 网硕互联帮助中心
网硕互联帮助中心本项目中使用的jar包链接如下:
http://我用夸克网盘分享了「dataTrans.jar」,点击链接即可保存。打开「夸克APP」,无需下载在线播放视频,畅享原画5倍速,支持电视投屏。 链接:https://pan.quark.cn/s/6a2a7566802c
本项目中104为源数据库,67为目标数据库。
一.新建job
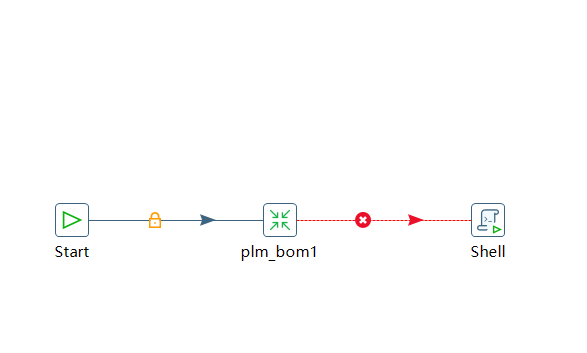
首先,编辑plm_bom1:
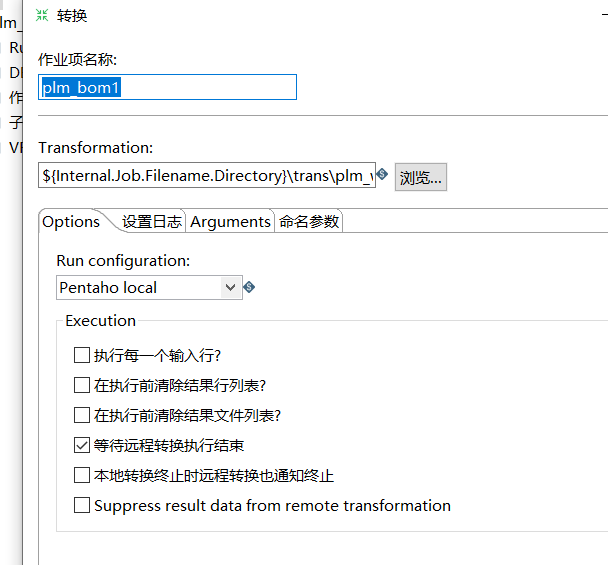
在Transformation框中输入下面的转移,便于job能迅速定位trans。
${Internal.Job.Filename.Directory}\\trans\\plm_wtpart.ktr
其次,在设置日志方面做如下修改:编辑日志文件名和后缀名。
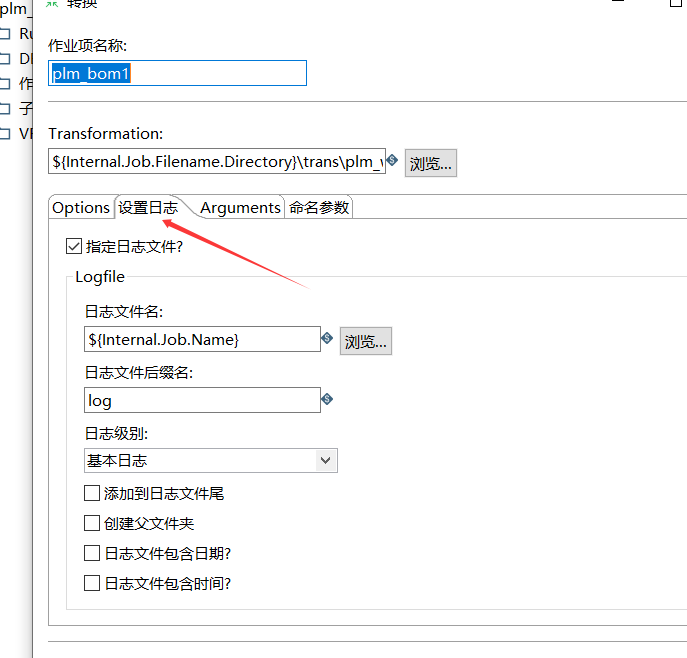
点击确定,完成job的编写。
二.新建trans
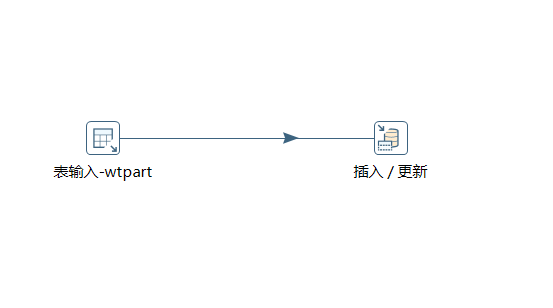
2.1 表输入
首先,新建数据库连接

进入后,
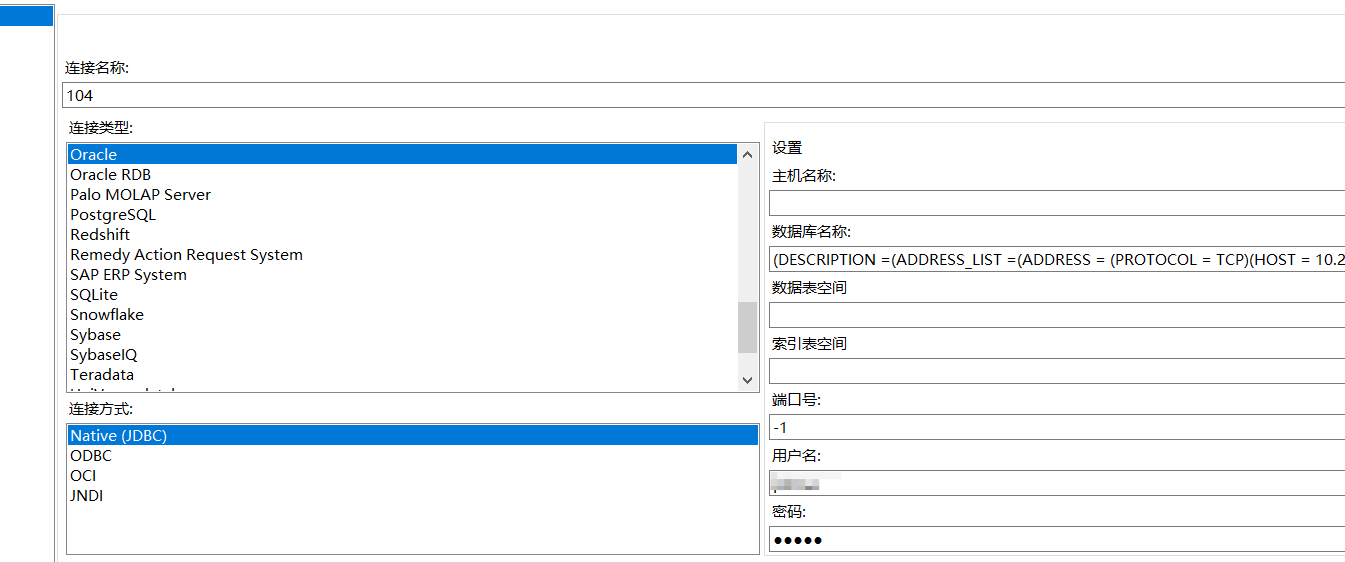
进行数据库的编辑(在数据库名称里面粘贴如下),以oracle数据迁移为例:
(DESCRIPTION =(ADDRESS_LIST =(ADDRESS = (PROTOCOL = TCP)(HOST = 你的服务器地址)(PORT = 1521)))(CONNECT_DATA =(SERVICE_NAME = 链接的oracle的服务名)))
其次,连接名称随意指定,输入用户名密码点击确定即可。
最后,编写sq查询语句,点击确定即可(可先用数据库查询工具如:navicat等,验证一下sql是否正确)。

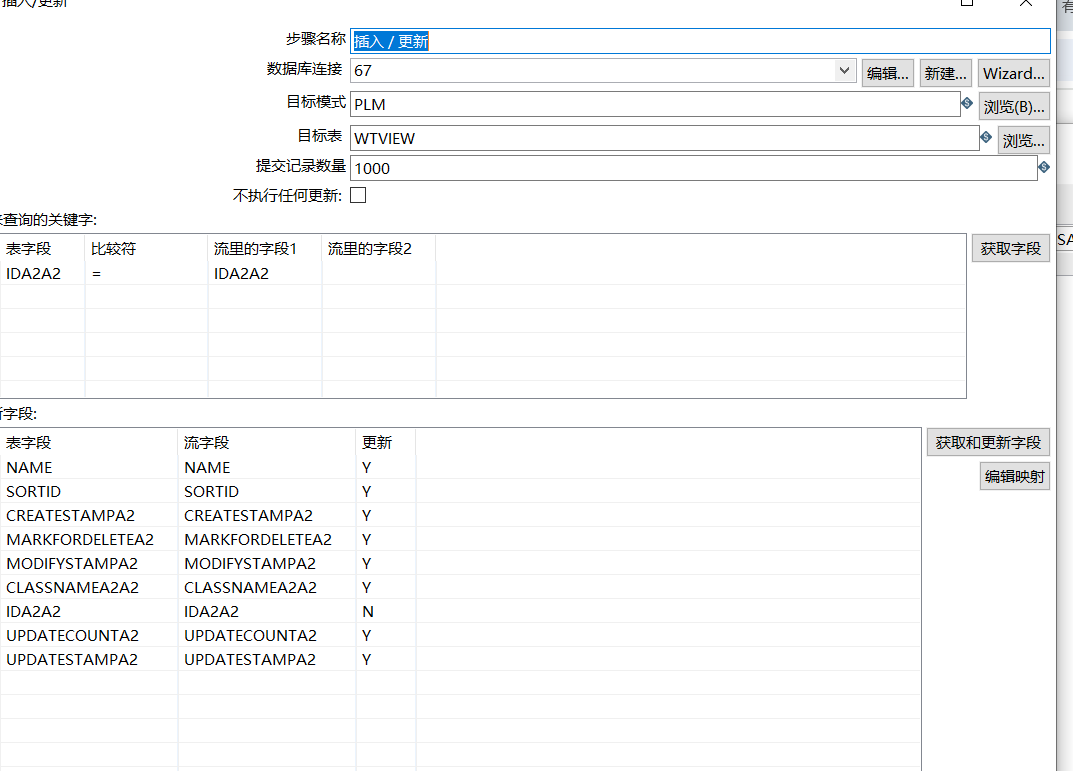
2.2 插入更新
新建数据库连接,这里不做多于赘述,参考二.一。
建好连接后,选择要插入的目标表。

点击获取字段,进行字段的对比和插入更新,对比的选择主键即可,更新字段选择全部字段,如果不能获取字段,可手动选择下拉框输入数据。
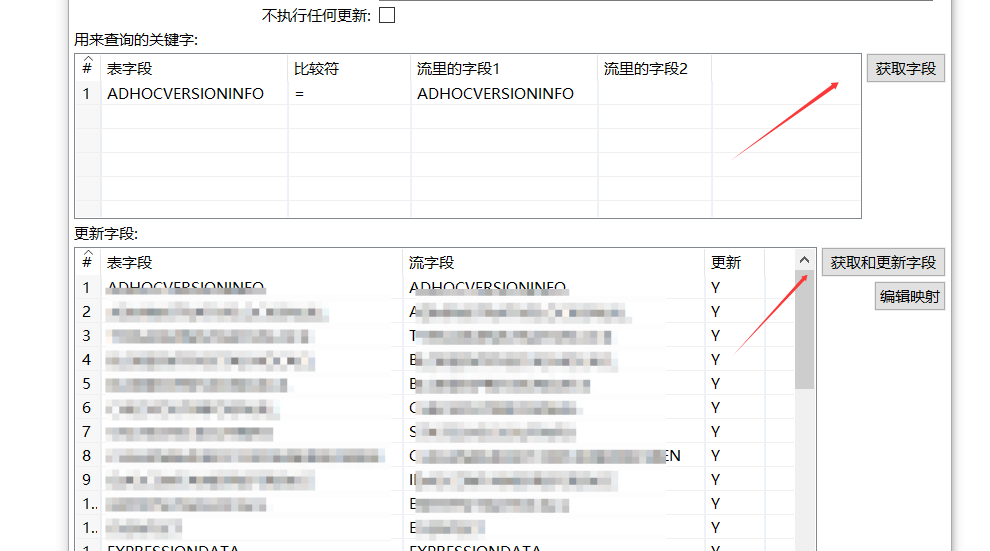
点击确定即可。
三.修改配置文件
3.1 修改配置
首先,在服务器中新建一个文件夹data_‘你的文件夹’ 用来存储job和trans
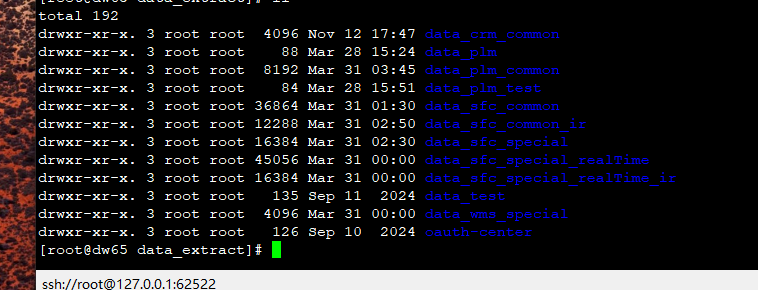
新建jobs进行存储,并上传dataTrans.jar

在jobs里上传kjb文件,并创建trans文件夹

在trans文件夹里上传ktr文件

最后回到data_‘你的文件夹’ ,运行runDataTrans.sh

runDataTrans.sh内容如下:
目录需自己设置,记得修改。
cd /data/data_extract/data_‘你的文件夹’
#!/bin/sh
java -Xms128m -Xmx1024m -Xss256k -jar dataTrans.jar
运行完成后数据便迁移完成。
3.2 设置定时任务
编写cron表达式,设置定时任务,定时进行数据的同步。
crontab -e
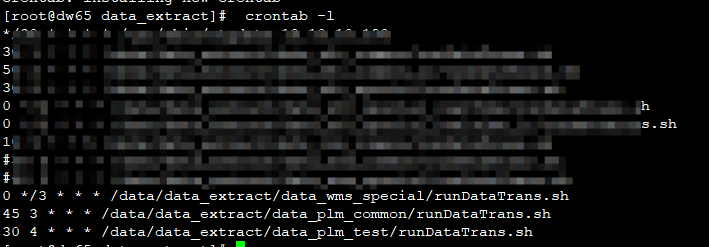
四.增量更新
增量更新逻辑:利用updatestamp字段进行对比。
与全量更新不同的是,建立流程如下:
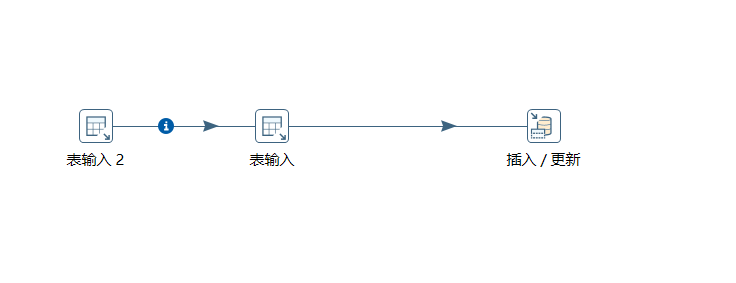
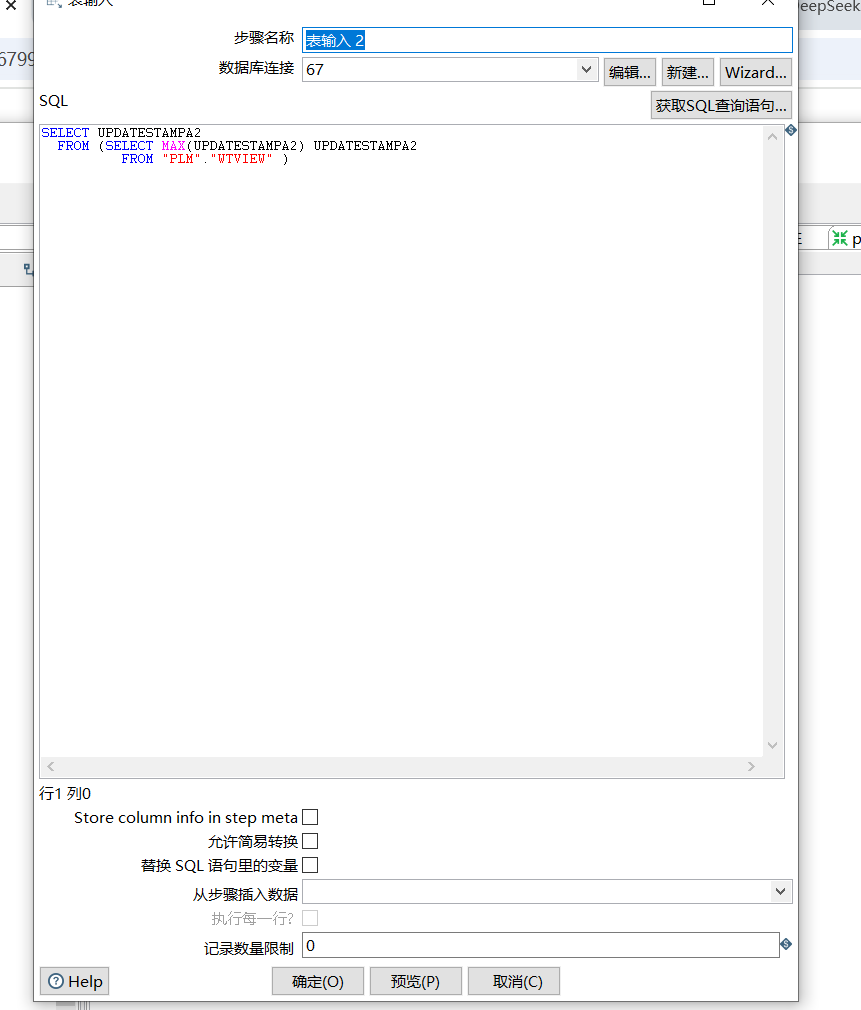
1.表输入2 写入sql语句,我们这里将目标数据库67的更新时间作为条件。
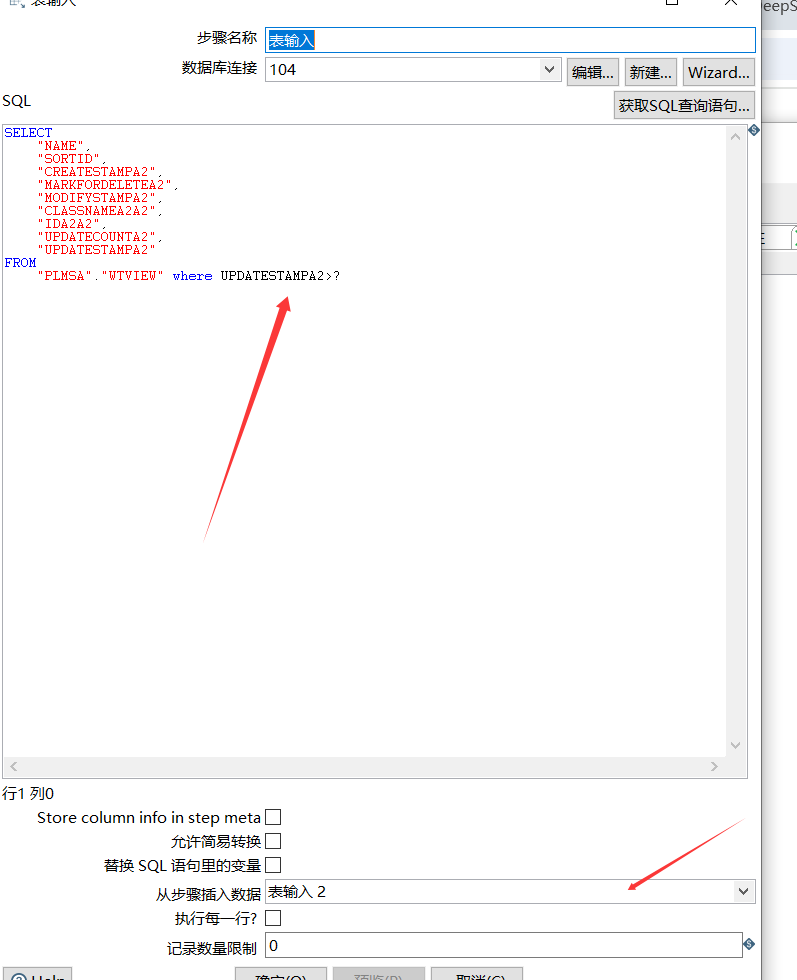
2.表输入中写入sql ,将更新时间作为条件,在源数据库104中查询增量更新的数据。同时下方的输入框选择 ‘表输入2’作为问号的参数。
3.在目标数据库67中进行插入更新操作。
五.数据同步过程中较慢的问题解决
1.给对比的字段建立索引
2.不使用kettle的“插入/更新”组件,转而使用“表输出”组件或“数据同步”组件,他们的性能更高。





评论前必须登录!
注册