 网硕互联帮助中心
网硕互联帮助中心前言
这篇是我自己的操作笔记,网上可以搜到好多相似文章,大家综合来看,寻找适合自己的,在配置环境过程中出现的问题可参考这篇文章【新手小白】在Linux服务器或本地IDE,跑深度学习代码指南
目录
前言
1. 下载代码并配置环境
2. 准备数据集
二维数据集(如.png)
三维数据集(如.nrrd)
3. 开始训练
4. 验证和推理
5. 其他
1. 下载代码并配置环境
打开vscode或pycharm等编辑器,进入到你想存放代码的文件夹下。
选择1:在终端输入命令,直接下载代码
git clone https://github.com/MIC-DKFZ/nnUNet.git
选择2:在github下载代码压缩包,再手动上传到服务器。
此时目录长这样
先创建一个新的conda环境并启动环境
conda create -n nnunet python=3.10
conda activate nnunet
再给环境安装pytorch包,先输入如下命令,查看CUDA Version是多少
nvidia-smi
我的是CUDA Version: 12.4 ,故选择低于CUDA12.4的pytorch,如CUDA11.8,终端输入如下命令
pip3 install torch torchvision torchaudio –index-url https://download.pytorch.org/whl/cu118
在终端,进入nnUNet目录后,逐步输入以下命令(也可以手动下载后上传服务器:hiddenlayer)
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple -e .
git clone https://github.com/FabianIsensee/hiddenlayer.git
cd hiddenlayer
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple -e .
2. 准备数据集
此处分为两种情况
- 二维数据集(如 .png、jpg 等)
- 三维数据集(如 .nrrd、niii.gz 等)
二维数据集(如.png)
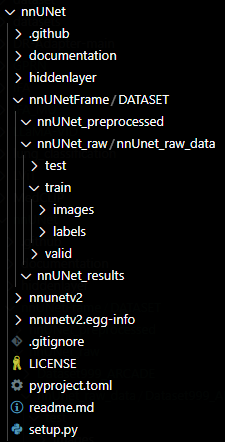
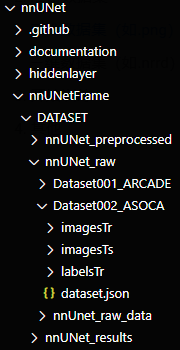
在nnUNet目录下,新建文件夹nnUNetFrame,DATASET,nnUNet_raw;nnUNet_preprocessed;nnUNet_results,nnUnet_raw_data,以及test;train;valid,在这三个目录下分别创建 images;labels
此时目录长这样
接下来上传 训练、测试、验证数据集到 images 和 labels,我用的都是.png格式的图片,images里放原始图像(shape:512, 512, 3),labels放mask掩码图像(shape: 512, 512)
然后,终端输入如下内容,都是咱刚刚创建好的目录(这一步骤,每重新打开一次电脑都要再运行一遍)
export nnUNet_raw="换成你自己的路径/nnUNet/nnUNetFrame/DATASET/nnUNet_raw"
export nnUNet_preprocessed="换成你自己的路径/nnUNet/nnUNetFrame/DATASET/nnUNet_preprocessed"
export nnUNet_results="换成你自己的路径/nnUNet/nnUNetFrame/DATASET/nnUNet_results"
接下来,到这个路径下:nnUNet/nnunetv2/dataset_conversion找到Dataset120_RoadSegmentation.py
可以把如下内容全部复制替换掉原内容,再按照代码里面的注释,改成自己的内容,并运行
import multiprocessing
import shutil
from multiprocessing import Pool
from batchgenerators.utilities.file_and_folder_operations import *
from nnunetv2.dataset_conversion.generate_dataset_json import generate_dataset_json
from nnunetv2.paths import nnUNet_raw
from skimage import io
from acvl_utils.morphology.morphology_helper import generic_filter_components
from scipy.ndimage import binary_fill_holes
def load_and_convert_case(input_image: str, input_seg: str, output_image: str, output_seg: str,
min_component_size: int = 50):
seg = io.imread(input_seg)
seg[seg == 255] = 1
image = io.imread(input_image)
if image.ndim == 3: # 如果是RGB图像
image = image.sum(2) # 合并通道
elif image.ndim == 2: # 如果是灰度图像
pass # 保持原样
else:
raise ValueError(f"不支持的图像维度: {image.shape}")
mask = image == (3 * 255) if image.ndim == 2 else image == 255
mask = generic_filter_components(mask, filter_fn=lambda ids, sizes: [i for j, i in enumerate(ids) if
sizes[j] > min_component_size])
mask = binary_fill_holes(mask)
seg[mask] = 0
io.imsave(output_seg, seg, check_contrast=False)
shutil.copy(input_image, output_image)
if __name__ == "__main__":
source = '这里换成你自己的路径哦,选择到放train,test,valid的文件夹/nnUNet/nnUNetFrame/DATASET/nnUNet_raw/nnUnet_raw_data'
dataset_name = '这里需要你取一个名字,必须形如:Dataset数据集号3位数字_数据集名称,如Dataset999_DATA'
imagestr = join(nnUNet_raw, dataset_name, 'imagesTr')
imagests = join(nnUNet_raw, dataset_name, 'imagesTs')
labelstr = join(nnUNet_raw, dataset_name, 'labelsTr')
labelsts = join(nnUNet_raw, dataset_name, 'labelsTs')
maybe_mkdir_p(imagestr)
maybe_mkdir_p(imagests)
maybe_mkdir_p(labelstr)
maybe_mkdir_p(labelsts)
train_source = join(source, 'train')
test_source = join(source, 'test')
with multiprocessing.get_context("spawn").Pool(8) as p:
valid_ids = subfiles(join(train_source, 'images'), join=False, suffix='png')
num_train = 0
r = []
for v in valid_ids:
label_path = join(train_source, 'labels', v)
if isfile(label_path): # 确认标签文件存在
num_train += 1
r.append(
p.starmap_async(
load_and_convert_case,
((
join(train_source, 'images', v),
label_path,
join(imagestr, v[:-4] + '_0000.png'),
join(labelstr, v),
50
),)
)
)
else:
print(f"警告: 图像 {v} 没有对应的标签文件,已跳过")
valid_ids = subfiles(join(test_source, 'labels'), join=False, suffix='png')
for v in valid_ids:
image_path = join(test_source, 'images', v)
label_path = join(test_source, 'labels', v)
if isfile(image_path) and isfile(label_path): # 确认图像和标签文件都存在
r.append(
p.starmap_async(
load_and_convert_case,
((
image_path,
label_path,
join(imagests, v[:-4] + '_0000.png'),
join(labelsts, v),
50
),)
)
)
else:
print(f"警告: 测试图像 {v} 或其标签文件不存在,已跳过")
_ = [i.get() for i in r]
generate_dataset_json(join(nnUNet_raw, dataset_name), {0: 'R', 1: 'G', 2: 'B'}, {'background': 0, '这里是你要分割的类别名称,如cat': 1},
num_train, '.png', dataset_name=dataset_name)
此时,nnUNet_raw文件夹中会出现如下内容
images中的命名形如1_0000_0000.png、1_0000_0001.png、1_0000_0002.png,一张图分成了三张,代表三个通道
labels中的命名形如1_0000.png、1_0001.png、1_0002.png,点开labels中的图片看,是全黑的
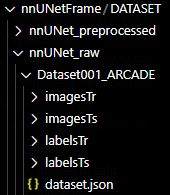
ps:labelsTs这个目录不是必须要有的,是我这个数据集里正好有,就一起放上来了
dataset.json中的内容如下,这是我生成出来的,以供参考:
{
"channel_names": {
"0": "R",
"1": "G",
"2": "B"
},
"labels": {
"background": 0,
"stenosis": 1
},
"numTraining": 997,
"file_ending": ".png",
"licence": "Whoever converted this dataset was lazy and didn't look it up!",
"converted_by": "Please enter your name, especially when sharing datasets with others in a common infrastructure!",
"name": "Dataset001_ARCADE"
}
接下来,终端输入如下内容
nnUNetv2_plan_and_preprocess -d 数据集号3位 –verify_dataset_integrity
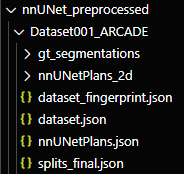
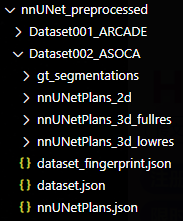
此时,nnUNet_preprocessed目录出现如下内容
三维数据集(如.nrrd)
此时目录效果如下:
dataset.json中的内容如下,这是我生成出来的,以供参考:
{
"channel_names": {
"0": "Artery"
},
"labels": {
"background": 0,
"artery": 1
},
"numTraining": 40,
"file_ending": ".nrrd"
}
然后,终端输入如下内容,都是咱刚刚创建好的目录(这一步骤,每重新打开一次电脑都要再运行一遍)
export nnUNet_raw="换成你自己的路径/nnUNet/nnUNetFrame/DATASET/nnUNet_raw"
export nnUNet_preprocessed="换成你自己的路径/nnUNet/nnUNetFrame/DATASET/nnUNet_preprocessed"
export nnUNet_results="换成你自己的路径/nnUNet/nnUNetFrame/DATASET/nnUNet_results"
接下来,终端输入如下内容
nnUNetv2_plan_and_preprocess -d 数据集号3位 –verify_dataset_integrity
此时,nnUNet_preprocessed目录出现如下内容
3. 开始训练
此处有其余问题可参考官方文档:训练推理 官方文档
该代码下可以修改 “num_epochs” 的大小,500就差不多了:nnUNet/nnunetv2/training/nnUNetTrainer/nnUNetTrainer.py
self.num_epochs = 500 # 1000
开始训练,终端输入如下命令,选择其中一种即可
形如 “服务器卡号(可省略)/ 训练 / 数据集号3位 / 配置(如下) / flod=0至5”
nnUNet 有四种配置:2D(2d)、3D 全分辨率(3d_fullres)、3D 低分辨率(3d_lowres)、级联的全分辨率 U-Net(3d_cascade_fullres)
CUDA_VISIBLE_DEVICES=3 nnUNetv2_train 001 2d 0
nnUNetv2_train 001 2d 0
nnUNetv2_train 001 2d 1
nnUNetv2_train 001 2d 2
nnUNetv2_train 001 2d 3
nnUNetv2_train 001 2d 4
nnUNetv2_train 002 3d_lowres 4
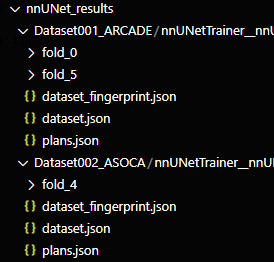
此时,可以看到文件夹更新了训练的内容,此处我只跑了001数据集的 fold=0 和 fold=5,还有002数据集的 fold=4
4. 验证和推理
执行如下命令验证,2d数据集用2d,3d数据集用3d
nnUNetv2_train 001 2d 0 –val –npz
nnUNetv2_train 001 2d 1 –val –npz
nnUNetv2_train 001 2d 2 –val –npz
nnUNetv2_train 001 2d 3 –val –npz
nnUNetv2_train 001 2d 4 –val –npz
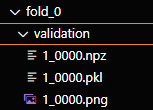
此时,nnUNet_results文件夹的每折validation文件夹出现npz文件
执行如下命令,找寻最优模型并给出推理命令,一共列了3种,选择适合自己的一种即可:
# 对数据集001寻找最佳配置(测试2d配置)
nnUNetv2_find_best_configuration 001 -c 2d
# 对数据集001寻找最佳配置(测试2d配置,从fold=1至5中找)
nnUNetv2_find_best_configuration 001 -c 2d -f 0 1 2 3 4
# 对数据集001寻找最佳配置(会测试多种配置)
nnUNetv2_find_best_configuration 001 -c 2d 2d 3d_lowres 3d_fullres 3d_cascade_fullres
接下来测试,首先创建一个文件夹放输出结果,如 “nnUNet/nnUNetFrame/OUTPUT”
终端输入如下命令
nnUNetv2_predict -f 0 –save_probabilities
nnUNetv2_predict -d Dataset004_Hippocampus -i nnUNet_raw\\Dataset004_Hippocampus\\imagesTs -o hippocampus_2d_predict -f 0 1 2 3 4 -tr nnUNetTrainer -c 2d -p nnUNetPlans –save_probabilities
nnUNetv2_predict -d 001 -i /home/Data/lizican/heart/nnUNet/nnUNetFrame/DATASET/nnUNet_raw/Dataset001_ARCADE/imagesTs -o /home/Data/lizican/heart/nnUNet/nnUNetFrame/OUTPUT -f 0 -tr nnUNetTrainer -c 2d –save_probabilities
结束后,文件夹长这样
现在就可以用这个生成的.png文件和原始标签文件计算Dice,可以自己写个脚本,当然过程会比较繁琐。
5. 其他
下述内容我还没有实际操作过
执行如下命令保存ensemble策略
nnUNetv2_ensemble -i /nnUNet/nnUNetFrame/OUTPUT -o /nnUNet/nnUNetFrame/OUTPUT/ensemble -np 8
推理完成后进行后处理,结构与上述命令一致,大家注意好自己的路径不要写错,得到对测试集的分割结果
nnUNetv2_apply_postprocessing -i /nnUNet/nnUNetFrame/OUTPUT/ensemble -o /nnUNet/nnUNetFrame/OUTPUT/processing -pp_pkl_file /nnUNet/nnUNetFrame/DATASET/nnUNet_results/Dataset001_ARCADE/nnUNetTrainer__nnUNetPlans__2d/fold_0/checkpoint_best.pth -np 8 -plans_json /nnUNet/nnUNetFrame/DATASET/nnUNet_results/Dataset001_ARCADE/nnUNetTrainer__nnUNetPlans__2d/plans.json









评论前必须登录!
注册