 网硕互联帮助中心
网硕互联帮助中心我们常常在讨论AI GPU时聚焦于涉及NVIDIA GB200 NVL72或NVIDIA HGX 8-GPU平台的高端集成机架,这些主要用于AI工厂应用。然而,大量AI应用其实发生在这些庞然大物之外。今天,我们将深入解析超微等厂商的8卡、标准、高密、边缘服务器及工作站方案,助你精准匹配H200 NVL、Blackwell RTX PRO 6000、L40S/L4等GPU,应对无处不在的AI负载。

8卡 PCIe GPU 系统
8卡PCIe GPU系统在某种程度上与基于SXM的系统类似,但存在几个重要的区别。PCIe GPU系统通常每块GPU功耗在300W到600W之间,使其功耗低于基于SXM的解决方案。除此之外,我们通常看到每块PCIe GPU配备两块东西向(East-West)400GbE网卡的比例,而在基于SXM的系统中,这个比例更接近1:1。同时,移除NVLink交换架构意味着这些系统可以以更低的成本(尽管牺牲了部分提升的性能)和更低的功耗生产。虽然听起来这些系统只是基于SXM平台的低功耗版本,但实际情况并非必然如此。它们提供了额外的选项来定制平台中使用的GPU,并增加额外的图形处理能力。

我们常见的典型PCIe GPU包括:
●NVIDIA H100 NVL / H200 NVL(搭配 NVIDIA AI Enterprise 软件)
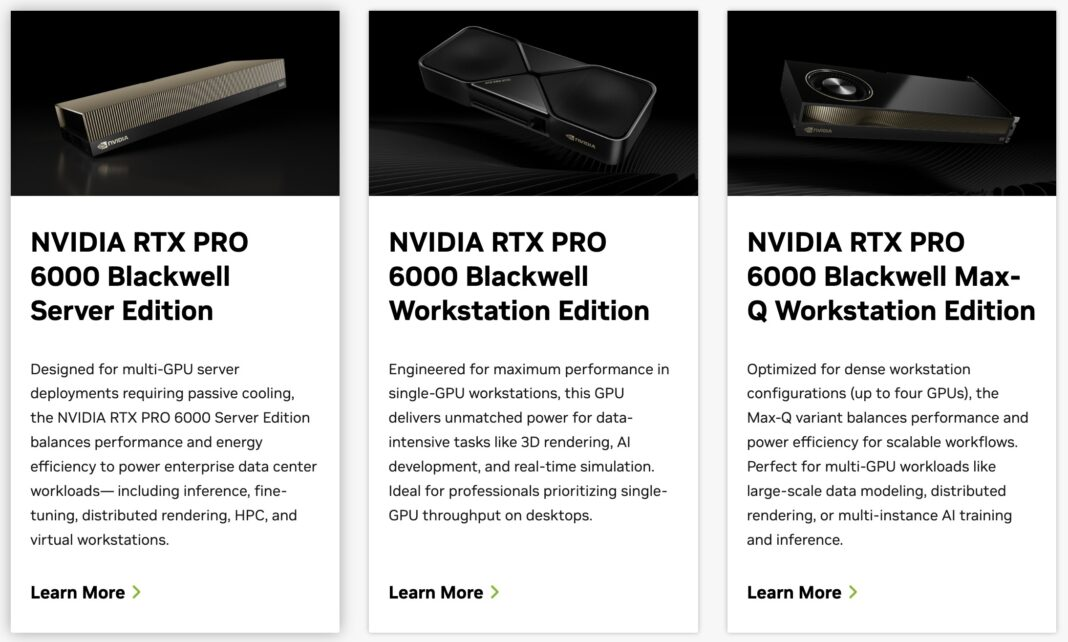
●NVIDIA RTX PRO 6000 Blackwell 服务器版
●NVIDIA L40S
NVIDIA H100 NVL 和 H200 NVL(搭配 NVIDIA AI Enterprise 软件) 设计用于在最多四块GPU之间包含NVLink互连技术。这些解决方案通常用于模型后训练和AI推理,其每GPU功耗可能低于SXM系统。选择H200 NVL而非H100 NVL的最大原因可能是其更新的HBM内存子系统,该子系统针对内存密集型工作负载进行了优化。

NVIDIA RTX PRO 6000 Blackwell 的用途略有不同。这是NVIDIA为运行大量混合工作负载的用户提供的解决方案。虽然这些卡没有高带宽内存(HBM),但它们拥有RT核心、编码器,甚至视频输出接口。这意味着RTX PRO 6000可以用于图形工作负载,例如工程设计、虚拟桌面基础设施(VDI)、渲染等。它们也可用于AI推理,每块卡配备96GB GDDR7显存。在8卡系统中,可以使用多实例GPU(Multi-Instance GPU, MIG)技术将这些GPU划分为四个实例,从而提供多达32个逻辑GPU。八块这样的GPU可为AI推理应用提供768GB的GPU组合显存。在8卡系统中,可以根据一天中的不同时间将GPU用于不同的应用(例如,白天用于VDI,晚上用于AI推理)。也可以在一天中的不同时间段将GPU用于不同的任务。这里的关键在于其使用上的灵活性,因为每块GPU都拥有大量显存,但更重要的是它具备专注于AI的GPU所没有的NVIDIA RTX图形处理能力。
NVIDIA L40S 本质上是该平台基于Ada Lovelace架构的一款低成本GPU。这些GPU拥有48GB显存和图形处理能力,但不具备MIG等一些较新的功能。
超微SYS-522GA-NRT,这是一款支持8块RTX PRO 6000 Blackwell服务器版GPU的RTX PRO服务器。在该平台内部,配备了两个PCIe交换机、两颗CPU、32个DDR5 DIMM插槽,以及可安装多块网卡和SSD的空间。

功耗因配置差异很大,但这些平台的优势在于其功耗通常低于SXM系统,从而降低了运营成本。采购成本也通常低于基于SXM的系统。
2025年的新变化是用于8卡PCIe GPU服务器的新型NVIDIA MGX PCIe交换板卡搭配NVIDIA ConnectX-8 SuperNIC。这是超微在其SYS-422GL-NR服务器中采用的一项重大平台变革。

新平台不再使用两个或四个大型交换机,而是利用ConnectX-8 SuperNIC及其内置的交换机为GPU提供高速网络连接。这是该平台多年来最重大的变革。

配备 PCIe GPU 的标准服务器
虽然8卡平台主要专为GPU计算设计,但AI的前景远不止于这类服务器。企业部署此类平台的一个重要原因是:如果你相信AI将融入几乎所有工作流程,那么问题就变成了如何应对它。如今部署不带GPU的服务器意味着唯一的选项是将负载转移到专门的AI服务器上。另一种模式是在传统服务器中添加GPU,以便在最适合加速的工作负载阶段使用它们。

与8卡系统类似,常用的GPU范围通常包括NVIDIA H100 NVL、H200 NVL、RTX PRO 6000 Blackwell和L40S。一个很大的区别在于,通常在2U服务器中只能并排安装两块GPU。

因此,在传统服务器中,4路NVLink远不如在每个(服务器)域中找到一块或两块GPU常见。一些用户也在部署像NVIDIA L4这样的低功耗GPU,它们提供较少的GPU算力和显存,但功耗和成本也更低。

例如超微 SYS-212GB-NR。这是超微 Hyper系列高端服务器之一,可以添加多种不同类型的GPU。其理念是,如果AI正成为你工作流的一部分(因为你运行的软件越来越多地融入AI),那么在服务器中添加一块GPU可以使AI推理保持在本地进行,这是有意义的。

配备 PCIe GPU 的高密度服务器
L4用途广泛,因为它是一款薄型(low-profile)GPU,冷却需求极低。多年来,我们看到SuperBlade和其他高密度超微平台能够容纳各种GPU,从单槽薄型GPU到双槽GPU。其设计理由通常与标准服务器相同,只是采用了更高密度的设计。

配备 PCIe GPU 的边缘服务器
边缘服务器带来了不同的机遇。计算机视觉等应用在边缘端正变得越来越普遍。一个很好的例子是许多零售场所的自助结账系统,它们由配备GPU的边缘服务器驱动。零售业的其他典型应用还包括库存分析、顾客分析等。
这些服务器通常受到严格的功耗和空间限制,因此采用75W TDP或更低功耗的单槽薄型GPU是首选方案。

除了L4 GPU,在从网络基础设施到智慧城市的其他边缘用例中,也可能使用更大的GPU,通常搭配更高端的网络设备。
配备 PCIe GPU 的工作站
在工作站领域,AI时代使其成为热门话题。人们希望本地开发AI工具。也许更大的转变将是,随着AI成为日常工作中越来越重要的一部分,配备更强大的GPU可以带来显著的生产力提升。

当NVIDIA推出RTX 6000 PRO Blackwell时,有三个版本。一个是600W版本,旨在单个PCIe插槽中提供最大性能。另外两个是双槽卡:一个是300W主动散热版本;另一个是我们常在8卡系统中看到的被动散热版本。
最近我们评测了超微 AS-2115HV-TNRT,这是一款2U服务器,可容纳多达四块双槽GPU。其创新之处在于,市场上大多数其他工作站,即使可以转换为4U或5U工作站,也最多只能容纳三块GPU。而使用该系统,我们可以在配备IPMI管理功能的同时,将多达四块GPU装入系统,然后将其放入数据中心机架中。

超微还有其他选项,例如AS-531AW-TC和SYS-532AW-C,它们设计用于容纳单块600W的NVIDIA RTX PRO 6000或多块300W版本(如Max-Q版)。
结语
AI 的浪潮远非仅局限于巨型 AI 工厂。随着 AI 深度融入各类工作流,低延迟需求、数据主权考量、工作流整合以及部署灵活性正强力驱动 GPU 算力向更广泛的领域扩散——从企业数据中心的标准与高密服务器,到空间与功耗受限的边缘节点,再到开发者的本地工作站。

展望未来,GPU 形态、互连技术与应用场景将持续演进。但核心趋势已然明晰:AI 算力正成为普适性基础设施的关键组件,其部署范式正从集中走向分布式,深入企业乃至边缘的每一个环节。 我们致力于提供当前最优的 GPU 选项与平台方案,助力客户构建面向未来的敏捷 AI 能力。




评论前必须登录!
注册