 网硕互联帮助中心
网硕互联帮助中心RAG:大模型的外挂神器,解锁AI新姿势
一、RAG 是什么
RAG,全称 Retrieval-Augmented Generation,即检索增强生成,是一种将检索技术与生成模型相结合的技术框架,简单来说,它就像是给大模型配备的一个 “外挂知识库”。
传统的大语言模型在回答问题时,只能依赖自身在训练过程中学习到的知识 ,一旦遇到训练数据中没有涵盖的内容,就可能出现回答不准确、缺乏针对性,甚至 “胡言乱语” 的情况,也就是我们常说的 “幻觉” 现象。而 RAG 的出现,很好地解决了这些问题。
RAG 的核心原理是在大模型生成回答之前,先从外部知识源(如数据库、文档库、互联网等)中检索与问题相关的信息,然后将这些检索到的信息作为额外的上下文输入到模型中 ,帮助模型生成更加准确、丰富和符合上下文的回答。就好比你在考试时,遇到不会的题目,可以查阅参考资料,再给出答案,而不是单纯依靠自己的记忆。通过这种方式,RAG 能够让大模型在处理各种任务时,生成的结果更加贴近真实需求,大大提升了模型的实用性和可靠性 。
二、RAG 诞生,解决大模型痛点
大语言模型虽然在自然语言处理任务中展现出了惊人的能力 ,但它们并非完美无缺,在实际应用中,大模型暴露出了不少局限性。
首先是知识时效性问题。大模型的训练数据往往来自过去某个时间段的语料库 ,这就导致它们对于训练完成之后发生的新事件、新趋势以及新的研究成果等信息了解甚少。比如,若训练数据截止到 2022 年,那么对于 2023 年才出现的新科技产品、新政策法规等问题,大模型就可能无法给出准确且最新的回答 。
其次是知识准确性。由于大模型是基于大规模数据进行训练学习,通过概率计算来生成回答,并非真正理解知识,所以在回答问题时容易产生 “幻觉”,也就是编造一些看似合理但实际上并不存在或错误的信息。例如,在询问某些复杂的科学原理、历史事件细节时,大模型可能会给出错误的解释或不准确的描述 。
最后,当涉及到专业领域知识时,通用大模型的表现也往往差强人意。专业领域知识通常具有高度的专业性和复杂性,需要深入的专业理解和背景知识 。像医疗、法律、金融等领域,对于知识的准确性和专业性要求极高,通用大模型如果没有经过专业数据的充分训练,很难提供专业、可靠的答案 。
正是为了解决这些问题,RAG 技术应运而生。它通过检索外部知识库,引入实时和准确的信息,让大模型在生成回答时能够有更多的参考依据,从而有效提升回答的准确性、时效性以及专业性,为大模型在实际场景中的应用开辟了更广阔的道路 。
三、RAG 工作原理大揭秘
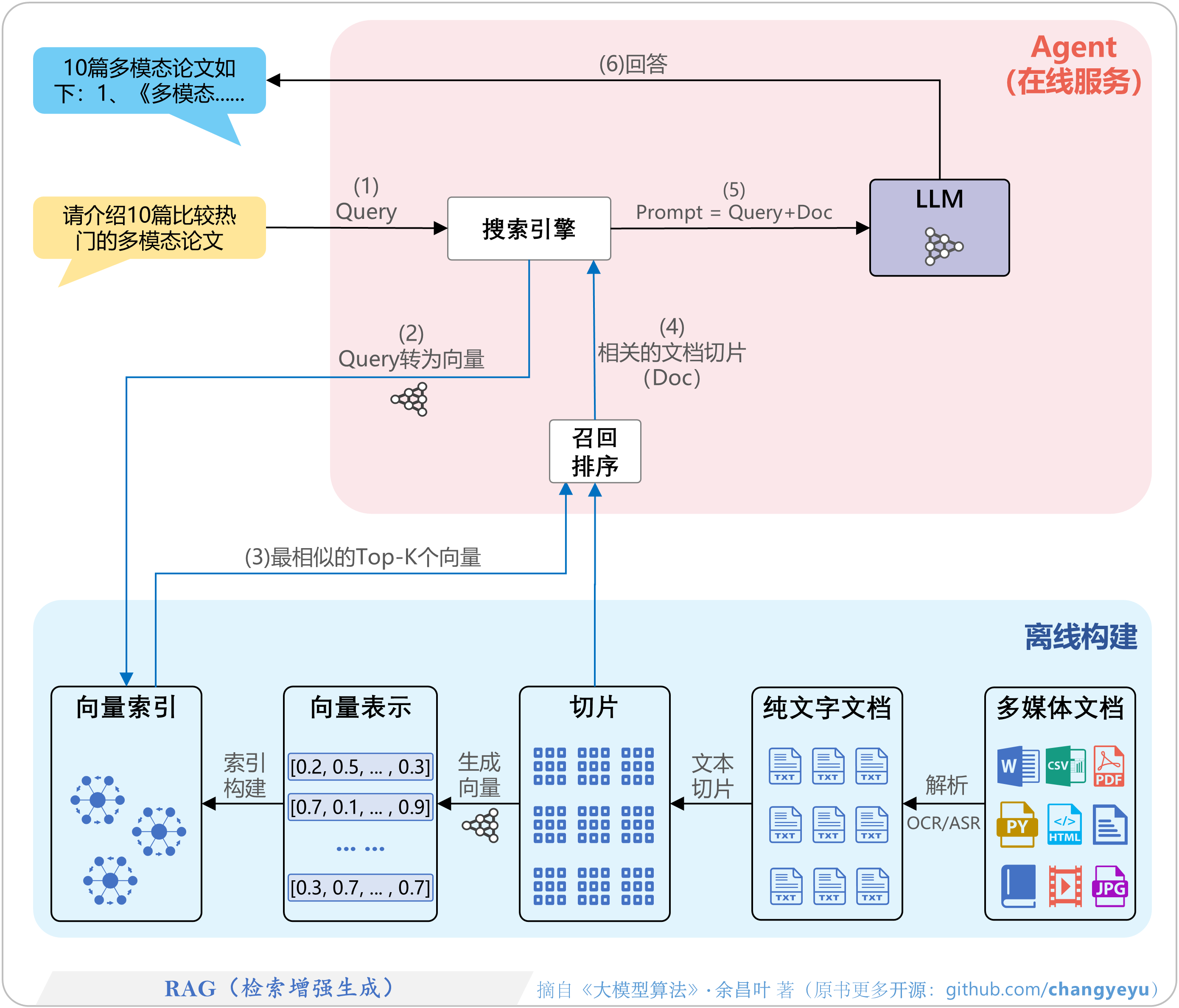
(一)构建知识库
要想让 RAG 技术发挥作用,首先得构建一个强大的可检索知识库,就好比搭建一座知识宝库,方便后续快速从中获取所需信息 。这个过程主要包含以下几个关键步骤 :
知识整理:把各种来源的知识,以文件格式存储起来,像常见的 word、pdf、ppt、excel 文档,或者在线网页内容等,这些都是构建知识库的原材料 。
数据清洗及格式化:不同格式的数据内容需要提取为纯文本,方便后续处理。同时,还得清理数据中的噪声、错误和冗余信息,比如删除文档中不必要的页眉页脚、修正错别字等,让数据变得干净整洁 。
内容切分:将整理好的文本内容按段落、主体或者逻辑单元切分成较小的知识片段(Chunk) 。因为大模型处理能力有限,把长文本切分成小片段,更便于模型理解和处理,也能提高检索效率 。
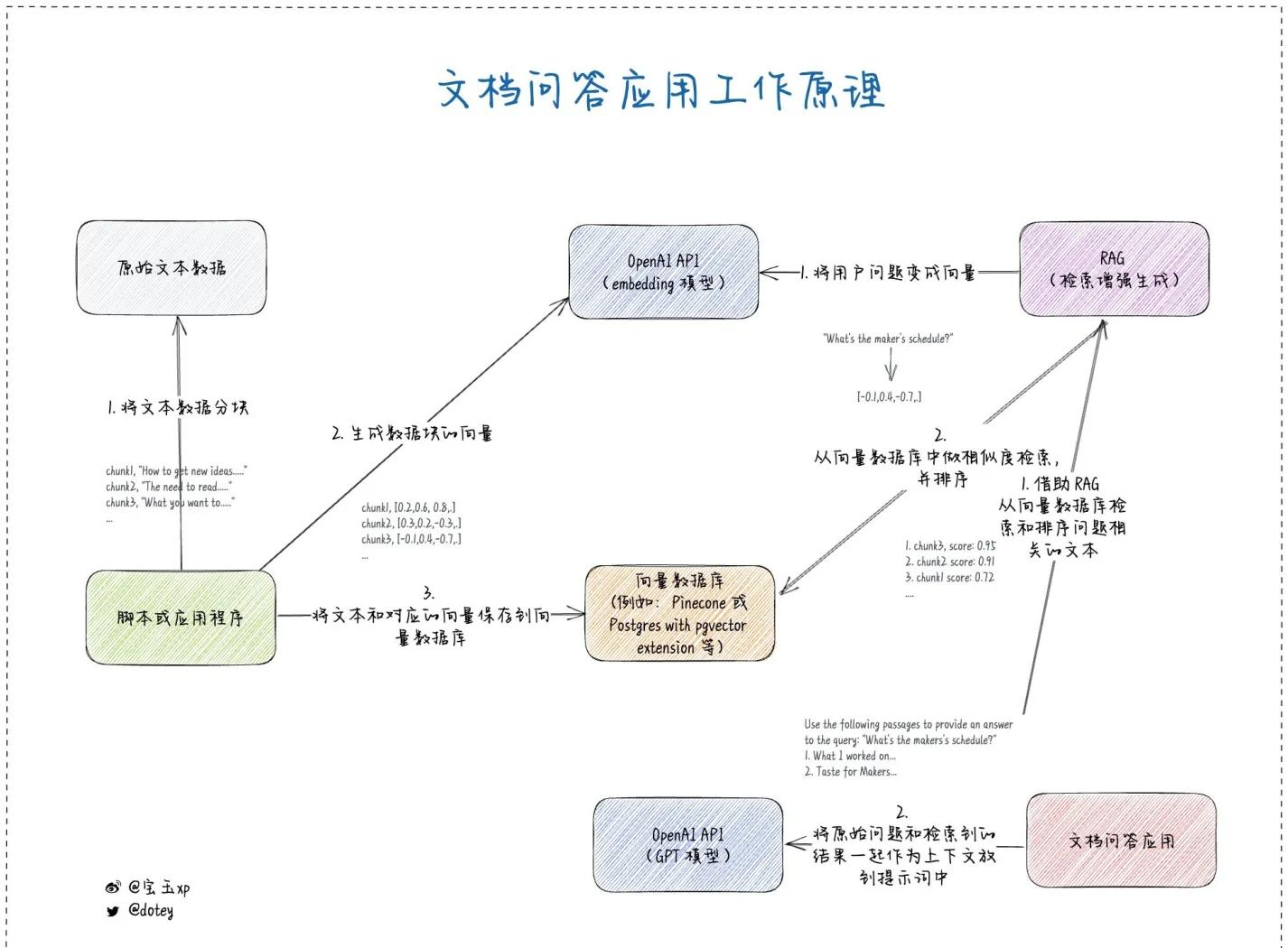
向量化:借助 Embedding 模型,将每个知识片段转化为向量表示 。向量是一种将复杂信息转化为计算机可处理的数值形式的工具,本质上是 “高维空间中的有序数值数组” 。比如句子 “我喜欢 AI” 会被转化为向量,像用 Word2Vec 技术生成 [0.8, -0.3, 1.2, …] 这样的数字串,向量中的每个数字代表一个隐藏的语义特征 。通过向量化,就能把文本转化成计算机能理解的数字形式,还能通过计算向量之间的相似度,找出语义相近的文本片段 。
关联元数据:给每个向量关联相关元数据,比如文档名称、创建时间、作者、来源等 。这些元数据能为后续的检索和使用提供更多有用信息,比如根据文档创建时间筛选出最新的资料 。
载入向量数据库并建立索引:把向量化后的知识片段及其对应的元数据载入向量数据库,如 FAISS、Pinecone、Weaviate 等 。向量数据库专门用于存储和管理向量数据,能够高效地进行向量检索 。建立索引则是为了加快检索速度,就像给图书馆的书籍编制目录,方便快速找到想要的书 。
部署集成:将向量数据库集成到 AI 产品流程中,与生成模型搭配使用 。这样,当用户提问时,系统就能快速从向量数据库中检索相关知识,并交给生成模型进行处理 。
(二)模型调用
当用户提出问题后,RAG 系统就会进入模型调用阶段,这个阶段主要包含以下操作 :
向量转换:系统会将用户输入的 Prompt 转化成向量 。同样是利用 Embedding 模型,把用户的问题也变成和知识库中知识片段一样的向量形式,方便在向量数据库里进行相似度比较 。
相似片段检索:将用户问题转化后的向量,在向量数据库里进行相似度检索 。向量数据库会根据向量之间的相似度,找出与用户问题最相关的 1 条或者多条知识片段 ,也就是召回相关内容 。比如,用户问 “苹果的营养价值有哪些?”,向量数据库就会检索出与 “苹果营养价值” 相关的知识片段 。
合并输入:将检索出的知识片段与原 Prompt 合并在一起,组成新的 Prompt 。这样,新的 Prompt 就包含了用户问题以及从知识库中检索到的相关信息,为大模型提供了更丰富的上下文 。
生成回复:把新的 Prompt 输入到大模型中,大模型基于这些信息进行理解和推理,生成最终的回答 。由于大模型在生成回答时参考了从知识库中检索到的相关知识,所以回答会更加准确、丰富和有针对性 。
四、RAG 优势大盘点
(一)经济高效
在传统的大模型应用中,如果想要模型学习新的知识,往往需要收集大量的新数据,然后对整个模型进行重新训练 。这个过程不仅需要耗费大量的计算资源,像使用高性能的 GPU 集群,还需要投入大量的时间和专业人力 。以训练一个中等规模的语言模型为例,可能需要数千块 GPU 并行计算数周时间,成本高达数十万元甚至更多。
而 RAG 则大大降低了这方面的成本 。当有新的信息需要添加时,我们只需要将新的数据按照一定的格式整理好,添加到外部的知识库中即可 。无需对大模型本身进行大规模的重新训练,这就节省了大量的技术和财务成本 。比如,一个企业想要让大模型了解最新的产品信息,只需要将产品的更新文档添加到知识库,模型就能在后续的回答中运用这些新知识,而不用花费大量资源去重新训练模型 。
(二)实时更新
在信息爆炸的时代,数据的时效性至关重要 。RAG 技术最大的亮点之一,就是能让大模型与实时数据紧密相连 。通过连接实时数据源,如新闻网站的 API 接口、金融市场的实时数据接口等,大模型可以获取到最新的信息 。
例如,在金融领域,投资者想要了解某只股票的最新价格走势、公司的最新财报数据等,使用 RAG 技术的大模型就能及时获取这些实时数据,并给出准确的回答 。又比如,在新闻资讯领域,当有突发新闻事件发生时,大模型可以迅速从新闻源获取相关报道,为用户提供最新的事件进展和解读 。这种实时更新的能力,确保了大模型的回答始终具有高度的相关性和准确性,使其在应对各种时效性要求高的场景时,都能游刃有余 。
(三)提高可信度
在面对大模型给出的回答时,很多用户常常会心存疑虑:这个答案准确吗?有没有可靠的依据?RAG 技术很好地解决了这个问题 。
当大模型基于 RAG 技术生成回答时,它会同时列出回答所依据的信息来源 ,这些来源可以是具体的文档、网页链接、研究报告等 。用户通过查看这些来源,就能验证答案的可靠性,增强对大模型输出内容的信任 。例如,当用户询问某个科学问题时,大模型不仅会给出答案,还会列出参考的科学文献、研究机构的报告等,让用户能够进一步查阅相关资料,深入了解问题 。这种透明的信息呈现方式,有效提升了大模型回答的可信度,让用户使用起来更加放心 。
(四)灵活可控
对于开发人员来说,RAG 提供了极大的灵活性和可控性 。在实际应用中,不同的用户可能有不同的需求和使用场景,开发人员可以根据这些需求,灵活地更改 RAG 系统的信息源 。
比如,在企业内部应用中,开发人员可以将信息源设置为企业的内部文档库、知识库等,确保员工获取的信息都是企业内部的机密信息和专业知识 。同时,通过设置不同的授权级别,开发人员还可以限制对敏感信息的检索 。例如,普通员工只能检索一般性的工作资料,而管理层则可以访问更高级别的商业机密和战略规划文档 。这种灵活可控的特性,使得 RAG 能够满足不同用户在不同场景下的多样化需求,为大模型的广泛应用提供了有力支持 。
五、代码实操:手把手教你实现 RAG
(一)准备工作
在开始实现 RAG 之前,我们需要确保环境配置正确,并安装所需的依赖包。主要涉及 Python 包的安装、OpenAI 账户申请以及配置文件的创建 。
pip install langchain openai weaviate – client
申请 OpenAI 账户获取 API 密钥:访问 OpenAI 官网(https://openai.com/ ),注册并登录账户 。登录后,点击右上角头像,选择 “API” 进入控制台 。在 “API Keys” 部分,点击 “Create new secret key” 生成 API 密钥 ,请妥善保管该密钥,后续代码中会用到 。
创建.env 文件存放配置信息:为了安全和方便管理,我们创建一个.env文件来存放 OpenAI API 密钥 。在项目根目录下创建.env文件,并添加以下内容 :
OPENAI\\_API\\_KEY='your\\_openai\\_api\\_key'
注意将your_openai_api_key替换为实际生成的 API 密钥 。然后,在 Python 代码中使用dotenv库加载该文件中的环境变量 。首先安装dotenv库:
pip install python – dotenv
在代码开头添加以下内容加载环境变量:
import os
from dotenv import load\\_dotenv
load\\_dotenv()
openai\\_api\\_key = os.getenv('OPENAI\\_API\\_KEY')
(二)向量数据库操作
接下来,我们需要将文本数据进行处理,并存储到向量数据库中,以便后续检索 。这里我们使用LangChain的TextLoader加载文本数据,CharacterTextSplitter对文档进行分块,OpenAIEmbeddings生成向量嵌入,最后将数据存储到 Weaviate 向量数据库 。
from langchain.document\\_loaders import TextLoader
loader = TextLoader('example.txt')
documents = loader.load()
from langchain.text\\_splitter import CharacterTextSplitter
text\\_splitter = CharacterTextSplitter(chunk\\_size = 1000, chunk\\_overlap = 200)
texts = text\\_splitter.split\\_documents(documents)
from langchain.embeddings.openai import OpenAIEmbeddings
embeddings = OpenAIEmbeddings(openai\\_api\\_key = openai\\_api\\_key)
import weaviate
from langchain.vectorstores import Weaviate
client = weaviate.Client(url = "http://localhost:8080")
vectorstore = Weaviate.from\\_documents(texts, embeddings, client = client, index\\_name = "ExampleIndex")
这里假设 Weaviate 服务运行在本地的http://localhost:8080,并创建了一个名为 “ExampleIndex” 的索引 。
(三)RAG 实现步骤
完成上述准备工作后,我们就可以实现 RAG 的核心逻辑了 ,主要包括定义检索器组件、准备提示模板以及将检索增强提示输入大模型生成回答 。
retriever = vectorstore.as\\_retriever()
from langchain.prompts import PromptTemplate
prompt\\_template = """Context information is below.
{context}
Based on the context information and not prior knowledge, answer the following question:
{question}
"""
prompt = PromptTemplate(template = prompt\\_template, input\\_variables = \\["context", "question"])
from langchain.chains import RetrievalQA
from langchain.chat\\_models import ChatOpenAI
llm = ChatOpenAI(openai\\_api\\_key = openai\\_api\\_key, model\\_name = "gpt-3.5-turbo")
qa\\_chain = RetrievalQA.from\\_chain\\_type(llm, retriever = retriever, chain\\_type\\_kwargs = {"prompt": prompt})
question = "What is the main idea of the text?"
result = qa\\_chain.run(question)
print(result)
上述代码中,首先定义了一个RetrievalQA对象qa_chain,它结合了大模型llm和检索器retriever,并使用了之前定义的提示模板 。然后,设置一个示例问题并运行qa_chain,最终打印出大模型生成的回答 。通过以上步骤,我们就完成了一个简单的 RAG 系统的实现 ,可以根据实际需求对代码进行进一步优化和扩展 。
六、应用领域与展望
RAG 技术凭借其独特的优势,在众多领域都展现出了巨大的应用潜力 ,为各行业的智能化发展提供了有力支持 。
在智能客服领域,RAG 可以让客服机器人快速检索企业的产品知识库、常见问题解答库等,针对用户的问题给出准确、详细的回答 。无论是解答用户对产品功能的疑问,还是处理售后问题,RAG 都能大大提升客服机器人的服务质量和效率,减轻人工客服的工作压力 。
教育领域,RAG 可作为智能辅导工具,根据学生的问题,从教材、学术论文等资料中检索相关内容,为学生提供详细准确的解答 。还能通过分析学生的学习情况和问题类型,提供个性化的学习建议和练习推荐,帮助学生更好地掌握知识,提高学习效率 。
医疗行业中,医生借助 RAG 技术,可以访问最新的医学文献、临床指南和病例数据 。在诊断疾病时,系统检索相关信息,为医生提供参考,辅助医生做出更准确的诊断和治疗方案 。此外,RAG 还能用于医学研究,帮助科研人员快速检索和分析大量的医学资料,推动医学领域的研究进展 。
法律行业里,法律专业人士使用 RAG 能够快速检索法规、判例和文书摘要 。在处理案件时,律师可以通过 RAG 迅速找到相关的法律条文和类似案例,为案件的分析和辩护提供有力支持 ,显著节约时间成本,提高工作效率 。
展望未来,RAG 技术还有很大的发展空间 。在检索机制方面,未来的研究将致力于进一步提升检索的精度和效率 。通过优化检索算法,利用更先进的机器学习和深度学习技术,让 RAG 能够在海量的数据中更快速、准确地找到最相关的信息 。
多模态数据融合也是一个重要的发展方向 。随着技术的不断进步,RAG 有望与多模态 AI 相结合,将文本、图像、视频等多种类型的数据进行综合处理 。例如,在医疗领域,结合患者的病历文本信息和医学影像数据,为医生提供更全面、准确的诊断辅助;在教育领域,通过融合文本讲解和动画演示等多模态信息,为学生创造更加丰富、生动的学习体验 。
此外,随着各行业对智能化需求的不断增加,RAG 的行业定制化应用将成为趋势 。针对不同行业的特点和需求,开发出更具针对性的 RAG 解决方案,让 RAG 更好地服务于各个行业的实际业务场景,推动行业的智能化转型和发展 。
七、总结
RAG 作为一种创新的技术框架,为大模型的发展注入了新的活力 。它巧妙地将检索技术与生成模型相结合,有效弥补了大模型在知识时效性、准确性和专业性等方面的不足 。通过构建强大的知识库和高效的检索机制,RAG 能够让大模型在生成回答时,充分利用外部知识,从而生成更加准确、丰富和可靠的内容 。
从实际应用来看,RAG 在智能客服、教育、医疗、法律等多个领域都展现出了巨大的潜力 ,为各行业的智能化转型提供了有力支持 。而通过本文的代码实操,相信大家已经对 RAG 的实现有了更直观的认识 ,能够亲身体验到 RAG 技术的魅力和应用价值 。
随着人工智能技术的不断发展,RAG 技术也将持续演进 ,未来,它有望在更多领域发挥重要作用 ,为我们带来更多的惊喜和变革 。希望大家通过本文对 RAG 有了全面深入的了解后,能够积极探索和实践 RAG 技术 ,将其应用到更多的实际场景中,共同推动人工智能技术的发展和创新 。
更多大模型知识分享
泡泡搜索【码上有模力】









评论前必须登录!
注册