 网硕互联帮助中心
网硕互联帮助中心目录
1.请详细描述 MySQL 的 B+ 树中查询数据的全过程。(难)
2.为什么 MySQL 选择使用 B+ 树作为索引结构?(中)
3.MySQL 三层 B+ 树能存多少数据?(中)
4.详细描述一条 SQL 语句在 MySQL 中的执行过程。(中)
5.MySQL 是如何实现事务的?(难)
6.MySQL 事务的二阶段提交是什么?(中)
7.MySQL 中长事务可能会导致哪些问题? (中)
8.MySQL 中的 MVCC 是什么?(难)
9.MySQL 中的事务隔离级别有哪些?(易)
10.MySQL 默认的事务隔离级别是什么?为什么选择这个级别?(易)
1.请详细描述 MySQL 的 B+ 树中查询数据的全过程。(难)
1)自顶向下定位:查询从 B+ 树的根节点开始,通过二分查找不断与节点内的有序键值进行比较,选择正确的指针向下层遍历(非叶子节点层),直到抵达包含目标数据的叶子节点层。
2)判断索引:若是主键索引,叶子节点条目直接包含完整数据行,直接读取返回。若是二级索引,叶子节点条目包含索引键值和主键值,需要根据主键值回表查询主键索引的 B+ 树来获取完整行数据。
3)范围查询:B+ 树叶子节点通过双向链表连接,范围查询只需定位到起始点,然后顺序遍历链表即可高效获取范围内所有记录。
拓展:
关于B+树:数据结构合集 – B+树_哔哩哔哩_bilibili
三阶B+树:
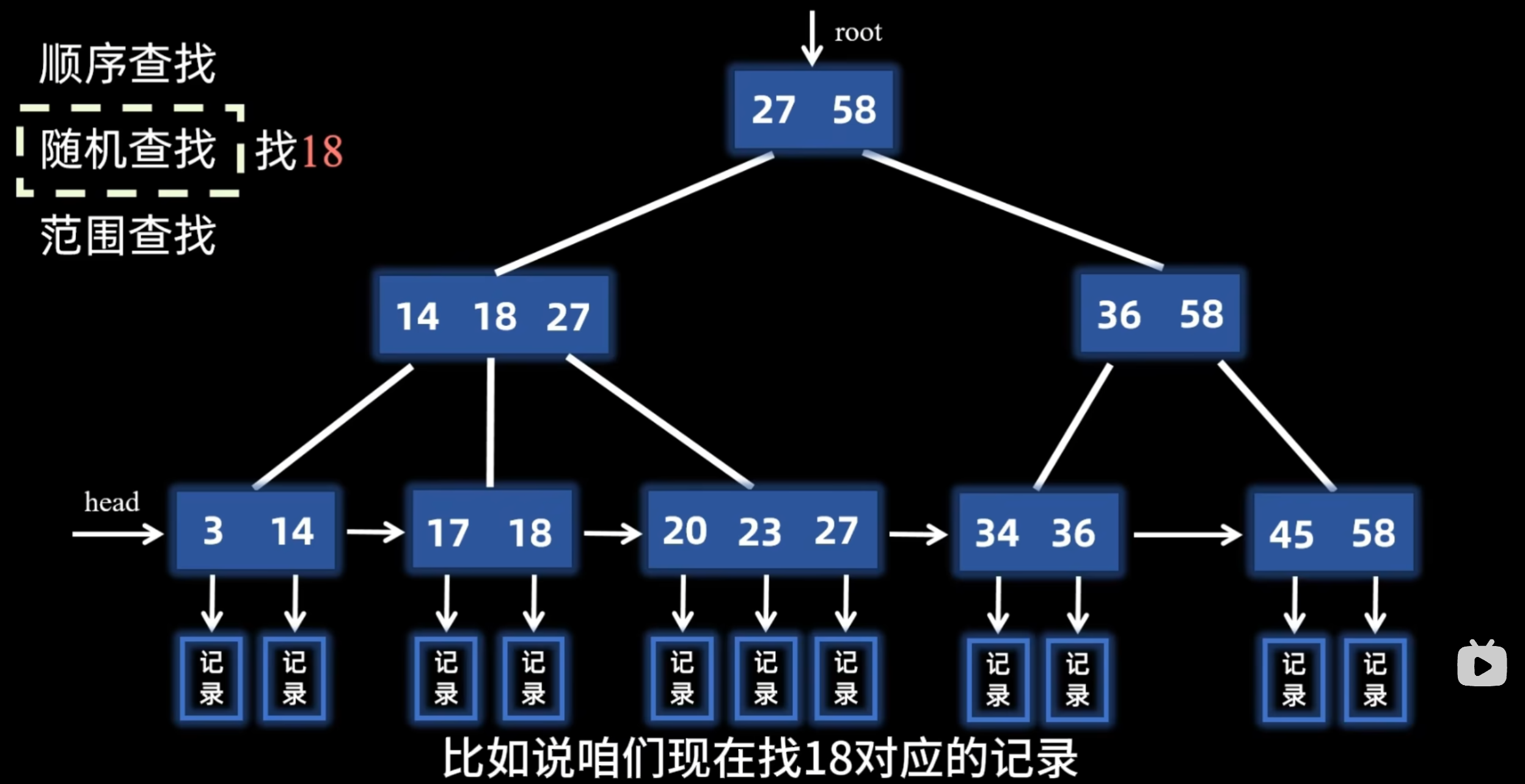
追问:为什么选择 B+ 树?
2.为什么 MySQL 选择使用 B+ 树作为索引结构?(中)
1)减少磁盘 I/O 次数:B+树是一种多路平衡树,相同数据量下,B+ 树的高度远低于二叉树(如 AVL、红黑树),3~4 层即可支撑千万级数据,查询时最多只需 3~4 次磁盘 I/O。
2)范围查询高效:B+ 树叶子节点通过双向链表连接,范围查询只需定位到起始点,然后顺序遍历链表即可高效获取范围内所有记录。
3)数据存储更集中:非叶子节点仅作索引导航,所有真实数据(或主键指针)集中存储在叶子节点。使得非叶子节点可缓存到内存,加速查询路径检索;顺序扫描全表时,直接遍历叶子节点链表,效率接近顺序 I/O。
拓展:
B+树与B树:
| 数据存储位置 | 仅叶子节点存储数据 | 所有节点均可存储数据 |
| 叶子节点结构 | 双向链表连接,支持顺序扫描 | 无链表,范围查询效率低 |
| 非叶子节点功能 | 纯索引,无数据指针 | 存储数据指针 |
| 树高与I/O | 更低(相同数据量下) | 较高 |
| 适用场景 | 范围查询、磁盘数据库索引 | 内存数据库或特定场景 |
3.MySQL 三层 B+ 树能存多少数据?(中)
MySQL 三层 B+ 树的存储量主要由页大小、主键长度和数据行大小决定。以 InnoDB 默认页大小 16KB、BIGINT 主键和 1KB 单行为例,根节点和第二层非叶子节点各存储约 1170 个指针,叶子节点每页存储约 16 行数据,三层结构总计可支撑约 2200 万行数据。
拓展:
I.详细计算(以 InnoDB 默认配置为例):
页大小:16KB(16384 字节)
主键类型:假设为 BIGINT(8 字节)
指针大小:页内指针 6 字节(InnoDB 约定)
数据行大小:假设单行 1KB(实际场景需按字段计算)

4.详细描述一条 SQL 语句在 MySQL 中的执行过程。(中)
1)连接器建立通信并验证权限。
2)解析器进行词法/语法分析生成解析树。
3)优化器基于成本模型选择最优执行计划(如索引选择)。
4)执行器调用存储引擎读写数据(通过 Buffer Pool 减少磁盘 I/O)。
5)结果集经处理后返回客户端。
拓展:

I.具体实现:
连接阶段
-
客户端与 MySQL 服务器建立连接(TCP/IP 或 socket)
-
连接器验证用户名密码及权限
-
连接成功后分配线程并检查查询缓存(MySQL 8.0 已移除)
解析与预处理
-
查询解析器进行词法分析(识别 SQL 关键词)和语法分析(生成解析树)
-
预处理器检查表/列是否存在,解析名字和别名
-
验证用户是否有相应操作权限
查询优化
-
优化器生成多种执行计划,基于成本模型选择最优方案
-
决定使用哪些索引、多表连接顺序、是否使用临时表等
-
生成执行计划并传递给执行引擎
执行阶段
-
执行引擎调用存储引擎 API
-
对于查询:通过索引检索数据(可能涉及回表)
-
对于更新:先查询后修改,记录 undo log
结果返回
-
将结果集放入网络缓冲区
-
逐步返回给客户端
-
如果是更新操作还会记录 binlog 和 redo log
5.MySQL 是如何实现事务的?(难)
MySQL 通过 InnoDB 存储引擎实现事务,核心依赖 Redo Log(重做日志)、Undo Log(回滚日志)、锁机制 和 MVCC(多版本并发控制) 四大组件协同工作,保障 ACID 特性。
1)原子性: Undo Log 记录旧版本,支持回滚; 2)持久性: Redo Log 优先写盘(WAL 机制),崩溃后重放恢复数据; 3)隔离性:
-
锁机制(行锁+间隙锁)解决写冲突与幻读;
-
MVCC 通过 ReadView 和版本链实现非阻塞读(RC/RR 级别);
4)一致性: 由前三者共同保证。
最终通过 Redo Log、Undo Log、锁、MVCC 四者协同,在性能与数据安全间取得平衡。
拓展:
I.事务执行全流程:
1)原子性(Atomicity)
-
Undo Log 实现回滚: 执行 INSERT/UPDATE/DELETE 前,先将数据旧版本写入 Undo Log。若事务失败,利用 Undo Log 反向操作恢复数据。
-
两阶段提交(2PC): 跨多个引擎的事务(如 InnoDB + binlog)通过 2PC 保证原子性(如 XA PREPARE → XA COMMIT)。
2)持久性(Durability)
-
Redo Log 优先写盘(WAL 机制): 数据修改前,先写 Redo Log 到磁盘(顺序写,性能高)。即使崩溃,重启后通过 Redo Log 重放恢复数据。
-
刷盘策略:
-
innodb_flush_log_at_trx_commit=1:每次提交刷盘(强一致)
-
=0/2:异步刷盘(高性能,有丢数据风险)
-
3)隔离性(Isolation)
-
锁机制(悲观并发控制):
-
行级锁:写操作加排他锁(X Lock),阻塞其他写操作。
-
间隙锁(Gap Lock) + 临键锁(Next-Key Lock):解决幻读(RR 隔离级别)。
-
-
MVCC(乐观并发控制):
-
ReadView:事务开启时生成活跃事务 ID 快照。
-
版本链:每行数据隐藏字段(DB_TRX_ID、DB_ROLL_PTR)指向 Undo Log 中的历史版本。
-
可见性规则:根据 ReadView 和版本链决定是否可见(RC 级别每次读生成新 ReadView,RR 级别复用第一次 ReadView)。
-
4)一致性(Consistency)
-
原子性 + 持久性 + 隔离性共同保障数据逻辑一致性(如外键约束、唯一索引)。
II.事务操作示例(以 UPDATE 为例):
开启事务:BEGIN
生成 ReadView(RR 级别)
执行 UPDATE:
-
加行锁(X Lock)及间隙锁
-
写 Undo Log(记录旧值)
-
写 Redo Log(Prepare 状态)
-
修改 Buffer Pool 数据页
提交事务:COMMIT
-
Redo Log 标记 Commit
-
释放锁
-
Binlog 写入(主从同步)
回滚事务:ROLLBACK
-
用 Undo Log 恢复数据
-
释放锁
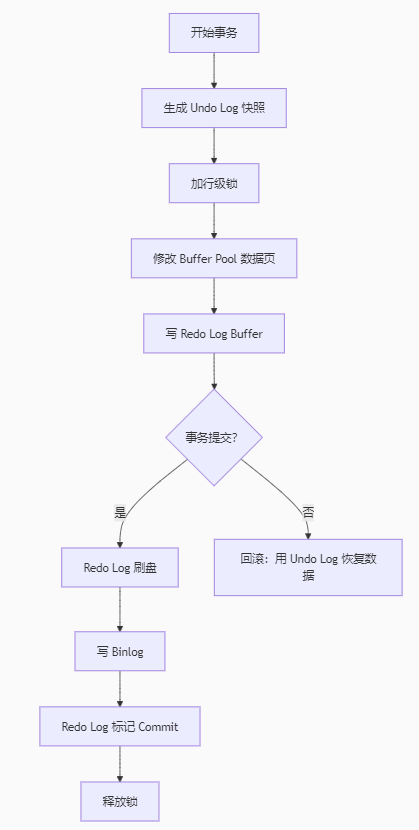
III.不同隔离级别的实现:
| 读未提交(RU) | 不加锁,直接读最新数据(含未提交事务) | 无 |
| 读已提交(RC) | MVCC 每次读生成新 ReadView,读已提交版本 | 脏读 |
| 可重复读(RR) | MVCC 首次读生成 ReadView,后续复用 + 间隙锁 | 脏读、不可重复读、幻读 |
| 串行化(S) | 读加共享锁,写加排他锁(完全串行化) | 所有并发问题 |
6.MySQL 事务的二阶段提交是什么?(中)
MySQL 的二阶段提交是协调 redo log(存储引擎层)和 binlog(Server 层)的核心机制: 1)Prepare 阶段: 写入 prepare 状态的 redo log,确保物理修改持久化。 2)Commit 阶段: 先写 binlog(逻辑操作),再提交 redo log(标记 commit)。崩溃恢复时,通过对比 redo log 的 prepare 状态和 binlog 完整性,决定事务提交或回滚,从而保障跨日志系统的原子性与数据一致性。
拓展:
I.执行流程(以事务提交为例):
1)阶段一:Prepare(准备阶段)
写 redo log(prepare 状态)
-
InnoDB 将事务的修改写入 redo log,标记为 PREPARE 状态(物理日志,记录数据页变更)。
通知执行器
-
存储引擎通知执行器:“已准备好提交”。
2)阶段二:Commit(提交阶段)
写 binlog
-
执行器将事务的 SQL 操作逻辑写入 binlog(逻辑日志,记录 SQL 语句)。
写 redo log(commit 状态)
-
执行器通知 InnoDB 提交事务,redo log 标记为 COMMIT 状态。
释放资源
-
释放事务持有的锁,清理 Undo Log。
注意:
-
binlog 写入必须在 redo log 的 prepare 之后、commit 之前。
-
若任一阶段失败,事务会回滚(利用 Undo Log 恢复数据)。
II.崩溃恢复时的处理逻辑:
MySQL 重启后检查 redo log 和 binlog 状态:
| redo log 有 commit 标记 | 事务已提交,无需处理 |
| redo log 有 prepare 标记 | 检查 binlog 是否完整: |
| – binlog 完整存在 | 重做 commit(提交事务) |
| – binlog 不完整/丢失 | 回滚事务(利用 Undo Log) |
7.MySQL 中长事务可能会导致哪些问题? (中)
MySQL 长事务会引发四类核心问题:
1)锁阻塞与死锁:长期占用行锁/间隙锁,导致并发事务阻塞甚至死锁。
2)Undo Log 膨胀:阻止 Purge 线程清理旧版本,引发存储空间爆炸。
3)主从复制延迟:Binlog 写入滞后,主从数据不一致。
4)连接资源耗尽:持续占用线程与内存资源,触发连接池溢出。
解决需从监控(INNODB_TRX)、拆解事务、设置超时参数三方面入手,本质是避免事务长时间不提交。
拓展:
I.具体问题:
1)锁阻塞与死锁
-
行锁/间隙锁长期持有: 未提交的事务持续占用锁资源,导致其他事务阻塞(如 UPDATE 被卡住),高并发下触发死锁概率飙升。
-
示例:事务 A 更新 10 万行未提交 → 事务 B 更新同一行时无限等待。
2)Undo Log 膨胀
-
历史版本无法清理: MVCC 依赖 Undo Log 存储旧数据版本,长事务导致 Purge 线程无法清理其开始前的旧版本(因快照读仍需访问)。
-
后果:Undo 表空间持续增长,甚至撑爆磁盘(错误 The total number of locks exceeds the lock table size)。
3)主从复制延迟
-
Binlog 积压: 主库未提交的事务会延迟 Binlog 写入(事务提交才写 Binlog),从库同步滞后,导致读写分离时读到旧数据。
4)连接资源耗尽
-
长期占用连接: 每个事务占用一个数据库连接(线程 + 内存),长事务使连接池快速耗尽(Too many connections),新请求被拒绝。
5)数据逻辑错误风险
-
旧快照读失真: RR 级别下,长事务的 ReadView 长期不更新,可能读到已被物理删除的“幽灵数据”(逻辑上已失效)。
II.解决方案:
监控与告警:
SELECT * FROM information_schema.INNODB_TRX; — 查运行中事务
监控 trx_duration(事务持续时间),超过阈值报警(如 60 秒)。
自动 Kill 长事务: 通过脚本定期清理超时事务(KILL trx_mysql_thread_id)。
拆解大事务:
分批次提交(如 1000 行/次):
UPDATE table SET col=val WHERE id BETWEEN 1 AND 1000;
COMMIT; — 分批提交
设置超时参数:
innodb_lock_wait_timeout=50 — 锁等待超时(秒)
innodb_rollback_on_timeout=ON — 超时自动回滚
8.MySQL 中的 MVCC 是什么?(难)
MySQL 的 MVCC(Multi-Version Concurrency Control,多版本并发控制) 是通过数据多版本和快照读实现的无锁并发控制机制:
1)核心结构: 每行数据隐藏事务 ID(DB_TRX_ID)和回滚指针(DB_ROLL_PTR),通过 Undo Log 构建版本链。
2)可见性控制: 事务读操作时生成 ReadView,基于事务 ID 和活跃事务列表判断版本可见性。
3)隔离级别适配:
-
RR 级别:首次读生成 ReadView 并复用,解决不可重复读。
- RC 级别:每次读生成新 ReadView,解决脏读但允许不可重复读。
4)优势: 在保证隔离性的同时,显著提升读写并发性能。
拓展:
I.实现原理:
1)隐藏字段(每行数据包含)
-
DB_TRX_ID(6 字节):最近修改该行的事务 ID(插入/更新时写入)。
-
DB_ROLL_PTR(7 字节):回滚指针,指向 Undo Log 中的历史版本链。
-
DB_ROW_ID(6 字节):隐含自增行 ID(无主键时生成聚簇索引)。
2)Undo Log(版本链存储)
-
每次更新数据时,将旧数据拷贝到 Undo Log 中,并通过 DB_ROLL_PTR 连接成单向链表(版本链)。
-
示例:
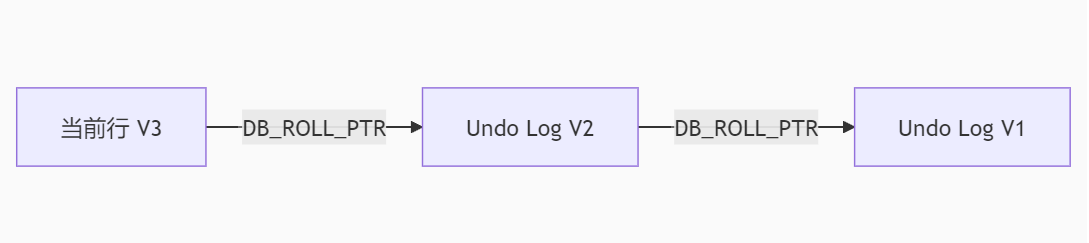
3)ReadView(可见性判断规则)
事务首次执行 SELECT 时生成 ReadView,包含:
-
trx_ids:当前活跃事务 ID 列表(未提交的事务)。
-
min_trx_id:trx_ids 中的最小事务 ID。
-
max_trx_id:系统预分配的下一个事务 ID(当前最大事务 ID +1)。
-
creator_trx_id:创建该 ReadView 的事务 ID。
4)可见性规则(判断数据是否可见)
对版本链中每个数据版本,按顺序检查:
若 DB_TRX_ID == creator_trx_id → 可见(当前事务自身修改);
若 DB_TRX_ID < min_trx_id → 可见(事务已提交);
若 DB_TRX_ID > max_trx_id → 不可见(事务在 ReadView 后开启);
若 DB_TRX_ID 在 trx_ids 中 → 不可见(事务未提交);
否则 → 可见。
II.MVCC 工作流程示例(RR 级别):
假设事务 A(ID=100)执行 SELECT * FROM users WHERE id=1:
生成 ReadView:trx_ids=[99,101](活跃事务),min_trx_id=99,max_trx_id=102。
读取 id=1 的数据行,发现其 DB_TRX_ID=101(在 trx_ids 中)→ 不可见。
沿回滚指针找到旧版本:DB_TRX_ID=98(小于 min_trx_id=99)→ 可见,返回该版本数据。
9.MySQL 中的事务隔离级别有哪些?(易)
MySQL 提供四种标准事务隔离级别,用于平衡数据一致性与并发性能。
事务隔离级别从低到高:
1)读未提交(RU): 可能读到未提交数据,存在脏读、不可重复读、幻读; 2)读已提交(RC): 避免脏读,但存在不可重复读和幻读(每次读生成新 ReadView); 3)可重复读(RR,默认): 避免脏读和不可重复读,并通过 MVCC(首次读 ReadView) + 间隙锁 解决幻读; 4)串行化(S): 完全串行执行,避免所有并发问题但性能最低。
| 读未提交(RU) | ❌ 可能发生 | ❌ 可能发生 | ❌ 可能发生 | 直接读取最新数据(无 MVCC,无锁阻塞读) |
| 读已提交(RC) | ✅ 避免 | ❌ 可能发生 | ❌ 可能发生 | MVCC:每次读生成新 ReadView(仅读取已提交版本) |
| 可重复读(RR) 🔹 | ✅ 避免 | ✅ 避免 | ✅ 避免(InnoDB 特调) | MVCC:首次读生成 ReadView + 间隙锁(Gap Lock) 阻止插入/删除 |
| 串行化(S) | ✅ 避免 | ✅ 避免 | ✅ 避免 | 读操作隐式加共享锁(S Lock),写操作加排他锁(X Lock),读写互斥 |
10.MySQL 默认的事务隔离级别是什么?为什么选择这个级别?(易)
MySQL 默认事务隔离级别是 RR(可重复读)。选择 RR 的原因是: 1)性能层面: 通过 MVCC 实现非阻塞快照读,避免重复生成 ReadView 的开销,适合高并发读场景。 2)一致性层面: 天然解决不可重复读,并通过间隙锁抑制幻读,满足多数业务对数据一致性的要求。 3)对比优势: 在避免脏读的前提下,比串行化(S)并发度高,比读已提交(RC)数据一致性更强。 这是 InnoDB 在性能与数据安全间权衡后的最优解。
拓展:
I.为什么选择 RR 作为默认隔离级别?(详细解释)
1)高并发读场景的性能优势
-
MVCC(多版本并发控制): RR 级别下,事务首次读生成 ReadView(快照),后续读操作复用该视图,避免重复创建快照的开销。
-
非阻塞读: 读操作不阻塞写操作(写操作通过行锁控制),显著提升读多写少场景的并发性能。
2)解决不可重复读与幻读(实际业务强需求)
-
避免不可重复读:同一事务内多次读相同数据,结果一致(例如:余额校验、订单状态确认)。
-
抑制幻读:通过 间隙锁(Gap Lock) 锁定查询范围,阻止其他事务插入新数据(如 WHERE age > 20 会锁定 age>20 的间隙)。
3)对比其他级别的劣势
| RC | 不可重复读(同一事务内读到其他事务提交的修改) → 业务逻辑可能出错 |
| RU | 脏读风险高 → 数据完全不可控 |
| S | 并发性能差(读加共享锁阻塞写) → 难以支撑高并发 |
II.RR 级别的实现机制:
MVCC 快照读(核心)
-
事务首次 SELECT 时生成 ReadView,记录当前活跃事务 ID 快照。
-
后续读操作基于该 ReadView 判断数据可见性(通过 DB_TRX_ID 和 DB_ROLL_PTR 访问 Undo Log 历史版本)。
间隙锁(解决幻读)
-
对查询范围加锁(如 id BETWEEN 10 AND 20 会锁定 [10,20] 区间),阻塞其他事务插入区间内的新数据。
本文到此结束,如果对你有帮助,可以点个赞~
后续会在合集里持续更新 MySQL 相关的面试题,欢迎关注~
祝各位都能拿到满意的offer~




评论前必须登录!
注册