column_medians[column])
# 打印处理后的数据
print(df.to_string())
六、图像
1.创建柱状图
import matplotlib.pyplot as plt
# 每个月的空气质量指数(AQI)
aqi_data = {
"1": 53,
"2": 58,
"4": 50,
"5": 55,
"6": 38,
"7": 35,
"8": 31,
"9": 30,
"10": 37,
"11": 52,
"12": 30
}
# 将数据转换为列表
months = list(aqi_data.keys())
aqi = list(aqi_data.values())
plt.figure(figsize=(10, 6))
plt.bar(months, aqi, color='skyblue')
plt.title('Monthly AQI')
plt.xlabel('Month')
plt.ylabel('AQI')
plt.show()
2.创建饼图
plt.figure(figsize=(8, 8))
plt.pie(aqi, labels=months)
plt.title('AQI Distribution')
plt.show()
3.创建水平柱状图(barh)
plt.figure(figsize=(10, 6))
plt.barh(months, aqi, color='green')
plt.title('Monthly AQI (Horizontal Bar)')
plt.xlabel('AQI')
plt.ylabel('Month')
plt.show()
4.创建折线图
plt.figure(figsize=(10, 6))
plt.plot(months, aqi, marker='o', color='red')
plt.title('Monthly AQI Line Chart')
plt.xlabel('Month')
plt.ylabel('AQI')
plt.show()
5.创建散点图
plt.figure(figsize=(10, 6))
plt.scatter(months, aqi, color='hotpink')
plt.title('Monthly AQI Scatter Plot')
plt.xlabel('Month')
plt.ylabel('AQI')
plt.show()







评论前必须登录!
注册