 网硕互联帮助中心
网硕互联帮助中心目录
一 数据结构,相关概念
1. 数据结构:
2. 数据(Data):
3. 数据元素(Data Element):
4. 数据项:
5. 数据对象(Data Object):
6. 容器(container):
7. 结点(Node):
8. 迭代器(iterator):
9. 前驱 节点:
10. 后继 节点:
二 数据结构分类
1. 逻辑结构分类
1. 集合结构
2. 线性结构
3. 树型结构
4. 图状结构或网状结构
2. 物理结构分类
1. 顺序存储结构
2. 链接存储结构
3. 数据索引存储结构
4. 数据散列存储结构 hash
5. 总结
性能对比与分析
3. 总结
逻辑结构与物理结构的对应关系
一 数据结构,相关概念
1. 数据结构:
是相互之间存在一种或多种特定关系的数据元素的集合。不同的数据元素之间不是独立的,而是存在特定的关系,我们将这些关系成为结构。
2. 数据(Data):
是对信息的一种符号表示。在计算机科学中是指所有能输入到计算机中并被计算机程序处理的符号的总称。描述客观事物的符号,是计算机中可以操作的对象,是能被计算机识别,并输入给计算机处理的符号集合。(数据不仅包含整型、实型等数值类型,还包括字符及声音、图像、视频等非数值类型。)
3. 数据元素(Data Element):
是数据的基本单位在计算机程序中通常作为一个整体进行考虑和处理。一个数据元素可由若干个数据项组成。
4. 数据项:
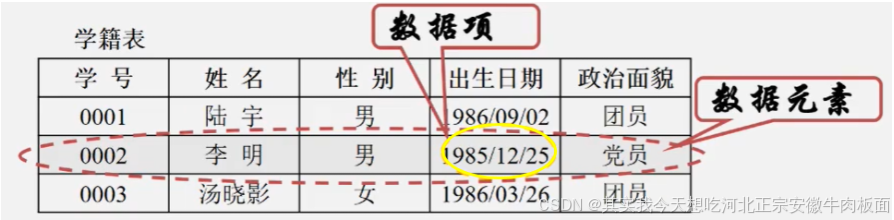
一个数据元素可以由若干个数据项组成。(比如:人可以有眼耳口鼻这些数据项)。数据项是数据不可分割的最小单位。
5. 数据对象(Data Object):
是性质相同的数据元素的集合。是数据的一个子集。
6. 容器(container):
装入数据元素的外部对象。一般是先有数据关系,再有可以装入数据元素的容器,一个容器对应一个数据元素,可以把它想象成一个纸箱。
7. 结点(Node):
数据关系中,用于建立关系支撑的连接点,比如路由器网关,树的分叉;与节点接近但有所区别。
8. 迭代器(iterator):
一个超级接口! 是可以遍历集合的对象,为各种容器提供了公共的操作接口。
9. 前驱 节点:
数据值小于节点n,且与节点n数值最接近的节点(记为节点m)
10. 后继 节点:
数据值大于节点n,且数值最接近节点n的第一个节点(记为节点m)
11. 检索(索引 index):
根据索引快速的找到数据元素;
12. 遍历:
将数据对象中的所有数据元素全部访问一遍;
13. 动态扩容:
数据对象中的数据元素数量发生变化。
二 数据结构分类
数据结构是计算机中组织、管理和存储数据的方式,分为 逻辑结构 和 物理结构(存储结构)。二者的核心区别在于:
-
逻辑结构:关注数据元素之间的抽象关系(如顺序、层次、连接等),与计算机存储无关。
-
物理结构:数据在内存中的实际存储方式(如连续存储、分散存储),直接影响程序性能。
1. 逻辑结构分类
逻辑结构的分类与特点
| 线性结构 | 数据元素间呈一对一关系,形成序列。 | 数组、链表、栈、队列 | 顺序操作(如遍历、排序) |
| 树形结构 | 数据元素间呈一对多关系,形成层次结构。 | 二叉树、B树、堆、字典树 | 文件系统、数据库索引、决策模型 |
| 图结构 | 数据元素间呈多对多关系,形成网络结构。 | 有向图、无向图、邻接表/矩阵 | 社交网络、路径规划、依赖分析 |
| 集合结构 | 数据元素间无明确逻辑关系,仅属于同一集合。 | 哈希集合、无序列表 | 去重、成员检测、数学集合运算 |

1. 集合结构

定义:数据元素之间无明确逻辑关系,仅属于同一集合。 特点:
-
关注元素的唯一性和存在性,而非顺序或关联。
-
核心操作:插入、删除、查找。
常见类型:
哈希集合(HashSet):基于哈希表实现,查找时间复杂度O(1)。
-
示例:Python的set类型。
树集合(TreeSet):基于平衡二叉搜索树实现,元素有序。
-
示例:Java的TreeSet。
应用场景:
-
数据去重:快速检测重复元素。
-
成员检测:判断元素是否存在于集合中。
-
集合运算:并集、交集、差集(如数据库查询优化)。
2. 线性结构

定义:数据元素之间存在一对一的顺序关系,形成线性序列。每个元素有且仅有一个直接前驱和一个直接后继。 特点:
-
元素按顺序排列,无分支。
-
支持遍历、插入、删除等操作。
常见类型:
数组:连续内存存储,支持快速随机访问。
-
示例:int arr[5] = {1, 2, 3, 4, 5};
链表:通过指针链接非连续内存块,支持动态扩展。
-
示例:单链表、双向链表。
栈(Stack):后进先出(LIFO),如函数调用栈。
-
操作:push(入栈)、pop(出栈)。
队列(Queue):先进先出(FIFO),如任务调度队列。
-
操作:enqueue(入队)、dequeue(出队)。
应用场景:
-
数组:需要快速访问元素的场景(如排序)。
-
链表:频繁插入/删除的场景(如实现队列)。
-
栈:撤销操作、表达式求值。
-
队列:消息队列、打印任务管理。
3. 树型结构
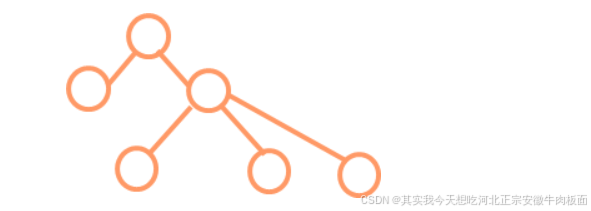
定义:数据元素之间存在一对多的层次关系,形成树状层级结构。 特点:
-
每个节点最多有一个父节点,但可以有多个子节点。
-
具有唯一的根节点,叶子节点无子节点。
常见类型:
二叉树:每个节点最多有两个子节点。
-
示例:二叉搜索树(BST)、平衡二叉树(AVL树)。
B树/B+树:多路平衡查找树,用于数据库索引。
堆(Heap):完全二叉树,支持快速插入和删除最值。
-
类型:最大堆、最小堆。
字典树(Trie):用于字符串前缀匹配,如输入法提示。
应用场景:
-
文件系统:目录与子目录的层次关系。
-
数据库索引:B+树加速数据查询。
-
哈夫曼编码:压缩算法中构建最优前缀树。
4. 图状结构或网状结构
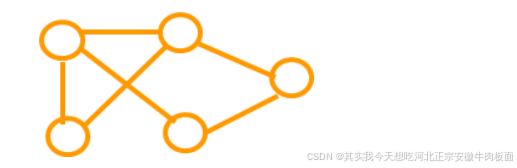
定义:数据元素之间可存在多对多的复杂关系,形成网络结构。 特点:
-
顶点(节点)表示实体,边表示实体间的关系。
-
边可带权重(如距离、成本)或方向(有向图/无向图)。
常见类型:
邻接矩阵:二维数组表示顶点间连接关系。
-
空间复杂度:O(V²),适合稠密图。
邻接表:链表数组存储每个顶点的邻居。
-
空间复杂度:O(V + E),适合稀疏图。
有向图:边有方向(如微博关注关系)。
无向图:边无方向(如微信好友关系)。
应用场景:
-
社交网络:用户之间的关注/好友关系。
-
路径规划:Dijkstra算法求最短路径。
-
推荐系统:基于图的关系挖掘(如PageRank)。
2. 物理结构分类
物理结构的分类与特点
| 顺序存储 | 数据元素在内存中连续存储。 | 数组、动态数组 | 优点:随机访问快; 缺点:插入/删除效率低 | 线性结构(数组、栈、队列) |
| 链式存储 | 数据元素通过指针链接,存储位置不连续。 | 单链表、双向链表、树节点指针 | 优点:插入/删除灵活; 缺点:访问效率低 | 线性结构、树、图 |
| 索引存储 | 通过索引表记录数据地址,数据本身可分散存储。 | 数据库索引、文件系统 | 优点:快速定位; 缺点:索引维护开销 | 集合、线性结构 |
| 散列存储 | 利用哈希函数计算存储位置,数据按计算结果存放。 | 哈希表、布隆过滤器 | 优点:查找极快; 缺点:哈希冲突处理 | 集合、键值对存储 |
总结对比
| 顺序存储 | 数组 | 插入/删除 O(n),访问 O(1) | 静态数据、高频随机访问 |
| 链接存储 | 链表 | 插入/删除 O(1),访问 O(n) | 动态数据、频繁修改 |
| 索引存储 | 结构体数组 + 索引表 | 插入 O(n log n),查找 O(log n) | 数据库、文件系统 |
| 散列存储 | 哈希表 + 链地址法 | 插入/查找 O(1)(平均) | 缓存、字典、去重 |
1. 顺序存储结构
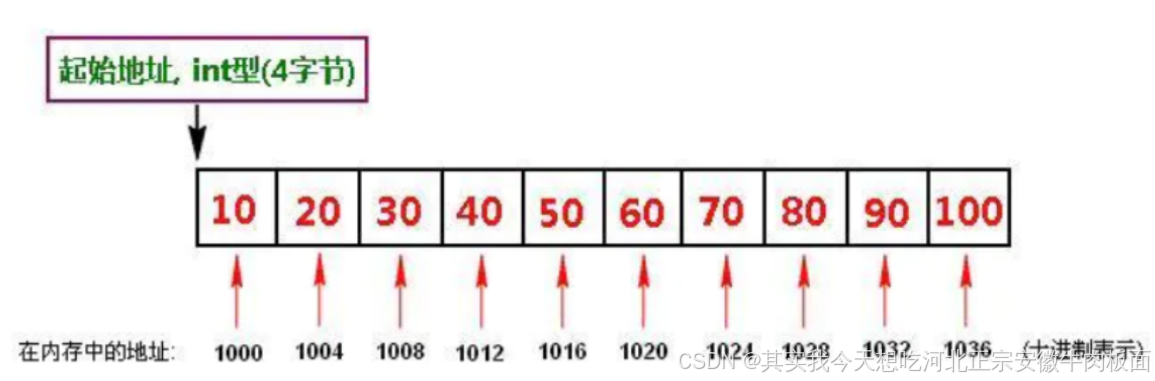
定义:数据元素在内存中按顺序连续存放,通过元素下标直接访问。 特点:
-
物理连续:元素地址连续,无额外指针开销。
-
随机访问:通过下标直接定位元素,时间复杂度为 O(1)。
| 优点 | 访问速度快;内存利用率高(无指针开销)。 |
| 缺点 | 插入/删除需移动大量元素,效率低;容量固定(动态数组扩容有额外成本)。 |
| 实现方式 | 数组、动态数组(如 C++ 的 vector)。 |
| 适用场景 | 数据量固定或变化小,需频繁随机访问的场景(如排序、矩阵运算)。 |
示例:
int arr[5] = {1, 2, 3, 4, 5}; // 定义数组
printf("%d", arr[2]); // 直接访问第3个元素(输出:3)
2. 链接存储结构

定义:数据元素通过指针链接,存储位置不连续。 特点:
-
动态分配:内存按需分配,支持灵活扩展。
-
链式访问:通过指针跳转访问元素,时间复杂度为 O(n)。
| 优点 | 插入/删除效率高(仅修改指针);无需预先分配内存。 |
| 缺点 | 访问效率低(需遍历);指针占用额外内存。 |
| 实现方式 | 单链表、双向链表、树结构(如二叉树的指针实现)。 |
| 适用场景 | 频繁插入/删除的场景(如队列、图结构)。 |
示例:
struct Node { int data; struct Node *next; }; // 定义节点
struct Node a = {10}, b = {20}; a.next = &b; // 手动链接两个节点
printf("%d", a.next->data); // 输出:20
3. 数据索引存储结构

定义:通过索引表记录数据地址,数据本身可分散存储。 特点:
-
快速定位:索引表存储键与物理地址的映射。
-
分层管理:索引与数据分离,需维护索引一致性。
| 优点 | 支持高效范围查询;适合大规模数据管理。 |
| 缺点 | 索引维护复杂(增删需同步更新);存储开销大(需额外索引空间)。 |
| 实现方式 | B树、B+树(数据库索引)、文件分配表(FAT)。 |
| 适用场景 | 数据库索引、文件系统、有序数据查询(如按范围搜索)。 |
示例:
int data[3] = {100, 200, 300}, index[3] = {0, 1, 2}; // 数据与索引表
printf("%d", data[index[1]]); // 通过索引访问(输出:200)
4. 数据散列存储结构 hash
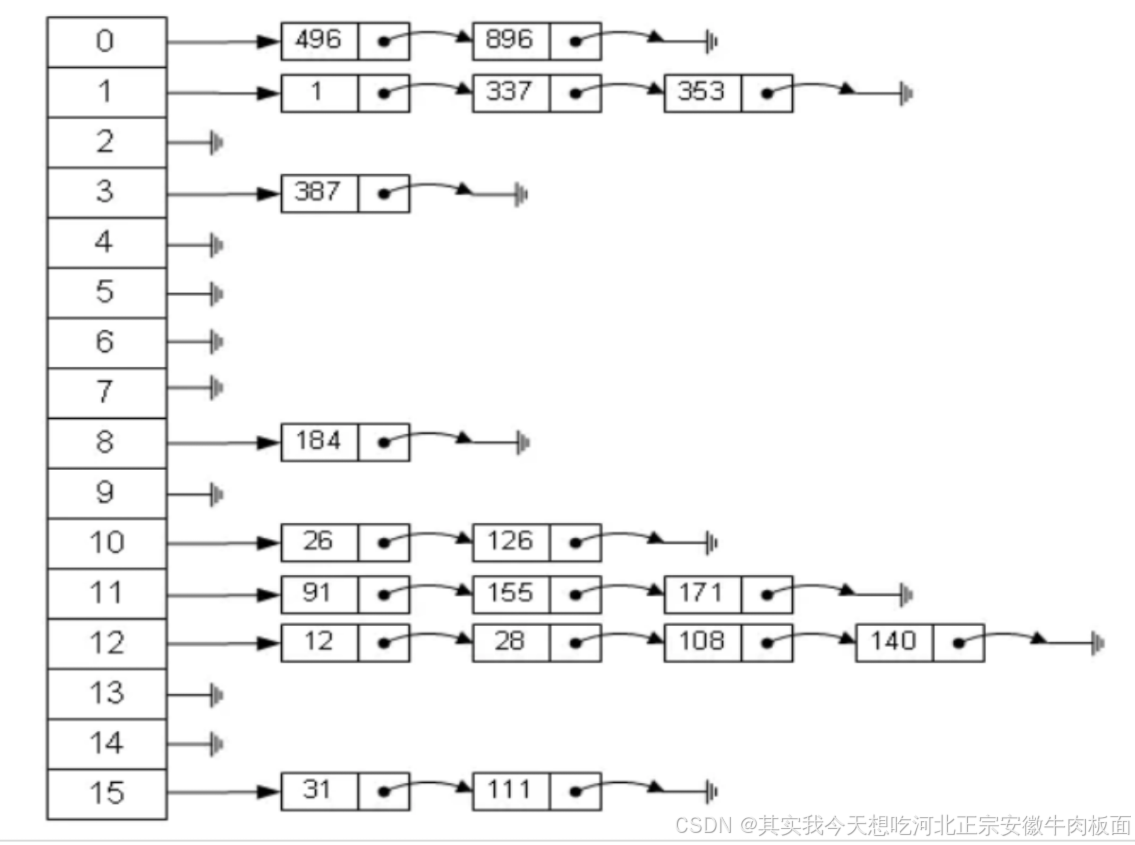
定义:通过哈希函数计算数据存储位置,直接定位内存地址。 特点:
-
快速查找:理想情况下时间复杂度为 O(1)。
-
冲突处理:需解决哈希冲突(如开放寻址法、链地址法)。
| 优点 | 查找速度极快;适合精确匹配查询。 |
| 缺点 | 哈希冲突影响性能;不支持范围查询。 |
| 实现方式 | 哈希表、布隆过滤器、一致性哈希。 |
| 适用场景 | 缓存系统(如 Redis)、字典、去重(如 HashSet)。 |
示例:
struct HashNode { int key; struct HashNode *next; } *table[10] = {NULL}; // 哈希表
int idx = 5 % 10; table[idx] = &(struct HashNode){5, NULL}; // 插入键5
printf("%d", table[idx]->key); // 输出:5
5. 总结
性能对比与分析
| 随机访问 | O(1) | O(n) | O(1)(平均) | O(log n) |
| 插入/删除 | O(n) | O(1) | O(1)(平均) | O(log n) |
| 空间利用率 | 高(连续存储) | 低(指针额外开销) | 中等(哈希表负载因子) | 中等(索引结构) |
| 适用场景 | 静态数据、频繁访问 | 动态数据、频繁修改 | 快速查找、去重 | 有序数据、范围查询 |
| 顺序存储 | int arr[5]; arr[2]=3; | 连续内存,直接访问 |
| 链接存储 | struct Node { … }; a.next = &b; | 动态指针,灵活增删 |
| 索引存储 | data[index[1]] | 索引表加速定位 |
| 散列存储 | table[hash(key)] = &node; | 哈希函数映射,冲突处理 |
3. 总结
逻辑结构与物理结构的对应关系
| 线性结构 | 顺序存储、链式存储 | – 数组(顺序存储) – 链表(链式存储) |
| 树形结构 | 链式存储、顺序存储(完全二叉树) | – 二叉树(指针链式) – 堆(数组顺序存储) |
| 图结构 | 链式存储(邻接表)、顺序存储(邻接矩阵) | – 邻接表(链表实现) – 邻接矩阵(二维数组实现) |
| 集合结构 | 散列存储、索引存储 | – 哈希集合(散列存储) – 有序集合(B树索引存储) |




评论前必须登录!
注册