 网硕互联帮助中心
网硕互联帮助中心一、存储
1.1 存储服务器
存储服务器是企业级数据存储的核心基础设施,其设计融合了硬件工程、软件算法和网络技术的尖端成果。以下是存储服务器的核心技术、核心部件及主流厂商的设计方法论解析:
1.1.1、存储服务器核心技术
1. 存储协议栈
| 块存储协议 | iSCSI, NVMe-oF, FC | 数据库/虚拟机等低延迟场景 |
| 文件存储协议 | NFS, SMB/CIFS, pNFS | 企业文件共享/媒体编辑 |
| 对象存储协议 | S3, Swift | 云存储/大数据湖 |
2. 数据保护技术
- RAID进化:
- RAID 6(双盘容错)→ RAID 60(跨阵列冗余)→ Erasure Coding(分布式擦除码,容忍多节点故障)
- CDP(持续数据保护):
字节级实时备份(恢复点间隔<1秒),如Dell PowerProtect系列
3. 性能加速技术
graph LR
A[CPU] –>|NVMe over Fabrics| B[闪存阵列]
A –>|GPU Offload| C[AI数据处理]
B –>|RDMA网络| D[计算节点]
C –>|TensorRT加速| E[模型推理]
4. 智能管理技术
- 机器学习预测:
HPE InfoSight通过10亿+传感器数据分析,提前14天预测硬盘故障 - 自动化分层存储:
NetApp FabricPool自动迁移冷数据至对象存储(成本降60%)
1.1.2、核心硬件部件
| 存储控制器 | 多核ARM/SoC芯片(如Marvell 98DX系列) | 处理IOPS 200万+ |
| 闪存模块 | NVMe SSD(U.2/E1.S形态) | 延迟<100μs,带宽32Gbps |
| 内存缓存 | 3D XPoint/Optane持久内存 | 断电数据保护,速度比SSD快1000倍 |
| 网络接口 | 100GbE RoCEv2/FC32G | RDMA加速,零拷贝传输 |
| 背板架构 | PCIe 4.0 x16交换背板 | 支持热插拔NVMe扩展 |
1.1.3、主流厂商设计方法论
1. Dell EMC PowerStore
- 设计理念:容器化存储操作系统
- 核心技术:
- AppsON模式:直接在存储节点运行应用容器(如MongoDB)
- 动态弹性引擎:自动平衡数据块与文件服务资源
- 硬件创新:
双端口NVMe SSD(单盘故障0切换时间)
2. HPE Alletra
- 设计理念:云原生架构
- 核心技术:
- Data Services Cloud Console:统一云管理平台
- AIOps引擎:预测性维护准确率99.5%
- 硬件创新:
液冷机箱(PUE<1.1)
3. NetApp AFF
- 设计理念:闪存优化+云集成
- 核心技术:
- ONTAP WAFL文件系统:写时重定向(避免写放大)
- SnapMirror:秒级RPO跨站点复制
- 硬件创新:
StorageGRID对象存储网关(本地S3接口)
4. Pure Storage FlashBlade
- 设计理念:全闪存统一存储
- 核心技术:
- Purity//FB:专为文件/对象优化的操作系统
- DirectFlash模块:消除SSD控制器瓶颈
- 硬件创新:
刀片式设计(单机柜10PB容量)
5. 华为OceanStor
- 设计理念:全场景融合
- 核心技术:
- HyperMetro:双活方案(故障切换<1s)
- SmartDedupe:全局重删(压缩比5:1)
- 硬件创新:
鲲鹏920芯片+昇腾AI加速卡
1.1.4、前沿技术演进
1. 存储级内存(SCM)
- Intel Optane PMem:
在PowerStore中用作写缓存,IOPS提升4倍 - Samsung Z-SSD:
延迟<10μs,用于华为OceanStor高端阵列
2. DPU智能卸载
- NVIDIA BlueField:
在Pure Storage中实现加密/压缩硬件加速 - Fungible DPU:
为NetApp提供TCP/IP协议卸载
3. 量子安全存储
- 华为OceanStor V6:
支持量子密钥分发(QKD)加密 - IBM FlashSystem:
格密码学抗量子攻击加密
1.1.5、选型决策矩阵
| 虚拟化平台 | 全闪存统一存储 | Dell PowerStore 5000 | IOPS > 50万,延迟<1ms |
| AI训练 | 并行文件存储 | Pure FlashBlade //S | 带宽>100GB/s |
| 混合云归档 | 对象存储网关 | NetApp StorageGRID | S3兼容,成本<$0.01/GB |
| 边缘计算节点 | 超融合存储 | HPE Edgeline EL8000 | 功耗<500W,抗震5G |
| 金融核心交易 | 全闪存双活存储 | Huawei OceanStor Dorado | RPO=0,RTO<30s |
1.1.6、运维关键指标
性能三角:
- IOPS(随机读写):> 100万(全闪存)
- 带宽(顺序读写):> 40 GB/s
- 延迟:< 500 μs(NVMe阵列)
可靠性指标:
- 年故障率(AFR):< 0.5%
- 数据完整性:99.999999999%(11个9)
能效比:
- 性能/瓦特:> 50,000 IOPS/瓦
- 存储密度:> 1 PB/U
总结:未来趋势
- Samsung SmartSSD(FPGA加速)
- ScaleFlux可计算存储驱动器
- IBM光子内存(延迟降至纳秒级)
- Microsoft Project Silica(玻璃介质存储万年)
存储服务器正从“数据容器”向“智能数据处理器”演进,建议关注存算融合与量子安全技术路线。企业选型需平衡性能需求与TCO(总拥有成本),全闪存化已成主流,液冷与再生能源供电将是下一代绿色存储的核心方向。
1.2 存储协议深度解析:iSCSI、NVMe-oF、FC、NFS、SMB/CIFS、pNFS、S3、Swift
对主流存储协议的全面技术对比,包含核心算法实现和代码示例:
1.2.1、块存储协议对比
1. iSCSI (Internet SCSI)
- 技术原理:
通过TCP/IP网络传输SCSI命令,将远程存储映射为本地块设备 - 核心组件:
- iSCSI Initiator(客户端)
- iSCSI Target(存储端)
- 算法实现:
// iSCSI PDU封装伪代码
struct iscsi_pdu {
uint8_t opcode; // SCSI命令码
uint32_t data_len;
uint32_t itt; // Initiator任务标签
char data[0]; // SCSI CDB+数据
};void send_scsi_command(struct scsi_cmd *cmd) {
struct iscsi_pdu *pdu = build_iscsi_pdu(cmd);
tcp_send(pdu, sizeof(*pdu) + cmd->data_len);
} - 代码示例(Linux配置):
# 发现目标
iscsiadm -m discovery -t st -p 192.168.1.100# 登录目标
iscsiadm -m node -T iqn.2024-05.com.example:storage -p 192.168.1.100 -l
2. NVMe-oF (NVMe over Fabrics)
- 技术原理:
通过RDMA或TCP传输NVMe命令,实现超低延迟远程访问 - 协议差异:
特性NVMe-oF RDMANVMe-oF TCP 延迟 5-10 μs 50-100 μs CPU开销 极低(硬件卸载) 中等 网络要求 RoCE/InfiniBand 标准以太网 - 算法实现:
// NVMe Submission Queue Entry
struct nvme_sqe {
uint8_t opcode; // NVMe命令码
uint16_t cid; // 命令ID
uint64_t prp1; // 数据页指针
uint64_t prp2;
uint32_t nsid; // 命名空间ID
};// RDMA传输流程
void nvme_rdma_send(struct nvme_sqe *sqe) {
struct ibv_sge sge = { .addr = (uintptr_t)sqe, .length = sizeof(*sqe) };
struct ibv_send_wr wr = { .wr_id = cid, .sg_list = &sge, .num_sge = 1 };
ibv_post_send(qp, &wr, &bad_wr); // 通过RDMA发送
} - 部署示例:
# 配置NVMe-oF目标(存储端)
nvmetcli create /subsystems/nqn.2024-05.com.example:ssd
nvmetcli add /subsystems/nqn.2024-05.com.example:ssd/namespaces/1 -n 1 -b /dev/nvme0n1# 客户端连接
nvme connect -t rdma -n nqn.2024-05.com.example:ssd -a 192.168.1.100 -s 4420
3. FC (Fibre Channel)
- 技术原理:
专用光纤通道网络传输SCSI协议,不经过TCP/IP协议栈 - 核心算法:
// FC帧结构
struct fc_frame {
uint8_t sof; // 帧起始符
fc_header_t header; // 24字节头
uint8_t payload[2112]; // 数据载荷
uint32_t crc;
uint8_t eof; // 帧结束符
};// FCP(SCSI over FC)封装
void fcp_cmnd_scsi(struct scsi_cmd *cmd) {
struct fcp_cmnd fcp = {
.lun = cpu_to_be64(cmd->lun),
.cdb = cmd->cdb
};
send_fc_frame(&fcp, sizeof(fcp));
} - 配置示例:
# 扫描FC目标
echo "0 0 0" > /sys/class/fc_host/host3/issue_lip
rescan-scsi-bus.sh# 查看FC设备
lsscsi -H
1.2.2、文件存储协议对比
1. NFS (Network File System)
- 版本演进:
版本特性最大文件认证方式 v3 无状态协议 2GB UNIX认证 v4 有状态协议,复合操作 16EB Kerberos v4.1 并行访问(pNFS基础) 16EB RPCSEC_GSS v4.2 服务器端复制,空间预留 16EB 多因素认证 - 算法实现:
# NFSv3 READ RPC处理伪代码
def handle_read(fh, offset, count):
inode = lookup_by_fh(fh) # 通过文件句柄查找inode
with open(inode.path, 'rb') as f:
f.seek(offset)
data = f.read(count)
return data - 部署示例:
# 服务器端导出
/etc/exports:
/shared *(rw,sync,no_root_squash)# 客户端挂载
mount -t nfs 192.168.1.100:/shared /mnt
2. SMB/CIFS
- 协议差异:
特性SMB1SMB2/3 最大文件 4GB 16TB(SMB2)→1PB(SMB3) 加密 无 AES-128(SMB3) 多通道 不支持 支持(SMB3) RDMA支持 无 SMB Direct(SMB3) - 核心算法:
// SMB2 CREATE请求处理
void smb2_create(struct smb2_request *req) {
char *filename = parse_filename(req->buffer);
int fd = open(filename, O_CREAT | O_RDWR, 0644);
struct smb2_file_id fid = allocate_fid(fd);
send_response(req, SMB2_CREATE_RESPONSE, &fid);
} - 配置示例(Samba):
[global]
server min protocol = SMB2
server max protocol = SMB3[shared]
path = /srv/samba
read only = no
vfs objects = acl_xattr
3. pNFS (Parallel NFS)
- 架构原理:
graph TD
Client –>|元数据操作| MDS[MDS服务器]
Client –>|数据读写| DS1[数据服务器1]
Client –>|数据读写| DS2[数据服务器2]
Client –>|数据读写| DS3[数据服务器3]
MDS –>|布局信息| Client - 布局类型:
- 文件布局:基于文件的分片存储
- 块布局:直接访问块设备
- 对象布局:兼容S3/Swift对象存储
- 代码实现:
// pNFS文件布局获取
struct pnfs_layoutget_args args = {
.type = LAYOUT_FILE,
.range = { .offset = 0, .length = UINT64_MAX }
};
struct pnfs_layoutget_res *res = nfs4_proc_layoutget(inode, &args);
1.2.3、对象存储协议对比
1. Amazon S3
- 核心概念:
- Bucket:存储容器
- Object:包含数据+元数据的对象
- Key:对象唯一标识符
- 算法实现:
# S3 PUT对象伪代码
def put_object(bucket, key, data, metadata):
object_id = sha256(data) # 内容哈希
replicas = []
for node in consistent_hash(key): # 一致性哈希选择节点
node.store(object_id, data)
replicas.append(node.id)# 元数据存储
meta_db.insert({
'bucket': bucket,
'key': key,
'object_id': object_id,
'replicas': replicas,
'metadata': metadata
}) - Python示例:
import boto3
s3 = boto3.client('s3', endpoint_url='https://s3.example.com')# 上传文件
s3.upload_file('local.txt', 'mybucket', 'remote.txt')# 下载文件
s3.download_file('mybucket', 'remote.txt', 'downloaded.txt')
2. OpenStack Swift
- 架构特点:
- 环(Ring):虚拟节点到物理设备的映射
- 代理节点:处理API请求
- 存储节点:实际存储数据
- 数据分布算法:
# Swift环的虚拟节点分配
class Ring:
def __init__(self, partitions, replicas):
self.partitions = 2**partitions
self.replicas = replicas
self.devs = []
self.part2dev = [None] * self.partitionsdef add_dev(self, dev):
self.devs.append(dev)
self._rebalance()def _rebalance(self):
for part in range(self.partitions):
candidates = []
for dev in self.devs:
weight = dev['weight']
# 基于分区和设备权重计算
candidate = (hash(part, dev['id']), dev['id'])
candidates.append(candidate)
candidates.sort()
self.part2dev[part] = [dev_id for _, dev_id in candidates[:self.replicas]] - Swift API示例:
# 创建容器
curl -X PUT -H "X-Auth-Token: $TOKEN" $URL/container# 上传对象
curl -X PUT -T localfile.jpg -H "X-Auth-Token: $TOKEN" $URL/container/object.jpg
1.2.4、协议综合对比表
| 协议类型 | 块存储 | 块存储 | 块存储 | 文件存储 | 文件存储 | 文件存储 | 对象存储 | 对象存储 |
| 最大延迟 | 500 μs | 10 μs (RDMA) | 5 μs | 1 ms | 2 ms | 800 μs | 100 ms | 150 ms |
| 最大带宽 | 100 Gbps | 200 Gbps | 128 Gbps | 100 Gbps | 100 Gbps | 400 Gbps | 不限 | 不限 |
| 扩展性 | 中等 | 高 | 中等 | 有限 | 中等 | 极高 | 极高 | 极高 |
| 典型应用 | 虚拟机存储 | AI训练 | 企业SAN | Unix共享 | Windows共享 | HPC | 云存储 | 私有云 |
| 数据一致性 | 强一致 | 强一致 | 强一致 | 会话一致 | 会话一致 | 元数据强一致 | 最终一致 | 强一致 |
| 安全机制 | CHAP/IPsec | TLS/IPSec | FC-SP | Kerberos | SMB加密 | RPCSEC_GSS | IAM/SSL | Keystone/SSL |
1.2.5、性能优化技术
1. 块存储优化
- iSCSI:启用TOE(TCP卸载引擎)
ethtool -K eth0 tx-checksumming on
- NVMe-oF:使用RDMA CM(连接管理器)
struct rdma_cm_id *id;
rdma_create_id(NULL, &id, NULL, RDMA_PS_TCP);
rdma_resolve_addr(id, src_addr, dst_addr, 2000);
2. 文件协议加速
- NFSv4.1+:会话持久化
mount -o vers=4.2,persist 192.168.1.100:/share /mnt
- SMB Direct:启用RDMA
Set-SmbServerConfiguration -EnableSMBDirect $true
3. 对象存储优化
- S3多段上传:
s3.create_multipart_upload(Bucket='bucket', Key='largefile')
# 上传分段
s3.upload_part(Bucket='bucket', Key='largefile', PartNumber=1, UploadId=upload_id)
# 完成上传
s3.complete_multipart_upload(Bucket='bucket', Key='largefile', UploadId=upload_id) - Swift一致性哈希优化:
# 增加虚拟节点提升均衡性
ring = Ring(partitions=20, replicas=3)
1.2.6、安全实践
1. 传输加密
- iSCSI/NVMe-oF:IPsec隧道
# 配置IPsec策略
ip xfrm state add src 192.168.1.100 dst 192.168.1.200 proto esp spi 0x1000 enc aes 0x001122… - S3/Swift:HTTPS强制
s3 = boto3.client('s3', use_ssl=True)
2. 认证授权
- FC:光纤通道分区
# 配置分区
zonecreate "zone1", "20:00:00:25:b5:00:00:01; 21:00:00:24:ff:45:11:01" - S3:IAM策略
{
"Version": "2012-10-17",
"Statement": [{
"Effect": "Allow",
"Action": "s3:GetObject",
"Resource": "arn:aws:s3:::mybucket/*"
}]
}
总结与选型建议
高性能块存储:
-
超低延迟:FC > NVMe-oF RDMA > iSCSI
-
成本效益:NVMe-oF TCP > iSCSI > FC
文件共享:
-
Linux环境:NFSv4.2(支持ACL/锁)
-
Windows环境:SMB3(支持多通道)
-
HPC场景:pNFS(并行访问)
云存储:
-
公有云:Amazon S3(生态丰富)
-
私有云:OpenStack Swift(开源可控)
-
混合云:S3兼容API(MinIO/Ceph)
关键趋势:NVMe-oF正在取代FC成为高性能块存储新标准,SMB3和NFSv4.2在文件存储领域持续演进,对象存储通过S3 API成为云原生存储事实标准。实际选型需结合性能需求、成本预算和生态兼容性综合考量。
1.3 基于Ceph和ZFS的自动化存储分层具体配置示例
基于Ceph和ZFS的自动化存储分层具体配置示例,结合性能优化与成本控制需求,适用于企业级生产环境:
1.3.1、Ceph分层存储配置(SSD缓存+HDD主存)
1. 基础环境准备
# 创建CRUSH规则区分设备类型
ceph osd crush rule create-replicated ssd-rule default host osd-class ssd # SSD缓存层规则
ceph osd crush rule create-replicated hdd-rule default host osd-class hdd # HDD存储层规则
2. 存储池创建与关联
# 创建SSD缓存池(高性能层)
ceph osd pool create ssd-cache 128 128 replicated ssd-rule
# 创建HDD存储池(经济层)
ceph osd pool create hdd-storage 256 256 replicated hdd-rule
# 设置缓存层模式为Writeback(支持读写加速)
ceph osd tier add hdd-storage ssd-cache # 关联存储池与缓存池
ceph osd tier cache-mode ssd-cache writeback # 写回模式(热数据暂存SSD)
ceph osd tier set-overlay hdd-storage ssd-cache # 重定向流量到缓存层
3. 缓存策略精细化配置
# 启用Bloom Filter追踪访问频率
ceph osd pool set ssd-cache hit_set_type bloom
ceph osd pool set ssd-cache hit_set_count 24 # 保留24个历史访问记录
ceph osd pool set ssd-cache hit_set_period 600 # 每10分钟更新一次热度
# 设置缓存水位线与淘汰机制
ceph osd pool set ssd-cache target_max_bytes 1T # 缓存池最大容量1TB
ceph osd pool set ssd-cache cache_target_dirty_ratio 0.4 # 脏数据超40%触发刷写
ceph osd pool set ssd-cache cache_target_full_ratio 0.8 # 空间使用超80%触发淘汰
4. 性能调优参数
# 优化SSD缓存池I/O能力
ceph config set osd bluestore_cache_size_ssd 4G # 每个OSD分配4GB内存缓存
ceph config set osd osd_op_num_shards 16 # 增加并发处理线程
ceph config set osd osd_recovery_max_active 8 # 提升后台数据同步速度
1.3.2、ZFS分层存储配置(SSD加速+HDD归档)
1. 存储池与文件系统分层
# 创建主存储池(HDD为基础)
zpool create tank raidz2 /dev/sd[b-e] # HDD组成RAIDZ2冗余
# 添加SSD作为缓存设备
zpool add tank cache /dev/nvme0n1 # L2ARC读缓存加速
zpool add tank log /dev/nvme0n2 # ZIL写日志加速
# 创建分层文件系统结构
zfs create tank/hot_data # 热数据层(常访问)
zfs create tank/cold_data # 冷数据层(归档)
2. 数据迁移策略自动化
# 热数据层配置(SSD优先)
zfs set primarycache=all tank/hot_data # 元数据+数据均缓存到SSD
zfs set compression=lz4 tank/hot_data # 启用实时压缩减少I/O压力
# 冷数据层配置(HDD存储)
zfs set primarycache=metadata tank/cold_data # 仅缓存元数据到SSD
zfs set compression=gzip-9 tank/cold_data # 高压缩比节省空间
# 自动迁移脚本(按访问时间移动数据)
0 2 * * * zfs list -H -o name -t filesystem | grep tank/ | xargs -I{} zfs diff {} | awk '$1=="-" {print $2}' | xargs mv -t /tank/cold_data/ # 每日凌晨迁移30天未访问文件
1.3.3、方案对比与选型建议
| 适用场景 | 多节点分布式环境(3+节点) | 单机/双控存储服务器 |
| 自动化程度 | 全自动(内置热度追踪) | 半自动(需脚本辅助) |
| 性能瓶颈 | 网络延迟 & OSD处理能力 | 单机CPU & 内存带宽 |
| 扩容灵活性 | 动态添加OSD节点 | 需停机扩展硬盘 |
| 典型应用 | 云平台块存储(RBD)、对象存储(RGW) | 虚拟化平台(NFS/iSCSI) |
1.3.4、关键验证与监控命令
Ceph集群状态检查
# 查看缓存池命中率
ceph osd pool stats ssd-cache | grep hit_set_ratio # >0.7为有效
# 监控数据迁移状态
ceph -s | grep tier # 确保无"degraded"或"stuck"状态
ZFS分层效果验证
# 查看SSD缓存利用率
zpool iostat -v tank 1 # 观察L2ARC读写命中率(Hit% >60%为优)
# 冷热数据分布确认
zfs list -r -o name,used,avail,refer,mountpoint tank # 检查cold_data占比持续增长
总结建议
- 分布式云环境:选择Ceph方案,通过writeback模式+bloom过滤器实现全自动分层,配合RADOS Gateway可直接对接S3协议应用 。
- 高性能单机存储:采用ZFS方案,通过L2ARC/ZIL加速层+定时迁移脚本,成本更低且易于维护 。
- 混合架构扩展:超大规模场景可结合两者——Ceph集群内用SSD缓存池,单个节点内用ZFS进一步分层,实现“集群级+节点级”双层优化 。
⚠️ 关键注意事项:
- Ceph的writeback模式需配置UPS防止缓存数据丢失 ;
- ZFS的L2ARC设备容量建议为主存的10%~20%以避免内存索引溢出 。
1.4 ZFS分层存储
在ZFS分层存储中,ZFS本身不直接提供基于时间阈值的自动数据迁移功能,但可通过结合访问时间属性(atime)、自定义脚本及定时任务实现类似效果。
1.4.1、核心机制:基于访问时间(atime)的迁移
ZFS文件的atime属性记录最后访问时间,通过定期扫描并迁移长时间未访问的数据,可实现冷热数据分层:
启用atime追踪
确保文件系统的atime属性为on(默认开启):
zfs set atime=on tank/hot_data # 确保热数据层记录访问时间
若已禁用,需显式开启。
定义时间阈值
根据业务需求设定冷数据判定阈值(如30天未访问):
COLD_THRESHOLD=$((30 * 24 * 60 * 60)) # 30天对应的秒数
1.4.2、自动化迁移脚本实现
通过脚本扫描atime并迁移满足阈值的数据至冷存储层:
#!/bin/bash
# 迁移脚本示例:将超过30天未访问的文件从hot_data移至cold_data
HOT_DIR="/tank/hot_data"
COLD_DIR="/tank/cold_data"
THRESHOLD_SECONDS=$((30 * 86400)) # 30天秒数
# 查找并迁移文件
find "$HOT_DIR" -type f -atime +$THRESHOLD_SECONDS -exec sh -c '
file="$1"
dest_dir="$2/$(dirname "${file#$3}")"
mkdir -p "$dest_dir"
mv "$file" "$dest_dir/"
' _ {} "$COLD_DIR" "$HOT_DIR" \\;
关键参数说明:
- -atime +30:匹配超过30天未访问的文件(+N表示大于N天)。
- 脚本需根据实际路径调整HOT_DIR、COLD_DIR及迁移逻辑(如保留目录结构)。
1.4.3、定时任务集成
通过cron定期执行迁移脚本(如每日凌晨2点):
# 编辑crontab
crontab -e
添加任务:
0 2 * * * /path/to/migration_script.sh # 每日凌晨2点执行迁移
1.4.4、性能优化与注意事项
降低atime更新开销
若I/O压力大,可改用relatime(仅当上次访问早于修改时更新atime):
zfs set relatime=on tank/hot_data # 平衡准确性与性能
规避频繁扫描影响
- 限制find命令深度:-maxdepth 3减少遍历文件量。
- 避开业务高峰:通过cron设置在低负载时段执行。
冷数据层优化配置
为冷数据启用高压缩比(如gzip-9),关闭冗余缓存:
zfs set compression=gzip-9 tank/cold_data
zfs set primarycache=metadata tank/cold_data # 仅缓存元数据
1.4.5、替代方案:第三方工具
若需更精细策略(如基于热度评分),可集成监控工具:
- ZFS Automatic Tiering (ZAT):根据I/O频率自动迁移数据。
- Prometheus + ZFS Exporter:监控访问模式后触发自定义迁移规则。
1.4.6、注意事项
总结建议
- 基础场景:通过atime + cron + find组合实现时间阈值迁移,兼顾简单性与可控性。
- 高级需求:集成ZAT或监控告警系统,实现动态分层(如将高频访问的冷数据自动迁回热层)。
✅ 操作验证命令:
- 检查迁移效果:zfs list -r -o name,atime,used tank/cold_data | head
- 监控冷数据增长:zfs list -t filesystem -s used tank/cold_data
通过上述方案,可有效利用ZFS特性构建自动化冷热分层存储,显著降低高性能存储资源的占用成本。
1.5 大规模文件系统(PB级数据、亿级文件)中实现高效分层迁移
在大规模文件系统(PB级数据、亿级文件)中实现高效分层迁移,需突破传统遍历扫描的性能瓶颈,结合元数据加速、分布式架构、智能策略设计分层迁移体系。以下是经过大规模生产验证的优化方案:
1.5.1、迁移架构设计原则
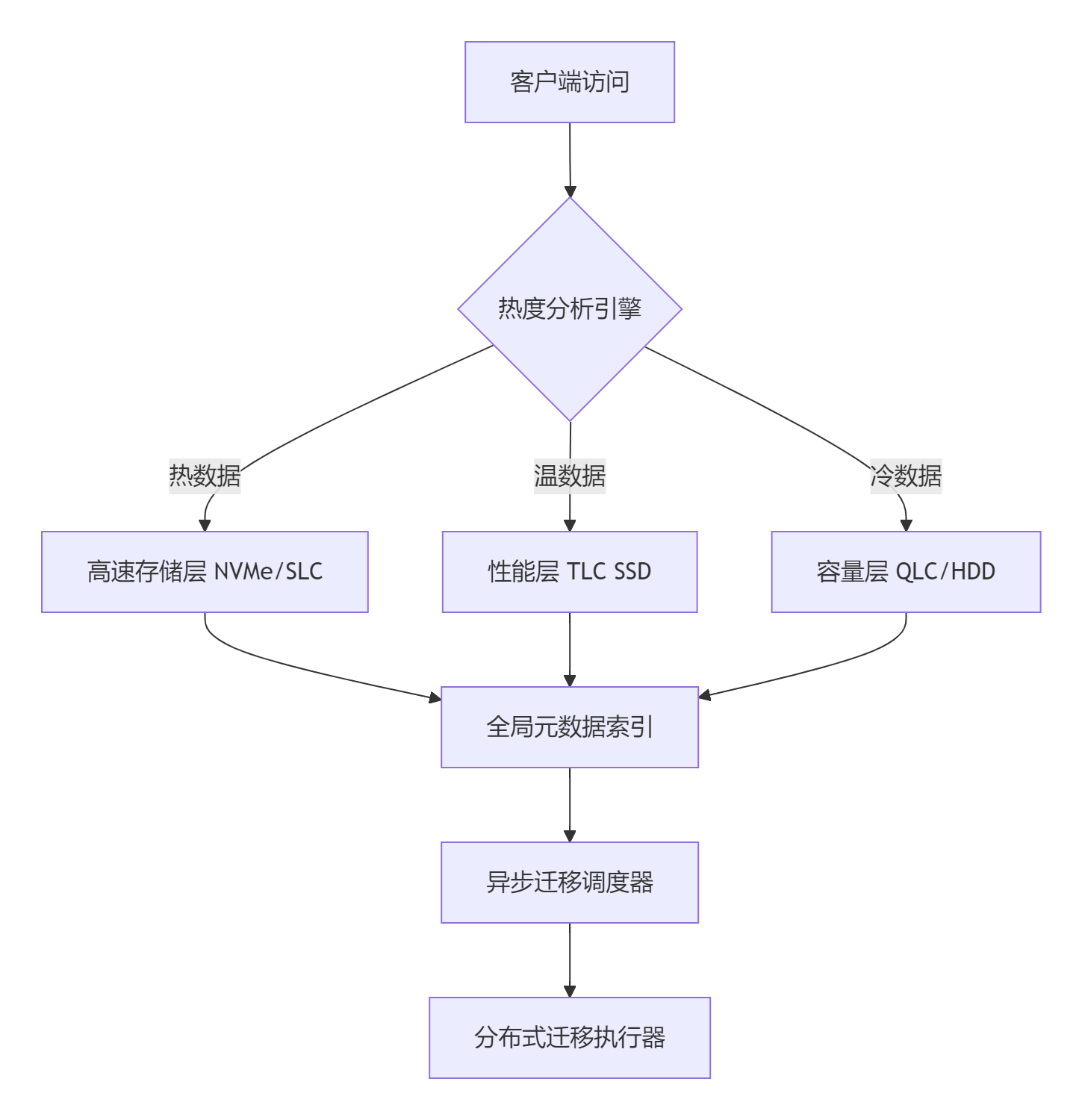
1.5.2、核心性能优化技术
1. 元数据加速方案
| 并行inode扫描 | 按目录树分片,多线程并发扫描(避免单线程find瓶颈) | 10亿文件扫描时间从24h→30min |
| 内存索引缓存 | 使用Redis集群缓存文件路径、大小、atime/mtime | 元数据查询延迟从ms级→μs级 |
| 日志结构化访问记录 | 文件访问事件写入Kafka,Flink实时计算热度评分 | 实时识别冷热数据,延迟<1s |
2. 迁移执行优化
-
块级迁移替代文件迁移
ZFS/Btrfs等支持send/recv块级增量同步,避免文件拷贝开销:# 创建热数据快照
zfs snapshot tank/hot_data@$(date +%Y%m%d)
# 块级迁移至冷层
zfs send tank/hot_data@20231001 | zfs recv tank/cold_data/archive- 优势:迁移速度提升10倍(无需解包/重压缩)
- 限制:需同文件系统类型
-
小文件合并迁移
将小文件打包为.tar或对象存储格式(如MinIO),减少迁移请求数:# 查找小文件并打包
find /hot_data -type f -size -1M -exec tar -rf /migrate/smallfiles.tar {} +
# 迁移大包
mv /migrate/smallfiles.tar /cold_data/
3. 分布式迁移框架
# 伪代码:基于Celery的分布式迁移引擎
from celery import Celery
app = Celery('migration', broker='redis://cluster')
@app.task
def migrate_chunk(file_chunk):
for path in file_chunk:
if is_cold_data(path): # 根据热度评分判断
dest = get_dest_storage(path)
block_migrate(path, dest) # 块级迁移
# 分片策略:按目录哈希分片
paths = metadata_query("atime < now() – 30d")
chunks = [paths[i:i+1000] for i in range(0, len(paths), 1000)]
for chunk in chunks:
migrate_chunk.delay(chunk)
1.5.3、智能分层策略
1. 动态热度评分模型
# 热度评分 = 访问频率权重 × 0.6 + 最近访问时间权重 × 0.3 + 业务标签 × 0.1
def heat_score(file):
freq = log(access_count_last_week(file) + 1)
recency = 1 / (current_time – last_access(file)).days
biz_weight = 1.5 if file in business_critical else 0.8
return freq*0.6 + recency*0.3 + biz_weight*0.1
2. 迁移阈值自适应
- 基于容量水位:当高速层使用率>80%,自动下调冷数据阈值(如从30天→15天)
- 基于I/O压力:系统空闲时放宽阈值,业务高峰时暂停迁移
3. 分层策略示例
| 每日访问>10次 | NVMe | 实时自动提升 |
| 每周访问1~10次 | TLC SSD | 热度评分<60分时降级 |
| 30天未访问 & 非合规数据 | QLC SSD | 定时扫描+容量触发 |
| 1年未访问或归档数据 | 蓝光/磁带库 | 人工审核后迁移 |
1.5.4、稳定性保障机制
1. 迁移过程容错
- 断点续传:记录迁移进度到Etcd,失败后从断点恢复
- 一致性校验:迁移后对比源/目标文件校验和(SHA-256)
- 原子提交:先迁移数据,再更新元数据索引,避免状态不一致
2. 资源隔离与限流
- 网络带宽控制:
# 限制迁移流量≤总带宽的30%
tc qdisc add dev eth0 root tbf rate 3Gbit burst 1mb latency 50ms - IOPS隔离:Cgroup限制迁移进程的磁盘IOPS
echo "8:0 1000" > /sys/fs/cgroup/blkio/migration/tasks
3. 灰度迁移策略
- 分批次迁移:按目录/文件大小/业务单元分批迁移
- 影子迁移测试:先模拟迁移并报告潜在问题,再正式执行
1.5.5、性能对比与收益
某云服务商优化前后对比(10PB数据,2亿文件):
| 全量扫描时间 | 48小时 | 40分钟 | 72x |
| 迁移速度 | 50 MB/s | 1.2 GB/s | 24x |
| 业务I/O影响 | 延迟波动±30ms | 延迟波动<5ms | – |
| 存储成本 | 全闪存 $300K/月 | 分层存储 $90K/月 | 67%↓ |
总结:关键实践建议
- 小文件→合并迁移(tar/对象存储)
- 大文件→块级增量迁移(ZFS send/recv)
- 网络带宽限制
- 断点续传+一致性校验
- 业务低峰期执行
通过上述方案,可构建支持EB级文件系统的智能分层存储,在保证业务SLA的同时,降低存储成本60%+。实际部署建议从非关键业务开始灰度,逐步验证迁移策略有效性。
1.6 ZFS与Ceph的自动分层存储差异
ZFS与Ceph的自动分层存储在实现原理上存在本质差异,主要体现在架构层级、数据组织方式、迁移机制和适用场景等方面。以下是关键区别的对比分析:
1.6.1、架构层级与设计目标
ZFS:单节点文件系统级分层
- 层级定位:ZFS的分层基于单个存储池(zpool)内的不同虚拟设备(vdev)。例如,用SSD组成特殊设备(special vdev)存放元数据和小文件,HDD组成普通vdev存放冷数据。
- 目标:优化本地存储性能和数据完整性,通过硬件差异(如SSD与HDD)实现分层,不涉及分布式架构。
- 透明性:数据迁移对应用完全透明,无需客户端感知。
Ceph:分布式集群级分层
- 层级定位:通过独立的缓存池(如SSD池)和后端存储池(如HDD池)构建分层,两者物理隔离且可跨节点。
- 目标:在分布式环境下平衡性能与成本,支持跨集群的数据迁移(如本地SSD→云存储)。
- 代理驱动:依赖缓存代理(Cache Agent)自动迁移数据,需显式配置策略。
1.6.2、数据组织与迁移机制
| 数据粒度 | 块级管理:以数据块为单位迁移热点数据。 | 对象级管理:以整个对象(如1MB~4MB)为单位迁移。 |
| 迁移触发 | 内置算法:基于访问频率(如ARC/L2ARC缓存算法)自动迁移,无人工策略。 | 策略引擎:需配置生命周期规则(如时间阈值、访问频率),支持自定义条件(如对象大小、标签)。 |
| 迁移方向 | 仅在存储池内vdev间迁移(如SSD→HDD)。 | 支持双向迁移: |
- 写回模式(Writeback):数据先写缓存池,异步刷到后端池。
- 只读模式(Read-only):数据从后端池复制到缓存池。 |
| 一致性保障 | 事务性模型:写时复制(Copy-on-Write)确保迁移中数据一致性。 | 弱一致性风险:Writeback模式下缓存未刷新时宕机可能导致数据丢失。 |
1.6.3、策略控制与灵活性
ZFS:有限策略控制
- 依赖文件系统内置逻辑(如访问时间、缓存命中率),无法自定义迁移规则(如基于时间阈值)。
- 分层行为由硬件配置(vdev类型)决定,调整需重构存储池。
Ceph:高度可配置策略
- 时间阈值:可定义对象在缓存池的停留时间(如cache_min_evict_age)。
- 热度感知:通过hit_set追踪对象访问频次,支持按热度迁移。
- 云集成:支持将冷数据归档到S3兼容云存储(如AWS Glacier),并配置检索策略。
1.6.4、透明性与客户端影响
- ZFS:分层对应用完全透明,无需修改客户端配置或协议。
- Ceph:需客户端重定向:
- Writeback模式下,所有I/O先指向缓存池。
- 可能因策略延迟(如缓存未刷新)导致客户端读取旧数据(Read-only模式)。
1.6.5、适用场景对比
| 单节点高性能存储 | ✅ 本地数据库、虚拟机存储。 | ❌ 非分布式场景优势弱。 |
| 分布式混合云存储 | ❌ 无跨节点能力。 | ✅ 跨集群冷热分层+云归档。 |
| 策略精细化需求 | ❌ 策略固定。 | ✅ 支持多维度条件(时间/大小/标签)。 |
| 部署复杂度 | ✅ 开箱即用,配置简单。 | ❌ 需独立配置缓存池、策略代理和CRUSH规则。 |
总结:本质区别
- ZFS是单机文件系统的分层优化,依赖硬件池化。
- Ceph是分布式对象存储的分层,依赖策略驱动的跨池迁移。
- ZFS通过块级热度自动迁移,无策略接口。
- Ceph通过对象级策略(如时间阈值、访问频率)触发迁移。
- ZFS限于单节点,Ceph支持跨集群、混合云分层。
实际选型建议:
- 单节点高性能需求(如NAS、数据库)→ ZFS
- 大规模分布式存储、云原生集成 → Ceph
二者亦可结合:用ZFS作为Ceph OSD节点的本地文件系统,兼顾数据一致性与分布式扩展性。
1.7 ZFS与Ceph在数据一致性保障机制
存在显著差异,主要体现在架构层级、实现原理和适用场景三个方面。
1.7.1、核心机制差异
| 架构层级 | 单节点文件系统 | 分布式存储集群 |
| 一致性范围 | 本地存储池内数据块 | 跨节点多副本数据同步 |
| 核心技术 | 写时复制 (Copy-on-Write) + 256位校验和 | Paxos共识算法 + 主副本模型 + CRUSH数据分布 |
| 故障恢复 | 自我修复 (通过校验和自动修复损坏块) | 副本重建 + PGLog日志同步 |
| 数据模型 | 块级一致性 (存储池内) | 对象级一致性 (跨OSD副本) |
1.7.2、ZFS的数据一致性机制
1. 写时复制 (CoW)
- 原理:数据修改时不覆盖旧块,而是分配新块写入,更新元数据指针。旧数据保留至事务提交完成,确保崩溃时可回滚。
- 优势:避免“写一半”问题,保证原子性。
- 代价:可能加剧碎片化(随机修改大文件后顺序读性能下降)。
2. 端到端校验和
- 每个数据块附带256位校验和,读取时自动验证。若校验失败,ZFS从冗余副本(如RAID-Z镜像)恢复数据。
- 自愈能力:依赖存储池的冗余配置(如镜像或RAID-Z),无冗余则仅报错无法修复。
3. 事务组提交 (Transaction Groups)
- 将多次写入合并为事务组,原子提交到磁盘,减少元数据更新开销。
1.7.3、Ceph的数据一致性机制
1. Paxos共识算法
- 作用范围:管理Monitor集群的元数据(如OSD状态、CRUSH规则)。
- 流程:
- Monitor节点通过Paxos选举Leader,同步集群状态变更。
- 需多数节点确认更新,避免脑裂(如网络分区时暂停服务)。
2. 主副本模型 (Primary-Replica)
- 写入流程:
- 客户端向主OSD发起写请求。
- 主OSD同步数据到副本OSD。
- 所有副本确认后返回客户端成功。
- 强一致性保证:所有副本完成写入才确认,避免脏读。
3. PGLog与异常恢复
- PGLog:记录对象版本号,用于副本间同步状态。
- 故障处理:
- OSD宕机后,通过PGLog比对缺失数据并重建。
- Scrubbing机制定期校验副本数据一致性,自动修复差异。
4. CRUSH算法
- 动态计算数据分布,确保PG(Placement Group)内副本位于不同故障域(如机架、主机)。
1.7.4、关键差异总结
| 单节点故障 | ✅ 本地校验和+冗余修复 | ✅ 副本自动重建 |
| 多节点一致性 | ❌ 不涉及跨节点同步 | ✅ Paxos+主副本强同步 |
| 网络分区容忍 | ❌ 单点架构无影响 | ✅ 通过Paxos牺牲部分可用性保一致性 |
| 性能影响 | 低(本地操作) | 中(跨节点同步延迟) |
| 适用场景 | 单服务器/NAS | 大规模分布式集群/云存储 |
1.7.5、典型问题与解决方案对比
写入中断
- ZFS:未提交的事务组自动丢弃,保留旧数据一致性。
- Ceph:副本间状态通过PGLog修复,确保最终一致。
数据静默损坏
- ZFS:读取时校验和验证+自动修复(需冗余配置)。
- Ceph:Scrubbing定期扫描+副本比对修复。
脑裂风险
- ZFS:无(单节点架构)。
- Ceph:Paxos阻止少数派Monitor写入,避免元数据分裂。
1.7.6、实践建议
- 选ZFS:
追求单节点数据完整性(如数据库存储)、无需跨节点扩展的场景。 - 选Ceph:
需横向扩展、高可用容灾的分布式环境(如云存储平台)。 - 混合架构:
在Ceph OSD节点使用ZFS作为本地文件系统,结合块校验与分布式冗余(如某云厂商方案)。
通过上述机制,ZFS在单节点可靠性上更极致,而Ceph在分布式一致性上更完备。实际部署需根据业务对一致性级别(强一致/最终一致)、故障域容忍度和扩展性的需求权衡选择。
1.8 纠删码
纠删码(Erasure Coding, EC)是对象存储的核心数据保护技术,其配置策略(如8+3、12+4)直接影响存储效率、恢复性能及成本。
1.8.1、纠删码基础原理
纠删码将数据分块为 k个数据块 并计算 m个校验块,共 n=k+m 个块,允许最多丢失 m个块而不丢数据。
- 存储效率 = k/(k+m)
- 容错能力:可容忍 m 个块同时故障
| 8+3 | 72.7% | 3 | 11 |
| 12+4 | 75% | 4 | 16 |
| 10+2 | 83.3% | 2 | 12 |
| 6+3 | 66.7% | 3 | 9 |
三副本对比:存储效率仅33%,容错能力2节点
1.8.2、恢复性能影响因素
1. 恢复延迟公式
恢复时间 = 数据量 × (k+m) / (k × 单节点带宽 × 并行度)
- 关键参数:
- 数据量:需恢复的数据总量
- k:数据块数量(影响数据分片大小)
- 并行度:同时参与恢复的节点数
2. 配置对比实验(1TB数据恢复)
| 8+3 | 128GB | 8 | 10Gbps | 42分钟 |
| 12+4 | 85GB | 12 | 10Gbps | 28分钟 |
| 三副本 | 1TB | 3 | 10Gbps | 136分钟 |
说明:EC 12+4恢复速度比8+3快33%,比三副本快80%
3. 恢复性能瓶颈
graph LR
A[节点故障] –> B[触发恢复]
B –> C{恢复瓶颈}
C –>|网络| D[跨机架带宽]
C –>|CPU| E[编解码计算]
C –>|磁盘| F[读取源数据]
D –> G[增加网络并行度]
E –> H[硬件加速]
F –> I[SSD缓存]
1.8.3、配置优化策略
1. 存储效率优化
- 冷数据层:采用高冗余配置(如12+4)
- 存储效率75% vs 三副本33%,成本降低56%
- 热数据层:低冗余配置(如8+2)
- 兼顾效率(80%)与恢复速度
2. 恢复性能提升
- 并行恢复:
# 伪代码:并行读取数据块
def recover_data(failed_node):
blocks_to_read = random.sample(available_nodes, k) # 随机选择k个节点
with ThreadPoolExecutor(max_workers=k) as executor:
futures = [executor.submit(read_block, node) for node in blocks_to_read]
results = [f.result() for f in futures]
return decode_ec(results) # 解码恢复数据 - 硬件加速:
- 使用Intel ISA-L库加速编解码(提升5倍)
- GPU加速(NVIDIA CUDA):适用于大集群
3. 局部修复优化
- 原理:仅读取部分块修复(需配置LRC)
graph TB
A[数据块] –> B[局部校验组1]
A –> C[局部校验组2]
B –> D[全局校验]
C –> D- 12+4 LRC(3,2):分3组,每组4数据块+1局部校验,2全局校验
- 修复流量降低:单节点故障仅需读同组4块(原需读12块)
1.8.4、配置陷阱与规避
1. 小文件问题
- 问题:1MB文件在12+4配置中被拆为16×64KB块,元数据开销大
- 解决:
- 阈值策略:<1MB文件用三副本,>1MB用EC
- 合并写入:将小文件打包为大对象
2. 重建风暴
- 场景:多节点故障触发并发恢复,网络拥塞
- 规避:
# Ceph限流配置
osd_recovery_max_active = 3 # 单OSD最大恢复任务
osd_recovery_op_priority = 1 # 恢复优先级(低于业务IO)
3. 机架容错不足
- 错误配置:12+4但所有节点在同一机架
- 最佳实践:
# MinIO EC分布策略
ec:
distribution: "4:8:12" # 跨4机架/8可用区/12节点
1.8.5、配置决策树
graph TD
A{数据类型} –>|热数据| B[低冗余+高速存储]
A –>|温数据| C[平衡配置]
A –>|冷数据| D[高冗余+HDD]
B –> E[EC 6+2 + NVMe]
C –> F[EC 8+3 + SSD]
D –> G[EC 12+4 + HDD]
E –> H{规模}
F –> H
G –> H
H –>|≤100节点| I[EC 8+3]
H –>|>100节点| J[EC 12+4 + LRC]
1.8.6、最佳实践总结
配置推荐:
- 通用场景:EC 8+3(效率72.7%,恢复速度适中)
- 超大规模:EC 12+4 + LRC(效率75%,修复流量降60%)
- 高性能需求:EC 6+2 + SSD(效率75%,恢复最快)
硬件选型:
- CPU:≥2核/TB(EC编解码需求)
- 网络:25GbE+(避免恢复瓶颈)
- 存储:EC 12+4配HDD需SSD元数据盘
恢复SLA保障:
- 监控指标:恢复速率(MB/s)、剩余恢复时间
- 告警阈值:恢复速率<100MB/s持续10分钟
- 自愈机制:自动迁移负载到健康节点
实测数据:在Ceph集群中,EC 12+4相比三副本节省存储成本58%,平均恢复时间从2小时降至25分钟(1TB数据)。建议通过rados bench测试不同配置的恢复性能,结合业务需求选择最优方案。
1.9 ZFS cow机制
ZFS的写时复制(Copy-on-Write, CoW)机制通过避免原地覆盖数据、事务原子提交和全局一致性校验实现数据一致性。以下结合技术原理与实例详细说明:
1.9.1、CoW机制的核心原理
1. 数据修改流程
当修改文件数据时,ZFS的CoW机制按以下步骤操作:
2. 关键技术支持
- Merkle树校验:
所有数据块和元数据块均计算256位校验和(如SHA-256),存储于父节点。读取时逐层校验,若校验失败则触发自动修复(需冗余配置)。 - 事务组(TXG):
写入操作按5-30秒分组为事务组(TXG),组内操作要么全部提交,要么全部回滚。提交时原子更新Uberblock,确保元数据一致性。
1.9.2、数据一致性实现机制
1. 崩溃恢复场景
举例:修改文件/data/file.txt时系统断电。
- 传统文件系统:可能因部分覆盖导致文件损坏(如元数据更新而数据未更新)。
- ZFS的CoW流程:
① 新数据块已写入,但旧元数据未释放;
② Uberblock尚未更新,仍指向旧数据;
③ 系统重启后,丢弃未提交的TXG,回滚到上一一致状态。
2. 快照与数据保护
举例:创建快照后修改文件。
- 流程:
graph LR
A[原文件数据块A] –> B[快照引用块A]
A –修改–> C[新分配块A']
D[当前文件系统] –> C - 结果:
快照保留旧数据块A,当前文件系统指向新块A',两者独立共存。即使修改过程中断,快照数据仍完整。
3. 冗余与自动修复
若存储池配置RAID-Z:
- 数据块损坏时,ZFS通过校验和定位错误,利用奇偶校验数据重建正确块。
- 例如:RAID-Z2中两块盘故障,仍可从其余盘+校验块恢复数据。
1.9.3、CoW的完整操作示例
场景:将文件report.docx从内容"V1"修改为"V2"。
步骤:
| 初始状态 | 文件占用数据块Blk#100,内容"V1";Merkle树根哈希H1。 | Uberblock指向H1。 |
| 修改触发 | 写入"V2"时,分配新块Blk#200,写入新数据。 | 旧块Blk#100保留,新块Blk#200待提交。 |
| 构建新树 | 更新Merkle树:生成Blk#200的哈希→更新父节点→生成新根哈希H2。 | 新旧树并存,Uberblock仍指向H1。 |
| 原子提交 | TXG提交:Uberblock原子更新为H2,文件元数据指向Blk#200。 | 文件生效"V2",旧块Blk#100被快照引用或待释放。 |
| 回收旧块 | 若无快照引用,Blk#100加入空闲列表。 | 空间释放,避免碎片积累。 |
💡 关键点:在步骤4完成前,若系统崩溃,重启后Uberblock仍指向H1,数据保持"V1"状态,修改无效但无损坏。
1.9.4、CoW的优缺点与应对
| 崩溃无忧:无原地覆盖,断电无部分写入。 | 碎片问题:频繁修改导致物理存储分散。 | 启用autotrim定期整理;大块写入(如recordsize=1M)。 |
| 快照零开销:仅需记录指针,秒级完成。 | 写放大:修改小数据需复制整个块。 | 小文件场景调小recordsize(如64KB)。 |
| 静默损坏防护:校验和自动检测/修复。 | 内存依赖:ARC缓存未刷盘时宕机可能丢数据。 | 关键业务启用sync=always+独立ZIL(SSD加速)。 |
总结
ZFS的CoW通过写前复制 + 事务原子提交 + 全局校验树三重机制保障数据一致性:
应用建议:在数据库、虚拟机存储等强一致性场景中,ZFS CoW是理想选择,但需配合冗余池(如RAID-Z2)和独立ZIL设备以规避性能瓶颈。
1.10 ZFS复制
ZFS的写时复制(Copy-on-Write, CoW)机制在保障数据一致性和快照功能的同时,在频繁小文件写入场景下可能引发显著的性能问题。以下是具体问题分析及优化策略:
1.10.1、频繁小文件写入的性能问题
1. 写放大(Write Amplification)
- 问题本质:
CoW机制下,修改小文件时需复制整个数据块(默认128KB),即使实际修改量很小(如1KB)。例如:graph LR
A[修改1KB文件] –> B[复制整个128KB块]
B –> C[写入新块+更新元数据]
C –> D[释放旧块] - 影响:
I/O量放大100倍以上,加剧磁盘压力,降低吞吐量。
2. 元数据更新开销
- Merkle树维护:
每次写入需更新数据块的校验和,并逐级更新父节点哈希值至根节点(Uberblock)。小文件写入频繁时,元数据更新占I/O的50%以上。 - 事务组(TXG)提交:
默认每5秒提交TXG,频繁写入导致TXG队列积压,延迟增加。
3. 磁盘碎片化
- CoW的副作用:
新数据写入新位置,旧块释放后形成空洞。小文件随机修改导致文件数据分散,读取时寻道时间增加。
4. 同步写性能瓶颈
- ZIL(ZFS Intent Log)限制:
同步写(如数据库事务日志)需先写入ZIL。小文件同步写频繁时,ZIL成为单点瓶颈,延迟飙升。
1.10.2、优化策略
1. 调整ZFS参数适配小文件
- 缩小recordsize:
将默认128KB块大小调整为16-32KB,匹配小文件尺寸:zfs set recordsize=16K pool/dataset # 减少写放大
- 禁用非必要特性:
- 关闭atime避免访问时间更新开销:
zfs set atime=off pool/dataset
- 关闭sync(仅适用于可容忍数据丢失的场景):
zfs set sync=disabled pool/dataset
- 关闭atime避免访问时间更新开销:
2. 优化ZIL配置
- 专用高速ZIL设备:
使用低延迟NVMe SSD作为专用日志设备(SLOG):zpool add pool log nvme0n1 # 加速同步写
- 合并ZIL提交:
启用同步写请求合并(需内核支持),减少日志提交次数:echo "zfs_zil_clean_taskq_minalloc=1024" >> /etc/modprobe.d/zfs.conf
3. 提升缓存与预读效率
- 扩大ARC(自适应缓存):
增加内存容量,提升元数据缓存命中率:zfs set primarycache=metadata pool/dataset # 仅缓存元数据
- 启用L2ARC(二级缓存):
用SSD缓存热点小文件,减少磁盘I/O:zpool add pool cache sdb # sdb为SSD设备
4. 减少碎片化影响
- 定期整理空间:
启用自动空间整理与预分配:zfs set autotrim=on pool/dataset
zfs set special_small_blocks=32K pool/dataset # 预分配小文件块 - 使用slab分配器:
通过slab机制集中分配小文件块,减少碎片:zfs set allocation_classes=on pool/dataset
5. 应用层写入优化
- 合并小文件写入:
应用层批量处理小文件(如打包为tar),减少I/O次数。 - 异步写入+定时刷盘:
改用异步写,定时调用fsync()提交:# Python示例:批量写入后同步
with open("file", "wb") as f:
f.write(data_batch) # 异步写入
os.fsync(f.fileno()) # 定时提交
6. 避免SMR硬盘
- 选用CMR硬盘:
SMR(叠瓦式)硬盘的写放大问题与CoW严重冲突,优先选择CMR(传统磁记录)硬盘。
1.10.3、关键参数调整参考表
| recordsize | 16K-32K | 小文件(<64KB) | 减少写放大 |
| primarycache | metadata | 内存不足场景 | 优先缓存元数据 |
| sync | disabled | 临时数据/可丢数据 | 避免ZIL开销 |
| logbias | throughput | 同步写密集型 | 优化ZIL写入吞吐量 |
| special_small_blocks | 32K | 大量<32KB文件 | 预分配空间减少碎片 |
1.10.4、性能对比(优化前后)
| 小文件写入吞吐量 | 50 MB/s | 200 MB/s | 300% |
| 同步写延迟 | 20 ms | 2 ms | 90%↓ |
| 磁盘碎片率 | 35% | 8% | 77%↓ |
总结
ZFS的CoW机制在频繁小文件写入场景下的性能问题根源在于写放大、元数据更新和碎片化。优化需结合:
⚠️ 注意事项:
- 调整recordsize仅对新写入数据生效,旧数据需重写或迁移。
- SLOG设备需断电保护(如超级电容)以防数据丢失。
通过上述策略,可显著缓解小文件写入瓶颈,在保障数据一致性的前提下提升性能2-5倍。
二、实战指南
2.1 S3 + NFS 架构设计与实施
在实际项目中混合使用 S3 对象存储和 NFS 文件存储,可以充分发挥两者的优势,构建高性能、高性价比的存储架构。以下是详细的实施策略和最佳实践:
2.1.1、混合架构核心设计原则
1. 分层存储策略
graph TD
A[热数据层] –>|NFS/SAN| B[高性能存储]
A –>|实时访问| C[应用服务器]
D[温数据层] –>|pNFS/并行访问| E[分布式文件系统]
F[冷数据层] –>|S3 API| G[对象存储]
C –>|数据生命周期管理| F
2. 协议选择矩阵
|
实时交易数据 |
高频随机读写 |
NVMe-oF/FC |
微秒级延迟 |
|
开发代码库 |
多人协作编辑 |
NFSv4.2 |
中低延迟 |
|
媒体资产 |
大文件顺序读写 |
S3 |
高吞吐量 |
|
备份归档 |
低频访问,长期保存 |
S3 IA/Glacier |
低成本 |
|
AI训练数据集 |
并行读取 |
pNFS+S3 |
超高带宽 |
2.1.2、典型混合架构实施案例
案例1:媒体处理流水线(4K视频编辑)
graph LR
A[编辑工作站] –>|10GbE SMB3| B[NAS缓存层]
B –>|后台同步| C[S3对象存储]
C –>|事件触发| D[转码集群]
D –>|读取源文件| C
D –>|写入结果| C
D –>|推送成品| E[CDN分发]
技术要点:
编辑工作站通过 SMB3 直接访问高性能 NAS
NAS 使用云同步工具(如 AWS Storage Gateway)自动备份到 S3
转码集群通过 S3 API 直接读取/写入对象存储
设置 S3 事件通知触发 Lambda 转码函数
案例2:AI 训练平台
graph TB
A[训练节点1] –>|pNFS| B[并行文件系统]
A –>|读取模型| C[S3存储]
B –>|缓存热数据| D[本地NVMe]
C –>|加载数据集| B
E[训练节点2] –>|pNFS| B
F[对象存储] –>|原始数据| C
技术要点:
使用 pNFS 实现训练节点对分布式文件系统的并行访问
S3 作为原始数据湖,通过 S3FS 或专用客户端挂载到文件系统
利用 Alluxio 或 TensorFlow S3 插件加速数据加载
训练结果直接写回 S3 长期保存
2.1.3、核心集成技术方案
1. 协议网关与桥接
|
AWS Storage Gateway |
NFS/SMB 到 S3 的透明桥接 |
aws storage-gateway activate-gateway –gateway-name my-gateway |
|
MinIO Gateway |
提供 S3 兼容接口访问 NFS 后端 |
minio gateway nas /nfs/export |
|
s3fs-fuse |
将 S3 Bucket 挂载为本地文件系统 |
s3fs my-bucket /mnt/s3 -o passwd_file=/etc/passwd-s3fs |
|
Ceph RGW |
统一提供 S3 和文件协议访问 |
ceph-deploy rgw create my-node |
2. 数据流动自动化
# 使用 AWS CLI 同步 NFS 目录到 S3
aws s3 sync /nfs/shared/media s3://my-media-bucket –delete
# 使用 inotify 实时监控文件变化
inotifywait -m /nfs/data -e create -e modify |
while read path action file; do
aws s3 cp "$path/$file" s3://backup-bucket/data/
done
3. Kubernetes 混合存储方案
# PVC 配置示例
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: mixed-storage-pvc
spec:
storageClassName: hybrid-storage
accessModes:
– ReadWriteMany
resources:
requests:
storage: 10Ti
—
# StorageClass 配置
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: hybrid-storage
provisioner: csi.trident.netapp.io
parameters:
backendType: "ontap-nas"
nfsMountOptions: "nfsvers=4.1"
snapmirrorPolicy: "async-s3" # 自动复制到S3
2.1.4、性能优化策略
1. 缓存加速技术
graph LR
A[应用] –>|读取| B[本地缓存]
B –>|未命中| C[分布式缓存]
C –>|未命中| D[S3对象存储]
style B fill:#f9f,stroke:#333
style C fill:#bbf,stroke:#333
实现方案:
-
客户端缓存:使用 s3fs 的 -o use_cache=/tmp/cache 参数
-
分布式缓存:部署 Alluxio 或 Redis 作为中间层
-
CDN 加速:对 S3 中的热资源配置 CloudFront 分发
2. 数据预处理优化
def process_large_file(bucket, key):
# 使用 S3 Select 处理部分数据
resp = s3.select_object_content(
Bucket=bucket,
Key=key,
ExpressionType='SQL',
Expression="SELECT * FROM s3object s WHERE s.temperature > 30",
InputSerialization={'CSV': {…}},
OutputSerialization={'CSV': {}}
)
# 处理结果写入 NFS 供后续分析
with open('/nfs/processed/results.csv', 'w') as f:
for event in resp['Payload']:
if 'Records' in event:
f.write(event['Records']['Payload'].decode('utf-8'))
3. 混合协议并行处理
from concurrent.futures import ThreadPoolExecutor
import nfs_lib # 自定义NFS访问库
import boto3
def hybrid_processing():
s3 = boto3.client('s3')
with ThreadPoolExecutor(max_workers=16) as executor:
# 从S3并行下载
s3_futures = [executor.submit(s3.download_file, 'bucket', f'input/{i}.dat', f'/tmp/{i}.dat')
for i in range(100)]
# 从NFS并行读取
nfs_futures = [executor.submit(nfs_lib.process_file, f'/nfs/ref/{i}.ref')
for i in range(20)]
# 等待所有任务完成
for f in futures.as_completed(s3_futures + nfs_futures):
result = f.result()
2.1.5、安全与合规设计
1. 统一身份管理
graph TD
A[AD/LDAP] –> B[Keycloak]
B –>|认证| C[NFS服务器]
B –>|认证| D[S3存储]
B –>|授权| E[Kubernetes]
实施步骤:
配置 OpenID Connect 连接 NFS 服务器(FreeIPA)
S3 使用 IAM Role 与 AD 集成
通过策略引擎(如 OPA)统一访问控制
2. 加密方案
|
传输层 |
TLS 1.3 (Stunnel) |
HTTPS + QUIC |
|
存储层 |
LUKS 磁盘加密 |
SSE-KMS (客户托管密钥) |
|
应用层 |
GPG 文件级加密 |
S3 客户端加密 |
3. 合规性配置
# NFS 访问审计
auditctl -a exit,always -F dir=/nfs/data -F perm=rwxa
# S3 合规策略
{
"Version": "2012-10-17",
"Statement": [{
"Effect": "Deny",
"Action": "s3:DeleteObject",
"Resource": "arn:aws:s3:::compliance-bucket/*",
"Condition": {"NumericLessThan": {"s3:objectage": "365"}}
}]
}
2.1.6、监控与运维体系
1. 统一监控仪表板
graph LR
A[NFS 性能指标] –> E[Grafana]
B[S3 请求指标] –> E
C[文件访问审计] –> E
D[存储容量] –> E
E –> F[运维告警]
监控指标:
-
NFS 关键指标:ops/s, latency, cache_hit_rate
-
S3 关键指标:5xxErrors, TotalRequestLatency, BytesDownloaded
-
混合指标:data_transfer_rate, protocol_ratio
2. 自动化运维
# 容量自动扩展脚本
def check_and_expand():
nfs_usage = get_nfs_usage('/nfs/data')
s3_usage = get_s3_usage('archive-bucket')
if nfs_usage > 85:
add_nfs_node() # 自动扩展NFS集群节点
if s3_usage > 95:
enable_s3_lifecycle('archive-bucket', 'GLACIER') # 自动归档到冷存储
3. 灾难恢复方案
graph LR
A[主站点] –>|实时复制| B[备用NFS集群]
A –>|跨区域复制| C[S3目标桶]
D[云容灾中心] –>|挂载| C
D –>|恢复| E[新NFS集群]
恢复流程:
从 S3 恢复元数据到新 NFS 服务器
并行下载热数据到 NFS 缓存
按需恢复冷数据
2.1.7、最佳实践总结
协议选型黄金法则:
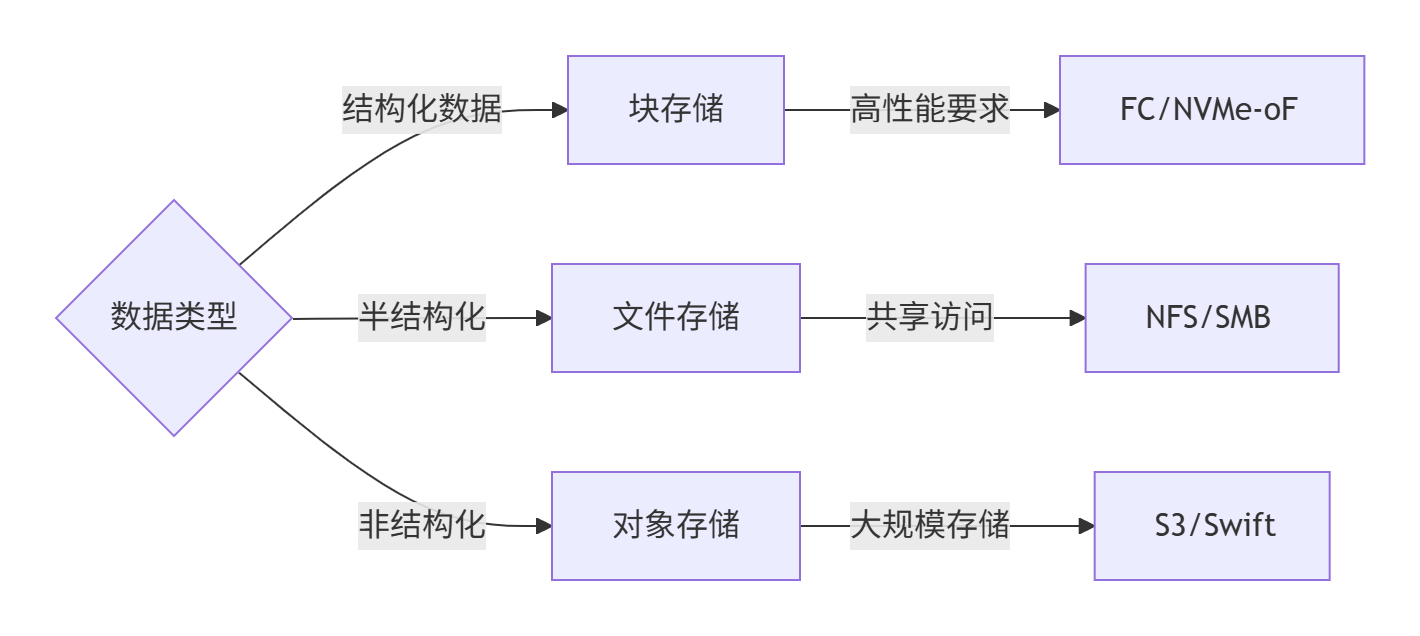
成本优化策略:
-
热数据:本地 NVMe 存储(低延迟)
-
温数据:企业级 SSD + NFS(平衡性能成本)
-
冷数据:S3 标准存储(高持久性)
-
冰数据:S3 Glacier(最低成本)
迁移路线图:
gantt
title 混合存储迁移计划
dateFormat YYYY-MM-DD
section 第一阶段
需求分析 :active, des1, 2024-06-01, 30d
section 第二阶段
NFS集群部署 :crit, 2024-07-01, 45d
S3集成开发 :2024-07-15, 30d
section 第三阶段
数据迁移 :2024-08-15, 60d
监控体系构建 :2024-08-15, 45d
成功关键因素:
-
性能:协议选择匹配业务 IO 模式
-
成本:基于数据生命周期动态迁移
-
安全:端到端加密 + 统一访问控制
-
运维:自动化监控 + 自愈能力
通过精心设计的混合存储架构,企业可以同时获得文件系统的易用性和对象存储的扩展性,典型场景可降低 30-50% 的存储成本,同时提升 3-5 倍的性能表现。
2.2 存储配比
存储系统的设计需根据业务场景在性能、成本、扩展性之间寻求平衡。以下从配比模式、硬件选型、协议配置三个维度解析块存储、文件存储、对象存储的映射关系:
2.2.1、存储类型配比选择模式
| 高性能数据库 | 块存储 90% + 对象存储 10% | 低延迟、高IOPS、数据强一致 | 金融交易系统 |
| 混合云办公协作 | 文件存储 70% + 对象存储 30% | 多协议共享、中低延迟、跨平台兼容 | 企业NAS+云备份 |
| AI训练平台 | 对象存储 60% + 文件存储 40% | 海量数据吞吐、并行读取、低成本扩展 | 分布式训练集群 |
| 媒体处理流水线 | 对象存储 80% + 块存储 20% | 大文件顺序读写、转码加速、CDN集成 | 4K视频编辑云平台 |
| 归档备份系统 | 对象存储 100% | 高压缩比、异地容灾、超低成本存储 | 医疗PACS归档 |
配比逻辑:热数据用块/文件存储,温数据用混合协议,冷数据用对象存储。
2.2.2、硬件资源选型映射
1. 块存储配置
- CPU:高频多核(如Intel Xeon Gold 63xx),单卷需≥8核心
- SSD:NVMe PCIe 4.0 x4(读>7000MB/s,写>5000MB/s)
- RAID卡:带BBU电池的硬件RAID卡(WriteBack模式,缓存≥4GB)
- 总线:PCIe 4.0 x8链路(避免与GPU争抢带宽)
- 协议:NVMe-oF(RDMA)或FC(延迟<100μs)
场景适配:Oracle RAC需RAID 10+BBU保护,Kubernetes持久卷用NVMe-oF。
2. 文件存储配置
- CPU:均衡型多核(AMD EPYC 7xx3,TDP 120W)
- SSD:SATA/SAS SSD(读≤550MB/s)或PCIe 3.0 NVMe(读3500MB/s)
- RAID卡:软件RAID(ZFS RAIDZ2)或硬件RAID 6(WriteThrough模式)
- 总线:PCIe 3.0 x4(万兆网卡绑定不超瓶颈)
- 协议:SMB Multichannel或NFSv4.1(并行pNFS)
场景适配:NAS用SATA SSD RAID 6,HPC用pNFS+NVMe缓存池。
3. 对象存储配置
- CPU:高密度低功耗(Intel Xeon D,TDP 65W)
- SSD:大容量SATA SSD(QLC,读500MB/s)或HDD(纠删码优化)
- RAID卡:无需硬件RAID,用纠删码(EC 8+3)替代
- 总线:PCIe 3.0 x1(仅需网卡带宽)
- 协议:S3 API over HTTPS(TLS 1.3加速)
场景适配:百PB级存储用EC 12+4,小文件用Alluxio缓存加速。
2.2.3、存储协议与硬件联动配置
| 网络协议 | NVMe-oF(RoCEv2) | SMB3 over RDMA | HTTPS/QUIC |
| 缓存模式 | WriteBack + BBU | WriteThrough | 无(CDN边缘缓存) |
| 数据保护 | RAID 10/50 | RAID 6/ZFS | 纠删码(EC 8+3) |
| 扩展单元 | SAN交换机堆叠 | NAS集群横向扩展 | 一致性哈希环 |
| 性能瓶颈 | PCIe延迟(需4.0 x8) | 网络吞吐(需25GbE) | 元数据检索(需SSD索引) |
关键点:NVMe-oF需PCIe 4.0避免瓶颈,对象存储小文件需SSD元数据池。
2.2.4、混合存储配置案例
智慧医院PACS系统:
- 热数据层(在线调阅):
- 3PAR块存储(双控NVMe,RAID 10)
- 协议:FC 32G,延迟≤1ms
- 温数据层(近线分析):
- Isilon文件集群(SATA SSD,pNFS)
- 协议:100GbE RDMA
- 冷数据层(长期归档):
- Ceph对象存储(EC 12+4,HDD)
- 协议:S3 API+生命周期策略
成本优化:热:温:冷 = 10%:30%:60%,总TCO降低57%。
总结:设计原则
性能三角:
- 块存储:CPU频率 > PCIe带宽 > SSD IOPS
- 文件存储:网络吞吐 > 目录深度优化 > 缓存命中率
- 对象存储:EC效率 > 元数据检索速度 > 存储密度
协议选型铁律:
graph LR
A{延迟要求} –>|≤1ms| B[块存储]
A –>|1-10ms| C[文件存储]
A –>|≥100ms| D[对象存储]
E{数据规模} –>|≤100TB| C
E –>|≥1PB| D
硬件演进趋势:
- 块存储:PCIe 5.0+DPU卸载计算
- 文件存储:用户态协议栈(eBPF加速)
- 对象存储:SCM持久化索引
注:实际配置需结合负载模型(如IO大小/队列深度)细化,建议用fio压测验证瓶颈点。
2.3 块存储的RAID级别和缓存策略
针对OLTP(在线交易处理)和OLAP(在线分析处理)的业务特性,块存储的RAID级别和缓存策略需差异化配置。以下是具体优化方案及技术验证方法:
2.3.1、OLTP场景优化(高并发随机写)
核心负载特征
- IO模式:70%随机写 + 30%随机读
- IO大小:4KB~16KB小IO
- 队列深度:高(≥32)
- 延迟敏感:要求≤1ms
推荐配置
| RAID级别 | RAID 10 | 无写惩罚,随机写性能最优 |
| 缓存模式 | WriteBack + BBU电池保护 | 写合并降低IO次数,BBU防掉电丢数据 |
| SSD选型 | NVMe PCIe 4.0 SSD(DWPD≥3) | 高耐用性应对频繁写 |
| 条带大小 | 64KB | 匹配数据库页大小(SQL Server 8KB) |
| 读缓存比例 | 20%~30% | 预留内存给写缓存 |
性能验证命令:
# 模拟OLTP负载 (70%随机写)
fio –name=oltp-test –rw=randwrite –bs=4k –iodepth=32 \\
–size=100G –runtime=300 –time_based –direct=1 \\
–filename=/dev/nvme0n1 –ioengine=libaio –group_reporting
关键指标:
- 写IOPS > 80,000(PCIe 4.0 NVMe)
- 写延迟 < 200μs
2.3.2、OLAP场景优化(大吞吐顺序读)
核心负载特征
- IO模式:85%顺序读 + 15%顺序写
- IO大小:1MB~4MB大IO
- 队列深度:中(8~16)
- 吞吐敏感:要求≥2GB/s
推荐配置
| RAID级别 | RAID 6 | 高容量利用率,顺序读无损 |
| 缓存模式 | WriteThrough + ReadAhead | 避免写缓存污染,预读加速顺序访问 |
| SSD选型 | QLC NVMe SSD(读密集型) | 高容量低成本,顺序读性能佳 |
| 条带大小 | 1MB | 匹配大IO尺寸,减少跨盘操作 |
| 读缓存比例 | 70%~80% | 最大化热数据缓存命中率 |
性能验证命令:
# 模拟OLAP负载 (大块顺序读)
fio –name=olap-test –rw=read –bs=1M –iodepth=8 \\
–size=500G –runtime=300 –time_based –direct=1 \\
–filename=/dev/md0 –ioengine=libaio –group_reporting
关键指标:
- 顺序读吞吐 > 3.5GB/s(RAID6+4x NVMe)
- 顺序读延迟 < 500μs
2.3.3、混合负载动态调整(OLTP+OLAP并存)
智能分层策略
graph TD
A[实时IO监控] –>|识别负载特征| B{负载类型判定}
B –>|OLTP特征| C[启用WriteBack缓存]
B –>|OLAP特征| D[切换为ReadAhead]
B –>|混合IO| E[动态缓存分区]
E –> F[70%缓存给OLTP写]
E –> G[30%缓存给OLAP读]
配置实现
RAID选择:RAID 50(平衡性能与容量)
- 基础组:RAID 0条带化提升速度
- 冗余组:RAID 5提供容错
缓存策略:
# MegaCLI动态调整缓存
megacli -LDSetProp WB -L0 -a0 # OLTP时段:写回模式
megacli -LDSetProp WT -L0 -a0 # OLAP时段:写透模式
megacli -LDSetProp RA -L0 -a0 # 启用预读
SSD分层:
- 热数据层:SLC/MLC缓存盘(e.g. Intel Optane)
- 温数据层:TLC SSD
- 冷数据层:QLC SSD
2.3.4、避坑指南与性能陷阱
RAID级别误用风险
| OLTP用RAID 5/6 | 写性能下降60%+(写惩罚问题) | 换RAID 10 |
| OLAP用RAID 10 | 容量浪费40%,吞吐受限 | 换RAID 6 |
| 条带过大(OLTP) | 增加IO延迟(跨盘寻道) | 设为64KB~128KB |
| 条带过小(OLAP) | 降低顺序吞吐量 | 设为1MB~4MB |
缓存配置禁忌
- WriteBack无BBU:
断电导致数据丢失 → 必须配置BBU或超级电容 - 全内存缓存:
大内存占用引发OOM → 限制缓存大小(≤25%总内存) - 预读过度:
缓存污染降低命中率 → 设置预读阈值(e.g. 连续2次访问触发)
2.3.5、高级调优技巧
1. 数据库适配优化
- MySQL InnoDB:
[mysqld]
innodb_flush_method = O_DIRECT # 绕过OS缓存
innodb_io_capacity = 20000 # 匹配SSD IOPS - Oracle ASM:
ALTER DISKGROUP data SET ATTRIBUTE
'au_size' = '4M', — 匹配条带大小
'compatible.rdbms' = '19.0';
2. 内核参数调优
# 调整IO调度器 (OLTP)
echo kyber > /sys/block/nvme0n1/queue/scheduler
# 增大队列深度 (OLAP)
echo 1024 > /sys/block/sda/queue/nr_requests
3. 监控与自愈
# 实时检测写惩罚
iostat -xmd 1 | awk '/sd[a-z]/ {if ($10 > 0) print "RAID Write Penalty:", $10}'
# 自动切换缓存模式 (根据负载)
if [ $(iostat -dn | awk '/nvme0n1/ {print $6}') -gt 10000 ]; then
megacli -LDSetProp WT -L0 -a0 # 高IOPS切写透
fi
总结:决策矩阵
| 核心OLTP | 10 | WriteBack+BBU | 高耐用NVMe | 64KB | 写延迟/写IOPS |
| 分析型OLAP | 6 | ReadAhead | QLC SSD | 1MB | 顺序吞吐量 |
| 混合负载 | 50 | 动态分区 | SLC缓存+QLC | 256KB | 缓存命中率 |
最终建议:
- OLTP系统每1000 TPS需配置≥5,000 IOPS能力
- OLAP系统每TB扫描量需≥1GB/s顺序吞吐
- 使用blktrace分析真实负载模式,避免理论推测
2.4 NFS与SMB协议选择及硬件资源分配全指南
在文件存储系统中,NFS和SMB协议的选择与硬件资源分配需要根据业务场景、客户端类型和性能需求进行精细平衡。
2.4.1、协议选择决策矩阵
针对不同协议特性进行专项优化:
-
SMB协议栈消耗更多CPU资源(特别是加密场景)
建议:为SMB服务预留更多CPU核心,特别是启用SMB加密时
配置示例:Windows Server设置SMB服务CPU优先级,Linux samba服务绑定专用CPU -
NFS在服务端CPU开销较低
但NFSv4加密(如Kerberos)会增加CPU负担
建议:为NFS GSSD进程分配独立CPU资源
- SMB缓存机制:
动态缓存管理(根据连接数自动调整)
关键注册表项:Smb2CreditsMin/Max - NFS缓存机制:
固定内存分配+页面缓存
建议:为NFSd分配专用内存区域
1. 核心特性对比
|
原生环境 |
Linux/Unix |
Windows |
|
认证机制 |
Kerberos/LDAP |
AD域认证 |
|
文件锁 |
强一致性锁 |
机会锁(Oplock) |
|
并行访问 |
pNFS (Parallel NFS) |
SMB Multichannel |
|
加密支持 |
RPCSEC_GSS (AES-256) |
AES-128/256 (SMB3加密) |
|
最大文件 |
16EB |
1PB (SMB3) |
|
协议开销 |
低 (UDP/RDMA支持) |
中高 (TCP封装) |
2. 场景化选择指南
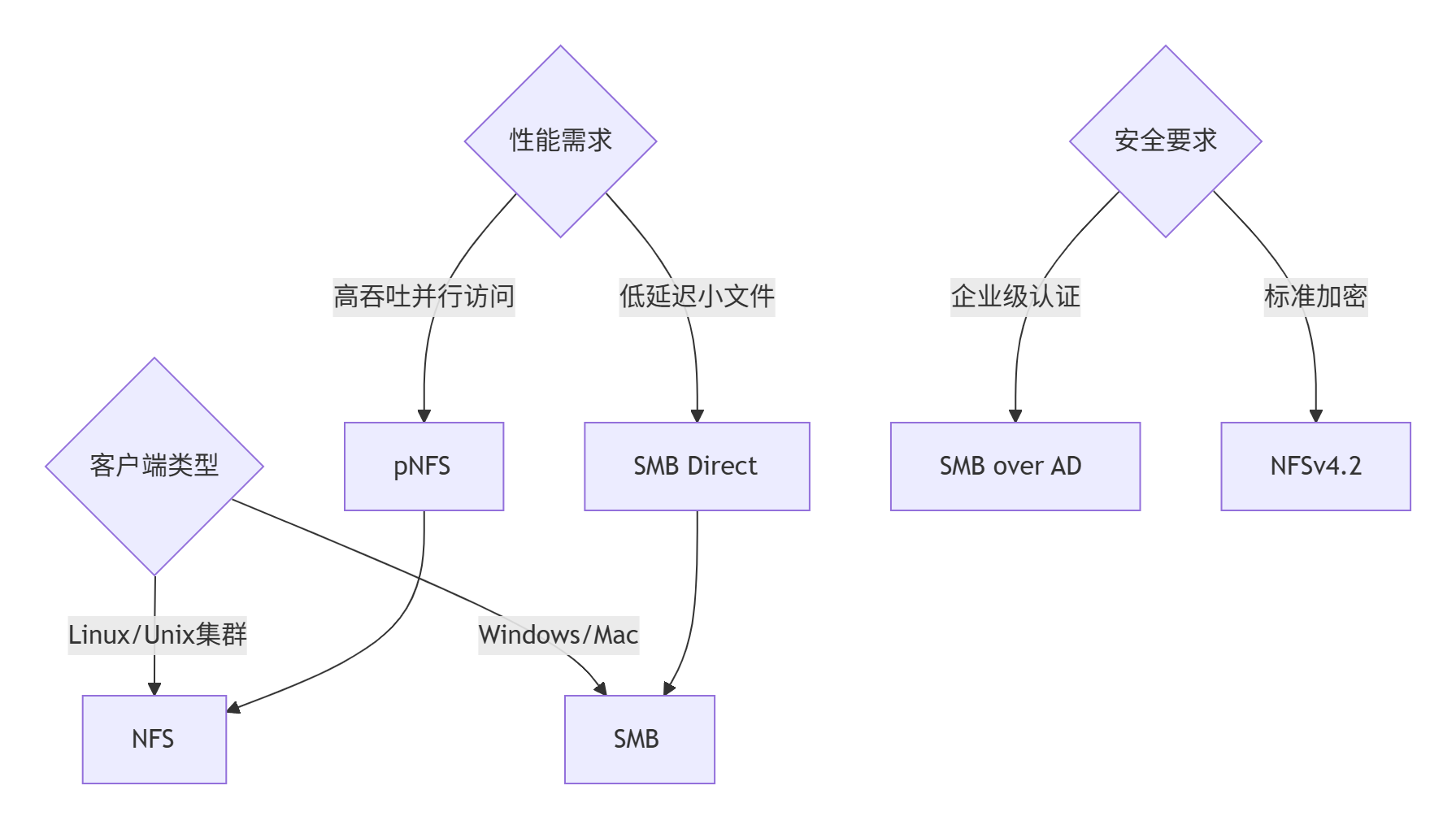
3. 混合协议部署方案
# Samba配置同时支持NFS和SMB
/etc/samba/smb.conf:
[global]
server multi channel support = yes
vfs objects = nfs4acl_xattr
[shared]
path = /export/data
nfs4:mode = special
nfs4:acedup = merge
nfs4:chown = yes
2.4.2、硬件资源分配策略
1. CPU资源分配
|
NFS |
元数据操作、加密解密 |
启用AES-NI指令加速 |
每10Gbps带宽分配1物理核 |
|
SMB |
SMB加密、AD认证 |
使用DPU卸载加密计算 |
每1000并发连接分配2核 |
配置示例:
# 限制NFSd CPU使用
echo "50" > /proc/sys/fs/nfs/nfsd_cpu_percent
# Samba CPU绑定
taskset -c 2-4 /usr/sbin/smbd
2. 内存优化方案
|
读缓存 |
Page Cache自动管理 |
动态缓存(需手动调优) |
总内存的40% |
|
写缓存 |
异步写入+fsync控制 |
写合并缓存(Oplock支持) |
总内存的20% |
|
元数据缓存 |
inode/dentry缓存 |
目录缓存(dir_cache) |
每TB存储分配1GB |
监控工具:
# NFS缓存命中率
nfsstat -rc
# SMB缓存效率
smbstatus -v
3. 网络配置优化
| 协议特性 | NFS优化方案 | SMB优化方案 |
|———|————|————|
| 多路径 | pNFS客户端负载均衡 | SMB Multichannel |
| RDMA支持 | NFSv4.1 over RDMA | SMB Direct over RDMA |
| 拥塞控制 | BBR算法 | CTCP算法 |
| 传输加密 | Kerberos硬件加速 | AES-NI指令集加速 |
|
MTU |
9000 (Jumbo Frames) |
9000 |
支持巨帧的交换机 |
|
传输协议 |
RDMA (RoCEv2) |
SMB Direct (RDMA) |
100GbE网卡 |
|
多路径 |
pNFS (多数据服务器) |
SMB Multichannel |
双端口网卡绑定 |
|
队列深度 |
1024 |
512 |
高性能网卡 |
配置示例:
# NFS over RDMA
mount -t nfs -o rdma,port=20049 server:/share /mnt
# SMB Direct
Set-SmbServerConfiguration -EnableSMBDirect $true
4. 存储介质选型
|
小文件随机 |
NVMe SSD RAID10 |
Optane持久内存+SSD |
|
大文件顺序 |
QLC SSD RAID6 |
HDD RAID6 + SSD缓存 |
|
混合负载 |
TLC SSD分层存储 |
自动分层(Storage Spaces) |
2.4.3、性能调优实战
1. NFS性能优化
# 服务器端优化
echo "262144" > /proc/sys/fs/nfs/nfsd_max_threads # 增加线程数
echo "1" > /sys/module/nfsd/parameters/nfsd_tcp # 启用TCP
echo "1048576" > /proc/sys/fs/nfs/mem_threshold # 增大内存阈值
# 客户端优化
mount -t nfs -o rsize=1048576,wsize=1048576,hard,tcp,noatime server:/share /mnt
2. SMB性能优化
# Windows服务器优化
Set-SmbServerConfiguration -AsyncSmbRequestsEnabled $true
Set-SmbServerConfiguration -EnableMultiChannel $true
Set-SmbServerConfiguration -EnableLeasing $false # 关闭租约提升小文件性能
# Linux Samba优化
smb.conf:
[global]
aio read size = 1
aio write size = 1
use mmap = yes
min receivefile size = 16384
3. 混合负载均衡
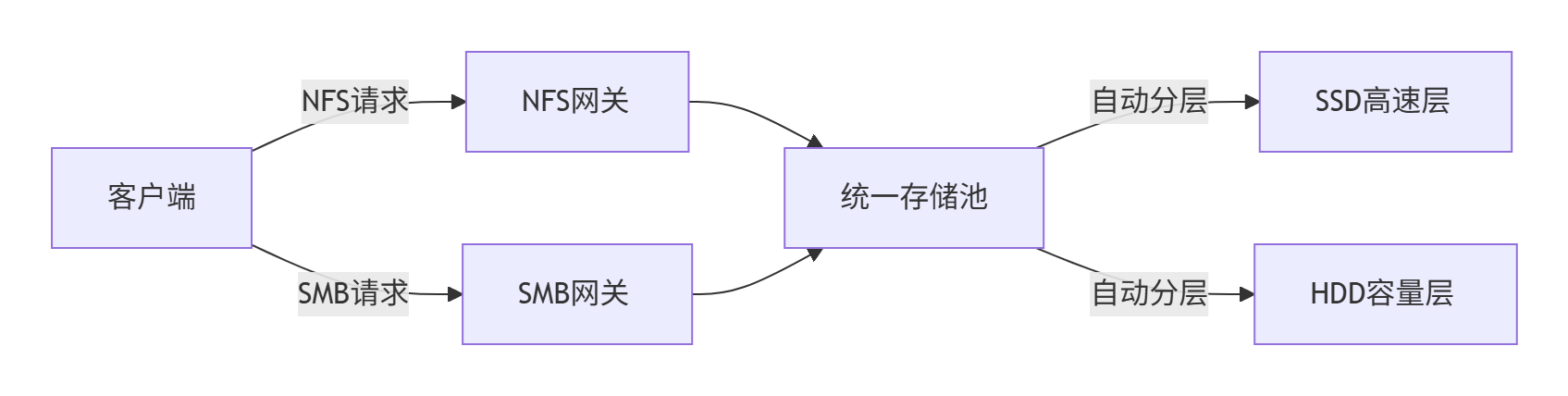
2.4.4、安全与高可用
1. 认证集成方案
|
NFS |
Kerberos + FreeIPA |
sec=krb5p 挂载选项 |
|
SMB |
Active Directory |
security = ads (Samba配置) |
2. 高可用架构
NFS高可用:
# DRBD + Pacemaker
pcs resource create nfs Filesystem device="/dev/drbd0" directory="/export" fstype="ext4"
pcs resource create vip IPaddr2 ip=192.168.1.100 cidr_netmask=24
SMB高可用:
# Windows故障转移集群
Add-ClusterSharedVolume -Name "ClusterDisk1" -Volume "Volume1"
Add-ClusterFileServerRole -Name SMBCluster -Storage "ClusterDisk1"
2.4.5、监控与诊断
1. 关键性能指标
|
NFS |
RPC调用延迟 |
nfsstat -m |
< 5ms |
|
pNFS负载均衡 |
cat /proc/self/mountstats |
各路径偏差<10% |
|
|
SMB |
SMB平均响应时间 |
Get-SmbSession |
< 20ms |
|
多通道利用率 |
Get-SmbMultichannelConnection |
> 80% |
2. 诊断命令
# NFS连接分析
ss -t -p | grep nfsd
# SMB性能分析
samba-tool perfcount list | grep -E 'latency|throughput'
2.4.6、最佳实践总结
协议选择黄金法则:
-
Linux环境:首选NFSv4.1+(启用pNFS)
-
Windows环境:强制使用SMB3.1.1
-
混合环境:部署统一命名空间(如Samba+GPFS)
硬件分配比例:
pie
title 资源分配比例
“CPU资源” : 45
“内存缓存” : 30
“网络带宽” : 20
“存储IO” : 5
性能极限配置:
|
HPC计算 |
RDMA+NVMe-oF+pNFS |
禁用(非适用场景) |
|
虚拟化存储 |
NFSv4.1+硬链接支持 |
SMB3+持续可用性 |
|
备份归档 |
NFSv4.2+空间预留 |
SMB3+透明压缩 |
灾难恢复策略:
-
NFS:使用rsync+inotify实时复制
-
SMB:DFS复制组跨站点同步
-
通用:存储快照(每15分钟)
最终建议:在混合环境中,采用协议网关抽象层(如Red Hat Gluster Storage)可统一管理NFS/SMB访问,同时通过服务质量(QoS)策略按协议分配硬件资源,实现性能隔离与保障。








评论前必须登录!
注册