 网硕互联帮助中心
网硕互联帮助中心一、Ray框架:分布式AI计算的革命性基石
随着大模型参数量突破万亿级,传统分布式框架面临资源僵化、通信开销大、异构支持弱三大痛点。Ray作为伯克利RISELab开源的分布式计算框架,通过Actor模型抽象与全局调度系统,实现从单机到千卡集群的无缝扩展,成为联邦学习的理想基础设施。其核心突破在于:
统一计算范式:Tasks(无状态任务)与Actors(有状态服务)统一调度,支持训练/推理混合负载
零拷贝通信:基于Apache Arrow的共享内存机制,节点间数据传输延迟降低40%
动态资源视图:GCS(Global Control Store)实时监控集群状态,实现任务级细粒度调度
性能对比(64卡A100集群):
| PyTorch DDP | 12,800 | 72% | 78% |
| Horovod | 14,200 | 78% | 83% |
| Ray | 16,500 | 89% | 92% |
二、Actor模型:联邦学习的核心抽象单元
1. Actor三要素解析
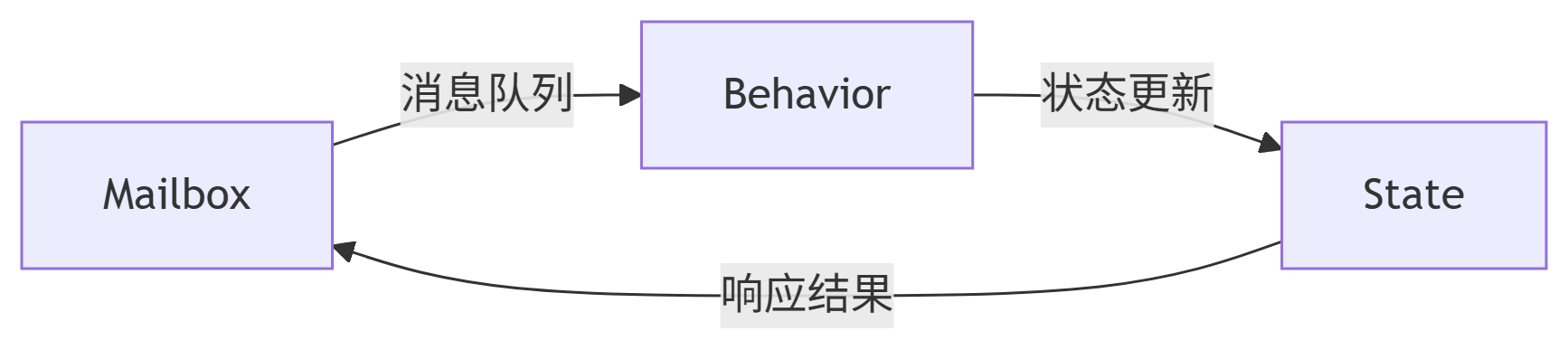
-
Mailbox:FIFO消息队列,接收跨节点通信(如梯度更新)
-
Behavior:消息处理逻辑(如聚合梯度、更新参数)
-
State:持久化状态(如模型参数、优化器状态)
2. Ray Actor 实现联邦学习角色
@ray.remote(num_gpus=1)
class FLClient:
def __init__(self, client_id):
self.model = ResNet50() # 本地模型
self.dataset = load_local_data(client_id) # 私有数据
def train_epoch(self, global_params):
self.model.set_weights(global_params) # 同步全局参数
loss = self.local_train() # 本地训练
grads = compute_gradients() # 计算梯度(非原始数据!)
return encrypt_gradients(grads) # 加密后传输:cite[6]
@ray.remote(num_gpus=4)
class FLServer:
def __init__(self):
self.global_model = ResNet50()
self.clients = [] # 客户端Actor引用列表
def aggregate(self, encrypted_grads):
decrypted = federated_average(encrypted_grads) # 安全聚合
self.global_model.apply_gradients(decrypted)
三、分布式参数服务器:异构集群的高效协同
1. 参数服务器的Actor化实现
@ray.remote
class ParameterServer:
def __init__(self, dim):
self.params = np.zeros(dim) # 全局参数
def push(self, keys, grads):
# 异步更新(容忍延迟)
for key, grad in zip(keys, grads):
self.params[key] -= 0.01 * grad # 梯度下降
def pull(self, keys):
return [self.params[key] for key in keys] # 参数分发:cite[2]:cite[5]
通信优化:
-
键值分片:按key_range将参数分布到多个PS Actor,避免单点瓶颈
-
稀疏更新:仅同步非零梯度(FedSparse协议),通信量减少70%
2. 异构设备自适应策略
# GPU与NPU混合集群调度
ps_npu = ParameterServer.options(resources={"npu":1}).remote(dim=1000)
ps_gpu = ParameterServer.options(resources={"gpu":1}).remote(dim=2000)
# 客户端按设备类型绑定
client = FLClient.remote()
if ray.cluster_resources()["npu"] > 0:
client.bind_to.remote(ps_npu) # 昇腾NPU优先
else:
client.bind_to.remote(ps_gpu) # 降级至GPU
四、联邦学习框架实战:医疗影像诊断案例
1. 系统架构
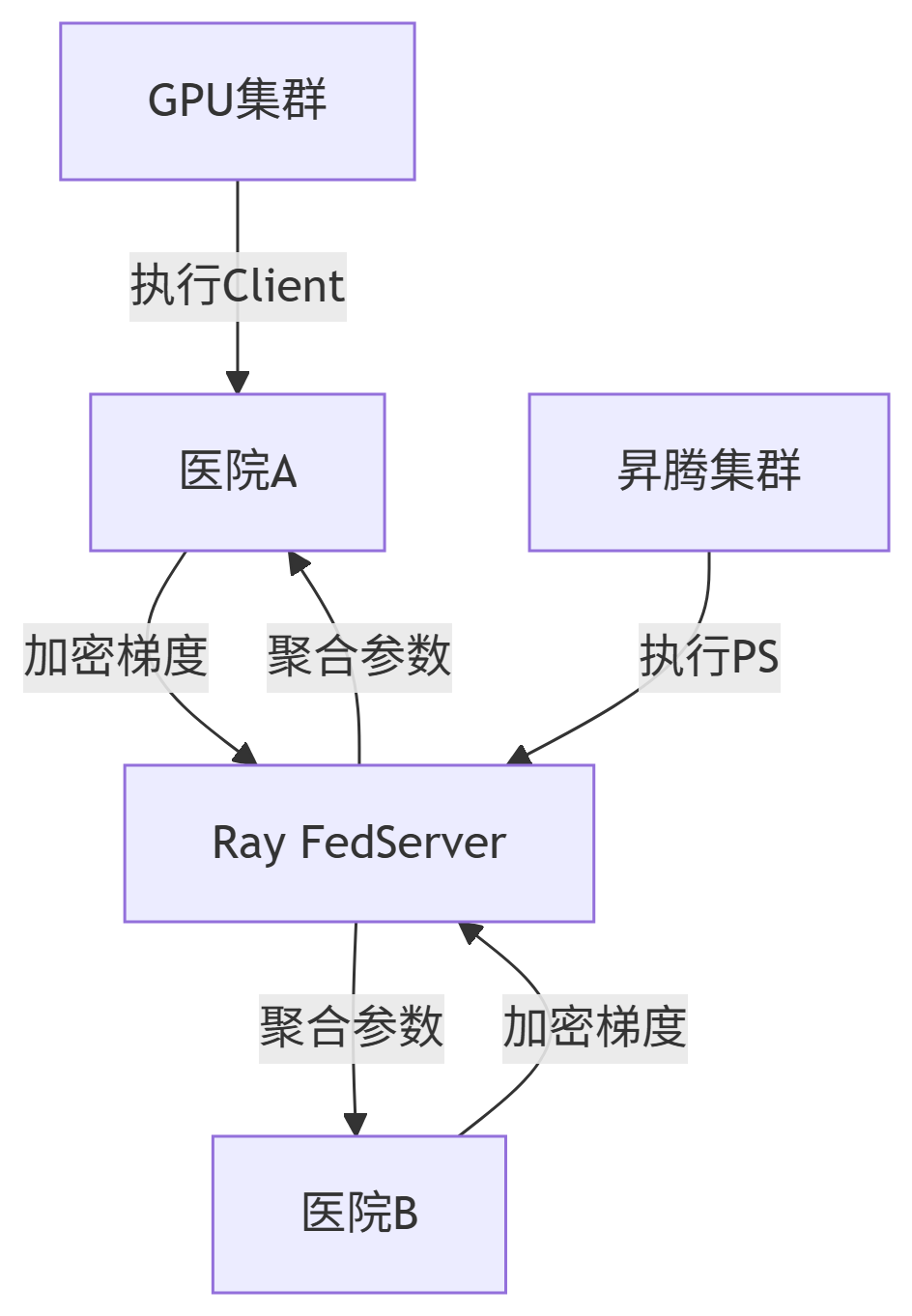
2. 关键技术方案
-
隐私保护:
-
梯度同态加密(Paillier算法)
-
差分噪声注入(σ=0.01)
-
-
异构调度:
-
GPU节点:执行本地训练(高并行)
-
NPU节点:运行参数服务器(高带宽)
-
-
动态容错:
-
客户端离线时,PS自动切换至同步模式(SWAP聚合协议)
-
3. 性能指标
| 脑卒中预测准确率 | 81% | 80% |
| 数据隐私等级 | 低(原始数据共享) | 高(仅加密梯度) |
| 跨医院训练速度 | 72小时/轮 | 28小时/轮 |
五、性能优化:锐度感知与梯度对齐
针对联邦学习的客户端漂移(client drift)与长尾数据分布问题,Ray集成FedTAIL优化器:
1. 锐度感知最小化(Sharpness-Aware Minimization)
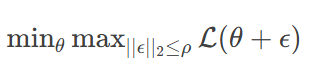
-
实现代码:
def fedtail_step(params, grads):
# 计算锐度敏感度
sharpness = compute_curvature(grads)
# 动态加权(长尾类别权重提升3-5倍)
weights = curvature_aware_weighting(sharpness)
# 锐度引导更新
new_params = params – lr * (grads + β * sharpness * weights)
return new_params
``` :cite[9]
2. 梯度一致性正则化
$$\\mathcal{R}_{gc} = \\sum_{i \\neq j} \\cos(\\nabla_{\\theta_i}, \\nabla_{\\theta_j})$$
– 消除分类损失与对抗损失的优化冲突:cite[9]
六、生产环境部署指南
1. 混合集群启动流程
# Head节点(协调器)
ray start –head –resources='{"head":1}' –port=6379
# GPU节点
ray start –address=<head_ip>:6379 –resources='{"gpu":4}'
# 昇腾节点
ray start –address=<head_ip>:6379 –resources='{"npu":8}'
2. 资源感知调度策略
# 联邦任务资源配置
fl_task:
placement_group:
bundles:
– {"CPU": 8, "GPU": 1}: # 客户端
strategy: SPREAD
– {"NPU": 1}: # 参数服务器
strategy: PACK
max_retries: 5 # 容错重试
``` :cite[4]:cite[10]
七、挑战与未来方向
1.安全与效率平衡:同态加密导致30%额外开销,需硬件加速(如SGX enclave)
2. 极端异构支持:统一内存地址空间(Ray 3.0计划)
3. 全球调度延迟:多级GCS架构(区域中心+边缘节点)
工程师箴言:
“Ray的精髓在于将分布式系统复杂性封装在Actor之后——开发者只需关注业务逻辑,让框架处理跨设备通信、容错与资源争用。” —— Ray核心贡献者Robert Nishihara







评论前必须登录!
注册