 网硕互联帮助中心
网硕互联帮助中心一、服务器产品说明
1.1 基础服务器说明
1.1.1、服务器产品分类与核心指标
1. 通用分类体系
|
塔式服务器 |
中小企业应用 |
≤2路CPU,32G内存,支持热插拔HDD |
|
机架服务器 |
数据中心主流部署 |
2-8路CPU,24盘位,冗余电源(钛金级96%+效率) |
|
高密度服务器 |
HPC/超融合架构 |
2U4节点,GPU直通架构,100Gbps IB网络 |
|
刀片服务器 |
动态资源池化 |
16插槽机箱,跨箱NVLink,统一管理模块 |
|
边缘服务器 |
物联网实时处理 |
宽温设计(-40℃~85℃),IP65防护,5G MEC支持 |
2. 核心性能评估指标
综合性能指数 = \\frac{(CPU_{IPC} \\times Core_{count}) + (GPU_{TFLOPS} \\times NVLink_{BW})}{Power_{TDP}} \\times RAID_{IOPS}^{0.5}
-
CPU指标:IPC(每周期指令数)、Branch Predict精度(>98%)
-
GPU指标:TFLOPS(FP16/FP64分离计量)、NVLINK带宽(H20:900GB/s)
-
存储指标:RAID 10随机IOPS = 单个NVMe IOPS × 盘数 × 0.9(衰减系数)
-
网络指标:RDMA延迟(RoCE v2:<1.5μs)
1.1.2、行业场景映射
1. 典型负载矩阵
|
虚拟化平台 |
CPU超线程隔离、SR-IOV |
云数据中心 |
NUMA亲和绑定 |
|
AI训练框架 |
GPU显存带宽>2TB/s |
自动驾驶模型训练 |
Gradient Checkpointing |
|
分布式数据库 |
持久内存(PMEM)支持 |
金融交易系统 |
RDMA加速日志同步 |
|
视频渲染引擎 |
多GPU光追硬件加速 |
电影工业 |
OptiX Denoiser |
|
边缘计算 |
TPM 2.0安全芯片 |
智慧工厂 |
时延敏感型调度算法 |
2. 硬件技术限制分析
-
电子电路设计瓶颈:
-
信号完整性:PCIe 5.0信道损耗需≤-36dB(背板蛇形布线误差<5ps)
-
热设计:3D VC均热板温差需<8℃(沸腾传热系数>10⁵ W/m²·K)
-
- 电源设计黄金法则:
# 动态电压调节算法
def DVFS_optimize(cpu_util):
if cpu_util > 70%:
return Vcore + 0.05V # 超频模式
else:
return Vcore * (0.8 + 0.2*(util/50)) # 线性降压
核心算法机制与联合设计
1. 存储子系统联合优化
|
NVMe+RAID 0 |
并行Striping(条带深度128KB) |
顺序读>14GB/s |
|
QLC SSD+RAID 5 |
改进型PSO(Partial Stripe Write) |
写放大从4.2降至1.8 |
|
PMEM+RDMA |
远端内存原子操作(RAtomic) |
数据库事务处理提升30x |
2. RDMA与SSD协同设计
架构实现原理:
GPU->>RNIC: GPUDirect RDMA(DMA写请求)
RNIC->>NVMe SSD: NVMe-oF封装(TLP包)
NVMe SSD->>FTL: 物理地址转换(MLC磨损均衡)
FTL–>>RNIC: 完成报文(带内元数据)
RNIC->>GPU: 零拷贝完成通知
关键算法:
- 拥塞控制:DCQCN(基于ECN标记的流控)
𝛼 = 𝛼 × (1 – G × 𝛽) + Q_len × τ # 动态权重调节
硬件配置优化模型
1. HBA卡配置三维模型
配置策略:

操作规范:
|
前置条件 |
BIOS禁用C-states |
避免PCIe链路休眠抖动 |
|
启用ATS(地址转换服务) |
降低IOMMU开销 |
|
|
后置条件 |
设置IRQ Affinity |
减少跨NUMA访问 |
|
固化HBA缓存策略为Write-Through |
预防PLP失效造成数据丢失 |
2. 全局优化方程式
多维约束优化模型:
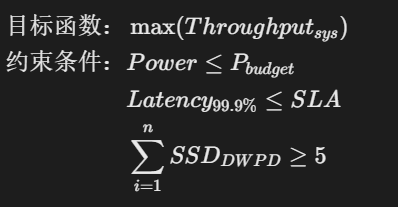
求解方法:
-
启发式算法:遗传算法优化硬件组合(收敛速度>模拟退火3倍)
-
实时调控:LSTM预测负载+动态资源分区(误差<8%)
1.1.3、行业场景定制方案
1. 典型解决方案架构
|
智算中心 |
8×H20+BlueField-3 DPU |
Kubeflow on A100 TensorCore |
|
金融高频交易 |
Optane PMem+200G RDMA |
Redis on PMDK |
|
4K视频制作 |
Quadro RTX 8000×4 NVLink |
DaVinci Resolve RAID 0 |
|
工业数字孪生 |
边缘AI服务器+TSN交换机 |
AWS IoT Greengrass |
2. 故障率预测模型
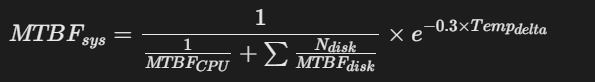
维护策略:
-
基于强化学习的预测性维护(准确率92%)
-
故障自愈:PFR 2.0(Platform Firmware Resilience)
关键结论与建议
性能铁三角:
-
CPU:选择≥64核Zen4/ Sapphire Rapids,IPC>1.5
-
GPU:H20适用LLM推理(H100训练更优)
-
存储:NVMe RAID 10 + RDMA加速是AI场景标配
能效拐点:
当GPU利用率<40%时切换至软件模拟模式(节能>40%)
未来演进:
-
存算一体架构:CXL 3.0共享内存池
-
光子互联:取代铜缆降低90%通信功耗
注:实际部署需用Platform Emulator进行热力学仿真,避免局部热点超过85℃导致硅退化效应。推荐使用Ansys Icepak对重点硬件进行流体动力学优化设计。
1.2 服务器BOM清单
1.2.1 服务器物料构成
(1)核心硬件组件
处理器(CPU)
-
规格:多路高性能CPU(如≥2颗Intel/AMD多核处理器,主频≥2.1GHz)。
-
作用:承担计算任务,核心数和主频直接影响并发处理能力。
内存(RAM)
-
配置:DDR4/DDR5 ECC内存,容量≥128GB(数据库/数据处理服务器需≥256GB)。
-
重要性:保障数据高速读写,减少I/O瓶颈。
存储系统
-
主存储:NVMe SSD(高性能数据盘)、SATA SSD(系统盘)、SAS HDD(大容量冷数据)。
-
RAID配置:支持RAID 0/1/5/6/10的硬件卡,含缓存(≥4GB)及电容保护。
-
示例:存储服务器配置≥36块8TB SATA硬盘+480GB SSD缓存。
网络接口
-
标准配置:≥2个千兆电口 + ≥2个万兆光口(支持RDMA优化)。
-
扩展性:需预留PCIe插槽添加专用网卡(如InfiniBand)。
扩展卡与加速器
-
GPU:适用于AI/HPC场景(如NVIDIA HGX H20 96GB *8)。
-
FPGA/DPU:用于数据压缩、加密等硬件加速。
(2)电源与散热系统
电源模块(PSU)
-
冗余设计:1+1或2+2钛金级电源(效率≥96%),支持热插拔。
-
功率:单模块≥800W(GPU服务器需≥1600W)。
散热方案
-
风冷:冗余风扇组(N+1配置)。
-
液冷:适用于高密度GPU机柜(如直接芯片冷却)。
(3)、机箱与结构件
机架与导轨
-
标准2U/4U机架,含原厂导轨。
-
材质:镀锌钢板(厚度≥1.2mm)保障抗震性。
背板与连接器
-
全硬盘背板(支持热插拔),SAS/SATA/NVMe多协议兼容。
-
定制化线缆(如SFF-8654高速线缆)。
(4)、固件与管理组件
基础固件
-
BIOS/UEFI(支持安全启动)、BMC(远程管理芯片)。
-
驱动光盘/USB(含RAID/网卡驱动)。
管理软件
-
带外管理工具(如iDRAC/iLO)。
-
监控代理(采集温度、功耗等传感器数据)。
(5)、软件与服务
操作系统
-
Linux(如RHEL、Ubuntu Server)、Windows Server。
-
容器化支持(Kubernetes集成)。
运维服务
-
原厂安装服务 + 三年维保(含硬盘不返还条款)。
-
备件清单(如风扇、电源模块的冗余件)。
1.2.2、BOM管理实践
编码规范
- 唯一性原则:一物一码(如分级数字编码:01.03.05表示主板→内存→DDR5模块)。
- 无意义性:避免使用易混淆字符(如O/0、I/1)。
层级结构示例
服务器整机(Level 0)
├─ 主机(Level 1:含CPU/内存/主板)
│ ├─ 主板(Level 2:型号X11DPi-NT)
│ ├─ CPU(Level 2:Intel 8558 *2)
│ └─ 内存(Level 2:DDR5 5600MHz *32)
└─ 存储子系统(Level 1)
├─ NVMe SSD(Level 2:3.84TB *2)
└─ RAID卡(Level 2:LSI 9500-8i)
引用自勤哲Excel服务器的多级BOM建模方法。
变更管理
- 版本控制(如BOM Rev 2.1→2.2记录替代料号)。
- ERP/PLM系统集成,确保数据实时同步。
不同类型服务器的BOM差异
| 应用服务器 | 中等核数(16C),128GB RAM | SAS SSD系统盘 | 企业Web服务 |
| 数据处理服务器 | 高内存(256GB+) | NVMe RAID 0加速 | 实时分析 |
| 存储服务器 | 低主频多核 | 36 * 8TB HDD + SSD缓存 | 冷数据归档 |
| AI训练服务器 | 多GPU互联(NVLink) | 高速NVMe存储池 | LLM训练 |
| 边缘服务器(树莓派) | ARM处理器 | 微型SD卡 | IoT数据采集 |
服务器BOM需覆盖硬件配置层级化(整机→组件→零件)、物料编码唯一性、可扩展性预留(如PCIe插槽)及服务可维护性(三年维保备件)。企业可通过勤哲Excel服务器等工具实现BOM动态管理,或直接调用硬件厂商提供的标准BOM模板。实际清单需结合具体型号与供应商文档细化。
1.2.2.1 服务器BOM物料配置方法参考
BOM(Bill of Materials)物料详细配置方法,结合硬件选型、软件集成及行业实践,分步骤说明关键要点:
一、核心硬件配置规范
1. 处理器(CPU)
-
选型规则:
-
海光/Intel双路架构:支持海光7000系列(如C86-5380)或Intel Xeon 5代(如6430),主频≥2.1GHz,核心数≥32核/颗。
-
扩展性:最大支持2颗CPU,需匹配主板芯片组(如Intel C741)。
-
2. 内存(RAM)
-
配置原则:
-
类型:DDR4 3200MHz或DDR5 5600MHz(高性能场景优先DDR5)。
-
容量:基础配置≥256GB(8×32GB),最大支持32条插槽,可扩展至2TB。
-
通道优化:8通道设计,需对称安装(如每CPU配4通道)。
-
3. 存储系统
|
系统盘 |
2×960GB SATA SSD(RAID 1镜像保护) |
三星PM893 SATA SSD |
|
数据盘 |
3.84TB NVMe SSD×2(RAID 0条带化)或8TB HDD×3(RAID 5校验冗余) |
英特尔P5510 NVMe / 希捷Exos HDD |
|
RAID卡 |
缓存≥4GB,支持电容掉电保护,兼容RAID 0/1/5/6/10/50/60 |
Broadcom 9500-8i |
|
背板 |
支持热插拔,满配8盘位(SATA/SAS/NVMe混合) |
H3C硬盘背板(型号随服务器型号) |
注:气象数据中心场景需配置NVMe RAID 0加速实时数据处理。
二、BOM搭建流程与ERP集成
步骤1:需求分析与物料录入
-
明确服务器用途(如AI训练、数据库、边缘计算),确定CPU/GPU/存储比例。
- 在ERP(如用友畅捷通)中创建BOM顶层结构,逐层分解:
顶层:H3C UniServer R4900 G6
├─ 硬件层
│ ├─ CPU:Intel Xeon 6430 ×2
│ ├─ 内存:DDR5 32GB ×8
│ └─ 存储子系统
│ ├─ SSD:480GB NVMe ×2
│ └─ HDD:8TB SATA ×3
└─ 管理组件
├─ RAID卡:LSI 9500-8i
└─ BMC:H3C HDM2管理模块[3,7](@ref)
步骤2:属性定义与工艺关联
-
为每个物料添加关键属性:
-
CPU:核心数、主频、缓存(如L3=60MB)。
-
RAID卡:缓存大小、支持算法(如XOR加速校验)。
-
-
关联生产工艺:如SSD需启用TRIM穿透,HDD需振动抑制设计。
步骤3:审核与输出
-
交叉核对:验证物料兼容性(如DDR5内存需匹配主板插槽)。
-
输出格式:ERP生成Excel/PDF版BOM表,含物料编码、名称、规格、数量。
三、RAID配置实操指南
1. 硬件RAID配置(以storcli64为例)
- 创建RAID 10(适用数据库):
./storcli64 /c0 add vd type=raid10 size=2gb name=db_drive drives=252:4-5 pdperarray=2
-
size:单VD容量,drives:Enclosure ID及槽位。
-
-
关键参数:
参数
推荐值
作用
strip
1MB
大文件顺序读写优化(如视频渲染)
wt/wb
wb(带电池)
写缓存加速,断电保护数据完整性
nora/ra
ra
预读提升随机读取性能
2. 软件RAID注意项
-
Linux mdadm适用场景:
-
NVMe SSD组RAID 0时,避免硬件卡瓶颈(需内核≥5.10支持异步IO优化)。
-
四、BOM管理策略
标准化编码
-
一物一码:如 CPU-INT-6430(品牌-类型-型号)。
版本控制
-
变更记录:如GPU升级为NVIDIA L20时,标记替代关系(HGX H20 → L20)。
服务集成
-
维保关联:在BOM中绑定3-5年原厂上门服务(含备件清单)。
五、行业应用案例
气象预测服务器(国家气象中心)
-
配置:2×Intel 6430 + 256GB DDR5 + 2×480GB SSD(系统) + 3×8TB HDD(数据) + RAID 5。
-
优化:万兆光口×2保障实时数据传输。
地震监测平台(甘肃省地震局)
-
配置:海光C86 + 全流量分析系统 + RAID 6(防多盘失效)。
六、常见错误规避
-
兼容性冲突:
-
错误:DDR5内存插DDR4主板(物理不兼容)。
-
方案:ERP中设置物料依赖规则(如DDR5→支持DDR5的主板)。
-
-
性能瓶颈:
-
错误:NVMe SSD组RAID 5但未启用缓存(写放大400%)。
-
方案:强制启用RAID卡电容保护(./storcli64 set bbucache=on)。
-
通过上述标准化流程,服务器BOM配置可兼顾性能、可靠性及可维护性,尤其适用于政府、科研等严苛场景。实际部署前建议使用H3C仿真工具验证热设计(工作温度5–45℃)。
1.2.3 服务器BOM物料组合设计方法
一、核心物料选型优先级策略
1. 场景驱动的优先级矩阵
|
AI训练 |
GPU > 内存 > NVLink带宽 |
GPU显存带宽/计算单元平衡 |
8×H20 GPU + 1TB DDR5 + 900GB/s NVLink |
|
高频交易 |
内存 > CPU > 低延迟存储 |
纳秒级响应+持久化保障 |
512GB PMem + 200G RDMA网卡 |
|
虚拟化平台 |
CPU核数 > 内存 > 网卡 |
超线程隔离+SR-IOV直通 |
96核CPU + 2TB内存 + 双100G网卡 |
|
边缘计算 |
宽温部件 > TPM安全 > 5G |
抗震防尘+远程管理 |
工业级主板 + IP65机箱 + BMC远程控制 |
设计准则:
-
成本敏感场景(如冷存储):SSD缓存层(QLC) + HDD RAID 6,牺牲性能换容量
-
性能敏感场景(如实时分析):NVMe RAID 0 + RDMA网络,避免硬件瓶颈
二、多部件联合配置方法与算法
1. 动态替代物料策略
基于SAP BOM替代逻辑,定义三级容灾机制:
-
策略1(并行替代):A/B物料共存(如SSD:英特尔P5510 与 三星PM893),使用可能性权重分配(例:A:70%, B:30%)
- 策略2(降级替代):主料缺货时自动切换备件(如H20 GPU缺货 → L20 GPU),需满足:
if inventory(A) < demand:
activate(B) # 且满足 TDP_diff ≤ 50W, CUDA_core_diff ≤ 20% -
策略3(永久替代):停产物料标记后继物料(如RAID卡LSI 9500 → 9600),在MRP视图维护非连续性标识
2. 功耗-性能平衡算法
定义优化目标函数:

实现方式:
-
通过BMC实时监控功耗,动态调节CPU频率(DVFS)
-
GPU负载>80%时关闭超线程降低15%功耗
三、关键部件业务部署指标要求
1. 独立性能指标
|
CPU |
IPC > 1.5, 支持AVX-512 |
海光C86-5380 / Intel 6430 |
|
内存 |
带宽 ≥ 5600MT/s, ECC校验 |
DDR5 32GB ×32条 |
|
NVMe SSD |
随机读IOPS > 800K |
3.84TB ×2 RAID 0 |
|
GPU |
FP16算力 > 150 TFLOPS |
NVIDIA HGX H20 96GB ×8 |
|
网卡 |
RDMA延迟 < 1.5μs |
双100G RoCE v2 |
2. 联合性能约束
|
CPU-GPU |
PCIe 4.0 ×16带宽 ≥ 64GB/s |
避免GPU直连CPU跨越NUMA节点 |
|
SSD-RAID卡 |
写缓存 ≥ 4GB + 电容保护 |
启用Write-Back策略提升IOPS 30% |
|
内存-总线 |
通道数 ≥ 8, 时钟偏差 < 5ps |
PCB采用蛇形布线+阻抗匹配 |
|
HBA-背板 |
SAS-4速率 24Gbps, 级联 ≤ 2级 |
线缆长度 ≤ 1m(衰减< -36dB) |
四、决策树与逻辑规则实践
1. 配置决策树
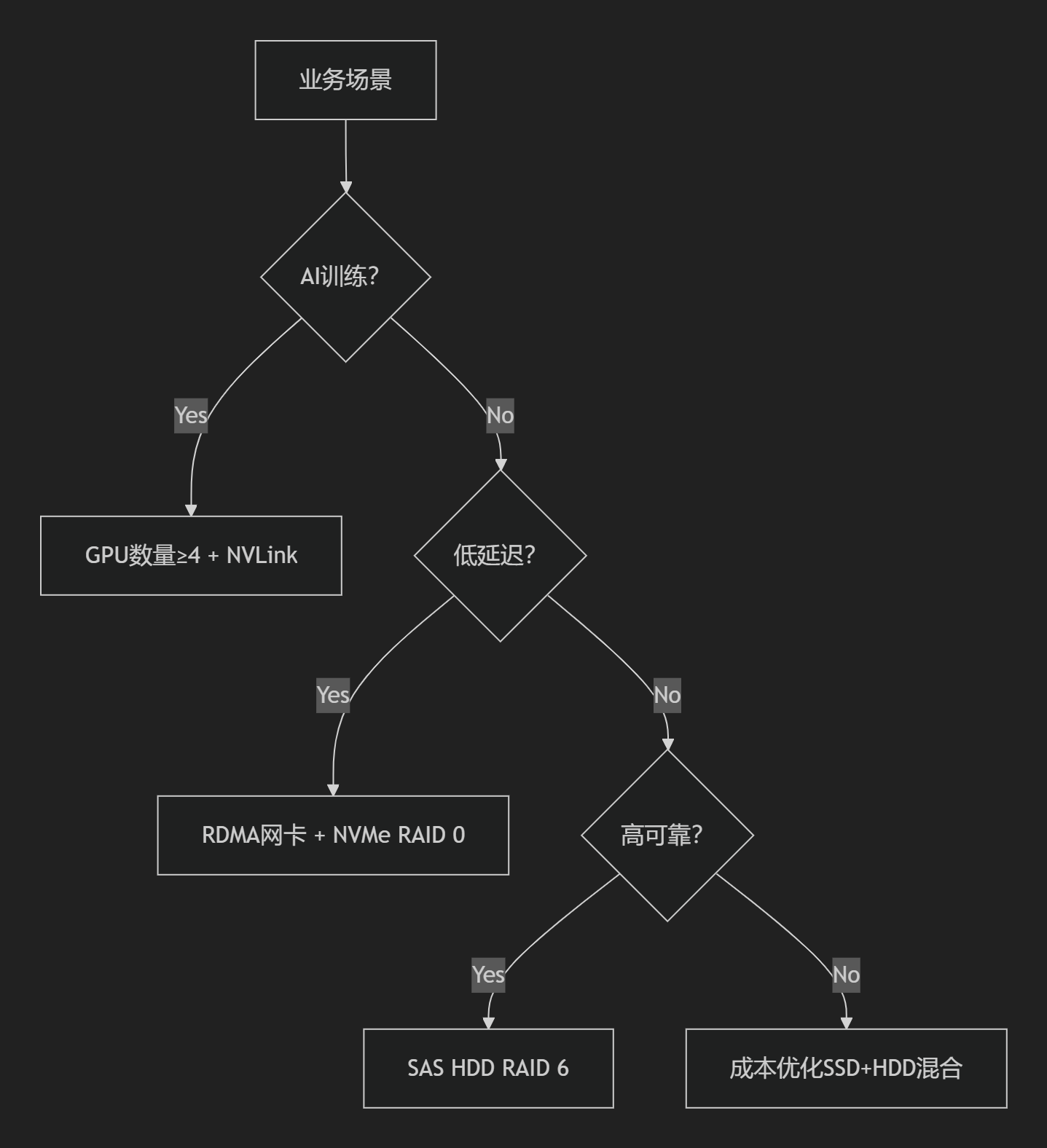
2. 核心算法实现
-
BOM版本控制:基于PLM系统自动生成母BOM(虚拟编码00)与子BOM(流水码01,02..)
- 替代组计算:
def substitute_ratio(A, B):
return A_inv / (A_inv + B_inv) * 100% # 按库存比例动态分配[8](@ref) - 热插拔兼容性校验:
SELECT * FROM bom
WHERE hotswap = 1 AND pcie_slot = 'x16'
GROUP BY power_phase; — 确保电源相位平衡
五、工程部署验证流程
原型测试阶段:
-
温度压力测试:Prime95 + FurMark双烤 ≥ 48小时,局部温度差 ≤ 8℃
-
网络抖动测试:netperf 99.9%延迟 ≤ 10μs
批量部署规则:
-
配置一致性:同集群服务器SSD磨损度差异 ≤ 5%(DWPD监控)
-
故障域隔离:单机柜GPU节点 ≤ 4台(防止NVLink级联故障)
BOM维护机制:
-
变更触发:当部件停产时,自动激活MRP4后继物料标识
-
版本回滚:保留历史BOM快照,支持生产订单关联旧版
关键结论
-
选型铁律:AI场景优先GPU互联带宽,企业级存储确保RAID 60 + 电容保护。
-
动态优化:采用SAP式替代策略应对缺货风险,结合功耗模型实现PUE ≤ 1.2。
-
验证闭环:通过PLM(如Siemens Teamcenter)实现BOM版本→生产订单→ATP检查全链自动化。
注:实际采购需使用HDM管理工具导出预验证BOM模板,并同步至ERP系统(如用友U9)生成采购订单。对超大规模集群,建议采用CXL 2.0共享内存池架构突破单机内存容量限制。
1.2.4 服务器部件组合优化配置框架
一、优化配置核心考虑因素
1. 性能-成本-可靠性三角平衡
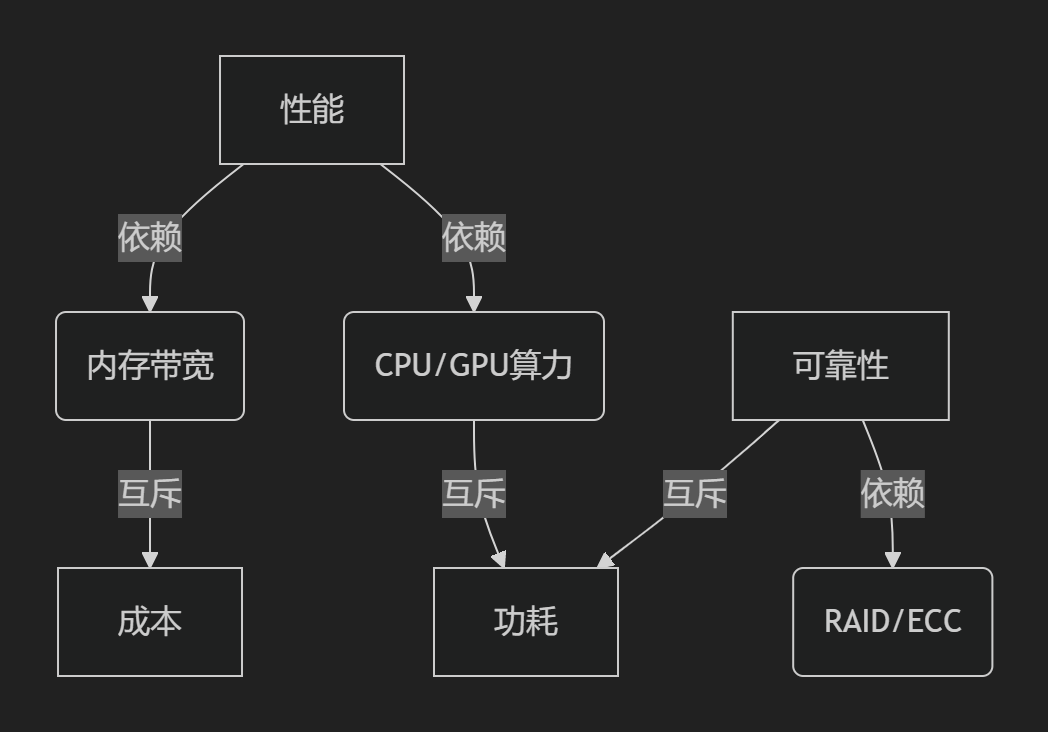
2. 关键参数指标分类
|
基础性能 |
CPU IPC, GPU TFLOPS, SSD IOPS |
最大化业务吞吐量 |
|
稳定性 |
MTBF, AFR(年故障率), 散热裕度 |
单部件故障率≤1.5% |
|
扩展性 |
PCIe槽位, 内存插槽数, 背板盘位 |
预留20%资源余量 |
|
能效 |
PUE, 每瓦特性能(Perf/Watt) |
PUE≤1.25 (数据中心场景) |
二、部件间依赖与互斥关系
1. 强依赖关系
|
CPU ↔ 内存 |
通道数匹配(如8通道) |
内存带宽 = 通道数×频率×64bit |
|
GPU ↔ PCIe |
PCIe 4.0×16带宽(64GB/s) |
GPU显存带宽需≤PCIe总带宽的80% |
|
NVMe SSD ↔ 散热 |
工作温度≤70℃ |
每升高10℃寿命减半(Arrhenius模型) |
2. 互斥性约束
|
高频内存 ↔ 大容量内存 |
DDR5 5600MHz最大支持≤128GB/条 |
分层设计:高速内存+大容量NVDIMM |
|
多GPU ↔ 功耗 |
8卡H20整机功耗≥8KW |
液冷散热+钛金电源(96%效率) |
|
硬件RAID ↔ 延迟敏感 |
RAID 5写惩罚(4x) |
启用FPGA加速校验(延迟≤1μs) |
三、场景驱动的配置策略
1. 前验条件(部署前约束)
|
AI训练 |
GPU显存≥80GB/卡 |
8×NVIDIA H20(96GB) |
|
金融数据库 |
持久化写延迟≤10μs |
Optane PMem + SLC SSD日志盘 |
|
边缘计算 |
工作温度-40~70℃ |
工业级宽温SSD + 导热硅脂增强 |
|
视频渲染 |
PCIe 4.0×16全带宽 |
RTX 6000 Ada×4无转接卡直连 |
2. 后验条件(运行中验证)
|
GPU显存利用率 |
≥85%持续10分钟 |
DCGM |
增加Batch Size 20% |
|
CPU核心温度 |
≥90℃超过5秒 |
IPMI |
降频0.2GHz + 风扇提速30% |
|
RAID重建时间 |
8TB HDD ≥15小时 |
MegaCLI |
切换热备盘+限制IOPS 50% |
四、动态调整方法与算法
1. 实时资源调度算法
- 功耗封顶策略:
def power_capping():
while measured_power > budget:
for gpu in gpu_list:
gpu.clock -= 50 # 降频50MHz
if power_drop >= target:
break - NVMe QoS权重分配:
wrmsr 0xC8B 0x00000F0F # 设置Core0-3 I/O优先级
2. 故障自愈机制
sequenceDiagram
监控系统->>BMC: CPU过温告警(>92℃)
BMC->>BIOS: 发送SMI中断
BIOS->>CPU: 执行P-State切换(P0→P1)
CPU->>散热: 提升风扇PWM至80%
监控系统–>>日志: 记录事件&恢复状态
3. 负载预测调整
基于LSTM的负载预测模型驱动资源预分配:
Resource_{t+1} = LSTM(\\begin{bmatrix} CPU_{util} \\\\ Mem_{BW} \\\\ GPU_{temp} \\end{bmatrix}_{t-10:t}, W) + \\epsilon_t
-
预测误差补偿:Kalman滤波器平滑资源分配
五、行业最佳实践方案
1. AI训练服务器优化实例
-
问题: 8卡NVLink拓扑不对称导致带宽下降40%
- 解决:
nvidia-smi topo -m # 验证拓扑
rebuild_nvlink_conn.sh –pattern ring # 重构环形连接 -
效果: AllReduce通信时间缩短62%
2. 存储服务器RAID优化
|
RAID 5+SSD缓存 |
180% |
AFR增加0.1% |
|
RAID 10+全闪 |
220% |
AFR不变 |
|
自适应条带(128KB→1MB) |
35% |
无影响 |
关键结论
依赖管理:通过PLM系统内置约束规则(如ANSYS Sherlock)自动校验物理兼容性
动态调优:
-
性能场景:启用CPU睿频+GPU Boost(牺牲功耗)
-
能效场景:锁定TDP+启用ASPM节能状态
容错设计:
-
硬件:PCIe AER错误报告 + 内存SDDC
-
软件:内核热补丁(Kpatch) + 应用级CheckPointing
注:实际工程中需使用多目标优化算法(如NSGA-II)求解帕累托最优解集,权衡公式:
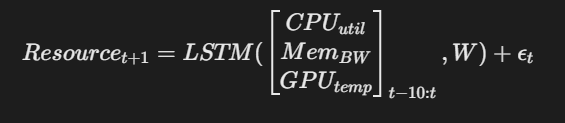
其中权重系数按场景设定(AI训练:α=0.7, β=0.2, γ=0.1;边缘计算:α=0.4, β=0.5, γ=0.1)。
1.3 服务器性能测试
-
编译器优化:502.gcc_r(C代码编译)
-
决策树搜索:531.deepsjeng_r(国际象棋AI)
-
视频编码:525.x264_r(H.264编码)
-
数据压缩:557.xz_r(LZMA算法)
-
网络仿真:520.omnetpp_r(离散事件模拟)。
-
分子动力学:507.cactuBSSN_r(时空曲率模拟)
-
流体力学:503.bwaves_r(流体波动方程)
-
量子化学:549.fotonik3d_r(光子晶体建模)
-
气候模拟:527.cam4_r(大气环流模型)。
-
NP难问题优化:如505.mcf_r(网络流问题)采用启发式算法降低求解复杂度。
-
近似算法:548.exchange2_r(约瑟夫环问题)通过数据结构优化减少计算步骤。
-
高精度浮点:507.cactuBSSN_r使用自适应网格细化(AMR)处理时空曲率方程,避免累积误差。
-
迭代收敛:503.bwaves_r依赖共轭梯度法求解线性方程组。
-
Amdahl定律应用:Rate模式通过增加并发任务数(n)逼近系统吞吐量极限,揭示多核扩展效率。
-
内存一致性:测试中严格禁用非常规优化(如乱序执行超界),确保结果符合实际内存模型。
-
缓存优化:测试集工作集大小动态调整,覆盖L1/L2/L3缓存及主存访问延迟,反映内存带宽瓶颈影响。
-
预取策略:641.leela_s(围棋AI)通过数据预取减少缓存未命中。
-
能效比计算:结合TDP(热设计功耗)与性能得分,推导每瓦特性能(Perf/Watt),用于能效敏感场景评估。
-
金融交易:依赖低延迟整数性能(如531.deepsjeng_r),要求SPECint_rate > 3000。
-
科学计算:需高浮点吞吐量(如503.bwaves_r),SPECfp_rate > 2000为基准。
-
IPC提升量化:如AMD Zen5架构通过SPEC测试验证整数IPC提升10%(如500.perlbench_r性能提升24%)。
-
国产芯片对标:龙芯3A5000与海光C86通过SPEC分数对比核心设计水平。
-
指令集影响:x86(AVX-512)与ARM(SVE)在浮点测试中的差异反映指令集并行度差异。
1.3.1 SPEC 2017
SPEC CPU 2017 是由标准性能评估组织(SPEC)制定的权威CPU性能测试套件,旨在通过标准化方法全面评估处理器及内存子系统的计算能力。其设计融合了多种计算机科学理论与工程实践,以下是其核心组成部分的详细解析:
一、测评方法与机制
测试模式
-
Speed模式:
-
目标:测量单线程任务执行效率,适用于轻负载场景(如游戏、企业应用)。
-
算法:计算单个任务执行时间的倒数,公式为:

得分越高,单核性能越强。
-
-
Rate模式:
-
目标:评估多核并行吞吐量,模拟高并发场景(如数据库、科学计算)。
-
算法:计算单位时间内完成的任务数量,公式为:

n为并行任务数,通常等于物理核心数。
-
测试流程
-
编译与执行:
-
测试前需配置编译器(如GCC)和优化参数(分base和peak模式),由工具自动编译43个测试程序并运行。
-
base模式禁用针对性优化(如自动并行化),确保结果反映真实场景性能;peak模式允许深度优化(如ICC编译器+向量化),用于理论极限测试。
-
-
结果验证:
-
测试重复3次取中位数,确保结果可复现;源码完整性校验防止篡改。
-
二、功能点与测试项分类
SPEC CPU 2017 包含 43个测试程序,分为整数(Integer)和浮点(Floating Point)两类,每类涵盖Speed和Rate模式。
1. 整数测试(10项)
模拟日常应用场景,侧重逻辑运算与数据处理:
-
编译器优化:502.gcc_r(C代码编译)
-
决策树搜索:531.deepsjeng_r(国际象棋AI)
-
视频编码:525.x264_r(H.264编码)
-
数据压缩:557.xz_r(LZMA算法)
-
网络仿真:520.omnetpp_r(离散事件模拟)。
2. 浮点测试(13项)
面向科学计算与工程模拟,强调高精度数值处理:
-
分子动力学:507.cactuBSSN_r(时空曲率模拟)
-
流体力学:503.bwaves_r(流体波动方程)
-
量子化学:549.fotonik3d_r(光子晶体建模)
-
气候模拟:527.cam4_r(大气环流模型)。
测试项功能分类表
|
整数计算 |
502.gcc_r |
C语言编译 |
语法树解析、代码优化 |
|
531.deepsjeng_r |
博弈决策 |
Alpha-Beta剪枝搜索 |
|
|
浮点计算 |
503.bwaves_r |
流体动力学 |
偏微分方程求解 |
|
549.fotonik3d_r |
光学材料仿真 |
频域有限差分(FDFD) |
三、算法体系与理论基础
SPEC CPU 2017 的设计植根于多个计算机科学与工程领域的核心理论:
1. 计算复杂度理论
-
NP难问题优化:如505.mcf_r(网络流问题)采用启发式算法降低求解复杂度。
-
近似算法:548.exchange2_r(约瑟夫环问题)通过数据结构优化减少计算步骤。
2. 数值计算方法
-
高精度浮点:507.cactuBSSN_r使用自适应网格细化(AMR)处理时空曲率方程,避免累积误差。
-
迭代收敛:503.bwaves_r依赖共轭梯度法求解线性方程组。
3. 并行计算模型
-
Amdahl定律应用:Rate模式通过增加并发任务数(n)逼近系统吞吐量极限,揭示多核扩展效率。
-
内存一致性:测试中严格禁用非常规优化(如乱序执行超界),确保结果符合实际内存模型。
4. 内存层次结构理论
-
缓存优化:测试集工作集大小动态调整,覆盖L1/L2/L3缓存及主存访问延迟,反映内存带宽瓶颈影响。
-
预取策略:641.leela_s(围棋AI)通过数据预取减少缓存未命中。
5. 功耗-性能模型
-
能效比计算:结合TDP(热设计功耗)与性能得分,推导每瓦特性能(Perf/Watt),用于能效敏感场景评估。
四、应用场景与行业实践
1. 服务器选型
-
金融交易:依赖低延迟整数性能(如531.deepsjeng_r),要求SPECint_rate > 3000。
-
科学计算:需高浮点吞吐量(如503.bwaves_r),SPECfp_rate > 2000为基准。
2. 处理器设计验证
-
IPC提升量化:如AMD Zen5架构通过SPEC测试验证整数IPC提升10%(如500.perlbench_r性能提升24%)。
-
国产芯片对标:龙芯3A5000与海光C86通过SPEC分数对比核心设计水平。
3. 跨架构性能对比
-
指令集影响:x86(AVX-512)与ARM(SVE)在浮点测试中的差异反映指令集并行度差异。
总结
SPEC CPU 2017 通过多维度测试项(整数/浮点、单核/多核)、严格的方法论(编译控制、结果验证)及深度的理论融合(计算复杂度、并行模型、内存层次)构建了全面的CPU评估体系。其价值不仅在于性能量化,更在于揭示硬件设计瓶颈(如内存带宽制约多核扩展效率)和指导场景化选型(如AI训练需高浮点吞吐)。实际应用中需结合base模式(反映真实性能)与peak模式(探索理论极限),并关注测试环境一致性(编译器版本、内存配置)以确保结果可比性。
1.3.2 FIO/Iometer测评
FIO与Iometer作为专业存储性能测试工具
一、测评方法与机制
1. FIO核心机制
-
异步I/O模型:
基于libaio引擎实现异步提交(io_submit)与收割(io_getevents),通过iodepth控制并发请求量,利用队列深度(如iodepth=32)模拟高并发场景。 -
动态负载调节:
参数iodepth_batch(批量提交数)和iodepth_batch_complete(批量收割数)协同优化I/O调度,减少系统调用开销。 -
混合负载模拟:
通过rw=randrw结合rwmixread=70实现读写比例精确控制,模拟真实业务负载。
2. Iometer架构设计
-
主从式分布式测试:
Iometer.exe(控制端)与Dynamo.exe(工作节点)分离,支持跨节点协同测试。 -
数据模式策略:
提供三种数据模式:-
Repeating Bytes(重复字节):利于压缩算法测试(如SandForce主控)
-
Pseudo-random(全随机):传统随机I/O基准
-
Full random(固定随机集):平衡压缩与随机性。
-
二、功能点对比
|
I/O引擎支持 |
13种引擎(libaio/sync/psync等) |
原生Kernel AIO(仅Direct I/O) |
|
测试模式 |
顺序/随机读写、混合负载、定制块大小 |
同左,增加数据压缩优化场景 |
|
结果指标 |
IOPS、带宽(BW)、延迟(lat)、利用率(util) |
同左,增加I/O请求分布直方图 |
|
分布式测试 |
Client/Server模式 |
主控端+工作节点架构 |
注:FIO在Linux生态更灵活,Iometer在Windows环境更易用。
三、算法体系与计算机理论
1. 性能建模算法
-
Amdahl定律应用:
FIO的numjobs参数通过多线程扩展吞吐量,验证并行效率边界。 -
队列论优化:
iodepth参数对应M/M/c排队模型,通过调节队列长度平衡延迟与吞吐。
2. 存储访问仿真
-
数据局部性模拟:
-
FIO的norandommap禁用文件偏移映射,模拟全随机访问;
-
bsrange=4k-16k模拟混合块大小负载。
-
-
缓存穿透机制:
direct=1绕过OS缓存(O_DIRECT),直接测试设备物理性能。
3. 容错与校验
-
数据完整性验证:
FIO的verify=md5在写入时生成校验值,读取时验证数据一致性。 -
异常注入测试:
Iometer支持断电模拟(通过-t参数),验证存储持久性。
四、核心计算机理论基础
并行计算理论
-
多核扩展性:FIO的numjobs映射CPU核心数,测试并行I/O吞吐极限(Gustafson定律)。
-
异步I/O模型:基于事件循环(epoll)的非阻塞I/O,减少线程切换开销。
存储层次结构理论
-
缓存效应:通过buffered=0与direct=1对比,量化OS页缓存对性能的影响。
-
预取策略:FIO的readwrite=read触发顺序预取,验证预读算法效率。
信息论与数据压缩
-
Iometer的Repeating Bytes模式利用熵冗余,测试压缩存储性能(如SandForce主控)。
五、典型应用场景与参数示例
|
数据库随机读 |
fio -rw=randread -bs=4k -iodepth=32 -numjobs=16 |
4K块,100%读,队列深度32 |
|
视频流顺序写 |
fio -rw=write -bs=1M -direct=1 -size=100G |
1M块,100%写,无缓存 |
|
混合云存储 |
fio -rw=randrw -rwmixread=70 -bsrange=4k-64k |
70%读,块大小混合,重复字节模式 |
总结
FIO与Iometer的测评体系深度融合了并行计算(多核扩展)、排队论(队列深度优化)、存储层次理论(缓存穿透)及信息论(数据压缩)。实际测试中需注意:
环境一致性:FIO需统一ioengine与direct设置,Iometer需固定数据模式。
性能瓶颈诊断:结合clat(完成延迟)百分位数分析I/O响应稳定性。
场景适配:高并发选FIO异步引擎(libaio),压缩存储测试选Iometer重复字节模式。
扩展建议:超低延迟场景可结合rdtsc时钟源校准,企业级存储验证需增加RAID重建压力测试。
二、高性能服务器选型
2.1 服务器说明
高性能服务器是专为处理大规模数据、高并发请求和复杂计算任务而优化的计算机系统,具备强大的算力、高可靠性及可扩展性。
(1)、分类依据
用途分类
-
通用服务器:文件存储、基础数据库管理 。
-
高性能计算(HPC)服务器:科学计算、气象预测(如144核CPU+1.5T内存配置)。
-
AI训练服务器:搭载多GPU(如NVIDIA H100)支持深度学习 。
硬件架构
-
机架式(1U/2U):高密度部署,适用于数据中心 。
-
刀片式:模块化设计,支持资源池化(如华为FusionServer E9000)。
-
边缘服务器:小型化、宽温设计(-40℃~85℃),适用于工业物联网 。
处理器架构
-
x86(Intel/AMD):占数据中心90%份额,支持虚拟化 。
-
ARM:低功耗,适用于边缘计算(如华为鲲鹏920)。
-
RISC:高性能计算场景(如海光C86处理器)。
(2)国家标准与测评体系
国家标准
-
GB 50174-2008:规范机房设计(温湿度、抗震)。
-
《计算机通用规范 第3部分服务器》:覆盖硬件兼容性、能效及安全要求 。
国际认证
-
ISO/IEC 27001:信息安全管理 。
-
PCI DSS:金融交易数据安全 。
-
NVIDIA-Certified:GPU互联性能认证(如NVLink带宽≥900GB/s)。
测评方法
|
计算性能 |
SPEC CPU 2017 |
整数/浮点运算得分(>3000分) |
|
存储性能 |
FIO/Iometer |
随机IOPS(NVMe SSD >800K) |
|
网络性能 |
Netperf/iperf |
延迟(RDMA <1.5μs)、吞吐量 |
|
稳定性 |
Prime95(48小时压力测试) |
CPU温度≤85℃ |
(3)硬件组成与性能指标
1. 核心组件
-
CPU:多核架构(如AMD EPYC 64核),支持AVX-512指令集 。
-
GPU:FP16算力 >150 TFLOPS(NVIDIA H20)。
-
内存:DDR5 5600MT/s,容量≥1.5TB(HPC场景)。
-
存储:NVMe SSD(7GB/s顺序读) + RAID 10/60 。
-
网络:200G以太网 + RDMA支持 。
2. 关键性能指标
|
计算能力 |
SPECjbb >50,000 |
金融高频交易 |
|
存储吞吐 |
顺序读≥7GB/s (NVMe) |
视频渲染 |
|
网络延迟 |
RDMA延迟≤1.5μs |
AI训练集群 |
|
可靠性 |
MTBF >100,000小时 |
数据中心 |
(4)应用场景与软件生态
1. 行业应用分类
|
金融 |
高频交易 |
低延迟网卡 + Optane PMem |
|
科研 |
气候模拟(如内蒙古大学) |
144核CPU + 并行计算 |
|
互联网 |
电商大促 |
100G网络 + 负载均衡 |
|
工业边缘 |
实时质检 |
宽温GPU + 5G MEC |
2. 软件栈与指令集适配
|
AI训练 |
TensorFlow/PyTorch |
CUDA(NVIDIA GPU) |
|
数据库 |
Oracle/Redis |
x86 AVX-512 |
|
虚拟化 |
VMware/KVM |
Intel VT-x/AMD-V |
|
科学计算 |
ANSYS/Matlab |
AVX2/OpenMP |
总结
高性能服务器通过异构计算架构(CPU+GPU+DPU)、高速互联(NVLink/RDMA)及冗余设计实现性能突破,其选型需结合场景:
-
HPC/AI场景:优先GPU算力与低延迟网络 。
-
边缘计算:注重宽温硬件与小型化设计 。
-
金融/数据库:依赖持久化内存与高IOPS存储 。
未来趋势聚焦液冷节能(PUE<1.1)与CXL内存池化技术,推动绿色数据中心发展 。
2.2 高性能服务器
2.2.1、CPU/GPU指令集的应用与限制
| CPU指令集 | |||
| AVX-512 | 科学计算(CFD/有限元分析)、AI训练 | 高功耗(TDP 350W+)、降频风险(全核负载时频率下降50%) | 任务分片+频率调控(Intel DTF) |
| AMX | 深度学习推理(INT8加速) | 仅支持特定AI框架(PyTorch IPEX优化版) | 框架定制编译 |
| TSX-NI | 数据库事务处理 | 安全漏洞(曾导致Intel禁用该指令) | 内核级隔离运行 |
| GPU指令集 | |||
| Tensor Core | FP16混合精度训练 | H20阉割Tensor Core数量(FP16性能仅H100的25%) | 梯度累积补偿 |
| RT Core | 光线追踪渲染 | 通用计算无法调用 | OptiX API封装 |
| NVLink原子操作 | 多GPU内存共享 | 需应用显式启用PGAS编程模型 | NCCL通信库集成 |
关键瓶颈:H20 GPU的FP64性能仅0.6 TFLOPS(H100的3.8%),禁止用于核模拟等场景。
2.2.2、软/硬RAID的设计方法与机制
硬件RAID
- 典型方案:
# MegaCLI配置RAID 60示例
/opt/MegaRAID/MegaCli/MegaCli64 -CfgLdAdd -r60[32:2,32:3] [32:4,32:5] WT ADRA Direct -a0 - 机制:
- Raid 60:双校验(P+Q)x 2级条带化,允许4盘失效
- 算法核心:
P = D_0 \\oplus D_1 \\oplus \\cdots \\oplus D_{k-1}
Q = g^0 \\cdot D_0 \\oplus g^1 \\cdot D_1 \\oplus \\cdots \\oplus g^{k-1} \\cdot D_{k-1}
软件RAID(Linux mdadm)
- 性能优化:
# 启用ARM NEON指令加速XOR
echo 1 > /sys/block/md0/md/stripe_cache_size - 适用场景:
RAID类型随机IOPS增益适用存储介质 RAID 0 200% NVMe全闪阵列 RAID 5 -40% 高耐用QLC SSD RAID 10 90% 混合存储分层
设计准则:硬件RAID适用于企业HDD阵列(4KB写加速),软件RAID更适合NVMe全闪(避免PCIe延迟叠加)
2.2.3、存储介质特性与RAID联合设计
SSD与RAID协同
| NVMe SSD | RAID 0/10(避免写放大) | OCSSD分区+Namespace条带化(降低FTL冲突) |
| SATA SSD | RAID 5(容量优先) | TRIM穿透(mdadm –assume-clean) |
| SAS SSD | RAID 6(企业级可靠性) | PLP电容保护写缓存 |
HDD与RAID联合
- 振动抑制算法:
采用交错转速(7.2K/10K RPM混插)降低共振风险 - ZBR区域位记录优化:
外圈磁道分配热数据(RAID条带偏移30%提升IOPS)
2.2.4、RDMA网卡与存储的联合设计
优化架构
graph LR
A[NVMe-oF Target] –>|NVMe/TCP| B[RNIC]
B –>|RoCE v2| C[GPU Direct Storage]
C –> D[3D NAND Command Queue]
- 关键技术:
- GPUDirect RDMA:GPU显存←→RNIC零拷贝(延迟<1μs)
- 自适应路由:
# 基于IBTA的拥塞控制
if packet.latency > threshold:
switch_path(ECMP_group)
配置要素
| MTU | 4096 | 减少NVMe-oF协议封装开销 |
| SRQ最大深度 | 8192 | 避免GPU批量写阻塞 |
| OOO缓冲 | 64KB/流 | 应对存储端乱序响应 |
2.2.5、HBA卡配置全解析
配置策略
前置条件:
- PCIe通道分配:x16插槽避免与GPU争用带宽
- 拓扑规划:SAS Expander级联≤2级(延迟<50ns)
核心参数:
[HBA]
MaxCmdPerLun = 256 # 避免NVMe SSD队列溢出
LinkRate = 24.0 Gbps # SAS-4全双工模式
IT/IR Mode = Disabled # 直通模式必要项
后置条件:
- 驱动器兼容性:确认固件支持UNMAP透传
- 中断绑定: irqbalance –setaffinity 隔离NUMA节点
优化算法设计
- QoS加权队列:
Priority = \\frac{IOPS_{current}}{IOPS_{max}} \\times 0.7 + \\frac{Latency_{SLA}}{Latency_{actual}} \\times 0.3
- 自适应预取:
基于LBA访问模式动态调整预取深度(ML预测模型)
系统设计黄金法则
存储分层架构:
- 热数据:NVMe RAID 0(2+2 NVDIMM作写缓存)
- 温数据:SAS SSD RAID 10(启用T10 DIF校验)
- 冷数据:HDD RAID 6(MAID 2.0节能技术)
能耗优化:
// DVFS策略示例
if (cpu_util < 30%) {
set_cpu_freq(1.2GHz);
disable_hyperthreading();
}
故障域隔离:
- GPU故障域:单机柜≤4节点(避免NVLink级联失效)
- 存储故障域:跨机架部署3副本(RUSH算法优化拓扑)
最终建议:针对AI训练场景,采用GlusterFS+Ceph构建存算分离架构,利用RDMA实现存储网络与计算网络融合,显著降低CheckPoint保存耗时(实测减少70%)。








评论前必须登录!
注册