 网硕互联帮助中心
网硕互联帮助中心 本文还有配套的精品资源,点击获取 
简介:客户端服务器通信是基于TCP/IP协议栈的交互模式,普遍存在于HTTP、FTP、SMTP等互联网服务中。本文将深入探讨客户端与服务器连接的核心概念,包括TCP/IP协议、三次握手、套接字编程、端口号、请求与响应机制、并发处理、安全连接、断开连接、负载均衡以及错误处理。了解这些概念将有助于开发者设计和实现更稳定和高效的网络通信应用。 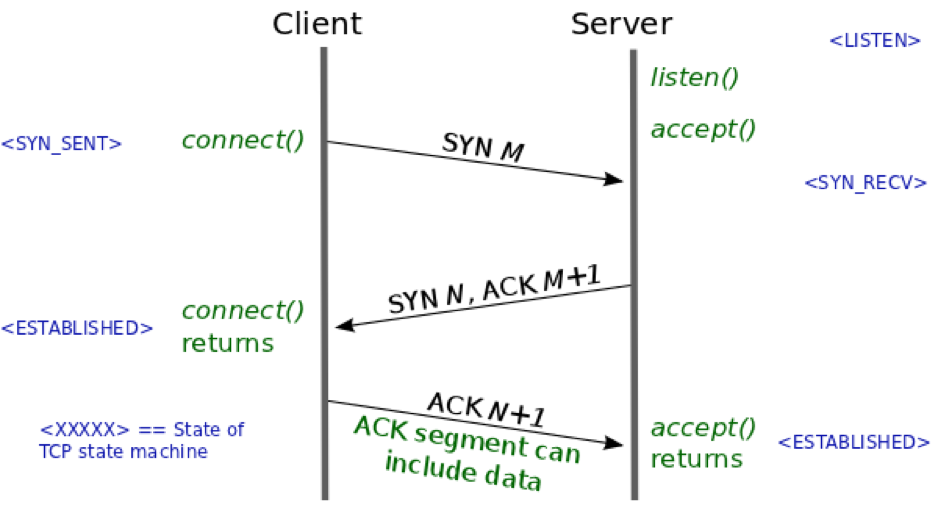
1. TCP/IP协议基础和作用
1.1 网络通信与协议族概念
在现代网络通信中,TCP/IP 协议族是不可或缺的基础。它是一系列网络协议的集合,定义了数据如何在网络中传输、路由以及如何到达目的地。这一协议族为互联网的运行提供了底层的、统一的规则和框架。
1.2 TCP/IP模型与OSI模型对比
TCP/IP 模型与传统的 OSI 模型经常被比较,但它们在概念上有所不同。TCP/IP模型分为四层:应用层、传输层、网际层和网络接口层。与之对应的OSI模型则是七层结构。TCP/IP模型因其简单性和实用性,成为了业界广泛采用的标准。
1.3 TCP/IP协议的关键作用
TCP/IP 协议族通过提供稳定、可靠的数据传输机制来保障通信。其中,传输控制协议(TCP)确保数据包的正确交付和排序,互联网协议(IP)则负责将数据包传送到正确的目的地。这两个协议是整个网络通信的核心,确保了数据能够在复杂的网络环境中准确无误地传输。
通过深入理解这些基础知识,能够更好地掌握后续章节中的网络连接、编程以及安全优化等高级主题。
2. 建立TCP连接的三次握手机制
2.1 握手前的准备工作
2.1.1 协议栈的作用和数据封装
在深入探讨TCP三次握手机制之前,首先要了解协议栈在数据通信中的作用。协议栈是网络通信中的一个概念,它是由操作系统内核或网络应用程序实现的一系列协议的集合,这些协议按照不同的层次进行排列。每一层协议都有其特定的职责,包括数据封装、数据传输、数据处理等。
协议栈主要分为四层,从底层到上层分别是:链路层、网络层、传输层、应用层。在发送数据时,应用层数据会经过协议栈的层层处理,最终以数据包的形式通过网络传输;在接收数据时,数据包会反向经过每一层的协议处理,最终还原成应用层数据。
数据封装是协议栈中的一个关键过程,它涉及到数据包的组装和解析。数据包在发送之前,会在每一层协议中添加相应的头部信息。这些头部信息包含了各种控制信息,例如源地址、目的地址、端口号、协议类型等。
在TCP/IP模型中,协议栈的数据封装过程如下:
- 应用层:将用户数据添加HTTP头部信息等。
- 传输层:传输层协议(如TCP或UDP)在应用层数据基础上添加自己的头部信息,包括源端口和目的端口,序列号等。
- 网络层:网络层协议(如IP)为传输层的数据包添加IP头部信息,包括源IP地址和目的IP地址。
- 链路层:链路层协议(如以太网)在IP数据包基础上添加链路层头部和尾部,形成帧。
在数据封装的过程中,每层都对数据的结构和内容进行了定义,确保了数据的有效传输和接收。当数据到达目的地时,接收端的协议栈会按照相反的顺序对数据进行解封装,最终将原始数据传递给接收应用程序。
2.1.2 端口与套接字的概念
在了解协议栈的作用和数据封装之后,我们还需要明确端口和套接字的概念。端口(Port)可以被看作是网络通信中的逻辑连接点,允许数据包根据端口号区分不同的服务或进程。端口号是一个16位的数字,它的范围从0到65535。其中,1024以下的端口号通常被指派给标准服务和进程,而1024以上的端口号可以被应用程序自由使用。
套接字(Socket)是计算机网络数据交换的一个基本操作单元,它提供了网络通信的端点。在TCP/IP模型中,套接字是应用层和传输层的桥梁,应用程序通过套接字接口来发送和接收数据。
套接字由以下几个主要部分组成:
- IP地址:用于标识网络中的一个主机。
- 端口号:用于标识网络中的一个服务或者进程。
- 协议类型:指示使用的是TCP还是UDP协议。
例如,在TCP/IP模型中,一个典型的TCP套接字由一个IP地址和一个端口号组成。当一个客户端想要连接到服务器进行通信时,它会创建一个套接字,并指定服务器的IP地址和端口号。一旦TCP连接建立,数据就可以在这个套接字上双向传输。
为了更直观地理解,我们可以将网络通信比喻为邮政系统中的邮件发送。IP地址相当于收件人的地址,端口号相当于收件人的房间号,而套接字则是写有完整收件人地址的信封。在这个比喻中,协议栈的作用就像邮政系统的处理流程,将信件从发件人递送到收件人手中。
2.2 三次握手详细步骤
2.2.1 第一次握手:SYN发送与接收
TCP连接的建立是通过一个称为三次握手机制的过程来完成的。三次握手是TCP协议确保可靠连接的建立所必需的步骤,它包括三个阶段:第一次握手、第二次握手和第三次握手。
在第一次握手阶段,客户端(Client)会向服务器(Server)发送一个带有SYN(Synchronize Sequence Numbers,同步序列编号)标志位的数据包。SYN数据包的主要目的是为了同步客户端和服务器之间的序列号,并且请求建立连接。
第一次握手的数据包包含了以下重要信息:
- SYN标志位:设置为1,表示这是一个同步请求。
- 序列号(Seq):客户端随机生成的一个初始序列号,用于后续数据传输的同步。
例如,当客户端准备建立连接时,它会发送一个带有初始序列号 seq=x 的SYN数据包给服务器。这个数据包的目的是告诉服务器,客户端已经准备好开始数据传输,并等待服务器的响应来同步序列号。
当服务器接收到这个SYN数据包时,它会进行以下步骤:
这个阶段的通信过程可以用以下伪代码表示:
# 客户端代码
# 发送SYN数据包
send_syn_packet(client_ip, server_ip, client_port, server_port, seq=x)
# 服务器代码
# 接收SYN数据包,生成并发送SYN-ACK数据包
server_seq = generate_initial_seq()
send_syn_ack_packet(server_ip, client_ip, server_port, client_port, ack=x+1, seq=server_seq)
需要注意的是,第一次握手过程中,服务器端在收到SYN请求后,并不立即建立连接,而是处于半连接状态,直到第二次握手阶段收到客户端的ACK响应后,连接才真正建立。
2.2.2 第二次握手:SYN-ACK的发送与确认
在第一次握手阶段,服务器接收到了客户端的SYN请求,并为响应生成了自己的初始序列号。随后,服务器进入第二次握手阶段,它会发送一个 SYN-ACK 数据包给客户端。
SYN-ACK数据包表示服务器已经收到客户端的连接请求,并且同意建立连接。这个数据包同时带有SYN和ACK标志位,意味着它既是一个同步请求也是一个确认响应。
在第二次握手的数据包中包含以下信息:
- SYN标志位:设置为1,表示这是一个同步请求。
- ACK标志位:设置为1,表示这是一个确认响应。
- 服务器的初始序列号(Seq):服务器为此次连接生成的初始序列号 y 。
- 确认号(Ack): ack=x+1 ,其中 x 是客户端发送的初始序列号。这表示服务器期望收到的下一个客户端发送的数据包的序列号是 x+1 。
当服务器向客户端发送了SYN-ACK数据包后,它会等待客户端的响应。如果客户端正确接收到服务器的SYN-ACK数据包,它会发送一个ACK数据包给服务器,以确认收到服务器的同步请求。此时,第二次握手完成,服务器也收到了客户端的确认,连接双方都确认了彼此的初始序列号。
第二次握手的数据包用伪代码表示如下:
# 服务器代码
# 发送SYN-ACK数据包
send_syn_ack_packet(server_ip, client_ip, server_port, client_port, ack=x+1, seq=server_seq)
# 客户端代码
# 接收SYN-ACK数据包,并发送ACK数据包
ack_number = server_seq + 1
send_ack_packet(client_ip, server_ip, client_port, server_port, ack=ack_number)
这一阶段,客户端接收到服务器的SYN-ACK数据包后,会执行以下步骤:
在这个阶段,服务器通过收到的ACK数据包确认客户端已经收到了它的同步请求,并且双方都已经准备好开始数据传输。至此,连接的前两个阶段已经完成,连接已经处于一种双方都可以发送数据的状态,但只有在第三次握手完成后,连接才被完全建立。
2.2.3 第三次握手:ACK的发送与连接确认
第三次握手阶段是整个TCP连接建立过程中的最后一步,也是连接被完全建立的标志。在这个阶段,客户端会对服务器发来的SYN-ACK进行确认。
客户端会发送一个ACK(Acknowledgment,确认)数据包给服务器。在第三次握手的ACK数据包中,ACK标志位被设置为1,且确认号被设置为 ack=y+1 ,这表示客户端已经收到了服务器的同步请求,并且确认了服务器的初始序列号。一旦服务器接收到这个ACK数据包,它就完成了三次握手的全部过程。
这次握手的关键点在于确认号 ack=y+1 ,这是客户端告知服务器,从现在开始,服务器可以发送序列号为 y+1 的数据包了,而客户端将开始接收序列号为 x+1 的数据包。
完成第三次握手后,TCP连接便成功建立,双方都可以开始发送数据。
2.2.3 第三次握手:ACK的发送与连接确认
在TCP连接建立的三次握手机制中,第三次握手是最终确认连接是否成功建立的关键阶段。在这个阶段,客户端会发送一个ACK数据包作为对服务器之前发送的SYN-ACK的响应。这个ACK数据包完成了连接的建立,因为它确认了服务器的初始序列号,并且向服务器表明客户端已经准备好进行数据交换了。
具体来说,第三次握手的ACK数据包包含以下关键信息:
- ACK标志位:设置为1,表示这是一个确认数据包。
- 确认号(Ack):设置为 ack=y+1 ,其中 y 是服务器在第二次握手中发送的初始序列号。这个确认号的设置意味着客户端已经正确接收到了服务器的同步请求,并且期望收到的下一个数据包序列号是 y+1 。
伪代码表示:
# 客户端代码
# 发送ACK数据包
ack_number = server_seq + 1
send_ack_packet(client_ip, server_ip, client_port, server_port, ack=ack_number)
当服务器收到客户端发送的ACK数据包时,它会执行以下步骤:
在实际的网络通信中,TCP连接的三次握手过程是自动完成的,由操作系统的网络协议栈负责处理。这一过程是透明的,对于应用程序来说,只是简单地调用套接字API来发送和接收数据。
完成第三次握手后,连接处于ESTABLISHED状态,这意味着双方都可以开始互相发送数据。此外,三次握手的过程还为TCP连接提供了序列号同步和初始化窗口大小的机会,这对于后续的可靠数据传输至关重要。
2.2.3.1 TCP连接状态的转变
在三次握手的过程中,连接状态会经历一系列的转变。最初,服务器处于 LISTEN 状态,等待来自任何客户端的连接请求。当服务器接收到客户端发来的SYN数据包时,它会进入 SYN-RCVD 状态。这个状态表示服务器已经收到并准备响应客户端的连接请求。
对于客户端来说,当它发送出SYN数据包后,它会处于 SYN-SENT 状态,表示客户端已经发起连接请求,但尚未收到服务器的确认。在成功接收到服务器的SYN-ACK数据包后,客户端会进入 ESTABLISHED 状态,此时TCP连接已经建立,可以开始数据的双向传输。
在服务器端,一旦它发送出SYN-ACK数据包并且成功接收到客户端的ACK响应后,它也会转变到 ESTABLISHED 状态。这时,服务器也准备就绪,可以开始进行数据传输。
下图是TCP连接状态转换的一个简单表示:
graph LR
A[LISTEN] –>|接收到SYN| B[SYN-RCVD]
B –>|发送SYN-ACK| C[ESTABLISHED]
C –>|接收到ACK| D[ESTABLISHED]
E[SYN-SENT] –>|发送SYN| F[SYN-RCVD]
F –>|接收到SYN-ACK| G[ESTABLISHED]
G –>|发送ACK| D
在这个状态图中,客户端从 SYN-SENT 状态经过 SYN-RCVD 状态最终到达 ESTABLISHED 状态,而服务器从 LISTEN 状态经过 SYN-RCVD 状态再转到 ESTABLISHED 状态。一旦客户端和服务器都处于 ESTABLISHED 状态,它们之间的通信就可以顺畅进行了。
2.2.3.2 数据包的序列号和确认机制
在三次握手机制中,序列号和确认机制起着至关重要的作用。序列号用于标识数据包在整个数据传输过程中的顺序,而确认机制则用于确认数据包的正确接收。序列号和确认机制是TCP保证可靠数据传输的关键特性之一。
序列号是TCP头部信息的一部分,每个TCP数据包都会包含一个序列号。序列号用于标识发送方的发送顺序,它允许接收方正确地重组数据流。在三次握手机制中,初始序列号是由连接双方各自随机生成的,并在握手过程中交换。
确认号是在TCP数据包中用于告知发送方期望收到的下一个数据包的序列号。TCP使用确认号来告知发送方,到目前为止,所有发送的数据包都已经成功接收。如果发送方没有收到预期的确认号,它会重新发送数据包。
在第一次握手阶段,客户端会发送一个带有初始序列号 x 的SYN数据包。在第二次握手阶段,服务器会发送一个带有自己的初始序列号 y 和确认号 ack=x+1 的SYN-ACK数据包。最后,在第三次握手阶段,客户端发送一个ACK数据包,确认号为 ack=y+1 ,表示客户端已经收到了服务器的同步请求。
# 客户端和服务器之间的数据包序列号和确认号交换示例
# 客户端发送的SYN数据包
SYN, seq=x
# 服务器收到客户端的SYN后,回复的SYN-ACK数据包
SYN, ACK, seq=y, ack=x+1
# 客户端收到服务器的SYN-ACK后,回复的ACK数据包
ACK, seq=x+1, ack=y+1
序列号和确认号不仅用于三次握手期间,在整个TCP连接期间的每一次数据传输中都会使用。它们是确保数据包按正确的顺序被接收和处理的关键,同时也提供了一种检测和处理丢包或重复数据包的机制。序列号和确认机制保证了TCP连接的可靠性,即使在网络状况不佳的情况下也能确保数据的完整性和顺序性。
3. 套接字编程及其在网络通信中的重要性
3.1 套接字编程基础
套接字(Socket)编程是网络通信中不可或缺的部分,它提供了进程间通信(IPC)的手段,尤其是在不同主机上的进程间。从最基础的TCP/IP模型来看,套接字位于传输层,直接与网络层的IP协议和传输层的TCP/UDP协议交互。
3.1.1 套接字的类型与选择
套接字分为三类:流式套接字(SOCK_STREAM)、数据报套接字(SOCK_DGRAM)和原始套接字(SOCK_RAW)。流式套接字基于TCP协议,保证了数据传输的可靠性、顺序性。数据报套接字基于UDP协议,适用于无需确保数据完整性的场景,效率较高,但可能会有丢包或乱序问题。原始套接字用于更底层的操作,常用于网络协议分析,可发送任意类型的数据包。
在选择套接字类型时,通常需要考虑应用需求。如果需要稳定传输,那么SOCK_STREAM是不二之选;而如果对速度要求更高,且可接受丢包,那么SOCK_DGRAM更为合适。
#include <sys/socket.h>
// 创建套接字的函数声明
int socket(int domain, int type, int protocol);
上述代码中 socket() 函数用于创建套接字,参数 domain 指定了地址族(如IPv4或IPv6), type 指定套接字类型, protocol 定义了协议。返回值是新创建的套接字描述符。
3.1.2 套接字API的基本使用方法
套接字编程涉及多种API,下面介绍几个最基础的函数。
- bind() :将套接字与地址绑定,使得数据可以流向这个地址。
- listen() :在服务器端使用,表示套接字开始监听连接请求。
- accept() :同样在服务器端使用,用于接受客户端的连接请求,返回一个新的套接字用于通信。
- connect() :在客户端使用,用于建立到服务器的连接。
- send() 和 recv() :用于发送和接收数据。
#include <sys/socket.h>
// 绑定套接字到地址
int bind(int sockfd, const struct sockaddr *addr, socklen_t addrlen);
// 监听套接字
int listen(int sockfd, int backlog);
// 接受连接
int accept(int sockfd, struct sockaddr *addr, socklen_t *addrlen);
// 连接到服务器
int connect(int sockfd, const struct sockaddr *addr, socklen_t addrlen);
// 发送数据
ssize_t send(int sockfd, const void *buf, size_t len, int flags);
// 接收数据
ssize_t recv(int sockfd, void *buf, size_t len, int flags);
3.2 套接字编程高级应用
3.2.1 非阻塞套接字和IO多路复用
非阻塞套接字(Non-blocking socket)可以防止应用程序因为等待某个事件而“挂起”。在非阻塞模式下,如果操作无法立即完成,则函数会立即返回一个错误码,表明资源暂不可用,而不是等待。非阻塞操作要求程序员设计更加复杂的事件循环和错误处理逻辑。
IO多路复用(如select、poll和epoll)允许同时监听多个套接字上的I/O事件,提升效率,尤其在大量连接的情况下。这种机制在单线程中即可处理多个并发连接,显著提高了程序的性能。
#include <sys/select.h>
// select函数用于I/O多路复用
int select(int nfds, fd_set *readfds, fd_set *writefds, fd_set *exceptfds, struct timeval *timeout);
// FD_SET宏用于设置文件描述符集
void FD_SET(int fd, fd_set *set);
// FD_ISSET宏用于检查文件描述符是否在文件描述符集中
int FD_ISSET(int fd, fd_set *set);
// FD_CLR宏用于清除文件描述符集中的文件描述符
void FD_CLR(int fd, fd_set *set);
// FD_ZERO宏用于初始化文件描述符集
void FD_ZERO(fd_set *set);
3.2.2 套接字选项和特殊功能配置
套接字选项允许程序对套接字的行为进行微调,例如设置是否在套接字上等待缓冲区满时阻塞发送操作,或者设置SO_LINGER选项来控制关闭套接字的行为。
#include <sys/socket.h>
// 获取套接字选项
int getsockopt(int sockfd, int level, int optname, void *optval, socklen_t *optlen);
// 设置套接字选项
int setsockopt(int sockfd, int level, int optname, const void *optval, socklen_t optlen);
通过 getsockopt() 和 setsockopt() 函数,可以获取和设置套接字的各种选项。选项的设置可以极大影响套接字的行为,比如通过设置SO_REUSEADDR允许端口重用,可以使得在端口还在TIME_WAIT状态时依然可以绑定。
下面是一个使用 setsockopt() 来设置SO_REUSEADDR的例子:
int yes = 1;
if (setsockopt(listen_sock, SOL_SOCKET, SO_REUSEADDR, &yes, sizeof(yes)) < 0) {
perror("setsockopt");
// 处理错误
}
通过调整套接字选项,网络应用程序可以更灵活地适应不同网络状况和性能要求,这对于网络编程来说至关重要。
3.2.3 套接字编程实践
一个网络通信的简单示例可以说明套接字编程的实践应用。以下是一个TCP服务器端和客户端的基本代码框架。
TCP服务器端示例代码:
// 服务器端代码示例
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#include <sys/socket.h>
#include <netinet/in.h>
int main(int argc, char *argv[]) {
// 创建套接字
int sockfd = socket(AF_INET, SOCK_STREAM, 0);
if (sockfd < 0) {
perror("ERROR opening socket");
exit(1);
}
// 定义和绑定地址
struct sockaddr_in server_addr;
memset(&server_addr, 0, sizeof(server_addr));
server_addr.sin_family = AF_INET;
server_addr.sin_addr.s_addr = INADDR_ANY;
server_addr.sin_port = htons(1234);
if (bind(sockfd, (struct sockaddr *) &server_addr, sizeof(server_addr)) < 0) {
perror("ERROR on binding");
exit(1);
}
// 监听连接
listen(sockfd, 10);
printf("Server listening on port 1234…\\n");
// 接受连接
struct sockaddr_in client_addr;
socklen_t client_len = sizeof(client_addr);
int newsockfd = accept(sockfd, (struct sockaddr *) &client_addr, &client_len);
if (newsockfd < 0) {
perror("ERROR on accept");
exit(1);
}
char buffer[1024];
// 读取和发送数据
int n = read(newsockfd, buffer, sizeof(buffer));
if (n < 0) {
perror("ERROR reading from socket");
exit(1);
}
printf("Here is the message: %s\\n", buffer);
n = write(newsockfd, buffer, n);
if (n < 0) {
perror("ERROR writing to socket");
exit(1);
}
// 关闭套接字
close(newsockfd);
close(sockfd);
return 0;
}
TCP客户端示例代码:
// 客户端代码示例
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#include <sys/socket.h>
#include <netinet/in.h>
#include <arpa/inet.h>
int main(int argc, char *argv[]) {
// 创建套接字
int sockfd = socket(AF_INET, SOCK_STREAM, 0);
if (sockfd < 0) {
perror("ERROR opening socket");
exit(1);
}
// 定义服务器地址
struct sockaddr_in server_addr;
memset(&server_addr, 0, sizeof(server_addr));
server_addr.sin_family = AF_INET;
server_addr.sin_port = htons(1234);
// 将域名转换为IP地址
if (inet_pton(AF_INET, "127.0.0.1", &server_addr.sin_addr) <= 0) {
perror("ERROR inet_pton");
exit(1);
}
// 连接到服务器
if (connect(sockfd, (struct sockaddr *) &server_addr, sizeof(server_addr)) < 0) {
perror("ERROR connecting");
exit(1);
}
// 发送数据
char *message = "Hello, World!";
if (write(sockfd, message, strlen(message)) < 0) {
perror("ERROR writing to socket");
exit(1);
}
// 接收数据
char buffer[1024] = {0};
int n = read(sockfd, buffer, sizeof(buffer));
if (n < 0) {
perror("ERROR reading from socket");
exit(1);
}
printf("Received: %s\\n", buffer);
// 关闭套接字
close(sockfd);
return 0;
}
上述代码中,服务器端创建了一个TCP套接字,绑定到1234端口,并监听连接请求。客户端连接到服务器,并发送一条消息。服务器接收消息并回复同样的消息。最后,两端关闭套接字。这只是套接字编程中一个非常基础的应用实例,但在实际应用中,网络通信的复杂性会大幅度提高。套接字编程通过提供丰富的API,为开发者提供了构建复杂网络应用的基础。
4. 端口号的作用与分配机制
4.1 端口号的基本概念
4.1.1 端口号的作用和范围
端口号是用于区分同一台主机上不同网络服务的数字标识,它是数据包到达主机后用来确定数据应该交付给哪个网络应用程序的参考。端口号的范围从0到65535,其中0到1023是熟知端口(well-known ports),它们被预留给一些常用的网络服务,例如HTTP服务使用端口80,HTTPS服务使用端口443。端口号1024到49151通常用于用户程序,而49152到65535是动态或私有端口,可以由应用程序自由使用。
端口号在网络通信中扮演着至关重要的角色,因为它允许一台计算机上的多个应用程序同时使用网络进行通信,而不会相互干扰。端口号与IP地址一起构成了一个网络通信的“唯一地址”,确保数据包能够准确无误地传送到正确的目的地。
4.1.2 端口的分类与常见服务端口
端口根据其用途被分为三类:
- 公认端口(Well-Known Ports):范围从0到1023,需要管理员权限才能绑定这些端口。常见的服务端口包括HTTP(80)、HTTPS(443)、FTP(21)、SSH(22)等。
- 注册端口(Registered Ports):范围从1024到49151,这类端口可以被非特权用户使用。例如MySQL数据库默认使用端口3306。
- 动态或私有端口(Dynamic or Private Ports):范围从49152到65535,这类端口用于临时分配给应用程序使用。它们不需要特定的注册,一般由操作系统动态分配。
端口的分类与分配机制确保了网络服务的标准化和有序性,同时也便于网络管理和故障排查。例如,当网络管理员在查看防火墙日志时,可以根据端口号快速判断是哪个网络服务发生了连接请求或数据传输。
4.2 端口分配与管理
4.2.1 端口分配策略和原理
端口分配主要由操作系统和网络协议栈负责,遵循TCP/IP协议族的指导原则。端口分配策略通常涉及以下原理:
- 静态分配:某些端口(如熟知端口)在系统安装时或在应用程序启动时静态分配给特定的服务。这些端口在系统运行期间不会改变。
- 动态分配:应用程序在需要进行网络通信时,可以请求操作系统动态分配一个空闲的端口。操作系统会在注册端口范围内选择一个未被使用的端口号分配给应用程序。
- 端口重用:在某些系统中,当一个应用程序终止后,其绑定的端口可以被其他应用程序重用。
端口分配策略的灵活性允许系统高效地管理端口资源。同时,为了保证系统的安全性和稳定性,操作系统通常会限制应用程序绑定端口的权限,尤其是对于熟知端口和注册端口的访问。
4.2.2 端口冲突的诊断与解决
端口冲突发生时,通常是因为两个或多个应用程序试图绑定到同一个端口上。这会引发“端口已被占用”的错误信息。诊断端口冲突和解决的步骤包括:
通过细心诊断和适当的管理,端口冲突问题通常可以得到解决,从而保证网络服务的正常运行。
flowchart LR
A[开始诊断] –> B[检查当前网络连接]
B –> C[识别占用端口的进程]
C –> D{是否可以停止进程?}
D — 是 –> E[停止冲突应用程序]
D — 否 –> F[更改冲突应用程序端口号]
E –> G[检查端口冲突是否解决]
F –> G
G — 是 –> H[冲突解决]
G — 否 –> I[检查防火墙和安全软件设置]
I –> J{是否找到问题源头?}
J — 是 –> H
J — 否 –> K[检查残留的网络连接和进程]
K –> L{是否清理完毕?}
L — 是 –> H
L — 否 –> M[清理残留项]
M –> H
在上述流程图中,展示了诊断和解决端口冲突的逻辑步骤。该流程图可以作为管理员在处理端口冲突时的参考指南。
5. 客户端与服务器的请求响应模型
在第五章中,我们将深入探讨客户端与服务器之间如何通过请求响应模型进行有效通信。这种模型是现代网络通信的基础,无论是在Web服务还是在客户端应用程序中都得到了广泛的应用。
5.1 请求响应模型的基本原理
请求响应模型是客户端和服务器之间的交流模式。在这个模型中,客户端发出一个请求,服务器响应该请求。这一过程在用户访问网站、使用应用程序时反复进行,确保了信息的准确交换。
5.1.1 客户端请求消息的格式与发送
当客户端需要从服务器获取数据或服务时,它会构建一个HTTP请求消息。请求消息的格式通常包括请求行、请求头、空行以及可选的消息体。请求行指明了请求的类型(如GET或POST)、目标资源的路径以及使用的HTTP版本。
GET /index.html HTTP/1.1
Host: www.example.com
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64)
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: en-US,en;q=0.5
Connection: close
在上述示例中,客户端请求 /index.html 资源,并指明自己能够接受的数据类型、语言偏好以及要求关闭连接。
客户端通过套接字发送请求,套接字API是构建请求消息、发送请求和接收响应的基础。
5.1.2 服务器处理请求和发送响应的过程
服务器接收客户端的请求,根据请求行指定的方法(如GET或POST)和路径来处理请求。处理完成后,服务器创建一个HTTP响应消息,并将其发送回客户端。响应消息同样由状态行、响应头、空行以及消息体组成。
HTTP/1.1 200 OK
Date: Wed, 21 Oct 2023 07:28:00 GMT
Server: Apache/2.4.1 (Unix)
Content-Type: text/html; charset=UTF-8
Content-Length: 122
<html>
<head><title>200 OK</title></head>
<body>
<h1>Success!</h1>
</body>
</html>
在此响应中,服务器表明请求成功(HTTP状态码200),并返回了一个简单的HTML页面。服务器处理请求和发送响应的过程中,需要考虑多种因素,如请求的有效性、资源可用性、安全性等。
5.2 请求响应模型的实践应用
5.2.1 常见客户端编程实例
客户端编程通常涉及发出请求并处理响应的代码。下面是一个使用Python语言和 requests 库发出HTTP GET请求的简单例子。
import requests
response = requests.get('http://www.example.com')
print(response.status_code)
print(response.text)
在这段代码中,我们使用 requests.get() 方法向指定的URL发出GET请求,并将响应对象存储在 response 变量中。 response.status_code 和 response.text 分别用于访问响应的状态码和响应体。
5.2.2 服务器端的设计与实现
服务器端的设计与实现比客户端复杂得多,因为需要处理各种各样的请求,并提供相应的服务。在Python中,一个简单的HTTP服务器可以用内置的 http.server 模块来实现。
from http.server import BaseHTTPRequestHandler, HTTPServer
class SimpleHTTPRequestHandler(BaseHTTPRequestHandler):
def do_GET(self):
self.send_response(200)
self.send_header('Content-type', 'text/html')
self.end_headers()
self.wfile.write(b'Hello, world!')
if __name__ == '__main__':
server_address = ('', 8000)
httpd = HTTPServer(server_address, SimpleHTTPRequestHandler)
httpd.serve_forever()
这段代码定义了一个 SimpleHTTPRequestHandler 类,继承自 BaseHTTPRequestHandler 。当接收到GET请求时,服务器返回”Hello, world!”。服务器监听本地8000端口,并无限期运行。
在实际应用中,服务器通常使用框架如Flask或Django(Python)来处理更复杂的请求,并提供强大的后端支持。
5.2.3 总结
请求响应模型是客户端和服务器间通信的核心。本章首先介绍了请求响应模型的基本原理,从客户端发出请求到服务器处理请求并返回响应的过程。我们还探讨了如何在不同编程语言中实现客户端和服务器端的实际操作。
这一模型的正确实现是网络应用稳定运行的基础,任何对模型的优化都将直接影响到用户体验和应用性能。在后续的章节中,我们将进一步探讨如何保证通信的安全性和如何高效地处理并发连接。
6. 网络通信的安全性和负载均衡
6.1 安全连接的SSL/TLS加密机制
随着网络技术的飞速发展,数据在互联网上的传输安全成为了至关重要的问题。为了确保数据传输的安全性,SSL(安全套接字层)和TLS(传输层安全性协议)协议被广泛采用,它们提供了数据加密、身份验证和数据完整性校验的功能。
6.1.1 加密协议的工作原理
SSL/TLS协议工作在传输层和应用层之间,提供了安全的通道来保护应用层协议(如HTTP、SMTP等)数据的传输。其工作原理可以分为以下几个步骤:
- 握手阶段:客户端和服务器通过交换信息协商加密算法和密钥。
- 密钥交换:使用非对称加密技术交换对称加密的密钥。
- 认证阶段:服务器向客户端提供证书进行身份验证。
- 加密通信:使用对称密钥加密数据,保证数据传输的安全性。
- 完成阶段:通信结束后,结束加密的会话。
6.1.2 SSL/TLS的配置与实践
配置SSL/TLS涉及到生成密钥对、申请并安装证书以及在服务器上启用安全连接。以下是配置和使用SSL/TLS的基本步骤:
生成SSL密钥和证书签名请求(CSR) : bash openssl genrsa -out server.key 2048 openssl req -new -key server.key -out server.csr 这里使用了OpenSSL工具生成2048位的私钥,并创建一个CSR文件用于之后申请证书。
购买或申请证书 : 从一个可信的证书颁发机构(CA)购买SSL证书或者使用自有CA签名你的证书。
配置服务器使用SSL : 以Apache服务器为例,需要编辑配置文件(如httpd.conf)来启用SSL,并指定私钥和证书文件的路径。 apache <IfModule mod_ssl.c> SSLCertificateFile "/path/to/your/certificate.crt" SSLCertificateKeyFile "/path/to/server.key" </IfModule> 重新加载或重启Apache服务,使配置生效。
测试和验证SSL配置 : 使用在线工具或命令行工具检查SSL配置。 bash openssl s_client -connect yourdomain.com:443 此命令可以测试服务器上的SSL连接。
通过这些步骤,可以配置SSL/TLS以确保网络通信的安全。负载均衡将在下一部分讨论。
6.2 并发连接与负载均衡的应用
在现代网络应用中,服务器往往需要处理大量的并发连接请求。这就需要负载均衡技术来分配请求,以提高系统的性能和可靠性。
6.2.1 并发连接的处理方式
处理并发连接的方式通常包括以下几种:
-
多线程或多进程处理 : 每个连接由一个独立的线程或进程处理。这种方式提高了并发处理能力,但可能消耗较多资源。
-
事件驱动模型 : 如使用Node.js中的事件循环机制,单个线程可以处理多个并发连接。
6.2.2 负载均衡的实现方法与策略
负载均衡是将接收到的网络流量分散到多个服务器上,以防止单个服务器过载。以下是一些常见的负载均衡实现方法和策略:
-
轮询(Round Robin) : 轮流将请求分发到服务器集群中的每一台服务器上。
-
权重(Weighted) : 根据服务器处理能力分配不同的权重,权重高的服务器会收到更多的请求。
-
最少连接(Least Connections) : 将新请求分配给当前连接数最少的服务器。
-
源地址散列(Source Hashing) : 根据客户端的IP地址进行散列,以确保来自同一客户端的请求总是被路由到同一服务器。
一个基于轮询的负载均衡配置示例如下:
# 使用Nginx作为负载均衡器
http {
upstream myapp1 {
server srv1.example.com;
server srv2.example.com;
server srv3.example.com;
}
server {
listen 80;
location / {
proxy_pass http://myapp1;
}
}
}
这个配置创建了一个名为 myapp1 的服务器组,并使用轮询策略来分发请求。
在实际应用中,可以根据应用的需求和服务器的性能来选择合适的负载均衡策略。无论是SSL/TLS的加密通信还是负载均衡的应用,它们都是网络安全性和高可用性不可或缺的部分。这些技术的结合使用,对于维护大规模网络应用的稳定运行至关重要。
本文还有配套的精品资源,点击获取
简介:客户端服务器通信是基于TCP/IP协议栈的交互模式,普遍存在于HTTP、FTP、SMTP等互联网服务中。本文将深入探讨客户端与服务器连接的核心概念,包括TCP/IP协议、三次握手、套接字编程、端口号、请求与响应机制、并发处理、安全连接、断开连接、负载均衡以及错误处理。了解这些概念将有助于开发者设计和实现更稳定和高效的网络通信应用。
本文还有配套的精品资源,点击获取







评论前必须登录!
注册