 网硕互联帮助中心
网硕互联帮助中心一、为什么要重新思考服务器选型?
RTX 5090 / 5080 的全面上市,标志着AI推理与模型部署的硬件底座迎来关键升级。相较前代RTX 4090,50系在显存容量、带宽调度及系统稳定性上实现全方位优化,完美契合大模型高负载、长时运行的严苛需求。
尽管4090仍在服役,但着眼于部署效率与长期可维护性,50系不仅是性能迭代,更是构建未来稳健算力平台的战略性投入。
随之而来的关键决策:
1.型号选择: RTX 5090 还是 RTX 5080?如何权衡性能与成本?
2.场景适配: 教学实验、科研探索、生产部署、工程落地…不同场景如何精准匹配硬件配置?
3.规模规划: 单卡、双卡、四卡乃至八卡?如何科学选型以满足算力需求与扩展性?
本文将基于项目交付经验,解析从单卡到八卡的主流配置方案,助您为实际业务甄选最优AI服务器整机。

二、50系GPU:高性能+高显存,适配推理部署主流需求
50系显卡(RTX 5090 / RTX 5080)凭借革命性的架构,在AI推理与科研应用中展现出显著优势。我们针对不同性能需求和预算场景,提供基于这两款旗舰GPU的整机解决方案:
RTX 5090 整机方案:为极致性能与扩展而生
● 超大显存 (32GB): 轻松部署百亿级大模型(如DeepSeek、Qwen等)。
● 顶尖推理吞吐量: 卓越应对高并发、多任务推理负载,稳定性出众。
● 强大集群扩展性: 理想用于构建4卡/8卡服务器推理节点集群。
核心价值: 是科研工程化落地、大规模推理服务部署、高性能AI平台搭建等严苛高负载场景的理想选择。

RTX 5080 整机方案:高性价比与灵活部署的典范
● 卓越性价比: 得益于全新Blackwell架构,ResNet等基准性能媲美RTX 4090,整体拥有成本更优。
● 高显存与能效平衡: 在提供充足显存的同时,功耗与散热控制更佳,适配工作站环境。
● 灵活部署优势: 单机即可满足绝大多数中小规模模型推理需求。
核心价值: 完美契合AI教学实验、个人/小组科研探索、中型团队模型验证与部署等场景。

无论您追求RTX 5090的巅峰性能,还是青睐RTX 5080的灵活性价比,我们都提供:开箱即用的整机方案(出厂预配置)、主流AI框架预设、优化推理模板及持续运维支持,一站式解决您的AI算力需求,大幅简化部署与运维复杂度。
三、配置建议:三档主流方案,场景导向选型
以下三种配置为我们目前交付量较大的组合,涵盖从轻量测试到企业级部署的主流使用场景。配置均可基于 5090 / 5080 进行定制,按业务强度推荐搭配。
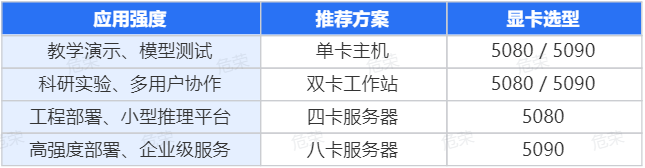
1.教研/实验探索场景:单机双卡塔式主机
适合人群:高校AI课题组、教学演示、多变量预测类任务
●推荐显卡: RTX 50801/2
●参考配置:
○平台:赋创EW240-G4
○CPU:W9-3595X1
○内存:64–128GB
○存储:2T M.2 NVMe+3.84T U.2 NVMe
●方案亮点:
○部署中小型模型(≤7B)用于教学、演示与模型测试
○可集成AI绘图、音频生成等轻应用流程

2.中型项目部署 / AI应用后端:4卡服务器平台
适合人群:科研项目落地、科研转工程应用团队,企业部署、轻量推理集群
●推荐显卡组合:5080 ×4
●参考配置:
○平台:赋创4U机架式服务器EG4412-G41
○CPU:Intel 至强 Gold 65302
○内存:64G DDR5 RECC 4800 4
○硬盘1:960G SATA 2.5寸 SSD 企业级2
○+3.84T U.2 NVMe PCIe 4.0 2.5寸 SSD 企业级1
○RAID控制器1
○网络:双万兆光口+ 管理端口
●方案亮点:
○支持模型并行部署、API服务开放、Web端访问接入
○可在多卡间实现模型拆分与负载均衡

3.企业级部署场景:多节点推理集群
适合人群:AI初创企业核心平台、大模型服务提供方集群部署
●推荐显卡: RTX 5090 ×8(高密集推理节点)
●参考配置:
○平台:赋创EG4812-A4
○CPU:EPYC 96542
○内存:64G DDR5 RECC 4800 16
○存储1:960G SATA 2.5寸 SSD 企业级2
○存储2:3.84T U.2 NVMe PCIe 4.0 2.5寸 SSD 企业级2
○RAID控制器*1
○网络:双口InfiniBand HDR100/ 或 100GbE 高速互联
●方案亮点:
○快速对接前端业务系统,降低工程接入门槛
○支持推理任务弹性扩展,适配国产大模型如DeepSeek、Qwen等
○构建企业级多模型服务架构,如Chat服务、搜索增强生成、定制API接口等
○适用于AI模型推理、大数据分析、自动驾驶技术分析等高计算需求场景

四、我们提供的整机服务,远不止“配置”
很多客户在选型时只看显卡和主机配置,但忽视了部署效率。其实,“部署”往往比“配置”更耗时间。
实际交付过程中,我们遇到最多的问题是:
●驱动冲突、CUDA版本错误、编译失败
●vLLM、TGI 等推理框架环境难配
●推理脚本缺乏调度/接口包装,落地效率低
推荐选择“赋创软硬一体”整机方案,交付内容包含:

不仅是交付一台机器,而是交付一个可直接运行的“AI工作平台”。
总结:部署大模型,选型先要看清需求
5090的出现确实让AI服务器进入了新的“性价比”区间。但部署效率、系统稳定、软件集成度,才是真正影响落地进度的核心。
如果你正在准备实验、科研项目部署,或为团队搭建AI算力平台,我们提供**【需求评估 → 配置推荐 → 环境预设 → 按需交付(远程/上门)→ 运维支持】**的持续服务。
欢迎留言咨询,获取您的专属配置方案 & 近期交付案例参考。我们将持续免费分享更多实用配置建议与部署经验!









评论前必须登录!
注册